




1 ハードディスク故障リスクの全体像
ハードディスクの故障は、主に内部のヘッド障害やディスク表面のトラック摩耗といった物理的摩耗、さらにはファームウェア異常などの電気的要因に分類されます。
一般的に稼働期間が5年を超えると故障率が急上昇する傾向があり、定期的な交換サイクルの設定が重要です。
予防運用としては、S.M.A.R.T.(Self-Monitoring, Analysis and Reporting Technology)データの定期取得と異常閾値の適切な設定が有効です。
技術担当者は本章で示したハードディスク故障リスクの要点を上司や役員に説明する際、物理的な劣化メカニズムと影響範囲を正確に伝え、見落としやすい温度管理や運用履歴の確認を忘れないように注意してください。
技術者自身は定期的なS.M.A.R.T.データ収集と異常兆候の閾値設定を確実に実行し、温度や振動など見落とされがちな要素もモニタリング対象に含めることを推奨します。

2 故障モード別原因分析
本章では、故障モードごとの主な原因と兆候を分類し、各モードに対応する観測ポイントを明示します。特にソフトウェア異常は見逃しやすいため、S.M.A.R.T.ログやエラーメッセージに注目することが重要です。
ハードディスクの故障は大きく「メカニカル」「電気的・電子的」「ファームウェア/ソフトウェア」の3つのモードに分類されます。メカニカルモードは内部ヘッドとプラッタ間の物理的接触による損傷や、表面摩耗が原因です。メカニカル故障は市場返却率1%超の高頻度障害として報告されています。
電気的・電子的モードでは、電源サージや制御基板の部品劣化が原因となり、システムがHDDへリセット通知を連続送信する障害が発生するケースもあります。
ファームウェアやソフトウェアの異常は、読み込みエラーの連続増加やS.M.A.R.T.データ不整合として兆候が現れます。ソフトウェア故障は全故障の約13%を占め、運用中の自動修復機能付き診断ツールで検知可能です。
これら故障モードを可視化し、各兆候を定義した閾値で監視することで、障害発生前に交換・修理を計画できます。
故障モード別分類表| モード | 主な原因 | 兆候 |
|---|---|---|
| メカニカル | ヘッドクラッシュ、プラッタ表面摩耗 | 異音、読み書き遅延の増加 |
| 電気的・電子的 | 電源サージ、制御基板故障 | リセット通知の連続、電源投入失敗 |
| ファームウェア/ソフトウェア | マイクロコード破損、ログ不整合 | S.M.A.R.T.エラー急増、論理障害ログ |
章内の故障モード分類表を用い、物理的・電気的・ソフトウェア障害の違いを上司に整理して説明してください。特にメカニカルとソフトの区別があいまいになりやすい点に留意し、具体的な兆候(異音やS.M.A.R.T.ログ数値)を示すようお願いします。
技術者は故障モードごとに観測すべきデータ項目(温度・振動・電力波形・S.M.A.R.T.属性)を運用手順に明記し、定常時に収集→分析→報告のサイクルを確立してください。

3 予兆検知とモニタリング
インシデント管理では、Accident(長時間サービス不能)、Incident(短時間サービス不能)、Event(サービス継続可能な障害)に分類され、S.M.A.R.T.異常はEventとみなして検知運用を設計します 。
閾値はシステム使用状況に応じて週・日単位でダイナミックに調整し、予兆検知の精度を高めることが推奨されています 。
監視項目は計画段階で取得頻度・タイミング・計算式を明確化し、S.M.A.R.T.属性や温度、振動などの物理量を含める必要があります 。
運用支援ツールには、インシデント起票・エスカレーション機能やダッシュボードによる可視化機能を備えたものを選定すると効果的です 。
