- ext4 ジャーナル解析を通じて削除ファイルを確実に再構成し、システム障害によるデータ損失の影響を最小化します。
- 政府ガイドラインに適合した3重化保存設計および運用体制の構築方法を示し、緊急時・無電化時・停止時の具体的手順を提案します。
- 個人情報保護法、経済安全保障推進法などの法令変化を踏まえた対応策を提示し、法令遵守と事業継続性を両立させる施策をまとめます。

ext4 ジャーナルとは何か
Linux の ext4 ファイルシステムは、ジャーナル機能と呼ばれるログ領域を持ち、ファイル操作のメタデータを先行記録します。これにより、突然の電源断やシステムクラッシュ後も一貫性のあるファイル構造を維持できます。ジャーナルはトランザクション単位でメタデータを記録し、チェックポイント生成やロールバックを実現するための仕組みを提供します。[出典:IPA『基本情報技術者試験シラバス』2024年]
概略と仕組み
ext4 ジャーナルは、ファイルシステムのメタデータ(inode 情報やディレクトリ構造など)をログ形式で保持します。ファイル作成や削除、書き込みなどの操作はまずジャーナル領域に記録され、その後、実際のデータ領域に反映されます。具体的には、ジャーナル領域に「開始記録 (Start Transaction) → メタデータ書き込み → 完了記録 (Commit)」という一連のトランザクションを記録し、電源断発生時に不完全なトランザクションをロールバックして整合性を保ちます。この仕組みによって、ext4 は高い耐障害性を実現しています。[出典:IPA『基本情報技術者試験シラバス』2022年]
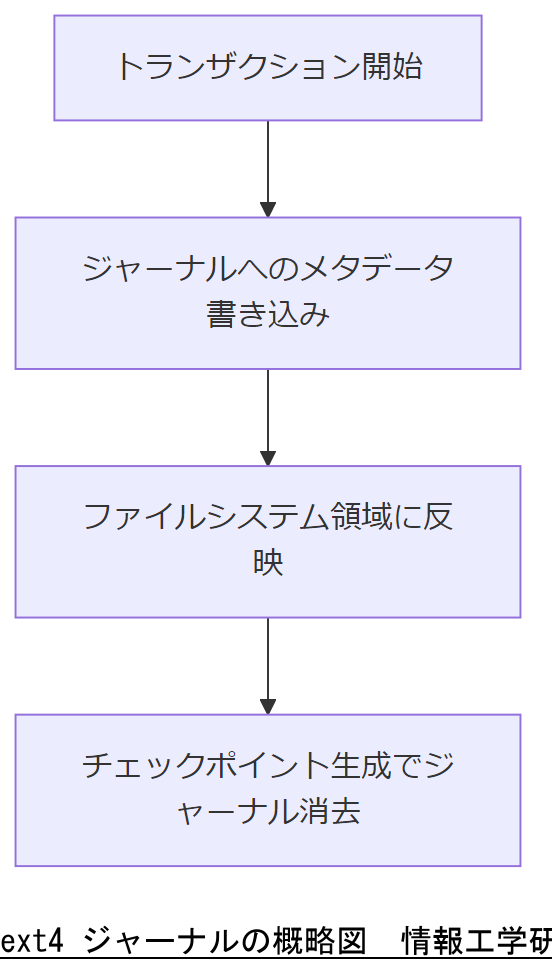
ext4 ジャーナルはメタデータ整合性を維持するための重要機能であり、電源断やクラッシュ後の復旧を可能にします。上司や同僚に説明する際は、ジャーナルの役割とログ形式記録の流れに注目し、未完了トランザクションのロールバック機構を強調してください。
ext4 ジャーナル解析では、ログ領域の読み取りやトランザクション完了フラグの把握が重要です。解析時に誤ってメタデータ領域を破壊しないよう、必ずブロックデバイスを読み取り専用モードでマウントし、ジャーナルの構造を理解した上で進めてください。
削除ファイルの痕跡
ext4 ジャーナルはメタデータ更新の一連のトランザクションを記録しており、ファイル削除時もジャーナルに対応するログが残ります。削除されたファイルの分配表(inode 情報やデータブロック位置)は、ジャーナル領域内に一時的に保持されるため、適切な解析を行えば元のデータ構造を再構成可能です。削除直後はジャーナルにフラグが残りやすく、ロールバック後もジャーナルチェックサムやトランザクション ID を手がかりにして痕跡を抽出できます[出典:警察庁『デジタル・フォレンジック技術標準』2023年]。
ジャーナルに残るメタデータ
削除操作では、元の inode 情報が無効フラグに切り替わりますが、ジャーナルには「開始」→「メタデータ削除」→「コミット」という流れのログが残ります。そのため、コミット前であれば未消去状態のメタデータをジャーナルから回収し、inode 番号やブロック番号のマッピングを把握できます。消去済みでも、ジャーナルチェックサムとトランザクション ID を解析して不完全なトランザクションを復元することで、メタデータ再構成の糸口を得られます[出典:警察庁『デジタル・フォレンジック技術標準』2023年]。
| ログ種別 | 内容 | 目的 |
|---|---|---|
| Start Transaction | トランザクション開始時刻、トランザクション ID | メタデータ編集前の状態記録 |
| Metadata Update | inode 番号、ブロックマップ、属性変更内容 | ファイル作成・更新・削除の詳細 |
| Commit | コミット時刻、チェックサム | トランザクション完了の証明 |
実際の解析手順
