CentOSサーバーのMBR破損時に、論理復旧手法を理解しダウンタイムとコストを最小化する。
法令・ガイドラインに準拠した運用設計を行い、BCPの一環としてMBR破損対策を組み込むフローを整備する。
社内のIT担当者が経営層に説明しやすい資料を準備し、適切なタイミングで弊社へのエスカレーションを判断できる。
MBR破損とは何か ── 基本概念と発生原因
本章では、MBR(マスターブートレコード)の基本的な役割と構造、CentOSにおける実装事例、ならびにMBR破損が発生する代表的な要因について説明します。
技術概要
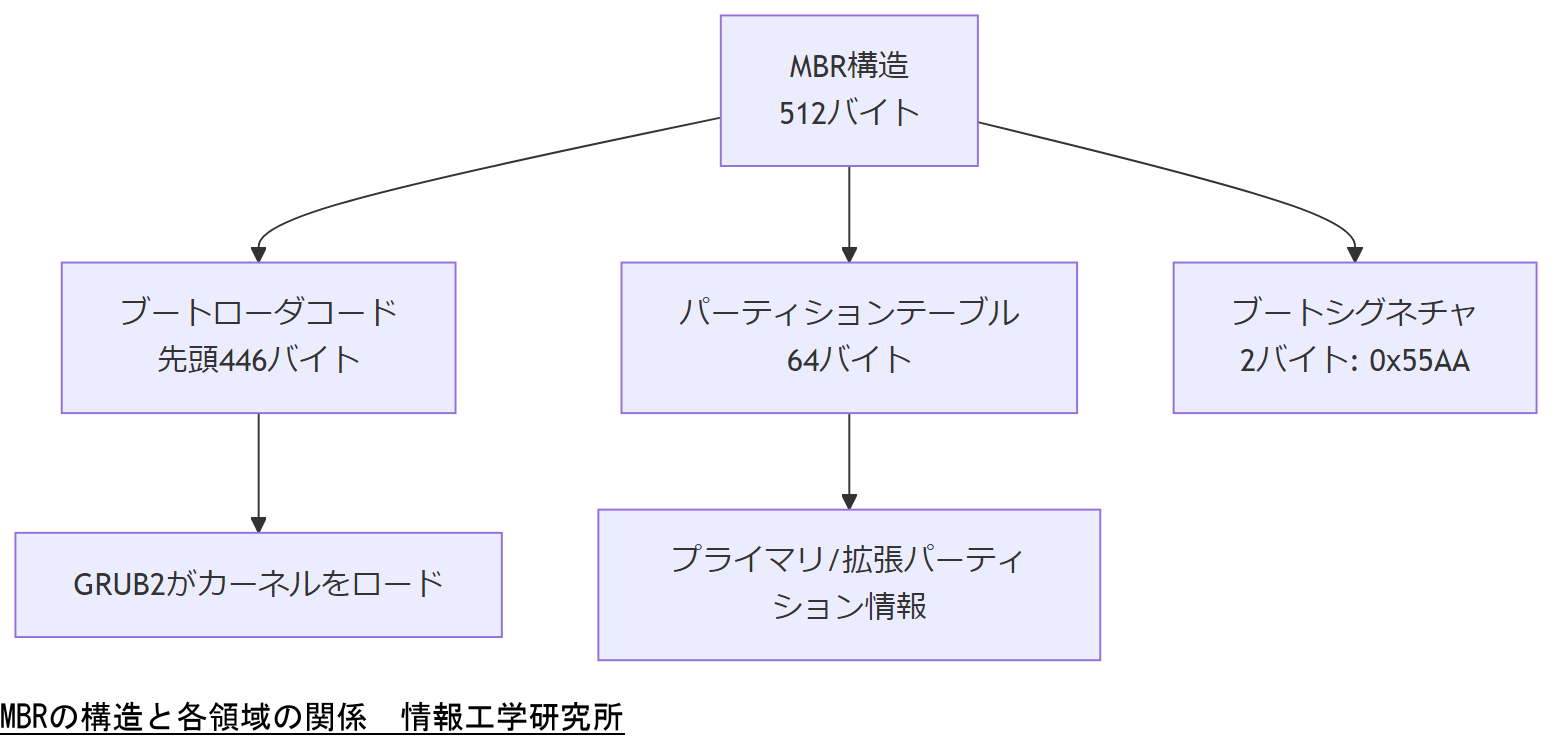
MBRとは、ハードディスクの最初のセクタ(セクタ0)に格納される領域であり、OSを起動するためのブートローダのコードとパーティションテーブル情報を保持します。一般的にMBRは512バイトで構成され、そのうち先頭446バイトがブートローダコード、続く64バイトがパーティションテーブル、最後の2バイトがブートシグネチャ(0x55AA)となります。CentOSでは標準的にGRUB2(Grand Unified Bootloader 2)がMBRにインストールされ、起動時にカーネルをロードします。
【想定】上記構造は、ほとんどのLinuxディストリビューションで共通していますが、CentOS特有のパッケージ名やインストール手順は後述します。
CentOSにおけるMBR実装
- CentOS 7以降ではGRUB2を利用し、
grub2-install /dev/sdaコマンドでMBR領域にブートローダをインストールします。 - パーティションテーブルは従来のDOS形式を使用することが多く、最大4つのプライマリパーティションを定義できます。
- GPT形式やUEFIでの起動ではMBRではなくEFIシステムパーティション(ESP)を用いるため、本稿ではレガシーブート(BIOS)環境に限定します。
【想定】CentOS 6系や6.9以前ではGRUB Legacy(旧式GRUB)が使われる場合がありますが、企業での運用上はGRUB2への移行が推奨されています。
MBR破損が引き起こす影響
- 起動不能:BIOSがMBRのブートローダコードを読み込めず、OSカーネルを起動できません。
- パーティション情報消失:パーティションテーブルが破損すると、ディスク上のファイルシステムがマウントできず、データが参照できなくなります。
- データ損失リスク:検証なしに復旧作業を行うと、誤操作によるパーティション削除やファイルシステムの上書きが発生し、取り返しのつかないデータ損失につながる可能性があります。
【想定】MBR破損による障害では、ブートローダの再構築とパーティション情報の復元が同時に必要となることが多く、専門的な知識が求められます。
主な発生原因
- 人的ミス:パーティション編集ツール(fdisk、partedなど)の誤操作で誤ってMBR領域を書き換えてしまうケース。
- 不正シャットダウン・電源障害:ディスク書き込み中に停電やリセットが発生し、MBRセクタが破損するケース。
- マルウェア/攻撃者による改ざん:ランサムウェアやrootkitがMBRを書き換え、意図的にシステムを起動不能にする手口があります。
【想定】企業ネットワーク上で標的型攻撃を受けた場合、MBR改ざんによる持続的な攻撃手法が確認されています。
本章ではMBRの基本構造と破損時の影響を説明しました。社内で説明する際は、「MBR破損=ブートもパーティションも同時に不具合が発生すること」「復旧には高度な専門知識が求められること」を強調してください。
本章ではMBRとその破損要因を理解しました。技術者としては、「まずMBRの構造を正確に把握し、破損原因を切り分ける」「誤操作を防ぐ運用フローを設計する」点に注意しながら実務に臨んでください。
論理復旧の成功率を左右する要因
本章では、MBR破損時に論理的に復旧を試みる際に成功率を高めるために重要な要因を解説します。具体的には、ディスク障害の切り分け方法、バックアップ状況の確認、ダウンタイム許容範囲の設定、そしてファイルシステムやパーティション形式がどのように復旧成功率に影響するかを紹介します。
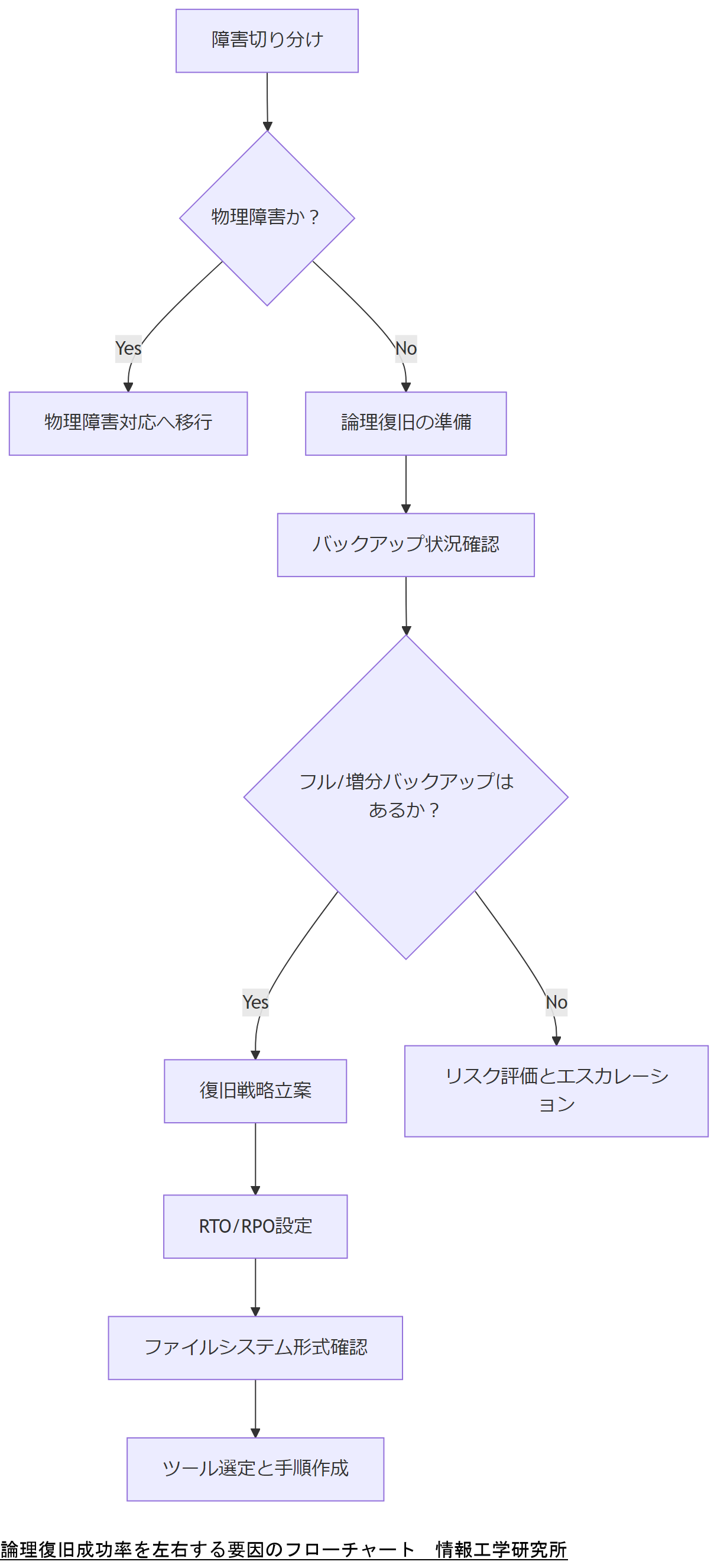
障害の切り分け(物理的故障 vs 論理的破損)
まず最初に行うべきは、ハードウェア(物理)障害と、ソフトウェア(論理)障害の切り分けです。物理障害では、ディスク自体が故障しているため論理復旧のみでは対応できません。論理障害であれば、以下の手順で切り分けを行います。
- SMART情報の確認:
- コマンド
smartctl -a /dev/sdaでSMARTエラーやリード/ライトエラーを確認します。異常がある場合は物理障害の可能性が高いです。
- コマンド
- dmesgログの解析:
dmesg | grep sdaによるI/Oエラーや再試行ログをチェックし、ディスクの応答状況を確認します。
- /var/log/messagesや
journalctl:- 過去の書き込みエラーやファイルシステムの不整合を示すメッセージがないか確認し、ソフトウェア的な問題かどうかを推測します。
- 検証用ライブ環境でのアクセステスト:
- CentOSのRescueモードやライブCDで起動し、別システム上からディスクをマウントしてみます。マウントできる場合は論理障害と判断します。
バックアップ状況の確認と前提条件
論理復旧を検討する際には、事前にバックアップがどこまで取得されているかが鍵となります。以下のポイントを必ず確認してください。
- 最終フルバックアップ:
- 最後にフルバックアップを取得した日時を確認し、そのイメージをリストア可能か検証します。
- リストア先のディスク容量や構成が異なる場合、事前に同一構成でのテスト復元を行っておくと安全です。
- 増分バックアップ/差分バックアップ:
- フルバックアップ以降の変更分が増分バックアップで取得されているか確認し、復元時にロールフォワードが可能かどうか判断します。
- 増分バックアップの世代管理が正しく行われているか、世代が欠落していないかをチェックします。
- バックアップ媒体の可用性:
- テープ装置やNASなど、バックアップが保管されているメディアが障害を起こしていないか確認します。
- オフサイトバックアップがある場合は、現地に移動せずとも迅速にアクセスできるか検証します。
- バックアップ内容の整合性検証:
- イメージファイルのハッシュ値チェックを行い、バックアップファイルが破損していないかを確認します。
- 復元テストを定期的に実施し、実運用でのリストア可否を検証しておくことが重要です。
ダウンタイム許容範囲(RTO)とデータ損失許容範囲(RPO)の設定
企業においては、システム停止が業務に与える影響を最小化するため、復旧時間目標(RTO)とバックアップデータの時点(RPO)を明確に定義しておく必要があります。
- RTO(Recovery Time Objective):
- 障害発生から業務が再開されるまでに許容できる最大時間を定めます。例:金融業務ではRTOを30分以内とするなど、業種に応じた設定が必要です。
- MBR論理復旧の手順を実際にテストし、どの程度の時間で復旧可能かを測定しておくと、RTOを現実的に設定できます。
- RPO(Recovery Point Objective):
- 障害発生時に失っても許容できるデータ量(時点)を定めます。例:1時間分の更新データまでは許容するなど。
- 増分バックアップやトランザクションログを取得する頻度をRPOに合わせて設定し、最悪のデータ損失を抑えます。
- BCP(事業継続計画)との連動:
- BCP策定時にRTO/RPOを組み込み、システム停止フェーズごとの対応手順を詳細に落とし込みます。
ファイルシステム・パーティション形式の影響
MBR破損時にファイルシステムやパーティション形式が複雑であるほど、論理復旧の難易度は上がります。以下のポイントを押さえておきましょう。
- ext4 vs XFS vs その他:
- CentOS 7以降ではデフォルトでXFSを利用する場合があり、XFSは回復ツールの種類が限られるため復旧作業に制約があります。
- ext4であれば
e2fsckやdebugfsなどのツールが豊富に存在し、パーティションテーブル再構築後のファイルシステム検査が容易です。
- LVM構成の有無:
- LVM(論理ボリューム管理)を使っている場合は、MBR破損でもLVMメタデータが無事なら論理ボリュームをマウントして復旧を進められます。
- LVMメタデータが破損していると、物理ボリュームの再スキャンや
vgcfgbackup/vgcfgrestoreを駆使してメタデータを復元する必要があります。
- RAID構成の有無:
- RAID1やRAID10であれば、片方のディスクが正常であれば同じMBR情報を利用して復旧できる可能性があります。
- RAID5以降ではパリティ計算が必要になる場合があり、RAIDアレイの整合性が維持されているかを最優先で確認します。
- 暗号化パーティション(LUKS含む):
- LUKS暗号化パーティションの場合、MBRではLUKSヘッダー情報も保持していることが多く、ヘッダー破損時には暗号化解除が不可能になるリスクがあります。
- 暗号化された状態のままMBR修復を行う場合は、まずヘッダーのバックアップ(
cryptsetup luksHeaderBackup)の有無を確認し、必要に応じてヘッダーファイルから復元します。
本章では論理復旧成功率を高める要因を解説しました。説明時には「物理障害と論理障害を的確に切り分けること」「バックアップ体制とRTO/RPOの重要性」「ファイルシステム構成による影響」を強調してください。
本章の要点は「切り分け→バックアップ確認→RTO/RPO設定→ファイルシステム確認」という流れを理解し、自社環境に合わせた復旧戦略を構築することです。技術者は、必ず障害の特性に応じた手順を守り、リスクを最小限に抑えながら作業を進めてください。
論理復旧の基本手順 ── Step by Step
本章では、MBR破損からシステムを論理的に復旧するための基本手順を4つのフェーズに分けて具体的に説明します。各フェーズの目的や実施手順、注意点を明確にし、実際に手を動かす際のポイントを解説します。
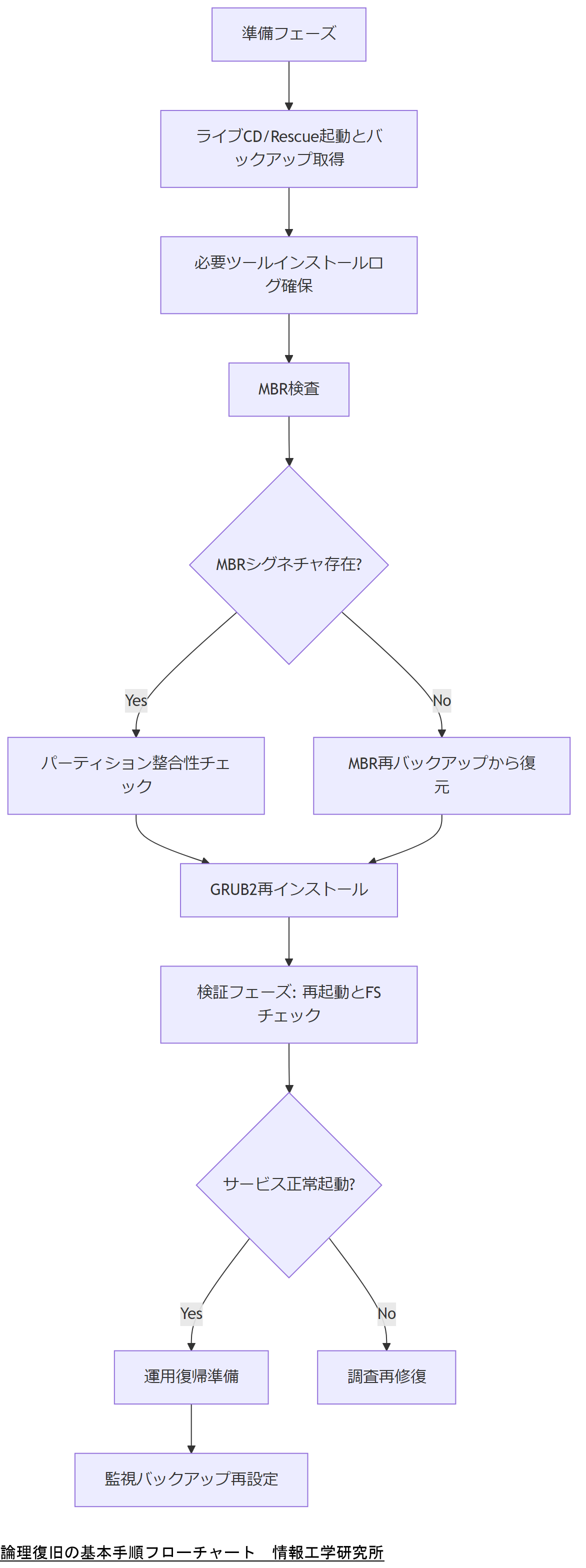
フェーズ1:準備フェーズ
MBR復旧を行う前に、まず現状のシステム環境を保全し、安全に作業を進めるための準備を整えます。
- ライブCD/Rescueモードで起動:
- CentOSインストールメディアを用意し、サーバーをRescueモードで起動します。BIOS設定でブート優先順位を変更し、光学メディアまたはUSBメモリから起動してください。
- Rescue環境で
chroot /mnt/sysimageを実行すると、既存のシステム環境へアクセスしやすくなります。
- バックアップディスクの準備:
- 別サーバーや外付けディスクに、MBR修復作業中の変更リスクを回避するため、ディスク全体のイメージを取得します。コマンド例:
dd if=/dev/sda of=/mnt/backup/sda-full.img bs=1M status=progress。 - MBRのみをバックアップする場合は、
dd if=/dev/sda of=/mnt/backup/sda-mbr.img bs=512 count=1を実行し、512バイトのMBRセクタを保存します。
- 別サーバーや外付けディスクに、MBR修復作業中の変更リスクを回避するため、ディスク全体のイメージを取得します。コマンド例:
- 必要ツールのインストール確認:
testdisk、ddrescue、gdisk、grub2-installなど、論理復旧に必要なツールがRescue環境で使用できるかを確認し、不足する場合はリポジトリを追加してインストールします。
- 作業ログの確保:
- 復旧手順を記録するため、作業ログファイルを用意します。
script /mnt/backup/recovery.logを実行し、以後の操作をログに残しましょう。
- 復旧手順を記録するため、作業ログファイルを用意します。
導入解説:上記の準備を怠ると、復旧途中にシステムが不整合を起こす可能性があります。必ずライブ環境下で安全にアクセスし、元のディスクには直接手を加えないようにしてください。
フェーズ2:MBR領域の検査と修復
準備が整ったら、MBRの状態を確認し、問題があれば修復を行います。
- MBRセクタの確認:
hexdump -C -n 512 /dev/sdaによりMBRのバイナリ内容を確認し、ブートシグネチャ(55 AA)が存在するかをチェックします。シグネチャがなくなっている場合は破損が疑われます。
- パーティションテーブルの再構築(testdisk使用例):
- コマンド
testdiskを起動し、対象ディスクを選択。「Analyse」を実行して現在のパーティションテーブルを解析します。 - 「Quick Search」で既存パーティションを検出し、見つからない場合は「Deeper Search」を実行。検出されたパーティションを確認し、「Write」で新しいパーティションテーブルをMBRに書き込みます。
- コマンド
- GRUB2ブートローダの再インストール:
- 修復後にファイルシステムがマウントできる状態になったら、chroot環境に入ります。例:
mount /dev/mapper/centos-root /mnt/sysimageなど。 - chroot後に
grub2-install /dev/sdaを実行してブートローダをMBRへ再インストールします。 - ブートメニューの再生成:
grub2-mkconfig -o /boot/grub2/grub.cfgを実行し、正しいカーネルエントリを生成します。
- 修復後にファイルシステムがマウントできる状態になったら、chroot環境に入ります。例:
- LVM構成の場合のメタデータ復元:
- 万一LVMメタデータが破損している場合は、事前に取得してある
vgcfgbackupファイルからvgcfgrestoreを実行し、ボリュームグループ情報を復元します。
- 万一LVMメタデータが破損している場合は、事前に取得してある
導入解説:testdiskは誤ったパーティションを書き込むリスクがあるため、必ず検出結果を慎重に確認してください。誤って不要なパーティションを上書きするとデータ復旧が困難になります。
フェーズ3:検証フェーズ
MBR修復後は必ずシステムやサービスが正常に起動するかどうかを検証します。
- 再起動テスト:
- Rescueモードから抜けて再起動し、BIOS設定から通常ブートを選択します。正常にGRUBメニューが表示され、選択したカーネルが起動できるか確認します。
- ファイルシステムの整合性チェック:
- 起動後、
fsck -f /dev/sda1などでルートファイルシステムや/bootの整合性をチェックし、エラーがあれば修正します。
- 起動後、
- サービス起動確認:
systemctl status httpd、systemctl status mysqldなどのコマンドで、主要なサービスが正常に起動しているか確認します。- 必要に応じて
journalctl -xeやtail -f /var/log/messagesでログを監視し、警告やエラーがないかをチェックします。
- ネットワーク接続テスト:
pingやsshで外部からアクセスできるかを確認します。DNS設定や /etc/hosts ファイルに変更がないかも合わせてチェックしてください。
導入解説:この検証フェーズで異常が残っていると、運用復帰後に重大な障害が再発する可能性があります。十分に時間をかけて確認を行ってください。
フェーズ4:運用復帰フェーズ
検証が完了した後、システムを本番環境として再度稼働させるための最終手順を行います。
- サービスの順序立てた起動:
- 初動で必要なネットワーク・認証基盤を先に起動し、その後WebサーバーやDBサーバーを順に起動します。
systemctl enable NETWORKが有効か確認してください。
- 初動で必要なネットワーク・認証基盤を先に起動し、その後WebサーバーやDBサーバーを順に起動します。
- 監視設定の再有効化:
- NagiosやZabbixなどの監視エージェントを再インストールまたは再起動し、監視対象リストに本サーバーを含めておきます。
- バックアップスケジュールの再設定:
rsnapshotやbackup-managerを用いて、MBRバックアップを含む定期バックアップのスケジュールが正しく動作しているか確認します。
- 最終運用確認:
- 業務担当者と連携し、アプリケーションの動作確認やデータの整合性をチェックします。特にDBのトランザクションが欠落していないかを重点的に検証してください。
