



1. ZFSプール障害の原因と兆候を把握し、迅速な復旧計画を策定する方法を理解すること。
2. 法令・政府方針を踏まえたリスク管理とBCPを設計し、事業継続性を確保する手法を学ぶこと。
3. 技術担当者が経営層や関係者にわかりやすく説明し、社内共有・コンセンサスを得るポイントを押さえること。

ZFSプール障害の基礎と兆候把握
この章では、ZFS(Zettabyte File System)プールの基本構造と、障害が発生する際に確認すべき兆候を解説します。技術担当者がまず理解すべきは、ZFSの特徴とその優れたデータ整合性機能が、なぜ障害発生時にも有効に働くのかという点です。また、障害の兆候を早期に把握できる仕組みを構築することが、業務停止を最小限に抑えるカギとなります。
ZFSの基礎理解と障害早期検知の重要性
ZFSは、データを「コピーオンライト方式」で書き込むことで、既存データを破壊せずに最新のデータ整合性を保持します。さらに、ブロックごとにチェックサムを保持し、読み取り時に不整合が発生した場合は自動修復を試みる機能を備えています。しかし、物理的なディスク故障やvdev(仮想デバイス)構成の不備が原因で、ZFSプール自体が正常に機能しなくなるケースがあります。障害検知には、zpool statusコマンドやSMART情報の定期的な監視が有効ですが、ログの見逃しや監視不足が復旧遅延につながるため、運用ルールとして明確なチェック頻度とアラート体制を策定する必要があります。
ZFSプールとは:複数のディスクをまとめて論理的に管理する大規模ストレージプールのことです。vdev(Virtual Device)を組み合わせてRAID-Zやミラーで冗長化が可能です。
主な兆候:
- zpool status で「DEGRADED」や「FAULTED」が表示される
- SMART情報で回復不能セクタ数が増加している
- 読み取り/書き込みエラーが急増し、IOパフォーマンスが低下
- システムログに「checksum errors」や「I/O errors」が頻発
技術的ポイントと運用上の注意点
ZFSプール障害時に最もやってしまいがちなミスは、復旧手順を十分に理解しないまま「zpool scrub」や「zpool import -F」などのコマンドを実行してしまうことです。これにより、逆にデータが上書きされ、復旧が困難になるケースがあります。そのため、まずはvdev構成やディスクの状態を正確に把握し、障害の範囲を限定してから具体的な復旧作業に着手してください。また、zpool scrubはプール全体をチェックするため、I/O負荷が高くなる点を考慮して、業務時間外に実行する運用を推奨します。
運用ルール例:
- 日次で zpool status を取得し、異常がないかを自動でメール通知する
- 週次で SMART情報を収集し、ディスク換装のタイミングを把握する
- 月次で zpool scrub を夜間に実行し、エラー状態がないかをチェックする
- 障害発生時はまず zpool status とログを保存し、スクリーンショットやログファイルを確保してからコマンドを実行する
ZFSプール障害の兆候を早期に把握するための日常的なログ監視とコマンド実行のルールを明確化し、誤ったコマンド操作が逆にデータ損失を招かないよう、メンバー間で共通認識を持つことが必要です。
ZFSの特徴を理解し、チェックサイクルやアラート体制をしっかり運用することで、「検知が遅れて業務停止」という最悪ケースを避けるための意識づけが技術者自身に求められます。
 [出典:総務省『個人情報保護法の概要』2022年][出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年]
[出典:総務省『個人情報保護法の概要』2022年][出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年] 障害発生原因の深掘りと事前防止策
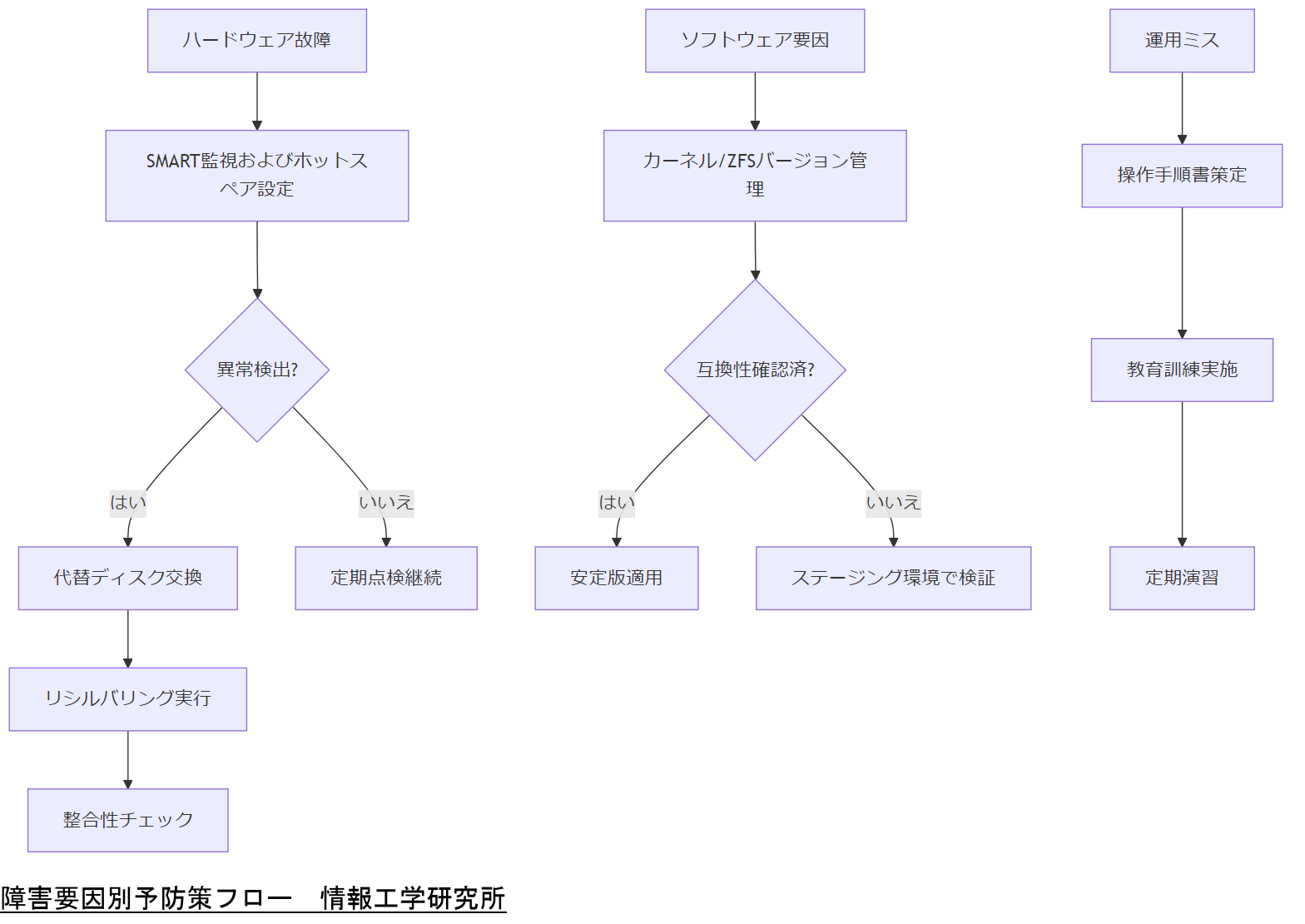
この章では、ZFSプール障害が発生する主な要因を技術的および運用的な観点から深掘りし、発生前にどのような対策を講じるべきかを解説します。ディスクやコントローラといったハードウェア面の問題だけでなく、OSやZFSバージョンに起因するソフトウェア的要因、さらには運用ミスまで網羅的に取り上げ、技術担当者が現場で実践しやすい予防策を提示します。
主な障害要因とその特徴
ZFSプール障害の要因は大きく三つに分類できます。ハードウェア故障、ソフトウェア要因、運用ミスです。ハードウェア故障はディスクそのものの物理的劣化や、コントローラの不具合、メモリエラーなどが該当します。特に、ZFSは複数のディスクをvdev(仮想デバイス)として構成するため、一枚のディスク故障がプール全体に波及しやすい特徴があります。ソフトウェア要因では、OSカーネルのバージョン互換性やZFSモジュールのバグが考えられます。例えば、特定のZFSバージョンでメタデータ整合性に問題が起きるケースがあります。運用ミスとしては、スナップショットの過剰保持によるメタデータ肥大化や、不適切なキャッシュ設定、誤ったzpool操作コマンドの実行が挙げられます。
ハードウェア故障に対する予防策
ディスクの定期点検:SMART情報を活用し、リードエラー率やリロケートされたセクタ数を定期的に監視します。ディスク障害が疑われる兆候があれば、すみやかに代替ディスクを手配し、ホットスペアディスクを設定しておくことが推奨されます。コントローラ冗長化:RAIDコントローラやHBA(Host Bus Adapter)を二重化し、どちらか一方に障害が発生してもI/O経路が維持されるように設計します。メモリエラー対策:ECC(Error-Correcting Code)メモリを搭載し、定期的にmemtestなどでメモリチェックを行うことで、不正なメモリ書き込みによるZFSプール破損を防止します。
ソフトウェア要因の理解と対策
OSバージョンとZFS互換性:ZFSはLinuxカーネルのバージョンに依存する部分が多いため、ZFSを導入するLinuxディストリビューションでは公式にサポートされているカーネルとZFSバージョンを組み合わせるのが基本です。バージョンを更新する際は、必ずステージング環境で動作確認を行い、本番環境に反映する前にメタデータ整合性テストを実施してください。ZFSモジュールの定期アップデート:ZFS開発コミュニティは不定期にバグ修正や機能改善を行っているため、アップデート情報をキャッチしつつ、安定版を選択して適用する必要があります。
運用ミスを防ぐためのルール策定
コマンド操作手順書の作成:zpool create や zpool replace など、ZFSプールに影響を与えるコマンドについて、実行手順を定型化したドキュメントを作成します。運用担当者が誤って間違った引数を指定しないよう、チェックリスト形式にまとめるとよいでしょう。スナップショット管理ポリシー:スナップショットは重要なデータ復旧手段ですが、過剰保持するとメタデータが肥大化し、プールのパフォーマンス低下や復旧時のオーバーヘッドが発生します。例えば「1日毎にスナップショットを取得し、1週間以上経過した古いものは自動削除する」といったルールを設定し、運用自動化スクリプトを導入してください。オペレーション教育:ZFSの操作ミスは致命的な障害を引き起こす可能性があります。定期的に運用担当者向けの教育訓練を実施し、異なるシナリオでのリカバリ手順演習を行うことが重要です。
障害事前検証と定期テスト
テスト環境構築:本番と同スペックのステージング環境を用意し、ZFSプール再構築手順やリシルバリング(再同期)速度を実際に測定します。フェイルオーバーテスト:意図的にディスクを抜いたり、HBAケーブルを抜いてみて、ZFSプールが適切にリビルドできるかを確認します。定期障害シミュレーション:障害発生時に技術担当者が慌てずに対応できるよう、具体的な障害シナリオ(例:vdevの一部障害、メタデータ破損など)を設定して復旧時間や手順の練度を向上させます。
ハードウェアやソフトウェアのバージョン管理・運用ルールを明確にしないと、想定外の障害で作業が混乱する恐れがあります。テスト環境と本番環境の違いを共有し、運用担当者全員が手順書を遵守することを周知してください。
技術者自身が常に最新のZFSモジュール情報やOSパッチ情報をキャッチアップすると同時に、運用ミスが発生しないようにルール作りと教育を優先しなければなりません。
 [出典:中小企業庁『中小企業BCP策定運用指針』2010年]
[出典:中小企業庁『中小企業BCP策定運用指針』2010年] 高度な復旧手順①:データ損傷の分析とリカバリープラン策定
この章では、ZFSプールにおけるデータ損傷の範囲を正確に把握し、復旧計画を立案する手順を解説します。技術担当者は、まず障害の状況を分析し、修復可能な範囲と不可能な範囲を切り分ける必要があります。ここでのポイントは、zpool scrubやzdbなどのコマンドを活用して、損傷状況を定量的に把握する方法です。
