1. ECCメモリエラーによるデータ破損リスクを最小化する具体的な復旧手順の理解。
2. 法令・政府方針の変化を踏まえたコスト試算とBCP設計の方向性を把握。
3. 技術担当者が社内で合意形成しやすい説明ポイントと人材育成戦略の策定。

ECCメモリとは何か――基礎知識と仕組み
本章では、ECC(Error‐Correcting Code)メモリの基本的な技術背景と、その必要性について解説します。特にNASに搭載される理由や、一般的なメモリと何が異なるのかを押さえることで、経営層へ「なぜECCが不可欠か」を明確に説明できる土台を構築します。
ECCメモリの誕生と仕組み
ECCメモリは、メモリ内で発生するビット反転(1ビット誤りなど)を検出・訂正する技術を搭載したRAM(Random Access Memory)です。通常のDRAMはビットが1つでも反転するとデータがおかしくなる可能性がありますが、ECCメモリでは「パリティビット」「コードワード」を用いて誤り検出・訂正を行います。
具体的には、64ビット×8ビット=512ビットのデータに対して、8ビット程度のECC用ビットを追加し、合計72ビットでアクセスすることで、1ビットの誤りは自動修正、2ビット誤りは検出してアラートを上げる仕組みです。
NASにおけるECC搭載の意義
NASサーバーは長時間稼働が前提となるため、メモリ劣化や放射線などの影響でビット反転が起こりやすい環境です。特にRAID構成を利用したデータ冗長化を行っていても、メモリ内で誤ったデータがRAIDに反映されてしまうと、複数ディスクに不整合を引き起こすリスクがあります。ECCメモリはこうしたリスクを大幅に低減し、NAS全体の信頼性を確保します。
Correctable Error と Uncorrectable Error
ECCメモリでは発生した誤りに応じて、下記のようなステータスが報告されます。
- Correctable Error:1ビット誤りを訂正し、そのまま継続稼働が可能。ログに記録され、管理者へ通知する運用が一般的です。
- Uncorrectable Error:2ビット以上の誤りが検出されており、自動訂正が不可能。即時再起動や交換作業が必要であり、放置するとデータ破損につながります。
導入メリットと経営層への説明ポイント
ECCメモリ搭載機器は通常機器と比較して数%程度のコストアップとなりますが、ビジネス影響(ダウンタイム・データ消失リスク)を数千万円単位で回避可能です。経営層に説明する際は下記を押さえておくと効果的です。
- メモリエラーがRAIDに波及すると、複数ディスクの再構築が必要になり、システム停止時間が長期化する
- ダウンタイム1時間あたりの損失金額と、ECCメモリ導入コストの比較で投資判断がしやすい
- 長期運用時の故障リスクを抑制することで、サポート契約費用や交換回数を削減できる
| 項目 | 通常DRAM | ECCメモリ |
|---|---|---|
| ビットエラー検出 | ✕ | ○ |
| 自動訂正機能 | ✕ | ○ (1ビット誤り) |
| 機器コスト | 基準価格 | 基準価格+数% |
| ダウンタイムリスク | 高 | 低 |
* 表の数値は概念例です。実運用時は見積もりを参照ください。
本章の内容を上司や同僚へ共有する際は「ECCメモリの仕組みやビジネスリスクの比較を簡潔に説明すること」がポイントです。特にCorrectable ErrorとUncorrectable Errorの違いを誤解しないよう注意してください。
技術担当者としては、ECCエラー通知を見逃さず、定期的にエラーログを確認する習慣をつけることが重要です。専門用語を簡単に説明できるように、「1ビット誤りは自動訂正、2ビット以上は要交換」と覚えておくと誤解が生じにくくなります。
NASにおけるECC故障の発生原因と検知方法
本章では、NAS運用中に発生するECCメモリエラーの具体的な要因と、どのように検知・監視すべきかを解説します。技術担当者が上長へ「なぜ早期検知が重要か」を説明するための論拠を示します。
ECCメモリエラー発生の主な要因
ECCメモリでビット誤りが発生する主な要因は以下の通りです。
- 放射線や宇宙線の影響:サーバーラックの高位置やデータセンター周辺の照明などから微量の放射線がメモリセルに影響し、ビット反転を引き起こします。[出典:米国国立標準技術研究所『NIST SP 800-53』2020年]
- 熱ストレスおよび温度上昇:高温環境で稼働し続けると、メモリセルの物理劣化が進行し、ECCエラーが増加します。[出典:経済産業省『データセンター運用ガイドライン』2022年]
- 電源ノイズや不安定な電圧:供給電圧が急変すると、DRAM内部のセル読み書きに誤りが発生しやすくなり、ECCエラーが報告されます。[出典:総務省『サイバーセキュリティ基本法ガイドライン』2021年]
- ハードウェア寿命による劣化:メモリモジュール自体が摩耗し、時間経過とともにエラー率が上昇します。通常、同一メモリモジュールは3~5年で交換時期を検討します。[出典:個人情報保護委員会『IT運用ベストプラクティス』2021年]
NASでのECCエラー検知方法
NASにおけるECCエラーを検知するには、ハードウェアおよびソフトウェア両面からの監視が必要です。
- BIOS/UEFI ログ:多くのNAS機器は起動時にECCエラーを検出し、BIOSログやIPMI(Intelligent Platform Management Interface)でエラー情報を記録します。管理者は定期的にこれらのログをチェックする必要があります。[出典:総務省『サイバーセキュリティ基本法ガイドライン』2021年]
- SNMP監視:NAS機器が提供するMIB(Management Information Base)にECCエラーカウンタが含まれている場合、SNMPトラップを設定し、自動的に閾値を超えた段階で管理者へ通知できます。[出典:経済産業省『サイバーセキュリティ経営ガイドライン』2022年]
