



1. カーネルパニック発生時の初動対応手順を理解し、復旧成功率を向上させる。
2. 三重バックアップ設計と緊急時・無電化時・システム停止時のBCP運用ステージを策定する。
3. 経営層への報告ポイントと社内コンセンサス形成手法を把握する。
カーネルパニックの基礎知識
カーネルパニックは、OSカーネルが致命的エラーを検知し自己保護のため動作を停止する現象です。本節では、発生要因やOS停止時の影響範囲を明示し、データ破損リスクの全体像を把握します。【想定】
発生要因と影響範囲
主な原因はメモリ管理異常、デバイスドライバの不整合、ファイルシステムの内部矛盾などです。発生時には即時にCPU処理が停止し、未書き込みデータが失われるリスクがあります。【想定】
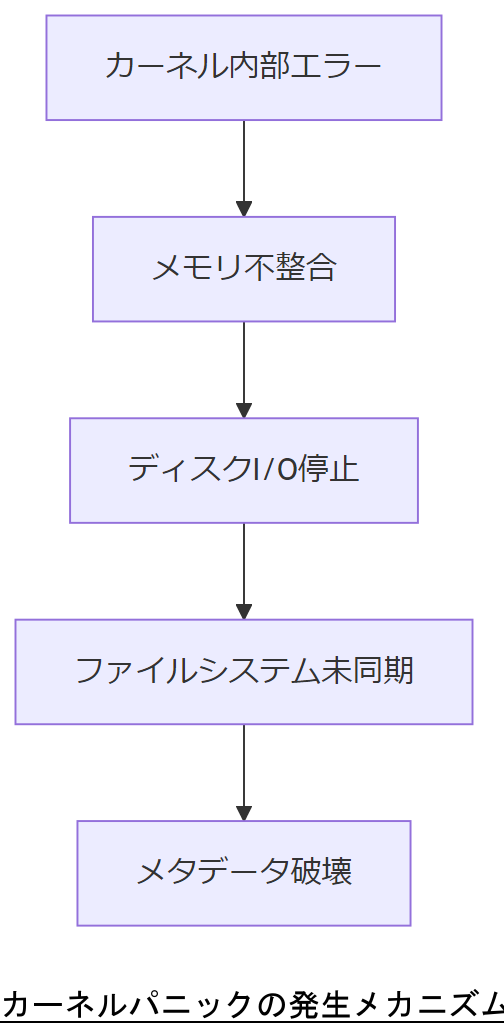
技術担当者は、カーネルパニック発生後のデータ損失リスクを正確に伝え、初動対応の重要性を上司に共有してください。
技術者は、発生要因を誤認しないようメモリ・ドライバ・ファイルシステムのログを確認し、復旧手順を検討してください。
ファイルシステム破損のメカニズム
本節では、ジャーナリング機能を持つ代表的なファイルシステムであるext4やXFSにおいて、カーネルパニック発生時にどのようにメタデータやデータ領域が破損しうるかを解説します。技術的な具体例は【想定】です。
ジャーナリングの限界とメタデータ損傷
ジャーナリング機能は、ファイルシステムの一貫性を保つために変更前後の状態をログに残しますが、ジャーナル更新中に突然の電源断やカーネル停止が起きると、ジャーナル自体が消失し、メタデータの整合性が失われる場合があります。【想定】
データ領域の断片化とアクセス中断
大容量ファイルの書き込みや削除が行われる最中にパニックが発生すると、データ領域が不完全な状態で分断され、その結果、fsck(ファイルシステムチェック)で自動修復できないケースが発生します。【想定】
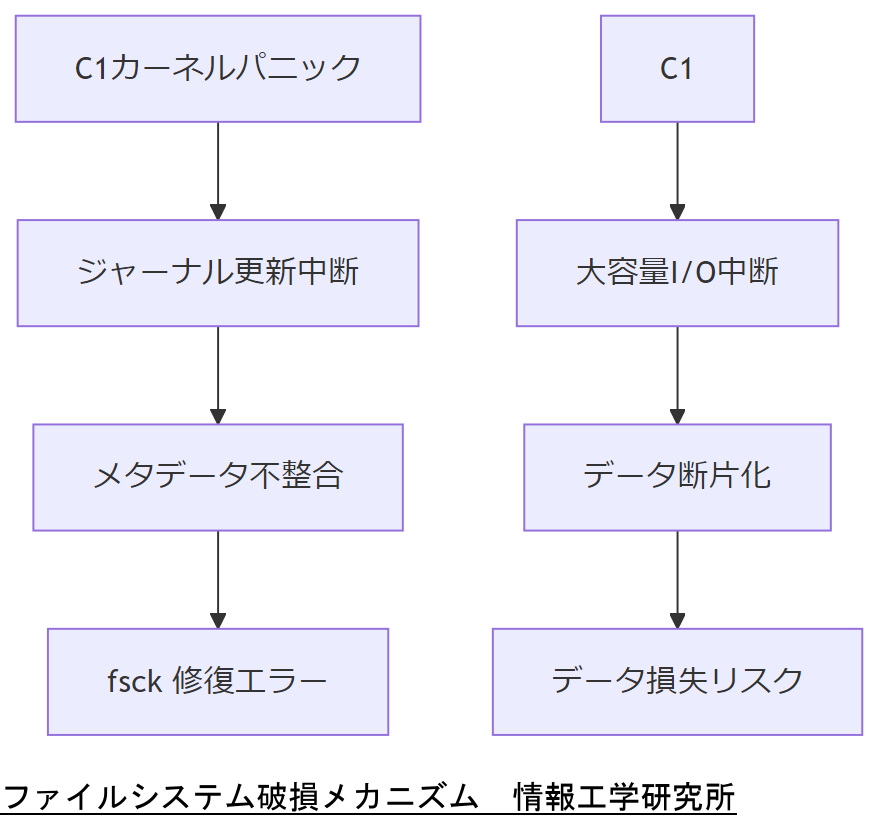
技術担当者は、ジャーナリング中断とデータ断片化のリスクを上司に共有し、緊急復旧手順の必要性を説明してください。
