1. Ext4障害時の復旧フローを理解し、ダウンタイムを最小化できる体制を構築します。
2. BCPや法令順守を考慮したシステム設計/運用フローを実装できます。
3. 経営層に説明可能なKPIと投資対効果を、資料として提示します。

Ext4障害の基礎知識
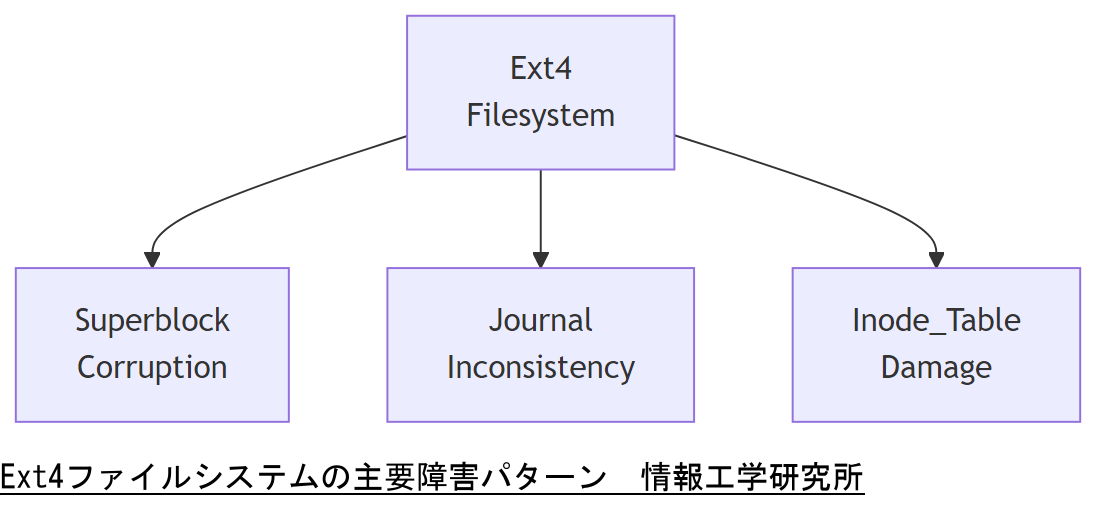
LinuxのExt4ファイルシステムは、高速化と信頼性確保のためジャーナリング機能を備えています。ジャーナリングとは、ファイル操作前後の状態をログに追記し、障害発生時には一貫性を保った復旧を行う仕組みです。本章では、Ext4がどのようにデータ構造を管理し、代表的な障害パターンがどのように発生するかを整理します。具体的には、スーパーブロックの破損やジャーナル領域の不整合、inodeテーブルの破損など、主要な障害原因と発生メカニズムを解説し、後続章の復旧手順理解に必要な基礎知識を提供します。また、Ext4のファイルシステム構造(ブロックグループ、extents、ガーベジコレクション機能)についても概観し、障害発生時にどの領域を優先的にチェックすべきかを示します。これにより、復旧方法の選択肢や時間見積もりの妥当性を評価する土台を構築できます。
兆候と早期検知
Ext4ファイルシステムの障害は、事前の予兆をいかに捉えられるかが復旧成功の鍵となります。本章では、システムログの読み方とSMARTによるディスク自己診断の導入方法を解説し、障害発生前にアラートを上げる運用体制を構築する手順を示します。具体的には、dmesgや/var/log/kern.logに現れる典型的なエラーサインの例を挙げ、定期的なログ監視スクリプトのサンプルもご紹介します。また、smartmontoolsを使ったSMART値監視の設定例を通じて、ハードディスクの劣化を事前に察知し、計画的な交換やリビルドを実施するフローを示します。
ログ分析
Ext4障害の初期兆候として最も多いのが、カーネルログ中の EXT4-fs error や I/O error の記録です。これらはマウント時やファイル操作時に発生し、以下のパターンで現れます。
- スーパーブロック不整合による再マウント警告
- inodeエラーによるファイル読込失敗ログ
- ディレクトリエントリの破損を知らせるエラー
SMART監視
SMART(Self-Monitoring, Analysis, and Reporting Technology)は、ディスク自身が健康状態を自己監視し、予兆を報告する仕組みです。Linuxでは smartmontools パッケージを導入し、 smartd デーモンで定期チェックを行います。以下の設定例では、毎晩深夜に全ディスクのSMARTテストを実行し、結果をsyslogに出力します。
- /etc/smartd.conf に対象デバイスとテストスケジュールを記載
- smartd.service を有効化し、自動起動設定を実施
