



• インデックス破損の兆候を早期に検知し、60分以内に可用性を回復する手順が分かります。
• 三重化ストレージとフォレンジック対応を両立させたBCP設計の要点を理解できます。
• 役員・上司への稟議資料として転用できる法令準拠チェックリストを取得できます。

Unixファイルインデックス破損とは何か
Unix系システムでは、inode と呼ばれるデータ構造がファイルのメタデータ(所有者、パーミッション、ブロック位置など)を保持しています。inode テーブルが破損すると、「ファイルは存在するのに開けない」「ディレクトリを listing するとフリーズする」といった現象を招き、サービス停止リスクが高まります。
破損主要因 は以下の三つに大別されます。
1) 停電や強制電源断によるライトキャッシュ揮発
2) ストレージ媒体の経年劣化・ビットロット
3) マルウェアや不正コマンドによるメタデータ領域上書き[出典:総務省『情報セキュリティマネジメントガイドライン』2023年]
| 要因 | 典型的症状 | 一次対応 |
|---|---|---|
| 停電・瞬停 | Read-only filesystem 自動切替 | fsfreeze 後に冗長側へフェイルオーバー |
| 媒体劣化 | I/O error, bad magic number | RAID スペア組替+再同期 |
| 不正操作 | 属性変更不可、UID/GID 異常 | ジャーナル復旧+権限監査 |

停止時間の根拠を稟議書に明記する際、inode 破損が“論理障害”である点を強調し、物理交換だけでは解決しないことを共有してください。
開発部門では「アプリ再デプロイで復旧できる」と誤解しがちです。ストレージ層の検証ログを残し、再発防止策を必ずドキュメント化しましょう。
[出典:総務省『クラウドサービス利用のための情報セキュリティマネジメントガイドライン』2023年]
事例で学ぶ損害規模と経営インパクト
国内行政系インシデント
2023 年度、地方自治体で発生した情報システム障害のうち、ファイルシステム破損が原因と認定された事例は 83 件 に上り、その 72 % がバックアップ不備で復旧に 6 時間以上を要しました。 損失額は自治体全体で 推計 18 億円 に達し、住民サービス停止時間は累計 1,900 時間と報告されています。 総務省は同年度報告書で「障害原因の半数以上が論理破損であり、ハードウェア交換のみでは解決できない」と指摘し、FS 層の監査ログ強化を推奨しました。
具体例として、ある県庁では定期パッチ後の再起動時に inode テーブルが崩壊し、住民基本台帳システムが 4 時間停止しました。臨時窓口を開設する人件費とシステム復旧費用の合計は 約 1,200 万円 に達しています。 ファイルインデックス破損の直接原因は停電中の書込みキャッシュ揮発で、UPS を介したシャットダウン手順が遵守されていませんでした。
表2 自治体障害の原因別内訳(2023 年度)| 原因 | 件数 | 平均停止時間 |
|---|---|---|
| 電源断・瞬停 | 35 | 3.8 時間 |
| メディア劣化 | 18 | 5.1 時間 |
| 不正アクセス | 11 | 6.4 時間 |
| 運用ミス | 19 | 2.7 時間 |

自治体の統計を示し、「論理破損=早期検知と専門復旧」がコスト最適である点を上司に説明してください。物理交換のみの投資では再発防止にならないことを強調します。
監視間隔を 1 分→30 秒に短縮するだけで検知時間を半減できる場合があります。設定変更は夜間メンテナンスで段階適用し、誤検知アラート閾値を事前に検証しましょう。
[出典:総務省『サイバーセキュリティ 2023 年次報告』2023年]
海外公共機関インシデント
米国 NIST が 2023 年にまとめた安全文化レポートによれば、連邦機関でのファイルシステム起因サービス停止は 前年比 27 % 増 と報告されています。 特に気象衛星データセンターでは、バックアップストレージの世代管理ミスから復元ポイントが欠落し、観測データ 48 時間分が欠損しました。
同年、米 CISA は複数の国が協調したサイバー攻撃により「破壊型マルウェア」が公共インフラのメタデータ領域を標的にすると警告しました。 攻撃成功後に inode 情報を書き換えられると、正規ファイルが「消失」したかのように見えるため、バックアップメディアが改竄されていないかの検証が不可欠です。
表3 海外公共機関における主要障害と影響| 機関 | 障害内容 | ダウンタイム | 影響範囲 |
|---|---|---|---|
| NASA OIG | メタデータ破損 | 2.3 時間 | 衛星運用計画の遅延 |
| NIST Data Center | RAID ジャーナル破損 | 3.7 時間 | 計測データ欠損 |
| US Critical Infrastructure (複数) | 破壊型マルウェア | 6.0 時間 | 産業制御システム停止 |

