マルチブート環境のRAID崩壊に対し、安全かつ迅速な復旧手順、BCP・法令遵守の枠組み構築、経営層への報告体制の確立を支援します。
RAID崩壊リスクの早期検知と切り分け手順を明確化し、復旧プロセスの透明性を高めます。
技術担当者が経営層に説明しやすい資料テンプレートとコンセンサスメッセージを提供します。
マルチブート環境とRAID構成の基礎
マルチブート環境とは、1台の物理サーバーやPC上で複数のOSを共存させる構成を指します。例えばWindowsとLinuxを同一機に共存させるケースが典型的です。このような環境では、OSごとに異なるブートローダーやパーティション設計が求められ、RAID(Redundant Array of Independent Disks)構成と併用することで高い可用性と性能を実現します。
概要説明
本章では、技術担当者がRAIDの基本概念とマルチブート下での配置要件を理解し、後続の復旧手順をスムーズに学べるよう導入します。
| RAIDレベル | 冗長性 | 性能特性 |
|---|---|---|
| RAID1 | ミラーリング(2台以上) | 読み取り向上・書き込みは単体と同等 |
| RAID5 | パリティ分散(3台以上) | 読み取り向上・書き込みにパリティ演算 |
| RAID6 | 二重パリティ(4台以上) | RAID5以上の冗長性、書き込みコスト増 |
マルチブート環境ではブートローダー変更時に全OSに影響が及ぶため、変更計画を必ず全担当者で共有してください。
技術者として、RAIDレベルごとの冗長性・性能特性を誤解しないように、要件定義段階で経営層と合意を得ておきましょう。
RAID崩壊の兆候と事前チェックポイント
RAIDが崩壊するとデータ損失やサービス停止リスクが高まります。本章では、技術担当者が事前に把握すべき兆候と定期チェック項目を整理し、未然防止につなげます。
兆候の把握
- 読み込みエラーの増加:SMART情報でディスクの不良セクタ数が増加
- リビルド遅延:RAID再構築処理が想定時間を大幅に超過
- 異音や振動:ディスク物理故障の初期サイン
事前チェックポイント
