【注意書き】本記事は、Linux上で運用されるCephクラスター障害と復旧(分散ストレージ復旧)の考え方について、一般的な情報提供を目的としてまとめたものです。実際の復旧可否(成功率)や所要時間は、クラスター規模、レプリカ数/EC設計、故障ドメイン、OSDの状態、ネットワーク帯域、ディスク性能、運用ポリシー、変更履歴などの条件で大きく変わります。障害対応はリスクが高く、誤操作で復旧率を下げることもあるため、個別案件では株式会社情報工学研究所のような専門家に相談のうえで判断してください。
その夜、HEALTHが赤くなった—「またか…」から始まるCeph障害の現実
夜間、通知が鳴ってダッシュボードを見ると、HEALTH_ERR。現場の頭の中はだいたい同じ流れになります。「よりによって今?」「結局、誰がどこまで見ればいいの?」「止めたら怒られる、でも放置もできない」。Cephは“分散ストレージ”であるがゆえに、単体サーバ障害の直感がそのまま通用しません。コンポーネントも障害の姿も多層で、復旧の成功率と復旧時間を左右する変数が多いからです。
まず事実として、Cephのデータ実体はRADOSに格納され、オブジェクトはOSD上に分散配置されます。その配置はCRUSHルール(および故障ドメイン)に従い、レプリケーション(複製)またはErasure Coding(EC)で冗長化されます。したがって「ディスクが1本死んだ」だけでも、クラスター全体としては 再配置(remap)・回復(recovery/backfill)・整合性確認(scrub) の負荷が連鎖します。ここでのボトルネックは、単に“残りのディスクが頑張る”ではなく、ネットワーク、OSDのスロットリング、PG(Placement Group)の状態遷移、MON/MGRの安定性、そしてクライアントI/Oの要求が絡み合って決まります。
「成功率」と「時間」を分けて考えると、判断がブレにくい
復旧対応の現場では、成功率(復旧できる見込み)と時間(いつ戻るか)を混同しがちです。たとえば、PGがdegradedでもクライアントI/Oが継続できる場合は「時間はかかるが成功率は高い」ことがあります。一方、複数OSD喪失でPGがinactiveやincompleteに入ると、データの可用性が落ち、場合によってはデータ欠損のリスクが現実になります。つまり、同じ“赤い”でも意味が違います。
この差を早い段階で見抜くために、最初に揃えるべきは「ログを全部読む」ではなく、クラスターが今どの状態遷移にいるかを把握することです。Cephは内部で状態機械のように進みます。手順が曖昧だと、焦って設定をいじり、回復を遅らせたり、最悪の場合は復旧率を下げる操作(たとえば状況に合わない強制操作)をしてしまいます。
心の会話:現場の本音を、いったん認める
「また“分散”のせいで原因が散らかってる…」
「ceph -s を見ても、結局“何をすればいいか”が書いてない」
「復旧って言われても、復旧してるのか悪化してるのか、数字が読めない」
こう感じるのは自然です。Cephは“自動回復”を持ちますが、自動回復=自動で最短復旧ではありません。自動回復はあくまで「可能な状態遷移に入る」ことであって、帯域・優先度・制限・障害範囲によっては、何時間も何十時間もかかりえます。
この章の結論:最初のゴールは「復旧を始める」ではなく「状態を固定する」
第1章の結論はシンプルです。障害直後にやるべきは、根性論で復旧を“加速”させることではなく、現状の状態(HEALTH・PG・遅延)を固定し、悪化要因を止めることです。次章以降で、復旧時間を支配する“時間軸”を分解し、どの数字を見れば成功率と時間の見通しが立つのかを具体化します。
何が壊れたかより「何が遅いか」—復旧時間を支配する時間軸の見方
Ceph障害対応で「原因は何ですか?」と聞かれる場面は多いのですが、実務的には、原因の確定より先に復旧時間の見通しが要求されます。上司・顧客・関係部門に説明する必要があるからです。ただ、Cephの復旧は“直線的に進む修理”ではなく、複数のフェーズが重なりながら進みます。だからこそ「いま何が遅いか」を時間軸で捉えると、説明も判断もブレにくくなります。
Ceph復旧をフェーズに分ける(現場向けの実用モデル)
障害発生から通常運転に戻るまでを、現場向けに分解すると概ね次のようになります。
- 検知・初動:HEALTHの変化、OSD down/out、MONのクォーラム変動、クライアント影響の有無を確認
- 影響範囲の確定:どのプール/サービスが影響を受けているか、PG状態で可用性を評価
- 安定化:MON/MGRの安定、ネットワーク飽和の抑制、誤操作リスクの排除
- 回復フェーズ:recovery/backfillの進行(データ再配置と複製/EC再構成)
- 整合性フェーズ:scrub/deep-scrubの追いつき、再発防止の監視指標整備
- 説明・再設計:原因と再発防止、運用ルール(変更管理、容量管理、故障ドメイン)の見直し