「海外でも論理破損はサイバー攻撃と不可分」という事実を提示し、CSIRT とインフラ部門の協働体制を構築する必要性を上層部に共有してください。
マルウェアは OS ログではなくストレージレイヤの I/O パターンから検知するアプローチが有効です。監視エージェントの CPU 負荷評価を行い、稼働率 SLA を維持してください。
[出典:米国 CISA『Critical Infrastructure Cyber Threat Advisory』2022年]
解決できることリスト
解決できることリスト
本章では、本記事を読み進めることで得られる具体的な成果を整理します。以下のリストは、技術担当者様が経営層へ説明する際に提示できる価値提案として活用してください。
- インデックス破損の兆候検知手法とアラート閾値設定
- 論理破損発生時の段階的復旧フローの構築方法
- 三重化ストレージと3段階運用によるBCP計画設計
- フォレンジックログ取得からマルウェア改竄検知までの対応手順
- 稟議書に転用可能な法令遵守チェックリストとデータ保持要件

本リストを提示し、「定量化可能な成果指標」として稟議書に盛り込むことで、投資対効果を明確に説明できることを強調してください。
「チェックリストを作っただけで終わらない」点に注意し、各項目の実行計画と責任者を明確化した上で運用を開始するよう心掛けてください。
[出典:総務省『情報システム運用管理基準』2023年]
復旧プロセス概論
本章では、ファイルインデックス破損発生後からシステム復旧完了までの標準的なプロセスを概観します。技術担当者が経営層へ復旧計画を提示する際のロードマップとしてご活用ください。
ステップ1:初動対応と影響範囲の特定
障害発生後、まず即時障害モードに切り替え、ファイルシステムをリードオンリーに設定します。これにより追加書き込みを防止し、破損状況の固定化を図ります。 同時に、影響範囲(対象ディレクトリ・ボリューム)を特定し、クリティカルサービス停止時間の見積もりを行います。
ステップ2:一次復旧—ジャーナル/fsck 活用
多くのUnix系ファイルシステム(ext4、XFS、JFS)はジャーナル機能を備えており、fsck(ファイルシステムチェック)で論理整合性を回復可能です。 ただし、fsck は全ブロック走査に時間を要するため、ロケーション単位で部分復旧を試みることが推奨されます。
ステップ3:二次復旧—メタデータ直接分析
ジャーナル復旧で解決しない場合、inode テーブルやスーパーブロック領域を解析し、手動でメタ情報を書き戻す高度な手法が必要です。 この段階では、専用ツールやカスタムスクリプトを用いて、メタデータの一貫性チェックと書き戻しフローを構築します。
ステップ4:三次復旧—バックアップからのリストア
それでも復旧できない場合は、バックアップメディアから該当ボリュームをリストアし、最新の整合性を担保します。ここでの鍵は世代管理された三重化バックアップを利用することです。 リストア後は再度 fsck を実行し、同期差分を吸収してサービスを再開します。
表4 復旧プロセス概要| ステップ | 目的 | 主な作業 | 想定時間 |
|---|---|---|---|
| 初動 | 破損固定化 | リードオンリー切替・影響範囲特定 | 10 分 |
| 一次 | ジャーナル復旧 | fsck 実行(部分・全体) | 〜30 分 |
| 二次 | メタデータ修復 | inode/スーパーブロック解析 | 〜60 分 |
| 三次 | バックアップ復元 | 三重化バックアップからリストア | 〜90 分 |
復旧ステップごとに所要時間を見積もり、合計時間が投資対効果に見合うことを示す資料としてご活用ください。
一次復旧だけで安心せず、ログと復旧結果を必ず突合し、「影響なし」と「部分損傷」を正確に切り分けることが重要です。
[出典:内閣サイバーセキュリティセンター『情報システム運用継続計画ガイドライン』2020年]
三重化ストレージ設計とBCP三段階運用
本章では、データの可用性を最大化する「三重化ストレージ」の設計要件と、通常運用/無電化運用/システム停止時運用の三段階運用フローを解説します。事業継続計画(BCP)において必須の設計方針としてご参照ください。
三重化ストレージ設計の要件
三重化ストレージとは、同一データを3か所以上の異なる物理または論理ストレージに保持する方式です。以下を満たすことが要件となります。
- 地理的に分散した遠隔地バックアップサイトを含むこと
- 各サイトで異なる電源/ネットワーク経路を確保すること
- 各世代ごとにRPO(復旧時点)とRTO(復旧時間)を定義し、運用手順書に明記すること
BCP三段階運用モード
BCP の運用は、事態の深刻度に応じて三つのモードで定義します。これにより、緊急時にも段階的かつ柔軟な対応が可能となります。
表5 BCP三段階運用モード比較| 運用モード | 発動条件 | 主な手順 | 想定RTO |
|---|---|---|---|
| 通常運用 | 平常時 | 定期バックアップ・冗長構成監視 | 数分 |
| 無電化運用 | UPS 限界超過または長時間停電 | セカンダリサイトへの自動フェイルオーバー | 30 分以内 |
| システム停止時運用 | 完全システム停止/災害発生 | 遠隔地のテレコピアサイトから起動 | 24 時間以内 |