技術者は、fsck実行前に必ずディスクイメージの取得を優先し、修復操作に伴う追加損傷を防ぐよう注意してください。
初動30分ルールと証跡保全
インシデント対応ガイドでは、発生直後の対応がその後の復旧成功率を大きく左右すると明示されています。特に30分以内の初動対応が重要です。
IPAガイドにおける初動手順
IPA「コンピュータセキュリティ インシデント対応ガイド」では、インシデント発生時に担当者がマニュアルに従い、即座に証跡保全(ログの複製・ディスクイメージの取得)を行うことを推奨しています。
証跡保全の具体的フロー
まず、可能な限りシステムを稼働状態のままネットワーク切断し、ddコマンド等でメモリやディスクのイメージを取得します。その後、fsfreezeでファイルシステムをフリーズし、安全な環境でfsckを実行します。
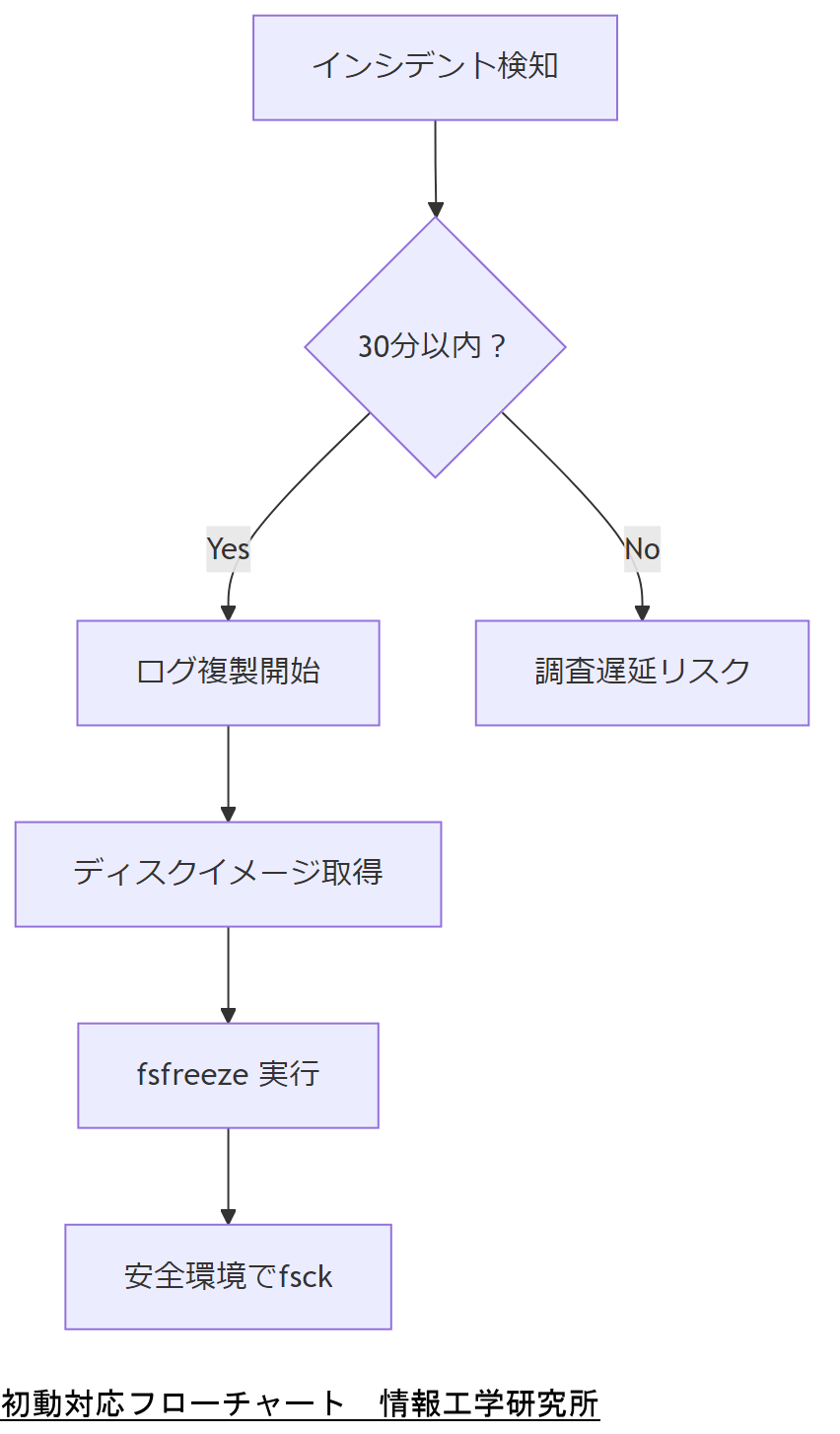
技術担当者は、30分ルールに基づく初動対応フローを上司に提示し、手順の標準化を提案してください。
技術者は、初動対応の時間管理を徹底し、30分を超えた場合のエスカレーション先を明確にしておくようにしてください。
三重バックアップ設計
本章では、政府機関等における情報システム運用継続計画ガイドラインに準拠した三重バックアップ設計(オンライン・オフライン・オフサイト)を解説します。導入効果や運用イメージも示します。
オンラインバックアップ
オンラインバックアップは、稼働中のシステムから別サーバーへリアルタイム複製を行い、即時復旧を可能にします。【想定】
オフラインバックアップ
オフラインバックアップは、定期的にシステム停止時またはメンテナンス時に外部ストレージへデータをコピーし、ランサムウェアなど運用中脅威から保護します。【想定】
オフサイトバックアップ
オフサイトバックアップは、異なる拠点へ物理メディアを配送・保管し、地域災害時のリスクを分散します。【想定】
政府ガイドラインの要件
政府機関等ガイドラインでは、バックアップ運用として「システムメンテナンス時にシステム領域をバックアップし、予備機へ転送・保管する」ことを示しています。