多くの現場で詰まるのは4番の回復フェーズです。ここは“自動”で進みますが、速度は自動では最適化されません。回復はクライアントI/Oと資源(CPU/ディスク/ネットワーク)を奪い合うため、闇雲に回復速度を上げると業務サービスが死にます。逆に慎重になりすぎると復旧が終わらず、障害が長期化します。
「何が遅いか」を切り分ける観測点(表)
| 遅さの正体 | 現象として見えるもの | 観測ポイント(例) | 対処の方向性(原則) |
| ネットワーク飽和 | 回復が進まない/クライアント遅延が増える | クラスタ間/ラック間帯域、NICエラー、スイッチ輻輳 | 回復優先度と帯域制限の調整、ボトルネック区間の特定 |
| OSD性能不足 | backfillが頭打ち/IOPSが出ない | OSDのディスク待ち、journal/WAL、DBサイズ、デバイス劣化 | 劣化OSDの隔離、回復対象の順序設計、性能不均衡の是正 |
| PG遷移の停滞 | peeringが終わらない/activeにならない | PG stateの偏り、stuck PG、OSDのflap | まず“揺れ”を止める(安定化)、原因OSD/ネットワークを潰す |
| 設定の過不足 | 回復が遅すぎる/速すぎてサービスが死ぬ | 回復関連の制限値、優先度、同時実行数 | “クライアント優先”を守りつつ段階的に調整(固定値の乱用は避ける) |
この章の結論:復旧時間は「障害の大きさ」より「ボトルネックの種類」で決まる
同じ“OSDが落ちた”でも、ネットワーク飽和が支配しているのか、OSD性能が支配しているのか、PG遷移が停滞しているのかで、時間の見積もりはまったく変わります。だから、まずは「原因のラベル付け」ではなく、遅さの正体を1つに絞るのが実務上の勝ち筋です。次章では、そのために最初に集めるべき“3つの数字”を具体化します。
まず集めるべき3つの数字—HEALTH/PG state/レイテンシで全体像を掴む
Cephの障害対応で最初にやることは、情報収集です。ただし、いきなりログの海に潜ると、判断が遅れます。最初の5〜10分で揃えるべきは、復旧可否(成功率)と復旧時間の見通しに直結する“3つの数字”です。ここが揃うと、上司や顧客への説明も、次の手も、格段に安定します。
数字1:HEALTHの種類と内訳(まず“赤の理由”を言語化する)
CephはHEALTH_OK / HEALTH_WARN / HEALTH_ERRのように健康状態を出しますが、重要なのはラベルではなく内訳です。たとえば、単に「OSDがdown」なのか、「MONクォーラムが不安定」なのか、「PGがinactive」なのかで意味が違います。特に、データ可用性に直結するのはPG関連の指摘です。
- OSD down/out:冗長性が残っていれば回復可能性は高いが、回復負荷が発生する
- PG degraded/undersized:冗長性が欠けた状態。可用性は保てることも多いが、追加障害に弱い
- PG inactive/incomplete:必要なピースが揃わずI/Oできない状態が発生しうる。データ欠損リスク評価が必要
ここで大事なのは、“いまデータが失われた”と決めつけないことです。CephはPGの状態により一時的にアクセス不能になっても、OSDが戻れば復旧することがあります。一方で、物理故障や人的ミスでOSDが完全に失われ、冗長性も失っているなら、欠損が現実になります。最初の段階では「事実として何が起きているか」を押さえます。
数字2:PG stateの偏り(回復が進む状態か、停滞する状態か)
復旧時間の見通しに最も効くのがPG stateです。PGはCephの“配置と回復の単位”で、PGの状態遷移が回復の進み具合を表します。ここで見るべきは、単発のPGではなく「状態の分布」です。
- remapped が多い:再配置の最中。回復がこれから増えるサイン
- degraded が多い:複製/ECピース不足。回復が走れば減っていくはず
- backfill_wait が多い:回復対象があるのに順番待ち。制限値や資源不足が疑わしい
- peering が長い:OSDのflapやネットワーク不安定などで状態が固まらない可能性
ここでの“現場のコツ”は、PG stateを見たら、すぐに「増えているのか、減っているのか」を追うことです。Cephの回復は時間とともに状態分布が変わります。減るべきものが減っていないなら、ボトルネックがある。逆に減っているなら、回復は進んでいる。これだけで、復旧時間の説明が現実的になります。
数字3:クライアントレイテンシ(“回復を速める”前に、サービス影響を測る)
回復が遅いと、つい回復設定を上げたくなります。しかし、Cephは回復処理がクライアントI/Oと同じ資源を使います。特に、RBDやCephFS、RGWなどの利用があるクラスターでは、回復を優先しすぎるとアプリ側の遅延が増え、障害が“二次災害”化します。
そのため、初動で必ず押さえるべき事実は「クライアントI/Oはどれくらい遅いか」です。現場の会話としてはこうです。
「回復は進めたい。でも、業務のDBが死んだら、結局もっと怒られるんだよな…」