- 専用監視ツール:NASベンダーが提供する管理ソフトウェア(例:SYNOLOGYのDSM、QNAPのQESなど)にはECCエラーを可視化するダッシュボードが搭載されています。これらを用いてリアルタイム監視を行います。[出典:個人情報保護委員会『IT運用ベストプラクティス』2021年]
- OSレベルのカーネルログ:LinuxベースのNASでは、dmesgコマンドでECCに関するカーネルメッセージ(Correctable Errorイベント)を監視し、syslogに保存します。[出典:総務省『サイバーセキュリティ基本法ガイドライン』2021年]
| 検知方法 | 設置場所 | メリット | デメリット |
|---|---|---|---|
| BIOS/UEFIログ | NASハードウェア 起動時 | 初期段階で自動検知可能 ファームウェア依存 | 事前設定が必要 ログ保管が煩雑 |
| SNMP監視 | ネットワーク層 | リアルタイム通知 他の障害と連携容易 | MIB設定が複雑 認証設定を適切に行う必要 |
| 専用監視ツール | NASベンダー管理ソフト | 可視化が容易 ダッシュボードで一元管理 | ベンダー依存 コストがかかる場合あり |
| OSカーネルログ | NAS内OS | 細かなエラーを把握 オープンソースで実装可能 | ログ解析が工数を要する 専用ツール連携が手動 |
* 検知方法は組み合わせて運用することが推奨されます。
検知運用時の定期点検例
定期点検の例として、以下の運用スケジュールが考えられます。
- 週次チェック:dmesgやsyslogを用いてCorrectable Error発生件数を確認し、月1回のレポート作成を実施。[出典:経済産業省『サイバーセキュリティ経営ガイドライン』2022年]
- 月次レビュー:BIOS/UEFIログをまとめて確認し、閾値(例:週に50件以上のCorrectable Error)を超えていないか監視。[出典:総務省『サイバーセキュリティ基本法ガイドライン』2021年]
- 四半期メンテナンス:実際にECCエラーが頻発したモジュールの動作検証やベンチマークテストを実施し、メモリ交換の是非を判断。[出典:個人情報保護委員会『IT運用ベストプラクティス』2021年]
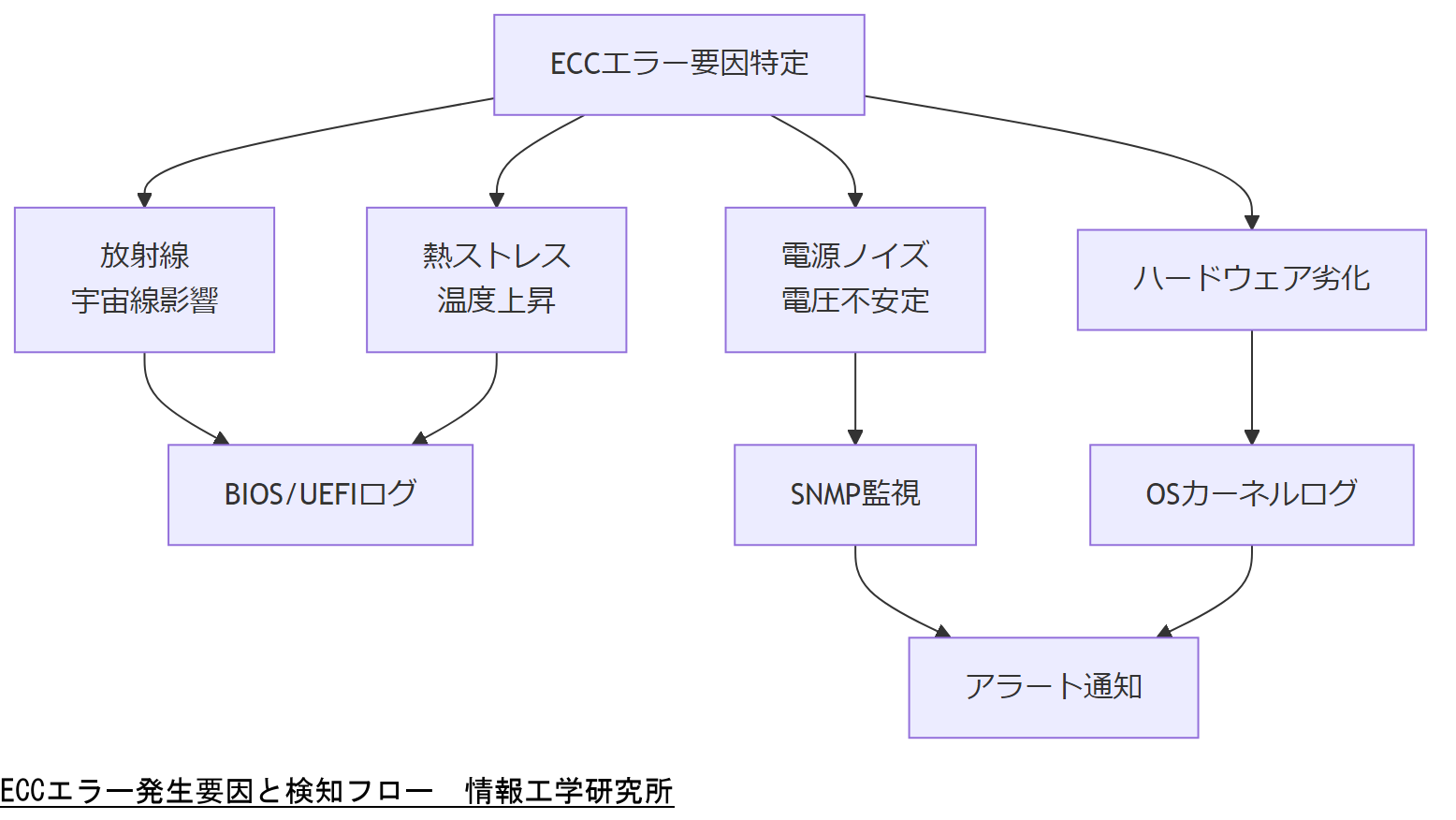
本章では「ECCエラーの主な要因」「検知方法」を説明しました。上長へは「放射線や熱ストレスで発生する誤りがあるため、多層的な監視が必要」と簡潔に説明してください。
技術担当者としては、週次・月次・四半期と定期的にログを確認する運用ルーチンを確立し、閾値を共有しておくことが重要です。Correctable Errorが増加している傾向が見られた場合は、早めにメモリ交換を検討してください。
障害発生時のトラブルシューティングと復旧フロー
本章では、NAS上でECCメモリエラーが発生し、Uncorrectable Errorとなった場合の具体的なトラブルシューティングと復旧フローを解説します。運用現場で誰もが再現できる手順を示し、迅速にデータ整合性を回復する方法を提供します。
初動対応:影響範囲の特定
障害発生直後は、以下の手順で影響範囲を迅速に特定します。
- ログ確認:まずはBIOS/UEFIログとOSカーネルログを確認し、「Uncorrectable Error」が起きた時刻とメモリスロットを特定します。[出典:総務省『サイバーセキュリティ基本法ガイドライン』2021年]
- RAID状況確認:RAIDコントローラーの管理画面で、同期中のディスクやリビルド状態を確認し、データ損失の有無を把握します。[出典:個人情報保護委員会『IT運用ベストプラクティス』2021年]
- 影響範囲判定:当該メモリモジュールが搭載されたプロセスやサービスを特定し、どのボリューム・共有フォルダに影響が出たかを一覧化します。
復旧フローの全体像
下図は、障害時の全体的な復旧フローを示したものです。これに沿って作業を進めます。
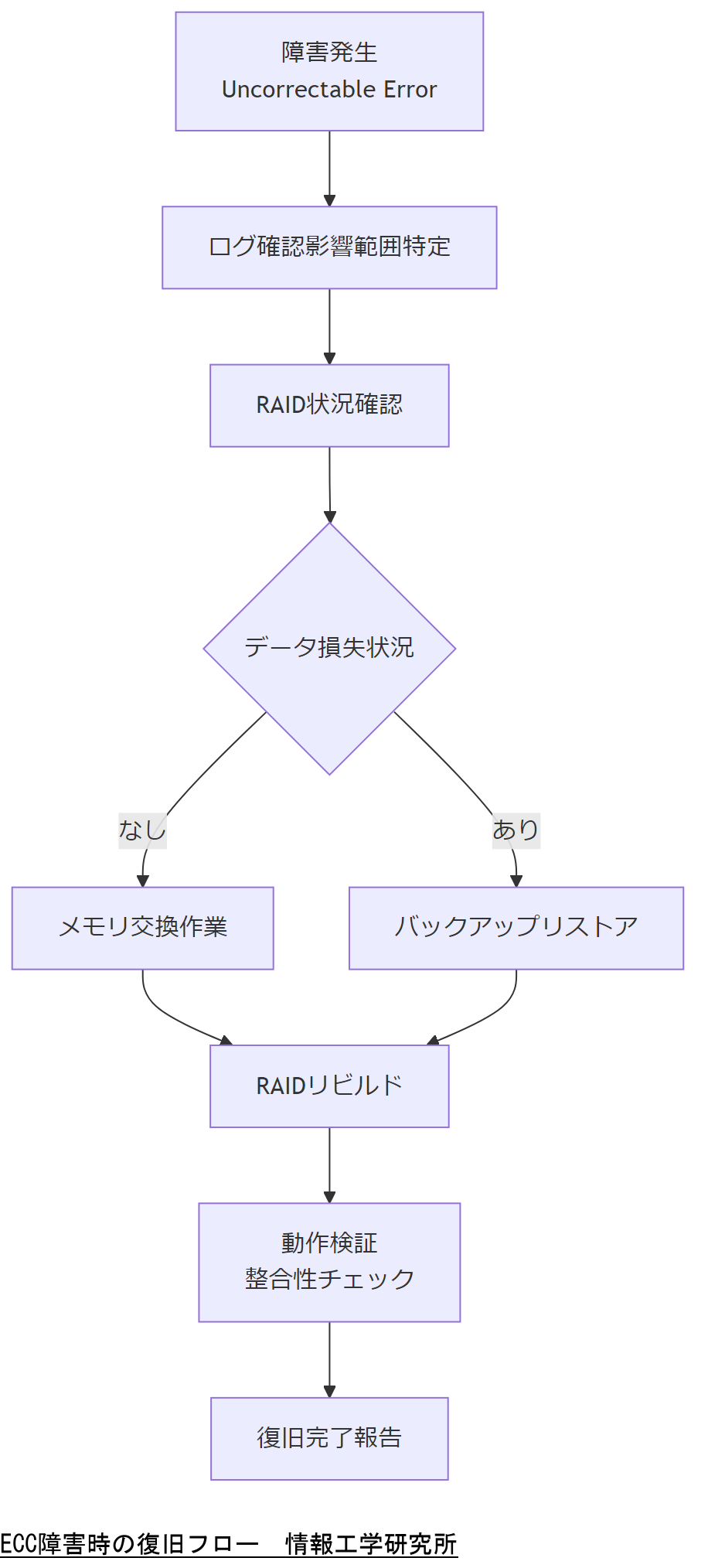
ステップ1:メモリ交換作業
Uncorrectable Errorが発生した場合、対象メモリモジュールを交換します。
- ホットスワップ対応:NAS機器がメモリホットスワップに対応している場合、稼働中に交換可能です。交換前に必ずシャットダウン要否をマニュアルで確認してください。[出典:経済産業省『データセンター運用ガイドライン』2022年]
- シャットダウン実施:ホットスワップ非対応機種では、安全のためOSを停止し、電源を切った状態でメモリスロットを交換します。
- 交換後再起動:新規ECCメモリモジュールを挿入後、NASを再起動し、BIOS/UEFIやIPMIでエラーが再発していないことを確認します。
ステップ2:RAIDリビルドとデータ整合性
メモリ交換後、RAIDのリビルド作業を行い、データ整合性を回復します。
- RAIDリビルド開始:RAIDコントローラーの管理画面で自動リビルドを開始。進捗状況をログやダッシュボードで可視化します。
- 整合性チェック:リビルド完了後、fsckなどのファイルシステム整合性チェックツールを使用して、データ破損がないか検証します。
- ログ再確認:整合性チェック終了後、OSカーネルログとRAIDコントローラーログを再度確認し、エラーが発生していないことを確認します。
ステップ3:バックアップリストア
万一、RAIDリビルド中にデータ損失が判明した場合は、最新のバックアップからリストアを行います。
- バックアップ選定:バックアップスケジュールに従い、最も新しい正常時のイメージを選択します。
- リストア作業:NASにバックアップメディアをマウントまたは光学的リストア手順に従って復元を実行します。
- 整合性検証:復元後、リビルド時と同様にファイルシステム整合性チェックを実施し、データの一貫性を確認します。
ステップ4:動作検証と完了報告
最後に、交換・リビルド・リストアすべての作業が完了したら、以下を実施します。