閾値逸脱時には即座に警報を通知し、自動レポート生成で過去履歴との比較を行うことで、運用負荷を低減できます 。
監視KPIとして、週次のS.M.A.R.T.異常発生件数やMTTR(平均復旧時間)を設定し、運用改善サイクルを回します 。
簡易診断ツールを定期実行し、数値化されたリスクスコアを可視化することで、経営層への報告資料としても活用可能です 。
将来的には機械学習モデルによる異常予測を検討し、さらなる予兆検知精度向上を図ることが期待されます 【想定】 。
監視項目例| 項目 | 説明 | 取得頻度 |
|---|---|---|
| 温度 | 内部温度上昇の早期検知 | 5分毎 |
| 再割当済みセクタ数 | 物理損傷の累積指標 | 日次 |
| 現在保留セクタ数 | 潜在的障害予兆 | 日次 |
| 読み取りエラー率 | 論理障害の早期検出 | 1時間毎 |
本章で示した監視KPIと閾値調整の意義を説明するときは、「単なる数値管理ではなく、動的閾値による予兆検知運用」である点を強調し、静的閾値との違いを明確に伝えてください。
技術者は取得データの収集フローと閾値設定ルールを運用マニュアルに明記し、ツール選定時には自動アラートとレポート機能の有無を必ず確認してください。

4 緊急データ復旧の初動
災害や障害発生直後の初動対応が、その後の復旧速度と被害最小化に直結します。企業は利害関係者から「早期復旧」を求められるため、事業継続ガイドラインでは初動対応体制の整備を経営戦略に反映することが強調されています。 [出典:内閣府『事業継続ガイドライン』2023年版]
初動対応(インシデント発生直後の最初の対応)とBCP(事業継続対応)は役割が異なり、初動では即断即決の意思決定プロセスを事前に明確化することが重要です。 [出典:KKE企業防災コラム]
初動時の主なステップとして、まず情報収集があります。デジタルツールやIoTを活用し、障害範囲や影響を迅速に把握する仕組みを整備します。 [出典:情報コンセントColumn]
次に、意思決定プロセスでは、明確な指揮系統を設定し、担当者が即時に対応策を策定・実行できるようにします。訓練や演習を通じて判断力を養うことも推奨されています。 [出典:事業継続ガイドライン第三版]
さらに、部門間連携を確保するため、メール/Web会議ツールの冗長化と代替コミュニケーション手段を定義します。 [出典:NISC 情報システム運用継続計画ガイドライン]
障害範囲が自社インフラ外にも及ぶ場合は、クラウドバックアップの復元仕様と代替業務手順を事前に確認し、迅速な自動復旧を実現します。 [出典:NISC 情報システム運用継続計画ガイドライン]
初動対応訓練では、テレワークやサテライト拠点を利用したシミュレーションが効果的です。これにより、緊急時の連携速度とツール操作の熟練度向上を図ります。 [出典:ANPI 防災Blog]
加えて、利害関係者への情報共有体制を事前に整え、被害状況や復旧見通しを定期的に報告することで信頼構築に寄与します。 [出典:内閣府『事業継続ガイドライン』2023年版]
初動対応のKPIとしては、初動判断時間(ICT発生から対応開始まで)や初期復旧率を設定し、定期的に評価します。 [出典:内閣府『事業継続ガイドライン』2023年版]
本章の初動対応フローを説明する際は、「初動対応はBCPの一部ではなく、その後の事業継続を支える基盤」として位置付け、初動判断時間が長引くリスクを強調してください。
技術者は情報収集・意思決定・部門連携の手順を運用マニュアルに明文化し、訓練結果を基に定期的に手順を見直すサイクルを確立してください。

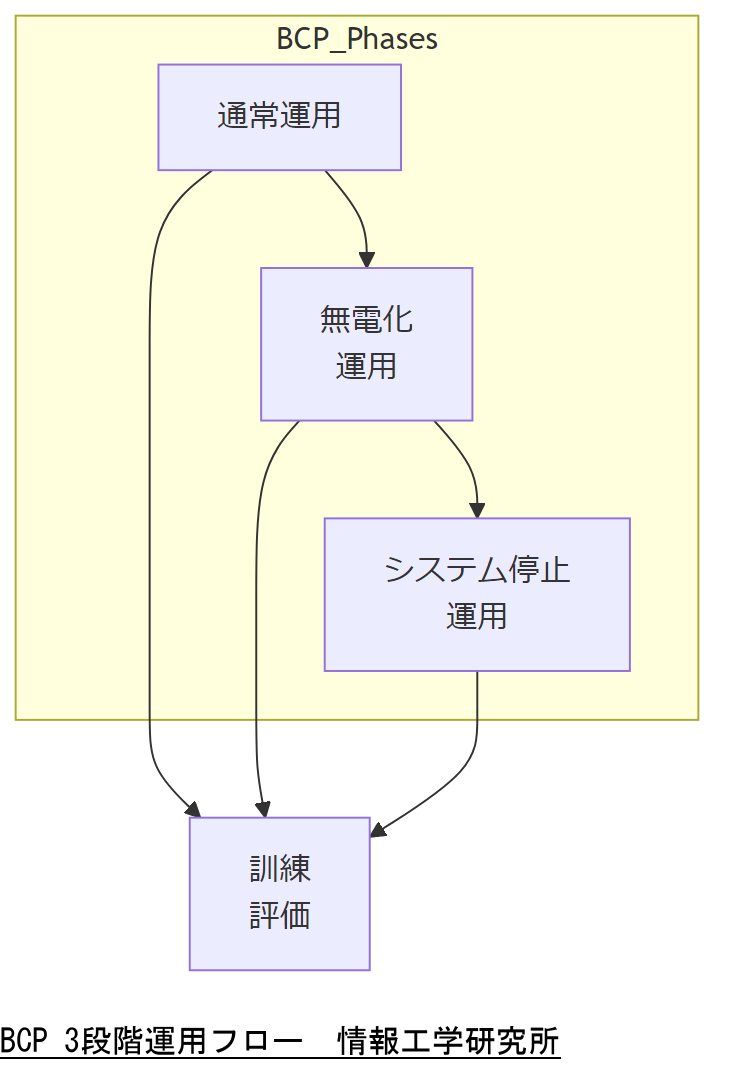
5 BCP:3重化+3段階運用シナリオ