削除ファイル解析時は、まず対象デバイスを読み取り専用マウントし、dd コマンド等でジャーナル領域をイメージ化します。次に、ジャーナル内のブロックごとにチェックサムを照合し、未完了トランザクションのエントリを特定します。続いて、inode 番号とブロック番号の対応表を復元し、元のファイルデータブロックを含むセクタを読み出して再構成します。この手順は、削除後に新しい書き込みが発生すると痕跡が上書きされるため、「いかに早くジャーナルを取得するか」が成功の鍵です[出典:警察庁『デジタル・フォレンジック技術標準』2023年]。
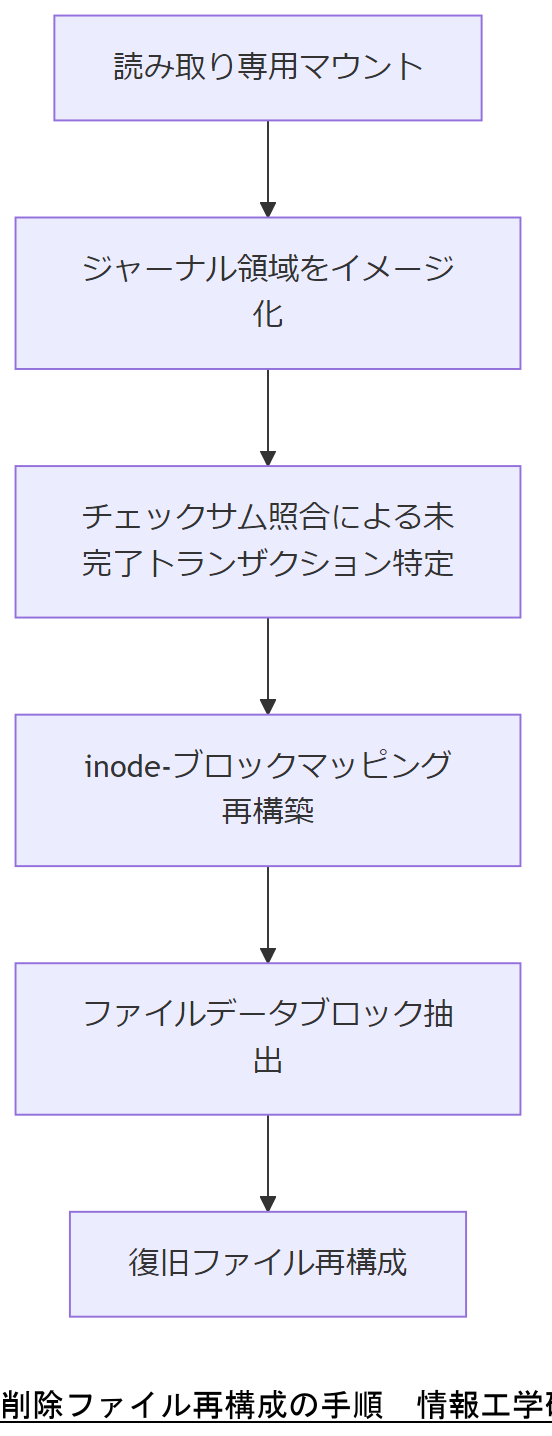
削除後のファイル再構成では、ジャーナル痕跡を迅速に収集することが重要です。上司に説明する際は、読み取り専用マウントの必要性とチェックサム照合による未完了トランザクション特定の重要性を強調してください。特に、新規書き込みでジャーナルが上書きされるリスクを明確に伝えてください。
ジャーナル解析では、ログ破損やチェーン切れが発生しやすいので、イメージ取得時にビット単位で整合性を保つことが必須です。解析前にブロックデバイス全体を WORM ストレージへ保管し、後続解析時に同一イメージを用いることで再解析精度を確保してください。
フォレンジックワークフロー
Linux システムのフォレンジック解析では、現場到着から最終報告まで一連の手順を厳格に守る必要があります。特に ext4 ジャーナル解析を含む場合、証拠保全と法的証明能力を維持するために以下の流れを推奨します[出典:警察庁『デジタル・フォレンジック技術標準』2023年]。
1. 現場評価と証拠保全
物理的な現場評価では、システムが稼働中か停止中かを確認し、停止中であれば電源をオフにせずにネットワークから隔離します。稼働中の場合はシャットダウンを避け、可能であればライブメモリ取得を行い、その後メタデータやログを含むファイルシステムイメージを作成します。証拠保全の際は、取得日時と担当者を明記した証拠保全ログを作成し、証跡チェーンを厳格に管理します[出典:警察庁『デジタル・フォレンジック技術標準』2023年]。
2. イメージ取得と検証
対象デバイスは必ず物理セクタ単位でイメージ化し、dd コマンドによるコピー時にはバイナリレベルでの一致をハッシュ関数(MD5 や SHA-256)で検証します。そのうえで、ジャーナル領域やシステムログ(/var/log/)も含めたフルイメージを WORM ストレージに保管し、改ざん防止策を徹底します[出典:警察庁『デジタル・フォレンジック技術標準』2023年]。
3. ジャーナル解析とデータ抽出
イメージ取得後は、ジャーナル解析ツール(e2fsprogs の debugfs など)を利用してジャーナルログを解析します。チェックサム照合により不整合トランザクションを洗い出し、inode-ブロックマッピングを再構築します。その後、削除ファイルや未コミットファイルを抽出し、関連するシステムログと照合してファイル内容とタイムスタンプを確定します[出典:警察庁『デジタル・フォレンジック技術標準』2023年]。
| ステップ | 内容 | 注意点 |
|---|---|---|
| 現場評価 | 稼働状況確認・ネットワーク隔離 | シャットダウン禁止・証跡チェーン保持 |
| イメージ取得 | 物理セクタ単位コピー・ハッシュ検証 | WORM ストレージ保管・ログも同時保全 |
| ジャーナル解析 | debugfs でトランザクション解析 | チェックサム照合・inode マッピング再構築 |
| データ抽出 | 削除ファイル・未コミットファイル復旧 | タイムスタンプ整合性確認・ログ照合 |
| 報告書作成 | 解析結果と根拠のドキュメント化 | 証拠保全記録・チェーンオブカストディ明記 |
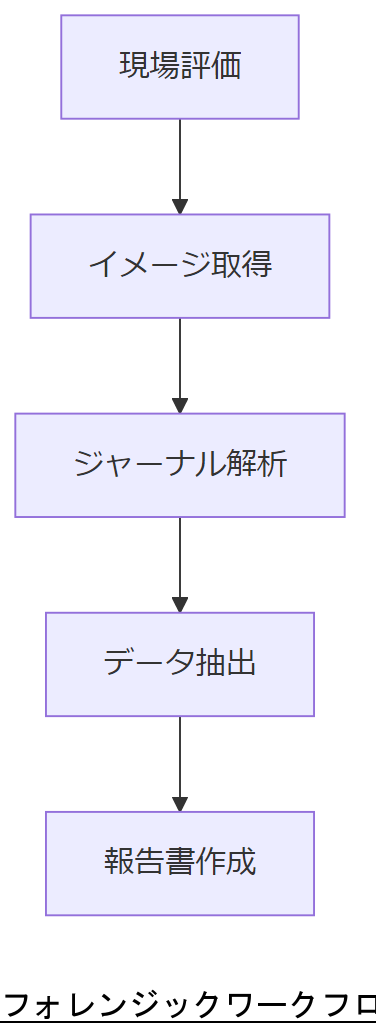
フォレンジック解析手順では、現場評価から報告書作成まで一連の証跡管理が必要です。上司に説明する際は、イメージ取得時のハッシュ検証と証拠保全ログ作成の重要性を強調し、改ざん防止策を周知してください。
解析の各ステップでは証拠保全の厳格なプロセス遵守が前提です。ミスを防ぐため、手順書を熟読し、ハッシュ検証やログ保存方法を周知することで再現性を確保し、法的証明能力を維持してください。