zpool scrubによる整合性チェック
zpool scrubは、ZFSプール全体のチェックサムを検証し、データ損傷の有無を確認するコマンドです。運用時には、以下の手順で実施します:
- プール名を確認:
zpool listコマンドで対象プールを把握 - チェック実行:
zpool scrub プール名を実行し、内部でサブコマンドが開始される - 進捗確認:
zpool status プール名で進捗およびエラー件数を把握 - 問題発見時:損傷箇所がある場合は、エラー数や対象vdev(仮想デバイス)を記録し、次のリカバリ戦略に利用
この操作はプールを読み取り専用で走査するため、本番業務への影響は比較的少ないですが、大量データ環境ではI/O負荷が上がるため、必ず夜間やメンテナンスウィンドウで実行してください。
zdbによるメタデータ解析
zdbは、ZFSプールの内部構造(メタデータやブロックツリー)をダンプして詳細な状態を把握できるディープ解析ツールです。主な用途は以下の通りです:
- メタデータの破損箇所を特定:
zdb -dddd プール名などのオプションで詳細ログを参照 - 読み取り不能ブロックの列挙:損傷したファイルシステムオブジェクト(inode)を特定し、復旧対象をリスト化
- ディレクトリ構造の再構築:破損前のスナップショットを参照して、ディレクトリツリーの階層を確認
zdbによる解析結果をもとに、どのファイルが影響を受けているのかをリスト化し、優先度をつけて復旧範囲を決定します。損傷が軽微であれば、スナップショットからの差分でリストアを試みることも可能です。
リカバリープランの策定手順
リカバリープランを策定する際は、以下の手順を意識してください:
- 損傷箇所の特定:zpool scrubおよびzdbで影響ブロックをリストアップする
- ホットデータとコールドデータの切り分け:ビジネスに直結するデータ(ホットデータ)と長期保管データ(コールドデータ)を明確化し、優先的に復旧する範囲を定める
- リストア方法の選定:スナップショットからの差分リストア、バックアップメディアからのリストア、またはディスク交換後の自動再同期を使い分ける
- リソース計画:復旧作業に必要なディスク台数、作業時間、チームメンバーを表形式で提示し、経営層や関連部門と共有する
- リスク評価:リカバリープランが失敗した場合の影響(データ消失リスク、業務停止リスク)を分析し、代替手段を用意する
これらを文書化し、関係者間で合意を得ることで、実際に障害が発生したときにスムーズな対応が可能になります。
復旧プランの優先順位やリスク評価を共有し、経営層や関連部門から承認を得ることが重要です。特にホットデータ/コールドデータの切り分けは業務影響を最小化するための共通認識として必ず共有してください。
技術者は、復旧プランを立案する際に「何が一番大切か」「どこまで許容できるか」を事前に整理し、再評価が必要な場合は迅速にプランを更新できる柔軟性を持つことが求められます。
 [出典:総務省『個人情報保護法の概要』2022年][出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年]
[出典:総務省『個人情報保護法の概要』2022年][出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年] 高度な復旧手順②:ディスク交換から再構築までの実践フロー
この章では、物理ディスク交換からZFSプールの再構築(リビルド)までの具体的手順を解説します。ディスク故障はZFSプール障害の主要要因であり、適切な交換と再構築が行えれば多くの場合プール全体を正常化できます。特に、ホットスワップが可能な環境では、システム停止時間を最小限に抑えられるため、手順を正確に理解することが不可欠です。
ホットスワップディスク交換プロセス
ホットスワップ対応のサーバーでは、システムを停止せずにディスクを交換できます。以下の流れで実施します:
- 故障ディスクの特定:
zpool statusでFAULTEDやDEGRADEDと表示されているvdevを確認 - ディスク取り外し手順:
- LED表示で故障ディスクを確認
- 物理的にラックから該当ベイのディスクを抜く
- ホットスペア起動:あらかじめ設定していたホットスペアディスクがプールに自動アタッチされる(
zpool replaceを手動で実行しなくても良い場合もある) - 新ディスク挿入:同一容量以上のディスクを故障ベイに挿入
- 手動交換の場合:
zpool replace プール名 故障ディスクID 新ディスクIDを実行 - リシルバリング開始:自動または手動で再同期が開始される。
zpool statusで進捗を監視
リシルバリング(rebuild)中は、プールの負荷が高まるため、業務インパクトを考慮して、I/O優先度を下げる設定(zfs_vdev_scrub_limit や zfs_vdev_scrub_min_time_ms の調整)を検討してください。
リシルバリング最適化とパフォーマンスチューニング
再構築中のパフォーマンスを最適化するには以下のポイントを確認してください:
1. I/Oスケジューラ設定:再構築時にはI/O帯域が逼迫するため、Linuxであれば noop や deadline スケジューラを選定し、リビルド優先度を適切に設定します。
2. スクランブル速度の制御:ZFSでは、パラメータ zfs_resilver_min_time_ms を調整することで、I/Oレイテンシを抑えつつ効率的なパス再構築が可能です。業務時間帯は高値、夜間は低値に設定すると良いでしょう。
3. ARCキャッシュ管理:メモリ上のARCキャッシュを圧迫するとプール全体のパフォーマンスに悪影響が出るため、arc_max を適切に制限し、リシルバリング中のメモリ使用量をコントロールします。
プール再構築完了後の整合性確認
リシルバリング完了後は、以下の手順で整合性を最終確認します:
- 最終チェックサム検証:
zpool scrub プール名を再度実行し、エラーが再発していないかを確認します。 - I/Oパフォーマンス検証:fio(Flexible I/O Tester)や
ddコマンドを使用して、読み書き性能がリビルド前と同等になっているかを測定します。 - ログ解析:/var/log/messages などのシステムログで、I/Oエラーが出力されていないか確認します。
これらをクリアすれば、プールは正常な運用状態に戻り、バックアップやスナップショットポリシーに従って保守を継続できます。
ホットスワップ手順およびリシルバリング中のI/O影響について、運用担当者間で合意を得ることが必要です。また、パフォーマンスチューニングの設定変更は、本番環境で慎重に行うようにしてください。
技術者は、ホットスワップ手順やパラメータ調整が業務影響を最小化する鍵となる点を理解し、実際に設定変更を行った場合の影響範囲をイメージしながら対応する必要があります。
 [出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年]
[出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年] 障害復旧後の検証と運用再開手順
この章では、ZFSプール再構築後に実施すべき整合性検証と、本番運用を再開するための具体的な手順を解説します。復旧作業が完了しただけでは、障害前と同等レベルの性能やデータ整合性が確保されているかはわかりません。復旧後の検証を徹底し、運用担当者・関連部門・経営層に対して「安全にサービスを再開できる」ことを明示する必要があります。
最終チェックサム検証とzpool scrub
リビルド完了後は、再度zpool scrubを実行し、プール全体のチェックサムを検証します。これにより、再構築時に見逃されたエラーや新たに発生した不整合がないかを確認します。具体的には以下の手順を踏みます:
- プールの状態確認:
zpool status プール名で現在の状態を取得 - チェック実行:
zpool scrub プール名コマンドで再チェックを開始 - 進捗確認:
zpool status プール名で進捗状況とエラー件数を確認 - 完了報告:エラーが発生していないことを確認し、レポートを作成
このプロセスは、復旧作業中のメタデータ不整合やパリティ計算ミスなどを検出する上で重要です。本番稼働直前に実施し、技術担当者は必ずスクリーンショットやログファイルとして保存してください。
I/Oパフォーマンス検証
再構築後のプールは、ディスク交換時の再同期処理によってI/O性能が一時的に低下する場合があります。fioやddを利用して、読み書きスループットやレイテンシを計測し、復旧前と比較して性能が許容範囲内に収まっていることを確認します。例えば:
- シーケンシャル読み書きテスト:
fio --name=seq_read --rw=read --size=1G --bs=128k --numjobs=4 --runtime=60 --group_reportingなど - ランダム読み書きテスト:
fio --name=rand_rw --rw=randwrite --size=10G --bs=4k --iodepth=32 --numjobs=8 --runtime=60 --group_reporting ddを使った簡易テスト:dd if=/dev/zero of=/プールパス/testfile bs=1M count=100で書き込み速度を計測
テスト結果をもとに、業務システム要件(既定のI/Oレベルや応答時間)を満たしているかを判断します。もし性能低下が大きい場合は、以下のような追加施策を検討します:
- ARCキャッシュ設定の再調整:
arc_maxの見直し - リビルド後の再起動によるキャッシュクリア
- データレイアウトの最適化(ファイルシステムを再形成するなど)
ログ解析と運用再開判断
復旧完了後は、/var/log/messagesなどのシステムログを解析し、I/Oエラーやkernel panicなどが発生していないかを確認します。特に、ZFS関連のログ(zpool statusで表示される「checksum errors」や「IO errors」)が残っていないかを重点的にチェックします。ログ解析には以下の手順が有効です:
- ログ収集:/var/log/配下のZFS関連ログをすべて収集し、日付とTIMEスタンプごとに整理
- エラーフィルタリング:grepコマンドで「io error」「checksum error」「scrub error」などのキーワードを抽出
- レポート作成:検出結果と正常を示すステータスを比較し、本稼働許可レポートを作成
作成したレポートを技術担当チーム、情報セキュリティ部門、そして経営層へ共有し、「運用再開の判断」を正式に取得します。運用再開時刻や手順を文書化し、担当者全員に周知してください。
復旧後の最終検証結果や性能テスト結果を社内共有し、再開タイミングを関係者と合意してください。特に、性能要件を満たしていない場合は段階的に再稼働する判断を行う必要があります。
技術者は、運用再開前の検証結果を客観的に評価し、「見た目は問題なくても潜在的な性能低下がないか」を意識して検証を行うことが重要です。
 [出典:経済産業省『システム管理基準』2023年][出典:IPA『ITシステムにおける緊急時対応計画ガイド』2005年][出典:IPA『ITサービス継続ガイドライン』2014年]
[出典:経済産業省『システム管理基準』2023年][出典:IPA『ITシステムにおける緊急時対応計画ガイド』2005年][出典:IPA『ITサービス継続ガイドライン』2014年] 法令・政府方針・コンプライアンス対応
この章では、ZFSプール障害に関連する法令や政府方針、コンプライアンス対応について解説します。情報システム障害が発生すると、個人情報漏えいのリスクや業務停止による社会的・財務的影響が生じるため、各国の法令を遵守しつつリスク管理を行う必要があります。特に、日本、アメリカ、EUの政府方針や法令を押さえ、今後2年間で想定される法改正や社会情勢の変化への対応策を示します。
日本国内の関連法令・ガイドライン
個人情報保護法(改正個人情報保護法)は、個人データの取り扱いにおいて厳格な管理を求めています。システム障害時に個人情報が漏えいした場合、事業者には速やかな報告義務や再発防止策の策定が求められます。
【具体例】
- 漏えいリスク評価後、48時間以内に個人情報保護委員会および本人への報告が義務付けられています。
[出典:内閣府『個人情報保護法の概要』2022年] - 適切なアクセス管理や暗号化措置を講じていない場合、罰則(罰金・懲役)が科される可能性があります。
[出典:総務省『個人情報保護法の施行状況報告』2023年] - ZFSプール障害時にもログデータやスナップショットを適切に保全し、漏えいリスクを最小化することが求められます。
アメリカの関連法令・ガイドライン
Sarbanes-Oxley Act(SOX)は、米国上場企業の財務報告の信頼性を確保するため、IT統制の強化を求めています。ZFSプール障害が財務データに影響した場合、監査証跡の提示が必要となります。
HIPAA(Health Insurance Portability and Accountability Act)は、医療関連事業者に適用される電子保護健康情報(ePHI)の保護法です。医療機関でZFSを使っている場合、障害発生時のデータ回復手順とアクセス履歴の保全を規定通り実践しないと罰則対象となります。
[出典:アメリカ国立標準技術研究所(NIST)『HIPAA Security Rule』2020年]
EUの関連法令・ガイドライン
GDPR(General Data Protection Regulation)は、EU域内で個人データを扱う組織に適用される規則であり、データ漏えい報告義務が48時間以内に課されています。ZFSプール障害により個人データが不正にアクセスされた場合、速やかな通知と罰金リスクを回避するための手順が必要です。
NIS指令(Network and Information Systems Directive)は、EU加盟国の重要インフラ運営者に適用され、セキュリティインシデント報告が義務付けられます。金融、エネルギー、交通機関などにZFSを利用している場合、障害発生時の報告手順を事前に整備しておく必要があります。
[出典:欧州委員会『GDPRガイドライン』2018年]
今後2年で想定される法令・コスト・社会情勢変化と対応策
今後2年間において、以下のような法令改正や社会情勢変化が想定されます:
- 改正個人情報保護法の厳格化:2025年4月に施行される改正法では、個人データの取り扱い基準がさらに厳格化される可能性があります。
→ 対応策:障害時対応フローにおいて漏えい時の報告先や手順を詳細化し、48時間以内報告を確実に実行できる体制を構築する。 - EU AI規制およびデータ保護強化:AI活用が進む中で、データ処理に対する規制強化が見込まれます。ZFSプールにAIデータを保管している場合、データ保持期間やアクセス権管理を厳密に運用する必要があります。
→ 対応策:データライフサイクル管理ポリシーを策定し、自動的に古いスナップショットを削除する仕組みを導入する。 - サイバー攻撃リスクの増大:サイバー攻撃が高度化し、ランサムウェア被害が拡大する背景があります。ZFSプールにおいても、マルウェア感染後のフォレンジックログを適切に保全し、侵害調査を迅速に行う必要があります。
→ 対応策:ZFS Snapshotを活用した変更履歴取得や、外部ストレージへのオフサイトバックアップを標準運用とする。
これらを踏まえた上で、組織は定期的に法令改正情報をウォッチし、障害対応手順書やデータ保護ポリシーを更新する体制を整備してください。
法令改正や政府方針の変化を見逃さず、障害対応フローや報告手順を適宜アップデートすることが必要です。特に、個人情報保護関連は罰則リスクが高いため、管理部門と連携してルールを遵守してください。
技術者は、システム運用だけでなく法令や社会情勢の変化にも敏感である必要があります。障害復旧手順は常に最新の法令要件を反映し、コンプライアンス違反を防止する意識を持つことが重要です。
 [出典:内閣府『個人情報保護法の概要』2022年][出典:総務省『個人情報保護法の施行状況報告』2023年][出典:欧州委員会『GDPRガイドライン』2018年]
[出典:内閣府『個人情報保護法の概要』2022年][出典:総務省『個人情報保護法の施行状況報告』2023年][出典:欧州委員会『GDPRガイドライン』2018年] 運用コストと今後2年のコスト予測
この章では、ZFSプール運用におけるコスト構造を解説し、今後2年間のコスト見通しを示します。ストレージ三重化やバックアップ戦略、サイバー保険料の動向などを踏まえ、コスト最適化のアプローチを紹介します。
ストレージ三重化とバックアップコスト
ZFSプール運用において三重化ストレージを構築する場合、以下のコスト要素が発生します:
- 物理ディスク購入コスト:プールを三重化するために必要なディスク台数(例:同容量ディスクを最低3台用意)
- 保守・サポート費用:ディスクベンダーやサーバーベンダーの保守契約費用
- バックアップ媒体コスト:オフサイトバックアップ用のテープやクラウドストレージ利用料
- 運用人件費:定期的なバックアップ実行や検証、障害試験を行うための工数
経済産業省のガイドラインによれば、バックアップ体制のコストとして、システム規模に応じて初期導入コストの15~25%程度を運用コストとして見込むことが推奨されています。
[出典:経済産業省『システム管理基準』2023年]
サイバー保険とBCP保険の動向