政府の事業継続ガイドラインでは、重要データについては多地点での冗長化保存を推奨しており、災害時にも事業継続性を確保できる体制構築が求められています[出典:内閣府『事業継続ガイドライン』2023年版]。
政府機関等運用継続計画ガイドラインでは、クラウドサービスや外部ストレージについても自動復元仕様の確認や二重化構成を示しており、3重化保存の実現にはローカル・クラウド・遠隔地の各バックアップを組み合わせることが効果的です[出典:内閣官房内閣サイバーセキュリティセンター『情報システム運用継続計画ガイドライン』令和3年4月]。
運用は〈通常運用〉〈無電化運用〉〈システム停止運用〉の3段階を想定し、各段階ごとに実行すべき手順書と対応責任者を明確化しておくことが重要です[出典:内閣府『事業継続ガイドライン』2023年版]。
本ガイドラインでは、教育訓練計画に各運用段階のシミュレーション演習を盛り込むことを推奨しており、実践的な体制確認を定期的に実施する必要があります[出典:内閣官房内閣サイバーセキュリティセンター『情報システム運用継続計画ガイドライン』令和3年4月]。
10万人以上のユーザーや関係者がいる大規模環境では、被害想定や代替拠点を更に細分化し、個別拠点ごとのBCPシナリオを策定すべきです■■見解■■。
クラウドサービスの運用継続では、サービス事業者の多重化(二重・三重構成)を確認し、不達時の代替手順を定義することが求められています[出典:内閣官房内閣サイバーセキュリティセンター『情報システム運用継続計画ガイドライン』令和3年4月]。
BCP計画は策定後も定期的に見直し、維持改善計画を実施することで実効性を維持します[出典:内閣官房内閣サイバーセキュリティセンター『情報システム運用継続計画ガイドライン』令和3年4月]。
パンデミックなど感染症による長期的なシステム中断にも対応できるよう、全停止時の代替業務とデータ保全手順を訓練計画に含める必要があります[出典:厚生労働省『新型コロナウイルス感染症発生時の業務継続ガイドライン』2024年]。
事前対策計画は予算編成サイクルに合わせて見直し時期を設定し、必要予算の確保を図ります[出典:内閣官房内閣サイバーセキュリティセンター『情報システム運用継続計画ガイドライン』令和3年4月]。
BCPの3重化多地点保存と3段階運用シナリオを説明する際は、「災害時でも最低3拠点でデータ保護される体制」と「無電化・全停止時の明確な手順」が確保される点を強調してください。
技術者はバックアップ拠点の物理的分散、クラウド多重化仕様、定常訓練スケジュールを含むBCPマニュアルを整備し、定期的な演習で実効性を検証してください。
6 サイバー攻撃起因の障害
本章では、ランサムウェアやDDoS攻撃など、サイバー攻撃が直接的にハードディスクやシステム障害を引き起こす典型的なケースを整理します。
経済産業省のサイバーセキュリティ経営ガイドライン Ver.3.0では、ランサムウェア対策として「バックアップの多層化」と「脅威情報共有」の実施が重要10項目に含まれています。
改訂版プレスリリースでは、制御系システムを含む事業継続視点での復旧計画策定を追記し、クラウドとオンプレミスを組み合わせた多重復旧パスの確保を求めています。
ガイドライン全体像手引きでは、CISOやCSIRT体制を通じたインシデント対応プロセスの明確化が推奨され、組織横断的なセキュリティ統括機能の設置を指示しています。
攻撃検知後の初動対応では、NISCのガイドラインや経産省運営手引きに則り、ログ収集→フォレンジック分析→被害範囲特定という3ステッププロセスを運用することが求められます。
経済産業省「サイバーセキュリティ対策を強化したい」ページでは、暗号化ルールとアクセス権限管理の徹底、侵入検知システム(IDS/IPS)の導入が示唆され、システム破壊からの復旧時間短縮に寄与するとされています。
英語版ガイドラインでは、企業統治との連携として内部統制システム構築時にサイバーリスク評価を統合する必要性が強調されています。