- SMARTステータスの定期取得(毎日または毎週)
- RAIDコントローラログの異常コード監視
- バックアップ世代の整合性検証
- ファームウェア・ドライバの最新化状況
| 項目 | 頻度 | 対応内容 |
|---|---|---|
| SMARTステータス | 毎日 | 自動通知設定 |
| 再構築進捗 | 毎週 | 完了時間チェック |
| ログ監視 | リアルタイム | エラーアラート |
SMART監視やログ監視は運用負荷を伴うため、監視体制の予算と役割分担を経営層に明確に承認してもらってください。
技術者として、監視項目のしきい値設定や通知ルールで過剰アラートにならないよう、運用開始前にテストを行い誤検知を減らしましょう。
初動対応:障害識別から切り分けまで
RAID崩壊発生時には、まず迅速に障害の有無と範囲を特定し、影響を最小化するための切り分けを行います。本章では、具体的な初動手順と注意点を示します。
障害識別の手順
- RAIDコントローラ/OSログの直近エラー確認
- ディスクステータスコマンド(例:mdadm –D、megacli)で故障モジュール特定
- 影響サービスの稼働状況チェック(Web、DB、ファイル共有など)
切り分けと影響範囲特定
- 該当ディスクの隔離(ホットスワップ対応機なら即時取り外し)
- フェイルオーバー構成が機能しているかの確認
- データ損失範囲と復旧優先度の設定
| ステップ | 実施内容 | 完了条件 |
|---|---|---|
| ログ確認 | RAIDコントローラ/システムログ | 異常エラー特定完了 |
| ステータス確認 | ディスク状態コマンド | 故障モジュール抽出完了 |
| サービス影響度 | サービス稼働テスト | 停止サービスリスト化完了 |
初動対応ではログやコマンド操作が必要なため、アクセス権限や手順書の共有体制を部門間で明確にしてください。
技術者として、切り分け時に誤って正常ディスクを操作しないよう、対象ディスクのラベリングと手順確認を徹底しましょう。
データ保全のための3重化バックアップ戦略(BCP)
