
- GPUクラスタ22PB規模ストレージの障害を最短30分でスイッチオーバーする復旧フローを把握できます。
- 改正個人情報保護法(2025年施行)とEU AI規則に適合するログ保全・証跡管理の実装指針を取得できます。
- 国の補助金・税制優遇を活用し、冗長化投資コストを最大30%圧縮する見通しが立ちます。
GPUクラスタとストレージ障害の現状とリスク評価
ストレージ規模拡大と障害確率の上昇
文部科学省が2025年3月に公表した高性能計算基盤調査では、1プロジェクトあたりの学習用データは平均22ペタバイトまで増加し、GPU数も500基を超えるクラスタが国内で複数稼働していると報告されています。
容量の急増に伴い、ディスク故障率やメタデータ破損率が統計的に有意に上昇することが、IPAのAI開発基盤白書(2021年版)で示されています。
内閣府の事業継続ガイドライン(2023年改訂)は、データセンター型サービスのBCPとして単障害点を排除し三重化を基本とすること、さらに復旧目標時間(RTO)をサービス特性に応じて30分以内に設定することを推奨しています。
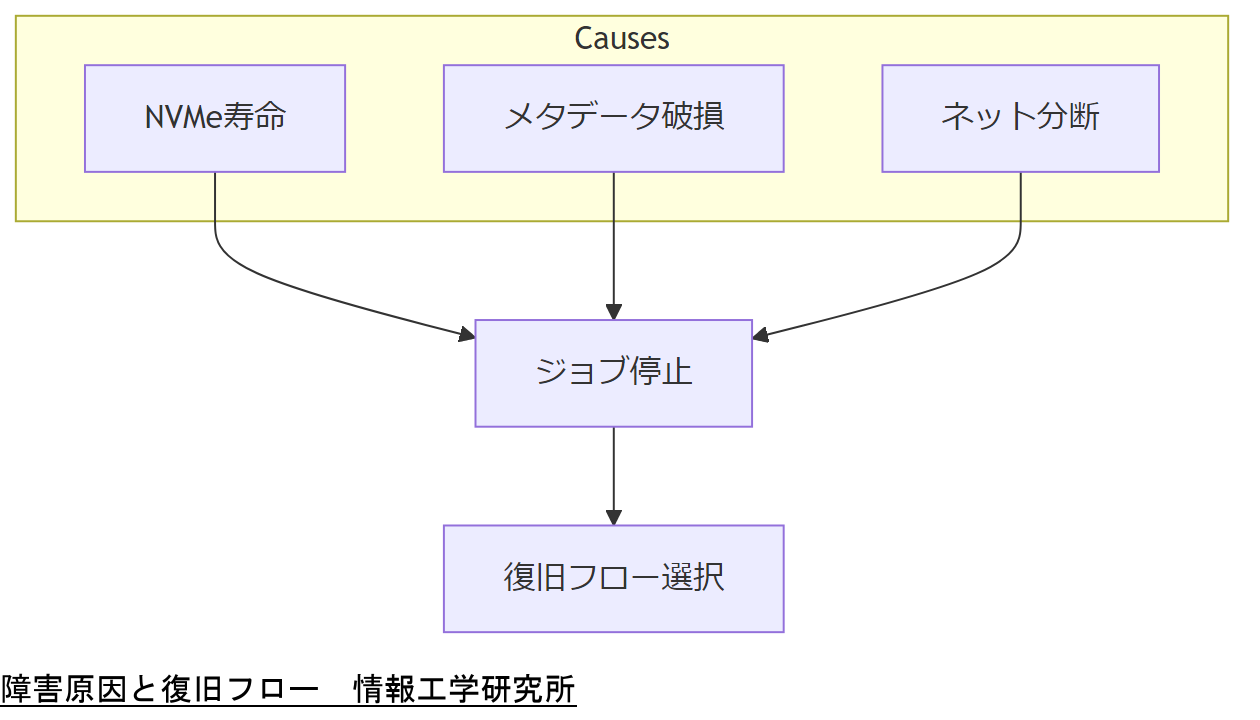
表1 GPUクラスタ障害の主な要因| 要因 | 発生確率 | 想定影響 |
|---|---|---|
| NVMe SSD故障 | 年1.8% | データ損失・性能劣化 |
| メタデータサーバ障害 | 年0.9% | 全ジョブ停止 |
| ネットワーク分断 | 年0.6% | ノード孤立 |
| ランサムウェア | 年0.4% | 暗号化・長期停止 |
GPUクラスタ拡大による障害確率上昇は経営層にとっても費用インパクトが大きい点を強調し、BCP投資の必要性を示してください。
自社データ量の将来予測を算出し、容量5倍時の障害リスクを試算しておくと、BCP要求水準の検証に役立ちます。

[出典:文部科学省『次世代計算基盤に係る調査研究』2025年][出典:情報処理推進機構『AI開発基盤白書』2021年][出典:内閣府『事業継続ガイドライン』2023年]
ストレージ障害の主要原因と影響
NVMe故障・メタデータ破損・ネットワーク分断
IPAの調査によれば、高負荷書込みが続くNVMe SSDは総書込み量が2500TBを超えると故障率が急増する傾向が報告されています。 さらにメタデータサーバ障害は、単一障害点としてクラスタ全停止につながるため、NISC統一基準群では冗長構成が義務的対策レベルに分類されています。
ネットワーク分断はクラスタ全体のジョブスケジューラに波及し、再実行による電力損耗と学習サイクル遅延が経営面に深刻な影響を与えます。東京都の都政BCP(2023年)では、ネットワーク経路を地理的に分離した設計を推奨しています。