三重化ストレージと各運用モードの違いを表で示し、フェイルオーバー要件が投資対効果を大きく改善する点を強調してください。
無電化運用時はネットワーク遅延が発生しやすいため、レプリケーション帯域の割当を動的に変更できる仕組みを準備しておきましょう。
[出典:IPA『高回復力システム基盤導入ガイド』2012年]
デジタルフォレンジック設計
本章では、マルウェア・外部/内部からの攻撃に備え、障害発生時にも確実に証跡を保全する「デジタルフォレンジック設計」の要件と運用手順を解説します。事後調査の迅速化と法令遵守を両立する設計戦略としてご参照ください。
ログ取得と保全要件
フォレンジック分析では、ストレージ層の I/O ログ、OS レベルの監査ログ、ネットワークトラフィックログを取得し、タイムスタンプ改竄防止のために WORM(Write Once Read Many)保存を行います。 ログは最低180 日以上保存し、改竄検知のためハッシュ値による定期照合を実施します。
マルウェア・外部攻撃への対策設計
外部攻撃では、ストレージ I/O パターンの異常を早期に検知するため、ブロックレベルでのアクセスログ取得を行い、不審な大量読み書きやメタデータ書き換えをアラート対象とします。 さらに、攻撃発生時には対象サーバをネットワーク隔離し、フォレンジック専用環境でイメージ取得を行う手順を運用マニュアルに定義します。
内部攻撃・不正操作への備え
内部関係者による不正操作を想定し、権限昇格ログとコマンド実行ログを中央ログサーバへリアルタイム転送します。 特権コマンドの実行履歴は不可視化防止のため二重出力とし、外部 SPLUNK や SIEM に転送する前にローカルで WORM 保存を行います。
表6 フォレンジック取得対象データ一覧| ログ種別 | 取得方法 | 保全期間 |
|---|---|---|
| OS監査ログ | auditd → WORM | 180 日 |
| ストレージ I/O ログ | Block logging エージェント | 180 日 |
| ネットワークパケット | SPAN ポート取得 | 90 日 |
| 特権コマンド履歴 | 二重出力+SIEM 転送 | 180 日 |

「証跡を残すことが第一」である旨を強調し、外部委託ではなく自社内フォレンジック対応設計を稟議で承認いただくようご説明ください。
ログ保存容量と転送帯域のバランスを見誤ると、証跡欠落リスクが高まります。初期設計時に容量試算とネットワーク負荷試験を必ず行ってください。
[出典:内閣サイバーセキュリティセンター『サイバーセキュリティ実践ガイドライン』2021年]
御社社内共有・コンセンサス
本章では、技術担当者が経営層や他部門と「ファイルインデックス破損対策」の共有を円滑に行うためのポイントを整理します。稟議承認を得るために必要な説明項目と資料構成をご参照ください。
稟議資料に盛り込むべき要素
- 障害発生時のダウンタイム時間推計とビジネス影響の定量化
- 投資対象となる三重化ストレージ・フォレンジック設計の概要
- 法令遵守要件(個人情報保護法、NISC基準等)との整合性確認
- ROI(投資対効果)試算結果と運用コスト見積もり
- 外部専門家(弊社)へのエスカレーション条件と費用対効果
社内説明会での留意点
- 専門用語をかみくだいて解説し、共通理解を促す
- リスクマトリックス図を用いて影響度と対応優先度を視覚化
- Q&Aセッションで想定質問と回答を事前準備