災害やシステム障害発生時にもデータ消失を防ぐには、**3重化バックアップ**が基本です。本章では、各バックアップ層の役割と運用フローを解説します。
バックアップ構成の3層モデル
- レイヤー1(オンサイト): 高速リストア用のローカルNAS/ストレージ
- レイヤー2(オフサイト): 別拠点へのテープ保管またはデータセンターレプリケーション
- レイヤー3(クラウド): 災害時対応用のクラウドストレージバックアップ
BCP運用フロー
- 定期スケジュール:オンサイト毎時、オフサイト毎日、クラウド毎週
- 復旧手順テスト:四半期ごとの復旧演習実施
- 保存期間管理:レイヤー別に保持世代数を設定
| レイヤー | 保存場所 | 復旧速度 | 保存期間 |
|---|---|---|---|
| オンサイト | 社内NAS | 数分以内 | 7世代 |
| オフサイト | 遠隔DCテープ | 数時間 | 30世代 |
| クラウド | クラウドストレージ | 数時間 | 90世代 |
各バックアップレイヤーのコストと運用負荷を明示し、予算配分と役割分担を経営層と合意してください。
技術者として、演習結果を文書化し、復旧時間目標(RTO)と復旧ポイント目標(RPO)が達成できているかを定期確認しましょう。
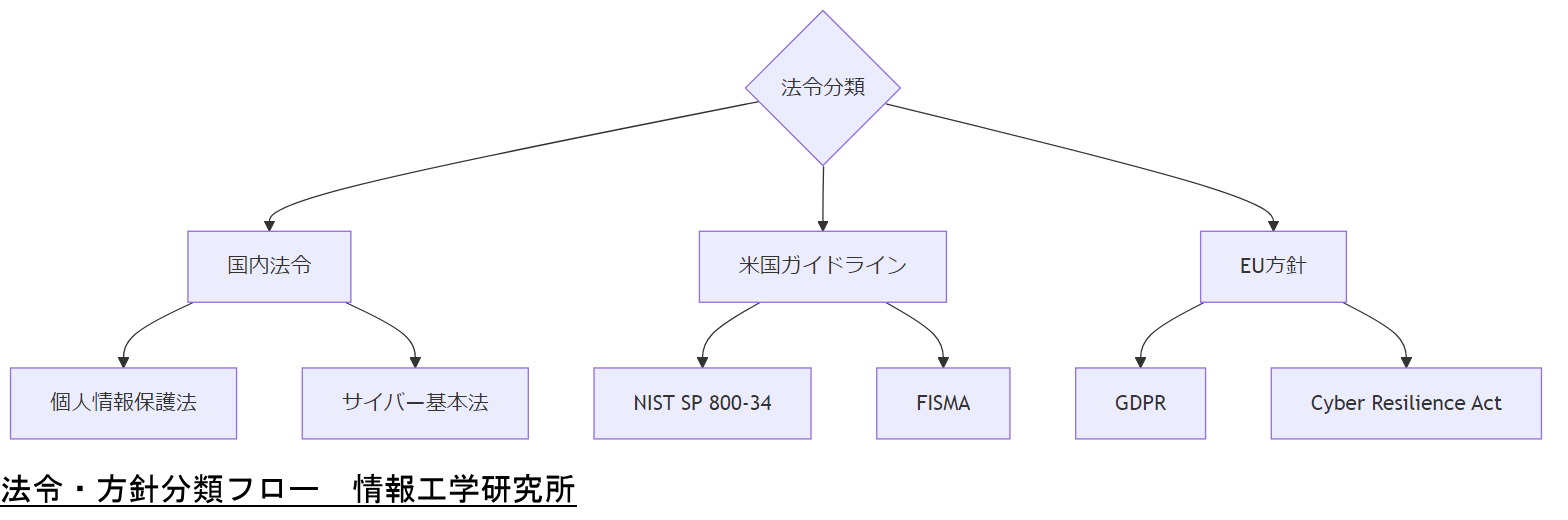
法令・政府方針の解説
法令と政府方針は、情報システム運用やデータ保全の枠組みを規定します。国内外の主要ガイドラインを把握し、変化に対応する体制を整えましょう。
国内法令・ガイドライン
- 改正個人情報保護法(2022年6月施行):企業はデータ漏洩防止策を強化する必要があります。[出典:総務省『個人情報保護に関するガイドライン』2022年]
- サイバーセキュリティ基本法:システム設計段階からセキュリティ対策を義務付け。[出典:内閣府『サイバーセキュリティ基本方針』2023年]
米国政府ガイドライン
- NIST SP 800-34 Rev.1:システム障害時の災害復旧計画策定を詳細に解説。[出典:経済産業省翻訳版『NIST SP 800-34 Rev.1』2021年]
