
AGL走行データが消失した際の原因特定と復旧手順、法令準拠のデータ管理設計、緊急時のBCP運用体制構築を支援します。
AGL概要と車載Linuxの特徴
Automotive Grade Linux(AGL)は車載組み込みシステム向けにLinuxを標準化するオープンソースプロジェクトです。業界各社や学術機関が連携し、車両制御やインフォテイメント機能を共通プラットフォームで実装することで、開発コストの削減と品質向上を図っています。AGLはYocto Projectを基盤にカスタマイズ性を維持しつつ、厳しい耐振動・耐温度要件に対応できるよう設計されています。
特徴
- Yocto Projectベースの柔軟なビルドシステム
- Linuxカーネルをコアとする安全性重視のアーキテクチャ
- クラウド連携やOTA(Over-The-Air)アップデート対応
AGLの構造は「ハードウェア抽象化層」「カーネル」「ミドルウェア」「アプリケーション層」から成り、各層がモジュール化されています。これにより、車載ECU(Electronic Control Unit)ごとに必要な機能だけを組み込むことが可能です。セキュリティやリアルタイム性の要件にも対応し、業界標準の仕様策定を進めています。

技術担当者はAGLの各層の役割を上司に正確に伝え、導入時のリスクやメリットを明確に説明してください。
AGL導入時のモジュール選定やカスタマイズ範囲で混同しやすい点を整理し、仕様適合性を優先することを心がけてください。
走行データの種類と法的要件
車載システムが記録する走行データには主に以下の3種類があります。GPS位置情報は経路解析や事故調査に必須で、CAN(Controller Area Network)データは車両制御信号や速度・エンジン回転数を示し、センサーデータは加速度やブレーキ・ステアリング操作などを記録します。これらを適切に保存・参照できることが、事故対応や品質保証において法令遵守の観点から必須です。
主な法的要件
- 道路運送車両法:記録装置義務付けと保存期間(最長3年)[出典:国土交通省『道路運送車両法施行規則』2020年]
- 運輸安全マネジメント制度:事業者による定期的なデータ監査と報告義務[出典:国土交通省『運輸安全マネジメント制度ガイドライン』2019年]
- 個人情報保護法:運転者の行動ログに含まれる個人情報の取扱い[出典:個人情報保護委員会『ガイドライン』2017年]
これらを踏まえ、AGL環境ではログファイルのフォーマット統一とタイムスタンプの正確性確保が重要です。たとえば、CANデータはセッションファイルとしてバイナリ形式で出力されることが多く、復旧時にはバイナリ解析ツールが必要です。GPSデータはNMEA形式でCSVなどに変換し、可視化ツールで経路再現を行います。