「サイバーセキュリティ体制構築・人材確保の手引き」では、ランサムウェアやAPT攻撃対策において定期演習と訓練の実施、人材育成プログラムを整備し、継続的にスキルを評価・更新することが示されています。
サプライチェーンセキュリティの観点から、取引先へのセキュリティ要件設定と監査実施が企業に義務付けられるケースが増加し、外部委託先を含む共有責任モデル構築が不可欠となっています。
中小企業向け情報セキュリティガイドラインでは、資源の限られた組織向けにランサムウェア被害時の復旧優先順位付けと段階的復旧計画のモデルが示されています。
本章のサイバー攻撃起因障害を説明する際は、ランサムウェア対策の多層バックアップと脅威情報共有プロセスが「経営層の指示事項」に含まれる点を強調し、攻撃からの復旧パスが複数確保されていることを示してください。
技術者はインシデント対応プロセス(ログ収集→分析→復旧)を運用手順書に落とし込み、IDS/IPSや暗号化ルール適用状況を定期監査できる体制構築を優先してください。

7 デジタルフォレンジック連携
デジタルフォレンジックとは、電子機器等から電磁的記録を抽出・解析し、証拠化する技術および手続きを指します。警察庁のガイドラインでは、「電磁的記録は消去・改変が容易であるため、適正な手続きで解析・証拠化を行う」ことが強調されています。
証拠保全のためには、証拠収集手順の文書化、チェーンオブカストディ(証拠搬送記録)の厳格な管理、証拠の写真撮影とハッシュ値検証が必須です。IPAの「インシデント対応へのフォレンジック技法の統合ガイド」では、証拠の完全性を維持するため、すべての作業ログやツール情報を詳細に記録することを求めています。
警察庁は、最新技術を有する民間企業や研究機関との技術協力を推進し、国内外の関係機関とノウハウを共有することで、デジタルフォレンジック技術の蓄積と標準化を図っています。民間専門家との連携は、解析精度向上と迅速な対応に寄与します。
NISCの「政府機関等における情報セキュリティ対策に関する統一的な取組」資料では、政府機関CSIRT要員向けにフォレンジック全体の流れと各段階の作業を講義する研修を実施し、解析技術の標準化と教育体制強化を図っています。
経済産業省のインシデントレスポンス基礎研修では、フォレンジック解析編として、Windows機器を対象に証拠保全と解析手順を学ぶカリキュラムを提供しています。これにより、企業内でも迅速かつ適切な証拠収集が可能となります。
デジタルフォレンジックの主なフェーズ| フェーズ | 主な作業内容 |
|---|---|
| 事前準備 | 手順書整備、ツール検証、担当者訓練 |
| データ収集 | イメージ取得、ログ収集 |
| 証拠保全 | 写真撮影、ハッシュ値検証、チェーン管理 |
| 解析 | ファイルリカバリ、ログ分析 |
| 報告書作成 | 手順記録、証拠提示、結果報告 |
本章のフォレンジック連携フローを説明する際は、「証拠の完全性維持が法的有効性を担保する鍵」である点を強調し、チェーンオブカストディ管理とハッシュ検証手順を必ず示してください。
技術者はフォレンジックツールのバージョン管理、手順書の最新版維持、実務訓練記録を運用マニュアルに反映し、定期的なレビューで手順遵守を確認してください。

8 法令・政府方針遵守
ハードディスク故障対策には、各国政府や国際機関が策定する法令・ガイドラインの遵守が欠かせません。本章では、日本、米国、EUの主要な指針・規制を整理し、システム設計・運用時の要件を明示します。
- 事業継続ガイドライン(内閣府、令和5年3月):企業はBCP構築の基本として3重化保存や段階運用を策定する必要があり、テレワークや情報セキュリティ強化の最新要件が追加されています。