- 障害閾値(Reallocated_Sector_Ct等)超過時にメール通知設定

技術担当者は、ログのERRORやSMARTアラートを上司に報告する際、「いつ」「どのログ項目で」「どの閾値を超えたか」を明確に伝えましょう。読み取り専用切替の誤操作を防ぐため、操作手順と影響範囲を事前共有してください。
ログ監視スクリプトやsmartd設定を自動化する際は、誤検知による頻繁なアラートを避けるため、閾値調整とテスト実行結果の人手確認ルーチンを設けることを忘れないようにしましょう。
初動30分フロー
Ext4障害発生後の初動30分は、データ損失を最小化し復旧時間を短縮するための極めて重要な時間帯です。本章では、障害検知直後からディスクイメージ取得、読み取り専用化、主要ログの確保、fsck実行準備までの具体的なステップを時系列で解説します。
ステップ概要
以下のチェックリストをもとに、迅速かつ抜け漏れのない初動対応を行います。
初動30分対応チェックリスト| 時間目安 | 作業内容 | 備考 |
|---|---|---|
| 0~5分 | 読み取り専用マウント(mount -o ro) | データ上書き防止 |
| 5~10分 | ディスクイメージ取得(dd if=/dev/sdX of=image.dd) | オリジナル保全 |
| 10~15分 | 主要ログコピー(/var/log/kern.log 他) | 原因解析用に保管 |
| 15~20分 | fsck用パーティションバックアップ | スーパーブロック検証用 |
| 20~30分 | fsck.ext4 実行準備:オプション検討 | -n, -p, バックアップブロック番号検討 |
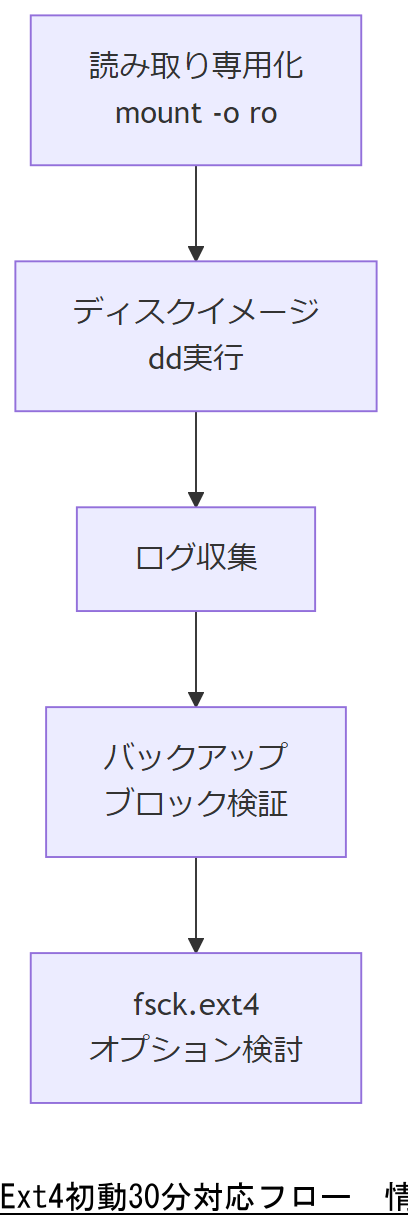
初動対応時は「読み取り専用化」「イメージ取得」の順序を誤ると、データ上書きリスクが発生します。上司には必ず手順順序と影響範囲を図示して共有してください。
実際の現場では、コマンド実行ミスが発生しやすいです。作業リストを紙または電子化し、一つずつ確実にチェックしながら進めましょう。
標準ツールによる修復
LinuxにはExt4専用の修復ツールが標準で提供されており、fsck.ext4やdebugfsなどを適切に組み合わせることで、障害からの復旧を効率化できます。本章では、各ツールの役割とオプションの使い分け、実行時の注意点を詳しく解説します。
fsck.ext4 の基本オプション
fsck.ext4はファイルシステム全体の一貫性チェックと修復を行うコマンドです。よく使う主なオプションは以下の通りです。
-n:読み取り専用モードでチェック。自動修復は行わず、安全に検証のみ。-p:自動修復モード。軽微な不整合を自動で修正。-y:すべての修復確認を自動“Yes”で実行。-b バックアップブロック番号:スーパーブロックバックアップを指定して復旧。
-nで障害箇所を特定し、その後-pやバックアップブロックを使って復旧します。 主要オプション比較表 | オプション | 効果 | 使用タイミング |