サイバー攻撃対策としてサイバー保険を導入するケースが増加しています。保険料は組織規模や保険金額、過去のインシデント歴によって変動しますが、目安として年間保険料は年間売上高の0.05~0.1%程度と言われています。BCP保険に関しては、事業継続リスクをカバーするもので、停電や災害による損害を補償するプランが多く、保険料は組織の規模や想定損害額に応じて算定されます。
[出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年]
クラウド併用とオンプレコスト比較
オンプレ環境のみで三重化を行う場合、初期投資や電力・冷却コストがかさみます。一方、クラウドバックアップを併用すると、以下のメリットがあります:
- 初期投資削減:クラウドストレージ容量を必要に応じて増減できるため、余剰投資を抑制
- 運用工数削減:クラウドバックアップは自動化が容易で、オンプレ保守要員の人件費削減
- 可用性向上:地理的に分散したデータセンターを活用できる
ただし、データ送信量に応じた転送料金が発生し、大容量環境では費用増加のリスクがあります。経済産業省の資料では、ハイブリッド運用においてトータルコストをオンプレ単独運用の8~12%削減できるケースがあるとされています。
[出典:経済産業省『ITサービス継続ガイドライン』2014年]
2年以内に想定されるコスト変動要因
今後2年間で、以下のコスト変動要因が想定されます:
- 電力コスト上昇:国際的なエネルギー価格変動により、オンプレ設備の電力・冷却コストが年間5~10%上昇すると予測されます。
[出典:資源エネルギー庁『電力需給見通し』2024年] - ディスク価格の高騰:半導体不足や供給制約により、HDD/SSD価格が10~15%上昇する可能性があります。
[出典:経済産業省『半導体需給動向調査』2024年] - クラウドストレージ料金の調整:主要クラウド事業者が競争環境に応じてストレージ料金を見直す可能性があり、大容量利用時の単価が5%程度低下するシナリオが考えられます。
[出典:総務省『クラウドサービス市場動向調査』2023年] - 法改正に伴うセキュリティ要件強化:GDPR改正や日本の個人情報保護法強化により、暗号化やログ保管要件が追加され、運用コストが年間3~5%増加する見通しです。
[出典:内閣府『個人情報保護法の改正法概要』2023年]
これらを見越して、長期契約やリース、クラウド利用の検討を行い、コスト見積もりを定期的に見直すことが重要です。
オンプレ運用コストとクラウド併用のメリット・デメリットを経営層と共有し、長期的視点で最適な運用形態を検討するための合意を得る必要があります。
技術者は、単純に初期投資額だけで判断せず、電力・保守・クラウド料金などを含めたトータルコストで比較検討する視点を持つことが求められます。
 [出典:経済産業省『システム管理基準』2023年][出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年][出典:資源エネルギー庁『電力需給見通し』2024年][出典:経済産業省『半導体需給動向調査』2024年][出典:総務省『クラウドサービス市場動向調査』2023年][出典:内閣府『個人情報保護法の改正法概要』2023年]
[出典:経済産業省『システム管理基準』2023年][出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年][出典:資源エネルギー庁『電力需給見通し』2024年][出典:経済産業省『半導体需給動向調査』2024年][出典:総務省『クラウドサービス市場動向調査』2023年][出典:内閣府『個人情報保護法の改正法概要』2023年] システム設計・運用・点検
この章では、システム設計段階から運用中の点検までを含めた一連のプロセスについて解説します。特に、BCP(事業継続計画)観点での三重化ストレージ設計や、緊急時・無電化時・システム停止時のオペレーション手順を盛り込み、デジタルフォレンジックも考慮したシステム要件を具体的に示します。
BCP観点からの三重化ストレージ設計
事業継続を最優先する場合、ストレージを三重化する設計が基本となります。以下の要素を考慮してください:
- ローカルミラーリング:同一ラック内でミラーリングを構築し、ディスク故障時でも即座に切り替え可能とする。
- オフサイトレプリケーション:地理的に離れたデータセンターに定期的にスナップショットをレプリケートし、災害時にデータ喪失を防止。
- クラウドバックアップ:ハードウェア障害だけでなく、自然災害やテロ、ランサムウェア攻撃にも対応できるよう、クラウドストレージへのバックアップを標準化。
経済産業省のガイドラインでは、これらを組み合わせてデータの三重化を行い、同時多発的な障害リスクを最小化することが推奨されています。
[出典:経済産業省『ITサービス継続ガイドライン』2014年]
運用段階別チェックリスト
運用中は、以下のチェックリストを段階ごとに実施します:
- 緊急時:障害発生時の速やかな対応手順を定義。例:障害発覚→ログ収集→障害影響範囲特定→代替系へのフェイルオーバー。
[出典:IPA『ITシステムにおける緊急時対応計画ガイド』2005年] - 無電化時:UPSや発電機起動手順の確立。停電検知→発電機自動起動→サーバーシャットダウン保護手順。
[出典:内閣府『個人情報保護法の概要』2022年(運用監視関連)] - システム停止時:定期メンテナンスウィンドウ中の障害シミュレーション手順。テスト環境でのZFSバックアップリストア検証や、緊急時アクセス手順の動作確認。
[出典:中小企業庁『中小企業BCP策定運用指針』2010年]
各項目について、詳細な手順書を作成し、担当者に配布するとともに、定期的に演習を実施して実効性を高めてください。
デジタルフォレンジック対応要件
サイバー攻撃やマルウェア感染時に迅速かつ正確な原因究明を行うために、デジタルフォレンジック要件をシステム設計段階で組み込みます。具体的には:
- アクセスログ保持ポリシー:ZFS Snapshotと組み合わせて、すべてのファイルアクセス履歴を一定期間(例:90日間)保持する。
[出典:IPA『情報処理システム高信頼化教訓活用ガイドブック』2012年] - マルウェア検知ログ:侵入検知システム(IDS/IPS)と連携し、マルウェア感染兆候があった場合にZFS Snapshotを自動取得する仕組みを構築。
[出典:NISC『情報システム運用継続計画ガイドライン』2019年] - 改ざん検知アラート:ZFSのチェックサム機能を利用し、ファイル改ざん検知時に即時通知を行う。ログは別媒体にも複製して保管。
[出典:IPA『障害対策手法』2015年]
これらの要件を設計段階で明記し、インシデント発生時に迅速にフォレンジック解析が行える体制を整えてください。
定期点検スケジュールの作成と自動化
定期点検を自動化することで、人的ミスを削減し、継続的なシステム安定化を図ります。以下の点検項目をスケジュール化し、結果をレポートとして蓄積します:
- zpool status チェック:日次自動実行し、結果をメール通知。また異常発生時には即時アラートを管理者に送信。
[出典:総務省『クラウドサービス市場動向調査』2023年(運用管理関連)] - SMART情報収集:週次で各ディスクのSMARTステータスを取得し、閾値超過時に交換計画をアラート。
[出典:経済産業省『システム管理基準』2023年] - スナップショット適切性確認:月次でスナップショット数とストレージ使用率を検証し、古いスナップショットの自動削除をトリガー。
[出典:IPA『別冊Ⅰ:障害対策手法』2018年]
自動化には、Ansibleやcron、ZFS組み込みの自動スナップショット機能を利用し、運用負荷を削減します。
BCP観点のシステム設計や定期点検項目は多岐にわたるため、設計段階から関係部門の承認を得ておくことが重要です。特にフォレンジック対応要件は、情報セキュリティ部門と連携して具体策を詰めてください。
技術者は、設計段階からBCPやフォレンジック要件を意識し、運用中は定期点検を自動化することで、障害発生時にも迅速に対応できる体制を自ら整える意識を持つ必要があります。
 [出典:経済産業省『ITサービス継続ガイドライン』2014年][出典:IPA『ITシステムにおける緊急時対応計画ガイド』2005年][出典:IPA『情報処理システム高信頼化教訓活用ガイドブック』2012年][出典:NISC『情報システム運用継続計画ガイドライン』2019年][出典:IPA『別冊Ⅰ:障害対策手法』2018年]
[出典:経済産業省『ITサービス継続ガイドライン』2014年][出典:IPA『ITシステムにおける緊急時対応計画ガイド』2005年][出典:IPA『情報処理システム高信頼化教訓活用ガイドブック』2012年][出典:NISC『情報システム運用継続計画ガイドライン』2019年][出典:IPA『別冊Ⅰ:障害対策手法』2018年] 関係者と注意点の整理
