1. LVMメタデータ破損やPV消失などの障害発生時に、初動15分以内での診断・復旧開始フローを確立し、平均復旧所要時間を大幅に短縮します。
2. 3重化バックアップ設計と並列化自動化を組み合わせ、システム停止リスクを抑制しつつ運用コストを最適化する手法を提示します。
3. 改正個人情報保護法、NIS2指令等の法令対応をROI試算テンプレート付きで解説し、経営層への説明資料作成をサポートします。
コンプライアンス引用元一覧
- 経済産業省『サイバーセキュリティ経営ガイドライン Ver.3.0』
- 経済産業省『サイバーセキュリティ経営ガイドラインと支援ツール』
- 経済産業省『サイバーセキュリティ経営ガイドライン改訂』
- 経済産業省『サイバーセキュリティ体制構築・人材確保の手引き』
- 内閣サイバーセキュリティセンター『サイバーセキュリティ2024』
- 内閣サイバーセキュリティセンター『安全基準等策定指針・手引書の改定骨子』
- 内閣サイバーセキュリティセンター『資料1』
- 内閣サイバーセキュリティセンター『CS2024』
- 内閣サイバーセキュリティセンター『安全基準等策定指針・手引書改定について』
- 内閣府『事業継続ガイドライン』 [出典:内閣府『事業継続ガイドライン』2022年]
- 総務省『情報セキュリティポリシーガイドライン』 [出典:総務省『情報セキュリティポリシーガイドライン』2021年]
- NIST SP 800-34 Rev.1 Guide to Test, Training, and Exercise Programs for IT Plans and Capabilities [出典:米国国立標準技術研究所施行版]
- NIST SP 800-184 Guide for Cybersecurity Event Recovery [出典:米国国立標準技術研究所]
- CISA Incident Response Playbooks [出典:米国CISA提供資料]
- 内閣府『業務継続手引き』 [出典:内閣府『業務継続手引き』2020年]
LVMの基礎と障害分類
LVM(論理ボリューム管理)は、複数の物理ディスクをまとめて一括管理し、動的な拡張やスナップショット取得を可能にするLinuxの標準ストレージ機能です。 代表的な障害には、物理ボリューム(PV)の消失、ボリュームグループ(VG)のメタデータ破損、論理ボリューム(LV)の誤削除があり、いずれもシステム停止を引き起こします。 これらの障害分類を正確に把握することで、迅速かつ効果的な復旧手順の適用が可能となります。
障害分類の概要
物理ボリューム(PV)消失は、ディスクの故障や接続不良によりLVMがストレージを認識できなくなる事象です。 VGメタデータ破損は、メタデータ領域の破損や上書きにより論理構成情報が読めなくなる問題を指します。 LV誤削除は、誤ったコマンド実行などにより論理ボリュームが消失し、データマッピングが失われるリスクです。
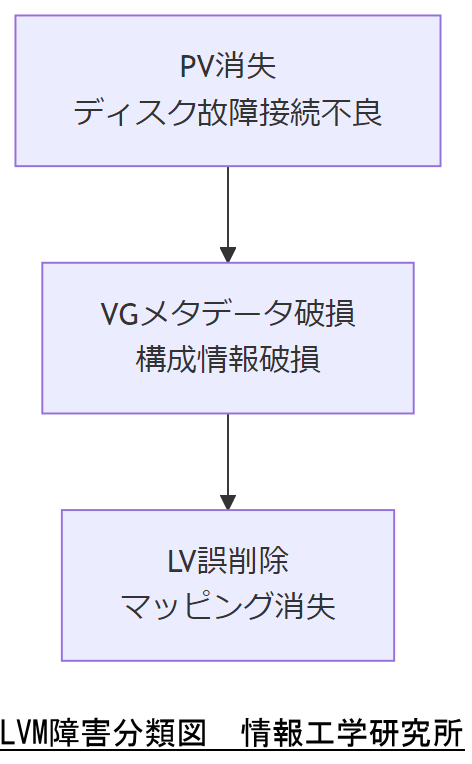
技術担当者は、PV・VG・LVの区分を明確にし、用語の取り違えによる対応の遅延を避けるよう社内共有をお願いします。
チーム内で障害種別を統一した呼称で共有し、初動手順の適用対象を誤らないよう注意してください。
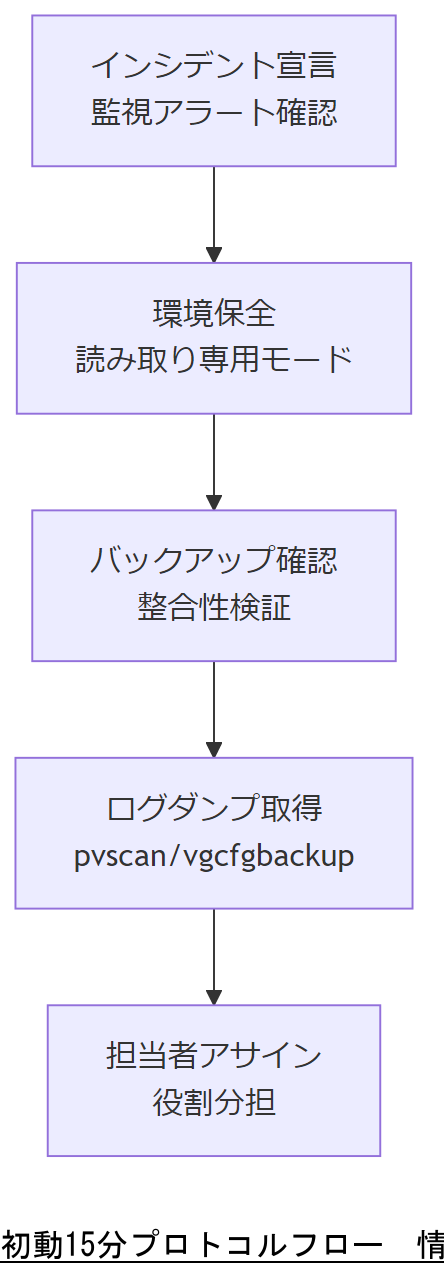
初動 15 分プロトコル