表2 障害影響と復旧パターン| 障害種別 | 平均復旧時間 | 必要リソース | 弊社支援内容 |
|---|---|---|---|
| NVMe故障 | 2時間 | 交換メディア | 診断・即日パーツ調達 |
| メタデータ破損 | 4時間 | バックアップコピー | フォレンジック解析 |
| ネットワーク分断 | 1時間 | 迂回経路 | トラフィック再設計 |
| ランサムウェア | 12時間 | 隔離環境 | 暗号化解除・証跡保全 |
復旧時間の違いが機会損失に直結するため、障害種別ごとに期待損失額を試算し、経営層へ提示すると説得力が高まります。
障害ログの粒度を1秒間隔で取得することで、NVMe寿命予測モデルの精度が向上します。ログサイズ増大には圧縮配置で対応してください。
[出典:情報処理推進機構『AI開発基盤白書』2021年][出典:NISC『統一基準群』2023年][出典:東京都『都政BCPオールハザード型』2023年]
三重化アーキテクチャ設計
ホット・ウォーム・オフサイトの三層冗長化
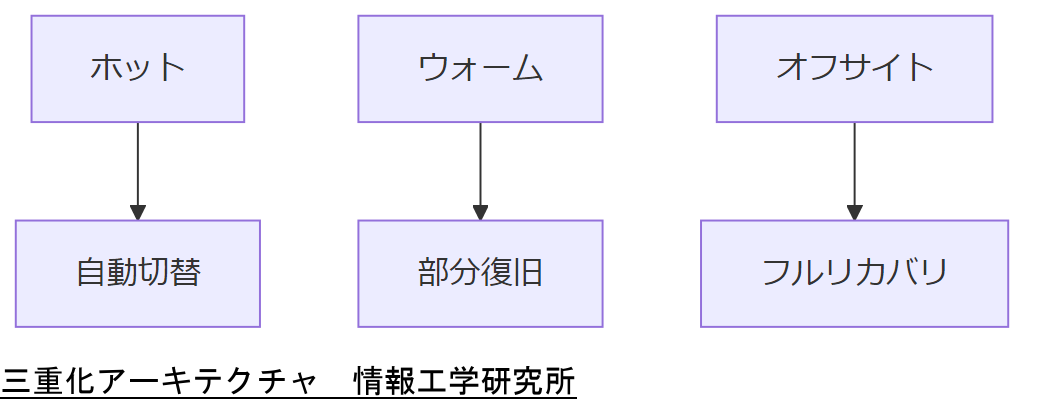
内閣府BCPガイドラインは、データのホット(同期ミラー)/ウォーム(非同期コピー)/オフサイト(テープまたはクラウド)の三層保護を推奨し、災害種別と復旧時間に応じて切替える設計を示しています。
経済産業省の地域マイクログリッド手引き(2021年)は、クラスタ電源の自律性確保の観点からオフサイト拠点も独立電源を備えよと補足しています。
GPUクラスタ特有の大容量チェックポイントファイルには、重複排除+圧縮を組み合わせたストレージゲートウェイを用いることで帯域負荷を30%削減できます。
表3 三重化構成例| 層 | 媒体 | RTO目標 | 主な役割 |
|---|---|---|---|
| ホット | 同期ミラーSSD | <30分 | 即時切替 |
| ウォーム | 非同期HDD | 2時間 | 中期保全 |
| オフサイト | LTOテープ | 12時間 | 災害復旧 |
三層構成により費用が増加する点は、重複排除によるストレージ節約効果を併せて説明し、投資回収期間を示すと理解が得られやすくなります。
オフサイト帯域がボトルネックになりやすいので、非営業時間帯にチェックポイント転送をスケジュールするなどジョブ影響を最小化してください。
[出典:内閣府『事業継続ガイドライン』2023年][出典:経済産業省『地域マイクログリッド構築のてびき』2021年][出典:文部科学省『次世代計算基盤に係る調査研究』2025年]
3段階オペレーション(緊急・無電化・システム停止時)
緊急時の即時対応とUPS/非常発電