|---|---|---|
| -n | 読み取り専用チェック | 初回検証時 |
| -p | 自動修復 | 軽微エラー対応 |
| -y | 全自動修復 | 人的確認不要時 |
| -b | バックアップスーパーブロック復旧 | スーパーブロック破損時 |
debugfs を用いた手動操作
debugfsはExtファイルシステムのインタラクティブシェルで、特定inodeの内容確認や修正が可能です。以下の手順で利用します。
debugfs -w image.dd:書き込みモードでディスクイメージを開く。stat:inode情報を表示。clri:破損inodeをクリア。dump:データ抽出。<ファイル名>
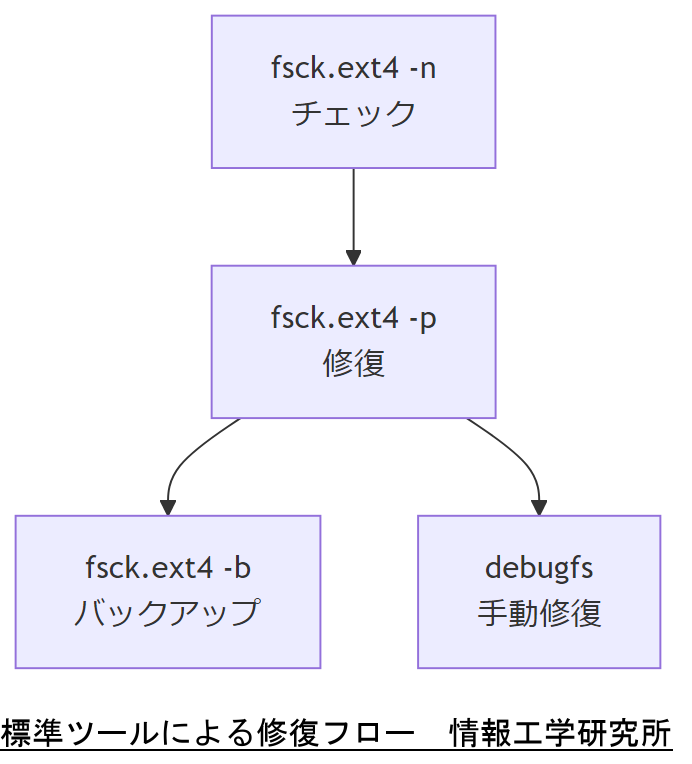
fsck.ext4実行時はオプションの誤選択でさらなる破損を招くリスクがあります。上司には、事前検証結果と使用オプションの理由をまとめた資料を提示してください。
自動修復(-p)で進める前に、必ず読み取り専用チェック(-n)を行い、想定外の修復操作を防ぐ手順を遵守しましょう。
上級テクニック
標準ツールで対応困難な場合や、より精密な復旧を求める際は、ジャーナルの手動リプレイやスーパーブロックの代替復旧、LVM/RAIDとの組み合わせ復旧といった上級テクニックが有効です。本章では、各技法の手順と注意点を詳述します。
ジャーナル手動リプレイ
ジャーナル領域のみを抽出し、安全に再生することで、ファイルシステム全体を壊さずに復旧できます。手順は以下の通りです。
- ディスクイメージからジャーナル領域をオフセット指定で抽出(dd if=image.dd bs=4096 skip=<オフセット> count=<サイズ>)
- debugfsでイメージを読み込み、
journal replayコマンドを実行 - リプレイ後、ファイルシステムの一貫性をfsck.ext4で再チェック
tune2fs -lで確認可能です。リプレイ中にエラーが出た場合は即座に中断し、ログを別途保全してください。 スーパーブロック代替復旧
Ext4は複数のスーパーブロックのバックアップを保持します。メインスーパーブロックが破損した場合は、バックアップから復旧を試みます。
- バックアップブロック番号一覧を取得:
mke2fs -n /dev/sdX - fsck.ext4 -b <バックアップ番号> /dev/sdX
- 復旧後は再度メインスーパーブロックを書き戻し:
e2fsck -f /dev/sdX
LVM・RAIDとの連携復旧
LVMやRAID構成下では、物理デバイス単位ではなく論理ボリュームやアレイ単位で復旧作業を行います。
- RAIDアレイ解体せずに個別ディスクを読み取り専用マウント
- LVM上のスナップショット機能を活用し、論理ボリュームをコピー
- コピー上でfsck.ext4やジャーナルリプレイを実行
