Ubuntu 上で発生するデータ損失の初期対応手順を理解し、証拠保全と法令対応を両立させた安全な復旧を実現します。
経営層や役員に説明可能な要点と資料構成を把握し、社内コンセンサス形成をスムーズにします。
BCP やデジタルフォレンジック要件を満たした運用設計を学び、緊急時の多層防御体制を整備します。

Ubuntu におけるデータ損失の主因と障害分類
Ubuntu をはじめとする Linux 系 OS 環境で発生するデータ損失は、多岐にわたる原因と障害形態があります。本章では、主に以下の四つのカテゴリーに分類し、それぞれの特徴と発生メカニズムを整理します。これにより、障害発生時に最適な初期対応を判断しやすくなります。
| 原因カテゴリー | 具体例 | 特徴 |
|---|---|---|
| ハードウェア障害 | HDD/SSD の物理故障 | 読み取りエラー、セクタ不良が発生。突然アクセス不能になる。 |
| 人的ミス | 誤ったコマンド実行によるファイル削除 | rm コマンド等によるデータ消失。誤操作後すぐの対応が鍵。 |
| マルウェア/ランサムウェア | 暗号化マルウェアによるファイル破壊 | ファイルが暗号化され、開封不能に。ランサム要求が発生。 |
| 自然災害・電源断 | 停電、雷、火災など | 異常シャットダウンに伴うファイルシステム破損。 |
Ubuntu 環境では、ext4 や XFS といったジャーナリングファイルシステムが標準ですが、異常シャットダウン時にはジャーナルの巻き戻しだけでは回復できない場合があります。また、暗号化ボリューム(LUKS)やソフトウェア RAID を組んでいる場合は、それら固有の障害モードも考慮が必要です。
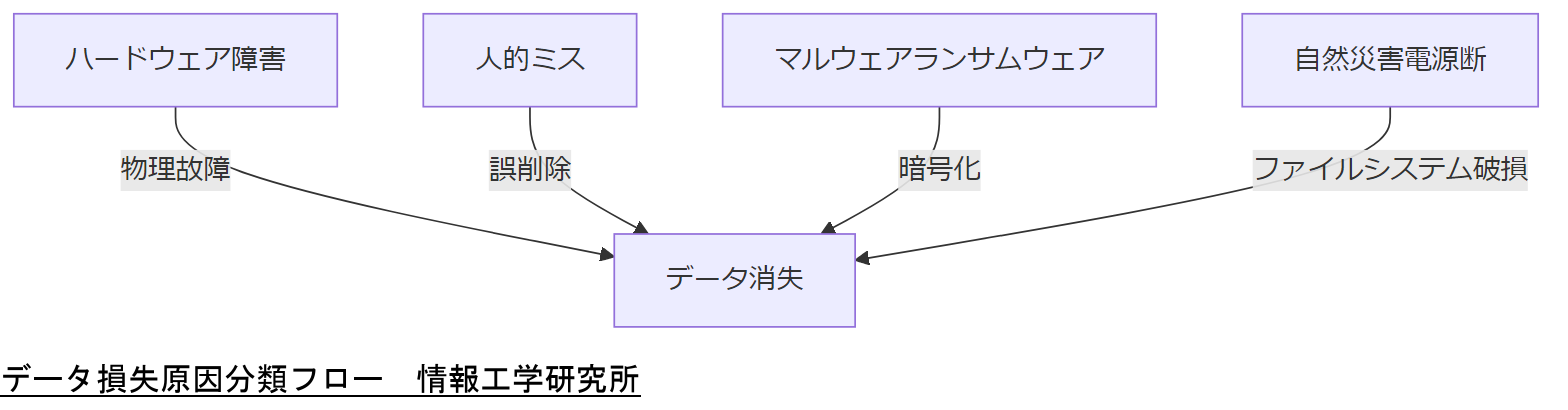
Ubuntu 環境の障害分類を示し、上司へ「何が起きているのか」「どの対策を優先すべきか」を明確に説明しましょう。誤操作かハード障害かで初動方針が大きく異なる点を特に強調してください。
技術担当者は、各障害原因の発生兆候とログ指標を押さえ、たとえばスマート値(S.M.A.R.T.)異常や削除コマンド履歴の確認手順を必ず実践してください。
事前準備:安全なライブ環境の構築と証拠保全
障害発生時に現場のシステムへ直接操作を加えると、証拠保全が困難になる恐れがあります。本章では、Ubuntu をインストールせず起動可能なライブ環境を構築し、かつ証拠保全要件を満たす初動対応手順を解説します。
USBメディア作成【想定】
Ubuntu の公式 ISO イメージを入手し、USB メモリへ書き込んでライブ環境を作成します。書き込みには tools コマンドなどを用い、BIOS/UEFI から確実に起動可能であることを事前検証してください。【想定】
証拠保全手順
ライブ環境起動後は、必ずマウント対象ドライブを 読み取り専用 でマウントします。ddrescue を使ってイメージファイルを取得し、その際のコマンド履歴と出力ログを外部メディアへ保存してください。証拠保全として、取得したイメージのハッシュ値(SHA-256 等)を記録・保管することが必須です。[出典:経済産業省『システム管理基準』2023]
ハッシュ値管理