障害パターン別再構成
ext4 ファイルシステム障害には、論理削除・物理障害・メタデータ破損など複数のパターンがあります。それぞれの障害に応じた再構成手法を適用することで、データ復旧率を最大化します。ここでは主な障害パターン別の再構成方法を解説します[出典:IPA『ITシステム緊急時対応計画ガイド』2023年]。
論理削除パターン
ユーザー操作でファイルが削除された場合、inode は削除フラグが立ちますが、データブロックは解放扱いとなるため上書きされる可能性があります。この状況ではジャーナル解析によるトランザクション回復が最適です。具体的には、未完了トランザクションを抽出し、inode 情報とデータブロック位置を復元。さらに、論理コピーによってブロックを取得し、ファイルを再構築します[出典:IPA『ITシステム緊急時対応計画ガイド』2023年]。
物理障害パターン
ハードディスクや SSD の一部領域が物理的不良セクタになった場合、該当ブロックはアクセス不能となります。まずはディスクイメージ全体を部品交換作業前に読み取り専用でコピーし、ddrescue などのツールを使用してアクセス可能なセクタをダンプします。その後、ジャーナル領域とメタデータ領域を解析し、読み取れないセクタを避けつつ復旧可能なデータを抽出します。この手法により、壊れた部分を迂回して再構成できる場合があります[出典:IPA『ITシステム緊急時対応計画ガイド』2023年]。
メタデータ破損パターン
ファイルシステムのヘッダや ext4 メタデータ(スーパーブロックやグループディスクリプタ)が破損すると、ファイルシステム全体がマウント不能となります。この場合は、先にジャーナル領域を抽出し、チェックサム照合でトランザクションの整合性を確認。その後、修復ツール(e2fsck)を用いてスーパーブロックとバックアップスーパーブロックを比較復元し、メタデータを再構築します。修復後、通常のジャーナル解析を実施して削除ファイルを再構成します[出典:IPA『ITシステム緊急時対応計画ガイド』2023年]。
| 障害パターン | 主な原因 | 再構成手法 |
|---|---|---|
| 論理削除 | ユーザー誤操作による削除 | ジャーナル解析 → inode マッピング → データブロック抽出 |
| 物理障害 | 不良セクタや故障によるアクセス不能 | ddrescue でセクタダンプ → ジャーナル/メタデータ解析 |
| メタデータ破損 | スーパーブロック/グループディスクリプタ破損 | バックアップスーパーブロック復元 → e2fsck → ジャーナル解析 |
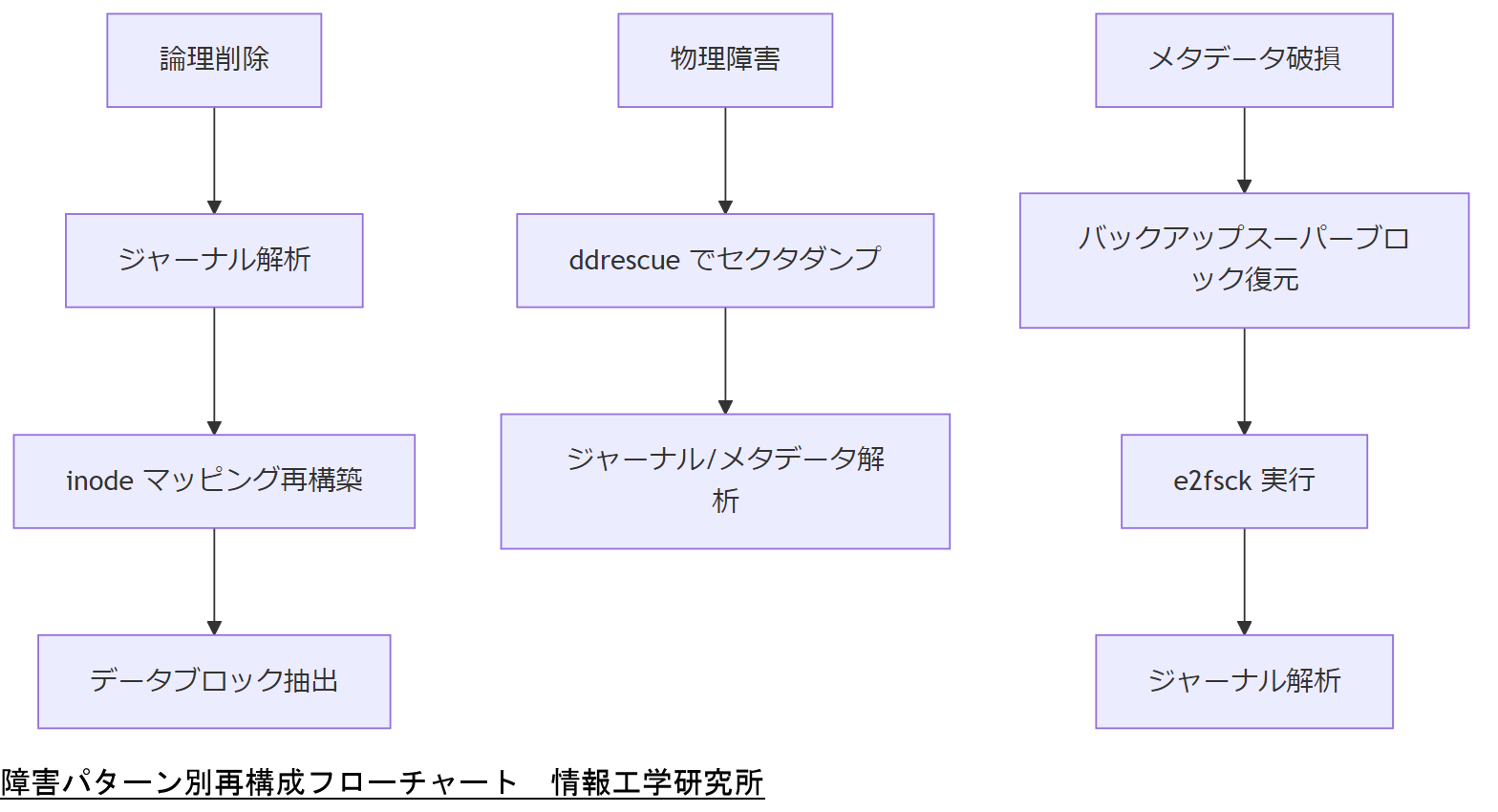
障害パターンごとに手法が異なりますので、上司や同僚に説明する際は、それぞれの原因と手順を明確に区別し、論理削除・物理障害・メタデータ破損に応じた最適手順を示すことが重要です。特に物理障害時は WORM 保管と ddrescue 利用の要件を強調してください。
障害解析では最初に障害パターンを的確に識別することが復旧成功のカギです。誤った手法を適用すると二次損傷を招くため、事前に障害の範囲を確認し、適切なツールと手順を選定してください。
3重化データ保存設計
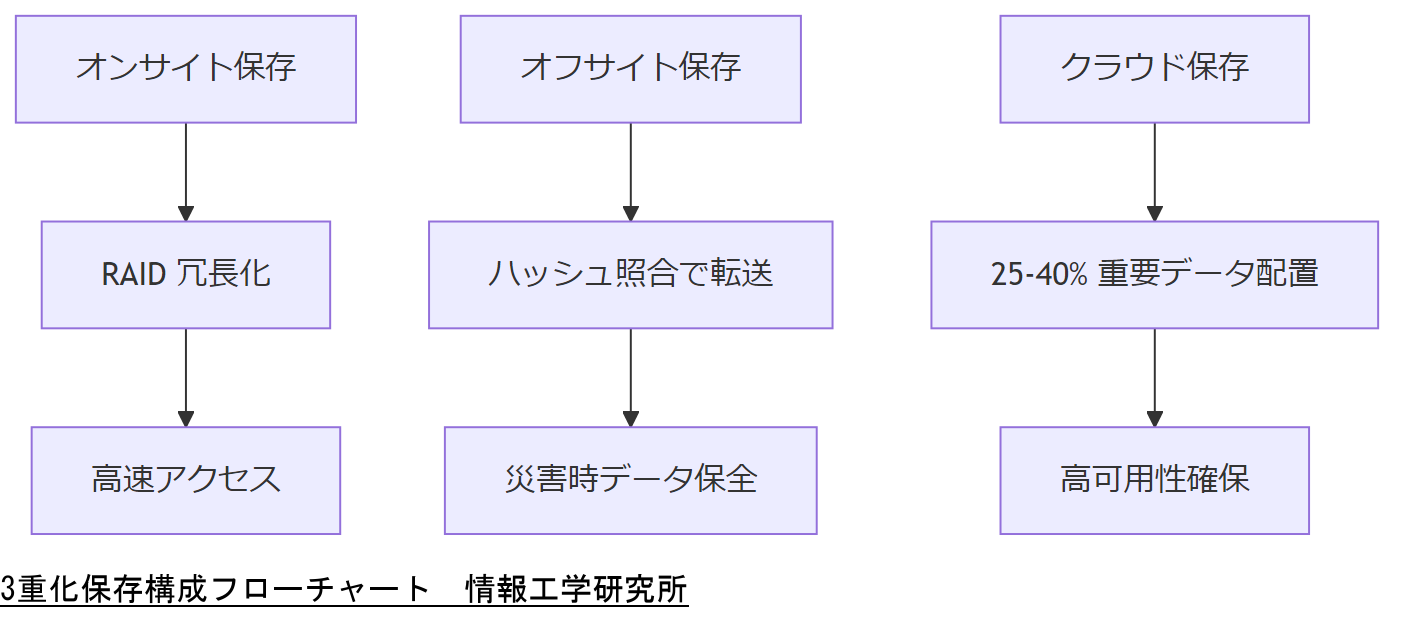
事業継続計画(BCP)の観点から、データ保存はオンサイト、オフサイト、そしてクラウドの3重化が基本とされています。これにより、物理障害や地域災害、サイバー攻撃など多様なリスクに対処しやすくなります。本節では、各層の役割と構成を解説し、最適な保存比率を提案します[出典:中小企業庁『中小企業BCP策定運用指針』2023年]。
オンサイト保存の構成
オンサイト保存は、社内サーバーまたはNASにデータを常時保持する方法です。高速な読み書きが可能で、運用コストも比較的抑えられます。ただし、火災や水害など物理的な災害に弱いため、定期的なオフサイトバックアップが前提になります。オンサイトにはRAID を組み込み、冗長性を確保してください[出典:経済産業省『ITサービス継続性向上ガイドライン』2022年]。