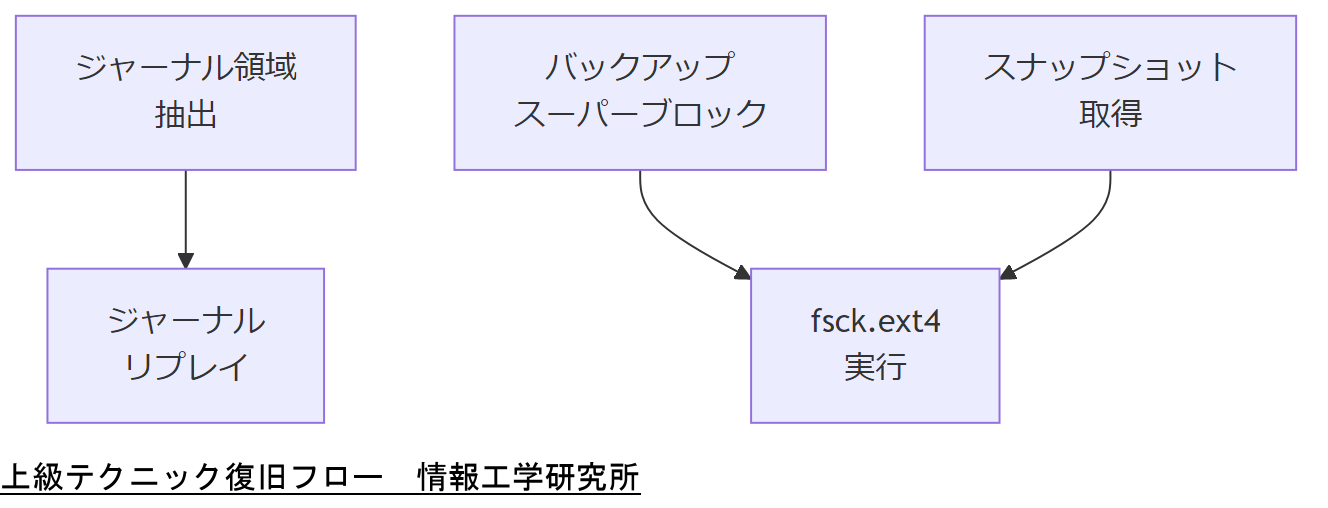
上級テクニックは手順ミスでデータをさらに破損するリスクがあります。操作前に必ずテスト環境での手順検証結果を経営層へ報告し、承認を得てから本番実行してください。
ジャーナルリプレイやバックアップブロック指定はオフセット誤りが致命的です。コマンド実行前に必ずパラメータを二重チェックし、ログを逐一保全する運用を徹底してください。
デジタルフォレンジック視点
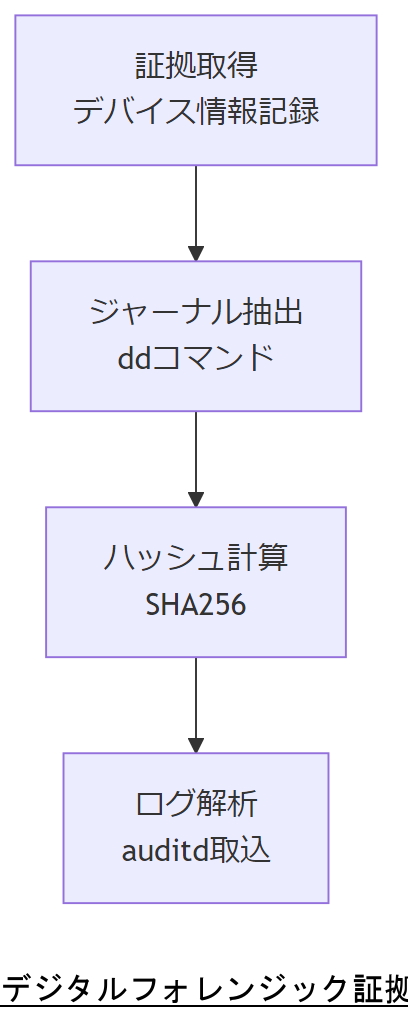
障害対応において、復旧作業中も証拠保全を同時に行うデジタルフォレンジックの視点が欠かせません。本章では、証拠保全手順(Chain‐of‐Custody)やジャーナル保全、改ざん検知のフローを政府機関向け標準に準拠して解説します。
証拠保全とChain-of-Custody
政府機関等のガイドラインでは、デジタル証拠の信頼性を担保するためにChain-of-Custody(証拠保全連鎖)の厳格な管理を求めています。具体的には、各データ取得時に以下を記録します:
- 取得日時・取得者名
- 対象デバイス情報(シリアル、モデル)
- 取得方法とツールバージョン
- 証拠保管場所とアクセスログ
ジャーナル領域の保全
ジャーナル領域には、直近のファイル操作履歴が格納されており、障害解析の重要な手がかりとなります。以下の手順で保全します:
- ディスクイメージからジャーナルセクタを抽出:
dd if=image.dd bs=4096 skip=<オフセット> count=<サイズ> - 抽出データのハッシュ値計算(SHA256など)による整合性確認
- ログ解析環境へインポートし、操作履歴を解析
マルウェア・内部不正の痕跡管理
内部不正やマルウェア攻撃では、改ざんされたファイルや不審プロセスの履歴を収集・保全し、後日責任追及が可能な形式で保存します。具体的には:
- /proc,/sys フォルダのスナップショット取得
- 実行バイナリのハッシュ収集
- プロセス起動ログ(auditd など)をセキュア転送
フォレンジック作業を開始する前に、必ず証拠保全手順書と取得ログを上司へ提出し、社内規定に沿った承認を得てください。
証拠データの取り扱いは一つのミスで証拠能力を失います。手順書通りの作業ログを逐次記録し、作業後速やかにハッシュ値を二重チェックしてください。
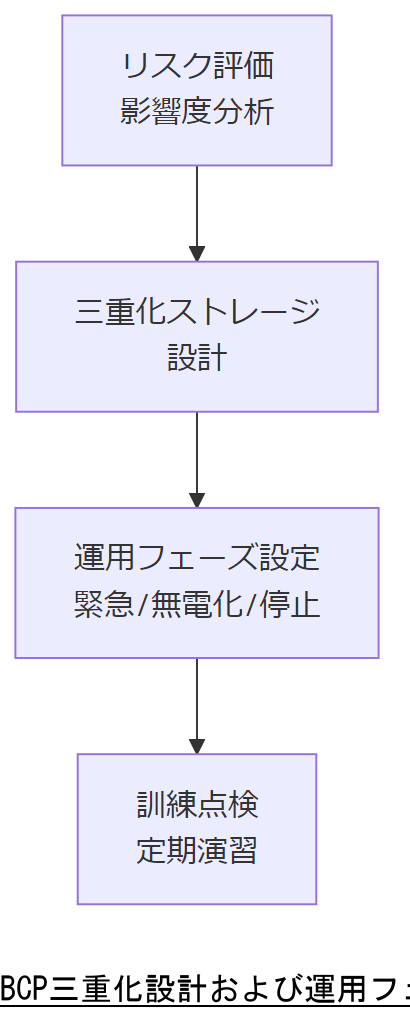
BCPと三重化設計
事業継続計画(BCP)は、企業が災害やシステム障害時にも重要業務を継続するための枠組みです。内閣府「事業継続ガイドライン」では、データ保存の三重化や、緊急時・無電化時・システム停止時の3段階オペレーションを基本とすべきと明記しています【出典:内閣府『事業継続ガイドライン』令和5年3月】。本章では、三重化ストレージ設計の要点と、各段階に応じた運用フローを解説します。
三重化ストレージ設計