この判断を支えるのがレイテンシです。レイテンシが既に悪化しているなら、回復速度を上げる前に、まずボトルネック(ネットワーク/特定OSD/フラップ)を潰し、安定化してから段階的に調整するのが原則です。
この章の結論:「3つの数字」が揃うと、復旧の“筋”が見える
HEALTHの内訳で「何が危険か」を言語化し、PG stateの分布で「進んでいるか停滞しているか」を判断し、レイテンシで「回復をどこまで攻めてよいか」を決める。この3点が揃うと、復旧の成功率と時間に関して、少なくとも“根拠のある説明”が可能になります。次章では、MON/MGRの揺らぎがなぜ成功率を下げやすいのか、そして“状態を固める”ために何を優先すべきかを掘り下げます。
MON/MGRの揺らぎが“復旧の成功率”を下げる理由
Ceph障害対応で意外と見落とされがちなのが、MON(Monitor)とMGR(Manager)の“揺らぎ”です。ディスクが壊れた、OSDが落ちた、という分かりやすい故障より先に、MON/MGRの不安定さが復旧の成功率や時間に影響することがあります。理由はシンプルで、Cephのクラスタ状態(OSDMap、PGMap、CRUSH mapなどの各種Map)はMONが正として配布し、MGRは統計・モジュール・運用可視化の中心になるからです。
現場の心の会話は、だいたいこうです。
「OSDが死んだのは分かる。でも、なんか全体がフワフワしてる…」
「復旧を進めたいのに、Mapが安定しない。見てる数字が信用できない」
こういう状態は、復旧手順を正しく踏んでも結果がブレやすく、“成功率が下がる”方向に働きます。なぜなら、OSDがdown/upを繰り返す(フラップ)状況や、ネットワーク分断に近い状況では、PGのpeeringが進まず、回復対象の再配置が何度もやり直しになり、復旧に必要な帯域とI/Oが無駄に消費されるからです。
MONの本質:クォーラムが揃わないと「判断」そのものが揺れる
MONはクォーラム(過半数)で合意してクラスタの“正しい状態”を決めます。クォーラムが不安定だと、たとえば「OSDをoutにする/しない」「OSDMapの更新」「障害検知の確定」などが不安定になります。データプレーン(OSD同士のデータ処理)が一部継続していても、コントロールプレーン(判断と状態配布)が揺れると、回復フェーズの“やり直し”が起きやすくなります。
ここでの原則は、回復速度の調整より先に、MONを安定させるです。時計ずれ(時刻同期の破綻)、ネットワーク遅延・パケットロス、MONのディスクI/O詰まり、プロセス再起動ループなど、揺らぎの原因は複数あり得ますが、まずは「クォーラムが安定している」事実を作るのが最優先になります。
MGRの本質:復旧の“見通し”を支える観測点がここに寄る
MGRはCephの運用において、可視化やモジュール(Prometheus連携など)に関わる中心です。MGR自体が揺れてもデータが即座に壊れるわけではありませんが、障害時に重要な「進捗」「ボトルネック」「傾向」を取り損ねます。結果として、回復の見積もりが外れたり、誤った打ち手(例えば回復を上げすぎてクライアントI/Oを殺す)を取りやすくなります。
この章の結論:復旧の第一歩は「OSDを増やす」ではなく「コントロールプレーンを固める」
MON/MGRが揺れている状態では、PGもOSDも“正しく回復に向かって進む”前提が崩れます。復旧成功率を上げるという意味でも、まずはクォーラムの安定、ネットワーク品質、時刻同期、MONのI/O健全性を優先して整えます。次章では、OSD障害がPG状態としてどう現れ、どの状態が「時間がかかるだけ」なのか「可用性が落ちて危険」なのかを、もう一段具体的に整理します。
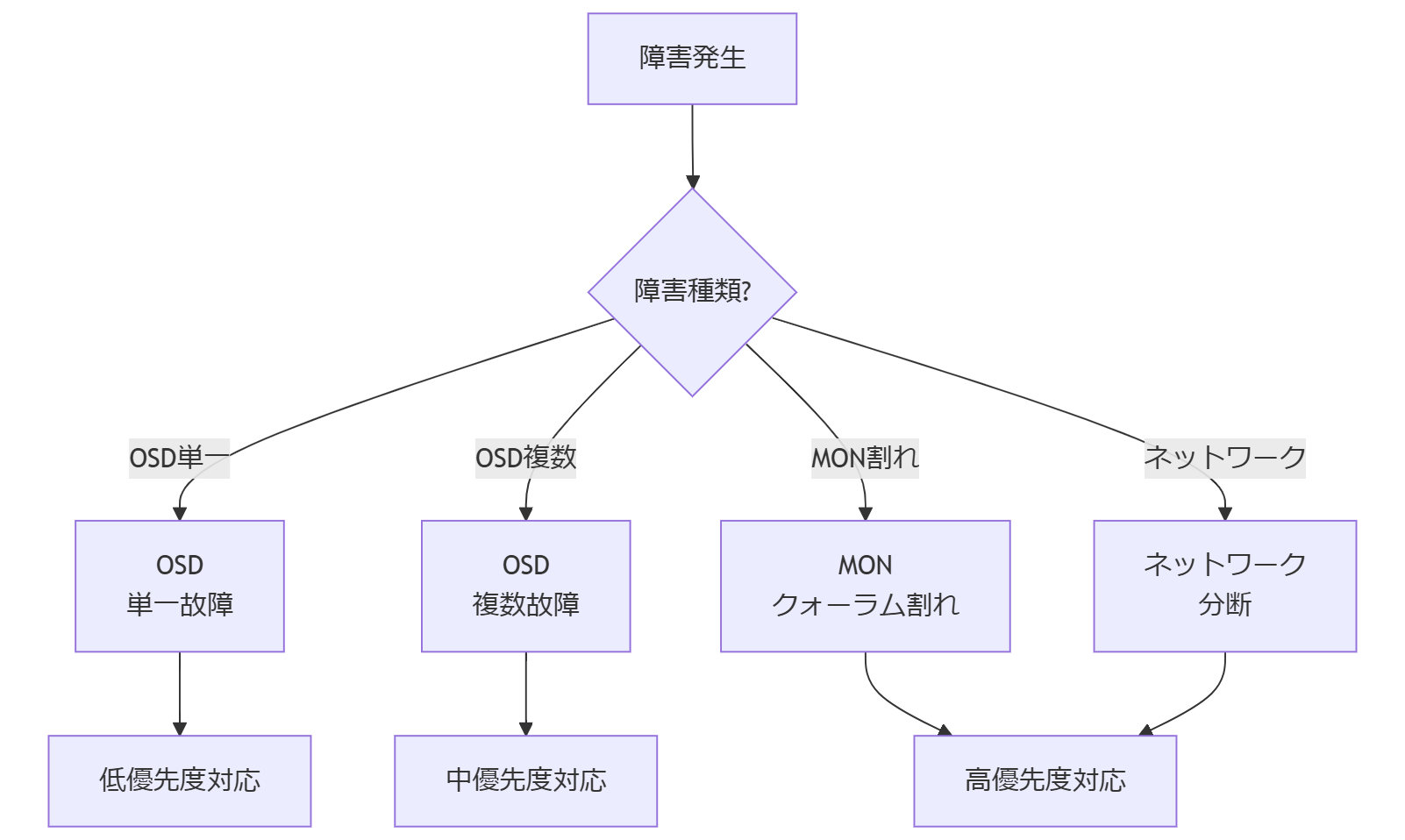
OSD障害とPG地獄—degraded/undersized/remappedの読み解きで迷子にならない
Ceph障害対応で“迷子”になりやすいのがPG状態です。OSDは物理的に壊れる・ネットワーク的に見えない・プロセスが落ちるなど、原因は比較的イメージしやすいのに、PGは状態名が多く、しかも複数状態が同時に付くため、読む順番を間違えると判断がブレます。ここは、成功率(戻せる見込み)と時間(どれだけかかるか)に直結するので、整理して見ます。
まず押さえる前提:OSD “down” と “out” は意味が違う
一般に、OSDが一時的に応答しない状態がdown、CRUSH上の配置対象から外された状態がoutです。downは「戻るかもしれない」、outは「戻らない前提で再配置が進む」方向に寄ります。ここで焦って強制的にoutを増やすと、回復(recovery/backfill)の対象データが一気に増え、ネットワークとディスクに負荷が集中して復旧が長期化しやすくなります。
現場の本音はこうです。
「戻るかもしれないOSDを、勢いでoutにしたら、結局“戻った後”にもっと地獄になりそう…」
この感覚は正しい疑いです。Cephは自己回復しますが、自己回復の“規模”は運用側の判断(outの扱いなど)で変わります。
PG状態の“危険度”をざっくり分類する
