※注意:本記事は Active Directory/グループポリシー(GPO)運用に関する一般的な情報提供です。環境・権限設計・監査方針・ログ保全状況によって最適解は変わります。重要システムへの適用前には検証を行い、必要に応じて専門家(株式会社情報工学研究所など)へご相談ください。
もくじ
- 朝、GPOが消えていた——「誰が・いつ・何を」が追えない運用は、障害より怖い
- GPOは“設定ファイル”じゃない:ADオブジェクト+SYSVOLの二重構造をまず疑う
- 「イベントログを見れば分かる」は半分正しい:残る条件と残らない条件
- 土台づくり:Directory Service Changes 監査で “差分” を記録する
- CN=Policies,CN=System を追跡する:GPOのGUIDと属性変更の読み解き方
- SYSVOL/DFS-R側も取り逃がさない:ファイル監査と整合性チェック
- 履歴があると復旧が速い:GPMCバックアップ/世代管理/運用ルール化
- 「消せない」を設計する:権限分離・委任設計・特権端末・多要素の現実解
- もし消えたら:AD Recycle Bin/権威復元/バックアップから戻す手順の全体像
- 結論:変更履歴は“解析”だけじゃ足りない——削除事故を起こさない仕組みに落とす

朝、GPOが消えていた——「誰が・いつ・何を」が追えない運用は、障害より怖い
Active Directory(AD)環境の運用で、グループポリシー(GPO)が「消えた」「いつの間にか変わっていた」という事象は、単なる設定ミス以上の意味を持ちます。理由はシンプルで、GPOは端末・サーバのセキュリティ境界、運用ルール、認証・更新・ログ設定の“根っこ”に触れるからです。影響範囲が広く、しかも原因特定に時間がかかると、復旧の遅延そのものが二次被害になります。
「誰が・いつ・何を」が不明だと、復旧は“再現性のない作業”になる
障害対応は本来、(1) 事象確認 → (2) 変更点特定 → (3) 影響範囲の切り分け → (4) 復旧 → (5) 再発防止、という順で進めるのがセオリーです。しかしGPO削除や不正変更の局面で、変更履歴(監査ログ)が残っていないと、(2)が破綻します。すると復旧が「当てずっぽうの設定戻し」になり、正しく戻せたかの検証コストが跳ね上がります。
“変更履歴解析”のゴールは、犯人探しではなく「運用の再現性」を取り戻すこと
本記事が扱うのは、GPOの変更・削除に対して、技術的に追跡可能な情報源を整理し、再現性のある調査ルートを作ることです。結論を先取りすると、追跡の軸は大きく2つあります。
- AD側(ディレクトリ):GPOを表すオブジェクトの作成・変更・移動・削除
- SYSVOL側(ファイル):GPOテンプレート(ポリシーファイル群)の変更・欠損・複製不整合
この2軸は“どちらか片方だけ見ても不十分”になりがちです。なぜなら、GPOはADとSYSVOLの二重構造で成立しているためです(この点は次章で正確に整理します)。
本記事で扱う範囲(現実に役に立つ境界線)
本記事は「Windows Server/AD DS/GPMCを前提に、GPOの変更履歴と削除対策を実務で回せる状態にする」ことを目的にします。反対に、製品宣伝や推測ベースの断定は避け、Microsoftが公開している仕様・監査イベント・機能制約に沿って説明します。
なお、実際の現場では「監査が未設定」「ログ保持が短い」「複数DCでログが分散」「委任権限が過剰」といった“よくある前提不足”が重なります。その場合、一般論だけでは解けない分岐が増えます。終盤では、一般論の限界と、個別案件で専門家に相談すべきポイントを明確にします。
GPOは“設定ファイル”じゃない:ADオブジェクト+SYSVOLの二重構造をまず疑う
GPOを「設定ファイルの集合」と捉えると、調査が高確率で迷子になります。GPOは実装上、AD上のコンテナ(Group Policy Container / GPC)と、SYSVOL上のテンプレート(Group Policy Template / GPT)の両方で成立します。つまり、削除・変更の原因は「ディレクトリ操作」かもしれないし、「ファイル操作」かもしれないし、両方が同期不全を起こしている可能性もあります。
GPOの“2つの実体”を、調査単位として固定する
仕様として、GPCはドメイン内の CN=Policies,CN=System 配下に格納され、GPOごとにGUID名のコンテナとして管理されます。一方、GPTはSYSVOLの \Policies 配下にGUID名フォルダとして存在し、スクリプトやセキュリティ設定などのポリシーデータを保持します。