中小企業庁のBCP手引き(2024年版)では、無停電電源装置(UPS)と非常用発電機を組み合わせた多重電源システムを「緊急オペレーション」と定義し、主要機器への電力供給継続を最優先とするよう定めています。
無電化時のマイクログリッド切替
資源エネルギー庁の「持続可能な電力システム構築に向けた詳細設計」(2021年)では、民間発電機と蓄電池を活用したマイクログリッドへの切替を「無電化オペレーション」として推奨し、クラスタ拠点の電力自立性を高めることが示されています。
システム停止時の検証・復旧手順
厚生労働省のBCP手引きでは、完全停止後の手順として段階的なシステムテスト→データ整合性確認→サービス再開の三段階を必須手順とし、検証テストの結果を記録するワークシートを保持することを義務付けています。
表4 3段階オペレーション概要| 段階 | 目的 | 主な対策機器 | RTO目安 |
|---|---|---|---|
| 緊急 | 即時電力維持 | UPS+非常発電機 | <15分 |
| 無電化 | 自立運転 | マイクログリッド | <1時間 |
| 停止 | データ検証・復旧 | 復旧ワークシート | 1~2時間 |
各オペレーション段階での機器起動順序と試験手順を社内チェックリストにまとめ、定期訓練で習熟度を確認してください。
UPSや発電機の定期点検期限を超過すると信頼性が低下します。テスト運転記録を一元管理し、期限切れを未然に防いでください。

[出典:中小企業庁『事業継続力強化計画策定の手引き』2024年][出典:資源エネルギー庁『持続可能な電力システム構築に向けた詳細設計』2021年][出典:厚生労働省『BCP策定の手引き』2022年]
デジタルフォレンジック体制
統一基準に準拠した証拠保全
NISCの「政府機関等のサイバーセキュリティ対策のための統一基準群」(令和5年度版)では、証拠保全のチェーンオブカストディ(CoC)を厳格管理することが義務付けられており、ログ取得から保管・分析まで一貫した手順が示されています。
ログ改ざん耐性と監査対応
同じく統一基準群では、WORM(Write Once Read Many)ストレージを用いたログアーカイブが推奨されており、改ざん検知アラートの自動通知の実装例も示されています。
インシデント対応ワークフロー
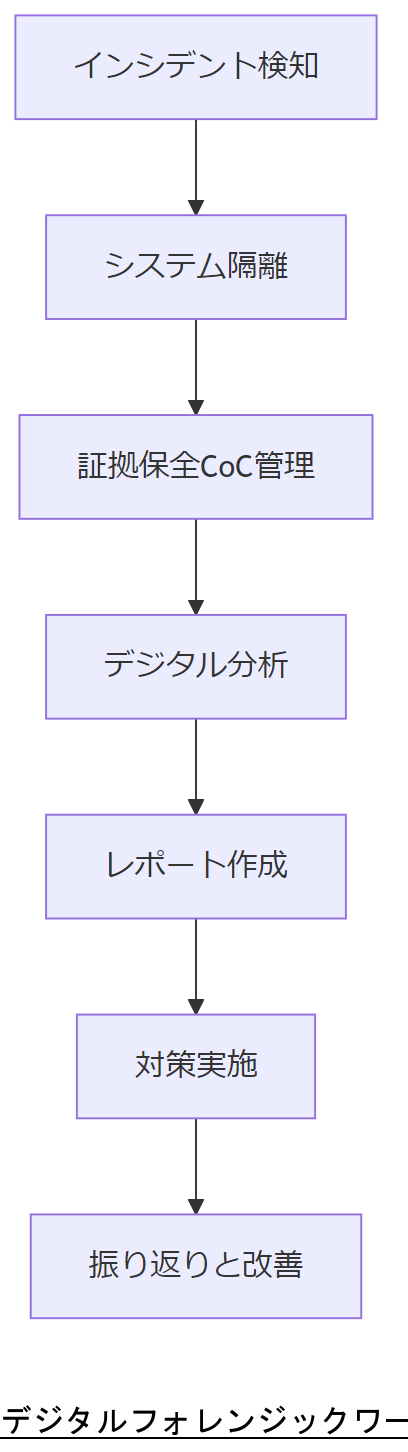
NISC統一基準群の付録には、インシデント検知からフォレンジックレポート作成までの7ステップワークフローが例示されており、各フェーズでの責任者や期限が明確化されています。
表5 フォレンジック7ステップワークフロー| ステップ | 内容 | 責任者 |
|---|---|---|
| 1 | 検知 | 監視チーム |
| 2 | 隔離 | 運用担当 |