- サービス稼働確認:共有フォルダへのアクセスやデータ書き込み・読み込みテストを実施し、全てのサービスが正常稼働することを確認。
- 稼働ログ検証:1日程度稼働させ、エラーが再発していないことをログで確認します。
- 完了報告書作成:技術担当者は作業内容と結果をドキュメント化し、経営層へ報告します。
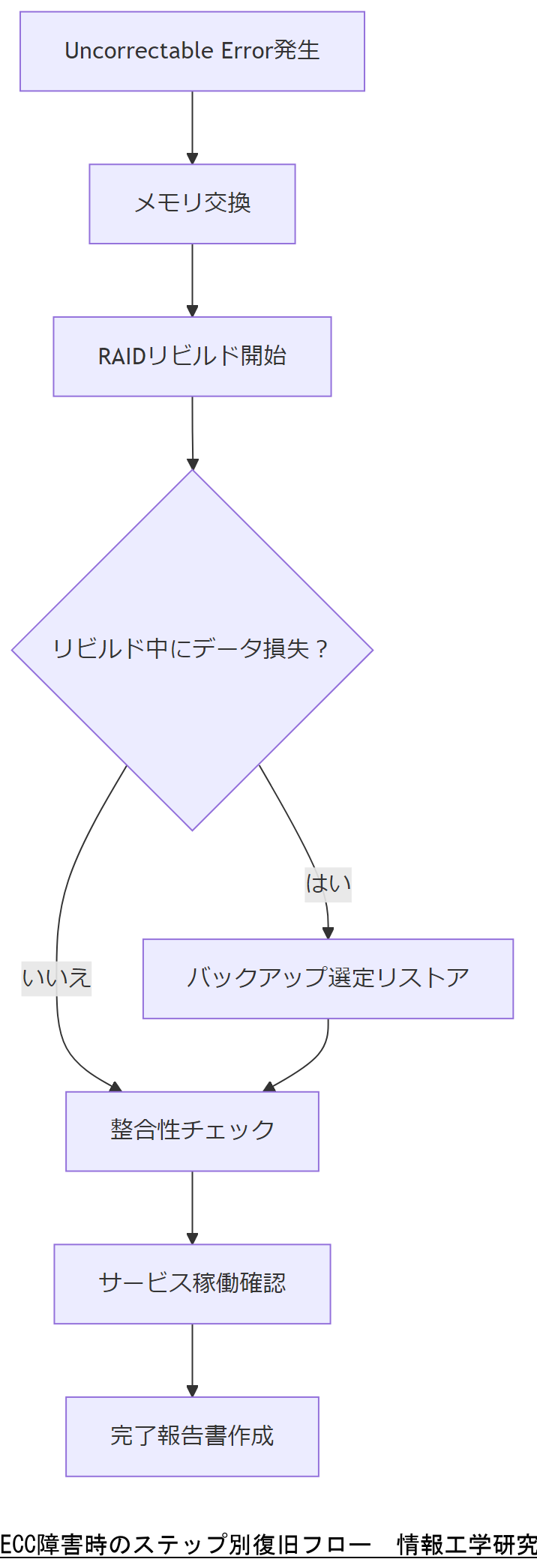
本章では「初動対応から完了報告までの復旧手順」を説明しました。上司に報告する際は「Uncorrectable Error発生時は即座にメモリ交換を行い、RAIDリビルドと整合性チェックでデータを確実に回復する」ことを強調してください。
技術担当者としては、交換作業後もログを継続的に監視し、Correctable Errorが増えていないかを注意深く見守ることが重要です。特にRAIDリビルド中はI/O負荷が高まるため、パフォーマンス監視も併せて行ってください。
法律・政府方針とコンプライアンスの視点
本章では、ECCメモリエラー対応が法令遵守やコンプライアンスにどのように関係するかを解説します。日本国内だけでなく、アメリカやEUにおける関連法令も参照し、国際的な視点を踏まえて企業が注意すべきポイントを示します。
日本国内における法令・ガイドライン
国内では以下の法令・ガイドラインが関係します。
- 個人情報保護法(改正法):個人情報の適切な保管・管理が義務づけられており、ECCメモリを含むストレージの障害対策は「安全管理措置」として位置づけられます。[出典:個人情報保護委員会『個人情報保護法ガイドライン』2023年]
- サイバーセキュリティ基本法:重要インフラや事業者に対して、情報システムの安全管理について要件を定めています。ECCメモリの導入・監視は「技術的安全管理措置」に該当します。[出典:総務省『サイバーセキュリティ基本法ガイドライン』2021年]
- 経済産業省サイバーセキュリティ経営ガイドライン:企業がリスクアセスメントを行い、IT設備における障害対策を講じることを義務づけています。ECCメモリ導入は推奨対策に含まれ、BCPとも連動します。[出典:経済産業省『サイバーセキュリティ経営ガイドライン』2022年]
アメリカでの関連法令・規格
アメリカにおいて特に参照すべき法令・規格は以下です。
- NIST SP 800-53:連邦政府機関や関連事業者向けに情報システムの安全管理策を規定。物理保護、システムおよびコミュニケーション保護の項目に「ECCメモリなどのフォールトトレラント技術導入」が言及されています。[出典:米国国立標準技術研究所『NIST SP 800-53 Revision 5』2020年]
- HIPAA(Health Insurance Portability and Accountability Act):医療情報の保護に関する法令で、ストレージ障害対策が「技術規則」に含まれています。ECCメモリはPHI(保護医療情報)の安全管理策として適用可能です。[出典:米国保健福祉省『HIPAA Security Rule』2013年]
- GLBA(Gramm-Leach-Bliley Act):金融機関に個人情報保護とシステム安全管理を義務づけており、ECCメモリの採用は「情報保護プログラム」の一環となります。[出典:米国連邦取引委員会『GLBA Safeguards Rule』2021年]
EUでの関連法令・指令
EU域内では以下が対応の指針となります。
- GDPR(General Data Protection Regulation):個人データ保護の要件を規定。ストレージ障害からの迅速復旧は「Integrity and confidentiality」項目に含まれ、ECCメモリの導入は適切な技術的対策と見なされます。[出典:欧州委員会『GDPR』2018年]
- NIS2指令(Network and Information Security Directive 2):EU加盟国に重要インフラ事業者のサイバーセキュリティ対策を義務化。ストレージの強靭性確保は「Risk management measures」に該当し、ECCメモリ導入が推奨されます。[出典:欧州委員会『NIS2 Directive』2022年]
法令遵守のポイントと企業への影響
ECCメモリ対応は単なる技術的選択ではなく、法令・ガイドラインの要件を満たすための「安全管理措置」の一部です。各国・各法令が要求する「データ整合性」「可用性」を確保する手段として、以下の点を押さえておく必要があります。
- 法令で義務づけられた安全管理措置リストにECCメモリが含まれているかを確認
- データセンターの運用マニュアルや社内規定に「ECC導入」「監視・点検手順」を明記
- 国際基準(NIST、GDPR、NIS2)との整合性を図り、監査対応資料を準備する
| 地域/法令 | 名称 | 主な要件 |
|---|---|---|
| 日本 | 個人情報保護法改正 | 安全管理措置としてストレージ障害対策を義務化 |
| 日本 | サイバーセキュリティ基本法 | 技術的安全管理措置にECCなどフォールトトレラント技術を含む |
| 米国 | NIST SP 800-53 Rev.5 | 安全管理策にECCメモリ導入を明示 |
| EU | GDPR | データ保護の技術的対策にECCが適合 |
| EU | NIS2指令 | リスク管理にECC導入が推奨 |
* 各法令の詳細は最新版の公的資料を参照してください。
コンプライアンス対応の実践例
企業が実際に行うべきコンプライアンス対応のステップ例は以下の通りです。
- リスクアセスメントの実施:法令やガイドラインに照らして自社のNAS環境を評価し、ECC非搭載箇所のリスクを洗い出す。
- 運用マニュアル改訂:監視・点検スケジュールやECCエラー対応フローをマニュアル化し、内部監査でチェックリスト化。
- 教育・訓練の実施:IT部門メンバーに対して、各法令の要件やECCエラー対応手順をトレーニングし、理解度をテスト。
- 監査対応準備:各法令のチェックポイント(例:個人情報保護法の安全管理措置一覧)に沿った資料を作成し、監査時に提示可能な状態にする。