イメージ取得後は、sha256sum コマンド等でハッシュ値を算出し、証拠台帳に記録します。医療情報管理基準でも同様に、電子証拠の改ざん検知 のためにハッシュ値管理が求められています。[出典:経済産業省『医療情報を受託管理する情報処理事業者における安全管理基準』2012] 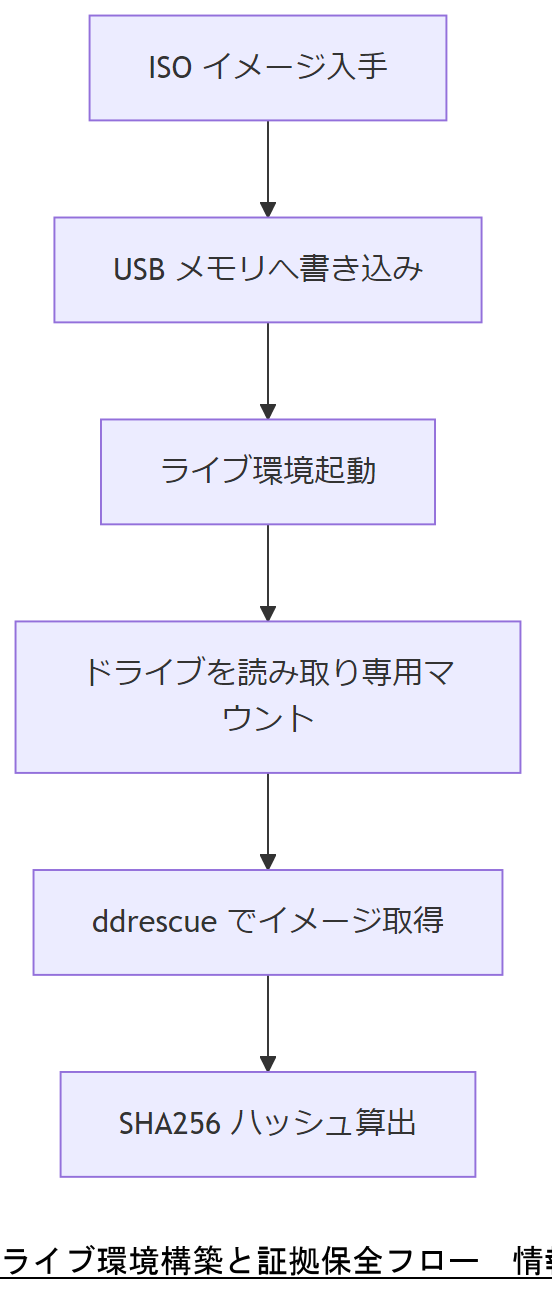
上司へは「現場システムに直接書き込みせず、証拠保全を最優先にライブ環境で取得したイメージを使う」点を強調してください。
技術担当者は、読み取り専用マウントやハッシュ計算を必ず手順通り実施し、ログの欠落がないか逐一確認してください。
基本復旧ツールの選定と使い分け
Ubuntu 環境でデータ復旧を行う際、用途や障害レベルに応じて最適なツールを選定することが重要です。大別すると「ブロックレベル復旧」と「論理レベル復旧」の二つに分類され、具体的には GNU ddrescue、TestDisk、PhotoRec、extundelete などが代表的です。各ツールの特徴を理解し、障害状況に応じた使い分け手順を整理します。
GNU ddrescue:ブロックレベル複製
GNU ddrescue は、読み取りエラーのあるディスクからブロック単位でデータを抽出し、イメージファイルへコピーするツールです。エラー発生箇所をスキップしながら再試行を行う機能により、物理障害ドライブからのデータ取得率を最大化します。Ubuntu の標準リポジトリからインストール可能であり、復旧作業の第一歩として最適です。
TestDisk:論理レベルのパーティション復旧
TestDisk はファイルシステムやパーティションテーブルの論理的な破損を修復するツールで、削除されたパーティションの再構築やブートセクタの復元に強みを持ちます。CLI 操作ですが、自動検索機能で失われたエントリを検出し、元の構造を復元します。
PhotoRec:ファイルカービングによるデータ復元
PhotoRec はファイルシステムを無視してディスク上のファイルシグネチャをスキャンし、削除されたファイルを復元するツールです。名前・ディレクトリ構造は復元できませんが、JPEG やドキュメントなど多数のファイルタイプに対応しています。TestDisk と同パッケージで提供され、GUI ラッパーも存在します。
extundelete:EXT3/4 専用リカバリ
extundelete は ext3 および ext4 ファイルシステム専用に設計された復旧ツールで、ジャーナルのログを解析して削除ファイルを復元します。特定パーティションからファイルを選択的に復元可能で、他の汎用ツールと併用すると効果的です。
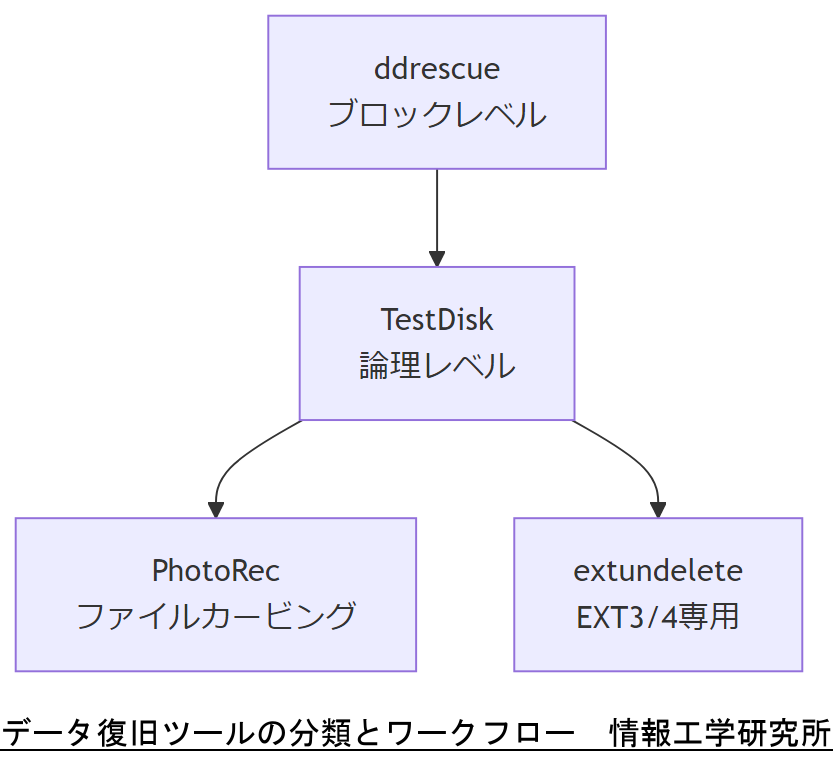
上司には「物理的に読み取れない場合は ddrescue、論理構造破損時は TestDisk、ファイル単位での復元は PhotoRec/extundelete を使い分ける」点を明確に伝えてください。
各ツールの前提条件(読み取り専用マウント、ファイルシステム種別など)を必ず確認し、不適切なツール使用による二次被害を防いでください。
ファイルシステム別復旧戦略
Ubuntu で広く用いられる ext4、XFS、Btrfs では、それぞれの構造に応じた復旧手順を理解することが重要です。
