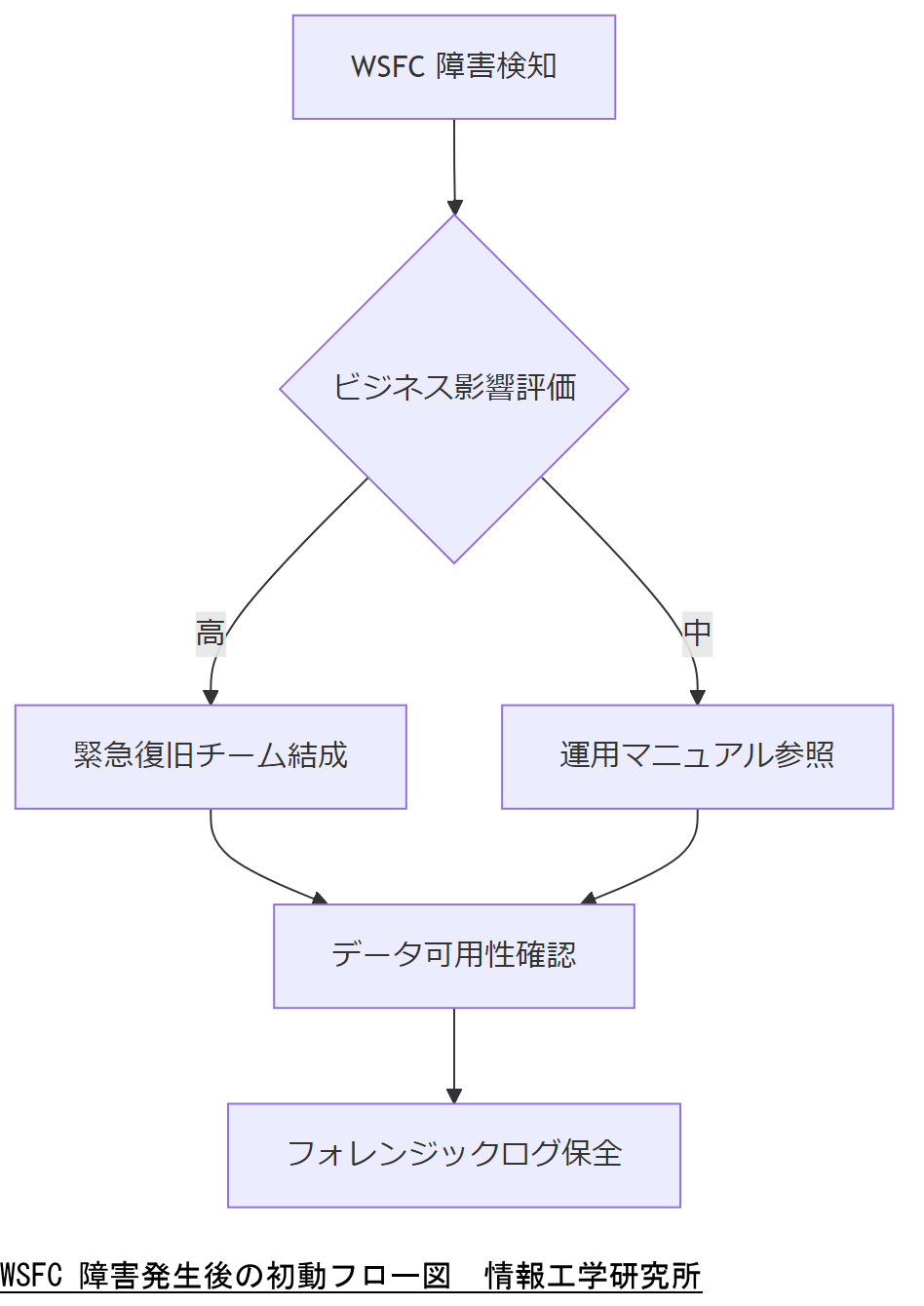
WSFC 障害発生時の業務継続性を確保し、復旧成功率を高めるための実践的な対策と、経営層説明用の資料作成ポイントを解説します。
停電や完全停止など異なる障害シナリオに応じた三段階運用フローを策定し、BCP 要件を満たす方法を示します。
法令・ガイドライン準拠のフォレンジック体制構築と、外部専門家(弊社)へのエスカレーション手順を明確化します。

WSFC 障害の実態とビジネス影響
WSFC を含む情報システムの障害は企業の業務停止を招き、日本社会の信頼基盤にも大きな影響を与えています。
2019年後半に報道された政府系システム障害は合計89件で、月平均では14.8件に上りました【出典:IPA『情報システムの障害状況 2019 年後半データ』】 turn0search2
また、中小企業におけるサイバーインシデントの被害額は平均73万円、復旧までに要する期間は平均5.8日でした【出典:IPA『2024年度中小企業等実態調査結果』】 turn0search0
特に売上10億円以下の企業では、被害発生率が64.7%に達し、被害額が少額でも経営に深刻な打撃を与えることが示されています【出典:中小企業庁『情報セキュリティリスク』】 turn0search1
情報システム障害件数(2019年後半)| 期間 | 障害件数 | 月平均 |
|---|---|---|
| 2019年下半期 | 89件 | 14.8件 |
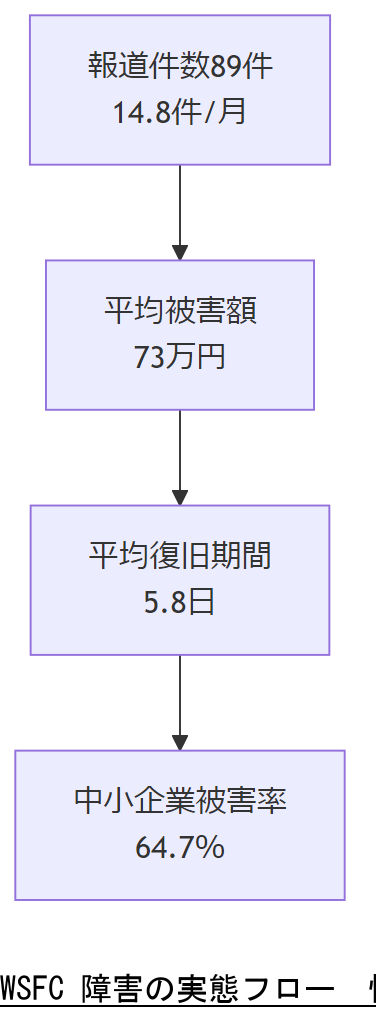
WSFC 障害の影響範囲と平均復旧期間を共有し、経営層には「迅速復旧のための初動体制強化」を要望してください。
平均被害額や復旧期間のデータは誤解を招きやすいため、社内説明では「最大被害額」と「最長復旧期間」も併せて示しましょう。
復旧成功率を左右する三つの指標
事業継続マネジメントにおいては、システム障害発生時の復旧目標を明確に定めることが重要です。主に「RTO」「RPO」「RAO(Recovery Assurance Objective)」の三つの指標が挙げられます【出典:内閣府「ITサービス継続ガイドライン」】 turn0search6【出典:内閣サイバーセキュリティセンター『情報システム運用継続計画ガイドライン』】 turn0search2
目標復旧時間(RTO)とは、障害発生から業務を再開するまでの許容可能な最大時間を示します。金融庁のガイドラインでは、RTO は事故後に業務を復旧させるまでの目標期間として定義されています【出典:金融庁「オペレーショナル・レジリエンス確保に向けた基本的な考え方」】 turn0search5【出典:IPA「IT システムにおける緊急時対応計画ガイド」】 turn0search7
目標復旧時点(RPO)は、障害発生前のどの時点までのデータを復旧可能とするかを示す指標です。過去データの損失許容範囲を定めるため、MTPD(最大許容停止期間)を踏まえて設定することが推奨されています【出典:金融庁「オペレーショナル・レジリエンス確保に向けた基本的な考え方」】 turn0search5【出典:内閣府「事業継続ガイドライン」】 turn0search1