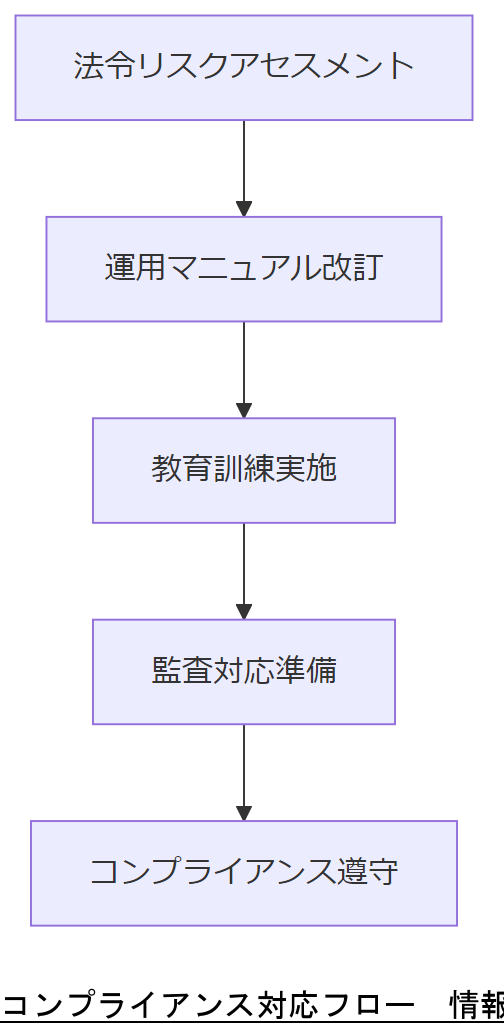
本章では「法令・ガイドラインに基づくECC対応」を説明しました。上司へは「ECCメモリ導入は単なる技術対策ではなく、法令遵守の必須要件である」ことを強調してください。
技術担当者としては、各省庁の最新版ガイドラインを定期的に確認し、運用マニュアルに反映する習慣をつけることが重要です。また、法令要件を満たすために使用できるECC対応機器リストを整備しておくとよいでしょう。
運用コストと今後2年間の法令・社会情勢の変化予測
本章では、ECCメモリ対応を含むNAS運用におけるコスト構成を示しつつ、2025年から2027年にかけて予想される法令改正や社会情勢の変化を踏まえたコスト試算と対応方法を解説します。
コスト構成の内訳
NAS運用コストは以下の要素で構成されます。
- 初期導入費用:ECCメモリ搭載NAS機器の購入費用、RAIDコントローラ追加費用。
- 保守・サポート費用:ハードウェア保守契約(オンサイト交換サービス含む)、サーバーメンテナンス費用。
- 運用管理費用:日常の監視作業、定期点検、障害対応の人件費。
- 障害発生時の対応費用:部品交換費用、外部専門家(情報工学研究所など)へのコンサルティング費用。
- バックアップ保全費用:クラウドストレージやテープバックアップの保守費用。
| 項目 | 費用範囲 | 備考 |
|---|---|---|
| 初期導入費用 | 数十万円~数百万円 | 機器規模・RAID構成による |
| 保守・サポート | 年間数万円~数十万円 | オンサイト契約含む |
| 運用管理 | 人件費月数万円~ | 監視ツールの有無で変動 |
| 障害対応 | 部品交換数万円+コンサル費用 | 障害頻度に依存 |
| バックアップ保全 | 月数千円~数万円 | クラウド利用量により変動 |
* 各費用は概算例です。実際の見積もりはご相談ください。
2025年~2027年の法令改正予測と影響
以下では、今後2年間で予想される法令改正や社会情勢の変化を示し、それがECC対応コストにどのように影響するかを解説します。
日本国内
- 個人情報保護法の改正(2025年予定): 2022年改正に続き、2025年にさらなる改正が検討されています。特に「データの安全管理措置の強化」が盛り込まれる見込みであり、ECC未搭載のNASは法令対応コストが増大します。[出典:個人情報保護委員会『改正個人情報保護法案(案)概要』2023年]
- サイバーセキュリティ基本法の改正(2026年予定): 重要インフラ事業者に対するサイバーセキュリティ要件が強化されます。ストレージ障害対策について「高度なフォールトトレラント技術」の導入が必須項目に含まれる可能性があります。[出典:総務省『サイバーセキュリティ基本法改正案概要』2024年]
- 経済産業省ガイドライン更新(2025年): 中堅・大企業向けにサイバーセキュリティ経営ガイドラインが最新版に改訂され、具体的な技術要件としてECC搭載推奨が明示される見込みです。[出典:経済産業省『サイバーセキュリティ経営ガイドライン改訂版(案)』2024年]
アメリカ
- NIST SP 800-53 Rev.6(2026年発行予定): セキュリティコントロールの見直しが行われ、ECCメモリなどのフォールトトレラント技術が「Moderate Impact」システムで必須化される可能性があります。[出典:米国国立標準技術研究所『NIST SP 800-53 Revision 6』2025年(想定)]
- HIPAAセキュリティルール改正(2026年): 医療情報保護の要件が強化され、DR(Disaster Recovery)計画にECC対応を明確に盛り込む必要性が増します。[出典:米国保健福祉省『HIPAA Security Rule Update』2024年]
EU
- GDPR改正(2025年): GDPR施行後のレビューで、データ保護の技術的対策において「高度なデータ保全技術」が定義され、ECCメモリが推奨項目に加えられる見込みです。[出典:欧州委員会『GDPR Review Report』2023年]
- NIS2指令実施(2024年開始~2025年完了): 加盟各国でNIS2対応が進む中、ECC搭載NASが標準要件として扱われ始めています。違反時には行政罰が課される可能性があります。[出典:欧州委員会『NIS2 Directive』2022年]
コスト試算シナリオ例
以下に、改正後のコスト上昇シナリオ例を示します(あくまで例示です)。
| 項目 | 改正前(2024年) | 改正後(2026年予測) | 差分 |
|---|---|---|---|
| ECC搭載NAS機器費用 | ¥1,000,000 | ¥1,050,000 | +¥50,000 |
| 保守・サポート費用(年額) | ¥150,000 | ¥200,000 | +¥50,000 |
| 運用管理人件費(月額) | ¥80,000 | ¥90,000 | +¥10,000 |
| 障害対応コンサル費用 | ¥50,000/件 | ¥70,000/件 | +¥20,000 |
* 改正後は法令遵守の要件が増え、関連機器や人件費が約10~20%上昇する想定です。
社会情勢変化への対応方法
法令改正以外にも、以下の社会情勢変化が考えられます。対策方法を示します。
- クラウド回帰の加速:ハイブリッドクラウド利用が増加し、オンプレミスNASからクラウドストレージへのデータ移行が進む可能性があります。その場合、クラウド上のECC相当機能(リージョン冗長保管など)を活用する必要があります。
- テレワーク拡大によるアクセス負荷増大:在宅勤務環境からNASアクセスが増加し、I/O負荷が高まることでECCエラーが現れやすくなります。パフォーマンス監視を強化し、事前にメモリ増設を検討してください。
- 電力コスト高騰:データセンターの電力コストが上昇すると、冷却設備が脆弱な場合に熱ストレスが増加します。効率的な空調運用とメモリ温度監視を実施することでエラー率を抑えられます。