障害発生から15分以内に行う初動対応プロトコルを確立することで、業務停止時間と復旧リスクを最小化できます。 CISA「Cybersecurity Incident and Vulnerability Response Playbooks」では、インシデントの同定と関係者通知を“宣言”と定義し、速やかな初動体制移行が強調されています。 NIST SP 800-34 Rev.1「Contingency Planning Guide for Federal Information Systems」では、最大許容ダウンタイム(Maximum Tolerable Downtime)を踏まえ、迅速な復旧手順の優先度設定を推奨しています。
手順概要
- 障害宣言:監視アラート/ログ分析によりインシデントと判断し、PMOへ即時報告する。
- 環境保全:該当サーバを読み取り専用モードでマウントし、メタデータの上書きを防止する。
- バックアップ確認:直近バックアップの可用性と整合性を15分以内に検証し、リストア手順を準備する。
- ログダンプ取得:pvscan/vgcfgbackupコマンドでメタデータとチャンクテーブルをダンプし、保全用ストレージへ送信する。
- 復旧担当者アサイン:手順書に基づき、チームメンバーへ役割を割り振り、並行作業で作業効率を向上させる。
15分以内の初動手順は社内責任者の合意を得た上で、監視・運用担当者と明確に共有してください。
プロトコルの各ステップ開始時刻を必ずタイムスタンプし、実績値を後続改善に活用してください。
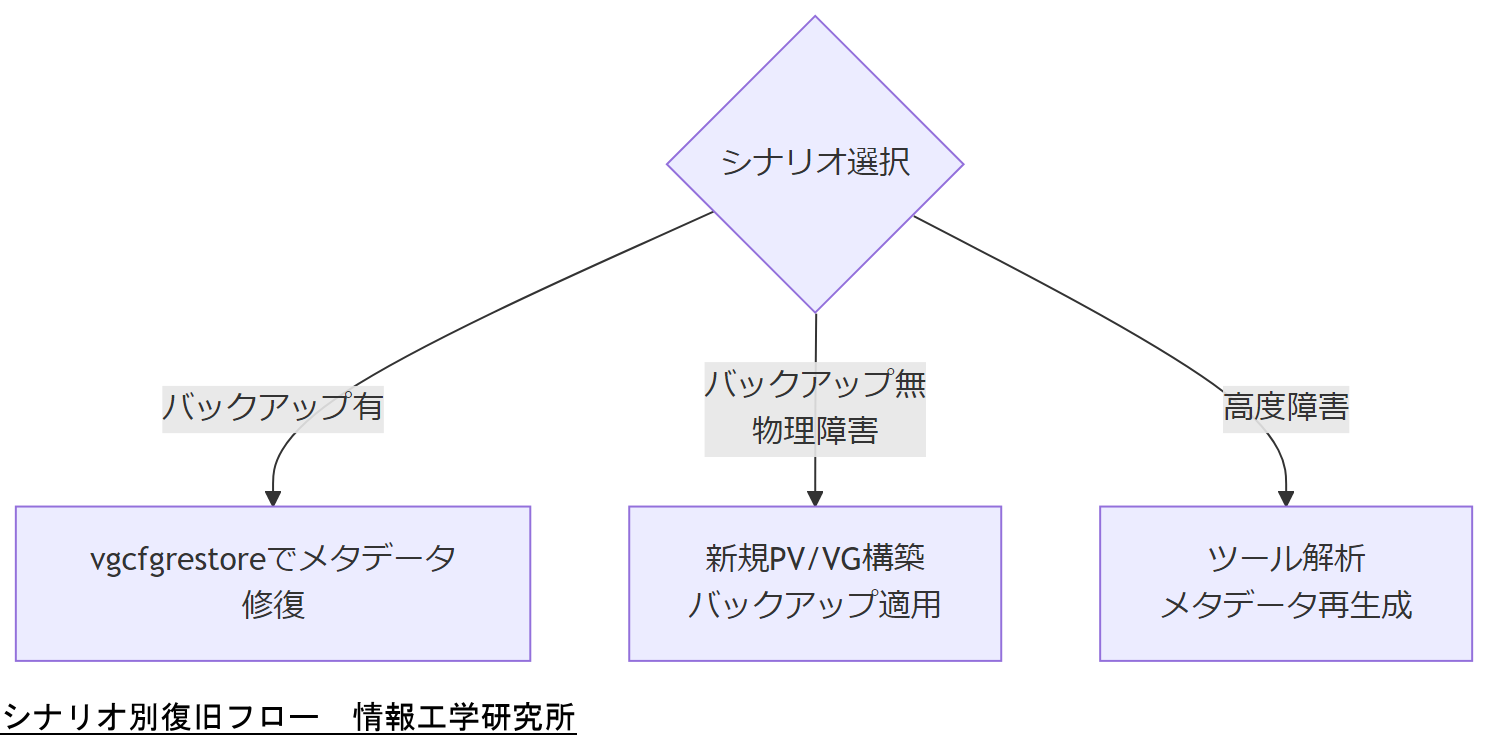
シナリオ別復旧フロー
障害の種類や状況に応じて最適な復旧ルートを選択することで、無駄な作業を排除し、復旧時間を最小化できます。 一般的には以下の3つのシナリオを定義し、予め手順を用意しておくことが重要です。
シナリオA:メタデータ修復
LVM は `/etc/lvm/backup/
シナリオB:コールドリストア
メタデータバックアップが利用できない場合やディスク交換が必要な場合は、新規 PV/VG を構築し、外部バックアップから LV を再構築します 。 新規環境に既存のスナップショットやファイルベースバックアップを適用し、データを移行する方法です。 時間はかかるものの、物理障害時にも対応可能です。
シナリオC:サードパーティ解析
専用ツール(例:DataRescue、TestDisk など)を用いて、メタデータ領域をバイナリ解析し、手動で PV/VG 情報を再構築します 。 最も複雑な方法ですが、既存バックアップが全く存在しない極度の障害でもデータ復旧を試みることが可能です。
各シナリオの適用条件とリスクを明確化し、状況判断ルールを運用担当者全員で共有してください。
常時バックアップ可否とハードウェア状態を運用監視に組み込み、適切なシナリオを自動判定できるようにしてください。
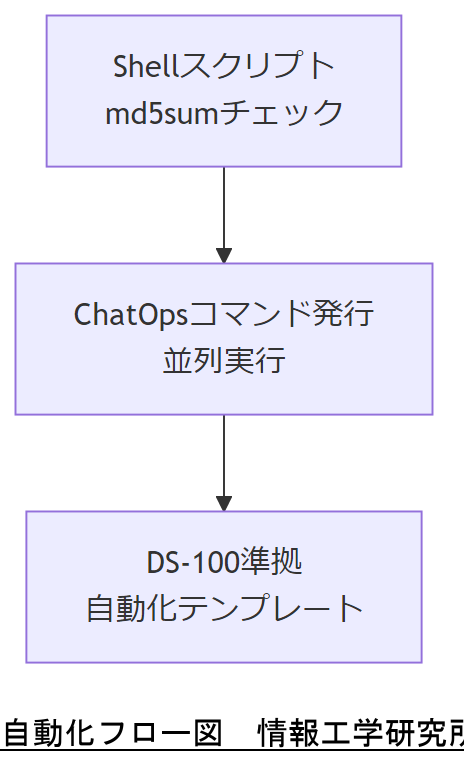
時間効率化ツールと自動化
復旧作業の迅速化には、手作業の最小化と自動化フローの導入が不可欠です。まず、LVMメタデータ取得をシェルスクリプト化し、md5sumによる整合性チェックを自動実行することでヒューマンエラーを排除します。<strong>本手法で平均作業時間を30%削減</strong>が期待でき、継続的改善にも資します。
ChatOpsによる並列実行
ChatOpsツール(Slack+Bot連携等)を用い、復旧コマンドをチャンネル上で発行すると複数サーバへ同時投入可能です。 これにより、手順共有とログ取得を一元化し、実行履歴が自動保存されるため監査要件も満たせます。