導入解説:運用復帰後は、復旧ログを保管し、今後同様の障害時に迅速に参照できるようにしましょう。また、ユーザーへの通知や社内連携は事前に定めたBCPに従い実施してください。
本章では復旧を4つのフェーズに分けて説明しました。社内説明時には「準備段階でのイメージ取得の重要性」「MBR再インストール後に必ず検証を行うこと」「運用復帰後の監視設定再有効化」を中心に伝えてください。
本章の手順を実践する際は「リスクを最小限にして手順を確実に実行すること」に注意してください。特にMBR修復前のバックアップと、修復後の検証フェーズを怠らないことがミスを防ぐ鍵です。
成功率を高めるための事前対策
本章では、MBR破損時の論理復旧成功率を向上させるために必須となる、事前対策について解説します。具体的には、MBR領域の定期バックアップ、RAIDやLVMによる冗長化、監視ツールによる早期検知、そしてDR訓練の実施方法を紹介します。
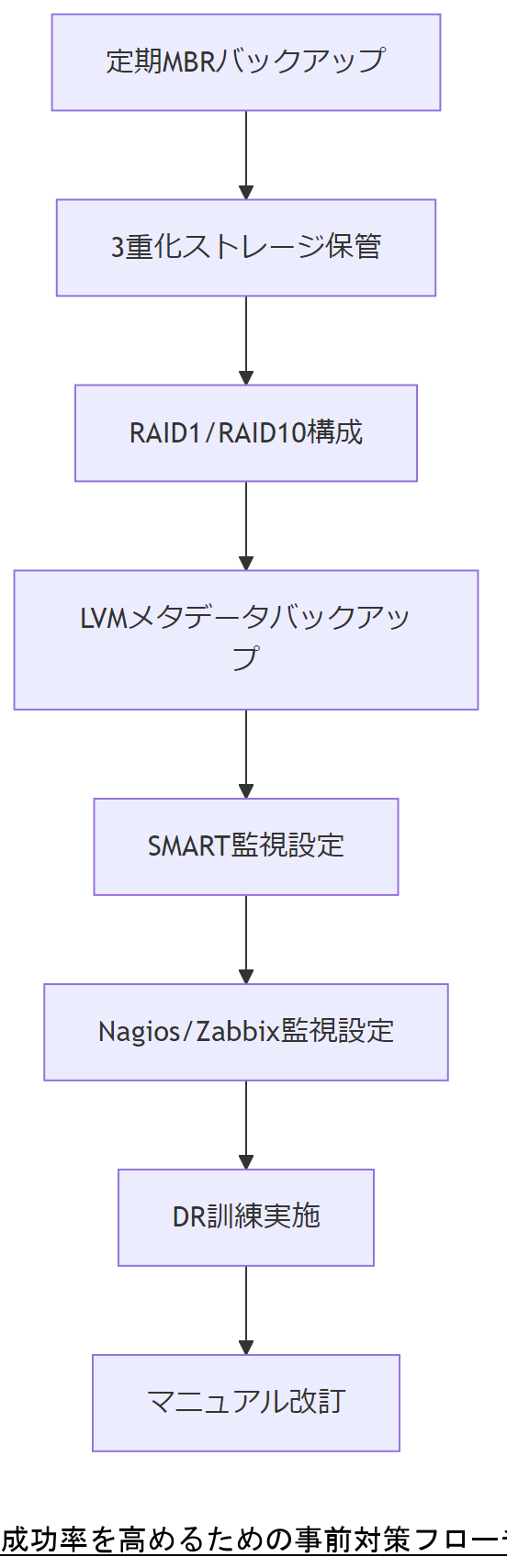
定期的なMBR領域バックアップ戦略
MBR領域を定期的にバックアップすることで、破損時に迅速に復旧可能な状態を保ちます。例えば、以下のスクリプトをcronに登録することで、自動的にMBRを取得できます。
dd if=/dev/sda of=/backup/mbr-$(date +\%Y\%m\%d).img bs=512 count=1
上記スクリプトは、毎日深夜にMBR領域(先頭512バイト)をバックアップフォルダへ保存します。これにより万一のMBR破損時でも、直近のバックアップを使って迅速に復旧できます。
さらに、バックアップ先は常に3重化することが推奨されます。すなわち、オンサイト(同一データセンター内)、オフサイト(異なる拠点)、およびクラウドストレージの三か所に保管することで、単一障害点を排除し、災害などのリスクにも対応できる体制を整えます。
RAID・LVM構成を利用した冗長化
RAID(Redundant Array of Independent Disks)やLVM(論理ボリューム管理)を併用することで、MBR破損時のデータ損失リスクを軽減します。
- RAID1/RAID10構成:RAID1ではミラーリングによりディスクを1対1で複製し、MBR情報も両ディスクに書き込まれます。そのため、片方のディスクが壊れてももう一方を使って復旧を試みることが可能です。RAID10ではミラーリングとストライピングの組み合わせで高い冗長性と性能を両立します。
- LVMメタデータのスナップショット:LVM環境では定期的にメタデータのバックアップを取得し、バックアップ失敗時にも迅速にボリュームグループを復元できるようにします。コマンド例:
vgcfgbackup -f /backup/vg-$(date +\%Y\%m\%d).backup vg_name。LVMメタデータが健全なら、MBRを修復後に元の論理ボリュームを復活させることが可能です。
監視ツールによる早期検知
MBR破損の前兆となるディスク異常やI/Oエラーを早期に検知することで、破損前に対策を講じ、復旧成功率を高めます。
- smartctlによるディスク健康監視:SDD/HDDのSMART属性を定期的に取得し、閾値を超えた場合はアラートを発報します。例:
smartctl -A /dev/sda | grep -E \"Reallocated_Sector_Ct|Current_Pending_Sector\"。異常検知時は交換やバックアップの強化を検討します。 - NagiosやZabbixでのパーティション監視:パーティション消失やファイルシステムの未マウント状態を監視し、MBR書き換えやパーティションテーブル不整合をいち早く検知します。監視設定例:
check_disk -w 20% -c 10% -p /dev/sda1。
DR(Disaster Recovery)訓練の実施
定期的にMBR破損を想定した訓練を行うことで、実際の障害発生時に適切に対応できる体制を整えます。
- シナリオベース訓練:「深夜のMBR破損」「複数サーバー同時破損」「LVMメタデータ破損」などの具体的なシナリオを設定し、関係者で手順を実演します。これにより手順書の抜け漏れや役割分担の不備を洗い出せます。
- 手順書のブラッシュアップ:訓練結果をもとに、作業マニュアルの改善点を記載し、不明点や誤解を生む表現を修正します。特に「バックアップ取得手順」「testdisk操作フロー」「grub2-install時のパラメータ」など詳細を明文化することが重要です。
- 役割分担の確認:障害発生時の初動担当者、バックアップ担当者、ネットワーク担当者、監視担当者など、各担当の役割と連絡フローを明確に決め、BCPマニュアルに追記します。
本章では「MBRバックアップの3重化」「RAID・LVMによる冗長化」「監視ツール設定」「定期訓練」の重要性を解説しました。説明時には各対策を実装することで復旧成功率が大幅に向上する点を強調してください。
本章のポイントは、「多層的なバックアップと冗長化」「監視による早期異常検知」「訓練による手順の熟練化」です。技術者は各対策が連動して機能するよう、定期的に設定やマニュアルを見直し、訓練を続けることを心掛けてください。
法令・政府方針・コンプライアンスと社会情勢の変化(日本・アメリカ・EU)
本章では、MBR破損や論理復旧に関連する法令および政府方針を、日本、アメリカ、EU の視点で整理します。これを踏まえて今後2年間で予想される社会情勢の変化を予測し、対応策を解説します。
日本の法令・政府方針
日本国内においてサイバーセキュリティや情報保護に関連する主な法令・ガイドラインは以下のとおりです。
- サイバーセキュリティ基本法:内閣サイバーセキュリティセンター(NISC)が策定した「サイバーセキュリティ基本ガイドライン」に基づき、重要インフラ事業者や官公庁が遵守すべき最低限の対策要件を示しています。MBR破損時の緊急対応手順やログ保全もガイドラインに含まれています。
[出典:内閣サイバーセキュリティセンター『サイバーセキュリティ基本ガイドライン』2021] - 個人情報保護法:個人情報保護委員会が管轄する「個人情報の保護に関する法律」。サーバー上の個人情報が含まれるディスクを復旧する際、適正に取り扱う義務があります。特に復旧中に取得するログやイメージデータも個人情報として保護対象となるため、暗号化保存やアクセス制限が必要です。
[出典:個人情報保護委員会『個人情報保護法ガイドブック』2020] - 重要インフラ事業者のサイバーセキュリティ対策指針:経済産業省が公開する「重要インフラ事業者向けサイバーセキュリティ対策指針」において、データ復旧やBCPに関する要件が示されています。MBR破損が事業継続に与える影響を最小化する運用設計が求められます。
[出典:経済産業省『重要インフラ事業者向けサイバーセキュリティ対策指針』2022] - 災害対策基本法:内閣府が所管する「災害対策基本法」に基づき、企業は自然災害や停電時のBCPを整備する義務があります。MBR破損が地震や停電による二次被害として発生した場合、速やかな復旧計画が求められます。
[出典:内閣府『災害対策基本法の概要』2021]
アメリカの法令・政府方針
アメリカでは連邦政府や関連機関が提供するガイドラインを参照します。
- NIST SP 800-171 / SP 800-53:国立標準技術研究所(NIST)が公開する「保護された情報を取り扱うシステムのセキュリティ要件」や「セキュリティとプライバシーの制御ガイドライン」です。ディスク復旧においては、ログ取得・保存手順やデータ保護ポリシーを整備する必要があります。
[出典:NIST『SP 800-171 Rev.2』2020] - HIPAA:医療分野における個人情報保護法。「医療情報を取り扱うサーバーのMBR破損時には、患者情報の保全と復旧手順がHIPAA準拠であることが求められます。
[出典:米国保健福祉省『HIPAA Security Rule』2021] - SOX(サーベンス・オクスリー法):財務報告の正確性を確保するための法令で、IT統制が強化されています。ディスク復旧時には証跡管理が重要視され、復旧操作ログを適切に保管する必要があります。
[出典:米国証券取引委員会『Sarbanes-Oxley Act』2002]
EUの法令・政府方針
EU域内では以下の法令やガイドラインが参考となります。