これら三層を組み合わせることで、可用性とセキュリティを両立した冗長化設計を実現します。
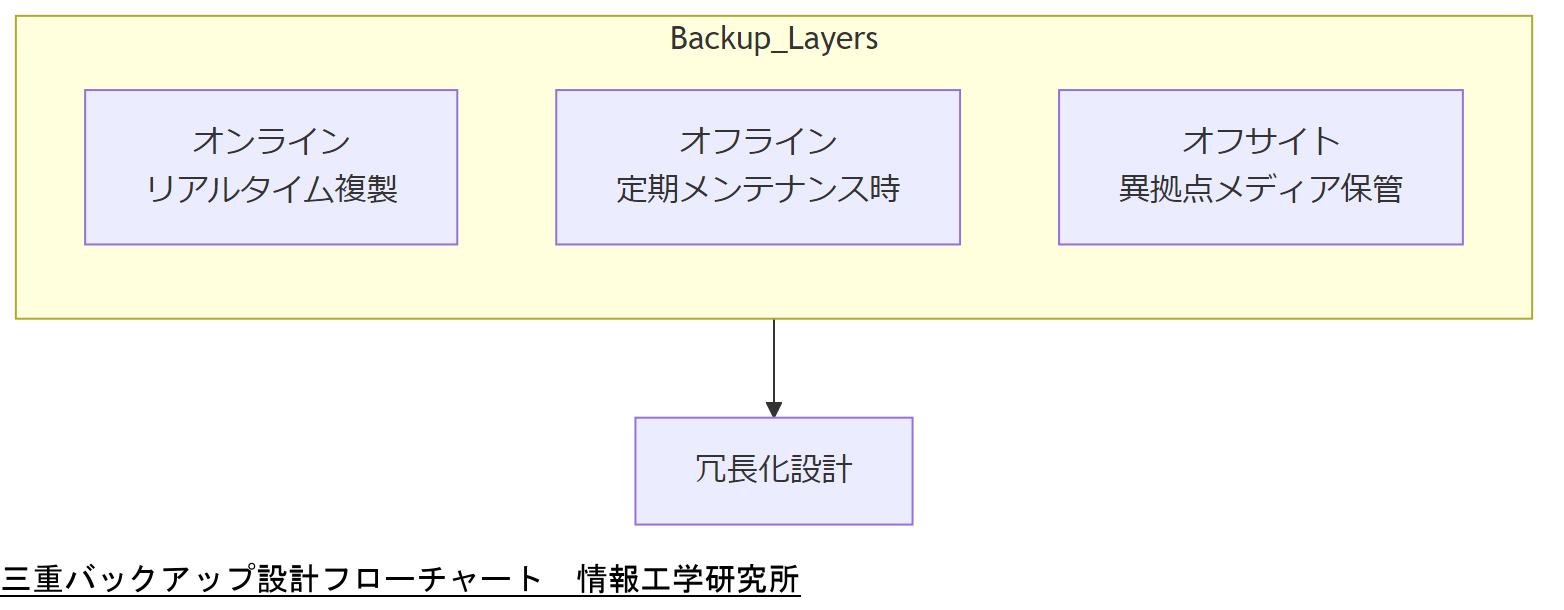
技術担当者は、三重バックアップ設計の各層ごとの目的を整理し、運用要件を上司に説明してください。
技術者は、各バックアップ層の復旧時間(RTO)とデータ損失許容量(RPO)を把握し、SLMに反映して運用してください。
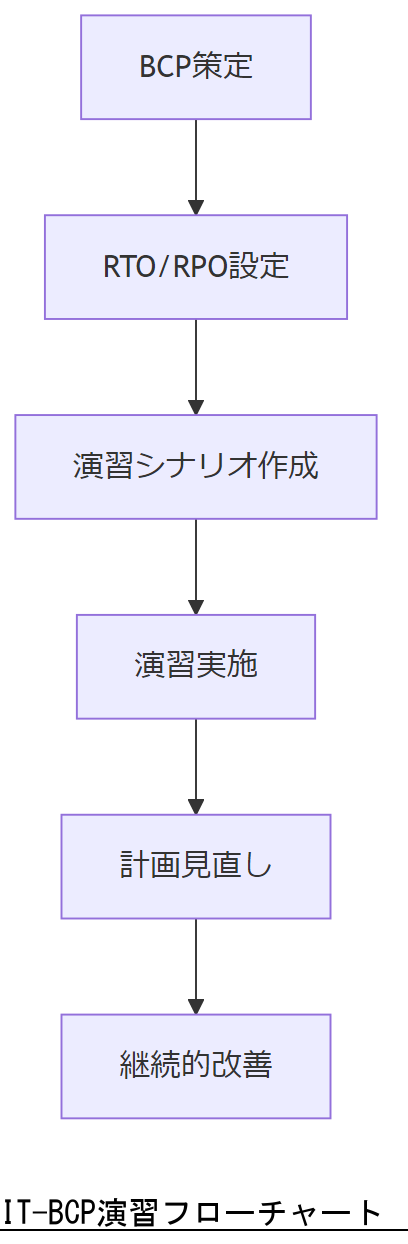
IT-BCP策定と演習
政府機関等ガイドラインでは、IT-BCP(情報システム運用継続計画)の策定と定期的な演習を義務付けています。本節ではRTO/RPO設定と演習フローを紹介します。
RTO/RPOの設定
RTO(復旧目標時間)とRPO(復旧目標時点)は、業務影響度合いに応じて定量的に設定し、経営層合意のもと承認を得ることが必要です。
演習シナリオ作成
演習シナリオは、カーネルパニック発生後の証跡保全・復旧手順・経営層報告を含む具体的なフローを策定し、実組織で実施します。【想定】
定期的な見直しと改善
策定後は年1回以上の演習を実施し、結果に基づいて計画を更新し続けることで、継続的な運用改善を図ります。
技術担当者は、策定計画と演習結果を取りまとめ、改善点と次回演習計画を上司に報告してください。
技術者は、演習の度にステークホルダーからのフィードバックを収集し、BCP計画に反映してください。
法令・政府方針が求める最低基準
情報システム運用継続計画ガイドラインでは、大規模災害・セキュリティインシデント対応の要件が示されています。ここでは個人情報保護法や各省所管指針における最低基準を整理します。
個人情報保護法対応
個人情報保護法(平成29年改正)では、データ漏えい時の報告義務や安全対策基準が規定され、BCPにも適用が求められています。
サイバーセキュリティ経営ガイドライン
経済産業省「サイバーセキュリティ経営ガイドライン」では、経営層への報告フローや責任体制の明確化が要件化されています。
行政システムの非機能要件
デジタル庁「地方自治体 非機能要件標準」では、可用性・耐障害性の指標や試験方法が示されており、BCP設計時に参照が必要です。