| 観点 | AD側(GPC) | SYSVOL側(GPT) |
|---|---|---|
| 実体 | ディレクトリ上の groupPolicyContainer オブジェクト(GUID) | ファイルシステム上のGUIDフォルダ(Policies\{GUID}) |
| 消える典型 | GPO削除/属性変更/権限変更/リンク変更の根拠が追えない | ポリシーファイル欠損/誤上書き/複製不整合(DC間) |
| 追跡の入口 | Securityログ(Directory Service Changes)+オブジェクトDN | ファイル監査ログ+SYSVOL複製状態(DFSR等) |
「GUIDが分からない」ときの考え方
GPOは一意のGUIDを持ちます。運用上よくある詰まりどころが、「表示名は覚えているが、GUIDが分からない」「GUIDは分かるが、どのGPOか分からない」です。ここは“どちらからでも相互参照できる”ようにしておくと、調査の速度が変わります。
- AD側:
CN=Policies,CN=System配下のGUIDコンテナを辿り、表示名などの属性で同定する - SYSVOL側:
Policies\{GUID}を起点に、AD側のコンテナGUIDと一致させる
この「二重構造の一致確認」は、削除対策だけでなく、“DC間で片方だけ反映されている”類のトラブル(複製遅延・不整合)の切り分けでも必須になります。
「イベントログを見れば分かる」は半分正しい:残る条件と残らない条件
GPO変更履歴の調査で最初に出る言葉が「とりあえずイベントログ(Security)を見よう」です。これは半分正しいのですが、“何でも残る”わけではありません。結論から言うと、Directory Service Changes の監査を有効化し、さらに対象オブジェクトにSACL(監査ACL)で適切な監査設定が入っている場合に限り、ADオブジェクトの作成・変更・削除がイベントとして記録されます。
Directory Service Changes で記録される代表イベント
Microsoftの監査サブカテゴリ「Audit Directory Service Changes」では、代表的に次のイベントが定義されています(作成/変更/削除など)。これらが揃って初めて「いつ何が起きたか」を時系列で追えます。
| Event ID | 意味(要約) | GPO調査での使いどころ |
|---|---|---|
| 5136 | ディレクトリサービスのオブジェクトが変更された | GPO属性変更(表示名・パス・バージョン・権限等の変化) |
| 5137 | オブジェクトが作成された | GPO新規作成の痕跡 |
| 5139 | オブジェクトが移動された | 想定外のOU移動・配置変更の痕跡(リンク/適用範囲の事故の入口) |
| 5141 | オブジェクトが削除された | GPO削除(GPC消失)の決定的手がかり |
「監査を有効化したのに出ない」典型:SACLが無い
たとえば5136(変更)は、監査サブカテゴリを有効にするだけで無条件に出るわけではなく、変更対象のオブジェクト(または属性)に対する監査設定(SACL)が必要です。つまり、監査ポリシーだけ有効化しても、SACLが未設定なら「何も起きていないように見える」状態になります。
ログは“残る設計”がないと、すぐ上書きされる
Directory Service Changes を真面目に取り始めると、ドメインコントローラのSecurityログは増えやすくなります(監査イベントの性質上、対象が増えるほど出力量が増えます)。ログ保持期間や転送(WEF/SIEM等)が無いと、事故が発覚した時点で「ログがもう無い」が起きます。これは設定論ではなく保全設計の問題なので、後の章で“現実解”として整理します。
土台づくり:Directory Service Changes 監査で “差分” を記録する
「ログを見れば分かる」の前に、まず“ログが残る状態”を作る必要があります。GPO変更履歴の核になるのは、ドメインコントローラ(DC)の Security ログに記録される Directory Service Changes(ディレクトリサービス変更)の監査イベントです。これを有効化し、さらに対象オブジェクトへSACL(監査ACL)を入れて初めて、GPOの作成・変更・削除が「誰の操作か」として残るようになります。