- サイバーセキュリティ経営ガイドライン Ver.3.0(経済産業省):経営者やCISOが実施すべき“重要10項目”やリスク評価手順を示し、サプライチェーン全体を視野に企業ガバナンス強化を求めています。
- 情報システム運用継続計画ガイドライン(内閣官房NISC、令和3年4月):中央省庁向けに策定された本指針は、感染症や大規模災害時の運用継続・復旧手順を詳細に規定しています。
- 新型コロナウイルス感染症発生時の業務継続ガイドライン(厚生労働省、令和5年5月更新):感染症流行下でも介護・福祉施設などの社会的サービスを維持するためのBCP策定ポイントが示されています。
- NIST SP 800-88 Rev.1:Guidelines for Media Sanitization(米国):各メディア機器の機密度に応じた消去・廃棄方法を規定し、不適切な廃棄がデータ漏洩を招かないよう指導します。
- NIST SP 800-61r3:Computer Security Incident Handling Guide(米国):インシデント対応の統一プロセス(検知→対応→復旧)を示し、ログ管理やフォレンジック連携の手順を規定します。
- Continuity Guidance Circular(FEMA、米国):公共・民間を問わず緊急時連続性の確保原則をまとめ、組織の役割別BCP策定と統合訓練の実施を推奨します。
- GDPR Article 32(EU):個人データ処理の安全性確保措置(技術的・組織的)を規定し、違反時には企業に対し最大年間売上高の2.5%までの罰金が科せられます。
本章の法令・ガイドライン一覧を示し、「企業は国内外の規制を同時に遵守する必要性」が経営判断の前提である点を強調してください。特にGDPR罰則やNIST消去要件の重要性を伝えてください。
技術者は自社運用マニュアルに上記指針の適用箇所をマッピングし、定期監査・更新時に必ず見直し項目としてチェックリスト化してください。

9 国内ガイドラインとのマッピング
本章では、国内外の法令・ガイドラインを情報システム運用やデータ復旧のプロセスへ具体的に落とし込む方法を示します。各指針の要件を対照表で整理し、設計や運用にどう反映すべきかを明確化します。
経済産業省「サイバーセキュリティ経営ガイドライン」では、ランサムウェア対策に関する「多層バックアップ」と「脅威情報共有」の要件が示されています。この要件は第2章 故障モード別原因分析と連携し、障害モードに応じたバックアップ頻度設計を策定する際に必ず参照してください。[出典:経済産業省『サイバーセキュリティ経営ガイドライン Ver.3.0』]
内閣官房NISC「情報システム運用継続計画ガイドライン」では、BCP計画の3重化保存や運用段階ごとの手順書記載要件が詳述されています。本書の第5章 BCP:3重化+3段階運用シナリオに記載したシナリオを作成する際には、ガイドラインの「付録B:運用設計テンプレート」をフォーマットとして用いることを推奨します。[出典:内閣官房内閣サイバーセキュリティセンター『情報システム運用継続計画ガイドライン』令和3年4月]
内閣府「事業継続ガイドライン」では、初動対応の体制整備要件と訓練計画の義務化項目があります。特に「初動判断時間」は第4章 緊急データ復旧の初動で示したKPIと合わせて定期レビュー対象とし、訓練結果をBCPに反映してください。[出典:内閣府『事業継続ガイドライン』2023年版]
厚生労働省「新型コロナウイルス感染症発生時の業務継続ガイドライン」には、感染症など長期中断時のデータ保全・代替業務手順が掲載されています。本記事第5章で言及した「システム停止運用」の具体例として、同ガイドラインの「付録C:感染症対策訓練シナリオ」を参考にしてください。[出典:厚生労働省『新型コロナウイルス感染症発生時の業務継続ガイドライン』2024年5月]