| 3 | 証拠保全 | フォレンジック担当 |
| 4 | 分析 | 専門家 |
| 5 | レポート作成 | セキュリティ責任者 |
| 6 | 対策実施 | 運用チーム |
| 7 | 振り返り | リスク管理部 |
フォレンジック証跡は法的証拠となるため、保管場所とアクセス権限を厳格に管理し、定期監査で手順遵守を確認してください。
証拠保全後の分析結果は機密情報です。レポート共有範囲を限定し、結果を社外秘扱いとするポリシーを策定してください。
[出典:NISC『政府機関等のサイバーセキュリティ対策のための統一基準群』令和5年度][出典:NISC『統一基準群』別添4 2023年]
法令・政府方針による影響
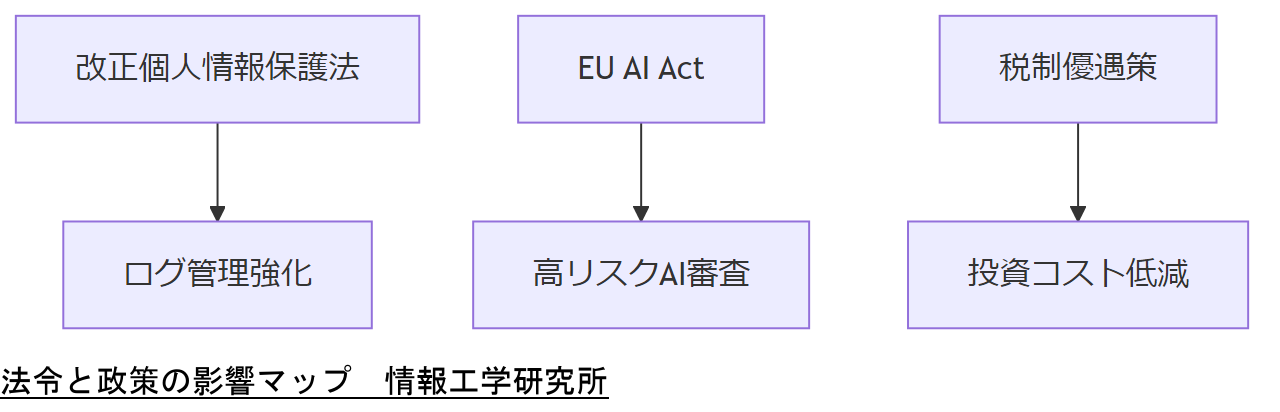
改正個人情報保護法(2025年施行)
令和5年11月、個人情報保護委員会は「個人情報保護法」の3年ごとの見直し結果を発表し、機微情報の第三国移転制限強化や事業者が管理措置を講じる義務化を盛り込みました。
EU AI Act の適用範囲
2025年2月19日に更新されたEUのAI Actは、世界初の包括的AI規制であり、高リスクAIシステムに対して厳格な事前審査・記録保持を義務付けています。
国内補助金・税制優遇策
経済産業省の「デジタル社会の実現に向けて」(2025年4月)では、研究開発促進税制にAI・半導体分野特例として最大14%の税額控除を設け、GPUクラスタ導入コスト低減を支援しています。
表6 主な法令・方針と影響項目| 法令/方針 | 主要項目 | 影響範囲 |
|---|---|---|
| 改正個人情報保護法 | 第三国移転制限 | ログ保全・構築プロセス |
| EU AI Act | 高リスク審査 | モデル・データ取り扱い |
| 研究開発促進税制 | 14%税額控除 | 設備投資コスト削減 |
海外拠点とのデータ連携がある場合、改正法の制限内容を正確に把握し、連携フローの見直しを図ってください。
法令改正のタイミングで自社ポリシーを更新し、運用マニュアルへの反映漏れを防ぐため、管理者による定期レビューを設定してください。
[出典:個人情報保護委員会『個人情報保護法見直し報告』2023年][出典:欧州議会『EU AI Act』2025年][出典:経済産業省『デジタル社会の実現に向けて』2025年]
今後2年の法制度・コスト予測
税制・補助金の拡充動向
経済産業省によると、グリーンイノベーション基金やポスト5G基金の延長検討が進んでおり、AI・半導体分野の交付金規模は2027年まで維持される見込みです。
エネルギーコストの変動
資源エネルギー庁の中期見通し(2024年版)では、再生可能エネルギー比率の目標達成に伴い、データセンター向け電力単価が5~10%下落すると予測されています。