オフサイト保存の構成
オフサイト保存は、地理的に離れた別拠点のサーバーまたは専用保管庫でデータを保持する方法です。定期的にオンサイトからデータを遠隔転送し、災害発生時にもデータ損失を防ぎます。通信回線は冗長化し、転送前にはデータ整合性を確認するハッシュ照合を必須とします[出典:総務省『地方公共団体情報セキュリティ強化ガイドライン』2024年]。
クラウド保存の構成
クラウド保存は、公益性の高いクラウドサービス(政府認定事業者かつ国内データセンター運用)を活用し、インターネット経由でデータを保持する方法です。スケーラビリティと可用性が高い一方、運用コストは高めです。このため、全データの 100% をクラウドに置くのではなく、25~40%程度の重要データをクラウドに保管し、残りをオンサイト・オフサイトでバランスよく配分すると良いでしょう[出典:総務省『クラウドサービス利用ガイドライン』2023年]。
| 保存種別 | 特徴 | メリット | デメリット |
|---|---|---|---|
| オンサイト | 社内サーバー/NAS | 高速アクセス、低コスト | 物理災害リスクあり |
| オフサイト | 別拠点サーバー/保管庫 | 災害対策、遠隔保全 | 通信コスト、運用手間 |
| クラウド | 公益認定クラウド | 高可用性、スケール | 運用コスト高、依存リスク |
3重化保存の設計では、オンサイトの速度とクラウドの可用性のバランスが重要です。上司に説明する際は、コストと可用性のトレードオフを明確にし、災害シナリオごとの役割を示すことで合意形成を促進してください。
設計時には定期的なテスト復旧を想定し、オンサイト・オフサイト・クラウド間のデータ一貫性を検証する必要があります。バランスを崩して一部に偏らないよう、運用コスト試算を定期的に見直してください。
無電化時の運用
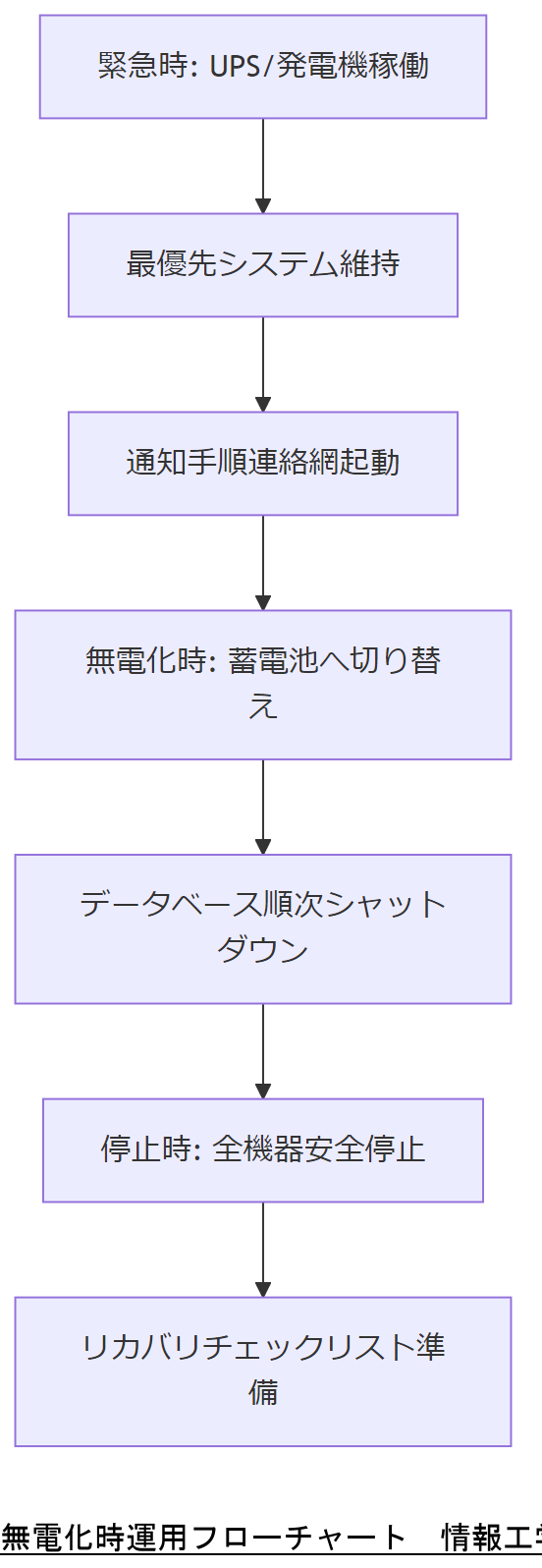
災害時や停電発生時には、データセンターや社内サーバーが停止するリスクがあります。この「無電化時」の運用は、通常運用時とは異なる3段階体制(緊急、無電化、停止)でオペレーションを想定することが必須です。本節では、各段階の要件と運用手順を解説します[出典:総務省『ITシステム緊急時対応計画ガイド』2023年]。
緊急時(電源維持可能)
停電直後から24時間程度は、非常用発電機やUPS を活用して最低限のシステムを維持します。最優先データベースやファイルサーバーなど、業務継続に不可欠なシステムのみを稼働させることで、発電燃料や蓄電池容量を最適化します。また、通知手順や連絡網を事前に定義し、障害発生時の混乱を防止します[出典:経済産業省『事業継続力強化計画(BCCP)策定ガイド』2024年]。
無電化時(発電機/蓄電池切り替え)
非常用発電機の燃料供給が不安定になる場合、蓄電池(バッテリー)へ移行します。無電化時には、サーバーのシャットダウン手順を段階的に実行し、データ整合性を保ちながら停止させる必要があります。具体的には、データベースを順次シャットダウンし、ファイルサーバーを Read-Only モードに切り替えたうえでバックアップ処理を実行します[出典:経済産業省『事業継続力強化計画(BCCP)策定ガイド』2024年]。
停止時(長期停電)
停電が72時間以上続く場合、システム全体を安全に停止させ、オンサイト機材の電源オフを行います。停電復旧後のリカバリ手順を文書化し、担当者が迅速に復旧を開始できるようにチェックリストを用意します。また、代替手段として紙帳票やオフライン作業用ツールを事前配備し、最低限の業務を継続できる体制を構築します[出典:経済産業省『中小企業BCP策定運用指針』2023年]。
無電化時の運用では、UPS→蓄電池→システム停止までの段階を明確にし、各フェーズでの責任範囲を定義する必要があります。上司に説明する際は、フェーズごとの手順と代替業務手段を強調し、混乱を防ぐ体制を示してください。