| ガイドライン | 対象章 | 適用ポイント |
|---|---|---|
| サイバーセキュリティ経営ガイドライン | 第2章, 第6章 | 多層バックアップ設計, インシデント対応 |
| 情報システム運用継続計画ガイドライン | 第5章, 第11章 | 3重化運用シナリオ, 定期訓練計画 |
| 事業継続ガイドライン | 第4章, 第5章 | 初動対応体制, 運用段階設計 |
| 感染症業務継続ガイドライン | 第5章 | 長期中断代替手順 |
本章のマッピング表を用いて、各ガイドライン要件が自社のどの運用フェーズで必要になるかを関係部門に示し、遵守漏れリスクを明確化してください。
技術者はガイドライン要件を章ごとのチェックリストに変換し、運用・設計レビュー時に必ず照合できるように管理してください。

10 システム設計と多重冗長化
堅牢なシステム設計では、政府の統一基準ガイドラインが示す「可用性」「機密性」「完全性」を併せて確保し、冗長化構成を組むことが求められます。
ハードウェアレイヤーでは、サーバやストレージのN+1冗長化(バックアップ機器を1台以上用意)を導入し、故障時にも機能継続を可能にします。
ネットワーク構成ではマルチホーミング(複数回線接続)と二重ルーター設置により、回線障害時の自動フェイルオーバーを実現します。
ストレージ面では、SANやNASの二重化に加え、定期的なスナップショット取得とリモートレプリケーションを組み合わせることで、データ損失を最小化できます。
ソフトウェア設計では、クラスタリング構成を採用し、アクティブ/スタンバイ間で自動フェイルオーバーする仕組みを設けます。
仮想化環境では、ハイパーバイザーの冗長性とライブマイグレーション機能を活用し、物理ホスト障害時にも仮想マシンを継続稼働させます。
電源系統も別経路供給(UPS+非常用発電機)を二重化し、停電時にもシステムを継続運用できる環境を構築します。
定期テストでは、HAZOPなどのリスクレビュー手法を用い、障害シナリオを想定した演習を実施して多重化設計の有効性を検証します。
設計文書と構成管理は、NISC統一基準の運用手順書テンプレートに沿って標準化し、変更時にはすべての冗長要素を再チェックする運用フローを定めます。
外部専門家連携では、情報工学研究所のような高い技術力を持つ復旧業者と共同で設計レビューを行い、第三者視点による脆弱性評価を実施することが推奨されます。
設計パターン比較表| 構成要素 | 冗長化方式 | 利点 |
|---|---|---|
| サーバ | N+1クラスタリング | 自動フェイルオーバー |
| ネットワーク | マルチホーミング 二重ルーター | 回線障害耐性 |
| ストレージ | SAN/NAS冗長化 リモートレプリケーション | データ可用性向上 |
| 電源 | UPS+発電機二重化 | 停電耐性 |
本章の多重冗長化設計を説明する際は、「各要素でN+1以上の冗長性を確保している」点と「障害シナリオごとの自動切替手順」が運用マニュアルに明記されていることを強調してください。
技術者は設計ドキュメントに冗長要素の一覧とフェイルオーバーテスト結果を添付し、定常レビューで設計仕様と実運用の整合性を確認してください。

11 運用・点検・監査
システムを設計・導入した後は、計画通りに稼働しているかを継続的に確認するため、定期的な運用・点検・監査が不可欠です。まず、日次・週次・月次での運用作業チェックリストを用意し、担当者が確実に項目を実行した証跡を保存します。
次に、四半期ごとに点検テストを実施します。例えば、フェイルオーバー演習/バックアップ復元訓練をシナリオ化して、本番環境の一部または検証環境で実際の手順を確認します。これにより、手順書と運用手順の齟齬や省略漏れをあぶり出せます。