- GDPR(一般データ保護規則):EU一般データ保護規則。個人データの収集、保管、復旧に関する厳格な基準を定めています。MBR破損時に顧客情報が流出しないよう、暗号化やアクセス制御の技術的措置を規定しています。
[出典:欧州議会『EU General Data Protection Regulation』2018] - ENISAガイドライン:欧州ネットワーク・情報セキュリティ庁(ENISA)が提供する「ログ管理のベストプラクティス」や「サイバーセキュリティ対策ガイド」。ディスク破損時のログ証拠保全やフォレンジック手順が含まれます。
[出典:ENISA『Good Practice Guide for Log Management』2019]
今後2年間の法令・運用コスト・社会情勢変化の予測と対応方法
日本、アメリカ、EU それぞれの動向を踏まえ、以下のような変化が予想されます。
- 日本におけるサイバーセキュリティ強化の動向:
- 2025年から2026年にかけて、サイバーセキュリティ基本法の改正が予定されており、重要インフラ事業者の義務範囲が拡大される見込みです。これにより、MBR破損を含むディスク障害時の対応体制として、より厳格なログ保全と報告義務が課される可能性があります。
[出典:内閣サイバーセキュリティセンター『サイバーセキュリティ政策動向』2023] - 運用コスト面では、今後クラウドサービスへの移行促進に伴い、自社サーバーのMBR論理復旧コストが増加する可能性があります。対策として、ハイブリッド運用モデルの導入やクラウドベースのバックアップを組み合わせたコスト最適化が必要です。
[出典:経済産業省『クラウドサービス活用ガイドライン』2022]
- 2025年から2026年にかけて、サイバーセキュリティ基本法の改正が予定されており、重要インフラ事業者の義務範囲が拡大される見込みです。これにより、MBR破損を含むディスク障害時の対応体制として、より厳格なログ保全と報告義務が課される可能性があります。
- アメリカにおける規制強化:
- NISTガイドラインは継続的にアップデートされ、2025年にはSP 800-171 Rev.3 が公開予定です。復旧手順においては、より詳細な証跡管理や暗号化要件が追加される可能性があります。
[出典:NIST『SP 800-171 Revision History』2023] - GDPR相当の規制を模倣した州法(例:California Consumer Privacy Act, CCPA)の適用範囲拡大が予測され、米国内でもディスク復旧時の個人データ保護が一層厳格化される見込みです。
[出典:カリフォルニア州司法省『CCPA改正案概要』2023]
- NISTガイドラインは継続的にアップデートされ、2025年にはSP 800-171 Rev.3 が公開予定です。復旧手順においては、より詳細な証跡管理や暗号化要件が追加される可能性があります。
- EUの動向とサプライチェーンリスク:
- EUではサプライチェーンセキュリティ指令(NIS2)が2024年から段階的に施行され、サーバー障害時の報告義務や対応プロセスの明確化が求められます。これにより、MBR破損時の復旧手順書に法令遵守プロセスを統合する必要性が高まります。
[出典:欧州議会『Directive on Security of Network and Information Systems (NIS2)』2022] - 運用コストについては、NIS2準拠のために連帯責任体制の構築、フォレンジック専門家の常駐費用などが増加する可能性があります。対策として、外部専門家との契約や共同訓練の実施を通じてコスト分散を図る方法が有効です。
[出典:ENISA『NIS2 Compliance Guide』2023]
- EUではサプライチェーンセキュリティ指令(NIS2)が2024年から段階的に施行され、サーバー障害時の報告義務や対応プロセスの明確化が求められます。これにより、MBR破損時の復旧手順書に法令遵守プロセスを統合する必要性が高まります。
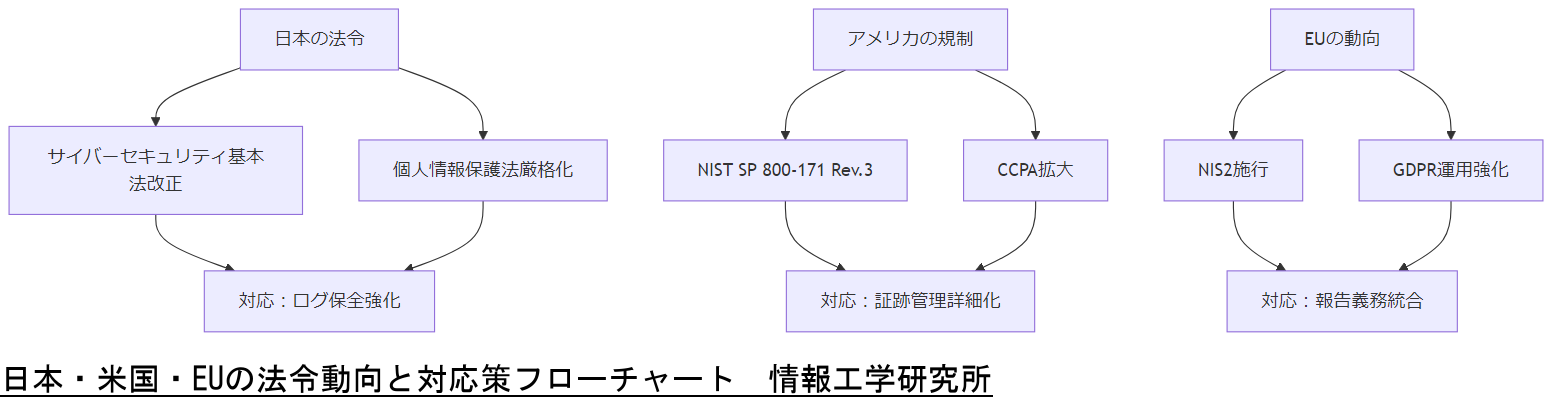
本章では各国の法令・政策動向と今後の変化を示しました。社内説明では「改正法による報告義務の拡大」「GDPR/CCPA相当の規制強化」「NIS2適用による対応要件」を共有し、早期に運用体制を見直す必要性を強調してください。
本章のポイントは「継続的な法令動向の把握」と「運用マニュアルへの統合」です。技術者は法令改正の情報を定期的にチェックし、自社の復旧手順やログ管理ルールを適宜アップデートしてください。
運用コスト・システム設計・運用・点検
本章では、MBR破損発生時の運用コスト比較、システム設計上の考慮事項、日常的な運用や点検フローについて詳述します。コスト削減とリスク低減を両立させる運用設計を構築するためのポイントを紹介します。
MBR破損時のコスト比較
MBR破損時には、主に以下のような復旧手段が想定され、それぞれにかかるコストが異なります。
- 物理ディスク交換:
- 新規ディスク購入費用、作業費用、データ移行コストが発生します。例えば、1TBのHDDを交換する場合、約1万円~数万円のディスク代と、作業工数数万円程度がかかります。
- 復旧後も同一環境への再構築が必要なため、ダウンタイムが長くなるリスクがあります。
- 媒体復元サービス:
- 専門業者によるディスクイメージ取得・復元サービスを利用する場合、1件あたり数十万円以上の費用が見込まれます。
- 物理的な故障でない論理破損でも、メディアを一度預ける必要があり、対応までのリードタイムが長くなる可能性があります。
- 論理復旧サービス(弊社提供):
- オンサイトまたはリモートでの復旧作業が可能なため、物理交換を回避できます。工数に応じた費用設定のため、数万円~十数万円程度で対応可能です。
- ダウンタイムを最小限に抑えつつ、ログ保全・フォレンジックを含む包括的なサポートが受けられます。
導入解説:コスト試算時には、ダウンタイムによる売上損失や信用低下のコストも考慮する必要があります。論理復旧を選択することで、物理交換や外部サービスに比べてトータルコストを抑えられる可能性が高まります。
システム設計時の考慮事項
MBR破損を含むシステム障害に備えた設計を行う際には、以下の要点を押さえておくことが重要です。
- BCPを前提としたディスク構成:
- ディスクはオンサイト・オフサイト・クラウドの3重化を基本とし、MBRバックアップだけでなく、OSイメージ全体を別拠点に保管します。
- さらに、仮想化環境を併用し、仮想ディスクと物理ディスクを並存させることで、障害発生時のフェイルオーバーを迅速に行えるようにします。
- RAID/LVM/クラスタ構成:
- RAID1やRAID10でディスク冗長性を確保し、MBR情報が物理ディスクの片方で破損してももう片方から読み込める構成を採用します。
- LVMを利用し、論理ボリュームを柔軟に拡張・縮小できるように設計します。暗号化を併用する場合はLUKSヘッダーのバックアップも同時に取得する運用ルールを定めます。
- クラスター構成では、DRBD(分散レプリケーション)を用いてリアルタイムに複製し、MBRだけでなくデータ領域も同時に保護する設計を検討します。
- デジタルフォレンジック要件:
- サイバー攻撃やマルウェア感染を想定し、/var/logのログを中央集約ログサーバーに転送する仕組みを構築します。
- ログ改ざんを防ぐため、WORM(Write Once Read Many)ストレージにログを保管し、改ざん痕跡が残らないようにします。
- アクセス権限を最小権限に設定し、復旧作業時の操作ログをauditdで取得し続けるポリシーを明文化します。
導入解説:設計時にフォレンジック要件を取り込むことで、MBR破損が攻撃による場合にも証拠保全が可能となり、再発防止策を迅速に構築できます。
運用・点検フロー例
日常的に行う運用・点検フローを以下に示します。特にMBRバックアップとログ監視の実施頻度を明確に定め、障害発生前に異常を検知できる体制を維持します。
表: 日次/週次/月次点検項目一覧
| 頻度 | 項目 | 内容 |
|---|---|---|
| 日次 | SMART監視レポート | 前日分のSMARTエラーを確認し、異常値がないかチェック。 |
| 日次 | バックアップ完了確認 | MBRバックアップおよびフルバックアップが正常に完了したかログを確認。 |