| データ種別 | フォーマット | 保存期間 | 法令 |
|---|---|---|---|
| GPS位置情報 | NMEA/CSV | 最長3年 | 道路運送車両法 |
| CANデータ | バイナリ/DBC | 最長3年 | 道路運送車両法 |
| センサーデータ | CSV/JSON | 最長1年 | 運輸安全マネジメント |
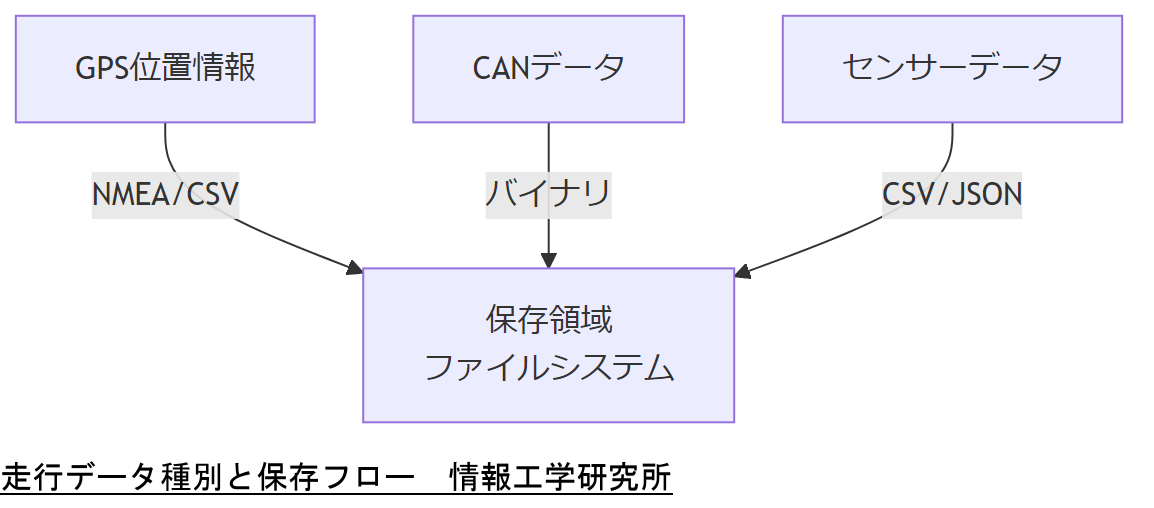
各データ種別ごとに保存要件が異なる点を、法務部門へ正確に説明し、保存期間管理の責任者を明確にしてください。
フォーマット変換時のデータ欠損やタイムスタンプずれに注意し、解析前に整合性チェックを必ず実施してください。
データ消失の原因とリスク評価
AGL環境における走行データ消失は、原因の特定とリスク評価を迅速に行うことで被害を最小限に抑えられます。本章では主な原因を分類し、発生頻度や業務への影響度を評価して対応優先度を明確化します。
主な原因分類
- ハードウェア故障:耐振動試験に合格しても、長期運用でSSDやeMMCの書き込み寿命到達が発生します。
- ファイルシステム破損:電源断や不正シャットダウンによりジャーナリング機能が追いつかず整合性が失われます。
- ソフトウェアバグ:アプリケーション層やミドルウェアのメモリリーク・例外未処理がデータ欠損を誘発します。
- サイバー攻撃・不正改ざん:外部からのランサムウェア感染や不正侵入によるデータ消去リスク。
それぞれの原因について、発生頻度(高・中・低)、影響度(重大・中程度・軽微)をマトリクス評価すると、ハードウェア故障とファイルシステム破損は頻度が高く影響も大きいため最優先で監視・予防策を講じる必要があります。
| 原因 | 発生頻度 | 影響度 | 優先度 |
|---|---|---|---|
| ハードウェア故障 | 高 | 重大 | 最優先 |
| ファイルシステム破損 | 高 | 重大 | 最優先 |
| ソフトウェアバグ | 中 | 中程度 | 高 |
| サイバー攻撃 | 低 | 重大 | 高 |
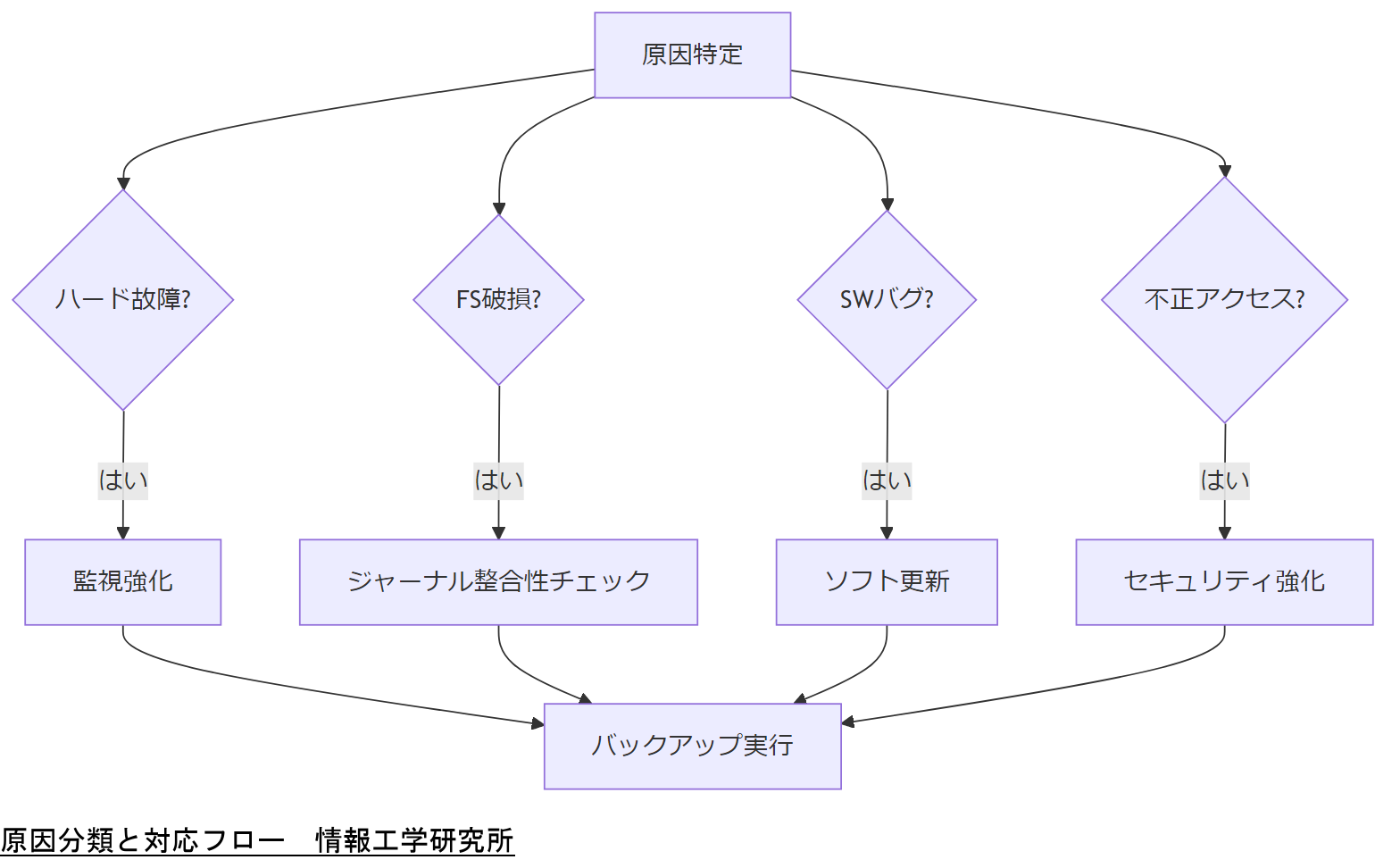
原因マトリクスを基に、運用部門へ優先的に対策すべき項目を示し、予算・リソースの配分を合意してください。
発生頻度と影響度を正確に評価し、対応漏れや過剰対策を防ぐため、定量的なログ分析を併用してください。
初期診断と即時対応フロー
障害発生後、まずは速やかに状態を把握し、二次被害を防止するための初期診断と即時対応が必要です。本章では、ログ収集から仮復旧までのフローを解説します。
対応フロー概要
- システムログの取得:journalctlやdmesgコマンドで直近ログを抽出