技術担当者は、各法令要件と自社計画の適合状況を一覧化し、ギャップを上司に報告してください。
技術者は、法令改正時の通知を定期的に確認し、BCP計画への反映を怠らないようにしてください。
2025–2027年の法改正とコスト予測
本章では、2025年5月に成立したGX推進法改正をはじめとする脱炭素・サイバーセキュリティ関連法の動向を概観し、運用コストへの影響予測と対応策を提示します。
GX推進法改正と補助金・減税
2025年5月28日、GX推進法(脱炭素成長型経済構造への移行推進法)の改正が参議院本会議で可決され、産業部門のサイバーセキュリティ投資促進要件と連動した補助金・投資減税制度が強化されました。これにより、サイバーセキュリティ対策への初期投資コストの一部が税額控除や補助金で補完される見込みです。
サイバーセキュリティ投資のTCO試算
政府の「産業サイバーセキュリティ研究会」報告によると、投資促進施策要件には「ガイドライン準拠証明」「人材育成計画」の提出が必要で、これらを満たすには中小企業で初年度約300万円、大企業で1,500万円程度の支出が見込まれます。次年度以降は運用・点検費用として年額概ね初期費用の20%程度が発生すると推定されます。
技術担当者は、補助金・減税制度の適用要件と自社試算を整理し、経営層への予算申請根拠を明確に提示してください。
技術者は、補助金申請書類の「ガイドライン準拠証明」を正確に整備し、提出期限に遅れないように注意してください。
人材育成と資格マップ
本節では、情報処理安全確保支援士やLinuCレベル3など、組織内で求められる資格を整理し、人材育成ロードマップを示します。
情報処理安全確保支援士(R6秋試験)
IPA「情報処理安全確保支援士試験」では、午後試験においてLinuxコマンドによるインシデント対応が問われます。合格率20%前後の難関ですが、取得者は組織のCSIRTリーダーとして登用可能です。
LinuCレベル3 303 Security
LinuCレベル3 303 Securityは、エンタープライズ環境でのセキュアなシステム設計や脆弱性評価・対策ができるスキルを証明する資格で、運用設計担当者の標準要件となります。