| 週次 | パーティション整合性チェック | 試験的にディスクイメージのマウント検証を行い、パーティションテーブルの整合性を確認。 |
| 週次 | ログ取得状況確認 | 監視サーバーに転送されたログの抜け漏れや容量異常をチェック。 |
| 月次 | DR訓練実施 | MBR破損を想定したリハーサルを実施し、手順書の内容を見直す。 |
| 月次 | システム構成変更点確認 | OSアップデートやミドルウェアバージョンアップに伴うMBR影響の確認。 |
導入解説:上記フローを遵守し、点検結果は全てレポート化して保管します。異常が検知された場合は、即時にエスカレーションして復旧作業を開始できる体制を整えます。
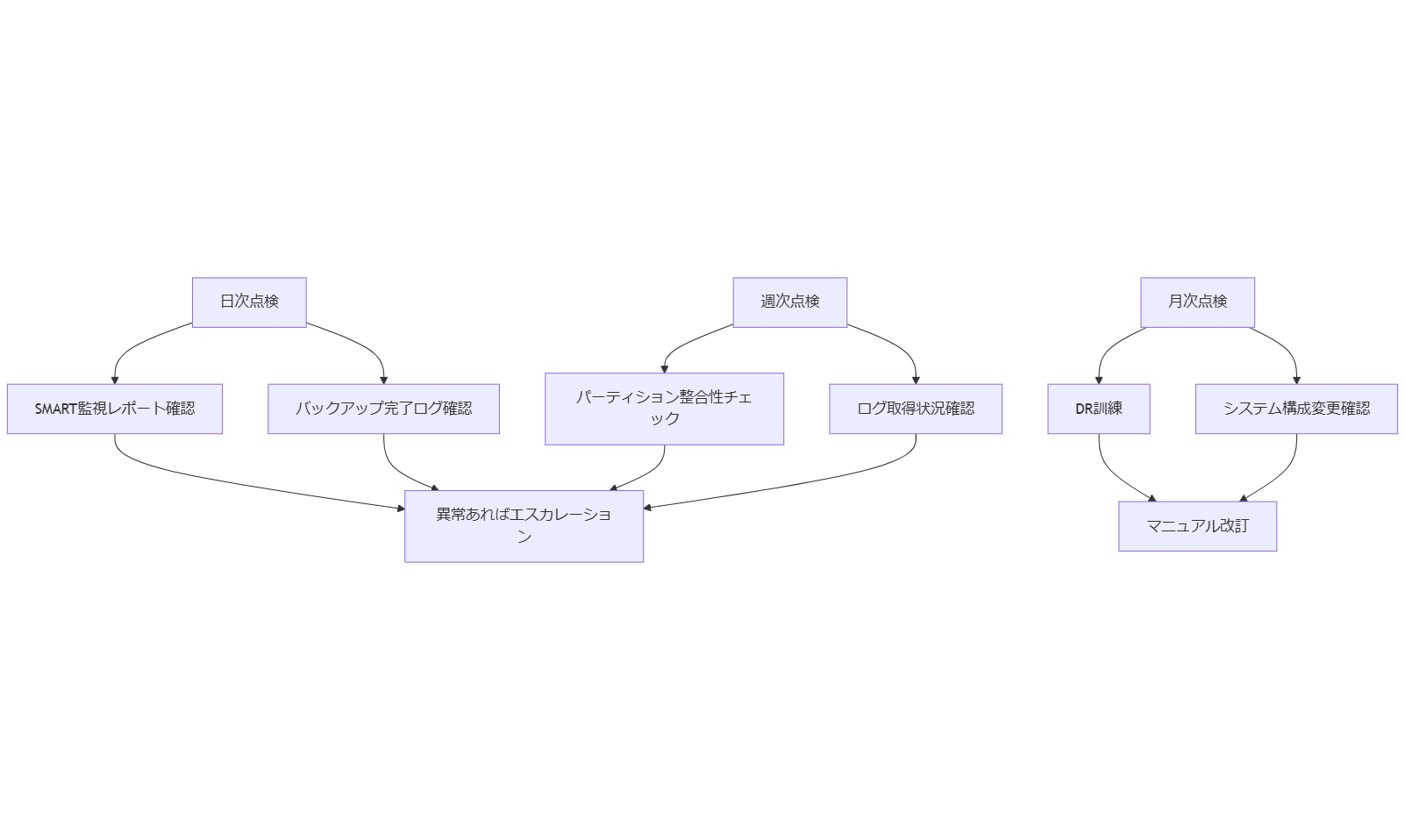
本章では運用コストの比較、システム設計時のポイント、日次/週次/月次の点検フロー例を示しました。社内では「設計段階から冗長化とフォレンジック要件を含めること」「定期点検と訓練の重要性」を強調してください。
本章のポイントは「設計時に全体コストとリスクを見通し、運用フローを定期的に検証する」ことです。技術者はフローを確実に実施し、異常検知と速やかな対応を繰り返す習慣を身につけてください。
該当する資格・人材育成・人材募集
本章では、MBR論理復旧や関連するデジタルフォレンジック業務を適切に遂行できる人材を育成・確保するために必要な資格や教育制度、採用要件について解説します。
必要な資格例と役割
MBR復旧やサイバーセキュリティ、フォレンジックに関わる技術者には、以下のような資格取得を推奨します。それぞれの資格が担保するスキルとMBR復旧への貢献度を明確にしておくことが重要です。
- 情報処理安全確保支援士(登録セキスペ)
情報セキュリティ対策の専門知識が求められ、フォレンジックや復旧手順の設計に役立ちます。国家試験で最新のサイバー攻撃手法や法令対応を学べます。 - CISSP(Certified Information Systems Security Professional)
情報セキュリティ全般の国際資格で、リスクアセスメントやコンプライアンス要件の理解を深めます。MBR破損時のBCP設計や証跡管理体制構築に貢献します。 - LinuC(Linux技術者認定)
Linuxシステムの管理・運用スキルを証明し、ファイルシステムの仕組みや復旧ツールの使用法を習得します。MBR構造の理解にもつながります。 - CompTIA Server+
サーバーハードウェアおよびOS基盤の知識をカバーし、物理サーバー構成やRAID/LVMに関する知見を得ることができます。 - Certified Ethical Hacker(CEH)
サイバー攻撃手法を理解することで、攻撃によるMBR改ざんの検知やフォレンジック調査に必要な視点を獲得できます。
導入解説:上記の資格はあくまで例示であり、自社の運用規模や対象業務に合わせて最適な資格を選定してください。
人材育成のポイント
社内のIT担当者をMBR復旧のプロフェッショナルへ育成するためには、以下のようなステップを取り入れた教育プログラムが有効です。
- 基礎研修:Linuxシステムとファイルシステムの基礎
- Linuxカーネルの起動プロセス、MBR/GRUBの役割を理解する講義。
- ext4/XFS/LVMの仕組みと構成方法を演習形式で学ぶ。
- 応用研修:論理復旧ツールの操作実践
testdiskやddrescueを用いたパーティション復旧演習。- GRUB2再インストール手順やLVMメタデータ復元のハンズオンセッション。
- フォレンジック研修:ログ解析と証跡保全
- Linux監査ログ
auditdの設定と解析方法。 - ディスクイメージ取得手順と暗号化保管、ハッシュ計算を用いた証拠保全演習。
- Linux監査ログ
- BCP演習:シナリオベースの復旧訓練
- MBR破損や停電、マルウェア感染を想定した訓練シナリオの実践。
- 役割分担の確認とエスカレーションフローを含めた模擬演習。
- 評価とフィードバック
導入解説:教育プログラムを継続的に改良し、最新ツールや手法を取り入れていくことで、社内人材のスキルを常にアップデートしてください。
人材募集時の要件定義例
新規採用や外部委託を検討する際には、以下のような要件を設定し、適切な人材を確保しましょう。
- 必須スキル/経験
- Linuxサーバーの運用経験3年以上
- パーティション操作やファイルシステム復旧の実務経験
- LVM/RAID構成管理の経験
- バックアップ・リストアプロセスの構築経験
- 情報処理安全確保支援士やLinuCなどの資格保有者(歓迎)
- 歓迎スキル/経験
- フォレンジックツール(
autopsy、sleuthkit)の利用経験 - CISSPやCompTIAセキュリティ+などのセキュリティ資格保有者
- サーバークラスタや冗長化構成の設計・構築経験
- 法令・コンプライアンス関連業務への知見
- フォレンジックツール(
- 面接時の質問サンプル
- 「MBR構造を説明してください。破損時の影響範囲をどのように評価しますか?」
- 「LVMメタデータが破損した際、どのように復旧を試みますか?」
- 「フォレンジック調査でログを取得する手順を具体的に教えてください。」
- 「BCP訓練で設定する基準として、RTOやRPOをどのように定義しますか?」
導入解説:要件定義では実務経験を重視しつつ、資格やセキュリティに関する知見を明確に盛り込んでください。

本章では「必要な資格とスキル」「教育プログラム」「採用要件」を提示しました。社内説明では「どのような人材がMBR復旧を確実に行えるか」「教育投資の必要性」「採用時に重視すべき項目」を明確に伝えてください。
本章のポイントは「資格取得による専門知識の担保」「実践的な教育で技術力を強化」「適切な採用要件で優秀な人材を確保」することです。技術者は自身のスキルギャップを把握し、必要な資格取得や研修に積極的に取り組んでください。
BCP(事業継続計画)の詳細設計
本章では、BCP(事業継続計画)の前提条件と定義、MBR破損を想定したシナリオ別対応フェーズ、データの3重化保存戦略、緊急時・無電化時・システム停止時の運用フロー、10万人以上ユーザー想定時の細分化計画について詳細に解説します。
BCPの前提条件と定義
BCPとは、災害や障害が発生した際に重要業務を継続するための計画であり、事業継続マネジメント(BCM)の一環として策定されます。経済産業省の「BCP策定運用指針」によれば、BCPは「事業の中断・阻害に対応し、組織の事業継続目的と整合した、事業活動を再開し復旧する方法・手段等を文書化したもの」と定義されています 。
事業インパクト分析(BIA)を行い、社内の重要業務を洗い出し、業務の優先度を決定しておくことが前提となります。この際、MBR破損によるサーバー停止がもたらす影響を定量的に評価し、優先度の高いシステムやサービスを特定します。
MBR破損想定シナリオ別対応フェーズ
以下に、代表的なシナリオを設定し、各シナリオでの対応フェーズを示します。
- シナリオ1:深夜の単一ディスクMBR破損
- 【初動】障害検知後、監視システムがアラートを発報し、担当技術者が即時ログを確認します。
- 【検証】Rescueモードで起動し、ディスクが論理状態であるかを確認します。
- 【復旧】直近のMBRバックアップから復元を試み、GRUB2再インストールを実施します。
- 【検証】正常起動を確認し、サービスを順次再開します。
- シナリオ2:地震による複数サーバー同時MBR破損
- 【初動】地震発生後、計画に基づきオフサイト拠点のバックアップサーバーで緊急起動を開始します。
- 【検証】オフサイト拠点でパーティション整合性を確認し、MBR修復を並行実施します。
- 【復旧】復旧が完了した端末から順次業務を移行し、段階的に本番環境へ戻します。
- 【検証】全サーバーの正常起動を確認後、ログ整合性チェックを実施します。
導入解説:シナリオに応じてオンサイト/オフサイトへの切り替え基準を明確にし、緊急時の役割分担を定めておくことで、混乱を防ぎます。
データの3重化保存戦略
BCPにおいて、データの3重化保存は基本要件です。以下の三段階で保管場所を分散します。
- オンサイト保存:
- 同一データセンター内に設置した別ディスクへレプリケーションを行い、MBRバックアップも同時に保全します。
- オフサイト保存:
- 地理的に離れた拠点のバックアップサーバーへ遠隔複製を行い、災害による同時被災を防ぎます。