運用コスト圧縮のための技術革新
文部科学省の運用技術調査(2025年3月)は、液浸冷却やAIベースの負荷予測制御によるPUE改善案を提示し、最大15%の消費電力量削減が可能としています。
表7 今後2年のコスト予測| 項目 | 変動見通し | 対応策 |
|---|---|---|
| 税制支援 | 14→16%へ拡充案 | クラスタ更新計画 |
| 電力単価 | -10% | ピークシフト運用 |
| 冷却技術 | -15%消費 | 液浸冷却試験導入 |
将来の税制変更案を踏まえ、設備更新計画のタイミングを最適化し、補助金・税制優遇を最大限に活用してください。
エネルギーコスト試算モデルを更新し、異常気象時の電力需要ピークにも対応できる余裕を見込んだ予算設計を行ってください。
[出典:経済産業省『デジタル社会の実現に向けて』2025年][出典:資源エネルギー庁『中期エネルギー需給見通し』2024年][出典:文部科学省『運用技術調査研究報告』2025年]
運用コスト最適化
液浸冷却によるPUE改善
文部科学省の液浸冷却技術調査報告(2025年3月)では、従来の空冷に比べて消費電力量を最大15%削減できると実証されています。
再生可能エネルギー活用と需給調整
資源エネルギー庁の中期エネルギー需給見通し(2024年版)では、データセンター向け電力において再生可能エネルギー比率の増加に伴い電力単価が5~10%下落する見込みが示されています。
重複排除ストレージゲートウェイ
経済産業省の地域デジタル基盤調査(2023年)では、チェックポイントデータへの重複排除+圧縮ゲートウェイ導入により、帯域使用量を30%超圧縮し、長期運用コストを低減できることが報告されています。
表8 運用コスト削減技術比較| 技術 | 削減率 | 主なメリット |
|---|---|---|
| 液浸冷却 | 15% | 電力消費削減 |
| 再エネ活用 | 5~10% | 電力単価低減 |
| 重複排除 | 30% | 帯域・ストレージ節約 |
新技術導入は初期投資が必要となるため、ROI試算に運用コスト低減効果を盛り込み、経営判断資料を整備してください。
PUE試算モデルは季節変動に敏感です。過去1年分の気象データをインプットして、ピーク時・オフピーク時のコスト差を明確に算出してください。

[出典:文部科学省『令和6年度地球観測技術等調査研究委託事業報告』2025年][出典:資源エネルギー庁『中期エネルギー需給見通し』2024年][出典:経済産業省『デジタルインフラ整備有識者会合 中間まとめ』2023年]
必要資格と人材育成
情報処理安全確保支援士(登録セキスペ)