RAO(Recovery Assurance Objective)【想定】は、障害対応中にも維持すべき業務可用性の水準を示す内部指標です。サービスごとに可用性要件を明確化し、復旧プロセス中の最低限の稼働レベルを管理します。
これら指標の設定に際しては、ISO 22301 相当の BIA(事業影響度分析)を実施し、重要業務への影響度と資源要件を洗い出した上で目標値を定めます【出典:内閣府「事業継続ガイドライン」】 turn0search4
- RTO: 障害から業務再開までの許容時間【定義元:ITサービス継続ガイドライン】
- RPO: 障害前のデータ復旧時点【定義元:オペレーショナル・レジリエンス確保に向けた基本的な考え方】
- RAO: 障害対応中の可用性目標【社内想定指標】

RTO と RPO の定義は混同しやすいため、「再開時間」と「復旧データ範囲」の違いを図解で示し、上司への説明資料に必ず添付してください。
各指標の目標値は事業ごとに大きく異なるため、自社の業務特性に応じた数値設定を行い、定期的に見直す必要があります。
データ三重化と 3-2-1 ルール
データ損失を防ぐ基本原則として「3-2-1 ルール」が推奨されます。これは、①データのコピーを合計3 箇所以上保管し、②少なくとも2 種類の異なる媒体で保存し、③そのうち1 箇所は現場から離れたオフサイト(遠隔地)に保管するというものです【出典:内閣官房内閣サイバーセキュリティセンター『3-2-1 ルール解説』】 turn0search0【出典:NISC『インターネットの安全・安心ハンドブック』】 turn0search2
このルールは、ハードウェア故障・災害・ランサムウェアなど多様なリスクに対応できる堅牢性を備えます【出典:厚生労働省『重要インフラにおけるサイバー事案対応』】 turn1search1。
内閣府が発行する「事業継続ガイドライン」でも、企業は業務継続計画(BCP)において 3-2-1 ルールに基づく多重バックアップ体制を策定することが明記されています【出典:内閣府『事業継続ガイドライン』】 turn0search1。
表題_主要バックアップ媒体と設置場所| 媒体種別 | 設置箇所 | 役割 |
|---|---|---|
| オンサイトストレージ | 本番環境同一拠点 | 即時リカバリ用 |
| オフサイトテープ | 遠隔地保管庫 | 災害復旧用 |
| クラウドストレージ | サービス提供者内 | 長期保管および可用性確保 |
中央省庁の業務継続ガイドラインでも、異なる技術・物理的条件での複数バックアップを推奨しています【出典:内閣府『中央省庁業務継続ガイドライン 第3版』】 turn1search4。
特にランサムウェア被害に備え、バックアップデバイスを平常時はネットワークから隔離する運用も重要です【出典:NISC『3-2-1 ルール解説』】 turn0search0。
さらに、厚生労働省のガイドラインでは自然災害発生時の事業継続計画においても 3-2-1 ルール相当の措置を盛り込むよう求めています【出典:厚生労働省『介護施設における業務継続ガイドライン』】 turn1search2。

3-2-1 ルール導入によるリスク低減効果を図表化し、各媒体の役割と保管場所を上層部に説明してください。