PG状態は詳細ですが、障害対応の初動ではまず次のように「危険度」を分類すると迷いにくいです。
| 分類 | 代表的な状態 | 意味(実務的な解釈) | 優先アクション |
| 時間はかかるが進む系 | degraded / remapped | 冗長性不足や再配置中。基本は回復が進めば減る | ボトルネック特定、回復の進捗が減っているか確認 |
| 順番待ち・詰まり系 | backfill_wait | やるべき回復があるのに進めない(資源や制限が原因になりやすい) | 制限値/帯域/OSD性能/ネットワークを疑う |
| 揺れ・停滞系 | peering が長い、stuck PG | 状態遷移が固まらない。OSDフラップやネットワーク品質が原因になりやすい | まず揺れを止める(OSD/ネットワーク/MON安定化) |
| 可用性が落ちる恐れ系 | inactive / incomplete | 必要なデータ片が揃わずI/Oが成立しない恐れ。欠損リスク評価が必要 | 影響範囲特定、戻せるOSDの優先復帰、慎重な判断 |
重要なのは、「状態名を暗記する」ことではありません。減るべきものが減っているか、揺れていて固まらないのか、可用性が落ちる兆候なのかを分けて考えることです。これができると、復旧時間の説明も「いまは回復が進んでいる」「いまはpeeringが停滞している」など、根拠ある言い方になります。
“PG地獄”を作る典型:OSDフラップと部分的ネットワーク不良
PGがいつまでも安定しない典型原因は、OSDがup/downを繰り返すフラップや、特定のラック・特定のスイッチ配下だけ品質が悪いといった“部分的”なネットワーク不良です。完全断ではなく、たまに通る・遅い・落ちる、という中途半端な状態が最も厄介で、PG peeringのやり直しや回復の巻き戻りを引き起こします。
この場合の現場判断は、「回復設定を上げる」ではなく、「揺れを止める」に寄ります。揺れが止まれば、回復は遅くても前に進みます。揺れが止まらなければ、速くしようとしても進捗が積み上がりません。
この章の結論:PG状態は“危険度”と“増減”で読むと、判断が早くなる
degradedやremappedは“回復フェーズ”のサインであり、進捗が減っているなら時間の問題になりやすい。一方でpeering停滞やstuckは“揺れ”のサインで、先に安定化が必要。inactive/incompleteが見えたら影響範囲とデータの成立条件を慎重に評価する。こうした読み分けができると、復旧成功率と時間の見通しが一段現実的になります。次章では、回復が「終わらない」状態をどう分析し、どこにボトルネックがあるのかを技術的に分解します。
backfill・recoveryが終わらない—優先度・制限・ネットワークが作るボトルネック
Ceph障害対応で最もつらい時間帯は、「回復が走っているのは分かるけど、終わる気配がない」局面です。数字は動く。けれど遅い。関係者からは「いつ終わるの?」と聞かれる。現場はこう思います。
「回復してるのに、ずっと終わらない。これ、何か間違ってる?」
ここは“根性”で乗り切るところではなく、ボトルネックを分解して見積もり可能な形に落とすところです。復旧時間は最終的に、回復対象のデータ量と実効スループットで決まります。実効スループットはネットワーク・ディスク・CPU・そしてCeph自身の制限値(スロットリング)の最小値に引っ張られます。
recovery と backfill を混同しない
用語としては環境や状況で見え方が変わりますが、実務的にはこう捉えるとよいです。
- recovery:冗長性を回復するためのデータ再構成(不足した複製やECピースを埋める)
- backfill:配置のズレを埋めるためのデータ移動(再配置後にデータを移す)
どちらも「ネットワークとディスクを使うデータ移動」です。違いは、トリガ(OSDのoutやCRUSH変更など)と、対象範囲の広がり方です。特に大きなクラスターでは、OSDの大量outやCRUSHルール変更があるとbackfillが広範囲に走り、時間が跳ねやすくなります。
“実効スループット”を決める3つの足かせ
回復が終わらないとき、だいたい足かせは次の3系統に分かれます。
1) ネットワーク:帯域だけでなく「品質」が効く
帯域が細いと遅いのは当然ですが、Cephでは“品質”も効きます。パケットロスや遅延があると、OSD間通信が不安定になり、回復が再送や待ちで詰まります。特定区間だけ悪い場合、PGの一部だけが停滞して「全体が終わらない」印象になります。回復は分散して進むので、遅いところが最後まで残るからです。
2) ディスク/OSD:遅いOSDが最後まで足を引っ張る
クラスターに性能の不均一があると、回復は“遅いOSD”に引っ張られます。特に障害で残存OSDに負荷が寄ると、普段は見えていなかった遅さが顕在化します。OSD側のI/O待ちが増えれば、回復もクライアントI/Oも同時に苦しくなります。
3) 制限値(スロットリング):安全のために意図的に遅くなる