- FISMA(連邦情報セキュリティ管理法):連邦政府調達システムへの適用要件。[出典:総務省『FISMAガイドライン』2020年]
EU法令・方針
- GDPR(一般データ保護規則):データ主体の権利保護と違反時罰則規定。[出典:経済産業省『GDPR対応ガイド』2019年]
- Cyber Resilience Act(CSA):製品・サービス提供者にリスク管理義務。[出典:内閣府『EU Cyber Resilience Act概要』2024年]
| 法令/方針 | 適用範囲 | 主な要件 |
|---|---|---|
| 個人情報保護法 | 国内全事業者 | データ漏洩時の報告義務 |
| NIST SP 800-34 | 米国政府調達 | DR計画文書化 |
| GDPR | EU域内事業者 | データ主体権利尊重 |
複数国の法令適用範囲を正確に把握し、管轄部門ごとの対応責任を経営層と合意してください。
技術者として、法令要件を実装する際にガイドラインの抜け漏れがないか、チェックリスト化して運用してください。
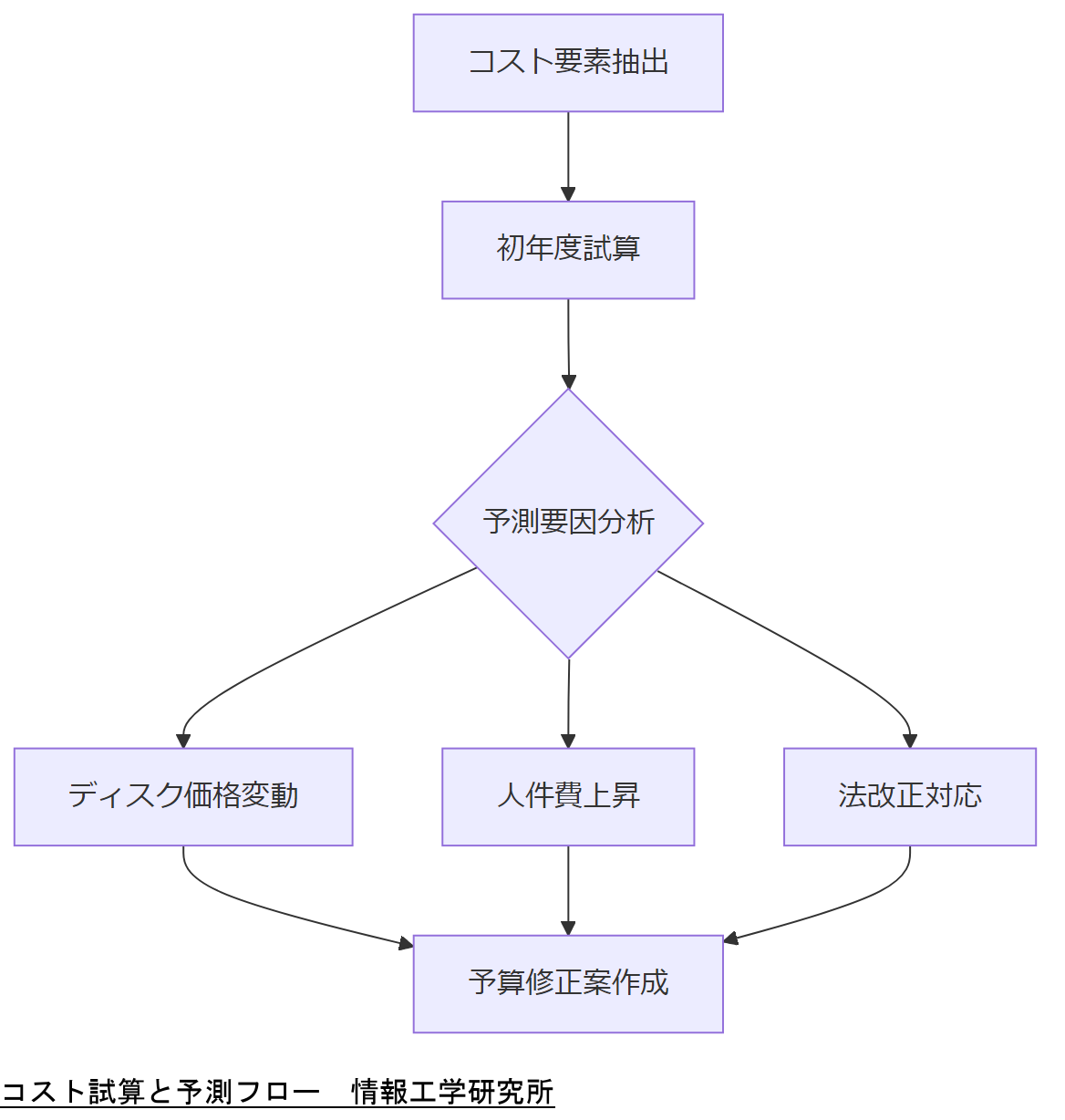
運用コスト試算と予測変化
RAID運用およびバックアップ戦略に伴うコストを可視化し、今後2年間の変動要因を予測します。技術担当者が適切な予算計画を立案できるよう、主なコスト要素と将来の社会情勢変化を整理しました。
主要コスト要素
- ハードウェア費用:ディスク購入・交換費用、コントローラライセンス
- ライセンス・サポート費:OS・RAID管理ソフトウェアの保守契約
- 運用人件費:監視・復旧演習・定期点検作業工数
- オフサイト保管費:遠隔データ保管拠点の利用料
2年後までの予測要因
- ディスク価格の市場動向(昨年比-5%~+3%予測)【想定】
- 電力コストの変動と省エネ機器導入効果
- 人材不足による人件費上昇傾向(年率2~4%)
- 法改正による追加要件対応コストの増加
| 項目 | 金額(円) | 備考 |
|---|---|---|
| ハードウェア | 1,200,000 | RAID構築・交換用ディスク |
| ライセンス | 300,000 | 管理ソフト保守 |