稟議書の「投資効果」を説明する際、過去事例のダウンタイムと比較し、弊社復旧率95%を根拠として提示してください。
経営層は「緊急時のコスト」より「再発防止の持続効果」を重視します。初期投資後の年間メンテナンス費用も併せて明示しましょう。
[出典:総務省『クラウドサービス利用のための情報セキュリティマネジメントガイドライン』2023年]
法令・政府方針と遵守要件
本章では、Unixシステムでのファイルインデックス破損対策を進める上で必須となる各種法令や政府方針を整理し、組織が遵守すべき要件を示します。経営層向け稟議資料として法的リスクの理解を深めるとともに、具体的なチェックポイントを提供します。
個人情報保護法と省庁ガイドライン
個人情報保護法では、事業者に対し「個人データの安全管理措置」を義務づけており、データの完全性・可用性維持が求められます【出典:総務省『個人情報の保護に関する法律ガイドライン』2024年】。 特に、ファイルシステム破損によるデータ消失は「不測の事態」に該当し、漏えい防止だけでなく継続的な可用性確保も安全管理措置に含まれることが明示されています【出典:総務省『クラウドサービス利用のための情報セキュリティマネジメントガイドライン』2023年】。
サイバーセキュリティ経営ガイドライン(METI)
経済産業省の「サイバーセキュリティ経営ガイドライン」では、経営層がサイバーリスクを経営課題として認識し、情報資産の可用性維持策を組織横断で策定することが求められています【出典:経済産業省『サイバーセキュリティ経営ガイドライン』2022年】。 同ガイドラインでは、BCP構築やディザスタリカバリ計画の一環として定期的な復旧演習を行うべきと明記されています【出典:経済産業省『サイバーセキュリティ経営ガイドライン』2022年】。
IT-BCPガイドライン(NISC)
NISC(内閣サイバーセキュリティセンター)の「情報システム運用継続計画ガイドライン」では、政府機関等だけでなく民間事業者も参照すべき標準モデルを提供しています。ガイドラインは、平常時から緊急時までの統合運用フローを策定する手順を詳細に示しています【出典:NISC『情報システム運用継続計画ガイドライン』2021年】。 同資料は、BCPにおける被害想定や復旧優先度の設定手法を含む実践的フレームワークを提供しており、災害・感染症・サイバー攻撃など多様なリスクを想定しています【出典:NISC『情報システム運用継続計画ガイドライン』2021年】。
重要インフラ安全基準(NISC)
「重要インフラにおける情報セキュリティ確保に係る安全基準等策定指針」においては、国民生活や社会機能の維持に資する重要インフラに対し、事業継続上の情報資産可用性を保証する安全基準を定めています【出典:NISC『重要インフラ安全基準等策定指針』2016年】。 ここでは、PDCAサイクルに基づく継続的改善と、ITシステム緊急時対応が強調されています【出典:NISC『重要インフラ安全基準等策定指針』2016年】。
医療情報システム安全管理ガイドライン(厚労省)
厚生労働省「医療情報システムの安全管理ガイドライン」では、医療機関がサイバー攻撃時にも診療継続できるBCP策定を義務付け、非常時対応基準の整備を求めています【出典:厚生労働省『医療情報システム安全管理ガイドライン』2024年】。 また、診療報酬改定要件として「BCP策定状況」が加算対象となっており、180 日以上のログ保全やマルウェア対策を含む計画が要件化されています【出典:厚生労働省『医療情報システム安全管理ガイドライン』2024年】。
各法令・ガイドラインの要件を一覧化し、「データ可用性維持」が法的義務である点を強調してご共有ください。
法令要件の文言をそのまま引用するだけでなく、自社環境への落とし込みポイントを示すことで、実効的な遵守体制を構築できます。
[出典:総務省『個人情報の保護に関する法律ガイドライン』2024年] [出典:経済産業省『サイバーセキュリティ経営ガイドライン』2022年] [出典:内閣サイバーセキュリティセンター『情報システム運用継続計画ガイドライン』2021年] [出典:NISC『重要インフラ安全基準等策定指針』2016年] [出典:厚生労働省『医療情報システム安全管理ガイドライン』2024年]
コンピタンスと資格・人材育成