監査を有効化する:Advanced Audit Policy(詳細監査)を前提にする
監査を“それっぽくON”にしても、環境によっては期待するイベントが出ません。運用の再現性を得るため、基本は Advanced Audit Policy Configuration(詳細監査ポリシー)を使って、サブカテゴリ単位で明示的に設定します。代表的には次の方針になります(DCに適用)。
- Audit Directory Service Changes:成功(Success)を有効化(GPOの変更・削除の痕跡の中心)
- 必要に応じて:Audit Directory Service Access / Audit Object Access(SYSVOL監査と組み合わせる場合)
よくある落とし穴:詳細監査が“上書きされる”問題を潰す
複数の監査設定が混在すると、「設定したのに効いていない」状態が起きます。一般的に現場で有効なのは、詳細監査を正とし、従来監査ポリシーの影響を受けにくいようにすることです。実務では、次の種別の設定が論点になります。
| 論点 | 起きがちなこと | 対策の方向 |
|---|---|---|
| 従来監査ポリシーと詳細監査の混在 | 期待するサブカテゴリが有効にならない/環境差が出る | DC向けGPOで詳細監査を明示し、運用ルールを統一する |
| 監査イベントの出力量 | Securityログが早期にローテーションして過去が消える | ログ容量・保持・転送(WEF/SIEM等)を“設計”として用意する |
SACL(監査ACL)を入れる:ここが「出る/出ない」の分水嶺
監査ポリシーが有効でも、対象オブジェクト側に監査設定(SACL)が無ければ、変更イベントは記録されません。GPOの追跡をしたいなら、少なくとも CN=Policies,CN=System(GPOコンテナがぶら下がる場所)配下で、作成・削除・変更に関する監査を記録できるようにします。
ただし、ここは設計の一部です。監査対象を広げすぎるとイベント量が増え、ログ保全が破綻します。逆に絞りすぎると肝心な操作が抜けます。現場では次のような判断が必要になります。
- 最小構成:GPOコンテナ(Policies配下)の作成/削除/主要属性変更に絞る
- 推奨構成:GPOコンテナ+リンク変更(OU側)+権限変更(ACL)まで追う
- 高精度構成:上記に加え、SYSVOL側のファイル監査も併用(ただしイベント量が増える)
「後から有効化した」場合の限界を理解しておく
監査はタイムマシンではありません。事故が起きてから監査をONにしても、過去の操作は復元できません。だからこそ、削除対策は「事故の再発を止める仕組み」と「次に起きたら確実に追えるログ設計」をセットにする必要があります。ここまでが、変更履歴解析の“土台”です。
CN=Policies,CN=System を追跡する:GPOのGUIDと属性変更の読み解き方
Directory Service Changes の監査が効き始めると、次は「イベントの読み方」が論点になります。GPOの実体(GPC)は CN=Policies,CN=System 配下にあり、GPOごとに {GUID} の名前で格納されます。したがって、GPO削除や変更は、最終的にこのDN(識別名)に対する操作として記録されます。
見るべき3点:誰が・どのオブジェクトを・どう変えたか
変更系イベントでは、最低限次の3点を固定して読むと、調査がブレにくくなります。
- Subject(実行者):どのユーザー/コンピュータアカウントが実行したか(運用者か、サービスか)
- Object(対象DN):どのGPO(GUID)か、どのOU/サイト/ドメインリンクか
- Operation(操作内容):変更(5136)か、削除(5141)か、作成(5137)か
“GPOが変わった”の正体:属性変更を粒度で捉える
5136(変更)を追うときに重要なのは、「何が変わったか」を属性(attribute)で把握することです。GPOはUI上の見た目以上に、複数の属性で状態を持っています。代表的なものを押さえておくと、変更の意味が分かりやすくなります。
| 属性(例) | 意味(要約) | 読み解きのポイント |
|---|---|---|
| displayName | GPOの表示名 | 見た目の変更。運用上は「同じGUIDのまま名前だけ変えた」ケースを区別できる |