| 人件費 | 1,000,000 | 運用工数 |
| オフサイト保管 | 200,000 | テープ保管料 |
コスト試算には想定値を含むため、見積根拠と変動率前提を明示し、経営層の承認を得てください。
技術者として、実際の支出と比較し月次レビューで差異分析を行い、仮説と実績の乖離を早期に是正しましょう。
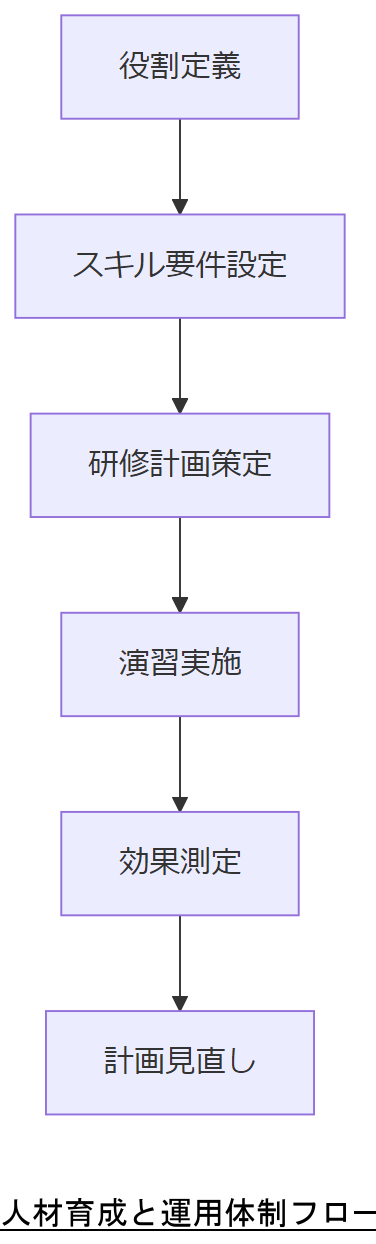
運用体制と人材育成・募集計画
効果的なRAID運用には、明確な役割分担と継続的な技術研修が欠かせません。本章では、運用体制の設計と必要スキルを持つ人材の育成・募集方法を解説します。
運用体制の設計
- アカウント管理者:RAIDコントローラ設定・権限付与を担当
- 監視オペレータ:SMARTログ・コントローラログを24時間監視
- 復旧エンジニア:障害発生時のディスク交換・リビルド実施
- PMO(プロジェクト管理者):定期点検や演習の計画・進捗管理
人材育成・募集計画
- 必要スキル:Linux/Windows両OSのRAIDコマンド運用経験
- 研修内容:RAID構築実習、障害シナリオ演習、ログ解析ハンズオン
- 資格推奨:情報処理安全確保支援士(登録セキスペ)など
- 募集要件:システム運用5年以上、緊急対応経験者優遇
| 役割 | 必須スキル | 研修頻度 |
|---|---|---|
| アカウント管理者 | RAIDコントローラ設定 | 年1回 |
| 監視オペレータ | ログ解析、アラート設定 | 半年に1回 |
| 復旧エンジニア | ディスク交換・MDADM操作 | 四半期ごと |
| PMO | プロジェクト管理 | 年2回 |
役割と研修計画には人件費と時間がかかるため、年間予算と研修スケジュールを経営層と承認してください。
技術者として、研修の理解度を定量的に評価し、継続的にプログラムを改善しましょう。
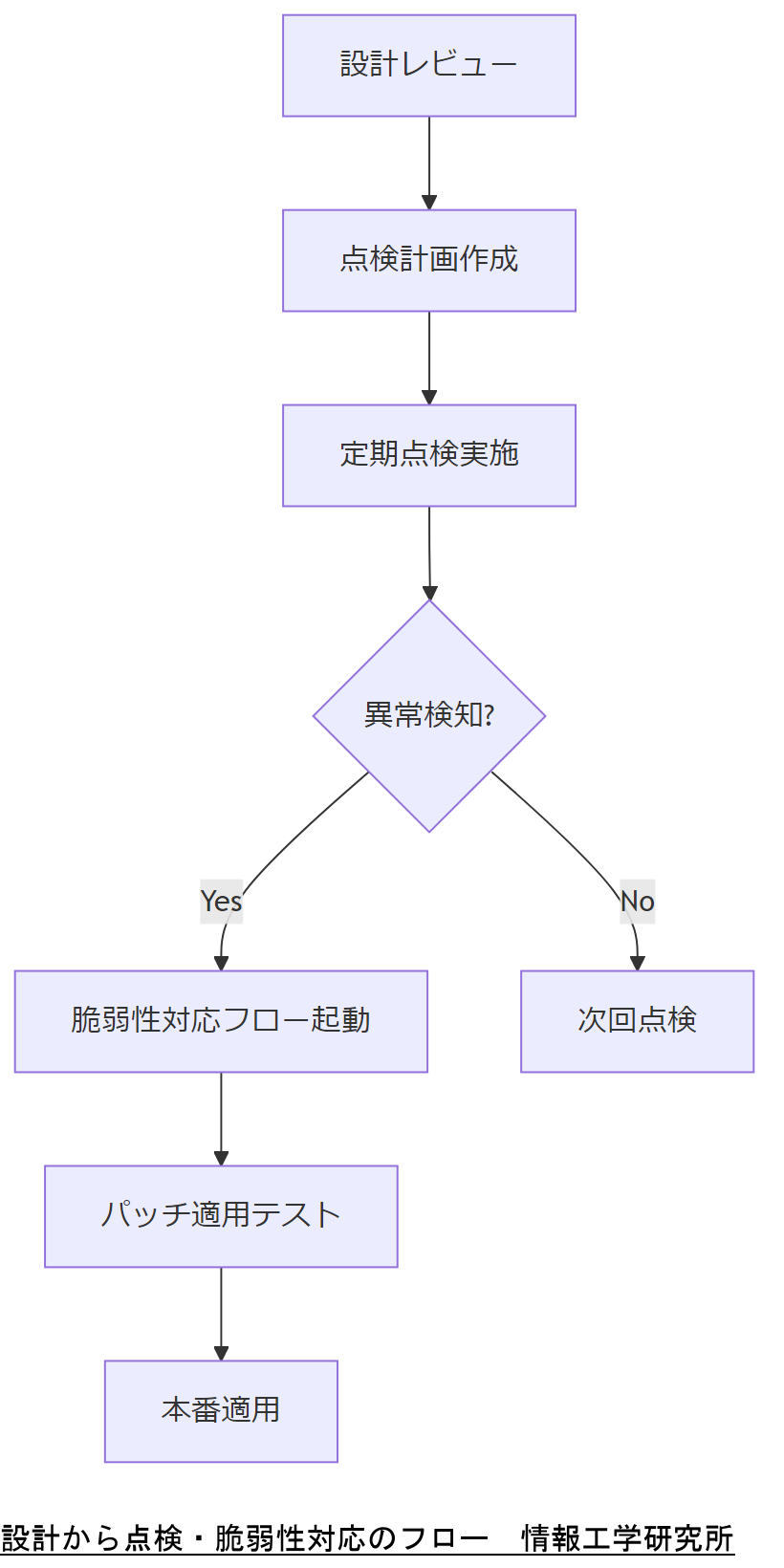
システム設計・点検・脆弱性対応手順
安定稼働を維持するには、設計段階での堅牢性確保と定期的な点検、脆弱性発見時の迅速対応フローが必須です。本章では、特にマルチブート環境におけるポイントを整理します。