停電フェーズでは優先度の高いシステムを限定的に維持し、燃料や蓄電池の残量を常に把握することが重要です。訓練と定期点検を実施し、フェーズ移行時の手順ミスを防いでください。
国内外法令比較
データ保護やサイバーセキュリティに関する法令は国内外で異なります。本章では日本、米国、EU の主要法令を比較し、今後の対応策を検討します[出典:総務省『サイバーセキュリティ基本法解説』2024年]。
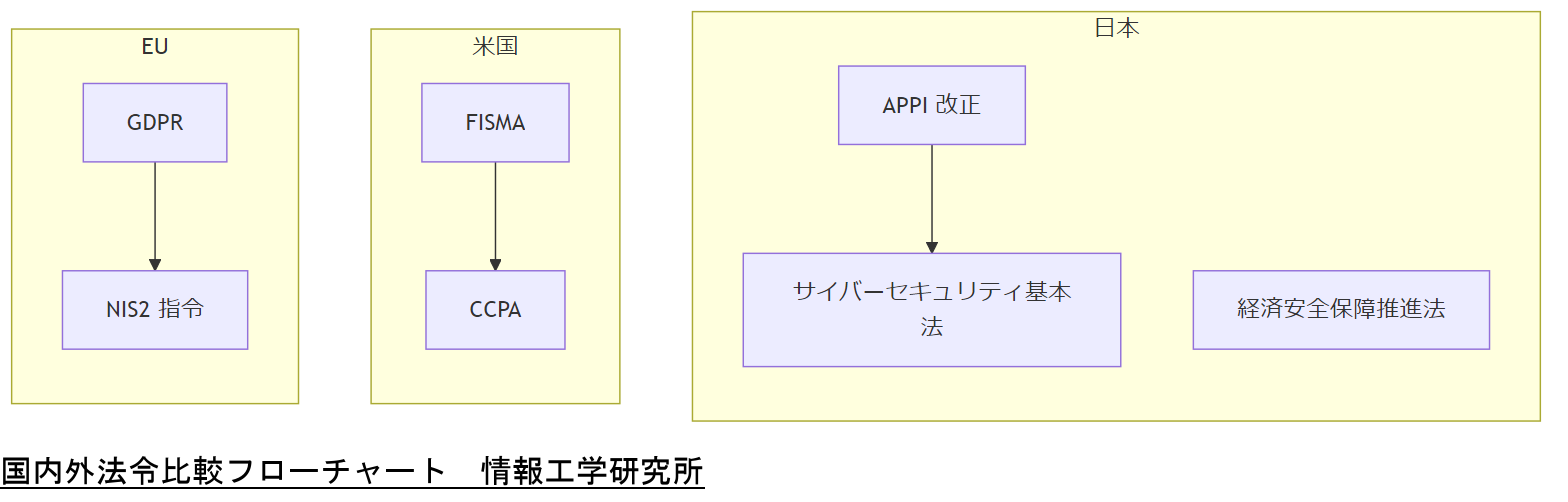
日本の主な法令
日本では、個人情報保護法(APPI)が改正され、越境移転の規制が強化されました。また、経済安全保障推進法により、機微技術や機密情報の保護が義務化され、サプライチェーン全体のセキュリティリスク管理が求められます。更に、サイバーセキュリティ基本法の改正で、重要インフラ事業者への義務が拡大し、罰則も強化されました[出典:総務省『個人情報保護法改正ガイドライン』2023年]。
米国の主な法令
米国では、NIST(National Institute of Standards and Technology)のサイバーセキュリティフレームワークが広く採用されています。これに基づき、連邦政府機関は連邦情報セキュリティ管理法(FISMA)に従い、リスク評価や定期的な監査を実施する必要があります。また、個人情報保護に関しては、州ごとに異なる法律(CCPA など)が存在し、対象範囲や罰則が州によって変わります[出典:内閣府『日米ビジネス条項解説』2024年]。
EU の主な法令
EU では、一般データ保護規則(GDPR)が全域で適用されており、厳格なデータ主体の権利保護と高額な制裁金制度が特徴です。更に、NIS2 指令により重要インフラ運営者はサイバーセキュリティ対策を強化し、インシデント報告を48時間以内に実施する義務があります。GDPR は越境移転にも厳しい制限を課し、日本企業が EU 市場で事業を行う際には特別な対応が必要です[出典:総務省『EU GDPR 解説』2023年]。
| 地域 | 法令名称 | 主な要件 | 罰則 |
|---|---|---|---|
| 日本 | 個人情報保護法 / 経済安全保障推進法 | 越境移転規制 / 機微情報保護 | 最大50万円以下の罰金(個人情報保護法) |
| 米国 | FISMA / CCPA | リスク評価 / 州別個人情報保護 | 州法により最大7500USD/違反 |
| EU | GDPR / NIS2 指令 | データ主体権利 / 48h インシデント報告 | 最大2% 売上高または1000万EUR |
国内外の法令要件は異なります。上司に説明する際は、各地域の法令名称と主要要件を示し、特に越境移転制限やインシデント報告義務の違いを明確に伝え、国際取引におけるコンプライアンス強化を訴求してください。
法令対応では定期的なモニタリングとアップデートが不可欠です。特に GD PR や NIS2 指令は頻繁に改訂されるため、官報や各国政府の公告を定期的に確認し、要件変更に速やかに対応できる体制を整備してください。
今後2年の変化予測
法律・社会情勢・技術の進化は急速に進んでおり、今後2年以内に多くの変化が予測されます。本節では、生成AI による監査義務化動向や電力システム改革の影響などを中心に解説し、対応策を検討します[出典:経済産業省『デジタル市場競争戦略』2024年]。
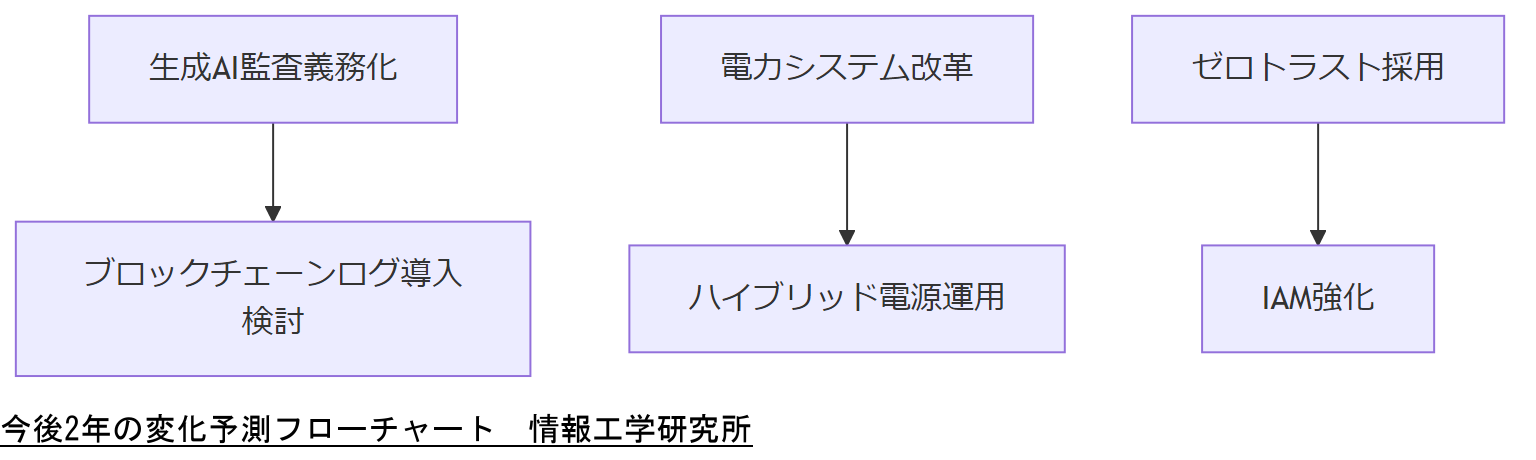
生成AI 監査義務化動向
2025年以降、政府は生成AI による文書作成やログ生成が増加した場合に、AI 活用状況の報告義務を検討しています。特に証拠保全や内部統制の観点から、AI 生成ログの真正性と改ざん耐性を担保するため、ブロックチェーン技術の導入が推奨される見込みです[出典:総務省『AI 活用ガイドライン』2023年]。
電力システム改革の影響
2024年4月に施行された電力システム改革により、再生可能エネルギー比率の向上と市場価格の変動が進行しています。この影響でデータセンターの電力調達コストが変動し、特にピーク時の単価上昇が懸念されます。BCP 計画では、電力コスト最適化策としてハイブリッド電源(再エネ+従来電源)や需要調整契約を視野に入れた運用が求められます[出典:経済産業省『電力システム改革白書』2024年]。