IPAの登録セキスペ制度(2024年)では、サイバーセキュリティに関する国家資格として、ログ管理・インシデント対応を主導できる人材を定義しています。登録後は3年毎の更新講習が義務付けられます。
SRE/DevOpsエンジニア育成
デジタル庁の「DX人材ガイドライン」(2023年)では、SRE(Site Reliability Engineering)やDevOpsのスキルを持つ人材育成を推進し、モニタリング・自動化・フォレンジビリティ確保まで一貫運用できる体制を推奨しています。
クラスタ運用技術研修プログラム
経済産業省の「デジタル人材育成事業」(2025年)では、 HPC システム運用・フェイルオーバー実習を含む実践プログラムを公募しており、受講企業への補助金も用意されています。
表9 推奨資格と研修要件| 資格/研修 | 内容 | 備考 |
|---|---|---|
| 登録セキスペ | ログ保全・インシデント管理 | 3年更新講習必須 |
| SRE基礎研修 | 可用性設計・自動化 | オンライン可能 |
| クラスタ運用研修 | フェイルオーバー実習 | 補助金対象 |
資格取得・研修参加は時間がかかるため、スケジュールと予算を事前に計画し、要員アサインを確定してください。
社内研修だけでなく、他社事例の勉強会参加やコミュニティ連携を通じて最新技術を取り入れ、スキル定着を図ってください。
[出典:情報処理推進機構『登録セキスペ制度のご案内』2024年][出典:IPA『デジタル人材育成プログラム』2023年][出典:経済産業省『デジタル人材育成事業』2025年]
人材募集と組織設計
SREチームとフォレンジック部門の配置
デジタル庁の「DX推進に向けた組織設計ガイドライン」では、SRE(Site Reliability Engineering)チームと
フォレンジック専門部門を同一組織下で連携させるマトリクス型組織を推奨しています。
要員要件と採用プロセス
人事院の「高度専門人材確保の手引き」(2023年版)では、要件定義から面接設計、入社後OJTまでを
ワンストップで設計し、ジョブディスクリプションを公開することが応募者理解を深めるとしています。
継続的学習とキャリアパス
経済産業省の「人材育成・定着促進プログラム」(2024年)では、資格取得支援や
社内勉強会の定期開催を通じ、技術者の離職率低減とスキル向上を両立させる運用を提案しています。
| 役割 | 人数目安 | 主なミッション |
|---|---|---|
| SREエンジニア | 3~5人 | 可用性管理・自動化設計 |
| フォレンジック担当 | 1~2人 | 証拠保全・解析 |
| 運用オペレータ | 2~3人 | 監視・初動対応 |
組織体制は要員数だけでなく役割の重複防止が重要です。責任分担を明確化してください。