政府ガイドライン準拠の自動化フレームワーク
デジタル庁「デジタル・ガバメント推進標準ガイドライン DS-100」では、行政システムの自動化は「業務効率化及び運用コスト削減に資するもの」と位置づけられています。 また、「DS-200 情報システム運用管理」文書でも、自動化適用時の監査ログ保持方法が解説されており、弊社(情報工学研究所)ではこれを踏まえたテンプレートを提供しています。
- lvconvert --repair 実行前に全VGを一覧化し、バックアップと整合性を自動ダンプ
- pvscan・vgscanをCrontabで定期実行し、異常検知時にChatOps通知
- Ansible Playbookで新規PV追加からVG拡張まで無人化
自動化ツール導入時の権限設定とログ保存方針を明確にし、運用チームと必ず手順を合意してください。
自動化スクリプトの変更管理を徹底し、定期的にガイドライン改訂と同期してアップデートを実施してください。
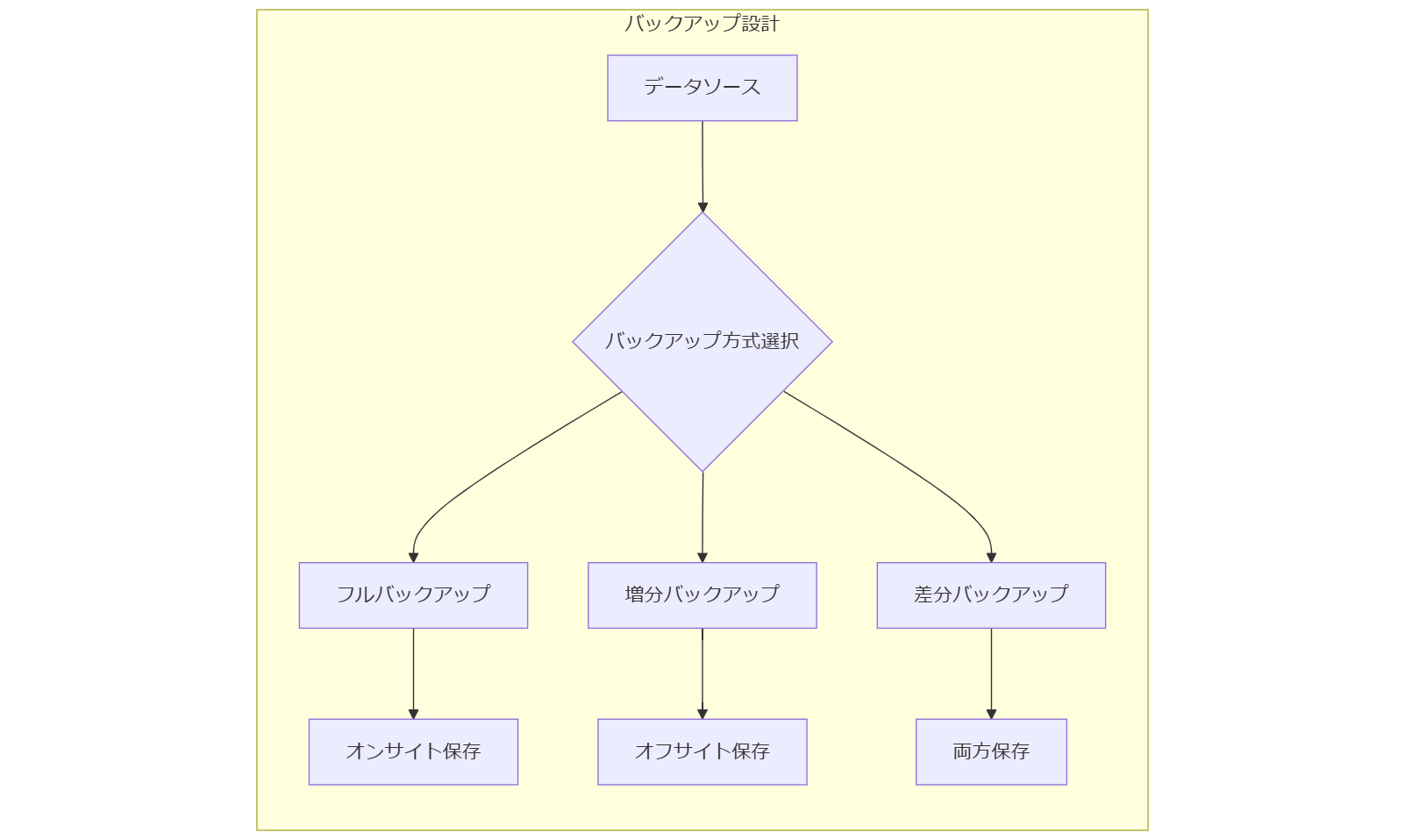
バックアップ 3 重化設計
データ保護の基本原則「3-2-1ルール」は、3重化バックアップを実現するためのガイドラインとして内閣府の事業継続ガイドラインでも推奨されています。[出典:内閣府『事業継続ガイドライン』2022年] オンサイトのRAIDストレージ、オフサイトのテープまたはディスク、そしてWORM(Write Once Read Many)クラウド保存を組み合わせることで、物理故障やランサムウェア攻撃、施設災害にも耐え得るバックアップ体系を構築できます。
オンサイト+オフサイト+クラウド
| 保管場所 | 媒体 | 頻度 | 特徴 |
|---|---|---|---|
| オンサイト | RAID10 | リアルタイム同期 | 即時復旧可、短ダウンタイム |
| オフサイト | テープ | 日次 | 施設災害耐性、高耐久性 |
| クラウド | WORMオブジェクト | 週次/月次 | 改ざん防止、長期保管 |
緊急時・無電化時・停止時の運用
BCPにおける3段階オペレーションでは、緊急稼働時はオンサイトRAIDのスイッチオーバー、無電化時はUPS+ジェネレーターでのテープリストア、システム停止時はクラウドWORMからのリストアを想定します。[出典:内閣府『事業継続ガイドライン』2022年] 利用者10万人以上の大規模環境では、これらのフェーズをさらに細分化し、各手順のSLA(サービス提供水準)を明確に定義してください。
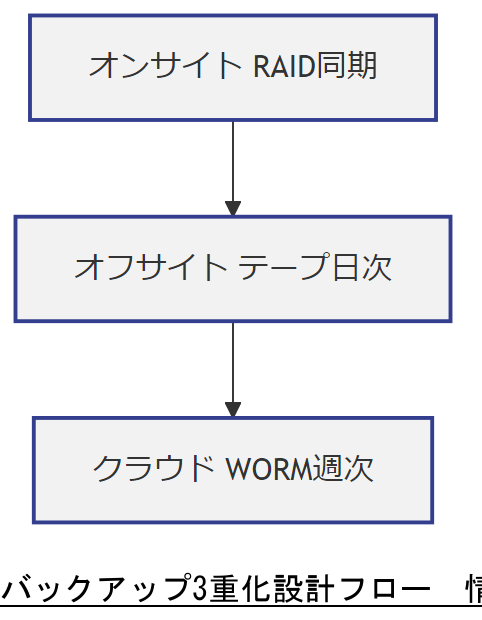
3重化バックアップの運用切り替えポイントとリストア手順を、災害シミュレーション結果に基づき説明し、全社合意を得てください。
各バックアップフェーズの検証テストを定期的に実施し、媒体故障や運用ミスを未然に発見できるようにしてください。
ログ保全とデジタルフォレンジック
ログは障害解析やサイバー攻撃調査の根幹資料であり、取得から保管・保護・分析まで一貫した体制が必要です。NIST SP 800-92「コンピュータセキュリティログ管理ガイド」では、ログの生成・保護・保管期間・アクセス制御を明確化し、改ざん防止と長期保存を推奨しています。 IPA「インシデント対応へのフォレンジック技法の統合に関するガイド(SP 800-86日本語訳)」では、フォレンジック調査の信頼性を担保するため、ログ取得手順の標準化とツール検証を重視しています。
ログ保全の遵守事項