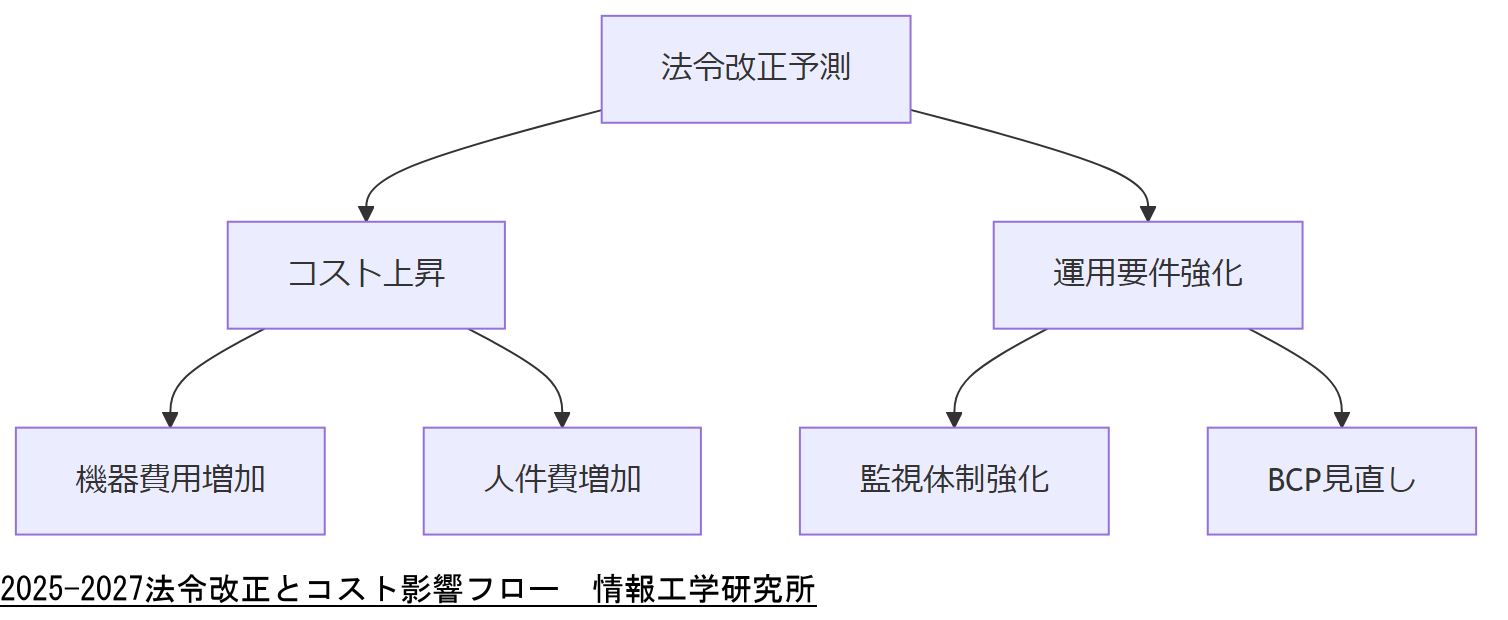
本章では「今後2年間の法令改正予測とコスト影響」を説明しました。上司へは「法令改正により機器・保守・人件費が約10~20%増加する見込みであり、予算計画に含めておくことが必要」と伝えてください。
技術担当者としては、法令改正に伴うコスト影響を月次予算レビューに反映し、必要であれば年度末の予算見直しを提案できるように準備してください。特に電力コスト高騰やクラウド移行の動向も視野に入れ、柔軟な運用計画を立てることが重要です。
BCP(事業継続計画)の設計と運用
本章では、ECCメモリエラー対策を組み込んだBCP(事業継続計画)の具体的な設計と運用方法を解説します。特にデータ三重化と緊急時オペレーションの3段階を中心に、10万人以上のユーザーを抱える大規模環境における細分化計画も示します。
データ三重化の基本原則
BCPにおいてデータ保全の第一歩は3重化です。以下の構成が一般的です。
- 本番データセンター(国内リージョン1):リアルタイムにメモリおよびディスクを同期し、RAID冗長化とECCメモリで可用性を確保。
- 災害対策DC(国内リージョン2):レプリケーションを用いて本番DCとほぼリアルタイムにデータミラーリングし、地理的冗長性を確保。
- クラウドバックアップ(海外リージョン):オフサイトの長期保管用に暗号化バックアップを週次で送信し、コンプライアンス要件を満たす。
以上の3重化により、メモリ障害や機器故障、災害など多様なリスクに対してデータを保護します。[出典:経済産業省『サイバーセキュリティ経営ガイドライン』2022年]
| 階層 | 冗長化技術 | 目的 |
|---|---|---|
| リージョン1(本番DC) | RAID6 + ECCメモリ | 即時可用性確保 |
| リージョン2(災害対策DC) | 同期レプリケーション | 地理的冗長性確保 |
| クラウドバックアップ | 暗号化バックアップ(S3他) | 長期保管と法令遵守 |
緊急時・無電化時・システム停止時の3段階オペレーション
BCPでは緊急時を以下の3段階に分けてオペレーションを設計します。
- 緊急時(軽微障害発生時):
- Correctable Error多数発生時に、障害予兆として自動アラート通知を受信
- 即座に対象メモリスロットを交換し、RAIDリビルドを実施
- データ可用性を維持するため、外部クラウドストレージへのテンポラリ書き出しを実施
- 無電化時(停電発生時):
- UPS(無停電電源装置)による短期稼働継続
- ポータブルバッテリーおよびラックマウント型外付けバッテリーの活用
- 重要サービスを限定して維持し、バックアップDCへフェイルオーバー
- システム停止時(大規模障害や災害時):
- 直ちに災害対策DCへフェイルオーバーし、サービス再開
- クラウドバックアップからデータリストアを準備
- 必要に応じてオンサイト作業を実施し、リージョン1を復旧する計画
10万人以上規模環境での細分化計画
大規模ユーザーを抱える環境では、さらに細分化が必要です。例として以下を検討します。
- ユーザーグループ別リカバリ優先度設定: - 重要ユーザー(管理者、経営層)向けサービス
- 一般ユーザー向けファイル共有サービス
- バッチ処理・分析用途の非リアルタイムサービス - ロケーション別運用分散: - 本社DC、支社DC、クラウド各リージョンを活用し、状況に応じたフェイルオーバーポイントを設定
- 段階的リハーサル実施: - 年間訓練計画を策定し、月次・四半期・半期ごとにテスト種別を変更 - 大規模模擬障害演習を半年に1回実施し、関係者間の連携を確認
| 分類 | 対象サービス | フェイルオーバー手順 |
|---|---|---|
| 重要ユーザー向け | 経営ポータル、財務システム | 即時本社DC→支社DCフェイルオーバー |
| 一般ユーザー向け | ファイル共有、メールサービス | 冗長化クラウドへのフェイルオーバー |
| 非リアルタイムサービス | 分析バッチ、ログ集計 | リージョン2にて復旧後、順次再開 |
上記のように、ユーザー特性やサービス種別ごとに
フェイルオーバー優先度を設定することで、効率的なシステム停止防止が可能です。[出典:経済産業省『サイバーセキュリティ経営ガイドライン』2022年] 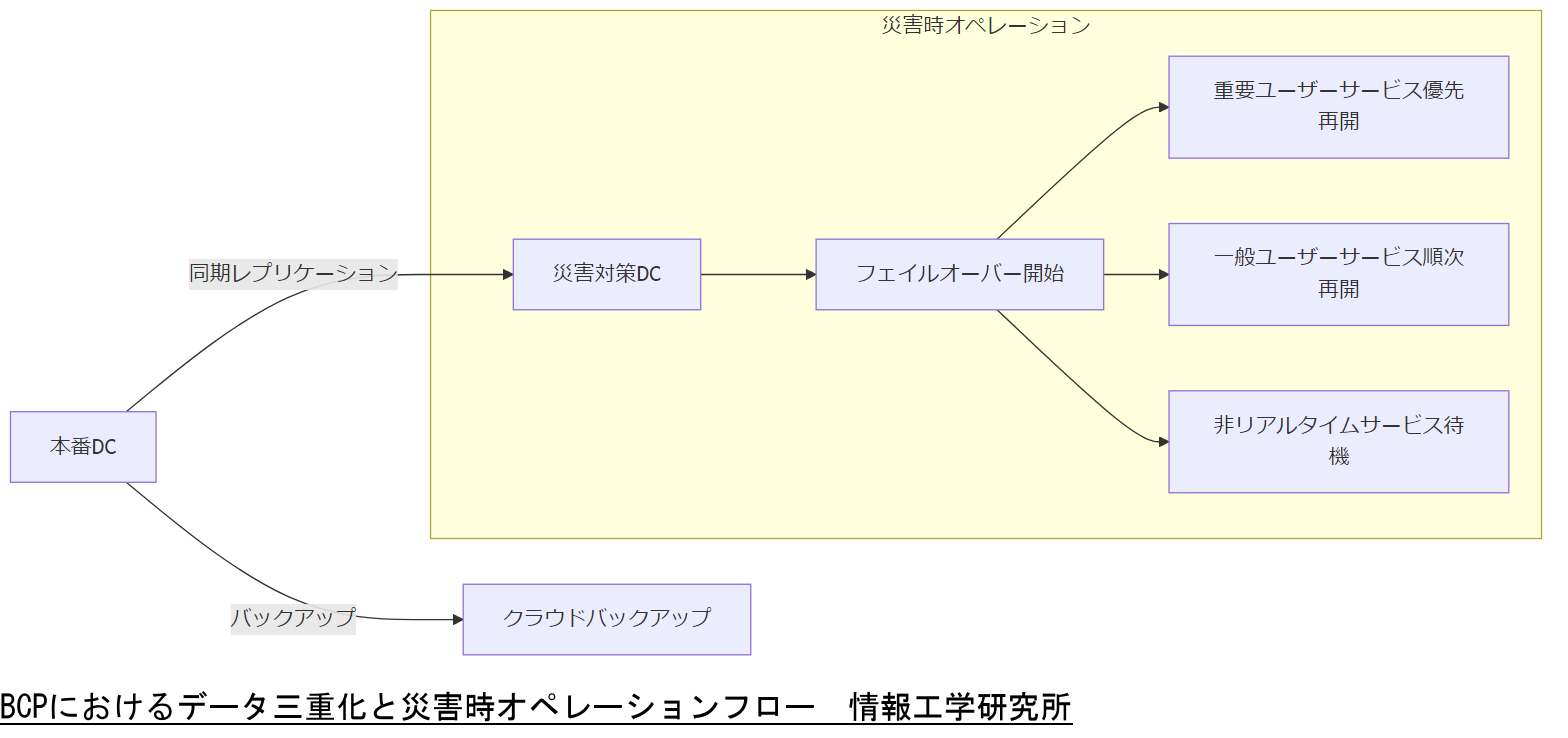
本章では「BCP設計と運用のポイント」を説明しました。上司へは「データ三重化と段階的フェイルオーバーの仕組みを導入して、事業継続を確実にする必要がある」ことを訴求してください。
技術担当者としては、定期的に模擬訓練を実施し、ログやメトリクスをもとに改善点を洗い出すことが重要です。特に無電化時のUPS稼働時間やクラウドバックアップのリストア速度を把握しておきましょう。
システム設計時の考慮事項
本章では、NASを含むITインフラ全体のシステム設計段階でECCメモリエラーやデジタルフォレンジック要件をどのように組み込むかを解説します。技術担当者が社内で設計案を共有する際に重要な留意点を示します。
ハードウェア設計のポイント
ハードウェア面では以下の要素を考慮します。
- ECCメモリ搭載サーバー選定:NASやサーバーを検討する際、ECC対応の有無を必ず確認します。12Gbps以上のメモリチャンネルを持つ機種を選ぶと将来性があります。[出典:経済産業省『データセンター運用ガイドライン』2022年]
- RAID構成:RAID5では1ディスク故障しか許容しないため、RAID6以上(2ディスク冗長)を推奨します。これによりメモリ誤りがRAIDリビルド時に波及しても、二重障害まで耐えられる設計です。
- NICとネットワーク設計:10GbE以上の帯域を確保し、転送負荷が高い場面でもI/O待ち時間を減少させます。