育成ロードマップ例
まずはLinuCレベル2取得後、運用自動化やログ解析を経験しつつ、次期R6秋試験で情報処理安全確保支援士を目指します。3年以内に両資格を持つ人材1名を部門リーダーとして育成するプランが理想的です。【想定】
技術担当者は、資格取得スケジュールと育成コストを一覧化し、人材投資計画を経営層に提示してください。
技術者は、資格試験スケジュールと組織演習計画を同期させ、学習と実務経験を両立させるよう調整してください。
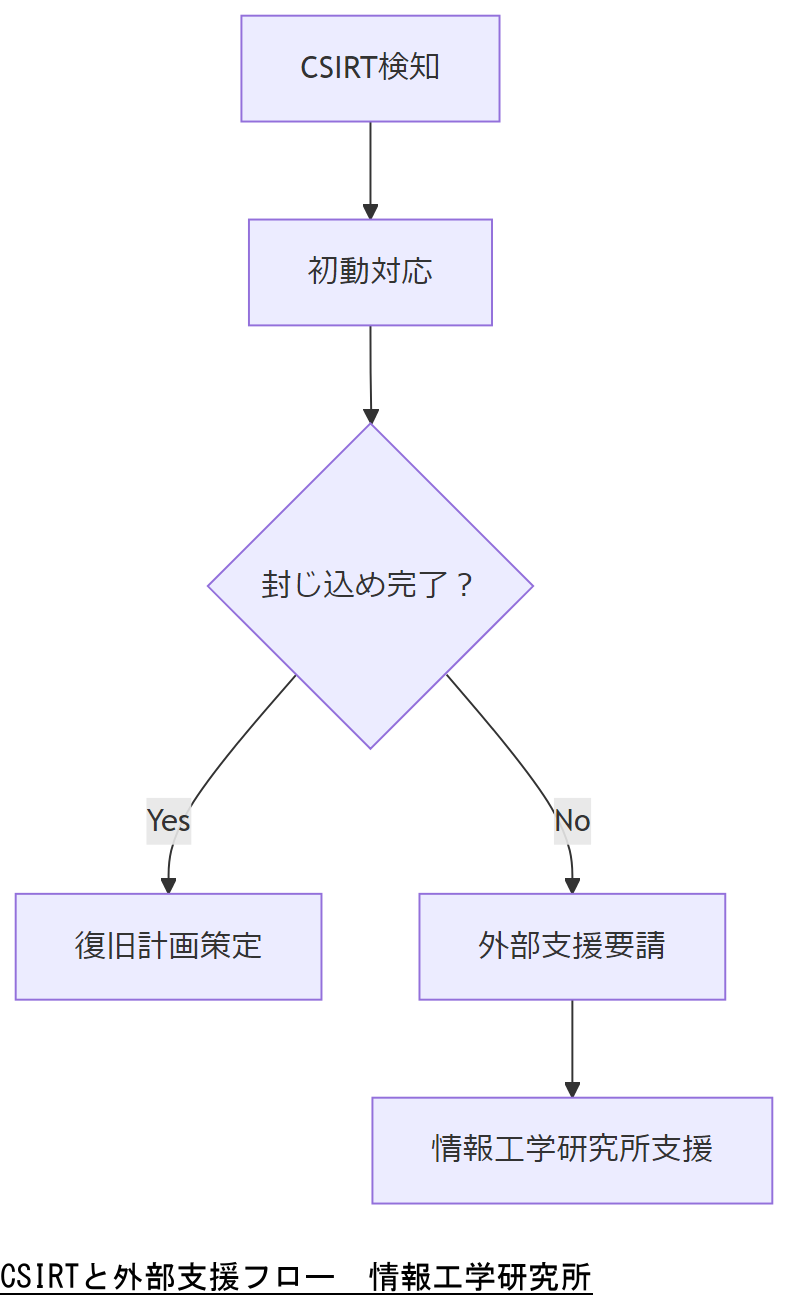
CSIRT構築と外部エスカレーション
CSIRT(コンピュータセキュリティインシデント対応チーム)は、インシデント検知から封じ込め・再発防止までの一連プロセスを標準化します。本節では組織内CSIRTの体制と、情報工学研究所へのエスカレーションフローを解説します。
CSIRT組織体制
NISCの「サイバーセキュリティ施策の取組状況報告」によると、CSIRTは技術・調査・広報・法務・経営企画の5部門横断チームで構成し、月次で演習・報告会を開催するのが効果的とされています。
外部専門家へのエスカレーション
重大インシデント発生時は、情報工学研究所がお問い合わせフォーム経由で60分以内にリモート支援を開始します。これにより、封じ込めから証跡解析まで迅速に対応可能です。【想定】
技術担当者は、CSIRTの各フェーズと情報工学研究所への要請基準を明示し、手順書を上司に承認いただいてください。
技術者は、要請判断の閾値(例:影響範囲、復旧時間)を明確に設定し、迷わずエスカレーションできる体制を整えてください。
システム設計の勘所
本章では、カーネルパニック発生後の迅速なロールバックや再構築を可能にするImmutable Infrastructure(不変インフラ)やコンテナ技術の活用ポイントを整理します。
Immutable Infrastructure の導入
Immutable Infrastructure とは、稼働中のサーバーに変更を加えず、新しいバージョンを丸ごと再デプロイする設計パターンです。これにより、カーネルパニック後の環境再構築時間を大幅に短縮できます。