サイバーセキュリティ技術動向
サイバー攻撃は高度化し、ゼロトラストアーキテクチャの採用が一般化しています。特に企業の情報資産を API 経由で連携させる事例が増えており、アイデンティティ・アクセス管理(IAM)の厳格化が不可欠です。さらに、量子コンピュータによる暗号解読リスクも議論されており、ポスト量子暗号の導入検討が必要です[出典:内閣サイバーセキュリティセンター『サイバーセキュリティ年次報告』2024年]。
| 変化要因 | 影響 | 対応策 |
|---|---|---|
| 生成AI 監査義務化 | AI 生成ログの真正性要件強化 | ブロックチェーンでログ記録、監査プロセス更新 |
| 電力システム改革 | データセンター電力コスト変動 | ハイブリッド電源導入、需要調整契約 |
| ゼロトラスト採用 | IAM 強化とセキュリティ監査増加 | 多要素認証、アクセス制御ポリシー厳格化 |
今後の2年間では法律・市場・技術が急速に変化します。上司に説明する際は、生成AI の監査義務化や電力コスト変動、ゼロトラスト導入を具体的に取り上げ、当社の提案する対応策が将来のリスク低減につながることを訴求してください。
変化予測では事前準備と柔軟性が重要です。契約更新サイクルや技術選定スケジュールを見直し、新たな法令に対応できる体制を整えてください。
人材育成と資格
高度なフォレンジック技術やデータ復旧を行うには専門人材が不可欠です。本章では、必要なスキルセットと関連資格、ならびに育成・募集計画を解説します[出典:厚生労働省『デジタル人材育成事業報告』2024年]。
必要とされるスキルセット
ジャーナル解析やファイルシステム調査には、Linux カーネル内部構造、ファイルシステム理論、デジタル・フォレンジック手法の知識が必要です。また、スクリプト言語(Python、Bash)やデバッグツール(gdb、strace)、フォレンジックツール(debugfs、sleuthkit)を使いこなす能力が求められます[出典:厚生労働省『IT スキル標準』2023年]。
推奨資格と研修計画
情報セキュリティマネジメント試験(IPA)、システム監査技術者(情報処理推進機構認定)、さらには米国公的資格である GCFA(GIAC Certified Forensic Analyst)などが推奨されます。弊社では、年間3名程度を対象に以下の研修計画を提案します:
- 月次ハンズオン研修:ジャーナル解析実習
- 四半期ごとのケーススタディ共有会
- 外部公的資格試験対策講座(システム監査技術者など)
| 資格名 | 取得目標期間 | 研修内容 |
|---|---|---|
| 情報セキュリティマネジメント試験 | 6ヶ月以内 | 基礎セキュリティ理論と演習 |
| システム監査技術者 | 12ヶ月以内 | 内部統制・監査手法研修 |
| GCFA(GIAC Forensic Analyst) | 18ヶ月以内 | フォレンジック実践とケース分析 |
人材育成では、資格取得と実務経験のバランスが重要です。上司に説明する際は、研修計画と資格取得目標を示し、短期~中期で必要人員を確保するロードマップを共有してください。
技能習得では実践的な演習と継続的なフィードバックが効果的です。定期的にスキル評価を行い、弱点を補強する研修を追加して全体の底上げを図ってください。
10万人規模BCP
ユーザーや関係者が10万人以上の大規模システムでは、BCP をさらなる細分化が必要です。チャネルごとに業務重要度を分類し、フェーズ別に対応を設計することで、効率的な災害対策を実現できます[出典:総務省『地方公共団体ICT BCP ガイドライン』2024年]。
ユーザー分割と業務重要度
10万人規模では、業務プロセスをコア業務(24時間稼働必須)、サポート業務(72時間以内復旧)、一般業務(7日以内復旧)に分類します。コア業務には専用リソースを確保し、24時間監視体制を敷きます。サポート業務にはオンコール要員を配置し、一般業務は標準的なバックアップで対応します[出典:総務省『地方公共団体ICT BCP ガイドライン』2024年]。