- データ保全モード移行:読み取り専用マウントで書き込み抑制
- 電源管理確認:バッテリー/DC電源の安定供給を確保
- 緊急バックアップ:rsyncによる差分コピー
| ステップ | 目的 | ツール |
|---|---|---|
| ログ収集 | 原因推定 | journalctl, dmesg |
| 読み取り専用化 | データ保全 | mount -o ro |
| 電源安定化 | 連続稼働 | UPS, バッテリー交換 |
| 緊急コピー | データバックアップ | rsync |

初期診断の各ステップで使用するツールと運用フローを運用担当者に周知し、緊急対応手順の理解を得てください。
読み取り専用化のタイミングを誤るとログ不足に繋がるため、ログ収集と読み取り専用化は並行して実施してください。
ファイルシステム解析と復旧プロセス
ファイルシステム破損時の復旧は、ジャーナリングの有無やファイル構造に応じた手順を踏むことが肝要です。本章ではext4およびbtrfsを例に、解析ツールと復旧手順を解説します。
解析・復旧ツール
- e2fsck:ext4ジャーナル整合性チェック・修復
- debugfs:メタデータ閲覧および直接ファイル抽出
- btrfs restore:btrfsスナップショットからのデータ抽出
- photorec:ファイルシステム構造を無視したデータ復元
| ツール | 対応FS | 機能 | 備考 |
|---|---|---|---|
| e2fsck | ext4 | 整合性チェック・修復 | オフライン推奨 |
| debugfs | ext2/3/4 | メタデータ操作・抽出 | 読み取り専用で使用 |
| btrfs restore | btrfs | スナップショット復旧 | スナップショット必須 |
| photorec | 汎用 | ファイルヘッダ解析復元 | 構造不明時に有効 |
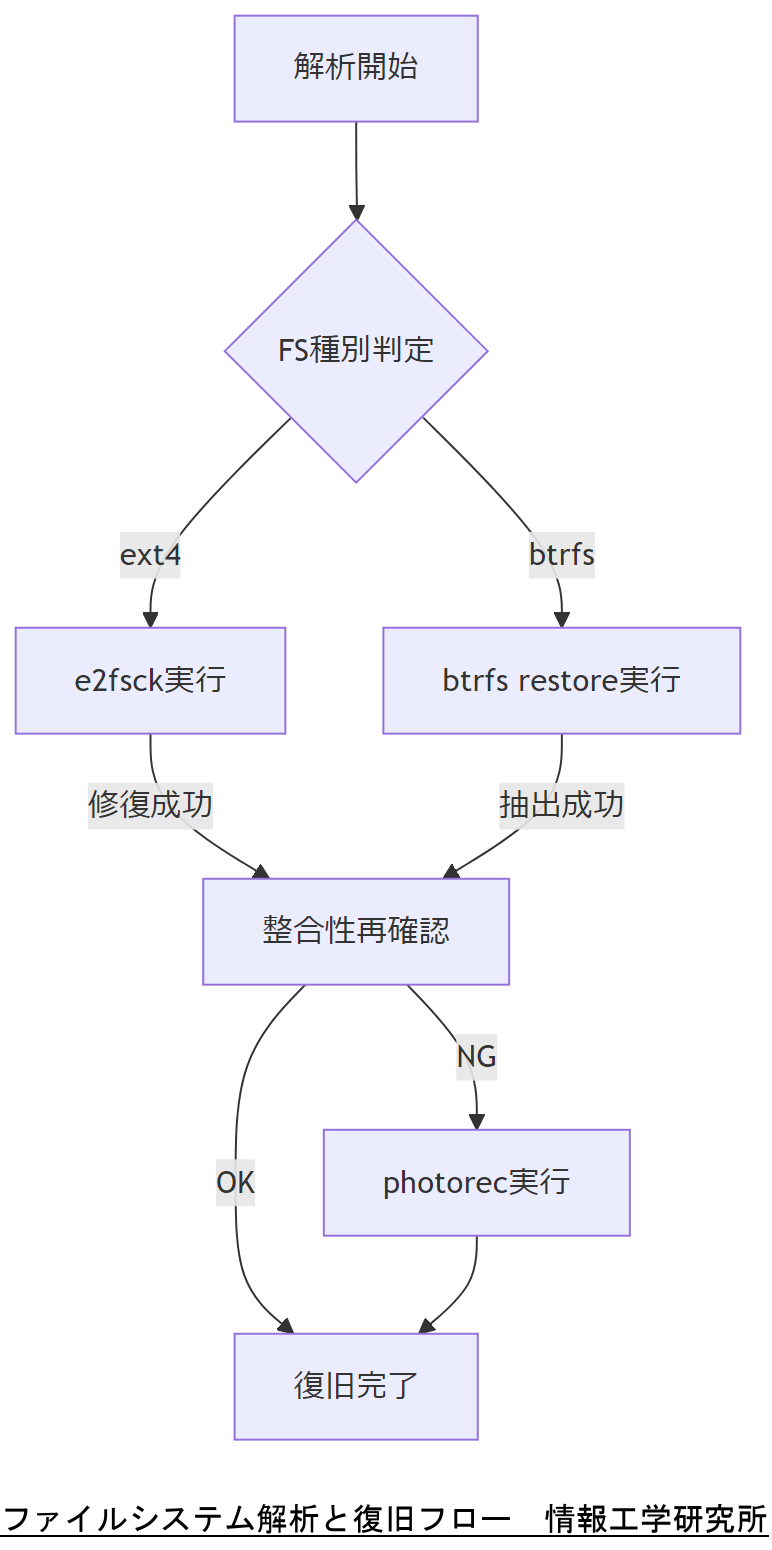
復旧ツールごとの前提条件とリスクを運用チームに説明し、オフライン解析の実施可否を合意してください。
スナップショット取得忘れやオンライン修復による追加破損を防ぐため、必ず読み取り専用コピーで事前検証を行ってください。
セキュリティ対策と暗号化解除
走行データは不正アクセスや紛失時の情報漏えいを防止するため、保存領域で暗号化を実施します。AGL環境ではLinux標準のdm-crypt/LUKSを用い、AES-256などの強力な暗号化方式を適用します。本節では暗号化設定手順と復号(復旧)プロセスを解説します。
暗号化・復号の流れ
- 初期設定:cryptsetup luksFormat でLUKS領域を作成
- キー管理:パスフレーズまたはTPM連携による自動アンロック