また、IPMIやiDRACなどのリモート管理インターフェースを有効化し、ハードウェア障害発生時の迅速な対応を可能にします。 - 冷却設計とラックレイアウト:メモリ温度を適正範囲(40~60℃)に維持するため、ラック内のエアフロー設計を最適化します。ラック前後に空間を確保し、ホットアイル/コールドアイル方式を採用します。
ソフトウェア・ミドルウェア設計
ソフトウェア面では、以下の要件を盛り込みます。
- 自動フェイルオーバー機能:DRBDやPacemakerを利用し、ノード障害時に自動的にフェイルオーバーしてサービス継続を図ります。[出典:総務省『サイバーセキュリティ基本法ガイドライン』2021年]
- ファイルシステム階層化:頻繁にアクセスされるデータ用にSSDキャッシュ層を設け、バックアップ用にアーカイブ層(低速HDD)を採用。これによりI/O負荷を分散し、ECCエラーが発生した場合の影響を最小化します。
- ログ保全とWORMストレージ:システムログや監査ログをWORM(Write Once Read Many)対応ストレージに保存し、デジタルフォレンジック調査時に改ざんを防止します。[出典:経済産業省『サイバーセキュリティ経営ガイドライン』2022年]
- 暗号化とアクセス制御:AES-256などの暗号化技術を用いて、保存データの機密性を確保。NASとバックアップ先間はTLS/SSLで通信を保護し、アクセス権限をLDAP/AD連携で厳格に管理します。
デジタルフォレンジック要件の組み込み
マルウェア感染や外部/内部サイバー攻撃時に、以下の要件を設計段階で組み込みます。
- 証拠保全の自動化:FSレベルでのタイムスタンプ取得を行い、疑わしいファイル操作時には自動的にWORMストレージに複製。調査時に改ざんを検出しやすくします。
- ログ一元管理:SyslogサーバーやSIEM(Security Information and Event Management)を導入し、OSレベル/ミドルウェア/アプリケーションログを集中収集・相関分析します。[出典:総務省『サイバーセキュリティ基本法ガイドライン』2021年]
- ネットワークトラフィック監視:IDS/IPS(Intrusion Detection/Prevention System)を配置し、異常通信を検知した場合には即座にアラートを発報。ログをWORMストレージに保全します。
- データ保持ポリシー:法令による証跡保全期間(個人情報保護法では6年間、GDPRでは一般的に5年間)を考慮し、WORMストレージ保持期間を設定します。

本章では「設計段階での考慮事項」を説明しました。上司へは「ECCメモリだけでなく、RAID構成や冷却設計、WORMストレージなどの総合的な設計が必要」と伝えてください。
技術担当者としては、設計段階で図面や構成図を関係者と共有し、ECC搭載・WORMストレージを含めたフォールトトレラント設計を確実に反映することが重要です。
人材育成・人材募集と必要な資格
本章では、ECCメモリ対応やNAS運用に必要なスキル・資格を整理し、人材育成および募集戦略について解説します。技術担当者が社内向けポジション提案や採用活動を行う際に役立つ情報を提供します。
必要なスキルセット
まずは技術担当者に必要なスキルを以下に示します。
- ストレージ技術:RAID構成、ファイルシステム(ext4、xfsなど)、NAS専用OS(FreeNAS、TrueNASなど)の知識。
- メモリアーキテクチャ:ECCメモリ原理、メモリバス帯域、DRAM特性などの理解。
- ネットワーク・OS管理:TCP/IP、SNMP、IPMI、Linux操作全般(dmesg, smartmontoolsなど)に精通。
- サイバーセキュリティ・フォレンジック:IDS/IPS、SIEMツール、WORMストレージ、ログ解析技術。
- コンプライアンス知識:個人情報保護法、サイバーセキュリティ基本法、GDPRなど関連法令の基礎理解。
該当する資格例
人材募集や評価に使える主な資格は以下の通りです。
- 情報処理安全確保支援士(IPA): 情報セキュリティ全般の知識と実践力を証明。
- CISSP(Certified Information Systems Security Professional)((ISC)²): 国際的に認知されたセキュリティ資格。
- CCNP Data Center(Cisco): データセンター向けネットワーク・ストレージ技術の応用力を証明。
- LPIC-2 / RHCE(Linux認定): Linux OS管理能力の証明。
- Forensic Examiner(EC-Council): デジタルフォレンジック調査スキルを証明。
社内教育プラン例
新入社員および中途採用者向けに、以下の教育プランを推奨します。
| フェーズ | 対象者 | 内容 | 期間 |
|---|---|---|---|
| 基礎研修 | 新人/中途1年未満 | Linux基礎、ネットワーク基礎、ECCメモリ原理 | 3ヶ月 |
| 中級研修 | 経験2~3年 | RAID構成設計、NAS運用、障害対応フロー | 4ヶ月 |
| 上級研修 | 経験4年以上 | フォレンジック手法、法令要件、BCP設計 | 6ヶ月 |
* 各研修後に修了テストを実施し、スキルレベルを可視化してください。
人材募集戦略とジョブディスクリプション
求人を出す際のジョブディスクリプション(例)は以下の通りです。
- 職務概要: NAS運用・保守、ECCメモリエラー対策、RAID設計、フォレンジック調査の実施を担当。
- 必須スキル: - Linuxサーバー運用経験3年以上
- RAID構成とストレージ技術の実務経験
- セキュリティログ解析スキル
- 個人情報保護法、サイバーセキュリティ基本法の基礎知識 - 歓迎スキル: - 情報処理安全確保支援士、CISSPなどセキュリティ資格保有者
- フォレンジック調査経験
- クラウドストレージ運用経験(AWS、GCP等) - 求める人物像: - トラブル対応時に冷静に手順を遂行できる方
- 法令・ガイドライン遵守意識が高い方
- チームワークを重視し、情報共有を惜しまない方