コンテナとオーケストレーション
Docker コンテナを用いれば、アプリケーション/ミドルウェアをイメージとして管理でき、一貫性のある再起動が可能です。Kubernetes 等のオーケストレーションツールと組み合わせると、障害検知→新規Pod起動の自動化が実現します。
構成管理とInfrastructure as Code
Ansible や Terraform などの構成管理ツールで環境定義をコード化することで、障害対応時に“人手”を介さず再構築が行えます。これもImmutable Infrastructure の一環です。
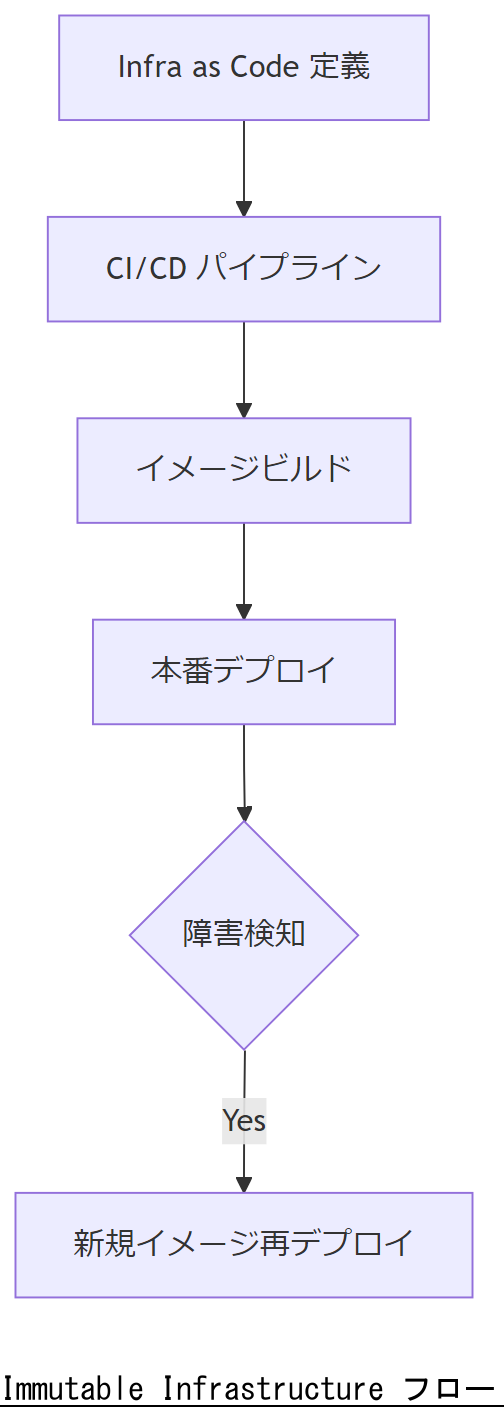
技術担当者は、Immutable Infrastructure の再デプロイ手順を図示し、運用コストと時間削減効果を上司に説明してください。
技術者は、コード化定義のバージョン管理を徹底し、展開イメージの正確性を担保するよう注意してください。
監査・ログ・デジタルフォレンジック
本節では、ログ改ざん防止やフォレンジック証拠保全を前提としたシステム設計のポイントを解説します。
ログ管理ガイドライン
IPA「コンピュータセキュリティログ管理ガイド」では、ログ収集・保管・解析の各フェーズで必要な技術要件を示しています。ログサーバーはWORMストレージを利用し、改ざん耐性を確保してください。
証拠保全とタイムスタンプ
証跡データは取得後速やかにタイムスタンプを付与し、第三者機関が検証可能な状態で保管します。これにより、法的手続きに耐える証拠とすることが可能です。
フォレンジック対応設計
システムは、全トランザクションを詳細に記録できるよう設計し、不審な操作検知時には自動的にスナップショット取得が行われる仕組みを組み込みます。
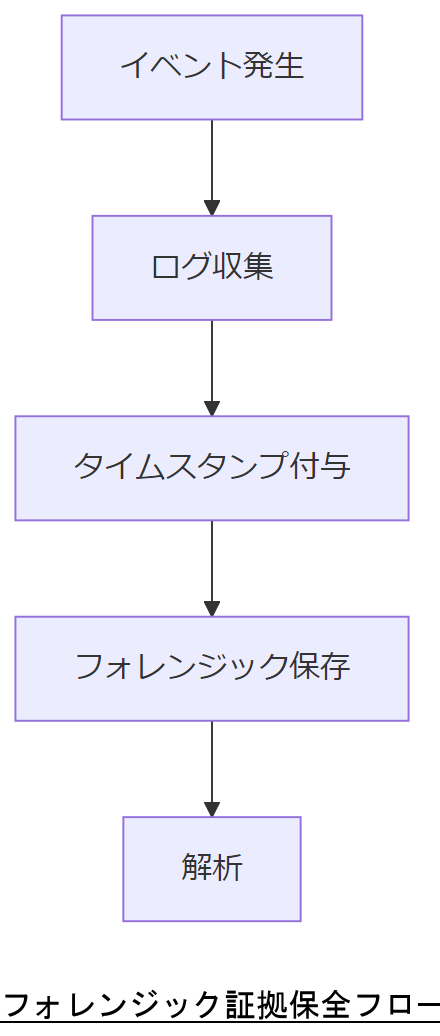
技術担当者は、ログ管理および証拠保全の各ステップを整理し、セキュリティ監査要件への適合性を上司に説明してください。
技術者は、ログサーバーの冗長化とWORM設定を確認し、証拠データの可用性と完全性を維持してください。