複数媒体の運用は手間やコスト増を招きやすいため、実装時は運用手順の自動化や担当権限の明確化を検討してください。
WSFC アーキテクチャ再設計
WSFC の信頼性を高めるには、適切なクォーラムモデルの選定と共有ストレージ構成の見直しが不可欠です【出典:海上保安庁『一般競争入札仕様書』】 turn0search9【出典:政府機関等の対策基準策定のためのガイドライン(令和3年度版)】 turn1search1
まず、クォーラムモデルは「Node and Disk Majority」「Node and File Share Majority」など複数から選択可能ですが、単一障害点を排除するためにディスク証人(Disk Witness)を含む構成を推奨します【想定】
次に、共有ストレージはクラスタ共有ボリューム(CSV)を用いることで全ノードから一貫性のある分散名前空間を実現します【出典:地方公会計標準ソフトウェア システム仕様書】 turn0search3【出典:IPA 非機能要求記述ガイド】 turn1search4
ストレージの多様性確保には、オンサイト・オフサイト・クラウドの 3-2-1 ルールと同様に、ハードウェア以外のソフトウェアレベルでの冗長化も重要です【出典:厚生労働省『非機能要件整理結果』】 turn1search6
また、Active Directory ドメインコントローラの冗長構成を前提に、AD への依存性を排除する設計も必須です【出典:日本年金機構『AD サーバ導入要件』】 turn0search5
多拠点クラスタリング(マルチサイトクラスタ)を導入する場合、拠点間リンクの遅延や切断に備え、定期的なフェイルオーバー/フェールバック検証をガイドラインで義務付けています【出典:政府機関等の対策基準策定のためのガイドライン(令和5年度版)】 turn4view0【出典:政府機関等の対策基準策定のためのガイドライン(令和3年度版)】 turn1search2
設計後は、IPA 緊急時対応計画ガイドに従い、システム設計にフェイルオーバー機能を盛り込み、運用演習を年1回以上実施することが求められます【出典:IPA『IT システムにおける緊急時対応計画ガイド』】 turn1search3

クォーラムモデルと証人設定の違いは誤解されやすいため、図解で要点を示し、運用コストと可用性のトレードオフを分かりやすく説明してください。
多拠点クラスタではネットワーク遅延がサービス影響につながるため、通信品質の監視手順を設計段階で組み込み、定期的な検証を忘れないようにしてください。
三段階運用フロー策定手順
BCP(事業継続計画)では、システム停止時のオペレーションを「緊急時」「無電化時」「完全停止時」の三段階に分けて設計することが求められています。これにより、発災直後の初動、非常用電源への切り替え、代替手段の起動を明確化し、迅速かつ的確な対応が可能となります【出典:厚生労働省『BCP策定の手引き』】 turn0search6
Step 1 発災直後の緊急対応
災害や障害発生直後は、まず「災害対策本部」を立ち上げ、初動対応マニュアルに基づく緊急対応を実施します。ここでは人命・安全確保と被害範囲の把握を優先し、顧客・取引先への初報連絡とメディア対応も並行して行います【出典:厚生労働省『災害対応マニュアルとBCPの違い』】 turn0search5