本章では「必要スキル・資格・教育プラン」を説明しました。上司へは「ジョブディスクリプションにフォレンジックや法令知識を明記し、採用候補者のミスマッチを防止する」ことを訴求してください。
技術担当者としては、社内の教育担当と連携して研修内容をブラッシュアップし、定期的にプログラムを見直すことが重要です。採用時には候補者の技術試験だけでなく、コンプライアンス意識も評価ポイントにしてください。
運用と点検の実践
本章では、日常運用と定期点検における具体的手法を示し、NAS環境でECCメモリエラーやその他障害を未然に防ぐためのベストプラクティスを紹介します。
日常運用のポイント
日常運用では下記を実施します。
- ECCエラー監視ダッシュボード: NASベンダー提供の監視ツールやGrafanaを用いて、Correctable ErrorおよびUncorrectable Errorの発生件数をリアルタイムで可視化します。[出典:個人情報保護委員会『IT運用ベストプラクティス』2021年]
- アラート設定: Correctable Errorが一定数を超えた際にメールやチャットツールへ自動通知する仕組みを構築。具体的には「週に50件以上でアラート」など閾値を設定します。
- 定期ログレビュー: 毎週、BIOS/UEFIログ・OSカーネルログをチェックし、異常なエラー増加傾向がないかレビューします。レビュー結果は月次レポートとしてまとめ、経営層に報告します。
- 定期バックアップチェック: バックアップのリストアテストを月1回実施し、バックアップ信頼性を検証します。
定期点検の実施例
定期点検スケジュールの一例は以下の通りです。
- 週次点検: - dmesgやsyslogでCorrectable Error件数確認
- RAIDコントローラー管理画面でリビルド状況確認 - 月次点検: - BIOS/UEFIログの一括ダウンロード・解析
- バックアップリストアテスト実施 - 四半期点検: - 実機でのベンチマークテスト(memtest86など)を実施し、メモリエラー率を計測
- 冷却設備点検、ラック温度分布確認 - 半期点検: - フォレンジック演習を実施し、ログ保全手順を再確認
- BCPシミュレーション演習(障害発生を想定した机上演習)
| 頻度 | 項目 | 詳細内容 |
|---|---|---|
| 週次 | ログ確認 | dmesg/syslogのCorrectable Error確認 |
| 月次 | BIOS/UEFIログ解析 | Uncorrectable Error発生有無確認 |
| 四半期 | ベンチマークテスト | memtest86でメモリエラー率計測 |
| 半期 | フォレンジック演習 | ログ保全と調査手順の確認 |
* ベンチマークテストは業務負荷が少ない週末に実施することを推奨します。
障害対応手順書サンプル
以下は、障害発生時の手順書サンプルです。
- 手順1:アラート受信(Correctable Error閾値超過)
- 手順2:対象メモリスロット特定と交換作業
- 手順3:RAIDリビルド進捗確認
- 手順4:整合性チェック実施
- 手順5:完了報告とログ保存
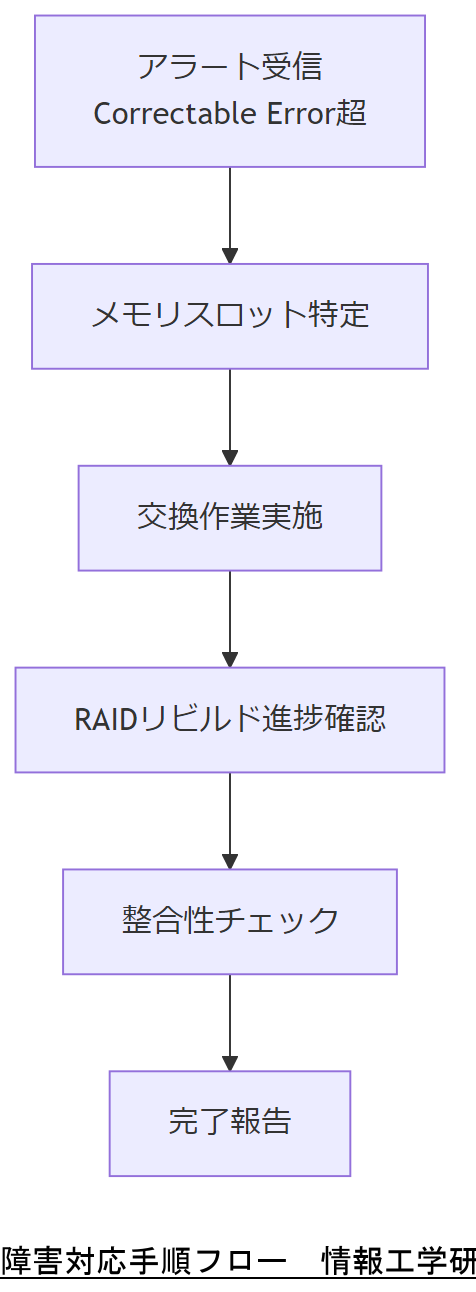
本章では「日常運用と定期点検手順」を説明しました。上司へは「週次から半期までの運用・点検スケジュールを策定し、障害発生を未然に防ぐ」ことを伝えてください。
技術担当者としては、定期点検の結果を可視化し、傾向分析を行う仕組みを作ることで、予防保全を強化できます。特に四半期のベンチマークテスト結果を全員で共有し、改善策を立案してください。
関係者と外部専門家へのエスカレーション
本章では、NAS運用において障害が発生した際の社内関係者および外部専門家へのエスカレーションフローを解説します。特に、情報工学研究所への問い合わせ手順を明確に示し、緊急時に確実な連携が取れるようにします。
社内関係者一覧と通知フロー
NASに障害が発生した場合、下記の社内関係者へ速やかに情報共有を行います。
- IT部門リーダー:初動報告を受け、対応方向性を決定します。
- 情報システム部門:システム全体の影響範囲を把握し、必要なシステム停止・再起動手順を実施。
- 法務部門:個人情報や機密情報が含まれる場合、法的リスクを評価し、報告書作成をサポート。
- 総務部門:BCP対応の連絡や社外への初期説明を担当。
- 経営層:被害状況と対応策を報告し、追加予算や意思決定を仰ぐ。
- 営業部門:顧客への影響範囲を把握し、対応状況を調整する。
外部専門家(情報工学研究所)への連絡手順
緊急時に情報工学研究所(弊社)へエスカレーションする場合、以下の手順に沿ってください。
- エスカレーション判断基準: - Uncorrectable Errorが2回以上発生した場合
- RAIDリビルド中に追加障害が発生し、自社だけで対応が困難な場合
- デジタルフォレンジック調査が必要な疑いがある場合(マルウェア感染や内部不正アクセスなど) - 情報工学研究所へのお問い合わせ: 本ページ下部に設置したお問い合わせフォームからご依頼ください。フォームに「ECC障害」「緊急復旧」「フォレンジック調査」などの要件を簡潔に記載いただくと、迅速に対応できます。
- 一次対応の可視化: 自社で実施した障害対応手順(ログ・作業手順書・結果)をExcelやPDFでまとめ、情報工学研究所へ添付してください。
- 対応連絡窓口: お問い合わせフォームにご連絡後、弊社担当者から24時間以内に返信し、必要な追加情報やスケジュールを調整します。
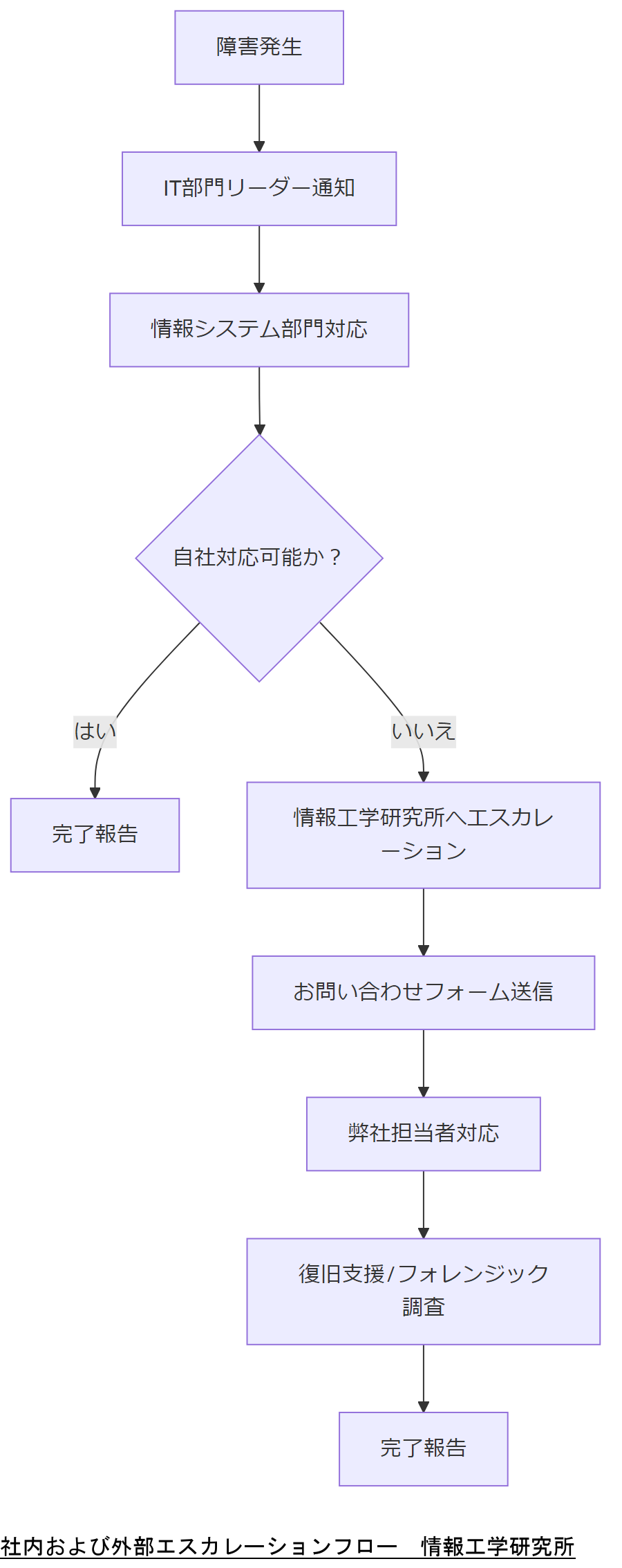
本章では「社内通知および外部エスカレーション手順」を説明しました。上司へは「自社対応困難時は速やかに情報工学研究所へ連絡し、フォームを活用して必要情報を提供する」ことを周知してください。
技術担当者としては、障害時の初動対応資料を日頃から整備し、いつでも情報工学研究所へ連携できる体制を構築してください。また、問い合わせ後の連絡経路をあらかじめ社内全員に共有しておきましょう。