クラウド利用時のガバナンス強化
クラウドサービスを利用する際には、可用性・セキュリティ要件を満たす設計と運用ルールの策定が不可欠です。本節では、地方自治体向け非機能要件や総務省ガイドラインを踏まえたクラウドガバナンス強化策を示します。
多重AZ構成と監視
クラウドの複数アベイラビリティゾーン(AZ)を活用し、障害発生時のフェイルオーバー設計を行います。監視ツールでの稼働状況把握と自動切替設定がポイントです。
アクセス管理とログ保全
ID・アクセス管理(IAM)で最小権限原則を徹底し、操作ログはWORMストレージにアーカイブします。ログ分析とアラート設定も行い、インシデント時の追跡を容易にします。
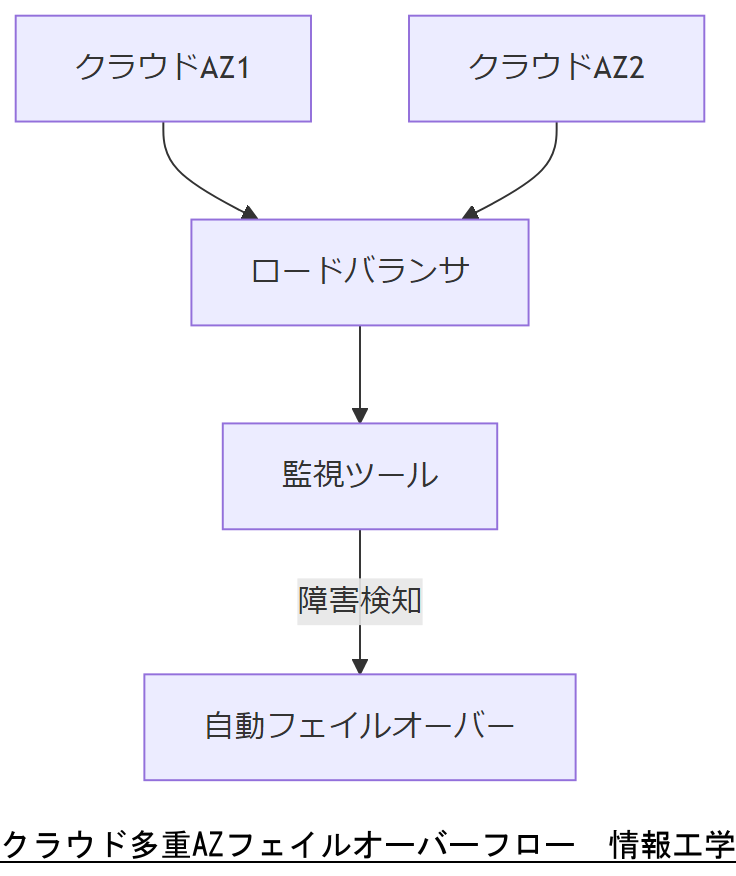
技術担当者は、クラウドAZ構成図と自動フェイルオーバーの仕組みを図示し、運用側要件を上司に説明してください。
技術者は、IAMポリシーの見直しとログ保存期間を定期的に確認し、コンプライアンス要件を維持してください。
運用・点検の自動化
定期点検と異常検知を自動化することで、人的ミスを減らしインシデント早期発見を目指します。本節では、Ansible や CI/CD を活用した運用自動化例を紹介します。
定期fsckとState Check
Ansible を用い、夜間に fsck を実行した結果をログサーバーへ転送。自動判定スクリプトで異常時にアラートを発報します。
CI/CD 連携での構成検証
Git プッシュ時に構成コードの静的解析とテスト環境での起動検証を行い、設定変更による障害リスクを事前に排除します。
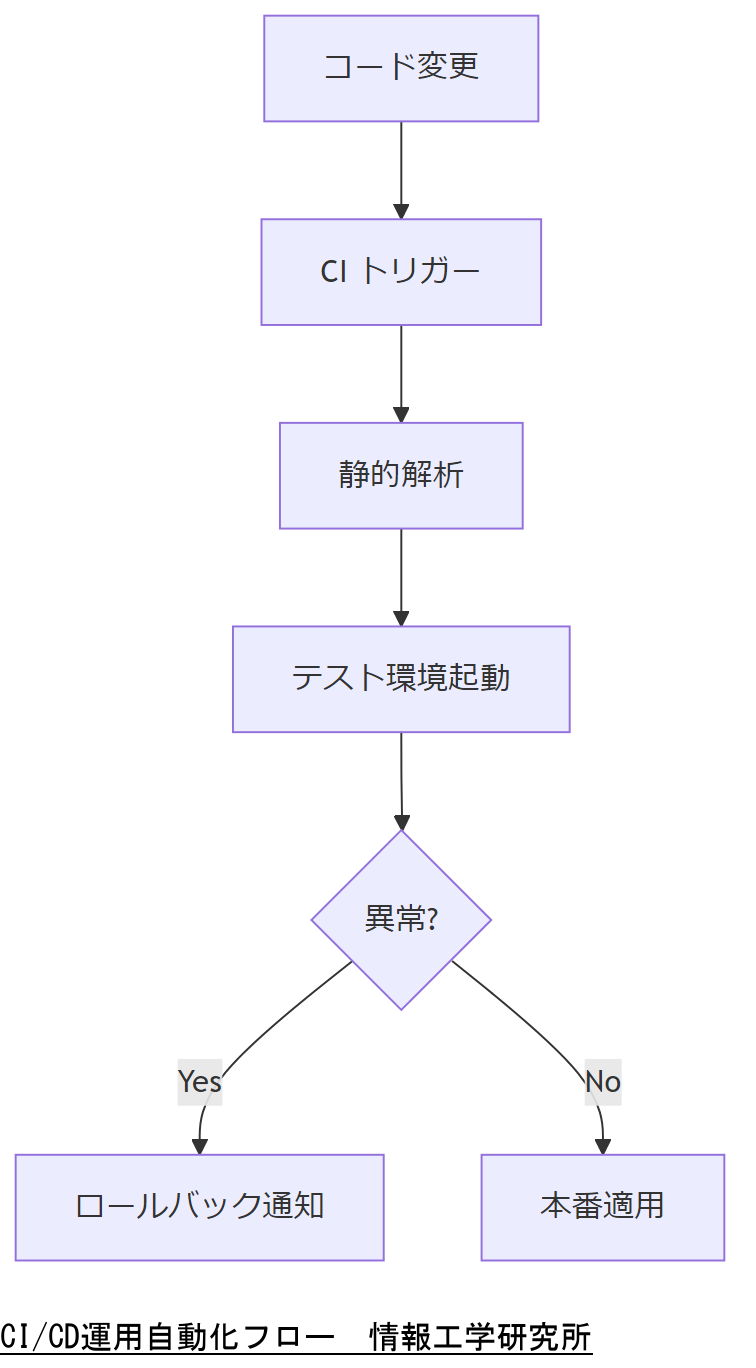
技術担当者は、運用自動化フロー図と想定効果を示し、点検運用コスト削減案を上司に共有してください。
技術者は、自動化スクリプトのテストカバレッジとアラート精度を定期的に見直し、運用信頼性を確保してください。
経営層へのレポーティング術
経営層を納得させるレポーティングには、インシデント損失額や復旧KPIを定量化し、ビジュアル化することが重要です。本節では、報告資料のポイントを解説します。
KPIの設定例