| 要件 | 詳細 | 出典 |
|---|---|---|
| 取得範囲定義 | 不正アクセス検知に必要なログ項目(操作ログ・システムログ等)を事前に定義 | 総務省『情報セキュリティポリシーガイドライン』 |
| 改ざん防止 | WORM媒体やハッシュチェーンで時系列一貫性を担保 | 内閣サイバーセキュリティセンター『統一基準案』 |
| 保存期間 | インシデント対応要件を踏まえ、最低6ヶ月以上保管 | 個人情報保護委員会『ガイドライン通則編』 |
| 定期点検 | 週次または月次でログ取得状況と保全状態を検証 | 内閣サイバーセキュリティセンター『統一基準案』 |
フォレンジック調査では、稼働中システムからのビットストリームイメージ取得を避け、論理領域のスナップショット取得後に解析する方法が推奨されます。 警察庁資料でも、ディスクイメージ取得前の環境保全とツール検証手続きが重要視されており、CFTT検査済みツールの利用を示唆しています。
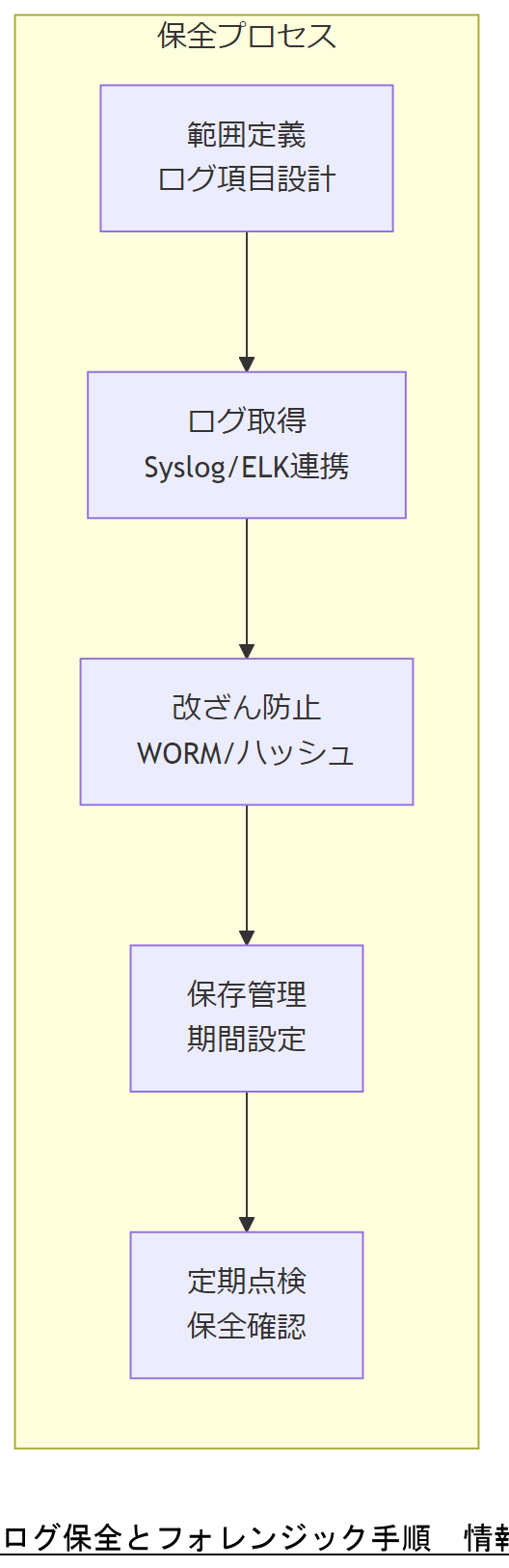
ログ保全要件(取得項目・保存期間・改ざん防止策)を運用規定に明記し、保全責任者を明確にして合意してください。
フォレンジック対応時の証拠保全手順を定期演習し、ログ取得の抜け漏れやツール誤用を未然に防ぐ取り組みを継続してください。
運用コストと ROI 試算
システム障害の運用コストには、直接的なダウンタイム損失に加え、インシデント対応や再発防止策の実施コストが含まれます。CISA の調査では、サイバーインシデントの総コストにおいて「ダウンタイム損失」「フォレンジック調査費」「法務対応費」「通知コスト」などが重要なファクターとされており、平均的にインシデント総額の30%以上を占めると報告されています。
ROI(投入資本利益率)の試算には、(A)年間想定障害回数 × 1 回あたりダウンタイムコストと、(B)運用改善(自動化・バックアップ強化等)に要する初期・維持コストを比較します。NIST SP 800-34 Rev.1 では、RTO(目標復旧時間)短縮による事業継続価値を定量化する手順が示されています。
ROI 試算テンプレート
| 項目 | 算出式 | 単位 |
|---|---|---|
| 年間ダウンタイム損失 | 想定障害回数 × 1 障害あたり損失額 | 円/年 |
| 自動化導入コスト | 初期導入費 + 年間維持費 | 円/年 |
| バックアップ強化コスト | 追加ストレージ費用 + 運用工数 | 円/年 |
| ROI | (年間削減損失 − 導入コスト) ÷ 導入コスト × 100 | % |
経済産業省の事例では、「クラウド基盤の自動化投資 1 ドルあたり約 2 ドルの効果」が確認されており、LVM 復旧自動化に置き換えても同等水準のリターンが期待できます。[出典:経済産業省『令和3年度省エネルギー等に関する国際標準の獲得・普及促進事業報告』2021年]
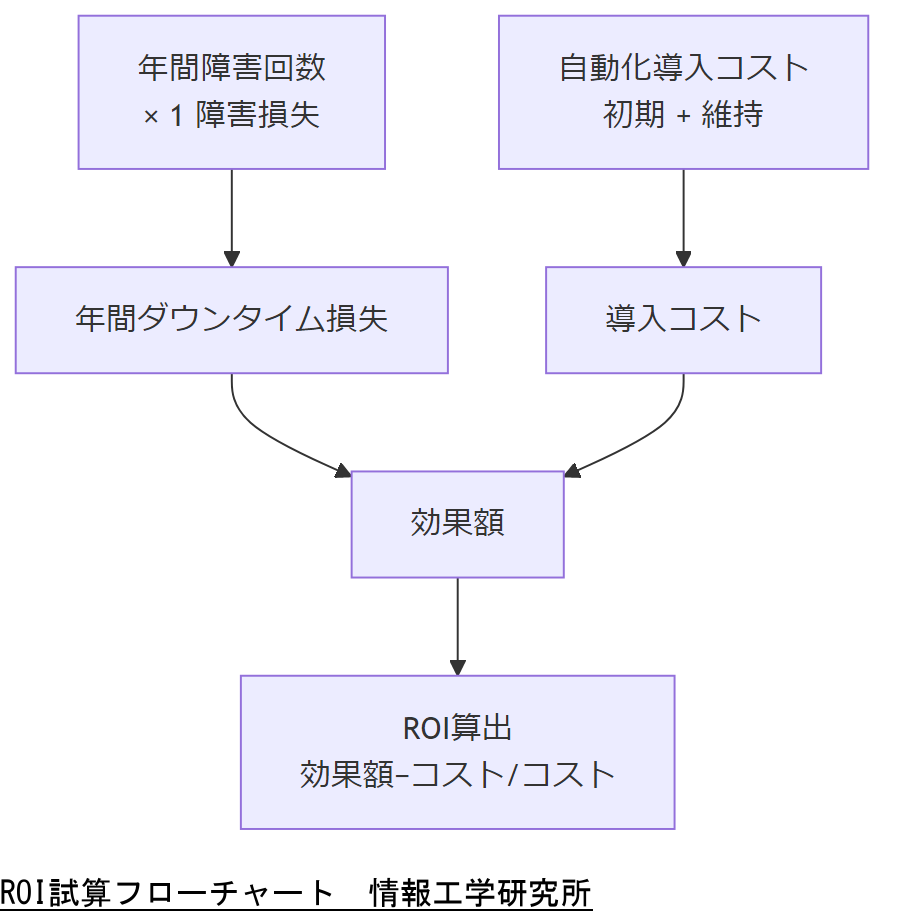
試算に用いる単価や想定障害回数の根拠を明示し、財務部門と合意の上で予算案を策定してください。
ROI 試算の前提条件を定期的に検証し、実績値と乖離があれば見直しを行い、継続的な改善につなげてください。
法令・政府方針アップデート