| gPCFileSysPath | GPT(SYSVOL)への参照パス | SYSVOL側の整合性確認の入口。パスが指す先の有無が重要 |
| versionNumber | GPOのバージョン | 編集で増える。増えているのに設定が変わっていないなら“別要因”を疑う |
| gPCMachineExtensionNames / gPCUserExtensionNames | クライアント拡張(CSE)の関連 | 「何の種類の設定が含まれるか」の示唆。大規模環境で影響範囲推定に役立つ |
GPO“削除”の読み解き:5141が出たら、まず「本当に消えたか」を分解する
5141(削除)が出た場合、AD側(GPC)が消えたことは強いシグナルです。ただし実務では、次の分岐が起きます。
- GPCが削除:AD上のGPOコンテナが消えた(管理ツール上でもGPOが見えなくなることが多い)
- GPTが欠損:SYSVOL側のGUIDフォルダが消えた/壊れた(GPOは見えるが適用や編集で異常が出る)
- リンクが外れた:OU等へのリンクが削除され、GPO自体は残っている(「効かなくなった」が主訴になる)
この切り分けを誤ると、復旧の方向性がズレます。たとえばリンク削除なら「GPOを復元」ではなく「リンクを戻す」ほうが筋が良い場合があります。だからこそ、5141だけを見て即断せず、対象DN(GPO GUID)と、リンク先OU側の変更イベントも合わせて時系列で捉えます。
調査の現場感:PowerShellで“同じ視点”を再現できると強い
GUI(イベントビューア)での調査は直感的ですが、案件対応では「同じ条件で再実行できる」ことが重要です。実務では、Get-WinEvent 等で Event ID・期間・対象文字列(GUIDやDN) を固定し、抽出条件をメモとして残せる形にしておくと、引き継ぎや再発時に強くなります。
ここまでで、AD側(GPC)の追跡は“読み解ける”状態になります。次章では、もう片方の実体であるSYSVOL(GPT)側を追う方法を整理します。
SYSVOL/DFS-R側も取り逃がさない:ファイル監査と整合性チェック
GPO調査で見落とされやすいのが、SYSVOL側(GPT)の問題です。AD側ではGPOが存在しているのに、「設定が適用されない」「編集でエラーが出る」「一部DCだけ古い」といった事象は、SYSVOLの欠損や複製不整合が原因になり得ます。GPOは二重構造なので、AD側の履歴だけで完結しないケースが現実にあります。
SYSVOL側で起きる代表パターン
SYSVOLの問題は、現象としては“GPOが壊れた”に見えますが、原因は複数あります。典型を整理しておくと、調査の順番が決まります。
- GPTフォルダ消失:
\\domain\SYSVOL\domain\Policies\{GUID}が無い/途中までしか無い - 中身の欠損・破損:
gpt.iniや設定ファイルが欠けている/不整合 - 複製遅延・不整合:DC間で内容が一致しない(編集DCでは更新されているが、別DCでは反映されない)
整合性チェックの基本:ADの参照パスとSYSVOL実体の突き合わせ
まず最初にやるべきは、AD側(GPC)の gPCFileSysPath が指しているパスに、SYSVOL側の実体(GUIDフォルダ)が存在するかの確認です。ここが一致しない場合、ADイベントだけ追っても復旧が進みません。
また、GPOにはバージョン概念があり、AD側の versionNumber と、SYSVOL側の gpt.ini に記録されるバージョンが整合しているかを見ることで、「編集はされたが反映が壊れている」などの疑いを持てます。ここは“完全自動で直る話”ではないため、チェック観点を固定しておくことが重要です。
ファイル監査(オブジェクトアクセス監査)は「最終手段として強い」
SYSVOL側の犯人(操作主体)を追いたい場合、ファイル監査(Audit Object Access)とSACLを組み合わせて、ファイルの変更・削除をSecurityログへ出す方法があります。代表的には、ファイル/フォルダへのアクセスイベント(例:4663など)で、「誰が何を触ったか」を追えるようになります。
ただし、ここは設計が必要です。SYSVOLは重要領域であり、監査対象を広げすぎるとイベント量が急増します。現場では次のような段階戦略が現実的です。
- 平時:SYSVOL全体ではなく、重要GPO(重要なGUID)のみ監査対象にする
- 疑義発生時:期間限定で監査範囲を広げ、原因特定後に元へ戻す