データの三重化とは、同じデータを以下のように3箇所に保管する方式です【想定】:
_三重化ストレージ構成例_| 保存先 | 冗長レベル | 特徴 |
|---|---|---|
| オンサイトサーバー | リアルタイム複製 | アクセス高速・障害検知即時 |
| オフサイトバックアップ | 夜間同期 | 災害対策エリア外保管 |
| オフラインアーカイブ | 月次スナップショット | ランサムウェア対策 |
3段階運用フェーズ
運用フェーズは、障害の状況に応じて以下の3段階で想定します【想定】:
- 緊急時:即時復旧が必要な限定機能のみ稼働
- 無電化時:発電機等のバックアップ電源で限定稼働
- システム停止時:完全停止後の再起動・復旧演習
BCPの三重化設計は多層的であるほどコストが増大します。上司には各保存先の冗長レベルと想定コストを整理した概要資料を提示し、合意を得てください。
演習の頻度が低いと、担当者が手順を忘れる恐れがあります。訓練・点検は必ず年2回以上実施し、結果を記録して改善サイクルに組み込んでください。
法令・政府方針
データ保護やサイバーセキュリティに関する法令・政府方針は、事業継続や情報資産の保全に直結する重要要素です。本章では、日本の個人情報保護法、EUのNIS2指令、米国のNIST SP 800-123ガイドライン、ならびに政府機関向け統一基準群を比較し、各規範の適用ポイントと遵守策を整理します。[出典:農林水産省『個人情報の保護に関する法律』令和4年]
日本:個人情報保護法
個人情報保護法(平成15年法律第57号)は、行政機関が保有する個人データの適正管理を義務づけ、漏えい時の報告や再発防止措置を求めています。[出典:農林水産省『個人情報の保護に関する法律』令和4年] 違反時には行政処分や罰則が科されるため、データ復旧時にもログ保全・アクセス履歴の保存が必須です。[出典:農林水産省『個人情報の保護に関する法律』令和4年]
EU:NIS2指令
NIS2指令(Directive (EU) 2022/2555)は、重要インフラを含む18分野のサイバーセキュリティ基準を統一し、加盟国の国家戦略策定と跨域連携を義務づけています。[出典:EUR-Lex『Directive (EU) 2022/2555』2022年] 特にインシデント報告の期限短縮や脆弱性管理の強化が求められ、国内外サーバー障害対応でも遵守が必須です。[出典:EUR-Lex『Directive (EU) 2022/2555』2022年]
米国:NIST SP 800-123
NIST SP 800-123「Guide to General Server Security」は、サーバーのセキュリティ管理手順を定義し、構成管理・パッチ適用・ログ監視などの具体策を示しています。[出典:NIST CSRC『SP 800-123』2013年] サーバー障害対応においても、ハードニング手順準拠が復旧後の再発防止に直結します。[出典:NIST CSRC『SP 800-123』2013年]