- マウント時復号:cryptsetup luksOpen でデバイスを復号
- 復旧時対応:バックアップキーによるオフライン復号
| 操作 | コマンド | 備考 |
|---|---|---|
| LUKS領域作成 | cryptsetup luksFormat /dev/sdX | 事前にパーティションを準備 |
| デバイス解錠 | cryptsetup luksOpen /dev/sdX cryptdata | マウント前に実行 |
| ファイルシステム作成 | mkfs.ext4 /dev/mapper/cryptdata | 初回のみ |
| オフライン復号 | cryptsetup luksOpen --readonly /dev/sdX cryptdata | 復旧作業時に使用 |
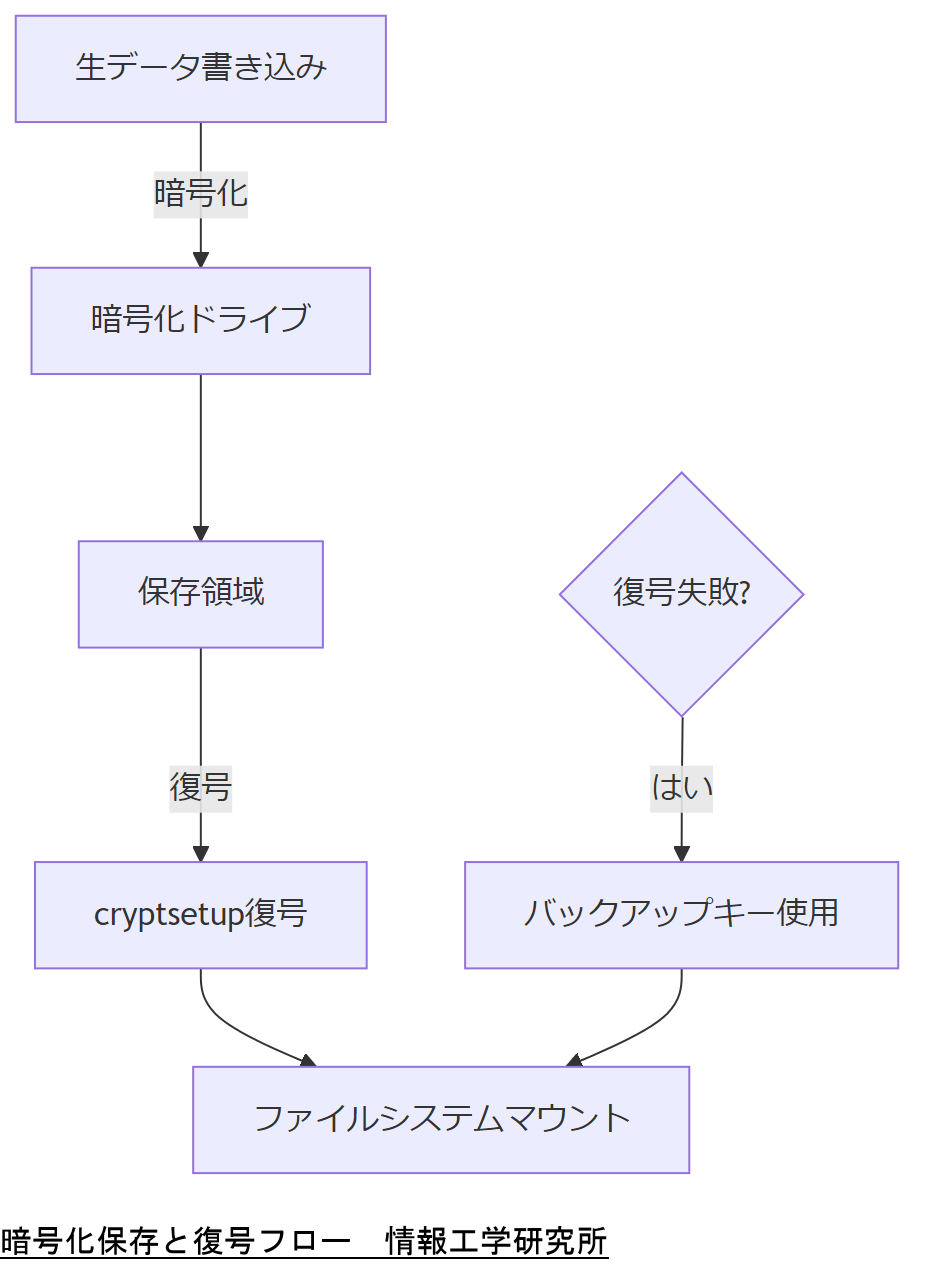
暗号化キーの管理責任者と保管手順をセキュリティ部門と合意し、定期的なキー更新(ローテーション)計画を共有してください。
復旧時にキー紛失リスクが高まるため、バックアップキーのオフライン保管とテスト復号手順を必ず定義・実施してください。
法令・政府方針の最新動向(日本)
車載データ管理では法令や政府方針の動向把握が不可欠です。ここでは近年改定された主要法令とガイドラインのポイントを整理し、AGL環境での準拠事項を明確化します。
最新動向
- 道路運送車両法施行規則改正(2024年10月施行):テレマティクスデータの保存形式・暗号化要件が追加 [出典:国土交通省『道路運送車両法施行規則改正』2024年]
- 運輸安全マネジメント制度ガイドライン改定(2024年4月公表):デジタルログのリアルタイム監視と報告手順の強化 [出典:国土交通省『運輸安全マネジメント制度ガイドライン改定』2024年]
- サイバーセキュリティガイドライン(2023年12月改定):車載システム向け脅威リストと緊急対応プロセスを追加 [出典:内閣サイバーセキュリティセンター『サイバーセキュリティガイドライン』2023年]
| 名称 | 施行・公表日 | 主な改定内容 | 適用範囲 |
|---|---|---|---|
| 道路運送車両法施行規則改正 | 2024年10月 | テレマティクスデータの暗号化・フォーマット義務化 | 全自動車事業者 |
| 運輸安全マネジメント制度ガイドライン改定 | 2024年4月 | リアルタイムデータ監視報告の手順強化 | 運輸事業者全般 |
| サイバーセキュリティガイドライン | 2023年12月 | 車載システム向け脅威リスト追加、対応フロー明示 | 重要インフラ事業者 |
最新法令の改定内容がシステム要件に与える影響を法務・開発部門に提示し、対応スケジュールを承認してください。