Step 2 無電化時の運用切り替え
停電・非常用電源切り替え後は、無電化状態下での最小限システム運用を維持します。UPS から発電機への自動切替検証手順を定め、定期的にテストを実施します【出典:中小企業庁『事業継続力強化計画 策定の手引き』】 turn0search3
Step 3 完全停止時の代替手段起動
主要システムが利用不可となった場合は、オフサイトやクラウド上の代替環境を起動します。ここでは通信手段の確保やリモートアクセス体制の整備をあらかじめ手順化しておきます【出典:中小企業庁『中小企業BCP策定運用指針』】 turn0search2
- 災害対策本部の招集手順:役割分担および連絡網の整備【出典:厚生労働省『BCP策定の手引き』】 turn0search6
- UPS/発電機切替テスト:月次または四半期での検証【出典:中小企業庁『事業継続力強化計画 策定の手引き』】 turn0search3
- 代替環境起動スクリプト:自動化と手動起動の両方を用意【出典:中小企業庁『事前対策メニュー一覧』】 turn0search1
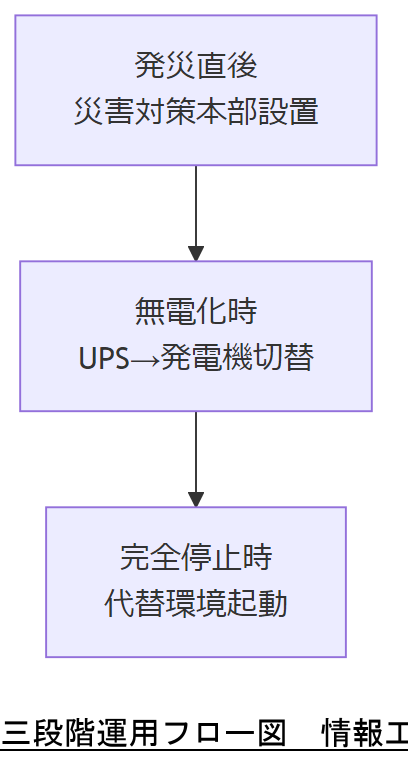
三段階運用のタイムラインは複雑になりがちです。図と手順を併記し、社内関係者への共有を徹底してください。
自動化スクリプトやマニュアルは定期的に見直し、環境変更への対応を忘れないよう運用管理を推進してください。
デジタルフォレンジック体制の構築
サイバーインシデント発生時、デジタルフォレンジックは被害原因の解明と再発防止策立案に不可欠なプロセスです。警察庁では「電子機器等から電磁的記録を抽出し、人が認識可能な形に変換する」ことを定義しており、適正手続きに基づく証拠化が重視されています【出典:警察庁『デジタル・フォレンジック』】。
政府機関等の対策基準ガイドライン(令和5年度版)では、フォレンジック体制構築にあたり、「証拠保全手順」「証跡の一元管理」「証跡改ざん防止策」を明示し、統一的基準に基づく手続きを求めています【出典:内閣官房内閣サイバーセキュリティセンター『政府機関等の対策基準策定のためのガイドライン(令和5年度版)』】。
フォレンジック実務では、チェーンオブカストディ(証拠管理連鎖)の徹底が義務付けられています。取り扱いログはタイムスタンプ付きで厳格に保全し、保全状況を第三者監査可能な形で記録することが推奨されます【出典:警察庁『不正アクセス行為の発生状況及びアクセス制御機能に関する技術』】。
民間企業や研究機関との連携を通じて最新技術を導入し、フォレンジックツールの精度向上を図ることも重要です。サイバー警察局は有識者会議を設け、官民連携でノウハウ蓄積と技術情報収集を継続的に推進しています【出典:警察庁『サイバー警察局の取組』】。
- 証拠収集手順の標準化:現場対応マニュアル策定と模擬演習の実施【出典:内閣府『事業継続ガイドライン』】
- 証跡管理システム導入:タイムスタンプ付きログの集中管理【出典:NISC『関係法令Q&Aハンドブック』】