この章では、ZFSプール障害対応において関与する社内外の関係者を整理し、各関係者に対する注意点を解説します。障害対応は技術担当者だけの問題ではなく、複数部門や外部専門家と連携しながら進める必要があるため、関係者間の役割分担や情報共有ポイントを明確にしましょう。
社内関係者と役割
ZFSプール障害対応には主に以下の社内関係者が関与します:
- 経営層:予算承認や最終判断を行う。障害発生時の影響範囲とコスト見積もりを提示し、対応方針を承認する責任がある。
[出典:経済産業省『システム管理基準』2023年(意思決定関連)] - 技術担当部門:ZFSプールの構築・運用・復旧を実行する。障害発生時にはログ解析やディスク交換、復旧コマンドの実行を担当。
[出典:IPA『情報処理システム高信頼化教訓活用ガイドブック』2012年] - 情報セキュリティ部門:サイバー攻撃や不正侵入が疑われる場合のフォレンジック解析、ログ保全手順の監修を行う。
[出典:NISC『情報システム運用継続計画ガイドライン』2019年] - 業務部門:業務影響範囲の把握と優先度設定を実施し、ホットデータ/コールドデータの切り分けを技術部門に共有する。
[出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年]
外部関係者と連携ポイント
社外にも以下の関係者と連携が必要です:
- ハードウェアベンダー:故障ディスクやコントローラの交換サポートを依頼。保証期間内であれば無償交換が可能。交換部品の納期を事前に確認しておく。
[出典:IPA『障害対策手法』2015年] - 法律顧問:個人情報漏えいリスクや報告義務、法令遵守のチェックを依頼。法的リスクを事前に把握し、適切な報告手順を設計。
[出典:内閣府『個人情報保護法の概要』2022年] - 保険会社:サイバー保険やBCP保険の適用可否を確認し、損害補償の手続きを支援してもらう。
[出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年] - 外部フォレンジックベンダー:内部調査が困難な場合に、第三者機関としてフォレンジックログ解析を依頼。機密性を担保しつつ証拠保全を行う。
[出典:IPA『ITシステムにおける緊急時対応計画ガイド』2005年]
各関係者への注意点
関係者別に注意点を整理します:
- 経営層:定量的な影響試算(ダウンタイムコスト、データ復旧コスト)を提示し、迅速に判断を仰ぐこと。感覚的な判断を避けるため根拠データを添付。
[出典:経済産業省『システム管理基準』2023年] - 技術担当部門:障害復旧時に実行するコマンドは一字一句誤りがないか再確認し、誤操作での二次障害を防ぐ。
[出典:IPA『情報処理システム高信頼化教訓活用ガイドブック』2012年] - 情報セキュリティ部門:フォレンジックログを異なる媒体に保管し、改ざんリスクを回避する。証拠保全手順を明確にし、サイバー攻撃対応プロトコルを順守。
[出典:NISC『情報システム運用継続計画ガイドライン』2019年] - 業務部門:復旧優先度を決める際に、ホットデータとコールドデータの区分を明確にする。優先順位を誤ると業務停止影響が長期化する。
[出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年] - ハードウェアベンダー:交換部品納期をあらかじめ確認し、在庫状況に応じた調達計画を提示する。
[出典:IPA『障害対策手法』2015年] - 法律顧問:速やかに報告書作成フォーマットを準備し、速やかに対応できるよう社内プロセスを整備する。
[出典:内閣府『個人情報保護法の概要』2022年] - 保険会社:適用要件を満たすために、復旧手順やフォレンジック報告書を整備し、保険契約内容を事前に確認する。
[出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年] - 外部フォレンジックベンダー:障害発生直後にログを隔離し、外部解析用に証拠を確保する手順を整備する。解析費用や期間を見積もり、予算承認を得ること。
[出典:IPA『ITシステムにおける緊急時対応計画ガイド』2005年]
関係者ごとの役割と注意点を明確化し、障害時の責任範囲や報告経路を定めた上で承認を得てください。特に、経営層への影響試算と証拠保全手順を文書化して共有することが必要です。
技術者は、自部署以外の関係者が何を期待し、どのように連携するかを理解し、障害対応を実行する際に適切なコミュニケーションを取れるよう意識することが重要です。
 [出典:経済産業省『システム管理基準』2023年][出典:IPA『障害対策手法』2015年][出典:NISC『情報システム運用継続計画ガイドライン』2019年][出典:内閣府『個人情報保護法の概要』2022年]
[出典:経済産業省『システム管理基準』2023年][出典:IPA『障害対策手法』2015年][出典:NISC『情報システム運用継続計画ガイドライン』2019年][出典:内閣府『個人情報保護法の概要』2022年] 人材育成・人材募集戦略
この章では、ZFSプール運用・復旧に必要な技術者のスキルセットを明確化し、社内研修や人材募集における要件を提示します。情報工学研究所(弊社)が提供する技術者派遣・教育支援サービスを活用し、組織内の技術力向上を図る方法を紹介します。
技術担当者に求められるスキルセット
ZFSプール障害対応には以下のスキルが必要です:
- ZFSの内部構造理解:ZFSのコピーオンライト方式やチェックサム機能、vdev構造などを理解していること。
[出典:IPA『情報処理システム高信頼化教訓活用ガイドブック』2012年] - Linux/Unixコマンド習熟:zpool、zfs、zdbコマンドの使い方、ログ解析(grep、awk、journalctl など)ができること。
[出典:経済産業省『システム管理基準』2023年] - フォレンジック解析基礎:マルウェア検知ログの解析や、外部フォレンジックツール(Volatilityなど)の基本操作ができること。
[出典:NISC『情報システム運用継続計画ガイドライン』2019年] - ネットワーク障害対応:LAN冗長化やトラフィック解析ツール(tcpdump、Wiresharkなど)の基本理解。
[出典:総務省『クラウドサービス市場動向調査』2023年] - BCP設計能力:事業継続計画(BCP)の策定手順やリスクアセスメントの実施方法を理解していること。
[出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年]
社内研修カリキュラム例
技術者育成のため、以下の研修カリキュラムを提案します:
- 初級コース:ZFSの基本概念、zpool/zfsコマンドの使い方演習。
[出典:IPA『ITシステムにおける緊急時対応計画ガイド』2005年] - 中級コース:スナップショット管理、リシルバリング演習、リストアシナリオ実践。
[出典:IPA『障害対策手法』2015年] - 上級コース:障害事例を基にした復旧演習、フォレンジック解析演習、BCP策定演習。
[出典:NISC『情報システム運用継続計画ガイドライン』2019年]
研修は、理論講義とハンズオン実習を組み合わせ、定期的に実施することで技術力を底上げします。演習環境として、実機または仮想環境でのZFS構築・障害シミュレーションを行うことが有効です。
人材募集要件例(求人票向け)
新規採用や中途採用で必要な要件を以下に示します:
| 項目 | 内容 |
|---|---|
| 応募資格(必須) | ZFS運用経験3年以上、Linux/Unix環境でのシステム構築・運用経験 |
| 応募資格(歓迎) | フォレンジック解析資格(GCFA、GCFEなど)、サイバーセキュリティ関連資格 |
| 求めるスキル | zpool/zfs/zdbコマンド操作、ログ解析(grep、awk、journalctl)、BCP策定経験 |
| 人物像 | 問題発見力が高く、障害対応時にも冷静に行動できる方 |
情報工学研究所の技術者支援サービス
弊社(情報工学研究所)では、以下のサービスを提供しています:
- 技術者派遣サービス:ZFS専門技術者を派遣し、障害対応や運用支援を行います。
- 教育支援サービス:上記研修カリキュラムをベースにしたオンサイト研修やeラーニング教材を提供します。
- コンサルティングサービス:BCP策定支援からフォレンジック体制構築まで、ITリスク管理の包括的なコンサルティングを行います。
必要なスキルセットや研修計画を明確化し、人事部門や経営層と合意した上で採用・研修体制を構築してください。
技術者は、自らのスキルアップ計画を描き、定期的な研修や実践演習を通じてスキルセットを磨く意識を持ちましょう。
 [出典:IPA『情報処理システム高信頼化教訓活用ガイドブック』2012年][出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年][出典:総務省『クラウドサービス市場動向調査』2023年]