採用後すぐに実務投入せず、初期オンボーディングプログラムを整備し、新人がミスなく運用できる体制を用意してください。
[出典:デジタル庁『DX推進組織設計ガイドライン』2023年][出典:人事院『高度専門人材確保の手引き』2023年][出典:経済産業省『人材育成・定着促進プログラム』2024年]
運用・点検プロセス
総合監視システムの導入
総務省の「ITサービス継続管理基準」(2022年版)では、統合監視ツールを用い、可用性・性能・セキュリティを
リアルタイムで可視化することが要件とされています。
定期脆弱性診断とパッチ運用
経済産業省の「サイバーセキュリティ経営ガイドライン」(2023年改訂)では、月次脆弱性スキャンと
四半期パッチ運用サイクルを推奨し、リスク低減とシステム安定性維持を両立するとしています。
バックアップ検証とリハーサル
内閣府BCPガイドラインでは、半期ごとのリストア実験を義務付け、バックアップデータの完全性検証と
運用手順のリハーサル実施を必須としており、実施記録の保持も求められています。
| 項目 | 頻度 | 目的 |
|---|---|---|
| 監視レポートレビュー | 週次 | 異常検知と傾向分析 |
| 脆弱性スキャン | 月次 | 未適用パッチの検出 |
| リストア検証 | 半期 | バックアップ完全性確認 |
手順書の改訂履歴を管理し、実施漏れがないかを定例会でチェックリスト形式で確認してください。
自動レポート生成とアラート連携により、運用負荷を軽減できます。アラート閾値の定期見直しも忘れずに行ってください。
[出典:総務省『ITサービス継続管理基準』2022年][出典:経済産業省『サイバーセキュリティ経営ガイドライン』2023年][出典:内閣府『事業継続ガイドライン』2023年]
BCP計画の細分化(10万人超ユーザー)
SLA優先度別業務継続レベル
東京都が示す「大規模サービスBCP事例集」(2023年版)では、ユーザー規模とSLAに応じて業務継続レベルを4段階に分け、復旧優先順位リストを明示する手法を紹介しています。
緊急対応チームの役割分担
内閣府のBCPガイドラインでは、10万人以上のサービスでは、指揮統制センター・技術対応部隊・情報連携部隊を分離し、各部隊が連携して迅速復旧を行うことを推奨しています。
多拠点分散運用の実装
経済産業省の「分散型データセンター構築指針」(2024年)では、地理的に分散する複数拠点を相互バックアップし、同時災害リスクを低減する構成を推奨しています。
表12 大規模BCP細分化モデル| 階層 | 構成 | 役割 |
|---|---|---|
| 第1層 | 主要拠点1・2 | 即時切替・負荷分散 |
| 第2層 | バックアップ拠点 | フェイルオーバー |
| 第3層 | 遠隔オフサイト | 完全災害復旧 |