Cephは、回復がクライアントI/Oを殺さないように、回復の同時実行数や優先度、スリープなどの制御(設定)を持ちます。ここを上げれば回復は速くなり得ますが、上げすぎれば業務I/Oが悪化します。つまり、ここは“アクセル”であり、踏む前にメーター(レイテンシ)を見る必要があります。
回復時間の説明を「見積もり」に寄せる(表)
| 見積もりに必要な材料 | 意味 | 詰まりやすいポイント |
| 回復対象のデータ量 | 失われた冗長性/再配置で動かす必要があるデータの総量 | out操作やCRUSH変更で急増しやすい |
| 実効スループット | 回復に使える帯域とI/O(ネットワーク×ディスク×制限値の最小) | 遅い区間・遅いOSD・制限値が“最後まで残る” |
| クライアント影響の上限 | 業務I/Oを壊さない範囲で回復をどこまで上げるか | 攻めすぎると二次障害、慎重すぎると長期化 |
この3つが言語化できると、「あと何時間ですか?」に対して、単なる希望的観測ではなく、条件付きで説明できます。たとえば「ネットワークがここまで空けば」「遅いOSDを隔離できれば」「回復設定を段階的に上げられれば」といった形です。これは現場にとっても救いになります。説明できる状態は、再現可能な運用に近づくからです。
この章の結論:終わらない回復は、だいたい“最後に残る遅い要素”が原因
回復は並列に進みますが、最後は遅いところが残ります。だから「全体の平均」より「遅い要素の特定」が重要です。ネットワーク品質、遅いOSD、過度に低い制限値、あるいは揺れ(フラップ)で進捗が積み上がらない。ここを特定できれば、復旧時間は“運”ではなく“見積もり”になります。次章では、実際に触る順番で結果が変わる理由を整理し、成功率を上げる「やること/やらないこと」を手順としてまとめます。
触る順番で結果が変わる—成功率を上げる「やること/やらないこと」
Cephの障害対応は、「何をするか」以上に「どの順番で触るか」で結果が変わります。復旧の成功率が落ちる典型は、焦って“加速”を狙った操作が、回復対象を増やしたり、揺れ(flap)を増幅させたり、クライアントI/Oを巻き込んで二次障害を起こすパターンです。逆に、順番を守るだけで、回復が“前に進む”状態に入りやすくなります。
心の会話:現場の疑いは健全です
「設定を上げれば早くなる?…でも、今それやっていいの?」
「OSDをoutにしたら回復が走るのは分かる。でも、戻る見込みがあるなら待つべき?」
この疑いはむしろ正しいです。Cephは自動回復しますが、回復の規模と負荷は運用判断(out扱い、制限、優先度、復旧対象の増減)で変わります。つまり、“早くしたい”がそのまま最短復旧にはならないことがあります。
やること:まず「揺れを止める」→「影響範囲を絞る」→「回復を進める」
実務で有効な優先順は、次の3段です。
- 揺れを止める(安定化):MONクォーラムが安定しているか、OSDがflapしていないか、ネットワーク品質(遅延・ロス)が局所的に悪化していないかを確認し、まず“状態が固まる”事実を作る。
- 影響範囲を絞る(評価):どのプール/サービスに影響が出ているか、PG状態分布が「進む系」か「停滞系」か「可用性低下系」かを分ける。ここで初めて成功率と時間の見通しが立つ。
- 回復を進める(段階調整):レイテンシを監視しながら、回復を段階的に調整する。最初から最大化しない。クライアントI/Oを守りつつ、回復が“減っていく”状態を維持する。
この順番を守ると、障害対応の会話が「気合い」ではなく「観測と判断」になります。関係者への説明も、「まず安定化」「次に影響評価」「最後に回復速度の調整」と段階が明確になり、意思決定が荒れにくくなります。
やらないこと:回復対象を“無駄に増やす”操作を初動で多用しない
初動で避けたいのは、回復対象を必要以上に増やし、backfill/recoveryの総量を膨らませる動きです。たとえば、戻る見込みがあるOSDを性急に「戻らない前提」に寄せると、回復対象が増え、ネットワークとディスクの奪い合いが激化して、結果として復旧が長引くことがあります。
もちろん、物理故障で戻らないOSDを待ち続けるのも危険です。要点は「戻る可能性の判断(根拠)」と「回復対象が増えるコスト」を天秤にかけることです。ここを曖昧にすると、成功率(安全に戻せる見込み)も、時間(終わる見通し)も両方が悪化しやすくなります。
判断をブレにくくするチェック表
| 確認項目 | 見たい事実 | 次の一手の方向 |
| MONクォーラム | 安定して維持されている(揺れない) | 揺れているなら回復調整より先に安定化 |
| OSDのflap | 特定OSDがdown/upを繰り返していない | 原因切り分け(ネットワーク/電源/ディスク/負荷)を優先 |
| PG状態の増減 | degraded/remapped等が時間とともに減っている | 減らないならボトルネック特定、無理な加速はしない |
| クライアント遅延 | 許容範囲で推移している | 悪化しているなら回復を攻める前に原因を潰す |
この章の結論:成功率を上げるコツは「大きく動かす前に、小さく確かめる」