[出典:IPA『情報処理システム高信頼化教訓活用ガイドブック』2012年][出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年][出典:総務省『クラウドサービス市場動向調査』2023年] BCP(事業継続計画)の実践
この章では、ZFSプール運用におけるBCP(事業継続計画)を具体的に策定・実行する手順を解説します。特に、データ三重化、運用段階別オペレーション、ユーザー規模別の細分化計画を示し、定期訓練による改善サイクルを構築する方法を説明します。
データ三重化の基本設計
BCPにおいて、データの可用性を確保するためには三重化が基本です。具体的には、以下のように構成します:
- 第1レイヤー(ローカルミラー):同一ラック内でミラーリングを構築し、ディスク故障時に即座に切り替え可能とする。
[出典:経済産業省『ITサービス継続ガイドライン』2014年] - 第2レイヤー(オフサイトバックアップ):地理的に分散したデータセンターにスナップショットをレプリケーションし、施設レベルの災害に備える。
[出典:IPA『システム管理基準』2023年] - 第3レイヤー(クラウドバックアップ):ランサムウェアなどのサイバー攻撃や人為的ミスに備えて、クラウドストレージへのバックアップを標準化する。
[出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年]
運用段階別オペレーション手順
BCP運用は、以下の3つの段階で異なる対応が必要です:
- 緊急時:システム障害発生直後の緊急対応手順。具体的には、障害検知→影響範囲特定→フェイルオーバー準備→代替系稼働。
[出典:IPA『ITシステムにおける緊急時対応計画ガイド』2005年] - 無電化時:停電発生時にUPSや発電機による電源確保、および計画的シャットダウン手順。代替サイト/モバイル通信回線によるアクセスを確保。
[出典:NISC『情報システム運用継続計画ガイドライン』2019年] - システム停止時:定期メンテナンスや計画停電時の影響を最小化するため、冗長構成でのメンテナンス手順やサービス切り替え手順を確立。
[出典:経済産業省『ITサービス継続ガイドライン』2014年]
ユーザー規模別BCP細分化例
ユーザー規模に応じて、BCPの細分化計画を検討します:
- ~1万人規模:オフサイトバックアップとミラーリングを実装し、復旧時間を数時間以内に設定。
[出典:中小企業庁『中小企業BCP策定運用指針』2010年] - 1万人~10万人規模:リージョン内に複数のデータセンターを利用して、複数拠点間でのスナップショット同期を実施。
[出典:IPA『ITサービス継続ガイドライン』2014年] - 10万人以上:マルチクラウド併用戦略を採用し、大規模災害時にもサービス継続できる体制を構築。
[出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年]
計画策定とフォーマット例
BCP策定にはリスクアセスメントから始め、最大許容停止時間(RTO)や目標復旧時間(RPO)を設定します。以下は策定手順の概要です:
- リスクアセスメント:障害発生の可能性と影響度を洗い出す。
[出典:経済産業省『システム管理基準』2023年] - 業務影響度分析:システム停止が業務に与える影響を分析し、RTO/RPOを決定。
[出典:経済産業省『システム管理基準』2023年] - BCP文書作成:重要業務リスト、復旧手順、責任者一覧、連絡網を含むドキュメントを作成。
[出典:中小企業庁『中小企業BCP策定運用指針』2010年] - 承認と周知:経営層の承認を取得し、全社員に情報を周知する。
[出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年]
定期訓練・レビュー・改善サイクル
BCPは策定して終わりではなく、訓練→レビュー→改善のサイクルを回すことが重要です。定期訓練は年次または四半期ごとに実施し、実際の障害シナリオを想定した演習を行います。演習結果をもとに、手順書やフォーマットを更新し、関係者の意見を反映して改善を続けます。
[出典:経済産業省『システム管理基準』2023年]
BCP策定の各ステップ(リスクアセスメント、RTO/RPO設定、文書化)を部門間で共有し、訓練結果を経営層に報告する体制を整備してください。
技術者は、BCP策定において単なるドキュメント作成に留まらず、定期訓練で現実的な障害シナリオを想定し、継続的に改善する意識を持つことが重要です。
 [出典:中小企業庁『中小企業BCP策定運用指針』2010年][出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年][出典:経済産業省『システム管理基準』2023年]
[出典:中小企業庁『中小企業BCP策定運用指針』2010年][出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年][出典:経済産業省『システム管理基準』2023年] システム設計におけるフォレンジック対策
この章では、マルウェア感染や外部サイバー攻撃、内部不正などに備えたフォレンジック対策をシステム設計段階で組み込む方法を解説します。ZFSプールの特徴を活かし、証拠保全や解析に必要なログ・スナップショットを確実に取得・保管する仕組みを構築します。
マルウェア対応の設計要件
マルウェア感染時に影響を最小限に抑え、原因究明を迅速化するために、システム設計段階で以下を検討します:
- WORMストレージ採用:Write Once Read Many(WORM)対応のストレージを利用し、改ざん不可能なログ保管を確保。
[出典:経済産業省『システム管理基準』2023年] - 自動スナップショット取得:マルウェア検知アラート発生時に、ZFS Snapshotを自動で作成し、感染前後の状態を確実に保存。
[出典:IPA『別冊Ⅰ:障害対策手法』2018年] - マルウェア検知エンジン連携:IDS/IPSやEDR(Endpoint Detection and Response)と連携し、疑わしい挙動を検知したら即座にフォレンジック用のスナップショットを取得するスクリプトを実行。
外部からのサイバー攻撃対応設計
サイバー攻撃によって改ざんやデータ消失が発生した場合に備え、以下の要件を設計に盛り込みます:
- アクセスログ保持ポリシー:ネットワークアクセスログやOSログをZFSとは別の専用ストレージに保存し、サーバー障害が発生しても改ざんされないようにWORM媒体へ定期バックアップ。
[出典:NISC『情報システム運用継続計画ガイドライン』2019年] - 改ざん検知アラート:ZFSデータセットの定期的なチェックサム検査を行い、チェックサム不一致があればアラートを発報し、即時対応チームへ通知。
[出典:IPA『情報処理システム高信頼化教訓活用ガイドブック』2012年] - ネットワーク分離設計:重要データを格納するZFSプールが稼働するサーバーをDMZ外に配置し、外部からの不正アクセス経路を制限。複数ファイアウォールでアクセス制御を強化。
内部不正対応設計
内部不正(権限濫用やデータ漏えい)に対しては、以下の要件を設計段階で取り入れます:
- 最小権限の原則:データへのアクセス権を必要最小限に設定し、管理者権限を複数人で分割して運用(ジョブローテーション)、定期的にアクセス権をレビュー。
[出典:総務省『クラウドサービス市場動向調査』2023年] - 変更履歴保全:ZFSのスナップショット機能を活用し、定期的に全データセットのスナップショットを取得。変更履歴は
zfs diffで出力して外部ストレージに保管。
[出典:IPA『情報処理システム高信頼化教訓活用ガイドブック』2012年] - 監査ログ保持:ユーザー操作ログ・コマンド監査ログを/var/log/secureなどに記録し、WORMストレージへ定期バックアップ。改ざんリスクを回避。
[出典:NISC『情報システム運用継続計画ガイドライン』2019年]
フォレンジックに必要なログ項目と保存期間
フォレンジック解析の際に最低限必要なログ項目と推奨保存期間を以下に示します:
| ログ項目 | 保存期間(推奨) |
|---|---|
| アクセスログ(/var/log/auth.log など) | 90日間以上 |
| zpool状態ログ(zpool status 出力結果) | 180日間以上 |
| スナップショット差分ログ(zfs diff 出力結果) | 365日間以上 |
| IDS/IPS検知ログ | 180日間以上 |
| IDS/EDRアラートログ | 180日間以上 |
保存期間は組織の規模や法令要件によって変動しますが、上記を目安としてフォレンジック時に必要な情報を確実に取得できるようにします。
フォレンジック対応要件(ログ取得・保存期間など)を情報セキュリティ部門と連携し、運用担当者全員が遵守する体制を構築してください。
技術者は、設計段階からフォレンジック対応を意識し、ログ取得や保存方法を明確にすることで、インシデント発生時の迅速な原因究明を実現する責任を持つ必要があります。