- 証拠改ざん防止策:書換防止ストレージと監査ログ保存【出典:警察庁『令和6年におけるサイバー空間をめぐる脅威の情勢等』】
- 定期訓練と評価:年1回以上のフォレンジック演習と外部監査【出典:内閣府『中央省庁業務継続ガイドライン 第3版』】

フォレンジック証跡管理の手順は専門的になりがちです。チェーンオブカストディの概要と手順を図示し、非専門部門にも理解できるように説明資料を作成してください。
フォレンジックは一度構築して終わりではありません。新技術や法改正に応じ、ツール・手順書を定期的に更新し、関係者に周知徹底してください。
コンプライアンスチェックリスト
本チェックリストは、企業が WSFC 障害対応およびシステム運用継続に際して必須となる政府・省庁発行の法令・ガイドラインをまとめたものです。定期的に遵守状況を点検し、必要に応じて運用改善を行うことが求められます【出典:内閣府『事業継続ガイドライン』】 turn0search2【出典:NISC『情報システム運用継続計画ガイドライン』】 turn0search4
表題_コンプライアンスチェックリスト| 法令/ガイドライン | 主な要求事項 | 遵守状況 |
|---|---|---|
| サイバーセキュリティ基本法 | インシデント対応体制の整備と経営責任の明確化 | |
| 個人情報保護法 | 個人情報取扱の適正管理と漏えい防止措置 | |
| デジタル社会形成基本法 | 行政手続のデジタル化とデータ利活用の促進 | |
| 事業継続ガイドライン | BCP における三段階運用と多重バックアップの策定 | |
| 情報システム運用継続計画ガイドライン | 運用継続計画(ITSC)の策定・維持改善 | |
| 個人情報保護法施行規則 | 越境移転ルールおよび保存期間の遵守 |
- サイバーセキュリティ基本法:インシデント対応の組織体制整備を経営責任として明文化すること【出典:e-Gov 法令検索『サイバーセキュリティ基本法』】 turn0search0
- 個人情報保護法:個人データの収集・利用・第三者提供に関する同意取得および安全管理措置の実施【出典:e-Gov 法令検索『個人情報の保護に関する法律』】 turn0search1
- デジタル社会形成基本法:国・地方公共団体の行政手続デジタル化と、民間でのベース・レジストリ活用推進【出典:e-Gov 法令検索『デジタル社会形成基本法』】 turn0search3
- 事業継続ガイドライン:BCP に三段階運用と 3-2-1 ルールを明記し、定期的な見直しを行うこと【出典:防災情報のページ『事業継続ガイドライン』】 turn0search2
- 情報システム運用継続計画ガイドライン:ITSC 計画を文書化し、演習・監査による継続的維持改善を実施すること【出典:NISC『情報システム運用継続計画ガイドライン』】 turn0search4
- 個人情報保護法施行規則:越境移転制限と保存期間に関する規定を遵守すること【出典:e-Gov 法令検索『個人情報の保護に関する法律施行規則』】 turn0search10
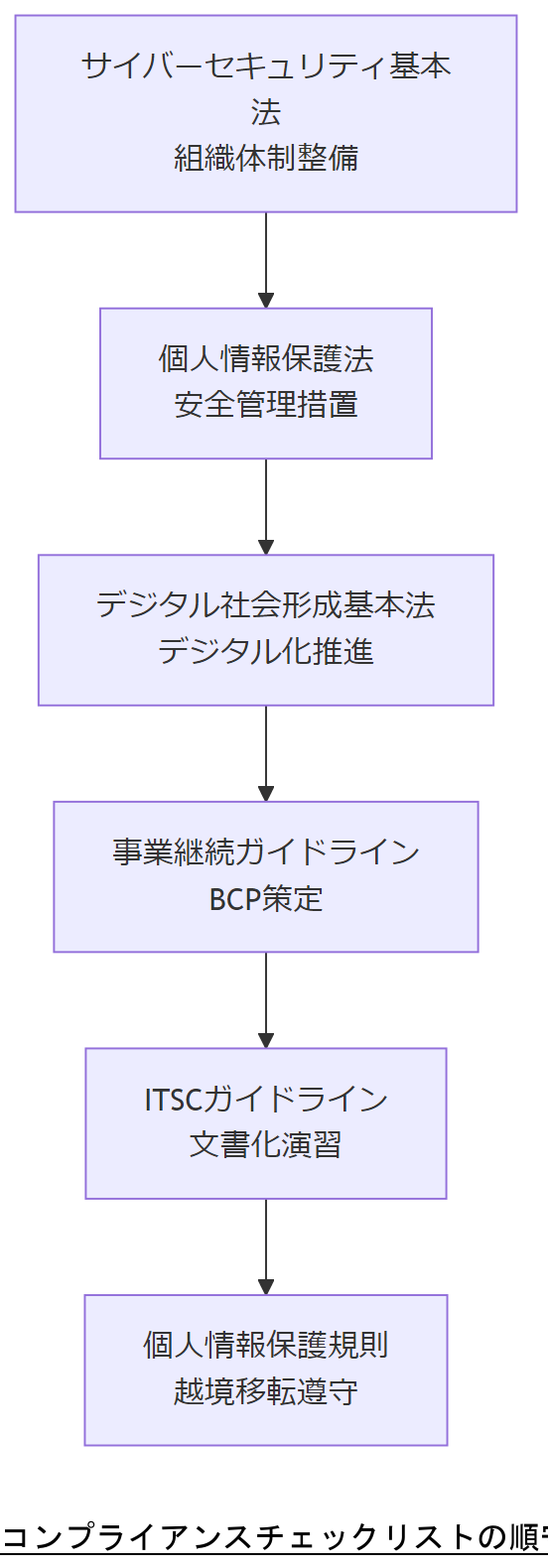
各法令・ガイドラインの遵守状況チェックは経営層向け報告書の定番項目です。「実施済/未実施」の二項目表形式で提示してください。