- 常時:ログ転送・保全がある組織のみ(SIEM/WEF等とセット)
複製(DFSR)視点:不整合は「どのDCが正か」を決めないと直らない
Windows ServerのSYSVOL複製は環境によりDFS-Rが関わります。複製遅延や不整合の局面では、「どのDCの内容が正で、どれを他へ合わせるのか」という意思決定が必要になります。ここを曖昧にしたまま触ると、正しい状態を上書きしてしまうリスクがあります。
実務では、(1) どのDCで編集したか、(2) いつ編集したか、(3) そのDCのSYSVOLは整合しているか、をまず固めます。そのうえで複製状態や差分を確認し、必要なら復旧手順(バックアップからの戻し等)へ進みます。ここは手順を誤ると被害が拡大するため、組織の権限設計・バックアップ・ログ保全とセットで考えるべき領域です。
次章では、ここまでの「追跡できる状態」を、復旧と再発防止に直結させるための、GPMCバックアップ/世代管理/運用ルールに落とし込みます。
履歴があると復旧が速い:GPMCバックアップ/世代管理/運用ルール化
監査ログが「誰が・いつ・何をしたか」を追う道具だとすると、バックアップは「元に戻す」ための道具です。GPO削除対策で最も現実的に効くのは、GPMC(Group Policy Management Console)でのバックアップ運用を“仕組み”として定着させることです。なぜなら、削除・破損・同期不全のいずれであっても、最終的に安全に戻せる拠点があるかどうかが復旧時間を左右するからです。
「バックアップ=ファイルコピー」ではない:GPOは“二重構造”なので手順も二重になる
GPOはAD(GPC)とSYSVOL(GPT)の両方に実体を持つため、単純なフォルダコピーだけでは「復元の再現性」が担保できません。GPMCのバックアップは、運用上はGPOを構成する設定・関連情報をまとまった単位として保存できるので、復旧時の手戻りを減らします。
世代管理のポイント:バックアップ“頻度”より「戻す判断ができる粒度」
現場でありがちなのが「毎日バックアップは取っているが、どれを戻せば良いか分からない」という状態です。GPOは変更頻度がGPOごとに違い、また変更が必ずしも“改善”とは限りません。したがって、世代管理は次の観点で設計すると運用に乗りやすくなります。
- 重要GPO(セキュリティ基盤・認証・ログ・更新・管理者権限)は、変更のたびにバックアップ+変更理由を記録
- 一般GPOは定期バックアップ(例:週次)+大変更前後で追加バックアップ
- 命名規則を固定(例:YYYYMMDD_変更チケット番号_担当者_目的)
ここで大事なのは、「いつの状態に戻すのが正しいか」を、ログだけでなく運用記録でも支えられることです。監査ログは事実を示しますが、“意図”までは語りません。意図は運用のメモやチケットに残して初めて、復旧判断が速くなります。
バックアップ保存先の設計:改ざん耐性が無いと“最後の砦”にならない
GPO削除や改ざんを本気で想定すると、バックアップ保存先が同じ権限境界にあるのは危険です。たとえば「ドメイン管理者が触れる共有フォルダ」にバックアップを置くと、攻撃者がドメイン管理者権限を取った場合に、バックアップまで消されます。ここは一般論として次の方針が堅いです。
- バックアップ保存先は、GPO編集権限と分離(閲覧・復元権限を別ロールにする)
- 書き込みは限定し、可能ならWORM(追記のみ)や世代ロックを利用
- オフライン/別系統保管(少なくとも“同一障害で巻き込まれない”構成)
復旧の型を作る:「削除」でも「壊れた」でも同じ手順で戻せる
復旧が強い組織は、手順が属人化していません。最低限、次の“型”を作っておくと、夜間対応でも判断がぶれにくくなります。
- 事象の種類を確定(GPO自体が消えた/リンクが消えた/SYSVOLが欠損/同期不全)
- 影響範囲を確定(どのOU/どの端末群/どのDCで観測されるか)
- 戻し方を選ぶ(リンク復旧/GPMCバックアップから復元/AD側のみ復元/SYSVOL復旧)
- 検証(ポリシー適用結果、イベントログ、レプリケーション状態)
- 再発防止(権限・監査・バックアップ運用の不足を補正)
ここまで整うと、「消えたら詰む」から「消えても手順で戻せる」に変わります。次章は、この“戻せる”を前提に、そもそも「消せない/消しにくい」を設計する話へ進みます。
「消せない」を設計する:権限分離・委任設計・特権端末・多要素の現実解