Ceph復旧は、一撃で解決する操作があるタイプの障害対応ではありません。揺れを止め、影響範囲を言語化し、回復を段階的に進める。これだけで、復旧が“前に進む”確率が上がり、説明可能性も上がります。次章では、そもそも「復旧が短く終わるクラスター」は何が違うのか、設計と運用の観点から整理します。
復旧時間を短くする設計—CRUSH・故障ドメイン・容量計画・地味な監視
障害対応が長引くたびに、「結局Cephって難しい」「分散はコストが高い」と言われがちですが、実は復旧時間の長さは“運用の頑張り”だけではなく、設計段階の前提でかなり決まります。CephはCRUSHによってデータ配置を決めるため、故障ドメイン(host/rack/zone)設計と容量計画が、回復フェーズの負荷と時間を直撃します。
CRUSHと故障ドメイン:壊れ方に合わせて「散らす」
分散ストレージの狙いは、単一障害で全体が止まらないことです。しかし故障ドメインの設計が現実と噛み合っていないと、障害時に回復対象が偏り、回復が遅くなります。たとえば、同一ラック内のスイッチ障害が起きる可能性が高い環境で、データがラック内に偏る設計になっていると、ラック単位障害で同時に多数のOSDが影響を受けます。するとPGの可用性が落ちたり、回復対象が一気に膨らんだりして、復旧が長期化します。
要点は、「現実に起きる故障単位」を基準にCRUSH階層を設計することです。host故障が多いのか、ラック障害が現実的なのか、電源系が弱いのか、ネットワーク分断があり得るのか。ここを前提に置くと、復旧の成功率と時間が読みやすくなります。
容量計画:空きがないクラスターは、回復が遅い(そして危険)
復旧が遅いクラスターの共通点として、空き容量が逼迫しているケースがあります。回復は「別の場所に複製/再配置する」処理なので、空きが少ないと、配置の自由度が落ち、回復が詰まりやすくなります。さらに、空きがない状態で障害が重なると、回復どころか可用性が落ちる方向に寄りやすく、成功率の評価自体が厳しくなります。
現場の本音はこうです。
「今は動いてるけど、障害が起きたら回復する“余白”がない。これ、危ないよな…」
これは正しい危機感です。分散ストレージは“平常時の性能”よりも、“障害時に回復できる余白”が重要です。
監視:地味だが最強の短縮策は「詰まりを早く見つけること」
復旧時間を短縮する最も現実的な施策は、障害時に必要な観測点が、平常時から揃っていることです。障害時に慌てて計測を始めると、原因が消えたり、再現できなかったりします。最低限、次のような観測があると「遅さの正体」を早く絞れます。
- PG状態分布の時系列(増減が見えること)
- クライアントレイテンシの時系列(回復をどこまで攻められるか判断できること)
- ネットワーク品質(帯域だけでなく遅延・ロス・輻輳)
- 遅いOSDの特定(極端に遅いノード/デバイスが最後まで残るため)
この“地味な四点セット”があるだけで、復旧の説明が「雰囲気」から「数字」に寄ります。数字に寄るほど、関係者の納得と、現場の意思決定が安定します。
設計で効くポイント(表)
| 設計・運用の論点 | 復旧時間への影響 | 失敗しやすいパターン |
| 故障ドメイン | 同時障害の範囲を限定し、回復対象の爆発を抑える | 現実の故障単位とCRUSH階層がズレている |
| 容量の余白 | 回復の配置自由度が上がり、詰まりを減らす | 平常時に“使い切る”設計で、障害時に回復できない |
| 性能の均一性 | “遅い要素が最後まで残る”問題を緩和する | 一部だけ遅いディスク/ノードが混在し、回復が頭打ち |
| 監視の粒度 | 詰まりの原因特定が早くなり、無駄な試行錯誤が減る | 障害時に必要な時系列がなく、判断が後手に回る |
この章の結論:復旧を短くする最短ルートは「障害時に回復できる余白」を設計で持つこと
障害対応の手順を磨くのも重要ですが、復旧時間を短くする根本は、CRUSHと故障ドメイン、容量の余白、監視の準備にあります。ここが整っていると、障害時の打ち手が少なくて済み、復旧は“再現可能”になります。次章では、障害後に必ずやるべき事後分析(タイムライン化)を扱い、「次は同じ地獄を踏まない」ための整理に進みます。
次が楽になる事後分析—ログとメトリクスで“説明できるタイムライン”を作る
Ceph障害対応がひと段落すると、現場には「もう触りたくない…」という疲労が残ります。ですが、ここで事後分析を省くと、次の障害で同じ迷子を繰り返し、復旧時間も説明コストも増えます。事後分析の目的は“犯人探し”ではなく、次回の復旧成功率を上げ、復旧時間の見積もり精度を上げることです。
事後分析のコアは「時系列」と「因果」を分けること
障害報告が荒れる典型は、時系列(何が起きたか)と因果(なぜ起きたか)が混ざるケースです。まずは事実の列を作ります。たとえば、次のように「観測できる事実」を時刻順に並べます。
- 最初に検知したアラート(HEALTHの変化、レイテンシ上昇など)と時刻
- OSD down/up、OSD out/in の変化と時刻
- MONクォーラム変動、MGR切替などコントロールプレーンの変化