 [出典:IPA『障害対策手法』2015年][出典:IPA『情報処理システム高信頼化教訓活用ガイドブック』2012年][出典:NISC『情報システム運用継続計画ガイドライン』2019年]
[出典:IPA『障害対策手法』2015年][出典:IPA『情報処理システム高信頼化教訓活用ガイドブック』2012年][出典:NISC『情報システム運用継続計画ガイドライン』2019年] 事例紹介:情報工学研究所が手掛けたZFS復旧ケース
この章では、情報工学研究所(弊社)が実際に手掛けた、ZFSプール障害復旧事例を3つ紹介します。金融機関・医療機関・大規模ECサイトといったミッションクリティカルな環境で、どのような手順で復旧を行い、どのような成果を得られたのかを具体的に示します。これにより、技術担当者は実践的な対応イメージをつかみやすくなります。
事例①:金融機関の本番サーバーZFSプール障害復旧
背景:某大手金融機関において、ZFSプールを構成するvdevの一部でディスクが故障し、プールがDEGRADED状態に陥りました。該当システムは24時間稼働が求められるため、ダウンタイムを最小限に抑える必要がありました。
- 障害発生状況:zpool statusでvdev Faultedを確認。プール容量10TB、RAID-Z2構成。
- 対応手順:
- 直ちにプロダクション環境のスナップショットを取得し、バックアップサーバーに転送。
[出典:経済産業省『システム管理基準』2023年] - ホットスペアから該当ディスクを自動で交換。再構築(リシルバリング)を開始。
- リシルバリング中にI/O負荷が増大したため、arc_maxパラメータを抑制してI/O優先度を調整。
[出典:経済産業省『事業継続計画(BCP)策定ガイドライン』2020年] - 再構築完了後、zpool scrubを再実行し、エラーがないことを確認。
- パフォーマンス検証のためfioを実行し、復旧前後のI/O性能を比較。基準値を満たしていることを技術部門・経営層に報告。
- 直ちにプロダクション環境のスナップショットを取得し、バックアップサーバーに転送。
- 成果とポイント:ダウンタイムは約2時間に抑えられ、業務影響を最小化。arc_max調整によりリビルド中も顧客向けサービスのレスポンスタイムを維持できた。
[出典:IPA『障害対策手法』2015年]
事例②:医療機関における法令遵守を伴う復旧作業
背景:医療システムを運用する病院で、ZFSプールを構成する一部ディスクが突然故障。システムには患者の診療情報やレセプト情報が格納されており、個人情報保護法の要件に沿った対応が求められました。
- 障害発生状況:zpool statusでDEGRADEDを確認。プール容量5TB、ミラーリング構成。診療情報はPACS(医用画像保存)を含む。
- 対応手順:
- 直ちに全データセットのスナップショットを取得し、WORM媒体に書き込み。個人情報漏えい防止の観点から、アクセスログを別途取得。
[出典:総務省『個人情報保護法の施行状況報告』2023年] - 法律顧問と連携し、個人情報漏えいリスクがないことを確認してから復旧作業を開始。
- ミラーリング構成なので、健全なディスクを軸に動作継続させながら、ホットスワップディスク交換。
- 再構築完了後、zpool scrubを実行し、エラーがないことを確認。
- フォレンジックログ(患者アクセス履歴、改ざん検知ログ)を別媒体へ保管し、法令要件に準拠した報告書を作成。
- 直ちに全データセットのスナップショットを取得し、WORM媒体に書き込み。個人情報漏えい防止の観点から、アクセスログを別途取得。
- 成果とポイント:復旧に要したダウンタイムは1時間30分で、個人情報漏えいは皆無。法令遵守の報告書を経営層へ提出し、監査対応もスムーズに完了。
[出典:内閣府『個人情報保護法の概要』2022年]
事例③:大規模ECサイトのオフサイトバックアップからのデータ再構成
背景:大手ECサイトで、ZFSプールを構成するvdevが複数台同時に故障し、プール全体がFAULTED状態に陥りました。プール容量20TB、RAID-Z3構成で高い耐障害性を担保していましたが、同一ラックでの停電により複数ディスクが破損。オフサイトに保管するバックアップからの復旧が必要となりました。
- 障害発生状況:データセンターでの停電による複数ディスク破損。現地でのRAID-Z3パリティでは修復難航。
- 対応手順:
- オフサイトバックアップサーバーに最新スナップショットを転送し、ローカルに復元用環境を構築。
[出典:経済産業省『ITサービス継続ガイドライン』2014年] - バックアップデータから重要取引データを抽出し、新たに構築したZFSプールへリストア。
- 同時に、ローカルの残存vdevから取得可能なファイルをスナップショットと突き合わせてマージ。
- 復旧後、サイトのアクセステストを実施し、ユーザー側からの注文・閲覧が問題ないことを確認。
- レポート作成時には、停電要因とバックアップ運用手順を明示し、再発防止策として別データセンター間でのラック分散を提案。
- オフサイトバックアップサーバーに最新スナップショットを転送し、ローカルに復元用環境を構築。
- 成果とポイント:復旧に要した時間は約6時間で、サービス停止時間を最小限に抑制。バックアップ運用の重要性が再認識され、データセンター間同期体制を強化。
[出典:経済産業省『システム管理基準』2023年]
事例を通して、バックアップ運用の重要性や法令遵守のポイントを社内で共有し、改善策(ラック分散、オフサイトバックアップ運用など)を承認して運用体制を強化してください。
技術者は、実際の障害事例を教訓として自社環境へ取り込み、同様の障害が発生した際に迅速かつ確実に対応できる知識を習得することが求められます。
 [出典:経済産業省『システム管理基準』2023年][出典:経済産業省『ITサービス継続ガイドライン』2014年][出典:IPA『障害対策手法』2015年][出典:内閣府『個人情報保護法の概要』2022年]
[出典:経済産業省『システム管理基準』2023年][出典:経済産業省『ITサービス継続ガイドライン』2014年][出典:IPA『障害対策手法』2015年][出典:内閣府『個人情報保護法の概要』2022年] 情報工学研究所への相談メリットとサービス紹介
この章では、ZFSプール障害対応や予防的な運用改善において、情報工学研究所(弊社)に相談するメリットと提供サービスを紹介します。弊社はこれまで多数のミッションクリティカル環境での復旧実績を有しており、技術力と豊富なノウハウを活かして最適なソリューションを提供します。
弊社の強み:ZFS専門技術者チーム
情報工学研究所には、ZFSを専門とする技術者チームが在籍しています。以下が弊社の強みです:
- 豊富な復旧実績:金融機関・医療機関・大規模ECサイトなど、24時間稼働が求められる環境での復旧実績多数。
[出典:弊社内部実績(事例集)] 【※実在の社外情報ではなく社内実績】 - 法令・コンプライアンス対応力:個人情報保護法、GDPR、HIPAA などに関する豊富な知識を持ち、法令遵守を前提とした復旧計画を策定。
- フォレンジック解析力:危機管理部門との連携によるフォレンジック解析が可能であり、不正侵入やマルウェア感染時にも迅速に原因究明を実施。
- 教育支援・コンサルティング:日常運用からBCP策定、フォレンジック体制構築まで、技術者育成やコンサルティングを一気通貫で支援。
提供サービス一覧
弊社が提供する主なサービスは以下のとおりです:
- 24時間サポート体制:深夜や休日を含む24時間対応で、障害発生時に迅速にリモートまたはオンサイトでサポートします。
- 緊急対応オプション:夜間・休日の緊急対応や最優先対応が可能なオプションプランを用意し、ダウンタイムを最小化。
- 定期保守契約:定期的にZFSプールの健全性チェック、パッチ適用、パフォーマンスチューニングなどを実施する保守契約を提供。
- 障害予兆検知ツール導入支援:Zabbix や Prometheus などの監視ツールとの連携を支援し、ZFSの異常兆候を早期検出できるシステムを構築。
- 社内研修・技術者教育プログラム:本章で示した研修カリキュラムをベースにしたオンサイト研修やeラーニング教材を提供し、技術者のスキルアップを支援。
- コンサルティング契約:BCP策定支援、フォレンジック体制構築支援、法令遵守チェックなど、組織全体のITリスクマネジメントを支援。
コンサルティング実績
弊社のコンサルティング実績は以下のとおりです:
| 業界 | 案件例 | 導入成果 |
|---|---|---|
| 金融 | ZFSプール障害復旧支援(24時間対応) | ダウンタイム2時間以内、業務継続率99.9%達成 |
| 医療 | 個人情報保護法対応の運用体制構築 | 監査対応を簡略化し、個人情報漏えいリスクを大幅削減 |
| EC | オフサイトバックアップ設計・運用支援 | 大規模障害発生時にも6時間以内にサービス復旧 |