| ファイルシステム | 主な特徴 | 推奨ツール |
|---|---|---|
| ext4 | ジャーナリング対応。inode とブロックマップで管理。 | extundelete、TestDisk |
| XFS | 高性能向け。ジャーナルサイズが大きい。 | xfs_repair、ddrescue |
| Btrfs | スナップショット機能、チェックサム対応。 | btrfs restore、ddrescue |
ext4 はジャーナルログから未コミット領域を回復できるため、小規模なファイル単位の復旧に強みがあります。
XFS はメタデータ操作に強く、xfs_repair で構造修復後に ddrescue でイメージ取得を行うのが定石です。
Btrfs はスナップショット機能を活用し、過去のスナップショットからデータを復元する手順が有効です。
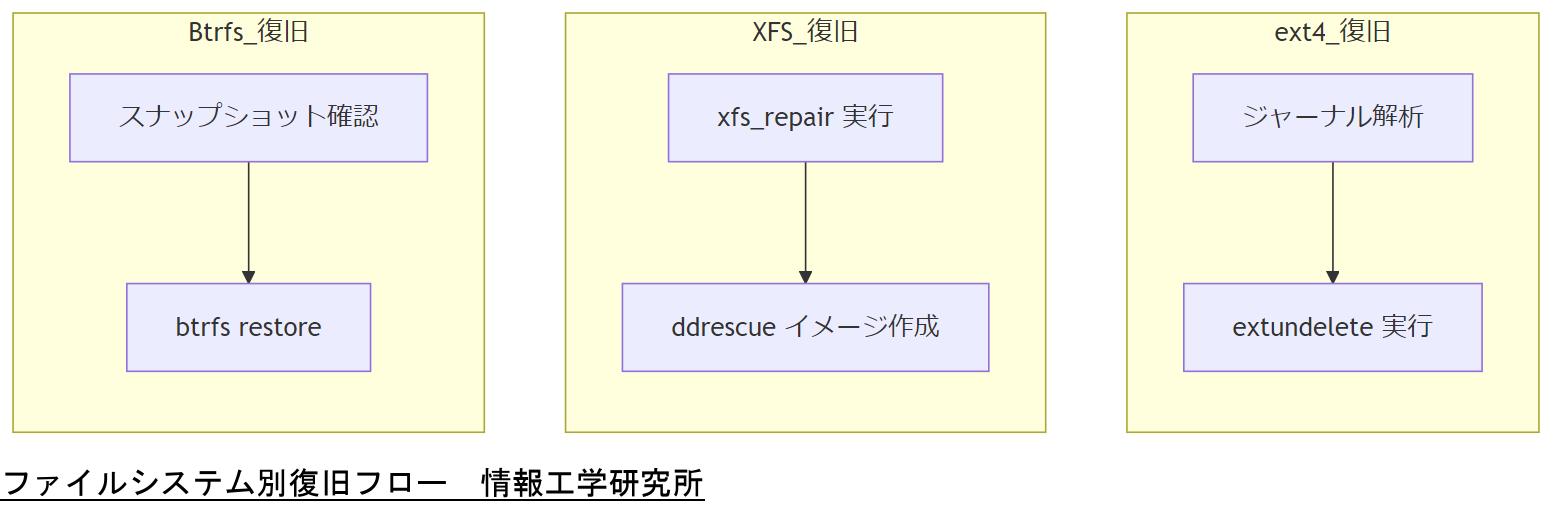
「ext4 はジャーナル解析、XFS は xfs_repair→ddrescue、Btrfs はスナップショット復旧」という各戦略を明確に共有してください。
各ファイルシステムで必須の前提条件(アンマウント状態、スナップショット有無)を確認し、誤操作防止のための手順書を整備してください。
ソフトウェア RAID/LVM/暗号化ボリュームの復旧
Ubuntu 環境で構築されるソフトウェア RAID(mdadm)、LVM(Logical Volume Manager)、LUKS 暗号化ボリュームは、いずれも論理層の障害に対して独自の復旧手順を必要とします。本節では、障害種別ごとに想定される復旧手順を整理します。
mdadm RAID 復旧想定手順
- 故障ドライブを取り外し、mdadm --examine でメタデータを確認
- mdadm --assemble --force による再構築試行
- 失敗時は mdadm --create --assume-clean でアレイを再作成し、データ整合性を後続ツールでチェック
LVM 論理ボリューム復旧想定手順
- 物理ボリュームの状態を pvdisplay で確認
- 欠損 PV がある場合はバックアップ PV を追加し、vgextend で再配置
- lvchange --activate y で LVM 論理ボリュームをアクティベート後、ファイルシステムチェックを実施
LUKS 暗号化ボリューム復旧想定手順
- cryptsetup luksDump でヘッダ状態を確認
- ヘッダ破損時はバックアップヘッダから cryptsetup luksHeaderRestore を実行
- マッピング後、内部のファイルシステムを通常手順で修復(ext4 なら e2fsck)
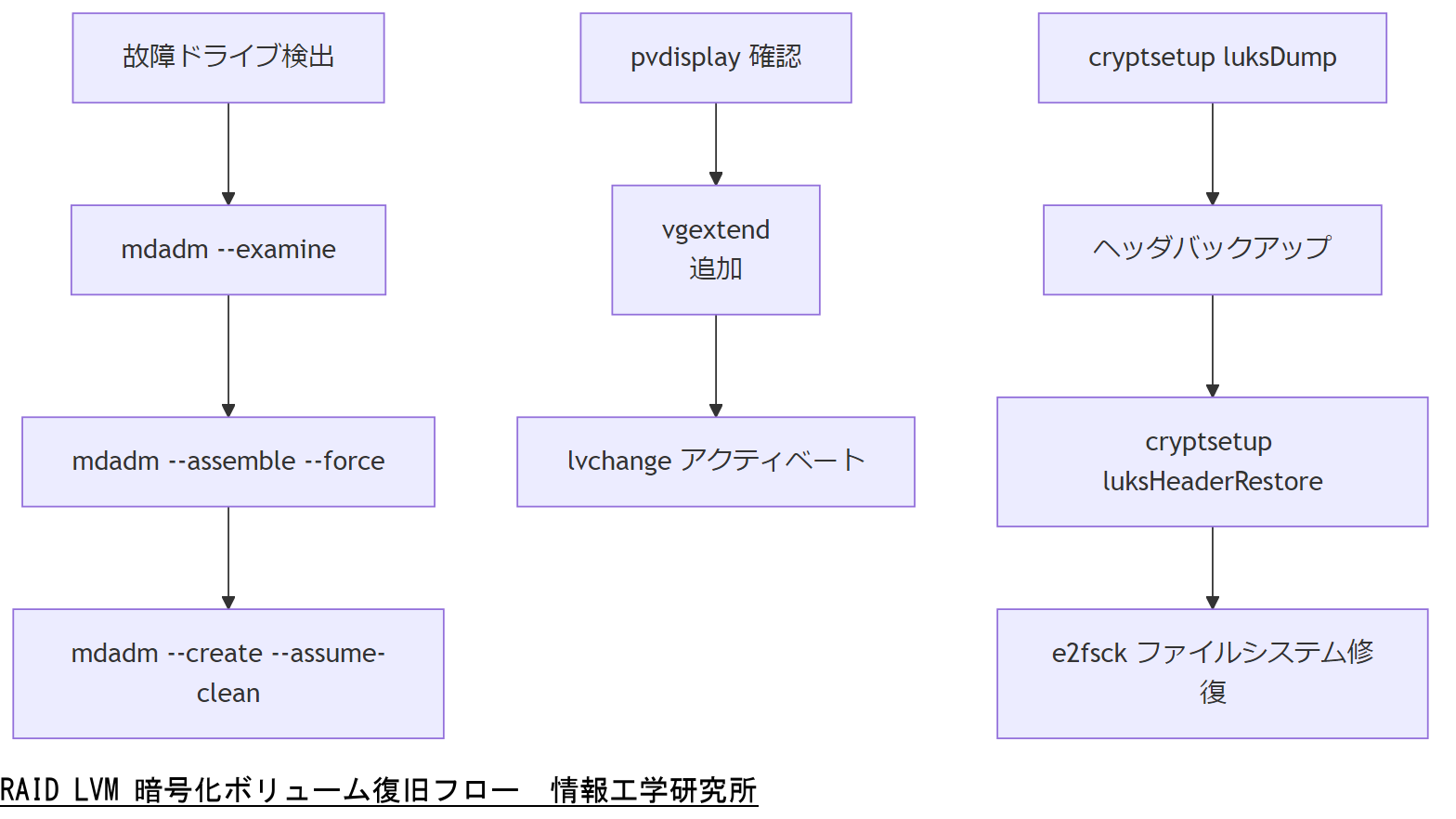
上司には「mdadm は metadata 再構築、LVM は物理ボリューム追加と再アクティベート、LUKS はヘッダバックアップからの復元」という流れを明確に説明してください。
各手順の前提条件(アレイ停止、バックアップヘッダの保管場所など)を厳守し、一連の操作ログを必ず保存してください。