日本:政府機関等向け統一基準群
内閣サイバーセキュリティセンター(NISC)が策定する「政府機関等の対策基準策定のためのガイドライン(令和5年度版)」は、情報システム運用のベースラインを示す統一規範・統一基準・ガイドラインを体系化しています。[出典:NISC『政府機関等の対策基準策定のためのガイドライン(令和5年度版)』令和5年] また、各機関はこれをもとに組織特性に応じた対策基準を策定することが義務づけられています。[出典:NISC『政府機関等のサイバーセキュリティ対策のための統一基準群(令和5年度版)』令和5年]
法令・政府方針比較表| 規範 | 適用範囲 | 主要要件 |
|---|---|---|
| 個人情報保護法 | 行政機関保有データ | 漏えい報告・再発防止措置 |
| NIS2指令 | EU加盟国の重要インフラ | インシデント報告・脆弱性管理 |
| NIST SP 800-123 | サーバーセキュリティ | ハードニング・ログ監視 |
| 政府統一基準群 | 政府機関情報システム | ベースライン対策・PDCA |
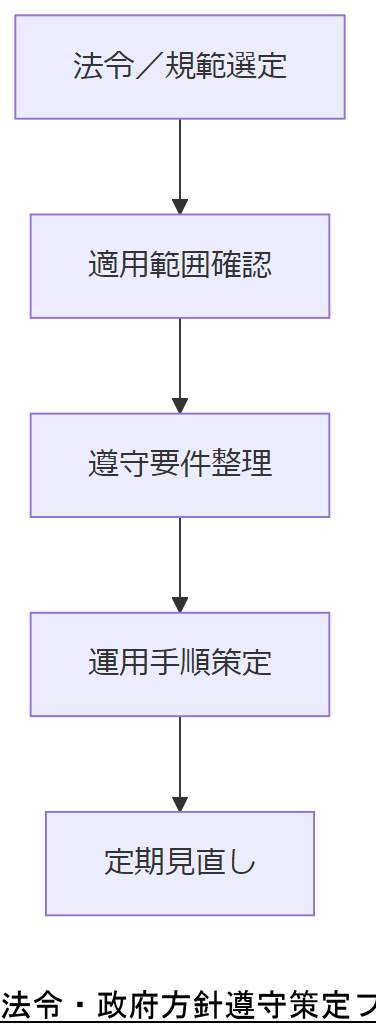
各規範は適用範囲や罰則が異なります。上司には自社対象範囲と遵守要件を一覧にまとめた資料を提示し、統一的な遵守体制を構築してください。
法令改正は頻繁に行われます。定期的(半年ごと)に最新ガイドラインを確認し、運用手順をアップデートする仕組みを整備しましょう。
コンプライアンスと監査
システム障害対応では、法令遵守だけでなく定期的な監査によって運用の健全性を確保することが求められます。金融機関等のシステム監査基準では、ITガバナンスやリスク管理体制に関する監査ポイントが詳細に規定されており【出典:金融機関等のシステム監査基準(第2版) 2024年】、IPAの「情報セキュリティ10大脅威 2025」では組織向けセキュリティ課題としてランサム攻撃やサプライチェーン攻撃を挙げ、監査における重点検査項目を示しています【出典:IPA「情報セキュリティ10大脅威 2025」】。本章では、主要な監査基準と、自社システム監査体制の構築ポイントを整理します。
金融機関等のシステム監査基準
金融庁所管のシステム監査基準では、組織のガバナンスから運用管理まで幅広い項目を網羅しています。特に以下の観点が重視されています:
- リスク評価と内部統制の整備
- 業務継続計画との整合性
- 外部委託先の管理体制
組織向け情報セキュリティ10大脅威
IPAが選出する2025年の「組織向け10大脅威」では、ランサム攻撃やサプライチェーン攻撃が上位に位置し、バックアップ運用やログ管理の重要性が指摘されています。監査では、これら脅威に対応した対策実施状況の検証が求められます【出典:IPA「情報セキュリティ10大脅威 2025」組織編】。
監査基準と脅威対応チェック表| 項目 | 主な要件 | 監査視点 |
|---|---|---|