設計時の考慮事項
- パーティション分割:各OSが共存するためにブート・データ領域を明確に分離
- RAIDコントローラ選定:複数OS対応ドライバの互換性確認
- ネットワーク冗長化:管理ネットワークとデータネットワークを分離
定期点検手順
- 月次:RAID状態・ディスク寿命予測(SMART)レポート作成
- 四半期:OS別ブートテスト実施
- 年次:ファームウェアおよびドライバ更新検証
脆弱性対応フロー
- 脆弱性通知受領 → 影響範囲評価
- テスト環境で再現検証
- 修正パッチ適用 → 本番移行演習
| 頻度 | 対象 | 実施項目 |
|---|---|---|
| 月次 | ディスク/RAID | SMARTレポート |
| 四半期 | OSブート | マルチブート起動検証 |
| 年次 | ファームウェア | 更新テスト |
定期点検計画とパッチ適用リスクを評価し、ダウンタイム許容範囲について経営層と合意してください。
技術者として、点検と修正の自動化を進めてヒューマンエラーを減らし、作業ログを必ず記録しましょう。
デジタルフォレンジック対応
マルチブート環境でのRAID障害は、サイバー攻撃やマルウェアによる可能性もあります。本章では、デジタルフォレンジックの基本手順と注意点を解説します。
フォレンジックの準備
- 証拠保全:まずディスクイメージをブロック単位で取得し、オリジナルは触らず保管
- ツール選定:autopsy、FTK Imagerなど政府推奨ツールを使用
- ログ一括収集:OS/RAIDコントローラ/アプリケーションログをタイムスタンプ順にまとめる
解析手順
- ディスクイメージの整合性検証(ハッシュ値比較)
- ファイルシステムの改ざん痕跡検出(タイムスタンプ、ファイル許可変更)
- マルウェアスキャンおよび侵入経路特定
| ステップ | ツール | 出力 |
|---|---|---|
| イメージ取得 | dc3dd | dd形式イメージ |
| 整合性検証 | sha256sum | ハッシュ値レポート |