三重化ストレージ設計と段階別 BCP オペレーション
事業継続計画(BCP)において、データ保存の三重化は「3 つの異なるロケーションで同一データを保持する」ことを指し、災害時の一極集中リスクを排除します。具体的には、オンサイト(本番センター)、コールドスタンバイ(別拠点)、オフサイト(クラウドまたは遠隔地)という三層構成を基本とします。
運用フェーズは「通常時」「無電化時」「システム停止時」の三段階に分かれます。通常時は同期レプリケーションを用いてリアルタイム複製を維持し、無電化時はグラニュラーなフェイルオーバーで待機系へ切り替えを行います。システム停止時には、全データのオフサイトコピーからの完全復旧手順を有効化し、代替業務プロセスを並行実行します。
大規模ユーザー数(10 万人以上)を抱える場合は、計画をさらに細分化し、ゾーン運用やセグメント毎のリカバリレベルを設定します。たとえば「インターネット受付系」「顧客管理系」「社内基幹系」の三セグメントに分け、それぞれで独立したレプリケーション・フェイルオーバー計画を策定します。
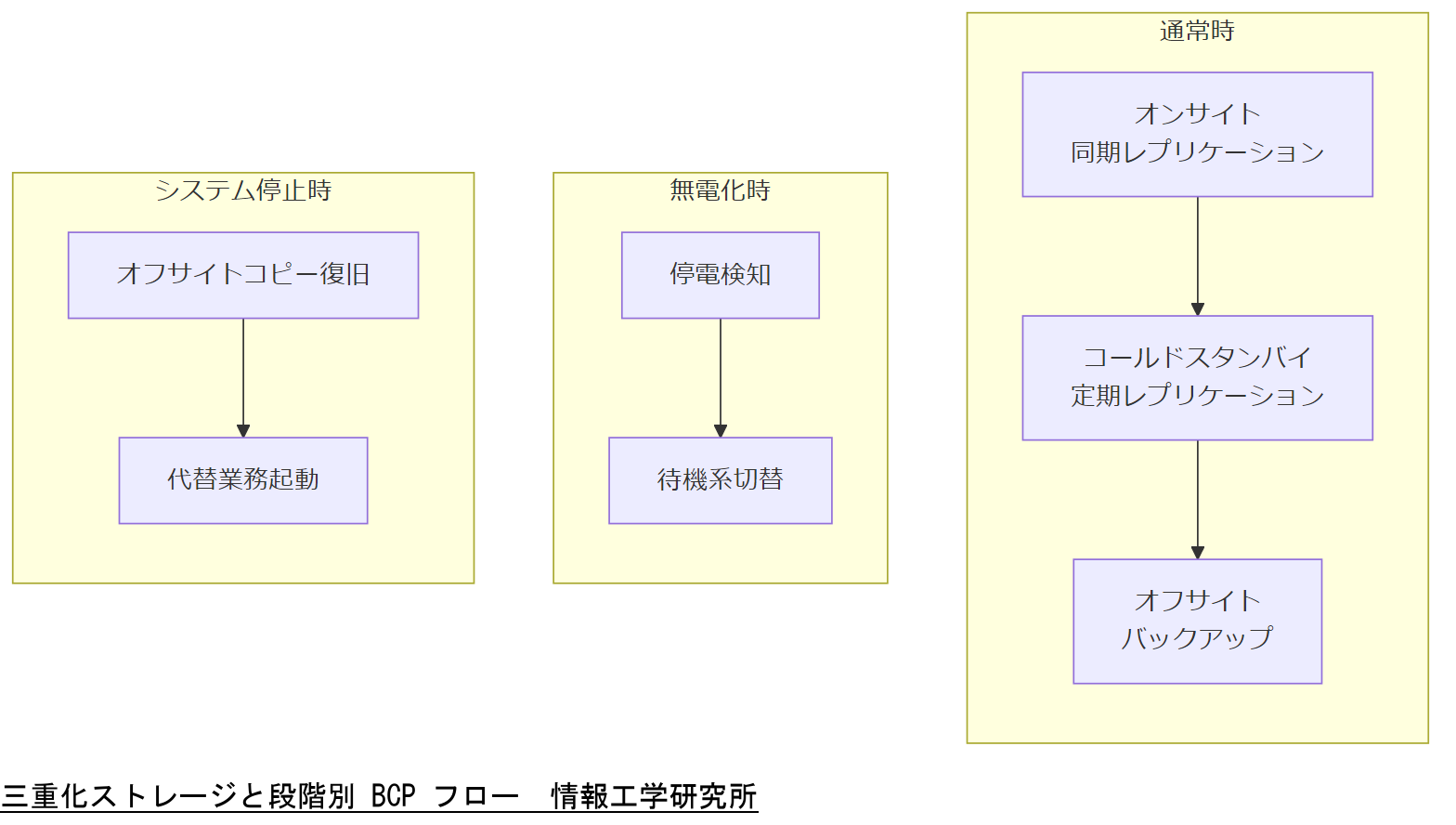
「データは本番/待機/オフサイトの三重化。運用は通常同期・停電待機切替・停止時オフサイト復旧の三段階」と明確に共有してください。
技術担当者は、各フェーズでの切替試験結果とログを必ず記録し、切替スクリプトや手順書に反映してください。
デジタルフォレンジックとログ保全
インシデント発生時には、現場のデータを「証拠」としてそのまま保全し、後続の調査や法的手続きに耐えうる状態で保存することが不可欠です。デジタルフォレンジックの第一歩として、対象システムやネットワーク機器からのログ収集・証拠保全プロセスを体系化します。
証拠保全の基本手順
- 対象デバイスを電源OFFまたはネットワーク切断して状態を固定し、可能な限り「As-is」の状態を維持する。
- Write Blocker(書込防止装置)を用いてメディアを読み取り専用モードに設定し、オリジナルへの書込を防止する。
- フォレンジックデュプリケーターや ddrescue で全体イメージを取得し、ハッシュ値(SHA-256)を計算・記録する。
ログ管理の要件
- 集中管理されたログは、改ざん防止のためタイムスタンプとハッシュ値を併せて保存する必要がある。
- 重要ログは「要保全情報」「要安定情報」に分類し、それぞれ別ストレージで複製・保管する。
- 保全情報の取扱制限(複製禁止・暗号化必須等)を厳格に運用ルールへ明記する。
フォレンジック手法の統合
- インシデント対応ガイドラインに従い、ログ取得→イメージ取得→解析→レポート作成のフローを統合的に実施する。
- ネットワークフォレンジックでは、パケットキャプチャログを保存し、改ざん検知のためにハッシュを併記する。
- IETF RFC3227 に準拠した証拠保全手順を運用マニュアルへ組み込む。
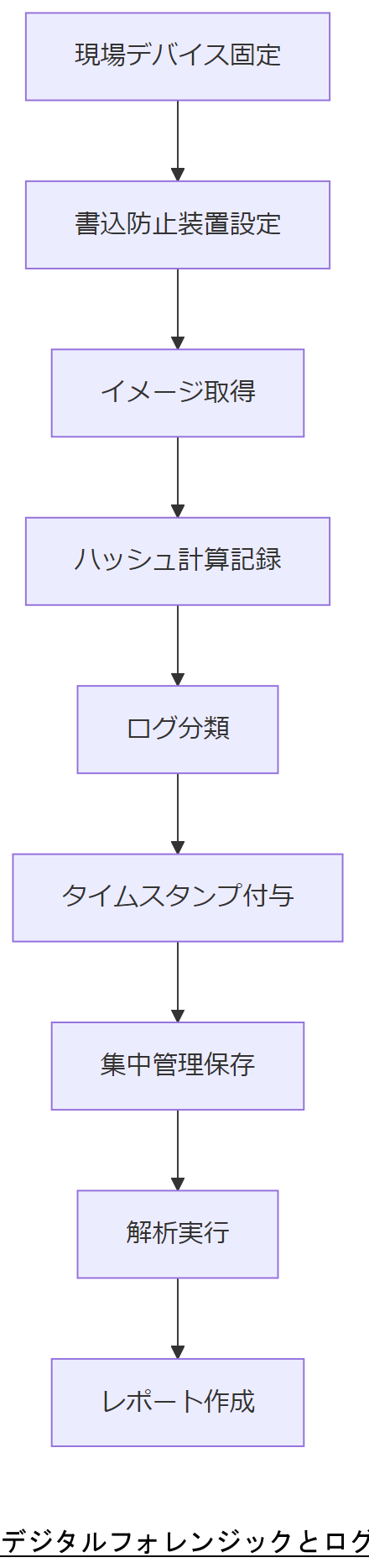
「証拠保全は As-is の固定→書込防止→イメージ取得→ハッシュ記録、ログは要保全情報として分類・集中管理」という手順を共有してください。