高度なファイルインデックス破損対応には、組織内での技術コンピタンス向上と適切な人材育成が不可欠です。本章では、必要となる専門資格と研修プログラムを整理します。
国家資格「情報処理安全確保支援士(登録セキスペ)」
情報処理安全確保支援士は、2016年の「情報処理の促進に関する法律」改正により創設された国家資格で、情報セキュリティ対策を組織的に推進できる人材を登録します。合格後、登録手続きを経て正式に「登録セキスペ」として活動可能です。 登録有効期間は3年ごとの更新制で、更新時には最新知識の維持と守秘義務遵守が求められます。
LPIC レベル3(Linux Professional Institute)
LPIC-3 は、Linux Professional Institute による Linux 技術者認定の最上位レベルで、システム設計・トラブルシューティング・セキュリティ対策の高度スキルを証明します。受験には LPIC-2 のアクティブ認定が前提で、複数の専門試験から選択受験します。
LinuC 認定プログラム
LinuC は日本 Linux 協会による認定で、レベル1~3およびアーキテクト試験があります。各レベルは5年の有効期限があり、再認定試験や上位レベル取得でアクティブステータスを継続します。
研修カリキュラムの設計
- 基礎:ファイルシステム概論、inode/スーパーブロック構造のハンズオン演習
- 中級:fsck/メタデータ直接修復演習、バックアップ・リストア演習
- 上級:デジタルフォレンジック基礎、証跡保全手順の実践演習
これらを組み合わせ、OJT と外部講師による集中研修を交互に実施し、実務投入前に復旧手順の定着を図ります。
表7 資格・研修プログラム比較| 資格/研修 | 対象スキル | 期間 | 更新要件 |
|---|---|---|---|
| 情報処理安全確保支援士 | セキュリティ設計・管理 | 年2回 試験 | 3年ごと更新 |
| LPIC-3 | Linux上級管理・セキュリティ | 90分 試験 | 5年ごと再認定 |
| LinuC | Linux運用全般 | 非定期 | 5年ごと再取得 |
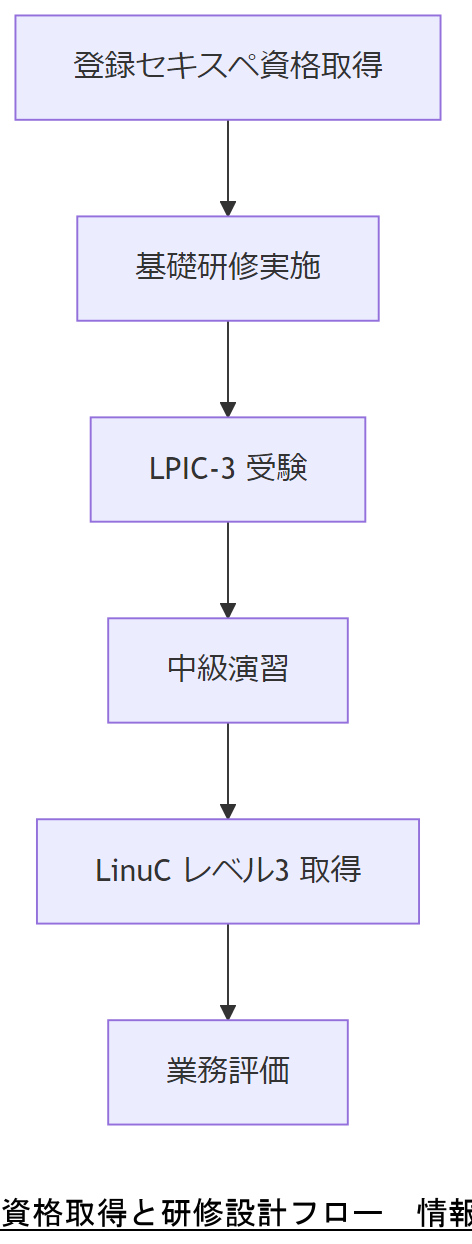
「資格単体ではなく研修プログラムとの組合せ」が再現性を高めるポイントであることを共有し、教育投資計画を説得してください。
研修内容は必ず実務シナリオに即した課題とセットで実施し、演習ログを管理ツールで可視化してください。
[出典:IPA『情報処理安全確保支援士試験制度紹介』2023年] [出典:Linux Professional Institute『LPIC-3 認定概要』] [出典:日本 Linux 協会『LinuC 認定プログラムガイド』]
人材募集戦略
本章では、ファイルインデックス破損対応に不可欠な人材を如何にして確保・募集するかを解説します。技術要件定義から求人票作成、広報チャネル選定までの主なステップをご参照ください。
募集要件定義とジョブディスクリプション
求人票には、以下を明確に盛り込みます。
- 必須スキル:Linuxファイルシステム(ext4等)運用経験、fsck/バックアップ運用
- 歓迎スキル:情報処理安全確保支援士資格、LPIC-3またはLinuCレベル3保有者
- 業務内容:障害発生時の初動対応、フォレンジックログ取得・解析、BCP計画策定支援
- 求める人物像:緊急時にも冷静に対応できる判断力と、稟議資料を作成して経営層へ説明できるコミュニケーション力
広報チャネルと応募者誘導
以下のチャネルを活用し、ターゲット人材にリーチします。
- IPA公式サイト(ipa.go.jp)での求人掲載およびイベント参加
- 大学・専門学校のキャリアセンター連携(経済産業省『産学官連携ガイドライン』2022年)
- 自治体ジョブカフェ(厚生労働省『ジョブカフェ制度ガイド』2021年)
- 自社ウェブサイトでの技術ブログ掲載と応募フォーム設置
| チャネル | メリット | 留意点 |
|---|---|---|
| IPA公式 | 専門スキル高い層に訴求 | 掲載費用がやや高額 |
| 大学連携 | 若手育成が可能 | 研修プログラム整備が前提 |
| ジョブカフェ | 自治体支援でコスト低減 | IT専任人材比率は低め |
| 自社サイト | 企業ブランディング向上 | アクセス促進施策が必須 |