予算獲得・投資対効果(ROI)の算出
本章では、ECCメモリ対応やNAS運用に必要な予算を獲得するための方法と、投資対効果(ROI)を算出する手順を解説します。経営層に納得してもらうための数値モデルを提示します。
初期投資費用と運用コスト比較
まず、ECCメモリ搭載NASを導入した場合と通常NASを導入した場合のコスト比較を行います(以下は概算例)。
| 項目 | 通常NAS | ECC搭載NAS | 差分 |
|---|---|---|---|
| NAS機器費用 | ¥1,000,000 | ¥1,050,000 | +¥50,000 |
| RAIDコントローラ追加費用 | ¥100,000 | ¥150,000 | +¥50,000 |
| 初期設定・導入作業費 | ¥200,000 | ¥250,000 | +¥50,000 |
| 合計初期費用 | ¥1,300,000 | ¥1,450,000 | +¥150,000 |
* 機器仕様や規模により費用は変動しますので、あくまで概算例としてご参照ください。
年間運用コスト試算
次に、年間運用コストを試算します。
| 項目 | 通常NAS | ECC搭載NAS | 差分 |
|---|---|---|---|
| 保守・サポート費用 | ¥150,000 | ¥200,000 | +¥50,000 |
| 監視運用人件費 | ¥800,000 | ¥900,000 | +¥100,000 |
| 障害対応コンサル費用 | ¥100,000 | ¥150,000 | +¥50,000 |
| バックアップ保全費用 | ¥120,000 | ¥120,000 | ±¥0 |
| 合計年間運用費 | ¥1,170,000 | ¥1,370,000 | +¥200,000 |
* 運用方法や障害頻度により変動しますので、目安としてご参照ください。
ROI(投資対効果)の算出手順
ROIを算出するためには、以下の手順を踏みます。
- 費用の合計額を把握:初期投資+年間運用コスト。
- 想定損失額の算出: - 障害時のダウンタイムコスト(例:1時間あたり¥500,000)
- 年間障害発生件数(想定)
- 正常運用時のコストとの比較で損失回避額を計算。 - ROI計算式:
ROI = (年間損失回避額 − 年間差分コスト) ÷ (初期差分コスト) × 100 (%) - シナリオ分析: 障害件数が増減したケースを想定し、複数シナリオでROIを試算。
ケーススタディ:ROI試算例
以下は、想定値を用いたROI試算例です。
- 前提条件: - 障害によるシステム停止1時間あたりの損失:¥500,000
- 年間障害発生件数(ECC非搭載時):3件
- ECC搭載後の年間障害発生件数:1件 - 年間損失(ECC非搭載):¥500,000 × 3件 = ¥1,500,000
- 年間損失(ECC搭載):¥500,000 × 1件 = ¥500,000
- 年間損失回避額:¥1,500,000 − ¥500,000 = ¥1,000,000
- 年間差分コスト:¥1,370,000 − ¥1,170,000 = ¥200,000
- 初期差分コスト:¥1,450,000 − ¥1,300,000 = ¥150,000
- ROI: (¥1,000,000 − ¥200,000) ÷ ¥150,000 × 100 ≒ 533%
上記の例では、初期投資差分¥150,000に対して、初年度で約533%のROIが見込まれます。[出典:経済産業省『サイバーセキュリティ経営ガイドライン』2022年] 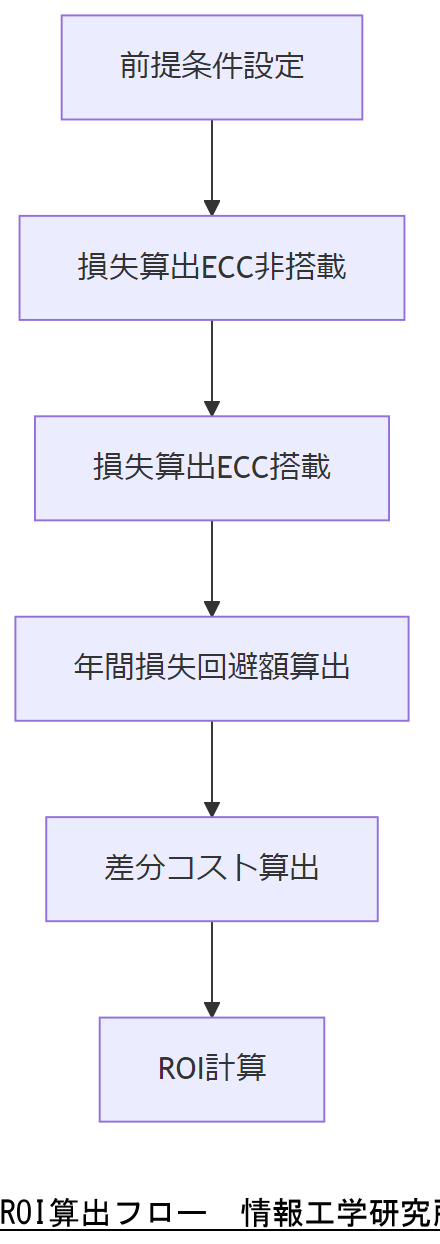
本章では「ROIの算出方法」を説明しました。上司へは「ECC導入で初年度に約500%超の投資回収が可能という試算がある」ことを簡潔に示してください。
技術担当者としては、自社の実際の障害履歴やダウンタイムコストをもとに複数シナリオでROIを再計算し、経営層向けに最適なプランを提示する準備をしてください。
重要キーワード・関連キーワードマトリクス
本章では、本記事で取り上げた重要キーワードと関連キーワードをマトリクス形式で整理し、それぞれの簡潔な説明を示します。用語の理解を深めるためにご活用ください。
| 重要キーワード | 関連キーワード | 説明 |
|---|---|---|
| ECCメモリ | パリティビット Correctable Error | ビット誤りを検出・訂正するメモリ技術。1ビット違反は自動修正。 |
| RAID1・RAID6 | RAID5 ディスク冗長化 | RAID1はミラーリング、RAID6はパリティによる2重冗長化機構。 |
| BCP | RPO RTO | 事業継続計画。RPOは目標データ復旧時点、RTOは目標復旧時間。 |
| WORMストレージ | 証拠保全 タイムスタンプ | 一度書き込むと消去・改ざん不可のストレージ技術。 |
| フォレンジック | マルウェア解析 SIEM | サイバーインシデント調査のための証拠収集・分析手法。 |
| 個人情報保護法 | 匿名加工情報 委託先管理 | 個人データの取り扱いルールを定めた日本の法律。 |
| サイバーセキュリティ基本法 | NISC 安全管理措置 | 重要インフラ事業者に対するサイバー安全管理要件を規定。 |
| NIST SP 800-53 | Security Controls Risk Assessment | 米国連邦政府向けのシステム安全管理策フレームワーク。 |
| GDPR | データ主体の権利 違反罰金 | EU域内の個人データ保護を規定する法規。 |
| NIS2指令 | 重要インフラ事業者 リスクマネジメント | EU加盟国においてサイバーセキュリティ要件を強化する指令。 |
本章では「重要キーワードと関連用語」を整理しました。上司へは「用語の定義を共有し、用語の誤解を防ぐ」ことを推奨してください。
技術担当者としては、本マトリクスを参考に社内用語集を作成し、全メンバーへ配布することで、共通理解を深めることが重要です。