技術担当者は、Write Blocker の利用可否とログ分類基準を事前に理解し、運用マニュアルに沿って手順漏れがないようチェックリストを活用してください。
国内外の法令・政府方針が求めるデータ保全要件
日本国内では、情報システムの運用継続やデータ保全について総務省・内閣府・IPA などが策定するガイドラインが基盤となります。政府機関等における情報システム運用継続計画ガイドラインでは、バックアップを「外部サービスも含めた運用継続の管理策」と位置付け、自動復元の仕様確認や第三者評価の受審を求めています。また、総務省の情報システム運用継続計画ガイドラインは、バックアップ媒体のオフサイト保管とテープ・ディスク等複数メディアの併用を明示し、脅威要素からの隔離保管を求めています。
米国では NIST SP 800-53 の CP-9(バックアップ管理)において、〈1〉記録媒体の信頼性と完全性を保証するための定期テスト〈2〉バックアップ実施頻度の明確化〈3〉オペレーティングシステムやアプリケーション構成情報の保全を管理策として定義しています。
EU では GDPR(一般データ保護規則)第32条で、適切な技術的・組織的対策を講じ、「データの可用性と回復性」を確保する義務を定めています。特に、自然災害やシステム障害発生時にも迅速な復旧を可能とするため、冗長化構成やリストア手順の定期検証を義務付けています。
これら国内外ガイドラインを総合すると、データ保全要件としては複数メディア/複数拠点でのバックアップ、定期的な復元テスト、改ざん検知のためのハッシュ管理、および運用手順の文書化・定期見直しが必須と言えます。
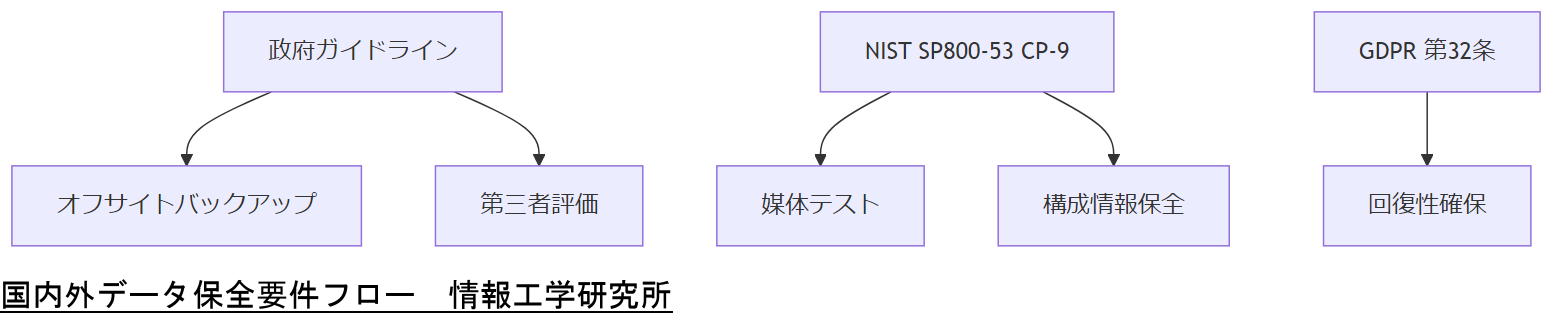
「国内はガイドラインによる複数メディア・オフサイト保管、米国は NIST の定期テスト義務、EU は可用性と回復性の確保」という要件を上司に共有してください。
技術担当者は、日本/米国/EU の要件を一覧化し、自社運用ルールに漏れがないかクロスチェックする資料を準備してください。
関係者マッピングと報告フロー
システム障害発生時には、多様なステークホルダーが関与し、それぞれに適切なタイミングと内容で報告を行う必要があります。本章では、主に以下の五つの関係者を想定し、報告ルートおよびフローを整理します。
- 現場技術担当者:障害検知と初動対応
- 情報システム部門責任者:復旧計画策定とリソース手配
- 経営層(CIO/CSO):事業影響評価と意思決定支援
- 法務・コンプライアンス部門:法令対応と証拠保全確認
- 外部専門家(弊社サービス含む):技術支援と追加調査依頼
| 関係者 | 主な役割 | 報告タイミング |
|---|---|---|
| 現場技術担当者 | 障害検知・初動対応 | 障害発生直後(10分以内) |
| 情報システム部門責任者 | 復旧計画策定・社内調整 | 初動後 30 分以内 |
| 経営層(CIO/CSO) | 影響範囲評価・意思決定 | 初動後 1 時間以内 |
| 法務・コンプライアンス | 証拠保全確認・法的助言 | 初動後 2 時間以内 |
| 外部専門家 | 追加調査・技術支援 | 必要時随時 |
本フローをもとに「誰が」「いつ」「誰に」報告すべきかを明確化し、各担当への責務をあらかじめ合意してください。