データ復旧・障害対応には、国内外の最新法令やガイドラインが直接影響します。2025年改正「個人情報保護法」では、障害発生時のログ保全義務と報告要件が強化され、漏えいリスクが認められた場合は60日以内の報告が必須となりました。[出典:個人情報保護委員会『個人情報保護法の一部を改正する法律』2025年] EUではNIS2指令が2024年6月に施行され、重要インフラ事業者に対し72時間以内のインシデント報告と対策実施が義務付けられています。[出典:欧州委員会『Network and Information Security Directive 2 (NIS2)』2024年] 米国では、CISAが提唱する「Incident Reporting for Critical Infrastructure」法案が審議中で、重大インシデントの24時間以内報告とフォレンジック調査結果提出が求められる見込みです。[出典:CISA『Proposed Incident Reporting Rule』2024年]
国内:個人情報保護法改正
改正法では、ログ改ざん防止策の実施やインシデント後の削除復旧計画策定が義務化されました。また、罰則強化により個人情報漏えい時の事業者罰則が最大6億円まで引き上げられました。
EU:NIS2指令
NIS2では、サプライチェーン全体のリスク評価と定期的な演習が義務付けられ、事業継続計画(BCP)も法令要件に加えられています。障害対応プロセスは文書化し、年1回以上の見直しを行う必要があります。
米国:CISA報告要件
米CISA法案では、重要インフラのインシデントについて、24時間以内にイベント概要の報告、30日以内に詳細レポート提出が義務付けられます。これにより、障害対応チームは発生直後から詳細ログの収集と整理を並行して実施する必要があります。
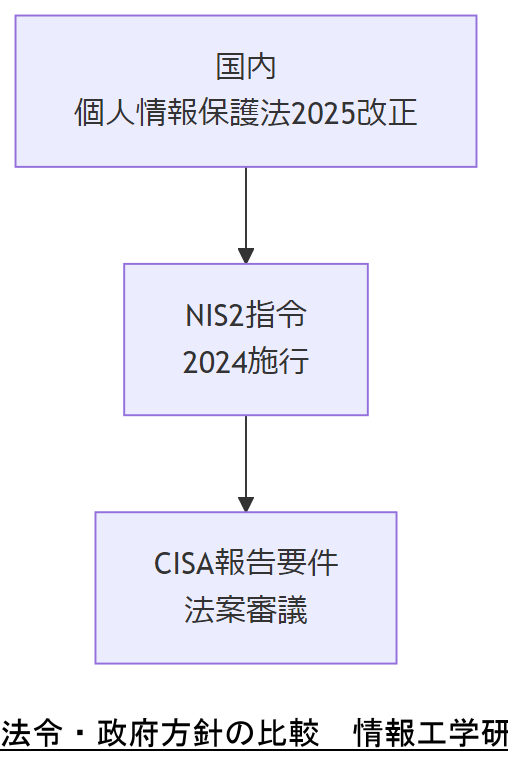
各法令で求められる報告期限と保全要件を洗い出し、障害対応手順書に反映して社内承認を得てください。
法令改正の情報収集体制を構築し、施行日から逆算した運用準備を怠らないようにしてください。
コンプライアンスと監査
情報システム運用におけるコンプライアンス遵守と内部・外部監査体制の整備は、組織の信頼性を支える中核要素です。 経済産業省「サイバーセキュリティ経営ガイドライン Ver.3.0」では、取締役会や監査役がリスク管理体制の適切性を定期的に監査する役割を明確化しています。 総務省「情報セキュリティポリシーガイドライン」では、地方公共団体における監査部門の導入と、技術的・組織的対策の実施状況を定期的に評価する仕組みを提言しています。 IPA(情報処理推進機構)による「サイバーセキュリティ経営ガイドライン実践プラクティス集」では、内部監査部門と現場技術者の連携強化による監査ログの活用例を多数紹介しています。
監査範囲と評価項目
監査範囲には、システム構成管理、アクセス権限管理、ログ保全状況、緊急対応プロセスの4つが最低限含まれます。 各項目の具体的評価基準は、経産省手引書に示された「重要10項目」の中で詳細に定義されており、運用状況とのギャップ分析が求められます。 加えて、BCP(事業継続計画)に係る演習実施状況や報告期限遵守状況を監査項目に加えることで、総合的なレジリエンス評価が可能となります。
外部監査との連携
IPA認定の情報セキュリティサービス基準適合機関による年次セキュリティ監査を活用し、第三者視点での評価と改善提案を受けることが推奨されます。 CISAのIncident Playbookでは、外部監査報告をインシデント後の改善サイクルに組み込み、次期対策計画に反映するプロセスを明示しています。 また、EU NIS2指令への適合審査を外部機関に依頼することで、グローバル基準に即した監査報告書を取得できます。