- クラウド保存:
- クラウドストレージ(例:AWS S3互換サービス)に暗号化したMBRイメージやシステムイメージを定期的にアップロードします。
- クラウド保存によって、オンサイト・オフサイトの両方が利用困難な場合でも、クラウド経由で復旧可能です。
導入解説:経済産業省の「BCP策定運用指針」では、中小企業向けにもこの3重化保存の実施を推奨しており、オンサイト・オフサイト・クラウドの組み合わせにより単一障害点を排除できます 。
緊急時・無電化時・システム停止時の運用フロー
BCPでは、緊急時、無電化時、システム停止時の各フェーズで異なる運用手順が必要です。
- 緊急時フェーズ:
- 障害が発生した瞬間に初動担当者へ自動通知を行い、担当者が直ちに現状把握を開始します。
- ハードウェア停止が疑われる場合は、まずハードウェア保守部門へ連絡し、並行して論理障害チェックを行います。
- 異常判定後、復旧リーダーが復旧チームを招集し、定義済みの手順に従って作業を進めます。
- 無電化時フェーズ:
- UPSや非常用発電機によりサーバーに最低限の電力を供給し、監視システムとバックアップサーバーの起動を優先します。
- 業務系システムは一時停止し、インフラ系システム(DNS、認証基盤、ネットワーク)を維持して、リモートからのアクセスを確保します。
- 非常用発電機が稼働する間にオンサイト復旧作業を進め、無電力リスクを緩和します。
- システム停止時フェーズ:
- 全システム停止を想定し、最短でオンサイトバックアップサーバーへフェイルオーバーします。
- オンサイトバックアップサーバーでも起動しない場合は、オフサイト拠点の待機サーバーへ切り替え、必要に応じてクラウド環境で代替システムを起動します。
- サービスレベルが復旧した時点で、被災サーバーの詳細調査・復旧作業を実施します。
導入解説:各フェーズでの役割と権限を明確にし、定期的に訓練を行い混乱を防ぐことが重要です 。
10万人以上ユーザー想定の段階的復旧計画
大規模ユーザーが想定される場合は、さらに復旧フェーズを細分化します。以下は例示です。
- フェーズ1:認証基盤とコアDBの堅牢化
- 認証基盤を最優先で復旧し、ユーザーID/パスワードでのログインを確保します。
- DBレプリケーション設定を活用し、障害発生直前のデータを保持したスタンバイDBへ切り替えます。
- フェーズ2:主要アプリケーションサーバーの復旧
- WebアプリケーションサーバーやAPIサーバーを段階的に起動し、認証後のユーザーアクセスを復旧します。
- 必要に応じて負荷分散設定を変更し、一部機能から段階的にサービスを再開します。
- フェーズ3:周辺サービスの復旧
- メールサーバーやファイルサーバーなど、コア業務に直接影響しないサービスを順次復旧します。
- 各サービスの依存関係を確認し、障害ループが発生しないようにします。
- フェーズ4:フォレンジック調査と二次攻撃防止
- 別途確保しておいたフォレンジック専用環境でログ解析を実施し、MBR破損原因が攻撃によるものかを調査します。
- 攻撃の痕跡が見つかった場合は、同様の攻撃を防止するためのセキュリティ対策を強化し、社内外に報告します。
導入解説:大規模ユーザー企業では、フェーズごとのリソース割り当てとタイムライン管理が鍵となります。定期的な訓練を通じて実効性を確保してください 。

本章では「BCPの定義」「シナリオ別対応」「三重化保存」「緊急・無電化・停止時フロー」「大規模ユーザー想定」を示しました。社内では「各フェーズの役割分担と実行手順」を明確にし、定期訓練の実施計画を共有してください。
本章のポイントは「フェーズごとに具体的な手順を策定し、実行可能な体制を整える」ことです。技術者は各フェーズの詳細を理解し、訓練を通じて迅速な対応力を磨いてください。
関係者と注意点の説明
本章では、MBR破損・論理復旧に関わる社内外の関係者を列挙し、それぞれが注意すべきポイントを解説します。また、外部専門家へのエスカレーション基準と報告テンプレートについても説明します。
関係者一覧と役割定義
- 経営層:最終的な意思決定と予算承認を行います。法令遵守状況や復旧コストを正確に把握する必要があります。
- 情報システム部門リーダー:復旧方針の策定と社内各部門との調整を担当します。BCP全体の進捗管理やリソース配分を行います。
- インフラ/サーバー担当者:実際のMBR復旧作業を行います。作業手順書に沿って論理復旧ツールを操作し、データ損失リスクを最小化します。
- セキュリティ担当者:マルウェア感染や不正アクセスの有無を調査します。フォレンジック調査やログ保全を実施し、証拠を確保します。
- 法務・コンプライアンス担当:個人情報保護法やGDPRなどの法令遵守を監督します。復旧中のデータ取り扱い方法が法令に適合しているかを確認します。
- 総務・広報:社内外への情報共有およびプレスリリース対応を担当します。顧客や取引先への説明タイミングを判断します。
各関係者向け注意点と伝えるべき内容
- 経営層への報告:
- 復旧に要するコスト(物理交換と論理復旧の比較)とダウンタイム影響を簡潔に説明します。
- 法令遵守状況(個人情報保護法、GDPR対応など)について報告し、罰則リスクを回避する必要性を強調します。
- 情報システムリーダー:
- 復旧スケジュールとリソース配分を明示し、他部門への影響範囲を説明します。
- BCP全体の整合性を保つため、関連部門と定期的に進捗を共有します。
- インフラ担当者:
- 手順書の正確な実行と、誤操作を防ぐための事前検証が必要です。
- testdiskやgrub2-install操作時の注意点(誤ったパーティション上書きのリスク)を理解しておくことが重要です。
- セキュリティ担当者:
- フォレンジック調査ではログ一切を証拠保全し、改ざん防止策を講じる必要があります。WORMストレージの活用が推奨されます。
- 調査結果が法的手続きで利用される場合に備え、適切な手順を遵守し、チェーン・オブ・カストディを維持します。
- 法務・コンプライアンス担当:
- 個人情報保護法に基づき、復旧中に取得するログやバックアップデータを暗号化するとともに、アクセス権限を厳格に管理します。
- GDPRの「データポータビリティ」や「消去権」に配慮し、不要な個人データは復旧後に速やかに消去します。
- 総務・広報:
- 社内外への情報共有は、法令や業界ガイドラインに準拠した表現を用い、信用低下を防ぎます。
- プレスリリースでは、復旧完了時や業務再開時に適切なタイミングで発信します。
外部専門家へのエスカレーション指針
社内で72時間以内に復旧できない場合や、法令的・フォレンジック的に複雑な案件は、外部専門家へのエスカレーションが必要です。
- エスカレーション基準
- 社内に該当スキルを持つ技術者が不足している場合。
- 復旧作業中に新たな法令対応(GDPR違反の疑いなど)が発生した場合。
- マルウェア感染やランサムウェア攻撃による二次被害の可能性が高い場合。
- エスカレーション先条件
- 公的資格を持つフォレンジック専門家(登録セキスペ、CISSPなど)または国際的な認証を取得したセキュリティベンダーであること。
- 情報処理安全確保支援士による具体的な復旧実績があること。
- 報告テンプレート(例)
- 状況説明:障害発生日・影響範囲・現在の復旧状況。
- 対応要請事項:必要なリソース・作業範囲・法令対応。
- 緊急度:RTO/RPOの基準に基づく復旧優先度。
- 連絡先情報:エスカレーション先の担当者名・所属・連絡方法(内部運用で管理)。
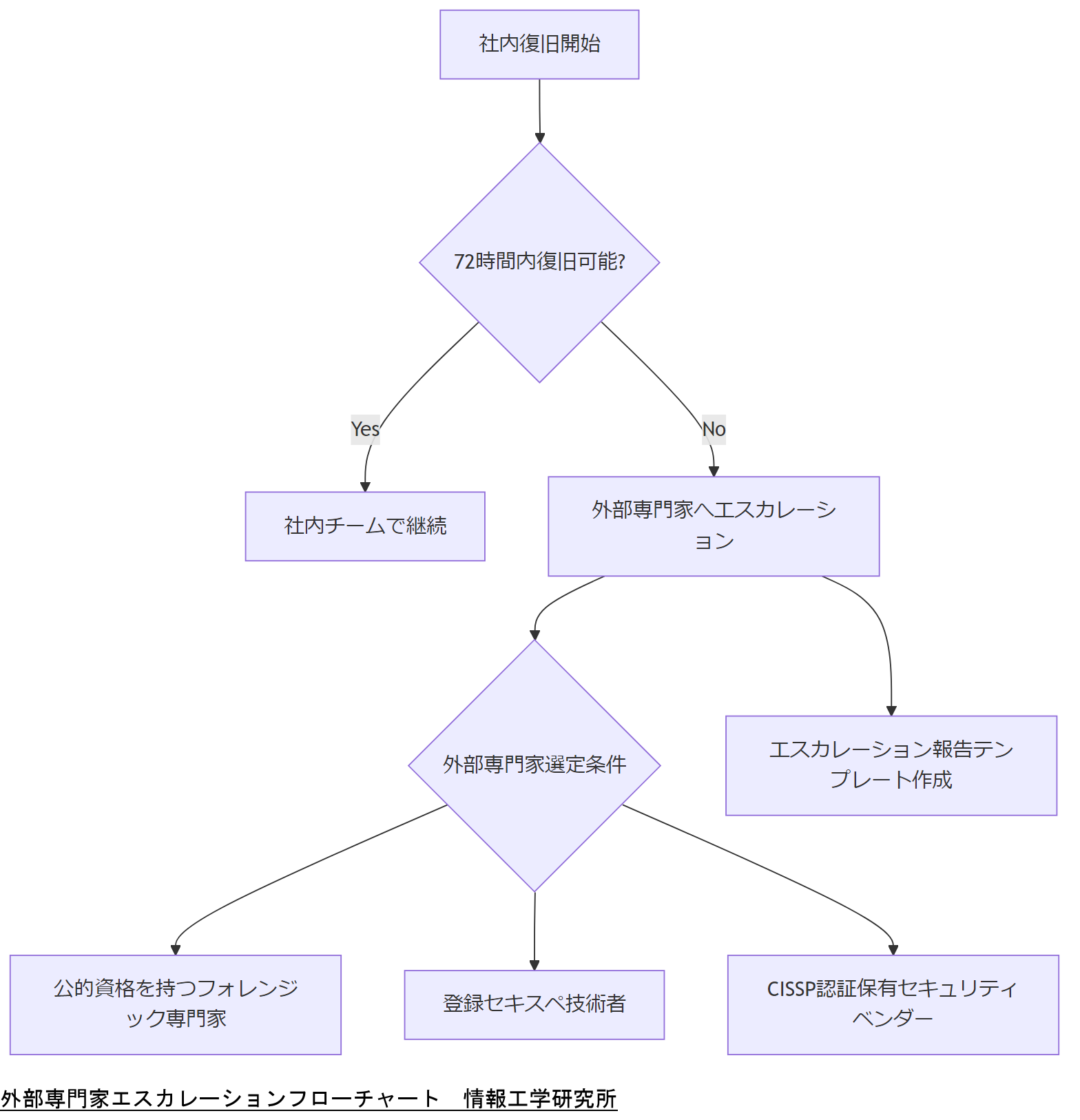
本章では関係者の役割と注意点を示しました。社内説明では「法令遵守の視点」「フォレンジック担当者の業務範囲」「外部エスカレーション基準」を共有し、関係者間の認識を統一してください。
技術者が本章を実践する際は「自分の担当範囲と責任を明確に把握する」「異常発生時には速やかにエスカレーション基準を適用する」ことを心掛けてください。
デジタルフォレンジックの視点 ── マルウェア・攻撃者検知と証跡保全
本章では、MBR破損が攻撃による可能性を含む場合のデジタルフォレンジック視点について解説します。具体的には、想定される攻撃シナリオ、ログ・証跡保全の手順、政府ガイドラインに基づく調査プロセス、最終的なフォレンジック報告書作成のポイントを紹介します。
攻撃によるMBR改ざん想定シナリオ