技術担当者は本フローに従い、各報告ログ(メール・チャット・会議記録)を確実に記録・保管し、後続調査に備えてください。
人材育成と体制構築(推奨資格・研修)
情報システム担当者が迅速かつ適切にデータ復旧を遂行するためには、組織的な人材育成プログラムと明確なキャリアパスの整備が不可欠です。経済産業省策定の「ITスキル標準(ITSS)」では、実務能力をレベル別に体系化し、独立行政法人情報処理推進機構(IPA)が ITSS+ として第四次産業革命時代の学び直し指針を示しています。
技術要員向け研修ロードマップ
- レベル1: 基礎知識研修(Linux 操作、ファイルシステム基礎)
- レベル2: 応用研修(データ復旧ツール演習、ジャーナリング理解)
- レベル3: プロフェッショナル研修(フォレンジック実践、BCP 設計)
推奨資格
- 情報処理安全確保支援士(登録セキスペ)– セキュリティ運用全般の証明
- CompTIA Linux+ – Linux 環境の専門知識を担保
- BCP コーディネータ – 事業継続計画の立案・運用能力を確認
体制構築のポイント
- ITSS レベル別スキルマップに基づく配置と異動計画を策定。
- OJT と集合研修を組み合わせたハイブリッド研修体系を導入。
- 定期的な演習(テーブルトップ演習、フェイルオーバー検証)とフィードバック会を実施。
「ITSS レベル1~3 に応じた研修計画と、セキスペ・Linux+ 等の資格取得を組み合わせる体制を整備している」点を上司に共有してください。
技術担当者は自身の ITSS レベルを把握し、不足部分を明確にしたうえで、OJT や外部研修の受講スケジュールを策定してください。
外部専門家へのエスカレーションと弊社サービス
情報セキュリティインシデントや重大障害発生時には、組織内だけでの対応では技術的・法的な要件を満たせない場合があります。政府のガイドラインでは、CSIRT 体制の中に「情報セキュリティインシデント対処に関する知見を有する外部の専門家等による必要な支援を速やかに得られる体制」を明確に構築することを推奨しています。
具体的には、以下のタイミングで外部専門家への連絡・協力要請を行います。
- 初動対応で障害の深刻度が判明した直後(評価フェーズ)。
- 内部リソースでは解析や復旧が困難と判断された時点(技術支援フェーズ)。
- 証拠保全後のフォレンジック解析・法令対応が必要な場合(法務支援フェーズ)。
また、BCP/DR 計画ガイドラインでは、「必要に応じて外部の専門知識を有する者の支援を受けて状況確認をする」とあり、外部ベンダーやコンサルティング会社へのエスカレーションが想定されています。国土交通省 A2-BCP 改訂版でも、外部機関との連携体制を図ることが推奨されています。
弊社(株式会社情報工学研究所)は、Ubuntu 環境を含む多様なシステム障害・データ復旧事案において、国内最高水準の技術支援とフォレンジック解析サービスを提供しております。お問い合わせフォームからご相談いただければ、24 時間以内に専任コンサルタントが対応を開始し、政府ガイドライン準拠の報告書を納品いたします。
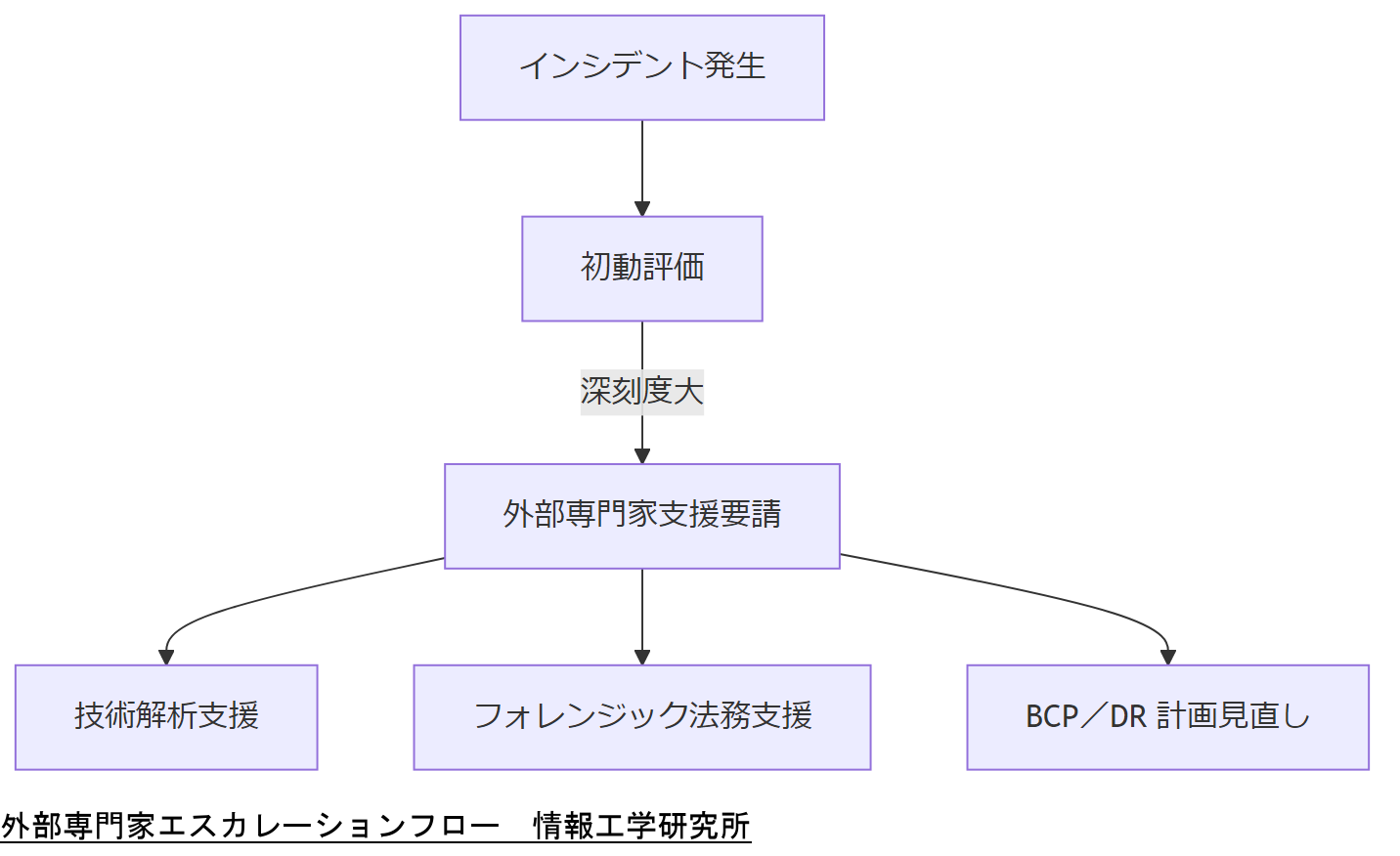