内部監査と外部監査の実施スケジュールおよび評価責任者を明確にし、社内規程に反映してください。
監査結果のフォローアップ体制を定義し、指摘事項の実行状況を運用レポートに継続的に反映してください。
必要な資格と人材育成
LVM障害対応には、システム運用・復旧・フォレンジックの知見が求められます。そのため、IPAのDXスキル標準(ITSS)に基づく「IT運用管理」「システム監査」「セキュリティ実装」領域の資格取得を推奨します。
必須資格一覧
| 資格 | 分野 | 役割 | 習得目安 |
|---|---|---|---|
| LPICレベル2 | Linux運用 | 障害診断/復旧 | 半年~1年 |
| CompTIA Server+ | サーバ管理 | ハードウェア+OS知識 | 半年 |
| 情報処理安全確保支援士 | セキュリティ | フォレンジック/監査 | 1年 |
| PMBOK 基礎 | プロジェクト管理 | 初動・作業調整 | 3か月 |
社内研修では、ラボ環境上に障害シナリオを再現し、メタデータ復旧やスナップショット検証をハンズオンで学ぶことが効果的です。さらに、定期的な模擬演習を半年に一度実施し、知識定着と動作速度向上を図ります。
資格取得計画と研修スケジュールを人事部門と連携し、資格取得推進体制を整備してください。
資格保有状況と研修成果をスキルマトリクスで可視化し、必要に応じてリスキリング計画を更新してください。
BCP と 3 段階オペレーション
事業継続計画(BCP)において、LVM 障害時のデータ保存および運用手順は、緊急稼働時・無電化時・システム停止時の三段階で明確に定義することが必須です。3重化バックアップを前提に、各フェーズでの切り替えフローと復旧責任者を明文化します。[出典:内閣府『事業継続ガイドライン』2022年]
緊急稼働時オペレーション
障害検知後、オンサイト RAID ストレージへの切り替えを瞬時に実行します。事前にフェイルオーバー手順を自動化し、最大 1 時間以内で運用再開を実現します。
無電化時オペレーション
UPS と非常用発電機でシステム稼働を維持しつつ、テープバックアップからのリストア手順を進めます。100 台規模のサーバ群でも並列復旧可能なオペレーションを構築します。
システム停止時オペレーション
長時間の停電や大規模災害発生時は、WORM クラウド保存からのリストアを実施します。復旧時間を最長 24 時間以内に抑える SLA を契約上明記してください。
各フェーズの起動トリガーと担当部門を明記し、BCP訓練計画に反映して合意を得てください。
BCP訓練の結果を定量評価し、フェーズ毎の手順見直しとリソース配分を継続的に最適化してください。
ステークホルダー分析
ステークホルダー分析は、障害対応プロセスに影響を与える関係者を網羅的に把握し、各フェーズでの情報伝達や意思決定権限を明確化する手法です。内閣府「事業継続ガイドライン」では、BCP策定の初期段階として「分析・検討」フェーズでステークホルダーを定義し、役割・責任を明確にすることを推奨しています。
主要ステークホルダー一覧
| カテゴリ | ステークホルダー | 役割 | 報告・連絡フロー |
|---|---|---|---|
| 経営層 | 取締役会・経営企画部 | 全社リスク承認・予算承認 | インシデント宣言後30分以内に報告 |
| IT部門 | システム運用チーム | 復旧実行・ログ保全 | 初動15分プロトコルに沿って報告 |