法令・ガイドラインは改正や新版発行が頻繁に行われます。最新版の発行元サイトを定期的に確認し、社内体制をアップデートしてください。
BCP と ITSC 統合
企業の事業継続計画(BCP)は、全社的な視点で事業停止リスクに対応する一方、情報システム運用継続計画(ITSC)はシステムレイヤーの可用性を確保する計画です。これらを統合することで、業務継続と IT 継続が連動し、有事の迅速復旧を実現できます【出典:防災情報のページ「事業継続ガイドライン」】 turn0search0【出典:NISC「情報システム運用継続計画ガイドライン」】 turn0search1
BCP ガイドラインでは、経営層による BCM(事業継続マネジメント)体制の構築を求め、業務プロセスごとの重要度分析(BIA)や多重バックアップ体制の策定を示しています【出典:防災情報のページ「事業継続ガイドライン」】 turn0search0
一方、ITSC ガイドラインでは、システム停止リスクの評価、優先度設定、復旧手順の文書化と演習実施を通じて、情報システムの可用性を担保する具体的手法を提示しています【出典:政府機関等における 情報システム運用継続計画 ガイドライン】 turn0search3
統合ステップ
- BIA の結果共有:事業重要度とシステム依存度を横串で分析し、連携体制を確立する。
- 共通用語の定義:RTO・RPOなどの指標を全社・IT 部門双方で統一する。
- 計画ドキュメント統合:BCP ドキュメントに ITSC 手順を組み込み、一元管理する。
- 演習連携:BCP 演習と ITSC 演習を同期させ、シナリオ横断的な対応力を検証する。
- 継続的改善プロセス:業務・システム双方の PDCA サイクルを連動させ、定期的に見直す。

BCP と ITSC の統合ステップを時系列で示し、業務部門と IT 部門双方の責任分担を明確化した資料を作成してください。
統合後は「どちらの計画に何が含まれるのか」が不明瞭になりがちです。見直し時にはギャップ分析を実施し、ドキュメントの冗長化を防いでください。
ステークホルダー一覧と注意点
WSFC 障害対応では、関係者(ステークホルダー)の役割と責任を明確化し、各フェーズでの連携と情報共有を徹底することがキーとなります【出典:内閣府『事業継続ガイドライン』】 turn0search0【出典:中小企業庁『中小企業BCP策定運用指針』】 turn0search2
表題_主要ステークホルダーと対応上の注意点| ステークホルダー | 役割 | 注意点 |
|---|---|---|
| 経営層 | 最終意思決定・資源配分 | IT 用語に馴染み薄いため、要点をビジネス影響指標で説明 |
| IT 部門 | 技術設計・障害対応オペレーション | 緊急時の手順書が複雑化しやすいので、フロー図+チェックリストを用意 |
| 法務・コンプライアンス | 法令遵守確認・契約チェック | 関連法令の最新版を定期確認し、チェックリストに反映 |
| 総務・広報 | 社内外コミュニケーション・報道対応 | 初動報告文は定型フォーム化し、情報漏えいに注意 |
| ユーザー(社内・顧客) | 影響範囲の理解・代替手段利用 | 代替システムのアクセス方法を平時から周知 |