「初動評価で重大と判断したら速やかに外部専門家を招へいし、技術解析・法務支援・BCP 計画見直しへとエスカレーションする」ことを合意しておいてください。
技術担当者は、社内リソースで対応可能な範囲を予め整理し、エスカレーション判定基準と問い合わせフローをあらかじめドキュメント化しておいてください。
ケーススタディ:成功・失敗から学ぶ判断基準
本節では、Ubuntu サーバで発生した二つの想定事例を通じ、「何をどう判断すべきか」「どの手順が有効だったか」を整理します。
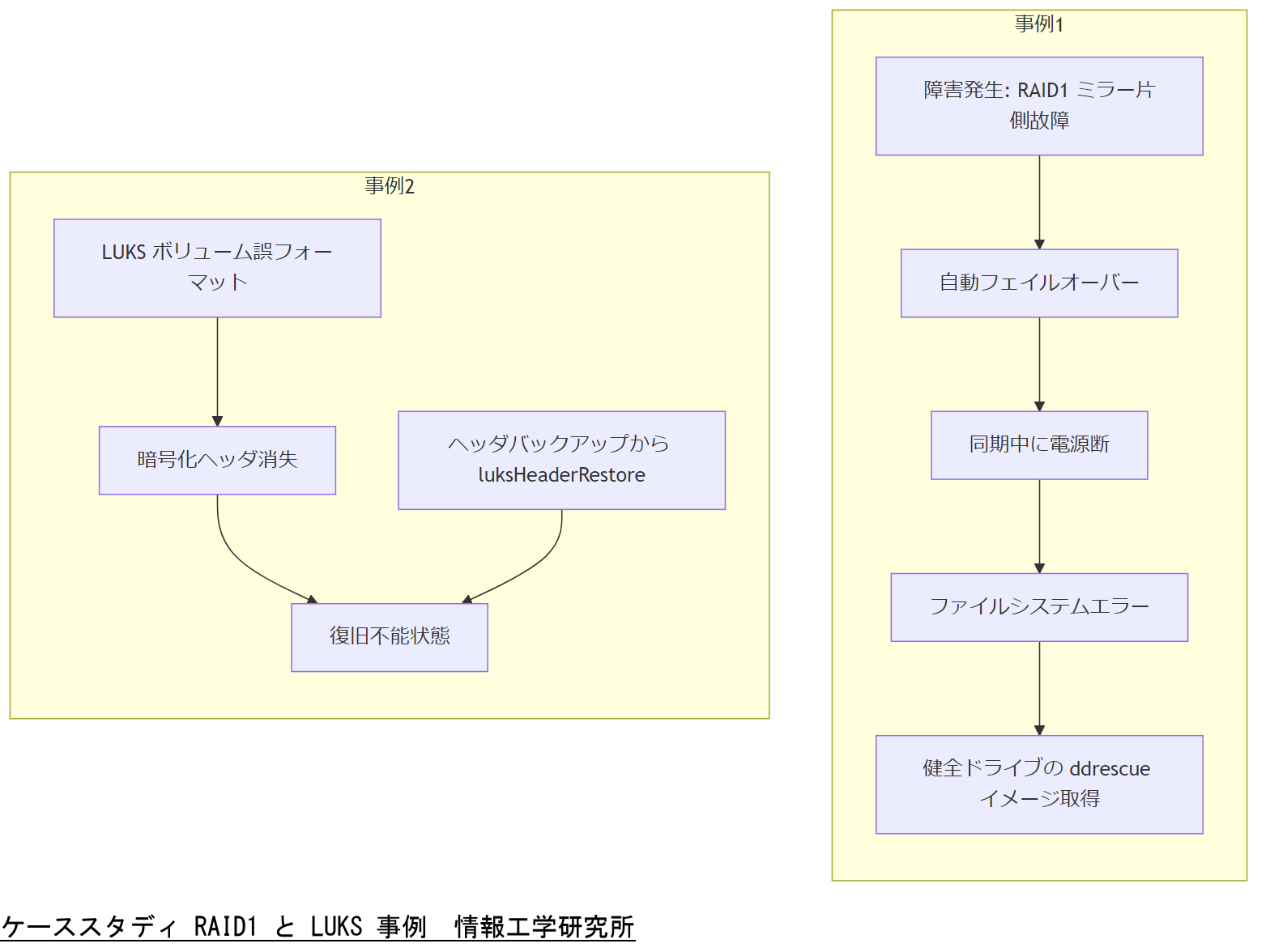
事例1:RAID1 ミラーの同期不整合によるデータ欠損
ある企業で RAID1 ミラー構成の一方ドライブに物理障害が発生し、自動フェイルオーバー後に復旧作業を実施。しかし、ミラー再同期中に電源断が重複し、一時的に両ドライブの整合性が崩れ、ファイルシステムエラーでサービス停止に至った。
- 失敗要因:再同期中の電源断に対するフェールセーフが未整備
- 有効手順:同期前に ddrescue で健全側のイメージを取得し、別環境で整合性チェック後に復元
- 学び:障害フェーズ毎のイメージ取得と同期手順を分離し、二次障害リスクを抑制する必要がある
事例2:誤操作による LUKS 暗号化ボリューム上書き
別のケースでは、管理者が誤って LUKS ボリュームを再フォーマットし、暗号化ヘッダが消失。バックアップヘッダも不適切に管理されていたため、一部データが復旧不能になった。
- 失敗要因:暗号化ヘッダバックアップの未保管
- 有効手順:事前に LUKS ヘッダを安全メディアへ保存し、cryptsetup luksHeaderRestore で復元
- 学び:暗号化環境では必ずヘッダバックアップ運用を義務化し、手順書に明記することが必須
それぞれの失敗要因と有効手順を対比し、「フェイルセーフ設計」と「暗号化ヘッダの運用管理」が核心要件である点を合意してください。
技術担当者は、自組織の類似システムで同様事例が起きうるか棚卸し、該当箇所への対策(自動バックアップスクリプトやフェイルオーバーテスト)を計画してください。
復旧後の検証と恒久対策
復旧作業が完了した後は、必ず復元データの整合性・可用性を検証し、再発防止に向けた恒久対策を策定・実施する必要があります。本章では、総務省・内閣府が示すガイドラインをもとに、検証手順と恒久対策のポイントを整理します。
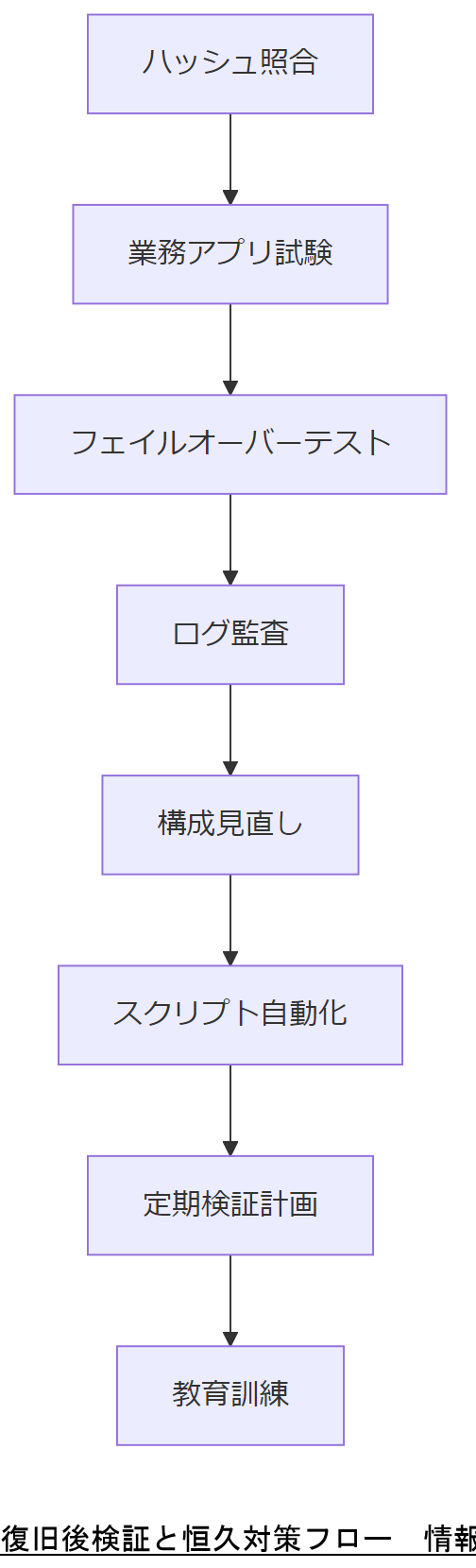
検証手順のステップ
- 復旧データのハッシュ値照合:バックアップ時のハッシュと照合し、データ破損がないか確認する。
- 業務アプリケーション試験:特定の業務フローを実運用データでテストし、機能・パフォーマンスに問題がないか検証する。
- フェイルオーバーテスト:BCP 計画に基づき、待機系への切替試験を実施し、手順・スクリプトの有効性を評価する。
- 監査ログ確認:ログ管理ガイドラインに従い、全操作ログの保存状況と改ざん防止措置を再チェックする。
恒久対策の策定
- 二重化構成見直し:障害点となった部分を強化し、必要に応じて三重化へ拡張する。
- 自動化スクリプト整備:復旧・検証プロセスを自動化し、作業時間を短縮するとともにヒューマンエラーを低減する。