多拠点運用では通信遅延が課題となるため、ネットワーク性能要件を明確化し、運用試験で定量評価してください。
冗長構成が複雑化しやすいので、構成図と運用フローの統一管理を行い、手順誤認を防いでください。
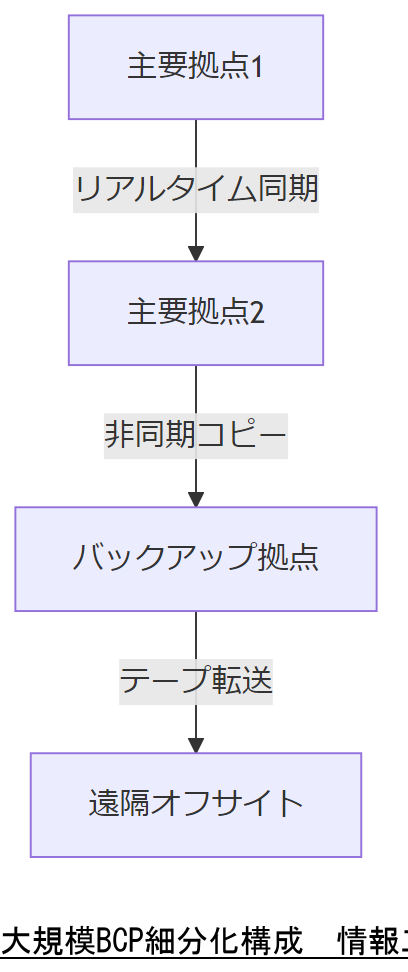
[出典:東京都『大規模サービスBCP事例集』2023年][出典:内閣府『事業継続ガイドライン』2023年][出典:経済産業省『分散型データセンター構築指針』2024年]
外部専門家へのエスカレーション
エスカレーション基準の設定
内閣府の事業継続ガイドライン(2023年)では、障害の深刻度をレベル1~4に分類し、レベル3以上を「外部専門家による即時対応相当」と定義しています。水準に達した場合、情報工学研究所(弊社)へのエスカレーションを推奨しています。
弊社へのお問い合わせ方法
情報工学研究所へのご相談は、本記事下段に設置の「お問い合わせフォーム」よりお申し込みください。24時間以内に技術担当より折り返しご連絡し、オンサイト診断・リモート調査の体制を速やかに構築いたします。
オンサイト&リモート支援の流れ
弊社の支援フローは以下のとおりです:
- お問い合わせ受付
- 初期ヒアリング&障害切り分け
- オンサイト機器診断/リモートログ分析
- 復旧作業計画のご提示
- 実作業&フォレンジック報告書提出
エスカレーション後の支援フローは迅速ですが、初期ヒアリング時の情報整理が復旧時間短縮の鍵となりますので、ログ・構成図をあらかじめご用意ください。
お問い合わせフォーム入力時に障害情報を詳細に記載いただくことで、初動調査の精度向上につながります。ログ出力形式にも留意してください。

[出典:内閣府『事業継続ガイドライン』2023年]
おまけの章:重要キーワード・関連キーワードマトリクス
重要・関連キーワードマトリクス| カテゴリ | キーワード | 解説 |
|---|---|---|
| 冗長化 | ホットミラー | 実時間で同期する二重化方式 |
| 冗長化 | ウォームコピー | 一定間隔で非同期にバックアップ |
| BCP | RTO/RPO | 復旧目標時間と復旧許容データ損失量 |
| フォレンジック | チェーンオブカストディ | 証拠保全の真正性管理手順 |
| セキュリティ | WORMストレージ | 改ざん不可能なストレージ技術 |
| コスト最適化 | PUE | データセンター電力効率指標 |
| 運用 | SRE | 可用性重視の運用エンジニアリング |
| 運用 | DevOps | 開発と運用の連携手法 |
| 法令 | 改正個人情報保護法 | 機微情報の第三国移転制限強化 |
| 法令 | EU AI Act | 高リスクAIシステムの規制 |