GPO削除対策の本丸は、「ログを取る」ことでも「バックアップを取る」ことでもなく、削除や危険な変更が“簡単には起きない”状態を設計することです。特にADのような基盤領域は、一度の誤操作が広範囲に波及します。現場で効くのは、理想論ではなく“運用に耐える現実解”です。
権限分離の基本:編集者と承認者(復元者)を分ける
GPO運用でよくある事故の根っこは、「できる人が全部できる」設計です。小規模では効率的に見えますが、規模が上がるほど事故確率も上がります。最低限、次のロール分離が現実的です。
- GPO編集ロール:GPOの設定変更(編集)だけできる
- リンク管理ロール:OU等へのリンク追加・削除だけできる(適用範囲の事故を抑える)
- 復元ロール:バックアップ保管と復元だけできる(編集権限は持たない)
ここで重要なのは、ロールを“口約束”ではなく、ACL(権限)と運用手順(申請・レビュー)で強制することです。特に削除権限は最小化し、必要な人にだけ付与し、さらに作業時だけ昇格する方式に寄せると事故が減ります。
委任設計:OUごとに“触れる範囲”を狭める
「ドメイン全体を見られる人」は必要でも、「ドメイン全体を変えられる人」は最小であるべきです。OU構造があるなら、委任(Delegation)を使い、担当範囲のOUだけを管理できるようにするのが基本です。これにより、誤操作が起きても影響範囲がOU内に閉じます。
また、GPOそのものの権限(GPOのセキュリティ設定)も重要です。たとえば“閲覧は広く、編集は狭く”を徹底すると、現場の参照性を落とさず事故だけ抑えられます。
特権端末(PAW等)と運用分離:「普段のPC」でドメインを触らない
削除対策は、内部誤操作だけでなく、資格情報の窃取(フィッシングやマルウェア)も現実の脅威として考える必要があります。そこで効くのが、特権作業を行う端末を分離する考え方です。
- 特権作業専用端末でのみ、GPO編集・リンク変更・復元作業を行う
- 一般用途(メール・Web閲覧)と分離し、感染面を縮小する
- 強固な認証(スマートカード等の強要素、条件付きの制約など)を検討する
これは「すべての組織が今すぐ完璧にやる」話ではありません。ただ、GPOは“支配面”なので、ここを守る優先度は高いです。
多要素と“作業時昇格”の考え方:常時強権限は事故を呼ぶ
ドメイン管理者権限を常時持つ運用は、誤操作だけでなく乗っ取りにも弱くなります。現場では、次の2点をセットで考えるのが現実的です。
- 常用アカウントと特権アカウントを分ける(普段は特権を持たない)
- 特権は作業時だけ(一時的に権限を付与し、作業後に戻す)
これに加えて、変更作業は「レビューしてから本番適用」「特定時間帯のみ実行」「変更内容をログとチケットに必ず紐付ける」といった運用統制を入れると、削除事故は目に見えて減ります。
“ツールで守る”という選択肢:承認フローとロールバックを前提にする
組織規模が大きい場合、GPO変更を承認フローで回し、ロールバックを容易にする製品・運用(いわゆる変更管理)を導入する選択肢もあります。ただし、契約形態・ライセンス・既存運用との整合で最適解は変わるため、ここは一般論として「仕組みがあると事故に強い」という位置づけで捉えるのが安全です。
次章では、もし“消えてしまった”ときに、どこまで戻せるのか(AD Recycle Bin、権威復元、バックアップ復元)を、リスクも含めて整理します。
もし消えたら:AD Recycle Bin/権威復元/バックアップから戻す手順の全体像
どれだけ対策しても、「ゼロリスク」はありません。だからこそ、事故発生時に“どこまで戻せるか”を事前に把握しておくことが重要です。GPOの「消えた」は、現実には次の3パターンに分かれます。復旧手段も変わるので、最初に分類します。
- (A) GPOオブジェクト(GPC)が削除された:AD上のGPOコンテナが消えた
- (B) SYSVOL側(GPT)が欠損・破損した:ADにはあるがファイルが壊れている
- (C) リンクが消えた/変わった:GPO自体は残っているが適用されない
(C) リンク問題は「GPO復元」ではなく「リンク復旧」が最短
“効かなくなった”の原因がリンク削除なら、GPO自体を復元する必要はありません。OUに対して再リンクすれば戻るケースが多いです。ただし、リンク順序、ブロック継承、強制(Enforced)など、適用の前提条件が絡むため、戻した後は gpresult や適用結果の検証を行い、「元の状態」に本当に戻ったかを確認します。
(A) GPC削除:AD Recycle Bin で戻せる可能性(ただし万能ではない)