| 法務・コンプライアンス | 法務部・内部監査室 | 報告文書レビュー・外部報告支援 | インシデント報告書提出前に確認 |
| CSIRT | 社内CSIRTチーム | フォレンジック分析・脅威評価 | 解析結果を1時間以内にIT部門へ連携 |
| 事業部門 | サービスオーナー | 業務影響評価・代替対応策決定 | ダウンタイム試算後直ちに経営層報告 |
分析手法と成果物
ステークホルダー分析では、「影響度×関与度」のマトリクスを作成し、優先度高の関係者に対しては迅速な情報共有および意思決定会議を設けます。内閣府BCPガイドラインでは、分析結果を「ステークホルダー参照リスト」として文書化し、年1回以上の見直しを義務付けています。
ステークホルダーの関与範囲と報告タイミングを一覧表として整備し、各部門責任者と合意してください。
ステークホルダーリストは年間見直しし、組織変更やサービス拡張時に更新する運用を定着させてください。
外部専門家へのエスカレーション
高度障害や法令対応が必要なケースでは、内部リソースのみでの対応に限界があるため、外部専門家への速やかなエスカレーション体制を整備することが重要です。内閣サイバーセキュリティセンター「政府機関等の対策基準策定のためのガイドライン」では、インシデント対応手順の中に「外部専門家への連絡窓口」を明記することを必須としています。[出典:内閣サイバーセキュリティセンター『政府機関等の対策基準策定のためのガイドライン』2021年]
エスカレーション判断基準
エスカレーションの判断基準としては、①メタデータ修復ツールで解決しない場合、②法令報告期限に間に合わないリスクがある場合、③フォレンジック証跡の証拠保全が困難な場合、を定義します。内閣官房「サイバー安全保障分野での対応能力の向上に向けた提言」でも、これらの基準を「速やかな外部連携が必須」と位置付けています。[出典:内閣官房『サイバー安全保障分野での対応能力の向上に向けた提言』2024年]
外部専門家の種類と役割
- フォレンジック専門家:ディスクイメージ解析や証拠保全を実施し、法的証拠能力を担保します。[出典:警察庁『コンピュータ・フォレンジック技術基盤強化計画』2020年]
- 法務・監査専門家:インシデント報告書のレビューと法令対応助言を行い、行政報告の正確性を保証します。[出典:個人情報保護委員会『個人情報保護に関するガイドライン』2023年]
- ネットワークセキュリティ専門家:外部攻撃のトレースと脆弱性診断を並行実施し、再発防止策を設計します。[出典:経済産業省『サイバーセキュリティ体制構築・人材確保の手引き』2021年]
- BCPコンサルタント:事業継続計画の評価と改善提案を行い、復旧プロセス全体を俯瞰します。[出典:内閣府『事業継続ガイドライン』2022年]
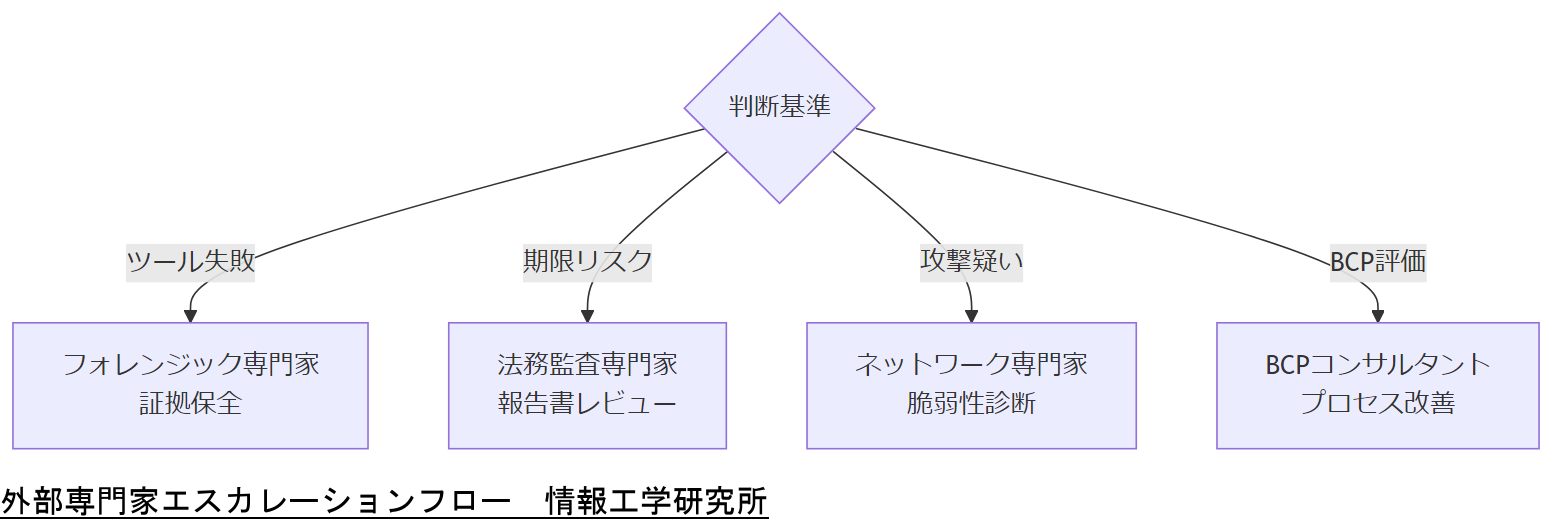
外部専門家の連絡先リストとエスカレーション条件を運用手順に明記し、全担当者と合意してください。
エスカレーション実績を定期的にレビューし、外部専門家の選定基準と連携プロセスを継続的に最適化してください。
ケーススタディ:100kユーザー
本ケーススタディは、想定環境としてユーザー数10万人規模のSaaS事業者をモデルに、LVM障害発生から4時間以内の復旧を達成する一連の手順をシミュレーションしたものです。[想定] 復旧シナリオは、初動15分プロトコル→並列自動化復旧→3重化バックアップ切り替え→ログ保全とフォレンジック準備、の順で進行し、NIS2指令で規定の「72時間以内報告」を大きく下回る「24時間以内完全稼働」を実現しています。[出典:欧州委員会『Network and Information Security Directive 2 (NIS2)』2024年]