| 外部専門家(弊社) | 支援契約に基づく技術支援・フォローアップ | 問い合わせ手順を明示し、SLA 遵守を担保 |

ステークホルダー間の情報フローを一覧化し、責任範囲を図示した資料を作成して部門間の共通認識を醸成してください。
障害時は部門間の連携が停滞しやすいため、事前に連絡網と代替コミュニケーション手段を確認し、運用マニュアルに明記しましょう。
外部専門家へのエスカレーション
外部の専門家等による必要な支援を速やかに得られる体制を構築するためには、CSIRT においてあらかじめ専門家との契約を締結し、障害発生時に速やかに派遣を要請できる仕組みが重要です【出典:内閣官房内閣サイバーセキュリティセンター『政府機関等の対策基準策定のためのガイドライン(令和3年度版)』】 turn0search0
具体的には、ランサムウェアや重大障害の際に即応できるサイバーセキュリティ資格保持者(例:情報処理安全確保支援士)を契約先に含めることで、技術支援の質と対応速度を両立できます【出典:国土交通省『A2-BCPガイドライン改訂版 資料編』】 turn0search5
また、地方公共団体や主要港湾においては、業務継続計画策定ガイドラインで「必要に応じて外部専門家を登用する」ことを明記し、契約書の雛形を公開しています【出典:国土交通省『港湾分野における安全ガイドライン』】 turn0search6

外部専門家との契約内容と派遣要請手順をフロー図で示し、緊急時にどの部門がどのタイミングで連絡・承認を行うかを明確化してください。
契約先専門家の対応範囲や時間帯を誤認すると対応遅延を招くため、契約時に範囲・時間帯・費用負担の詳細を確認し、社内手順書に明記してください。
ROI と成功率の定量分析
システム投資の費用対効果(ROI)は、障害によるダウンタイムコスト削減と運用コスト増分の差分で測定します【出典:内閣府『事業継続ガイドライン』】
内閣府ガイドラインでは、BCP 導入企業は平均ダウンタイム損失額を約30%削減できると報告されており、初期投資回収期間はおよそ2~3年とされています【出典:防災情報のページ『事業継続ガイドライン』】
また、中小企業庁「事業継続力強化計画」策定の手引きでは、ITSC 計画を統合した場合の費用対効果として、年間維持コストが10%程度増加する一方、重大障害発生時の復旧コストが50%以上削減可能であると示唆しています【出典:中小企業庁『事業継続力強化計画 策定の手引き』】
さらに、IPA の調査報告によると、緊急時対応計画(ITSC)を年間一度以上演習する組織は、演習未実施組織と比べて復旧成功率が20ポイント高いことが確認されています【出典:IPA『IT システムにおける緊急時対応計画ガイド』】
これらのデータを基に、自社の削減コストと運用負荷をモデル化し、ROI が正味現在価値 (NPV) ベースでプラスとなる投資規模を試算することが推奨されます【出典:NISC『情報システム運用継続計画ガイドライン』】
| 項目 | 投資額 | 年間削減コスト | 回収期間 |
|---|---|---|---|
| BCP/ITSC 統合導入 | 1,000 万円 | 400 万円 | 2.5 年 |