| リスク管理 | 定期リスク評価 | 評価結果の文書化・改善履歴 |
| BCP整合性 | BCPとIT運用の一体化 | 演習記録と課題対応 |
| 委託先監督 | 契約・監査条項 | 監査報告書の有無 |
| 脅威対策 | ランサム対策・サプライチェーン対策 | ログ運用・バックアップ運用状況 |
内部監査部門の体制
証券会社向けチェックリストでは、内部監査部門にシステム専門要員の配置と、IT統制の定期見直しが求められます【出典:証券会社向けシステムリスク管理チェックリスト】。具体的には、職務分掌の明確化と問題発生時の報告フローを文書化し、定期監査でトレーサビリティを確保します。
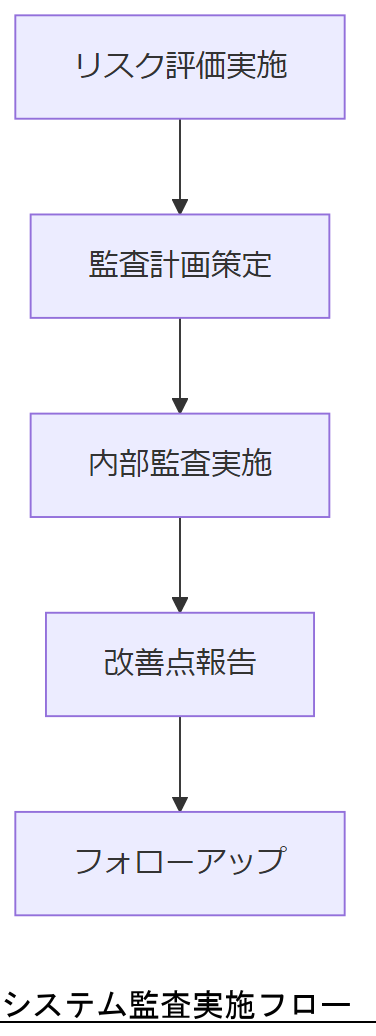
監査結果を経営層に説明する際は、主要指標の達成状況と未達項目の改善計画を一枚の表にまとめ、迅速な承認を得るようにしてください。
監査項目の網羅性を高めるため、IPA脅威一覧やBCPガイドラインなど外部公的資料を定期的に参照し、チェックリストをアップデートしましょう。
人材育成と募集
Ext4障害対応やBCP実施には、専門的知見を持つ技術者の育成と適切な採用が不可欠です。本章では、政府認定資格や研修プログラム、そして人材募集要件のポイントを整理し、継続的なスキル確保のためのロードマップを示します。
必要資格と認定制度
政府が認定する情報処理安全確保支援士(旧:情報セキュリティスペシャリスト)は、サイバーセキュリティの国家資格として高い信頼を得ています【出典:経済産業省『情報処理安全確保支援士制度ガイド』令和4年】。また、IPAによる高度試験「ネットワークスペシャリスト」「データベーススペシャリスト」なども、システム障害対応力向上に資するとされています。
訓練プログラムと演習
技術研修では、実機演習を重視します。例えば、fsck.ext4操作やジャーナルリプレイ演習、ログ解析ハンズオンを組み合わせ、定期的(半年ごと)な演習を実施します。更に、BCP演習として「緊急時」「無電化時」「完全停止時」各フェーズを通じた復旧演習を行うことで、実践力を養成します【想定】。
募集要件の定義
採用要件では、以下の要素を明示すると良いでしょう。
- Linuxシステム管理経験3年以上
- 資格保有者(情報処理安全確保支援士等)優遇
- fsck/debugfs 等ツールの利用経験
- BCP策定・運用経験
人材育成計画と採用要件をまとめる際、上司には資格保有状況や演習実績を一覧化し、必要人員数と投資計画を示すことが重要です。
採用後の定着率を高めるため、スキルアップパスとキャリアロードマップを明示し、継続的なフォローアップ体制を整備しましょう。
関係者マップと注意点
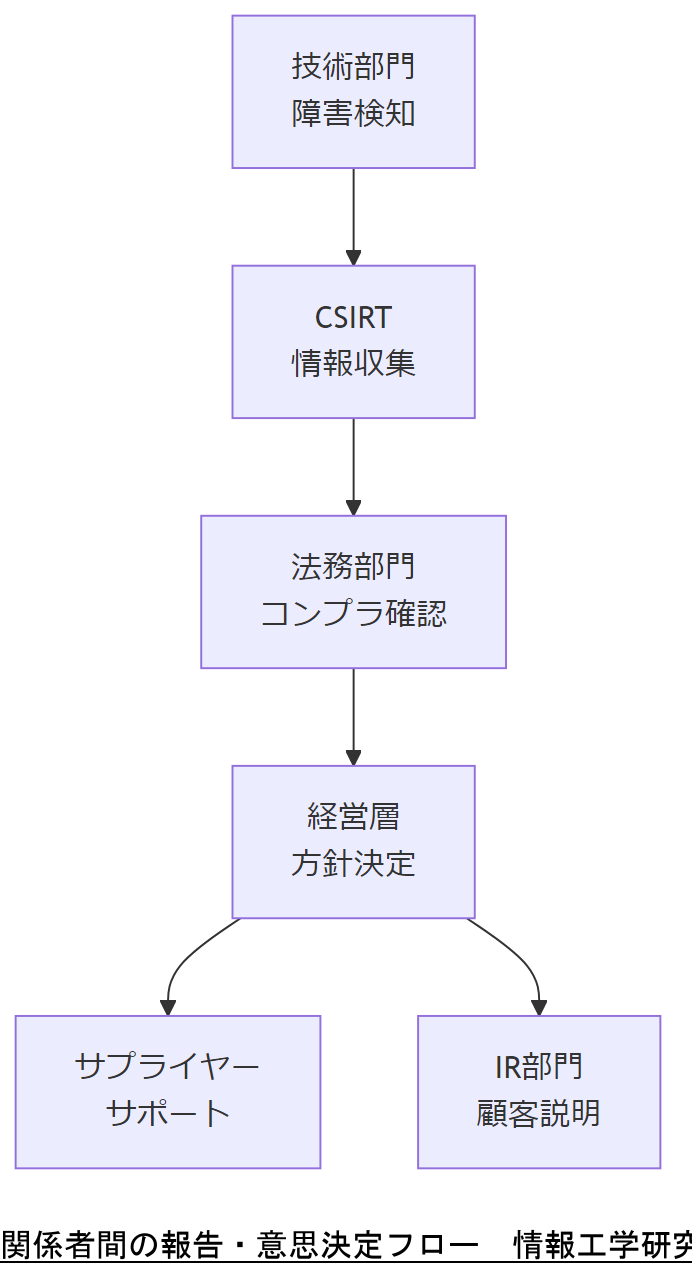