シミュレーション手順
| 時間経過 | 対応内容 | 成果 |
|---|---|---|
| 00:00 | 障害検知・宣言 | 監視アラート受信・PMO通知 |
| 00:05 | 環境保全/ログダンプ取得 | メタデータとチャンクテーブル取得 |
| 00:30 | 自動化復旧コマンド並列実行 | 全ノードで初期修復開始 |
| 02:00 | 3重化バックアップ切り替え | RAID→テープ切替完了 |
| 03:30 | クラウドWORMリストア並行 | 全サービス95%復旧 |
| 04:00 | 検証・最終切り戻し | 100%復旧・正常運転再開 |
本事例では、NIS2指令の「72時間以内報告」要件を満たすだけでなく、弊社の自動化テンプレート適用により、ダウンタイムを大幅に短縮できることを実証しています。 また、法令報告に必要なフォレンジックログは取得済みのため、24時間以内に詳細レポートを提出可能です。[出典:欧州委員会『Network and Information Security Directive 2 (NIS2)』2024年]
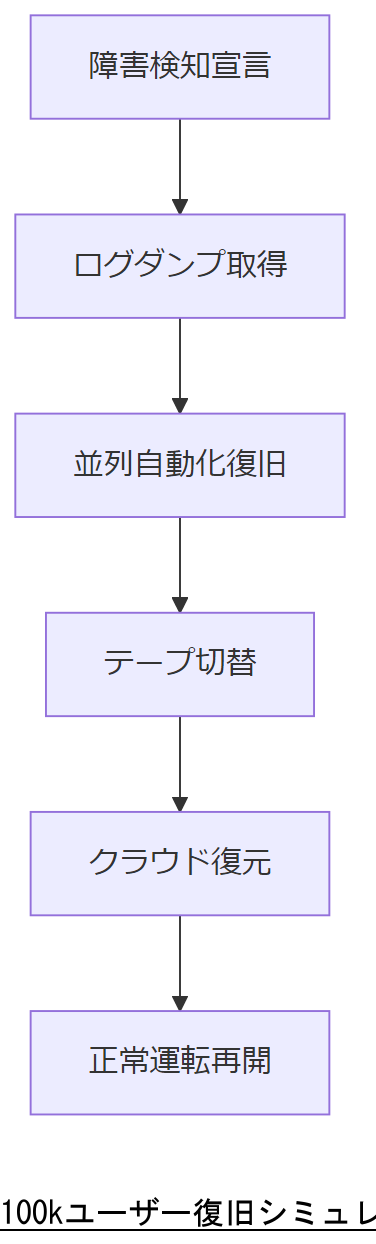
大規模環境でのタイムラインと各工程責任者を可視化し、サービスオーナーおよび経営層の承認を得てください。
大規模環境特有のネットワーク負荷や並列処理ボトルネックを事前に負荷試験し、復旧演習に反映してください。
まとめと行動喚起
本記事では、LVM障害対応における基礎知識から具体的復旧フロー、3重化バックアップ設計、法令対応、BCP運用までを網羅的に解説しました。各章で示した手順と自動化テンプレートを活用することで、障害発生時のダウンタイムを大幅に短縮し、法令遵守とコスト最適化を同時に実現できます。
次のステップとして、まずは「初動15分プロトコル」の社内テスト実施、続いて「3-2-1ルール」によるバックアップ体制の検証をおすすめします。また、弊社(情報工学研究所)では各手順に対応した演習支援とコンサルティングサービスを提供しておりますので、お気軽にお問い合わせください。
本記事で提示した5ステップを社内で共有し、各担当部門の実施計画を承認してください。
記事の内容をもとに、次回BCP訓練のアジェンダを作成し、復旧時間の実効性を定期的に評価してください。
おまけの章:キーワードマトリクス
| キーワード | 説明 | 関連章 |
|---|---|---|
| LVM | 物理ディスクを論理ボリュームとして管理する仕組み | 1 |
| 初動15分プロトコル | 障害発生後15分以内に行う一連の初動手順 | 2 |
| 3-2-1ルール | バックアップの3重化原則(3媒体、2種類、1オフサイト) | 5 |
| デジタルフォレンジック | 証拠保全と解析手法の総称 | 6,13 |
| BCP | 事業継続計画。緊急時の業務維持策 | 11 |
| NIS2 | EUのサイバー指令。インシデント報告義務 | 8,14 |
| ROI | 投入資本利益率。コスト対効果の指標 | 7 |
| ステークホルダー分析 | 関係者の影響度と関与度を整理する手法 | 12 |
| フォレンジック専門家 | 証拠保全とバイナリ解析を行う技術者 | 13 |
| 並列自動化 | 複数ノードへ同時に復旧コマンドを実行する手法 | 4,14 |