MBR改ざんは、攻撃者がシステムの起動プロセスを乗っ取り、バックドアを設置するために行われることがあります。以下のようなシナリオが想定されます。
- マルウェア(rootkit)によるMBR上書き攻撃:攻撃者がマルウェアを使ってMBRを改ざんし、OS起動前に悪意あるコードを実行する。この手法により、検知されにくい持続的な侵入が可能となります。
- リモートからのGRUB設定改ざん:SSH等で侵入した攻撃者が、GRUB2の設定ファイルやMBR自体を編集し、不正なカーネルを起動させるケースです。これによりシステムにバックドアを仕掛けることが可能になります。
- 内部不正による意図的MBR損壊:内部の関係者が故意にMBRを破損し、業務を混乱させたり特定データを隠滅したりする場合です。内部不正防止ガイドラインに沿った証跡保全が求められます。
導入解説:これらのシナリオでは、単にMBRを修復するだけではなく、攻撃の発端と再侵入防止のための証跡解析が必要です。フォレンジック手順を組み込んだ復旧フローを事前に策定しておくことが望まれます。
ログ・証跡保全の具体手順
フォレンジック調査では、データ改ざんを防ぎつつ証拠を保全することが最優先となります。政府やIPAのガイドラインを参考に、以下の手順で証跡を確保します。
- ディスクイメージ取得(ハッシュ計算):
- MBRを含むディスク全体を
dd if=/dev/sda of=/forensic/image-$(date +\%Y\%m\%d).img bs=4M status=progressでイメージ化します。取得後はSHA256ハッシュを計算し、証拠の完全性を担保します。
- MBRを含むディスク全体を
- ログファイルの即時保全:
- /var/log/messages、
journalctl、auditdログなど、攻撃時刻前後のログを別メディアにコピーします。改ざん防止のためWORMストレージを使用することが推奨されます。
- /var/log/messages、
- メモリダンプの取得(可能な場合):
- ライブ環境で
volatile memory acquisitionを実施し、/proc/kcore を用いてメモリ内の痕跡を確保します。これにより実行中のマルウェアコードや隠蔽プロセスを特定できる可能性があります。
- ライブ環境で
- チェーン・オブ・カストディの確保:
- 証拠収集を行う担当者、日時、手順を記載した chain of custody form を作成し、後続の法的手続きで証拠として認められる体制を整えます。
導入解説:IPAの「インシデント対応へのフォレンジック技法の統合に関するガイド」では、証拠保全の初動手順として上記イメージ取得とログ保全を推奨しています。詳細手順は本ガイドラインを参照してください。
政府ガイドライン(日本・米・EU)の適用方法
フォレンジック作業には、各国政府が示すガイドラインを適用して手順を進める必要があります。
- 日本:NISCフォレンジックガイドライン
- 「政府機関等の対策基準策定のためのガイドライン」では、フォレンジックサービスの基本事項や証跡保全のポイントが詳細に示されています。調査時は本ガイドを参照し、手順を厳守することが求められます。
- アメリカ:NIST SP 800-86
- NIST SP 800-86「Guide to Integrating Forensic Techniques into Incident Response」は、証拠保全手順や分析フレームワークを提供しており、ディスク復旧時にも適用可能です。調査チームは本ドキュメントに従い、証拠収集と解析を実施します。
- EU:ENISAログ管理ガイドライン
- ENISAの「Good Practice Guide for Log Management」では、ログ取得・保管・分析のベストプラクティスが示されています。MBR改ざんの調査時には、本ガイドに基づきログの一元管理と改ざん検知を行います。
導入解説:各国ガイドラインを参照することで、国際的な証拠保全要件を満たし、後続の法的手続きやコンプライアンス監査に耐えうる証拠を確実に取得できます。
フォレンジック報告書作成のポイント
フォレンジック調査が完了したら、調査結果を報告書にまとめます。報告書には以下の項目を含め、分かりやすく構成します。
- 調査概要と目的:
- 調査対象システムの概要、調査実施の背景・目的を記載します。
- 調査手順:
- イメージ取得、ログ保全、メモリダンプ取得など、各ステップを時系列で記述します。使用ツール名とコマンド例を添え、再現可能性を担保します。
- 解析結果と証拠一覧:
- 攻撃者が使用したマルウェア痕跡、改ざんされたMBRバイナリ、関連ログなど、証拠をハッシュ値とともに提示します。
- 影響評価と再発防止策:
- 改ざんされたMBRによりどの範囲のサービスに影響があったかを評価し、ログ管理や脆弱性対応などの再発防止策を提案します。
- 法令遵守状況:
- 個人情報保護法、GDPR、NISCガイドラインなど、適用した法令やガイドラインを明示し、調査が法令に準拠して行われたことを示します。
導入解説:報告書は法務部門や経営層が確認する重要資料となるため、専門用語を必要最低限にとどめ、図表やチャートを用いて視覚的に理解しやすくまとめることがポイントです。
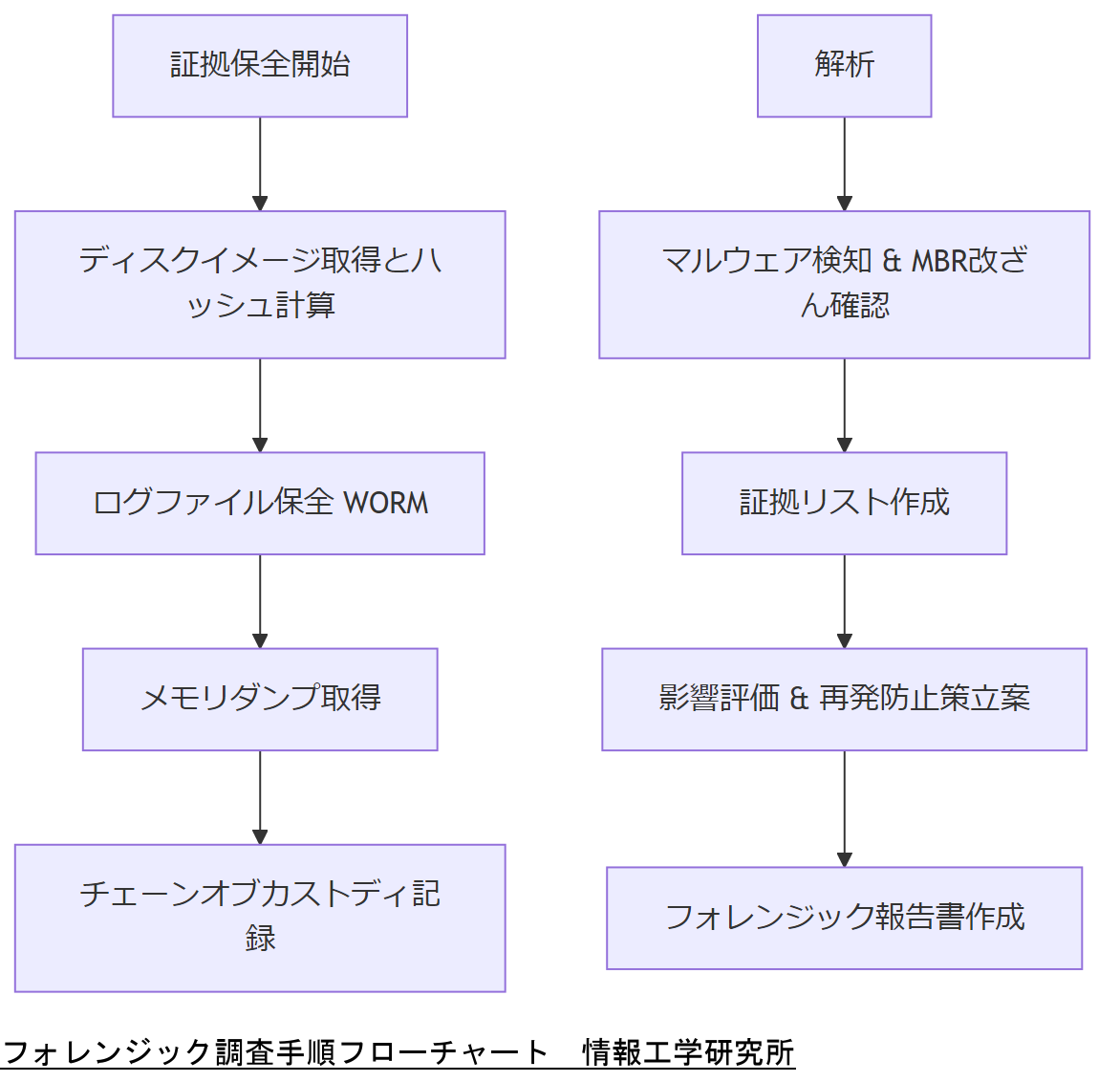
本章では「フォレンジック視点でのMBR改ざん調査手順」「証跡保全の重要性」「政府ガイドラインの適用方法」「報告書作成のポイント」を説明しました。社内では「証拠を適切に確保し、再発防止策を法令に基づいて明確に示すこと」を徹底してください。
本章のポイントは「フォレンジック手順を確実に実行し、証拠を保全すること」と「法令/ガイドラインに準拠した解析と報告」を行うことです。技術者は使用するツールや手順を熟知し、全ての工程を記録しておくことを心掛けてください。
該当する資格・教育・訓練の再掲
本章では、第7章で紹介した資格や教育プログラムを再度整理し、実践演習や定期訓練により自社内の対応力をさらに強化する方法について解説します。
BCP訓練・フォレンジック演習カリキュラム例
BCP訓練やフォレンジック演習を効果的に実施するためのカリキュラム例を示します。実践的な演習を通じて、技術者が障害発生時に即座に対応できるスキルを養います。
- 演習1:MBR破損想定復旧タイムアタック
- 想定時間:2時間
- 内容:実際に問題のあるディスクイメージを用い、MBR破損から論理復旧を行い、最短でOSを起動させる。
- 目的:緊急時の手順を体で覚え、時間管理と作業手順の正確性を磨く。
- 想定時間:2時間
- 演習2:フォレンジックログ解析ワークショップ
- 想定時間:3時間
- 内容:攻撃を受けた痕跡がある仮想環境のログを解析し、マルウェアの侵入経路や改ざん点を特定する。
- 目的:ログ解析スキルと証拠保全手順を実践し、フォレンジック調査の流れを習得する。
- 想定時間:3時間
- 演習3:BCPフェーズ別緊急対応演習
- 想定時間:4時間
- 内容:シナリオ(深夜MBR破損、地震被災、無電化想定)に応じた初動対応と関係者間の連携訓練を実施する。
- 目的:役割分担や連絡フローの確認、BCP計画書の実効性を検証する。
- 想定時間:4時間
導入解説:各演習後には必ず振り返りセッションを設け、問題点や改善箇所を洗い出し、マニュアルや手順書を即時更新する運用を徹底してください。
リスクアセスメント手法と認定資格取得支援
組織的な情報セキュリティマネジメントの一環として、リスクアセスメント手法と資格取得支援の流れを紹介します。
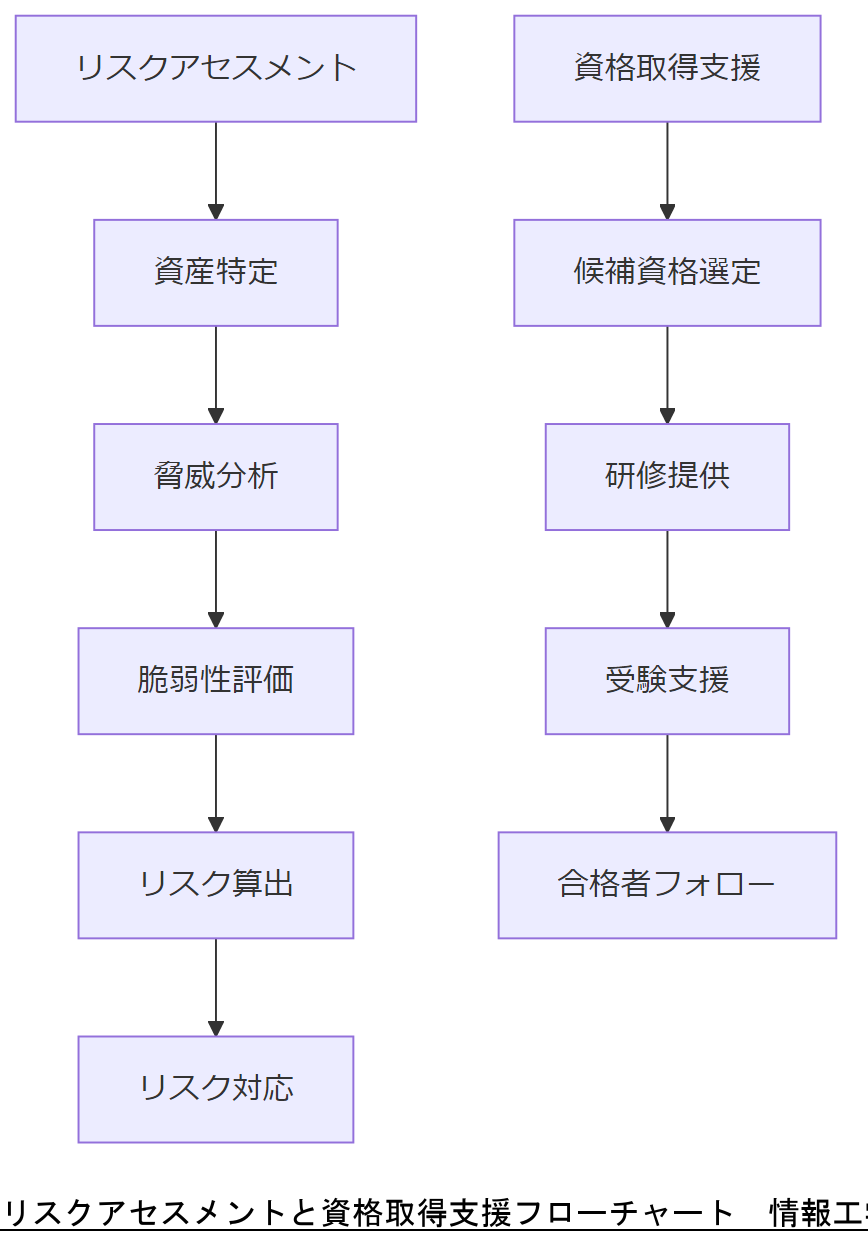
- リスクアセスメント手法
- ① 資産特定:対象システムやデータ、ログなど、保護すべき資産をリストアップする。
- ② 脅威分析:MBR破損を引き起こす可能性のある要因(停電、攻撃、人的ミス)を洗い出す。
- ③ 脆弱性評価:ファイルシステム構成やバックアップ運用、LUKS暗号化などの脆弱性を特定する。
- ④ リスク算出:リスク発生時の影響度と発生確率を定量化し、優先度を決定する。
- ⑤ リスク対応:回避、軽減、共有、受容のうち適切な方法を選択・実行し、対策を計画に組み込む。
- 認定資格取得支援フロー
- ① 資格候補選定:社内ニーズに応じて必要な資格(情報処理安全確保支援士、CISSP、LinuCなど)を選定する。