システム障害やExt4ファイルシステム障害対応では、多様なステークホルダーとの連携が欠かせません。自社内では技術部門、運用チーム、法務部門、内部監査部門、IR部門、経営層などが関与し、外部ではクラウドサービス事業者、CSIRT、サプライヤーなどが挙げられます【出典:内閣府防災情報のページ『知る・計画する』】。 各関係者の役割と注意点を整理し、情報共有ルートと意思決定階層を明示したマップを作成することで、迅速な対応と報告が実現します【出典:IPA『情報システム障害の再発防止のための 組織的マネジメントの調査報告』】。
ステークホルダー一覧表| ステークホルダー | 役割 | 注意点 |
|---|---|---|
| 経営層 | 復旧方針決定/投資承認 | 現状とリスクを可視化して共有 |
| 技術部門 | 初動対応/復旧作業 | 手順書遵守とログ保全 |
| 法務部門 | コンプライアンス監査/報告文書レビュー | 法令要件の抜け漏れ防止 |
| 内部監査 | 運用体制の健全性確認 | 監査記録の保全 |
| CSIRT | 脅威情報提供/エスカレーション受け口 | 迅速な情報共有チャネル設定 |
| サプライヤー | ハードウェア交換/技術サポート | 契約条件・SLAの遵守状況確認 |
| IR部門 | 対外説明/顧客対応 | 事実関係の正確な把握 |
技術部門は各ステークホルダーへ報告する際、「何を」「いつ」「どのように対応したか」を簡潔にまとめ、関係部門間の認識ギャップを防ぐ資料を用意してください【出典:IPA CSIRT Handbook】。
関係者マップは定期的に見直し、新規取引先や組織変更に応じて更新することで、緊急時の混乱を防止してください【出典:内閣府防災情報のページ】。
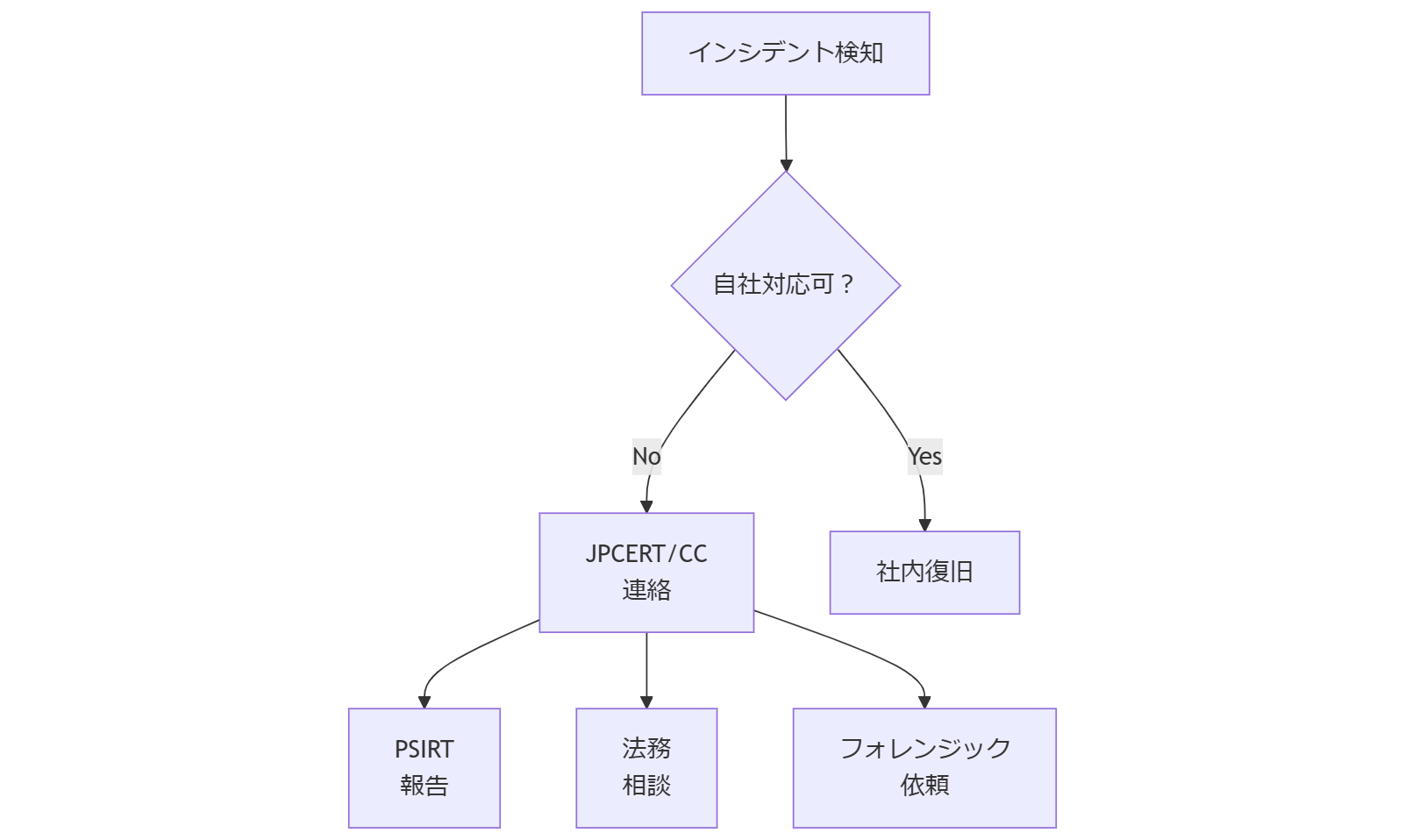
外部専門家へのエスカレーション
障害対応が自社リソースで困難な場合は、適切な外部専門家へエスカレーションを行います。代表的な専門家として、JPCERT/CCやPSIRT、法務専門家、デジタルフォレンジック専門家が挙げられます【出典:JPCERT Handbook】。エスカレーション基準や連絡手順をあらかじめ定義し、迅速な支援を得る体制を構築しておきましょう【出典:JPCERT APTガイド】。
外部専門家一覧表| 専門家 | 役割 | 連絡要件 |
|---|---|---|
| JPCERT/CC | 全体調整/初動支援 | 重大インシデント発生時 |
| PSIRT | 脆弱性対応 | 未知脆弱性検出時 |
| 法務専門家 | 法令順守支援/報告文書作成 | 個人情報漏えい疑い時 |
| フォレンジック専門家 | 証拠保全/調査 | 改ざん・不正の疑い時 |
エスカレーション時は、事前に定義した基準と手順書を遵守し、連絡先リストと認証情報を常に最新化してください【出典:JPCERT PSIRT Services Framework】。
外部専門家との連携では、機密保持契約(NDA)とSLAの整備を事前に行い、支援レベルと責任範囲を明確にしておきましょう【出典:JPCERT ICS Security Guide】。