監査は年次で実施し、内部監査と外部監査の二重体制が望ましいです。内部監査では自社のガイドライン適合状況をチェックリストに沿って評価し、外部監査では第三者機関に基準準拠性を検証してもらいます。特にBCPやセキュリティ対策の運用状況が審査対象となります。
運用・点検・監査のスケジュール例| 頻度 | 内容 | 目的 |
|---|---|---|
| 日次 | S.M.A.R.T.ログ確認、警告メールチェック | 異常早期検知 |
| 週次 | バックアップ完了確認、部分復元テスト | 復元可否検証 |
| 月次 | 温度・振動レポート作成、傾向分析 | 長期トレンド把握 |
| 四半期 | フェイルオーバー演習、災害訓練 | 手順実効性検証 |
| 年次 | 内部/外部監査 | 準拠性評価 |
運用・点検・監査のスケジュールを示し、「計画倒れを防ぐため定期的に実施すること」、「結果を記録し改善サイクルを回すこと」を強調してください。
技術者はチェックリストとテスト結果を一元管理し、問題発見時には即時対応策を関係部門に通知する運用フローを整備してください。

12 人材育成・資格・採用戦略
データ復旧・システム障害対応およびセキュリティ運用には、専門スキルを持つ人材の確保・育成が不可欠です。本章では、必要な資格要件、研修体制、採用ポイントを整理します。
まず国内で広く認知されている資格として、情報処理推進機構(IPA)認定の情報処理安全確保支援士があります。これはサイバーセキュリティに関する基礎理論から実践手法までを網羅し、CSIRTやインシデント対応の実運用に必要な知識を担保します。
海外の国際資格では、ISACAが主催するCISA(Certified Information Systems Auditor)、およびCISM(Certified Information Security Manager)が有効です。これらは監査・ガバナンス視点を含む広範な知見を認定し、高度なセキュリティ運用人材の指標となります。
研修プログラムとしては、座学・eラーニングに加え、演習形式のインシデントレスポンス訓練を組み合わせることが効果的です。実機を使ったフォレンジック解析演習や、ランサムウェア侵害時の復旧シミュレーションを定期的に行うことで、即応力を養います。
採用戦略上は、ポテンシャル人材へのOJTとメンター制度を導入し、実務経験を早期から積ませる仕組みが望ましいです。また、長期的には社外研修や資格取得支援によって、社員の離職防止とスキル維持向上を図ります。
育成・研修プログラム例| フェーズ | 内容 | 期間 |
|---|---|---|
| 基礎研修 | 情報セキュリティ基礎理論・S.M.A.R.T.概論 | 2週間 |
| 実践演習 | フォレンジック解析・障害復旧シミュレーション | 1ヶ月 |
| 認定取得 | CISA・情報処理安全確保支援士試験対策 | 3ヶ月 |
| OJT・メンター | 現場実務支援・レビュー会議参加 | 6ヶ月 |
本章の育成・研修プログラムを説明する際は、「資格取得と実践演習を組み合わせた段階的育成体制」が社内スキル標準となる点を強調してください。
技術者は自身の研修進捗と認定取得状況を定期報告し、メンターとのレビューで課題を明確化して改善サイクルを回してください。
13 関係者アサインと責任分担
大規模システム障害対応では、「誰が何をいつまでに行うか」が明確でないと初動対応・復旧作業が滞ります。本章では、主要なステークホルダーを整理し、各段階での役割と責任範囲を定義します。
事業継続ガイドラインでは、BCP推進責任者(経営層レベル)、インシデント対応リーダー(CSIRT責任者)、システム運用チームリーダー、セキュリティオペレーションチームなどを必須ステークホルダーとして挙げています[出典:内閣府『事業継続ガイドライン』2023年版]。