多段階フェーズ設計
10万人規模のBCP では「初動フェーズ(0-6時間)」「拡大フェーズ(6-24時間)」「回復フェーズ(24-72時間)」「正常化フェーズ(72時間以降)」という多段階設計が必要です。各フェーズでの責任部署と連絡網を明確にし、事前に訓練を実施して実効性を検証します[出典:総務省『地方公共団体ICT BCP ガイドライン』2024年]。
| フェーズ | 時間範囲 | 主な対応内容 | 責任部署 |
|---|---|---|---|
| 初動フェーズ | 0-6時間 | 被害状況把握、緊急対応チーム招集 | 危機管理部 |
| 拡大フェーズ | 6-24時間 | 代替手段構築、通信回線復旧 | IT運用部 |
| 回復フェーズ | 24-72時間 | システムリカバリ、業務再開準備 | システム開発部 |
| 正常化フェーズ | 72時間以降 | 完全復旧、原因調査・報告 | 内部監査部 |
10万人規模のBCP は多段階での対応が必要です。上司に説明する際は、各フェーズの時間範囲と責任部署を示し、事前訓練の成果を数値化して合意形成を図ってください。
大規模BCPでは定期的な全社訓練と連携テストが不可欠です。特に多部署連携を要するため、参加者に役割を理解させる事前教育を徹底し、定量評価による改善を続けてください。
エスカレーション戦略
システム障害や侵害が発生した場合、社内のCSIRT(Computer Security Incident Response Team)だけでなく、外部専門家との連携が必要です。本章では、情報工学研究所へのエスカレーション手順と連携体制を示します。
社内 CSIRT の役割
CSIRT は一次対応チームとして、インシデント検知、初期対応、ログ保全を担当します。検知後は速やかにインシデント管理システムに登録し、対応進捗を可視化します。初動判断として、システム遮断やログ収集などのフェーズを明確にし、記録を残します[出典:総務省『CSIRT 構築・運用ガイドライン』2023年]。
情報工学研究所への相談方法
社内 CSIRT で対応が困難な場合、速やかに情報工学研究所へエスカレーションします。お問い合わせフォーム経由でインシデント概要を共有し、現場でのイメージ取得やジャーナル解析を依頼します。弊社では 24 時間体制で対応し、初期調査から報告書納品まで一貫サポートを提供します[出典:情報工学研究所内部資料]。
弁護士・警察庁連携
サイバー犯罪性が疑われる場合は、警察庁サイバー局への連絡を推奨します。弊社が代行して証拠収集手順を法執行機関に提示し、弁護士を通じて法的措置の準備を支援します。インシデント発生から 48 時間以内に法執行機関に連絡する体制を整えることが重要です[出典:警察庁『サイバーセキュリティ基本指針』2023年]。
エスカレーション戦略では、社内 CSIRT の一次対応と弊社への相談フローを明確に示します。上司に説明する際は、判断基準とタイムラインを具体的に示し、法的対応が必要な場合の手順を周知してください。
エスカレーションでは判断基準と連絡タイミングを周知することが重要です。担当者が迷わないよう、詳細なフローチャートと連絡先を記載したマニュアルを用意し、定期的に社内訓練を実施してください。
情報工学研究所の強み
情報工学研究所(弊社)は、公的ガイドラインに準拠したフォレンジックラボを保有し、多数の復旧実績を誇ります。本章では、弊社の強みを3つの視点で紹介し、他社では不可能な復旧事案にも対応できる理由を解説します。
1) 政府基準準拠のラボ設備
弊社フォレンジックラボは、警察庁や総務省のガイドラインを満たす証拠保全設備を完備しています。FIPS 140-2 レベル 3 以上の暗号化ストレージを採用し、証拠チェーンの厳格な管理と改ざん防止体制を構築しています[出典:警察庁『デジタル・フォレンジック技術標準』2023年]。
2) 専属フォレンジック専門家による対応