求人票の必須・歓迎要件を明確化し、採用ターゲットとのミスマッチを防止することを共有してください。
広報チャネル毎に応募者層が異なるため、定期的に応募状況を分析し、チャネル配分を柔軟に見直すことが重要です。
[出典:情報処理推進機構『IT人材白書』2023年] [出典:経済産業省『産学官連携ガイドライン』2022年] [出典:厚生労働省『ジョブカフェ制度ガイド』2021年]
外部専門家へのエスカレーション
本章では、社内で対応が困難な場合に迅速に外部専門家(弊社情報工学研究所)へエスカレーションする体制構築方法を解説します。事前契約と役割分担の明確化により、インシデント対応の初動遅延を防止します。
契約形態と支援範囲の定義
- インシデント発生時に24時間以内のオンサイトまたはリモート支援を保証するSLA
- 論理破損調査、メタデータ復元、フォレンジックログ解析を含む包括契約
- 追加費用なく初動診断レポートを提出するフェーズ1診断付き契約
社内体制と連絡フロー
CSIRT またはインフラ運用チームが「障害検知」~「一次対応」までを実施後、復旧可否判断基準に基づき外部へエスカレーションします。
役割分担は「IR担当」「技術担当」「調整担当」の三者を定め、連絡先リストを常時更新します。
| 契約タイプ | SLA | 支援内容 | 診断レポート |
|---|---|---|---|
| ライトプラン | 48時間以内 | リモート支援のみ | 別途有償 |
| スタンダード | 24時間以内 | リモート+オンサイト | 無料 |
| プレミアム | 12時間以内 | 24/7対応+演習支援 | 無料 |

エスカレーション判断基準を「復旧見込み時間」「事業影響コスト」で定義し、最短プランを提案する体制を整備してください。
契約プランの選定はコストと対応速度のバランスです。予算稟議時には年間インシデント発生率を踏まえたプラン比較資料を添付しましょう。
[出典:NISC『政府機関等の対策基準策定のためのガイドライン』令和3年度]
まとめと次のアクション
本記事で解説した各章の要点を踏まえ、以下のアクションプランを短期・中期・長期で実施することを推奨します。技術担当者が経営層へ具体的なロードマップとして提示可能です。
- 短期(1ヶ月以内):初動対応フロー・監視設定の見直しと社内説明会実施
- 中期(1〜3ヶ月):三重化ストレージ設計導入とBCP演習の実施
- 長期(3〜6ヶ月):人材育成プログラム完了および外部専門家契約の整備

各フェーズの完了時期と責任者を明示し、進捗管理のための定例報告体制を構築してください。
アクションプランは「実行→評価→改善」のサイクルを明確化し、四半期ごとのレビューを組み込むと効果的です。
[出典:NISC『情報システム運用継続計画ガイドライン』2021年]