- 定期検証スケジュール:BCP ガイドラインに従って、半年または年次で検証試験を実施し、計画の有効性を維持する。
- 教育・訓練:技術担当者向けに検証・復旧手順の定期研修を実施し、ナレッジを組織内で共有する。
「復旧後はハッシュ照合・業務試験・切替テスト・ログ監査を行い、その結果を踏まえた構成見直しと自動化/定期検証/教育研修を恒久対策とする」旨をご承認ください。
技術担当者は、検証結果をドキュメント化して経営層へ報告し、恒久対策のスケジュール化・予算確保を確実に進めてください。
コンプライアンス監査への備え
情報システム運用継続計画やセキュリティ管理策を文書化した後、継続的な維持改善と監査対応体制の構築が不可欠です。政府機関等における情報システム運用継続計画ガイドラインでは「維持改善の計画とその実施」を明示しており、定期的なレビューと内部監査を求めています。
監査計画と役割分担
- 内部監査責任者を指名し、運用継続計画(BCP)やセキュリティ管理基準への準拠状況を定期チェック。
- 各部門に文書管理担当者を配置し、法令・社内規定の改定時にドキュメントを更新・周知する体制を整備。
- 年度ごとに監査項目リストを作成し、是正措置の計画と実施期限を明確化する。
外部監査・第三者評価
- 政府機関等の対策基準策定ガイドラインでは、統一基準遵守の第三者評価を推奨しており、外部専門家による年次監査を計画する必要があります。
- 経済産業省「システム管理基準」に基づく外部監査では、運用計画及び運用実績の整合性を重点評価項目とします。
- 監査報告書を経営層へ提出し、改善計画を全社で共有・実行します。
監査結果のフォローアップ
- 監査指摘事項ごとに対応オーナーを設定し、是正措置レポートを作成・提出する。
- 次回監査までの改善状況トラッキングを行い、定期レビュー会議で報告。
- 監査結果を踏まえ、文書管理や運用手順を見直し、継続的な改善サイクルを推進します。
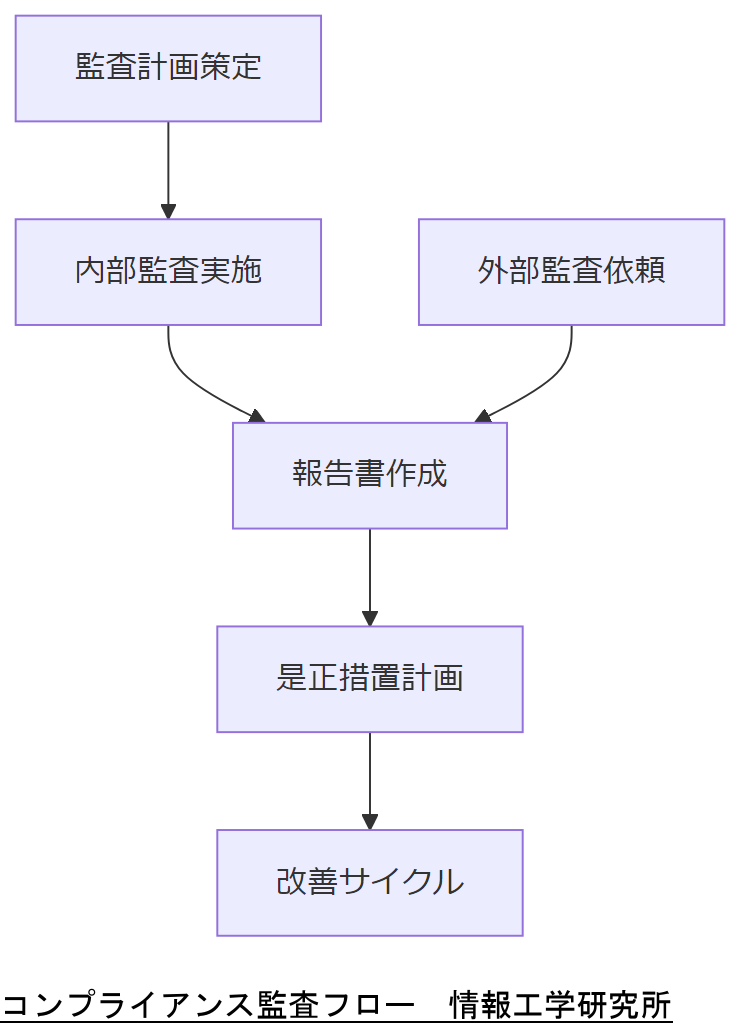
「内部監査と外部第三者評価を計画し、監査後の是正措置と改善サイクルを文書化している」点を経営層に承認いただいてください。
技術担当者は、監査チェックリストと是正措置一覧を常に最新版に保ち、監査時に速やかに証跡を提出できるよう準備してください。
まとめと次の一手
本記事では、Ubuntu 環境でのデータ復旧手順を初動から恒久対策まで体系的に解説しました。障害分類→証拠保全→ツール選定→各種構成復旧→BCP 運用→フォレンジック→法令対応→関係者報告→人材育成→外部エスカレーション→事例学習→検証→監査準備の全 15 ステップを網羅しています。
特に、証拠保全の正確な実施とBCP に基づく多層防御設計、監査対応体制の継続的改善は、情報漏洩リスクや業務中断リスクを最小化する鍵となります。
これらすべてのプロセスにおいて、弊社(株式会社情報工学研究所)は 最新の政府ガイドライン準拠かつ 国内最高水準の技術でサポートいたします。初動対応から監査対応まで、お問い合わせフォームからお気軽にご相談ください。

技術担当者は、本記事の各章を自社手順書として落とし込み、定期的な見直しと社内共有を通じて、常に最新かつ実践的な体制を維持してください。