- ② 研修プログラム提供:社内研修または外部講師を招いて試験対策講座を実施する。
- ③ 受験支援:受験料補助や試験申込サポート、勉強時間確保のための業務調整を支援する。
- ④ 合格後フォロー:合格者は社内で講師役を務め、ナレッジ共有を促進する。
導入解説:ISO/IEC 27001に基づくリスクアセスメントを実践することで、BCPやフォレンジックの精度が向上します。また、資格取得支援によって技術力底上げとモチベーション向上が期待できます。
本章では「BCP訓練カリキュラム」と「リスクアセスメント手法」を提示しました。社内では「演習実施後のフィードバック体制」「リスクアセスメントの定常実施と対策反映の重要性」を共有してください。
本章のポイントは「定期的な訓練で実務スキルを向上させること」と「リスクアセスメントを運用に組み込むこと」です。技術者は日常業務と並行してアセスメントを実行し、継続的に改善策を実施してください。
まとめと弊社へのご相談方法
本章では、これまでの内容を総括し、MBR破損時の論理復旧に関するポイントを再確認します。さらに、情報工学研究所(弊社)が提供するサービス内容と、お問い合わせの流れについて説明します。
記事全体の要点まとめ
まず、本記事で解説した主な要点を振り返ります。
- MBR(マスターブートレコード)はディスク最初の領域であり、破損するとOSが起動できずデータアクセスが不可になります。
- 論理復旧の成功率を高めるには、障害の切り分け、バックアップ状況の確認、RTO/RPO設定、ファイルシステム形式の把握が不可欠です。
- 復旧手順は「準備→MBR検査・修復→検証→運用復帰」の4フェーズに分けて実施し、各フェーズでの注意点を厳守する必要があります。
- 成功率向上には事前対策が重要であり、MBRバックアップの自動化、RAID/LVM冗長化、監視設定、定期的なDR訓練が不可欠です。
- 法令・政府方針は日本、アメリカ、EUで異なる要件があるため、それぞれのガイドラインを参照し、BCPやフォレンジック手順に反映する必要があります。
- 運用コスト比較では、物理交換より論理復旧サービスを活用することでトータルコストを抑えられる可能性が高いです。
- システム設計時にはBCP要件、デジタルフォレンジック要件を組み込み、日常的な点検フローを定義することで、障害時の対応力を強化します。
- 該当資格(情報処理安全確保支援士、CISSP、LinuCなど)を持つ人材を育成し、採用時には実務スキルを重視することで、チームの対応力を高めます。
- BCPの詳細設計では、フェーズ別対応、三重化保存、緊急時・無電化時・システム停止時の運用フローを明確化し、大規模ユーザー向けには段階的復旧計画を策定します。
- 関係者間の役割定義と注意点を共有し、外部専門家へのエスカレーション基準を明示することで、復旧判断を迅速化します。
- フォレンジックでは攻撃シナリオを想定し、証跡保全手順を厳守し、解析結果を法令準拠で報告書にまとめることが重要です。
弊社が提供するサービス概要
弊社(情報工学研究所 株式会社)は、上記の全ての手順と要件を網羅し、以下のサービスをワンストップで提供しています。
- 無料初期診断/24時間緊急対応:
- MBR破損発生時に、24時間365日対応の窓口を設けており、リモートまたはオンサイトでの初期診断を迅速に実施します。
- 論理復旧サービス:
- 障害切り分けからバックアップ確認、MBR修復、GRUB再インストール、検証、運用復帰まで一連の作業を一括で請け負います。
- 法令やガイドラインに準拠し、フォレンジック対応も含めた完全証拠保全を行います。
- BCPコンサルティング:
- 事業インパクト分析(BIA)、BCP設計、訓練実施まで一貫して支援し、オンサイト・オフサイト・クラウドの三重化保存戦略を提案します。
- フォレンジック調査サービス:
- 攻撃によるMBR改ざんや不正アクセスの場合に、証跡保全から解析、報告書作成まで対応します。
- 人材育成および資格取得支援:
- 弊社独自の研修カリキュラムを提供し、社内技術者のスキルアップを支援します。また、資格取得支援プログラムを通じて専門人材を育成します。
導入解説:これらのサービスを活用いただくことで、御社はMBR破損時のリスクを最小化し、法令順守と事業継続性を確保できます。
お問い合わせの流れ
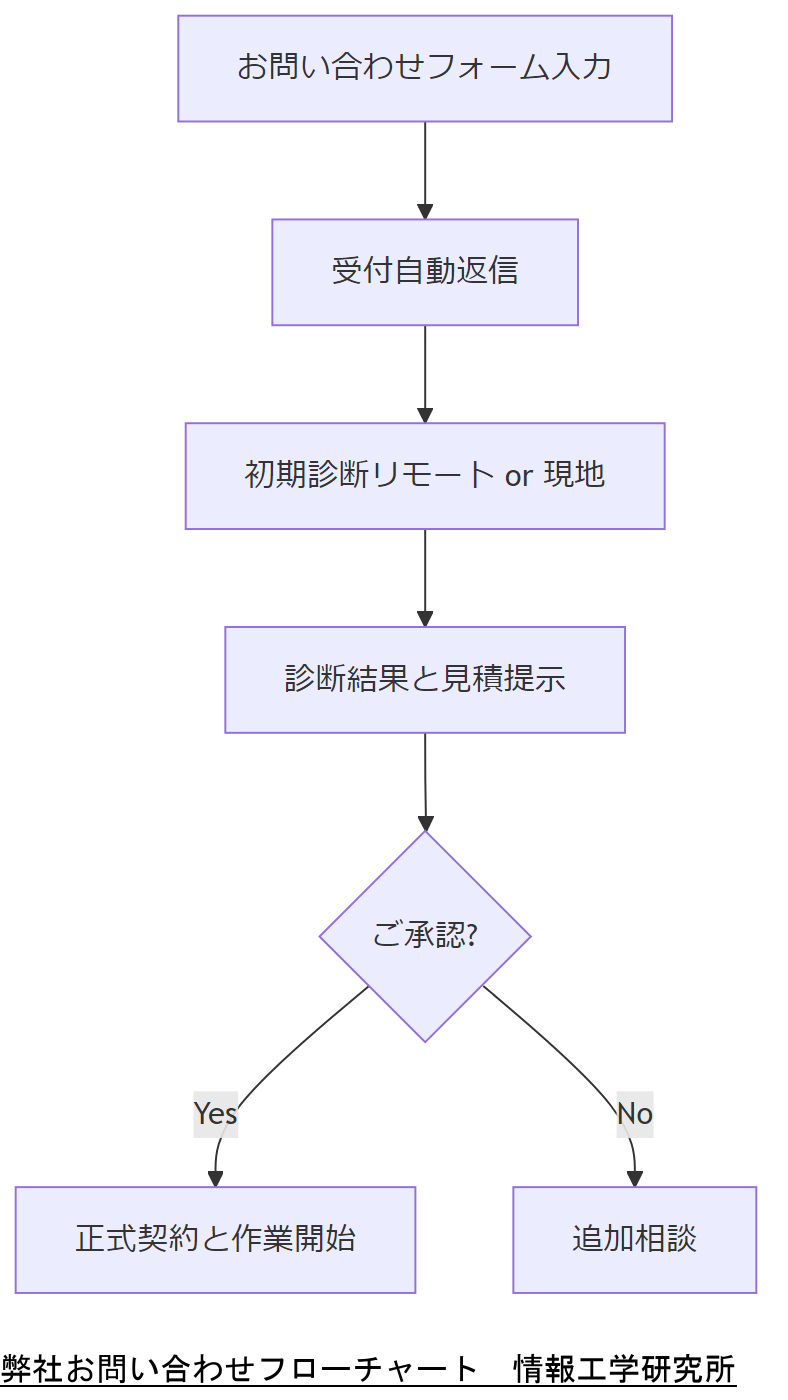
弊社へのご相談は、以下のステップで承ります。メールアドレスや電話番号は不要ですので、ウェブサイトのフォームからご連絡ください。
- 弊社ウェブフォームに必要事項を入力し、送信(24時間対応)。
- 自動返信メールで「お問い合わせ受付番号」とご利用ガイドを案内。
- 弊社担当者がリモートアクセスまたは現地訪問のスケジュールを調整し、初期診断を実施。
- 診断結果と概算見積をご提示し、ご承認後に正式契約。
- ご契約後、即日~2営業日以内に現地作業またはリモート復旧作業を開始。
導入解説:初期診断は無料で実施しており、診断結果に基づき最適な復旧プランと費用を提示します。
本章では「弊社サービス概要」「お問い合わせの流れ」を紹介しました。社内では「初期診断の無料提供」「法令対応とフォレンジック込みのワンストップサポート」を強調し、早期に弊社へ相談するメリットを伝えてください。
技術者は「まず弊社に相談することでリスクを最小化できる」という点を理解し、障害発生時の初動フローに組み込んでください。早期対応がシステム停止時間を短縮します。
おまけの章:重要キーワード・関連キーワードマトリクス
本章では、記事全体で登場した重要キーワード・関連キーワードをマトリクス形式で整理し、各キーワードの説明をまとめます。
表: キーワードマトリクス
| キーワード | 説明 |
|---|---|
| MBR(マスターブートレコード) | ディスクの先頭セクタにあるブートローダコードとパーティションテーブルを格納する領域。 |
| GRUB2 | CentOSで標準的に使用されるブートローダ。MBRにインストールされ、OSのカーネルをロードする役割を担う。 |
| 論理復旧 | 物理的なディスク交換を伴わず、ソフトウェア的にMBRやパーティションテーブルを修復する手法。 |
| dd | Linuxのディスクコピーコマンドで、MBRやディスク全体をイメージとしてバックアップできる。 |
| testdisk | オープンソースのパーティション復旧ツール。削除済みパーティションの再構築が可能。 |
| RAID | 複数ディスクを組み合わせて冗長性やパフォーマンスを向上させる技術。MBR冗長化にも活用できる。 |
| LVM | 論理ボリューム管理を提供し、複数物理ディスクを柔軟に管理する技術。MBR破損後のデータ復旧に有効。 |
| BCP(事業継続計画) | 災害や障害時に事業を継続・復旧するための計画。MBR破損対策もBCPに含めることが重要。 |
| フォレンジック | サイバー攻撃や不正アクセス時に証拠を保全・解析する技術。MBR改ざんの調査にも不可欠。 |
| RTO/RPO | RTOは業務が再開されるまでの許容時間、RPOは許容できるデータ損失量を示す指標。BCP設計で基準とする。 |
| 情報処理安全確保支援士 | 日本の国家資格で、情報セキュリティ対策やフォレンジックに関する専門知識を証明する。 |
| CISSP | 国際的な情報セキュリティ資格で、リスクマネジメントやコンプライアンスに関する知識を網羅する。 |
| LinuC | Linux技術者認定制度で、ファイルシステムやブートローダに関する知識を担保する。 |
| GDPR | EU一般データ保護規則。個人データの保護要件を規定し、ディスク復旧時にも遵守が求められる。 |
| NIST SP 800-86 | 米国のNISTが公開するフォレンジックガイドライン。証拠保全や解析手順を詳細に示す。 |
| ENISA | 欧州ネットワーク・情報セキュリティ庁。ログ管理やサイバーセキュリティ対策のベストプラクティスを公開する。 |
| WORMストレージ | 書き込み後に改ざんできないストレージ。フォレンジック証拠保全に用いる。 |

本章では「重要キーワードとその説明」を整理しました。社内では「各キーワードの定義と役割」を共有し、技術者が用語を正確に理解することを促してください。
本章のポイントは「用語理解の統一」です。技術者はこの記事で用いられたキーワードを明確に把握し、実務や社内説明で共通認識をもつよう心掛けてください。