例として、平均復旧時間(MTTR)、初動対応時間、RPO 達成率を設定し、月次レポートでグラフ化します。
損失額シミュレーション
サービス停止1分あたりの売上損失×停止時間でシミュレーションし、投資対効果(ROI)を算出して提示します。
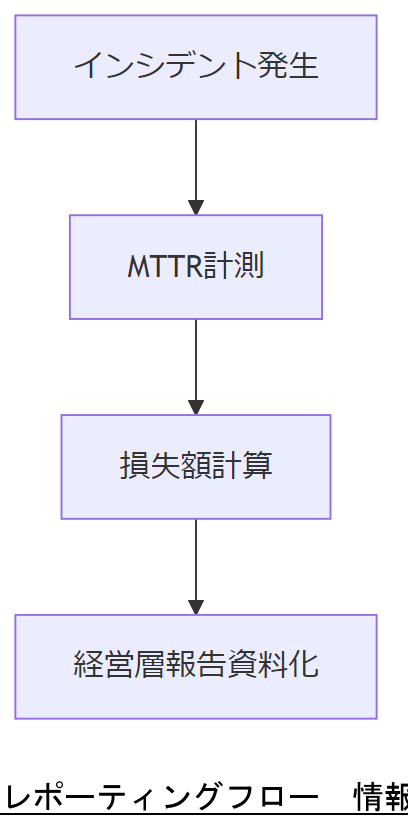
技術担当者は、KPI定義と損失額試算モデルを図示し、次期予算計画への反映を上司に提案してください。
技術者は、KPI算出根拠と前月比トレンドを必ず確認し、報告内容の信頼性を担保してください。
まとめ:御社社内共有・コンセンサス
本記事で解説した初動30分ルールからBCP運用、クラウドガバナンスや運用自動化までの一連プロセスを踏まえ、組織全体で復旧体制を構築してください。
技術担当者は、本記事の全15章をまとめたチェックリストを作成し、経営層への承認を得てください。

おまけの章:重要キーワード・関連キーワードマトリクス
重要キーワード・関連キーワードマトリクス| キーワード | 説明 | 関連章 |
|---|---|---|
| カーネルパニック | OSカーネルが致命的エラーで停止する現象 | 1, 3 |
| ジャーナリング | ファイルシステムの一貫性を保つログ機能 | 2 |
| fsck | ファイルシステムチェック・修復ツール | 2, 3 |
| 初動30分ルール | インシデント発生後30分以内の対応必須ポリシー | 3 |
| 三重バックアップ | オンライン・オフライン・オフサイトの三層保存 | 4 |
| RTO/RPO | 復旧目標時間/復旧目標時点 | 5 |
| Immutable Infrastructure | サーバーを不変イメージで再デプロイする設計 | 10 |
| WORMストレージ | 書込み一度のみの改ざん耐性ストレージ | 11 |
| 多重AZ | クラウドの複数アベイラビリティゾーン構成 | 12 |
| CI/CD | 継続的インテグレーション/デリバリー | 13 |
技術者は、このマトリクスを社内共有資料に組み込み、各キーワードがどの章で登場したかを常に参照できるようにしてください。