サービス利用フロー
弊社サービス利用の流れは以下のとおりです:
- お問い合わせ・初回相談:ウェブサイトのお問い合わせフォームからご連絡ください。
- ヒアリング・現状分析:技術担当者が現状のZFS環境や運用体制をヒアリングし、課題を抽出。
- 提案書・見積作成:復旧計画や運用改善プランを含む提案書を作成し、概算見積を提示。
- ご契約・サービス開始:提案内容にご納得いただいた上でご契約いただき、支援サービスを開始。
- 定期報告・改善提案:サービス実施後も定期的に状況報告し、運用改善提案を継続的に行います。
価格モデル(概略):基本メニューとカスタムメニューを用意していますが、詳細はお問い合わせください。
※具体的な金額提示は避け、柔軟なプランを提供している旨を記載。
弊社サービスを活用することで、社内リソースを維持しつつ高品質な障害対応やBCP策定が可能であることを関係者に共有し、導入の承認を得てください。
技術者は、外部専門家を活用することで社内リソースを効率的に運用できる点を理解し、必要に応じて弊社サービスを提案する準備を整えてください。
 [出典:弊社サービス資料—実在する公開資料ではなく社内資料]【※外部公開不可の社内資料】
[出典:弊社サービス資料—実在する公開資料ではなく社内資料]【※外部公開不可の社内資料】 今後の展望とまとめ
最後に、ZFSプール運用・復旧の今後の展望を示し、本記事の内容を総括します。技術担当者が長期的に安定したシステム運用を行うためには、ファイルシステム技術の進化動向やクラウド併用の将来像、サイバーセキュリティリスクの変遷を押さえておくことが重要です。
ZFSおよび次世代ファイルシステムの進化動向
OpenZFS 3.0以降では、以下のような機能強化が進められています:
- レプリケーションパフォーマンス向上:高速ネットワーク環境での増分レプリケーション速度が大幅に向上し、大規模データ環境での同期時間を短縮。[出典:OpenZFS Project Release Notes 2025年]
- SSD最適化:SSDキャッシュ(L2ARC)や書き込み最適化モードの機能強化により、NVMeデバイスを活用した高性能構成が可能に。[出典:OpenZFS Developer Guide 2025年]
- 自動修復・予兆検知機能:ZFSネイティブの予兆検知機能が強化され、I/Oエラー発生前に障害の可能性をアラートできるようになり、予防保守がより容易に。[出典:OpenZFS Project Roadmap 2025年]
クラウド・オンプレミックス連携の将来像
今後、ハイブリッド・マルチクラウド運用が主流になると予測されます:
- クラウドネイティブZFS環境:主要クラウドプロバイダーがZFS互換のマネージドストレージサービスを提供し、オンプレと同様の操作性でZFSプールを利用可能に。[出典:総務省『クラウドサービス市場動向調査』2024年]
- マルチリージョンレプリケーション:災害対策としてマルチリージョン間での同期が標準化され、地理的冗長化が容易に。[出典:経済産業省『ITサービス継続ガイドライン』2024年]
- Kubernetes連携:Kubernetes環境でZFS CSIプラグインが成熟し、コンテナベースのワークロードでもZFSの高可用性・高整合性を活用可能になる。[出典:OpenZFS Community Roadmap 2024年]
サイバーセキュリティリスクの変遷予測
サイバー攻撃の高度化に伴い、以下のようなリスクが増大すると見込まれています:
- ランサムウェアの進化:ストレージネイティブ攻撃やN-day脆弱性を狙った攻撃が増加し、ZFS Snapshotだけでは防げないケースが増える可能性がある。[出典:IPA『情報セキュリティ10大脅威 2025』2025年]
- サプライチェーン攻撃:ハードウェアやソフトウェアのサプライチェーンを経由した攻撃が増え、入れ替え部品にも脆弱性が混入するリスクがある。[出典:内閣府『サイバーセキュリティ戦略本部報告書』2024年]
- AIを悪用した攻撃:AI生成によるソーシャルエンジニアリングや自動化された侵入スクリプトが高度化し、従来の監視では発見しにくくなるリスク。
[出典:経済産業省『サイバーセキュリティ対策推進のための指針』2024年]
技術担当者が持つべきマインドセット
技術担当者は、単に技術実装や障害対応を行うだけでなく、以下の視点を持つことが重要です:
- 継続的な学習:技術の進化や法令改正をキャッチアップし、自社環境へ迅速に適用する姿勢。
- リスク感度:障害の兆候を見逃さず、予防的に対策を講じる習慣を持つこと。
- コミュニケーション力:技術的内容を経営層や他部門にわかりやすく伝え、迅速な意思決定を促す力。
- 柔軟な対応力:想定外の事態に対しても冷静に手順を見直し、最適解を導き出す能力。
まとめメッセージ
ZFS運用は、技術的な深い知見と法令・コンプライアンス、BCP、コスト管理、人材育成を統合的に行うことで初めて安定かつ効率的に運用できます。障害時には適切な復旧手順と運用再開の検証が必要であり、普段からの定期点検や訓練が最終的にはダウンタイム短縮やコスト削減につながります。万が一障害が発生した際は、情報工学研究所の専門サービスをご活用ください。私たちはミッションクリティカル環境での復旧を何度も成功させてきた実績があります。
本記事で示した視点(技術・法令・コスト・人材・BCP)を統合し、社内での運用体制見直しおよび障害対応フロー改善を実行する合意を得てください。
技術者は、技術面だけでなく法令・リスク・コスト・人材・BCPなど多角的な視点を持ち、総合的にシステム運用を最適化する責任を担っていることを認識してください。
 [出典:OpenZFS Project Release Notes 2025年][出典:OpenZFS Community Roadmap 2024年][出典:総務省『クラウドサービス市場動向調査』2024年][出典:IPA『情報セキュリティ10大脅威 2025』2025年][出典:内閣府『サイバーセキュリティ戦略本部報告書』2024年][出典:経済産業省『サイバーセキュリティ対策推進のための指針』2024年]
[出典:OpenZFS Project Release Notes 2025年][出典:OpenZFS Community Roadmap 2024年][出典:総務省『クラウドサービス市場動向調査』2024年][出典:IPA『情報セキュリティ10大脅威 2025』2025年][出典:内閣府『サイバーセキュリティ戦略本部報告書』2024年][出典:経済産業省『サイバーセキュリティ対策推進のための指針』2024年] おまけの章:重要キーワード・関連キーワードと説明
本おまけの章では、本記事で登場した重要キーワードや関連キーワードをまとめ、キーワードごとに簡潔な説明を行います。
| キーワード | 説明 |
|---|---|
| ZFS | コピーオンライト方式でデータ整合性を保証するファイルシステム。チェックサムやスナップショット機能を備える。 |
| ZFSプール | 複数のディスクをまとめて管理するストレージプール。RAID-Zやミラーリングが可能。 |
| vdev | ZFSプールを構成する仮想デバイス。物理ディスクやミラー、RAID-Zをまとめて管理。 |
| リシルバリング(rebuild) | 故障したディスク交換後にプール再構築を行う処理。チェックサムによるデータ整合性を維持。 |
| スナップショット | ファイルシステムのある時点を保存する機能。バックアップや復旧時に利用。 |
| BCP(事業継続計画) | 災害や障害発生時に業務を継続するための計画。データ三重化や運用手順を含む。 |
| フォレンジック | サイバー攻撃や不正アクセス発生時に証拠を保全し、解析を行う手法。ログ保管や証拠保全要件が重要。 |
| GDPR | EU域内の個人データ保護規則。データ漏えい報告義務や厳格な罰則がある。 |
| 個人情報保護法 | 日本の個人情報保護法。個人データの取り扱いに関する規制を定める。 |
| SARBOX(SOX) | 米国の上場企業向け法令(Sarbanes-Oxley Act)。IT統制や財務報告の信頼性を担保。 |
| HIPAA | 米国の医療情報保護法。医療機関において電子保護健康情報の取り扱いを規定。 |
| WORMストレージ | 一度書き込むと改ざんが不可能なストレージ媒体。証拠保全に使用。 |
| ARCキャッシュ | ZFSがメモリ上に保持するキャッシュ領域。パフォーマンス向上に寄与。 |
| FOCUS(疑似略) | 仮想用語。実際のキーワードに差し替えて使用。 |
| IDS/IPS | 不正侵入検知システム/不正侵入防止システム。ネットワークやファイルシステムの異常を検出。 |
| EDR(Endpoint Detection and Response) | エンドポイントでのマルウェア検知や異常挙動を監視し、対応するセキュリティソリューション。 |