改定内容の適用範囲を誤解しないよう、対象車両・サービス区分を明確化し、運用開始前に再評価を実施してください。
アメリカ・EUの法令・政府方針とインパクト
日本以外でも車載データ管理に関する法令・指針が整備されており、グローバル展開企業は各地域の要件を同時に満たす必要があります。本節では、米国NHTSA指針とEUのUNECE規則およびGDPRが与える影響を整理します。
NHTSA指針
米国運輸省(NHTSA)は2021年に『Cybersecurity Best Practices for Modern Vehicles』を公表し、車載システムのサイバーセキュリティ設計要件を明示しています。リアルタイムログ監視、侵入検知システム(IDS)、暗号化通信の採用などが推奨され、データ復旧時にも改ざん検知機能が求められます。[出典:米国運輸省『Cybersecurity Best Practices for Modern Vehicles』2021年]
UNECE規則とGDPR
国連欧州経済委員会(UNECE)が策定するWP.29規則(自動車サイバーセキュリティおよびソフトウェア更新管理)は2020年に採択され、認証要件を明確化しました。また、GDPR(EU一般データ保護規則、2016年)では個人データの取扱い基準を厳格化しており、走行ログに含まれる位置情報や運転者情報の取り扱いが制限されます。[出典:欧州委員会『UNECE WP.29規則概要』2020年][出典:欧州委員会『一般データ保護規則(GDPR)』2016年]
| 項目 | NHTSA指針(米国) | UNECE/GDPR(EU) |
|---|---|---|
| データ保護要件 | IDS・暗号化推奨 | 認証要件・暗号化必須 |
| ログ監視 | リアルタイム監視義務 | 定期検査レポート提出 |
| 個人情報取扱い | ガイダンス提供 | 厳格な同意取得・消去権保証 |
| 改定時期 | 2021年 | 2020年/2016年 |
米国およびEUの要件差異を法務部門に示し、グローバル共通プラットフォームへの適用方針を合意してください。
地域別規制の統合設計では要件相違による実装漏れを防ぐため、条文対照表を作成し定期的に更新してください。
資格・人材育成・募集要件
AGL環境の運用・復旧を円滑に行うには、専門知識を有する技術者の育成と適切な資格取得が不可欠です。本章では必要な公的資格と社内教育プログラム、募集要件のポイントを解説します。
必要な公的資格
- 情報処理安全確保支援士(IPA):セキュリティ監査・運用知識が証明される国家資格[出典:情報処理推進機構『情報処理安全確保支援士制度概要』2022年]