- PG状態分布(degraded/remapped/peering/inactive等)の推移
- 回復(recovery/backfill)の進捗が“減った/止まった/再加速した”時刻
- ネットワーク帯域・遅延・ロスなどの変化点
この「時系列」さえ作れれば、因果の議論が現実に寄ります。逆に、時系列が曖昧なまま「たぶんネットワーク」「たぶんディスク」と言い合うと、改善策が抽象化して、次に効きません。
最低限集めたい“証跡”は「再現性のある形式」で
障害時に後から効くのは、スクリーンショットよりも、機械可読な出力です。CephのCLIは人間向け表示もありますが、可能ならJSON形式を優先します。理由は、事後に同じ軸で比較でき、属人性が下がるからです。
- クラスタ概要:
ceph -s、ceph health detail(可能ならJSON出力) - PG観測:
ceph pg stat、stuck PGの情報(状態分布の推移を残す) - OSD観測:
ceph osd tree、ceph osd df、OSDごとの偏り - サービス影響:アプリ側レイテンシ、I/O待ち、タイムアウト増加の時刻
- 基盤観測:NICエラー、スイッチ側ログ(可能範囲)、時刻同期状況
ここでの現場の本音はこうです。
「あとで振り返るって言われても、結局“そのときの情報”が残ってないんだよな…」
だからこそ、障害対応の“途中”で、一定間隔で要点を採取する運用(またはスクリプト化)が効きます。これは「復旧を早くする」だけでなく、「説明できる」ことにも直結します。
“遅さの正体”を一言に落とす(改善が進む書き方)
事後分析の結論は、細部の羅列ではなく、遅さの支配要因を一言で言える形に寄せると、改善施策が刺さります。たとえば、次のような整理です。
| 支配要因の型 | 時系列で見える特徴 | 改善の方向 |
| ネットワーク品質型 | peering停滞やflapが出る。回復が進んだり戻ったりする | ボトルネック区間の特定、品質監視、設計(故障ドメイン)見直し |
| 遅いOSD型 | 最後に特定OSD/ノードが残り、全体完了が遅れる | 性能不均衡の解消、劣化デバイスの早期交換、混在構成の再検討 |
| 制限値・優先度型 | 回復が常に低速で安定。クライアント影響は小さいが完了が遅い | 段階的な調整指針の整備、障害時の運用Runbook化 |
| 容量逼迫型 | backfill_waitが多い、配置自由度が低く詰まる | 容量計画、余白確保、拡張計画とアラート閾値の見直し |
この章の結論:事後分析は「復旧の成功率」と「説明可能性」を同時に上げる投資
Ceph障害は、対応中の判断だけでなく、対応後の“学習”で難易度が下がります。時系列と証跡が残っていれば、次は早く状況を固定でき、どこが遅いかを短時間で絞れます。結果として復旧時間が短くなり、復旧成功率(安全に戻せる見込み)も上がります。次章では、ここまでの流れを踏まえて「一般論の限界」と「個別案件で専門家に相談すべき理由」を、現場目線でまとめます。
結論:Ceph復旧は「運」ではなく「数字と手順」で再現できる
Cephクラスター障害の復旧は、外から見ると“運ゲー”に見えることがあります。実際、分散システムには不確実性があり、障害の組み合わせも多いです。ただ、現場で再現性を作る鍵はあります。それが「数字(観測)」と「手順(順番)」です。本記事で扱ったのは、原因特定を急ぐより先に、復旧成功率と復旧時間に直結する事実を集め、揺れを止め、遅さの支配要因を絞るという考え方でした。
この結論に至る“伏線”を回収する
第1章で触れた「まず状態を固定する」は、MON/MGRの揺らぎやOSDフラップを止めることにつながります。第2章の「何が壊れたかより何が遅いか」は、回復対象量と実効スループットの観点に落ち、終わらない回復のボトルネック特定(ネットワーク品質・遅いOSD・制限値)に接続します。第3章の“3つの数字”は、状況説明の軸にもなり、事後分析で時系列を作る材料にもなります。つまり、書き出しのモヤモヤは、数字と手順に収束します。
ただし、一般論には限界がある(Cephは「条件の数」が多い)
ここが重要です。Cephは、設計(CRUSH/故障ドメイン、レプリカ/EC、ネットワーク構成、デバイス構成)と運用(監視、変更管理、障害時の判断基準)によって、同じ“症状”でも最適解が変わります。例えば、
- ECプールかレプリカプールかで、復旧時の計算・転送コストが変わる
- クラスター規模やPG数、OSD数で、回復の並列性や“最後に残る遅い要素”の形が変わる
- ネットワークが二重化されているか、分離されているかで、回復時のボトルネックが変わる
- 業務I/Oの特性(小IO中心か、大IO中心か)で、回復の攻め方が変わる
つまり「こうすれば必ず早い」「この設定が正解」と断言できる単一の処方箋は存在しません。ここを無理に一般化すると、かえって危険です。障害対応は、誤操作が取り返しのつかない結果につながり得るからです。
現場が本当に欲しいのは「判断の外注」ではなく「安全な意思決定の支援」