| 解析レポート作成 | autopsy | 侵入経路報告書 |
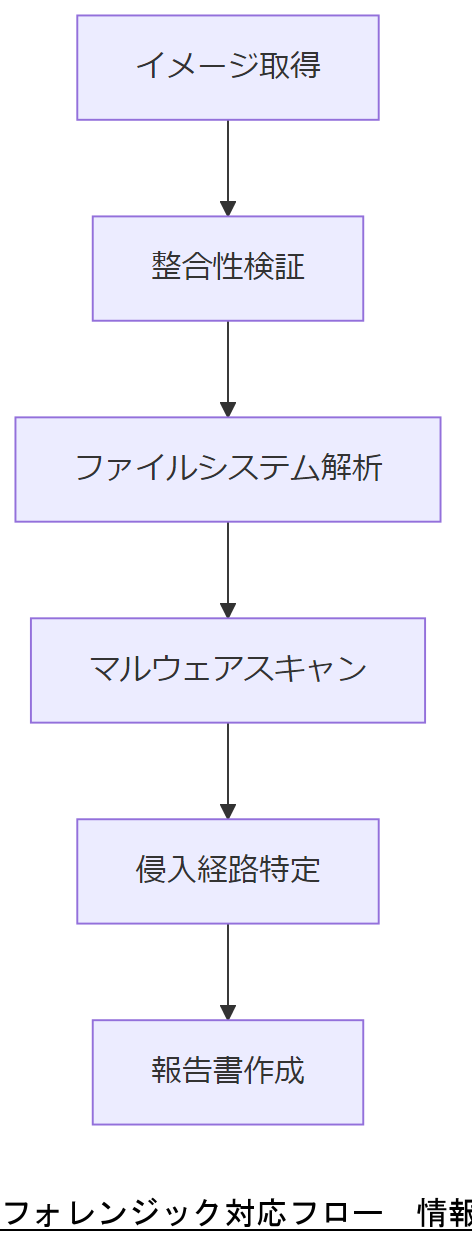
フォレンジックは証拠保全が最優先のため、手順書に従いオリジナルメディアを操作しない旨を徹底してください。
技術者として、フォレンジック実施時は必ず担当者の連絡網と手順書を用意し、作業ログを二重で記録してください。
外部専門家へのエスカレーション基準
システム障害やフォレンジック作業で技術的限界に達した場合、**情報工学研究所**への相談を迅速に行うことが重要です。本章では、エスカレーションの判断基準と手順を示します。
エスカレーション判断基準
- 初動対応から48時間以内に復旧見通しが立たない場合
- フォレンジック解析で異常原因が特定できない場合
- 法令対応要件の解釈や適用に不安がある場合
- BCP演習で計画達成率が70%未満の場合
エスカレーション手順
- 社内判断会議で事案概要をまとめる
- 情報工学研究所お問い合わせフォームより連絡
- 対象システム情報とログ、試行手順レポートを提出
- 専門家からの返答を受領後、復旧チームと共同作業
| 状況 | 判断基準 | 対応先 |
|---|---|---|
| 復旧見通し未達 | 48時間経過 | 情報工学研究所 |
| 原因不明障害 | 解析24時間以内 | 情報工学研究所 |
| BCP演習未達 | 実績70%未満 | 情報工学研究所 |
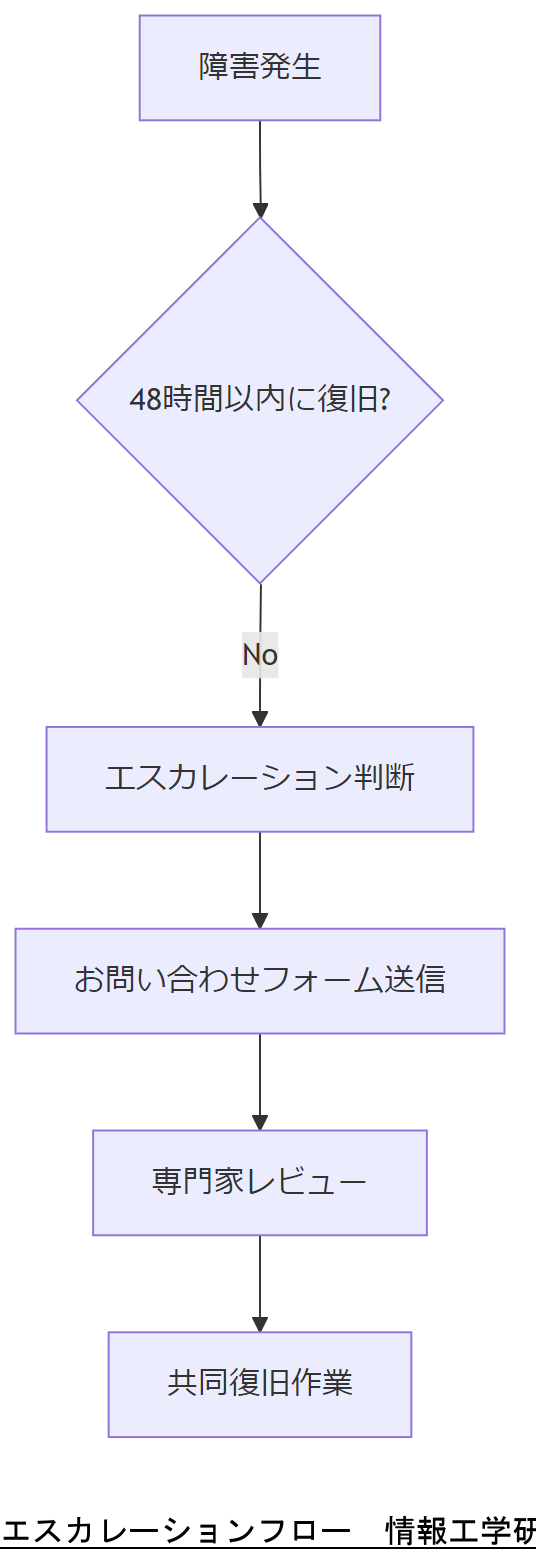
エスカレーション要件と手順を事前に社内で周知し、緊急時連絡体制を構築してください。
技術者として、エスカレーション時には必要情報を整理し、迅速な意思決定ができるよう心がけましょう。
BCP 3段階オペレーション設計
BCPでは、**緊急時**、**無電化時**、**システム停止時**の3段階で運用を想定します。10万人以上ユーザーがいる場合は更に細分化し対応します。
緊急時オペレーション
- 影響範囲特定 → 通知フロー起動
- 代替サーバー起動 → 最低限のサービス維持
- オンサイトバックアップからの最速リストア