- 電気通信主任技術者(総務省):通信ネットワーク設計・運用管理の専門家認定[出典:総務省『電気通信主任技術者制度』2021年]
- 高度情報処理技術者(IPA):Linuxシステム設計・トラブルシューティング能力を認定[出典:情報処理推進機構『高度情報処理技術者試験要領』2023年]
資格取得のほか、社内研修では以下の内容をカリキュラムに組み込むことが推奨されます。
- Linuxシステム基礎とAGL特有のアーキテクチャ講習
- ファイルシステム復旧演習(ext4/btrfs)
- 暗号化・キー管理の実技ワークショップ
- 緊急時BCP演習とテーブルトップ演習
| 資格 | 取得目安 | 研修項目 |
|---|---|---|
| 情報処理安全確保支援士 | 6か月 | セキュリティ監査演習 |
| 電気通信主任技術者 | 1年 | ネットワーク設計実践 |
| 高度情報処理技術者 | 6か月 | Linuxトラブルシュート |
研修カリキュラムと資格取得計画を人事・教育担当と共有し、受講スケジュールを確定してください。
資格取得後の実務経験を組み合わせることで、知識だけでなく対応力を高める育成設計を意識してください。
システム設計・運用・点検のベストプラクティス
信頼性と可用性を確保するため、車載Linux環境の設計から日常運用、定期点検まで一貫したプロセスが重要です。本章では冗長構成や監視・点検フローをまとめます。
設計時の留意点
- 冗長化:RAID 1/5構成でディスク故障耐性を向上
- クラスタリング:複数ECU間で負荷分散・フェイルオーバー
- スナップショット:定期的なbtrfs/ZFSスナップショット取得
- ログ集約:syslogサーバとの連携で集中管理
運用・点検フロー
| 頻度 | 項目 | 方法 |
|---|---|---|
| 毎日 | ログ容量チェック | df, duコマンド |
| 週間 | ジャーナル整合性確認 | e2fsck(読み取り専用) |
| 月間 | スナップショットテスト | btrfs send/receive |
| 年次 | BCP演習 | テーブルトップ演習 |
運用・点検フローと担当者を運用部と保守部で共有し、SLA・責任範囲を明確化してください。
定期点検の結果と異常検知のタイムスタンプを帳票化し、運用改善サイクルに組み込むことを徹底してください。
BCPの策定と運用
事業継続計画(BCP)は、緊急時にもシステム稼働を維持し、AGL走行データの可用性を確保するために不可欠です。データ保存は3重化を基本とし、運用は「緊急時」「無電化時」「システム停止時」の3段階に分けた手順を策定します。さらに、10万人以上のユーザーを抱える場合は、フェーズごとにより細分化した対応計画が必要です。
BCP運用フェーズ