「また新しいツール?どうせ運用が増えるだけじゃないの」
「“それ、誰がメンテするの?”ってまず考える」
この感情は自然です。だからこそ、外部に相談するときも、丸投げではなく、現場の制約(止められない、移行コストを増やせない、夜間対応を減らしたい)に沿って、どこまでを“守り”、どこからを“変える”のかを一緒に設計できる相手が必要になります。
株式会社情報工学研究所のような専門家に相談する価値が出るのは、まさにここです。単なるコマンド手順の提示ではなく、
- クラスター設計と現実の故障モードの整合(故障ドメイン、容量余白、性能不均衡)
- 障害時の観測点(数字)とRunbook(順番)の整備
- 復旧時間の見積もりと、業務影響(レイテンシ)とのトレードオフ設計
- 事後分析の型化(説明可能性の確保、再発防止の実装)
といった「一般論では決めきれない部分」を、個別の条件に合わせて現実解へ落とす支援です。復旧成功率と復旧時間は、こうした意思決定の質に大きく依存します。
この章の結論:悩んだときは「条件整理」から始めるのが最短
もし今、具体的な案件・契約・システム構成の制約(止められない、性能要件が厳しい、増設が難しい、ログが残っていない等)で悩んでいるなら、まずは条件整理から始めるのが最短です。何を優先し、何を守り、どこを変えられるか。その整理ができると、復旧方針も、予防策も、費用対効果も現実的になります。必要に応じて、株式会社情報工学研究所への相談・依頼を検討してください。
付録:現在のプログラム言語各種でCeph運用・障害対応を自動化する際の注意点
Cephの運用・障害対応は、CLIやAPI、監視基盤、ログ収集の組み合わせで自動化できます。ただし自動化は、誤ると復旧成功率を下げるリスクもあるため、言語ごとの“落とし穴”を理解しておくことが重要です。共通の原則として、人間可読なCLI出力のパースに依存しすぎず、可能ならJSON等の機械可読形式を優先し、タイムアウト・リトライ・冪等性(同じ操作を繰り返しても壊れない)を設計に入れます。
言語別の注意点(表)
| 言語 | 注意点(運用でハマりやすい) | 実務的な対策の方向 |
| Bash / Shell | エラー処理・引用符・空白で壊れやすい。部分失敗の検知が弱い | set -e相当だけに頼らず、戻り値・標準エラー・JSON検証を明示。段階ログを残す |
| Python | subprocessの扱い、例外の握りつぶし、依存関係差異で事故りやすい | 構造化ログ、例外の分類、タイムアウト、再試行、環境固定(venv等) |
| Go | 並行処理で“やりすぎ”になりやすい。タイムアウト未設定で詰まる | contextでキャンセル/期限を徹底。同時実行数制限、リトライは指数バックオフ |
| Rust | FFIやライブラリ連携の難易度、学習コストが高い。実装が重くなりがち | まずはCLI+JSONで安全に自動化。必要領域だけ段階的に高信頼化 |
| Java | 長時間プロセスでGCやスレッドプール運用が効く。過剰な抽象化で調査が遅れる | メトリクス/ログの標準化、I/Oタイムアウト、スレッド上限、障害時のダンプ設計 |
| JavaScript / TypeScript(Node.js) | 非同期処理の例外伝播、メモリ上限、child_process運用で落ちやすい | Promiseの例外設計、プロセス分離、ストリーム処理、再試行とレート制限 |
| PowerShell | 文字列ではなくオブジェクト中心で、外部CLIとの境界で混乱しやすい | 外部CLI出力はJSON化して受ける。リモート実行はタイムアウトと権限を明確化 |
| C / C++ | ABI/依存関係、メモリ安全性、ビルド環境差で保守が難しい | 運用自動化の中核に据える前に、責務を限定。テストとフェイルセーフを厚くする |
| Ruby / PHP | 長時間ジョブや大量ログ処理で性能・メモリが課題になりやすい | バッチ分割、ストリーミング処理、実行時間制限、ログの構造化 |
自動化で特に重要な共通ポイント
- 冪等性:同じチェックや収集は何度実行しても安全に。危険操作は必ず人手承認の設計に寄せる
- タイムアウトと再試行:ネットワーク揺らぎや一時エラーを前提に、無限待ちを避ける
- 段階ログ:いつ、何を、どの条件で実行したかを残し、事後分析(第9章)に直結させる
- 機械可読の優先:人間向け出力のパースは壊れやすい。形式を固定し、比較可能性を上げる
- 権限と秘密情報:認証情報は平文に置かない。実行権限を最小化し、監査可能性を確保する
付録の結論:自動化は“復旧を速くする”だけでなく“復旧を安全にする”ためにある
Ceph障害対応は、速さと安全性が常にトレードオフになります。自動化は、そのトレードオフを“運用の設計”として固定し、属人性を下げるために有効です。ただし、個別のクラスター条件(構成、業務要件、停止許容、変更管理)によって最適解は変わります。自社だけで判断が難しい場合は、株式会社情報工学研究所のような専門家と一緒に、条件整理・観測設計・Runbook化まで含めて進めるのが安全です。