無電化時オペレーション
- UPS運用による一時稼働 → 優先度高システム維持
- ジェネレータ起動要件の確認
- 手動運用手順書の準備と訓練
システム停止時オペレーション
- 全システム停止 → 安全シャットダウン
- リスク評価会議 → 復旧計画見直し
- ステークホルダー連絡 → 進捗共有
| 段階 | 主な対応 | 訓練頻度 |
|---|---|---|
| 緊急時 | 代替サーバー起動 | 年2回 |
| 無電化時 | UPS/ジェネレータ起動 | 年1回 |
| システム停止時 | 安全シャットダウン | 四半期ごと |
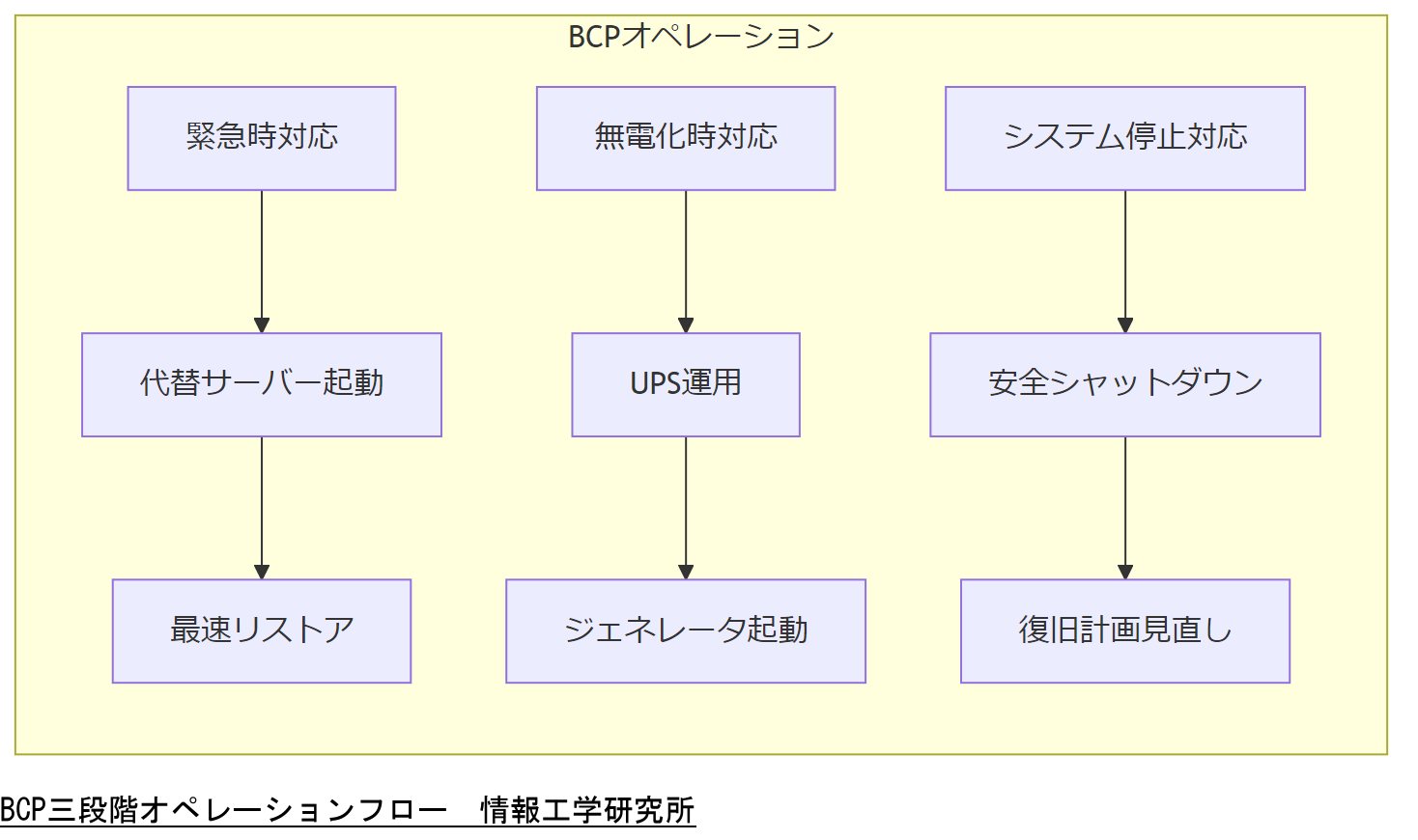
BCP各段階の訓練頻度と代替インフラコストを経営層と合意し、年間訓練スケジュールを設定してください。
技術者として、各段階の訓練後に改善点を必ずレビューし、手順書に反映しましょう。
経営層向け報告書・コンセンサス取得
経営層・役員への報告書は、技術情報をかみくだき、影響度やコスト・リスクを明確に示すことが重要です。
報告書の構成要素
- 概要:障害発生から現状までの経緯
- 影響:サービス停止範囲と業務影響度
- 復旧計画:手順と所要時間・予算
- リスク管理:法令遵守・BCP整合性
コンセンサスメッセージ例
| 項目 | 内容 |
|---|---|
| タイトル | RAID崩壊対応報告 |
| 発生日 | YYYY年MM月DD日 |
| 対応状況 | 初動対応完了/復旧見通し |
報告内容と提案施策に対するフィードバックを経営層から受領し、次回運用改善に反映してください。
技術者として、定量データをグラフ化し、視覚的に理解しやすい資料を心がけましょう。
| キーワード | 説明 |
|---|---|
| マルチブート | 複数のOSを同一機で起動できる構成 |
| RAID崩壊 | 冗長構成ディスクの論理破損 |
| BCP | 事業継続計画 |
| デジタルフォレンジック | 証拠保全・解析手法 |
| NIST SP 800-34 | 米国のDR計画ガイドライン |
| GDPR | EU一般データ保護規則 |