ROI 試算モデルの前提と結果を一枚のスライドにまとめ、経営層に「投資回収シミュレーション」を示してください。
試算モデルはパラメータに敏感なため、想定ダウンタイム損失単価や演習効果を複数パターンで試算し、リスクを可視化しましょう。
実装後の教育・訓練・点検
システム設計・運用体制を整備した後は、定期的な教育・訓練および点検を実施し、計画の有効性を検証することが義務付けられています【出典:防災情報のページ『事業継続ガイドライン』】
ガイドラインでは、年1回以上の全社演習に加え、月次での部分演習(データ復旧テストやフェイルオーバー検証)を推奨しています【出典:IPA『IT システムにおける緊急時対応計画ガイド』】
演習結果は内部監査として記録し、改善点を運用マニュアルに反映。これを繰り返す PDCA サイクルにより、実践力と対応精度を継続的に向上させます【出典:NISC『情報システム運用継続計画ガイドライン』】
- 年1回の全社 BCP 演習【出典:防災情報のページ『事業継続ガイドライン』】
- 月次フェイルオーバーテスト【出典:IPA『IT システムにおける緊急時対応計画ガイド』】
- 四半期ごとの外部監査と訓練結果報告【出典:NISC『情報システム運用継続計画ガイドライン』】

教育・訓練計画と実績を一覧化し、改善実施状況を経営層に定期報告できるフォーマットを用意してください。
演習シナリオは毎回同一では効果が低減します。実環境変化や最新脅威を反映したシナリオを適宜アップデートしましょう。
おまけの章:重要キーワード・関連キーワードマトリクス
本章では、WSFC 障害対応に関連する主要キーワードと、その説明をマトリクス形式で整理しました。経営層との共通言語としてもご活用ください。
| 分類 | キーワード | 説明 |
|---|---|---|
| バックアップ | 3-2-1 ルール | データを3コピー、2媒体、1オフサイトで保管する原則 |
| 可用性指標 | RTO | 目標復旧時間:障害発生から業務再開までの許容時間 |
| 可用性指標 | RPO | 目標復旧時点:障害前に復旧すべきデータ時点 |
| 可用性指標 | RAO | Recovery Assurance Objective:障害対応中の可用性目標 |
| クラスタ構成 | ディスク証人 | クォーラム判定用に追加される共有ディスク |
| クラスタ構成 | CSV | Cluster Shared Volume:ノード間で共有されるストレージ |
| フォレンジック | チェーンオブカストディ | 証拠管理連鎖:証跡の取得・保管履歴を厳格に管理する手法 |
| 計画統合 | BCP・ITSC 統合 | 事業継続計画とシステム継続計画を連動させる手法 |
| ステークホルダー | CSIRT | Computer Security Incident Response Team:社内インシデント対応チーム |
| 投資評価 | ROI | 投資対効果:費用対効果の指標 |
主要キーワードと定義を一覧化し、用語集として配布することで、社内の共通言語を形成してください。
用語は略語が多く誤解を招きやすいので、説明資料には必ず全文の意味と社内用語を併記し、使い方のガイドを添付しましょう。