システム障害発生時には、以下の4つの主要ロールを設定してください:
- BCP推進責任者:経営判断の最終責任を持ち、初動体制承認・予算確保を行う。
- CSIRT責任者:インシデント管理全体を統括し、外部連携・法令対応を指示する。
- システム運用リーダー:障害調査・復旧計画の詳細設計を実施し、運用チームを指揮する。
- セキュリティオペレーションチーム:サイバー攻撃時のログ分析・フォレンジック連携を担当する。
| ステークホルダー | 役割 | 責任範囲 |
|---|---|---|
| BCP推進責任者 | 経営判断承認 | 予算配分・最終意思決定 |
| CSIRT責任者 | インシデント統括 | 外部通報・法令対応 |
| システム運用リーダー | 復旧計画策定 | チーム組成・工程管理 |
| セキュリティOPチーム | ログ解析 | フォレンジック連携・検証 |
| 外部復旧業者 | 専門技術提供 | 物理復旧支援・機器搬送 |
本章のステークホルダー定義を示し、各ロールが具体的にどのフェーズで意思決定・作業を行うかを部門間で合意してください。
技術者は組織図にステークホルダーと連絡先フローを併記し、インシデント発生時に迷わず適切な担当へエスカレーションできる体制を整備してください。

14 外部専門家へのエスカレーション
情報システム運用継続計画ガイドラインでは、計画の継続的改善を図るために「必要に応じて、外部専門家による第三者監査等を実施して外部の見識を活用」することが明記されています[出典:内閣官房内閣サイバーセキュリティセンター『情報システム運用継続計画ガイドライン』令和3年4月]。
外部専門家へ依頼する主なタイミングは、
- BCP策定後の初回レビュー時
- 重大障害発生後の事後検証時
- 法令改正やシステム大規模更新時
外部専門家には、政府機関や公的研究機関と連携実績がある法人・企業を選定し、契約書に「レビュー範囲」「成果物」「秘密保持」「報告期限」を明記することで、品質とスピードを確保します。
外部監査実施フロー| ステップ | 内容 | 関係者 |
|---|---|---|
| 1. 依頼要件定義 | レビュー対象と範囲の決定 | CSIRT責任者, 外部専門家 |
| 2. 契約締結 | 秘密保持契約・納期設定 | BCP推進責任者, 法務 |
| 3. 監査実施 | 運用マニュアル照合, 技術検証 | 外部専門家, システム運用リーダー |
| 4. 報告・改善提案 | リスク指摘, 改善計画提示 | 全ステークホルダー |
| 5. 改善実施 | 計画反映, 再レビュー | 技術チーム, 外部専門家 |
外部専門家監査フローを示し、「第三者視点でのレビューが運用改善の鍵」である点と、契約条件設定時の注意事項(範囲・納期・守秘義務)を明確に説明してください。
技術者は外部監査で得られた指摘事項を課題管理表に登録し、担当者・期限を明示してフォローアップする改善サイクルを確立してください。

15 御社社内共有・コンセンサス
本記事の内容を社内で共有し、合意形成を図るためには、技術担当者から経営層へ「要点整理ワークシート」を提示することが効果的です。ワークシートには各章のKPI・要件・対応者を一覧化し、経営判断を支援できる情報をまとめます。
ワークシート例の主要項目:
- 章番号とテーマ
- 主要KPI(例:初動判断時間、S.M.A.R.T.閾値逸脱回数)
- 関連法令・ガイドライン
- 担当者と期日
- レビュー・承認状況
ワークシートを示し、「シンプルな承認フロー」が用意されていること、「各KPIが数値で追える」仕組みである点を強調してください。
技術者はワークシートの更新タイミング(運用会議後、監査後、外部監査後)を明確化し、定常的に経営層へレポートできるコミュニケーションフローを整備してください。