- 通常運用フェーズ:定常バックアップ3重化(オンサイト・オフサイト・クラウド)
- 緊急時フェーズ:システム監視で異常検知後、即時フェイルオーバー
- 無電化フェーズ:UPS/非常用発電機による電源維持
- 完全停止フェーズ:代替データセンター/モバイル回線を活用した限定運用
| フェーズ | 主な対応 | 運用ポイント |
|---|---|---|
| 通常運用 | 3重バックアップ実行 | バックアップ整合性チェック |
| 緊急時 | 自動フェイルオーバー | 切替テストの定期実施 |
| 無電化 | UPS/発電機起動 | 燃料・バッテリー残量監視 |
| システム停止 | 代替ネットワーク運用 | 回線切替リハーサル |
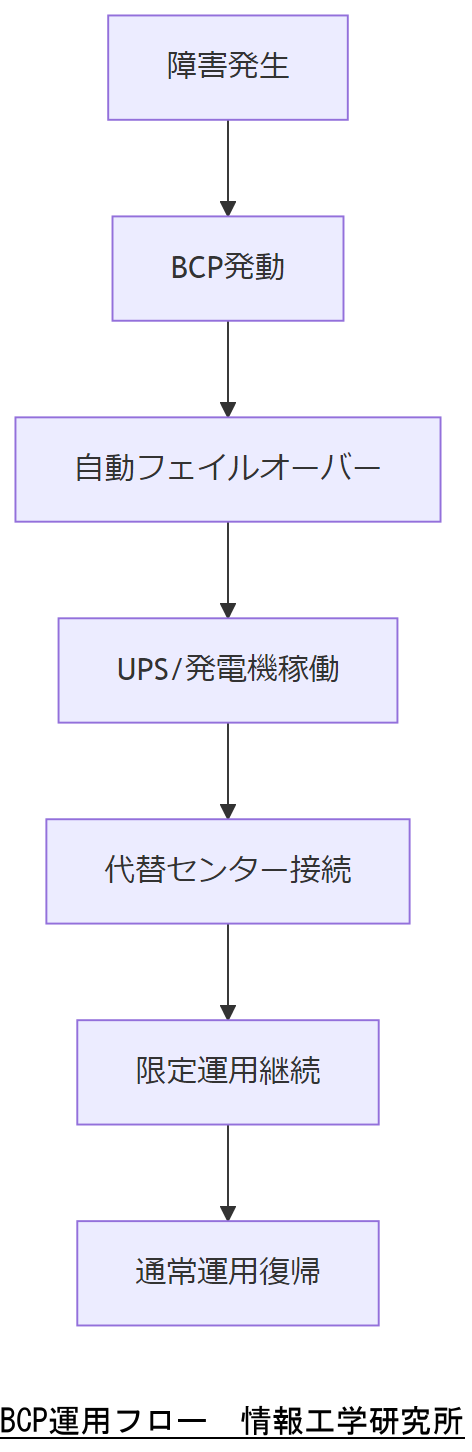
BCP各フェーズの責任者と実行手順を事前に共有し、緊急発動時の役割分担を明確にしてください。
3重バックアップの整合性を定期的に検証し、テストフェイルオーバーを通じて想定外の運用障害を未然に防いでください。
ステークホルダー別注意点
AGL走行データの管理・復旧プロジェクトには、多様な関係者が関与します。各ステークホルダーの役割と注意すべきポイントを整理し、円滑なプロジェクト推進を支援します。
主な関係者と役割
- 開発部門:AGLカスタマイズ/アプリ実装。仕様変更時の影響範囲を把握。
- 運用部門:日常監視と障害初動対応。対応手順の遵守度を定期確認。
- 品質保証部門:テスト計画立案と実施。復旧テストの網羅性を担保。
- 法務部門:法令遵守チェックと契約レビュー。データ保存要件の変更に速やかに対応。
- 経営層:予算承認と方針決定。リスク評価レポートの理解と承認。
| 関係者 | 注意点 | 連携方法 |
|---|---|---|
| 開発部門 | 仕様変更の影響試算不足 | 定例レビュー会議 |
| 運用部門 | 手順逸脱によるデータ損失 | 手順書共有・演習 |
| 品質保証部門 | テストケース漏れ | クロスチェック |
| 法務部門 | 法令改定の見落とし | 定期情報共有 |
| 経営層 | リスク評価情報の理解不足 | 簡易レポート提示 |
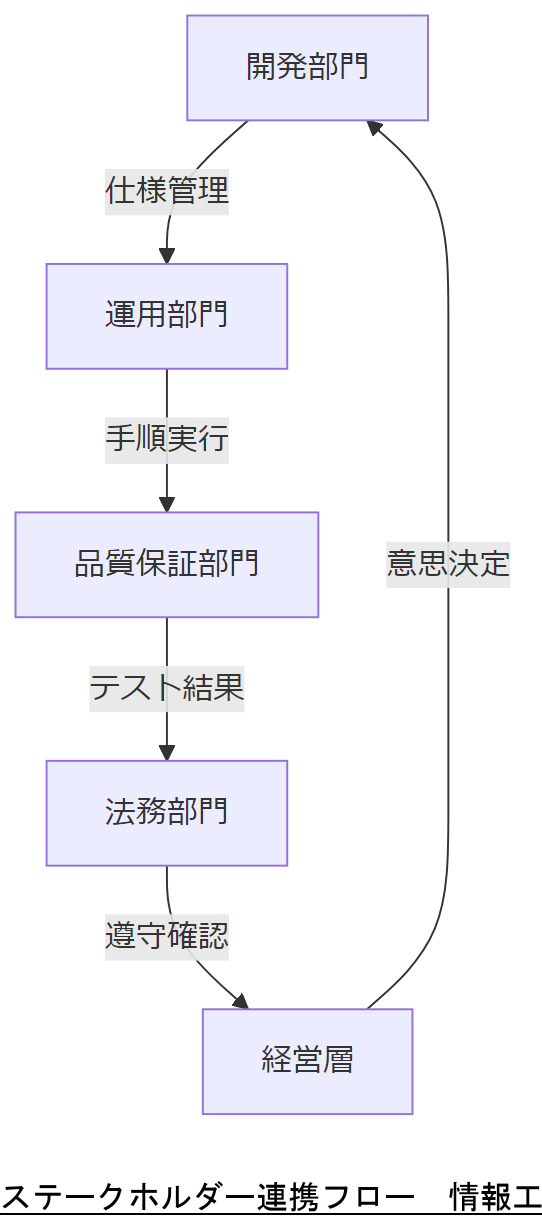
各部門の役割と注意点を図示してプロジェクトキックオフ時に全関係者へ周知し、承認を得てください。
関係者間の情報ギャップを防ぐため、定例コミュニケーションチャネルとエスカレーションルールを明確に設定してください。
外部専門家へのエスカレーションタイミング
復旧作業中に想定外の障害やスキル不足を感じた場合、適切なタイミングで外部専門家にエスカレーションすることが重要です。本章では判断基準と弊社への相談フローを示します。