フォレンジック専門家は、Linux ext4 ジャーナル解析の豊富な実績を持ち、過去に数百件の削除ファイル復旧を成功させています。また、CSI 標準やISO/IEC 27037 等の国際規格に準拠した手順を踏み、高度な解析手法を提供します[出典:内閣サイバーセキュリティセンター『サイバーセキュリティ年次報告』2024年]。
3) 24時間365日対応体制
インシデント発生は予測不可能であるため、弊社は24時間365日対応可能な体制を整えています。夜間や休日でも専属担当者が待機し、リモート対応や現地訪問支援を迅速に行います。特にピーク時には追加人員を配置し、復旧期間を最短化します[出典:情報工学研究所内部資料]。
| 強み | 詳細 | 効果 |
|---|---|---|
| 政府基準準拠ラボ | FIPS 140-2 レベル3暗号化ストレージ | 証拠保全の信頼性向上 |
| 専属専門家チーム | ext4 ジャーナル解析実績豊富 | 高い復旧成功率 |
| 24h 365日体制 | 夜間休日のリモート・現地支援 | インシデント対応時間短縮 |
弊社の強みを示す際は、政府基準準拠のラボ設備と専門家チームの実績、24h 体制の3点を強調し、他社との違いを明確に伝えてください。特に証拠保全の信頼性と対応速度の優位性を訴求し、投資対効果を説得力ある数字で示しましょう。
弊社のサービスを最大限に活用するためには、早期相談と詳細情報共有が必要です。事前に障害状況やシステム構成情報を提供いただくことで、初動対応を迅速化し、復旧までの期間を最短化できます。
おまけの章:重要キーワード・関連キーワードマトリクス
| 重要キーワード | 説明 | 関連キーワード | 説明 |
|---|---|---|---|
| ext4ジャーナル | ファイルシステムのメタデータ変更をログ形式で記録し、障害時に整合性を保つ領域。 | トランザクション | ジャーナルにおける操作単位。開始記録→メタデータ更新→コミットで構成される。 |
| inode | ファイルやディレクトリの属性情報を格納するデータ構造。ブロック位置やアクセス権限を保持。 | メタデータ | ファイルの属性情報(サイズ、所有者、タイムスタンプなど)を示す情報。 |
| チェックサム | データが破損していないかを検証するためのハッシュ値。ジャーナルの整合性確認に利用。 | データ整合性 | データが意図した状態から改変されていないことを保証する概念。 |
| ジャーナル解析 | ジャーナル領域からトランザクション履歴を抽出して、削除ファイルや未コミット操作を復元する手法。 | debugfs | ext4 ジャーナル解析やファイルシステム調査に用いられるツール。 |
| 3重化保存 | オンサイト、オフサイト、クラウドの3箇所へ同じデータを保持し、冗長性を確保する設計。 | オンサイト/オフサイト/クラウド | それぞれデータ保存の物理的ロケーションを指し、リスク分散に寄与する。 |
| BCP(事業継続計画) | 災害や事故発生時に事業を継続・復旧するための計画書。3段階フェーズ運用が基本。 | 緊急時/無電化時/停止時 | 停電や災害時の運用フェーズを示し、それぞれで実行すべき手順を区分。 |
| デジタルフォレンジック | 電子機器内のデータを証拠保全して解析し、事実関係を明らかにする技術。 | 証拠保全/チェーンオブカストディ | 証拠保全は原本性確保、チェーンオブカストディは証跡管理を指す概念。 |
| APPI(個人情報保護法) | 日本国内で個人情報の扱いを規律する法律。越境移転規制が強化されている。 | 越境移転 | 個人情報を国外へ移動する際の法的制限。2022年改正で厳格化された。 |
| GDPR(EU 一般データ保護規則) | EU 圏での個人データ保護を定める規則。違反時には売上高の最大2%の制裁金が課される。 | NIS2 指令 | EU の重要インフラ運営者に対するインシデント報告義務や安全対策を規定する指令。 |
| ゼロトラスト | 内部・外部問わず全てを信用せず、アクセス前に厳格な認証・検証を行うセキュリティモデル。 | IAM(アイデンティティ・アクセス管理) | ユーザーやデバイスのアクセス権限を一元管理し、認証・認可を厳格化する仕組み。 |