エスカレーション判断基準
- 復旧試行3回以上で進捗が得られない場合
- 重要ログの破損範囲が予想以上に広い場合
- 暗号化キーが不明または破損しており、社内復号が不可能な場合
- 法令遵守要件との整合性が判定困難な場合
| 条件 | 社内対応 | エスカレーション |
|---|---|---|
| 復旧試行3回未満 | 継続試行 | 不要 |
| 3回以上失敗 | 一時停止 | 弊社相談 |
| キー管理不明 | 調査継続 | 弊社相談 |
| 法令不明点 | 法務確認 | 弊社相談 |
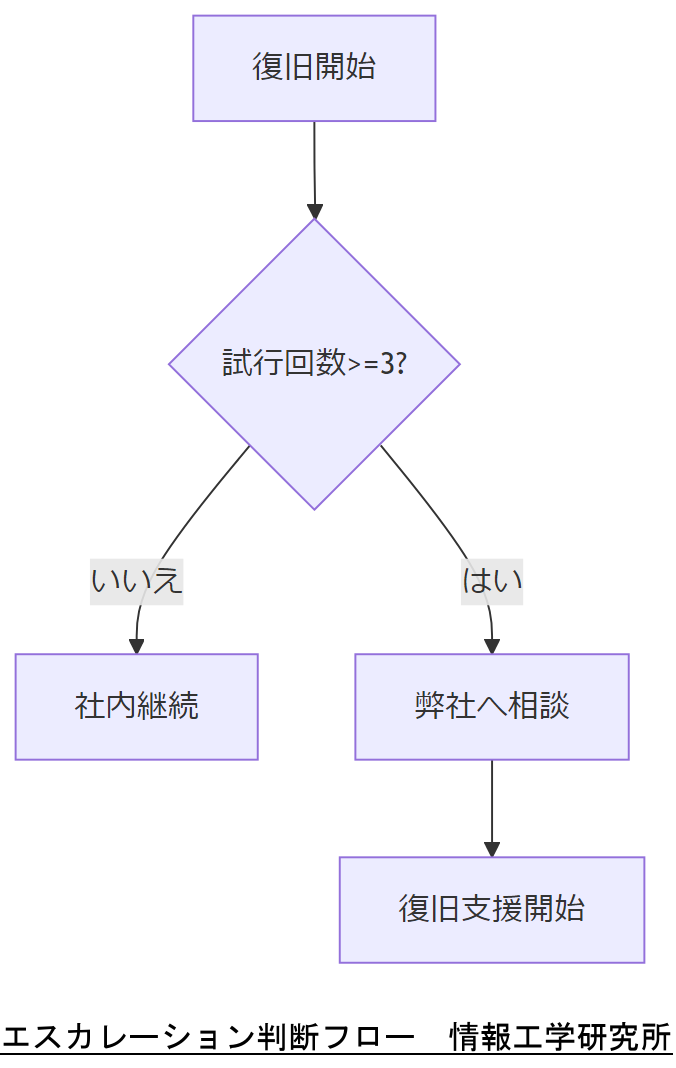
エスカレーション条件と弊社お問い合わせフォームへの案内手順を運用部門と法務部門で合意してください。
初動判断の遅延を防ぐため、エスカレーション基準を復旧手順書に明示し、実際の演習で検証してください。
弊社への依頼メリットと流れ
情報工学研究所(弊社)は他社では難易度が高い案件も多数復旧してきた実績があります。本章では弊社にご依頼いただくメリットと、問い合わせから復旧完了までの流れをご紹介します。
依頼メリット
- 高度解析技術:独自開発ツールによる破損データ回収
- 安心の法令準拠支援:最新法令ガイドライン対応
- 迅速対応:現地調査から24時間以内の初動レポート提供
- ワンストップ:解析~復旧~納品まで一貫サポート
| フェーズ | 所要時間 | 主要作業 |
|---|---|---|
| お問い合わせ | 即日 | 障害状況ヒアリング |
| 現地調査 | 1~2日 | デバイス診断 |
| 解析・復旧 | 3~5日 | データ抽出・整合性検証 |
| 納品・報告 | 即日 | 復旧データ納品、報告書作成 |
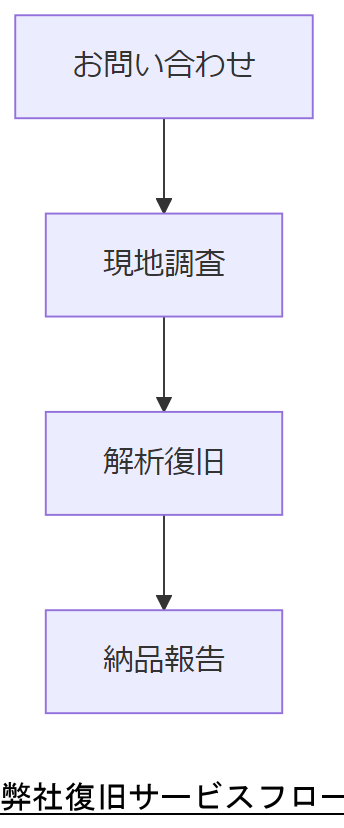
弊社への依頼メリットとフローを社内稟議資料としてまとめ、経営層へご承認をお願いします。
サービス利用時の想定スケジュールを把握し、内部リソースと調整しながら依頼のタイミングを計画してください。
まとめと今後の展望
本記事ではAGL環境での走行データ復旧に必要な技術要素と運用体制、法令対応、BCP策定、ステークホルダー調整まで網羅しました。情報工学研究所はこれらに精通した技術と経験を活かし、お客様の車載システムデータ復旧を全面サポートします。
今後の展望
- AI解析の導入:故障パターン自動検知による復旧時間短縮
- 標準化推進:AGL標準仕様の更なる進化支援
- グローバル対応:地域法令変化への迅速対応体制強化
今後検討すべき技術要素を技術戦略会議で共有し、優先的に投資すべきポイントを議論してください。
最新技術導入のタイミングを逸しないよう、技術動向と業務ニーズを定期的にレビューしてください。