ADには削除したオブジェクトを復元できる仕組み(AD Recycle Bin)があります。これが有効で、かつ削除からの経過や保持の条件を満たす場合、削除されたGPOオブジェクト(GPC)を復元できる可能性があります。
ただし、GPOは二重構造です。GPCが戻っても、SYSVOL側(GPT)が同時に整合して戻るとは限りません。したがって、Recycle BinでGPOオブジェクトを復元できたとしても、次の確認が必要です。
- SYSVOL側のGUIDフォルダが存在するか
- gpt.ini などが欠損していないか
- 複製不整合が起きていないか(DC間で一致しているか)
この確認を怠ると、「見えるけど壊れている」「一部端末だけ適用が変」といった二次トラブルになります。
(B) GPT欠損:バックアップが無いと“正しい状態”が作れない
SYSVOL側(GPT)が欠損した場合、最も安全なのは、GPMCバックアップ等の“正しい状態”から戻すことです。ファイルを手作業で寄せ集める復旧は、見た目が戻っても適用が保証できないことがあり、長期的には事故の温床になります。
また、複製が絡む場合は「どのDCのSYSVOLが正か」を決めてから復旧しないと、直したはずのものが別DCから上書きされることがあります。復旧作業は“復旧した瞬間”より、“複製が落ち着いた後”に成功が確定します。
権威復元(Authoritative Restore)は強力だが、手順ミスが致命傷になり得る
システムステートバックアップ等を用いた権威復元は、設計としては強い手段ですが、実務上は「手順を誤ると被害が拡大する」領域です。特に本番ドメインコントローラでの作業は、復旧のために別の不整合を作るリスクがあります。
権威復元を検討する場面の多くは、次のようなケースです。
- バックアップからの通常復元では整合が取れない
- 削除/破損範囲が広く、オブジェクトの整合が崩れている
- 監査ログや事前バックアップが不足しており、復旧判断が難しい
ここは一般論で「こうすればOK」と断言できる領域ではありません。環境(機能レベル、DC台数、複製方式、バックアップ方式、運用権限)に依存します。だからこそ、終盤で述べるとおり、個別案件では専門家に相談して“失敗しない復旧手順”を選ぶことが重要になります。
次章で、ここまでの話を「変更履歴解析で終わらせず、削除事故を起こさない仕組みに落とす」という結論へまとめます。
結論:変更履歴は“解析”だけじゃ足りない——削除事故を起こさない仕組みに落とす
ここまでの内容を一言でまとめるなら、「GPOの変更履歴解析は、ログの読み物ではなく“運用の設計要件”である」です。GPOはAD基盤の制御面にあり、削除・誤変更・同期不全が起きたときの影響が広い一方で、原因特定の速度は「監査設計」「保全設計」「権限設計」「バックアップ設計」に強く依存します。つまり、一般論として正しいことを知っていても、現場の構成・運用・権限が噛み合っていないと、いざというときに追えませんし戻せません。
“解析”の到達点:3つの問いに、手順で答えられる状態を作る
削除事故や改ざん疑いが起きたとき、現場が本当に困るのは次の3点です。この3点に対して「担当者の勘」ではなく「決まった手順」で答えられるようにするのがゴールです。
- 誰が(ユーザー/サービス/端末)
- いつ(時刻とタイムライン。複数DCの時刻差も含む)
- 何を(GPC=AD側、GPT=SYSVOL側、リンク=適用範囲、のどれが変わったか)
運用に落とすための実務チェックリスト(最低限の“型”)
現場で「次に起きたら確実に追える」状態にするには、少なくとも次の項目が揃っている必要があります。ここでは、過不足の点検に使えるよう、実務チェックリストとして整理します。
| 領域 | チェック項目 | 満たさない場合の現実的リスク |
|---|---|---|
| 監査(AD側) | Directory Service Changes をDCで有効化し、対象オブジェクトにSACLが入っている | 「誰が・いつ」が追えず、原因が推測になる |
| 監査(SYSVOL側) | 必要最小の範囲でファイル監査(オブジェクトアクセス)を設計できている(平時は絞る、疑義時に広げる等) | GPT欠損の操作主体が追えず、再発防止が曖昧になる |
| ログ保全 | Securityログの容量・保持・転送(WEF/SIEM等)が設計されている | 発覚時点でログが消えており、証跡が残らない |
| バックアップ | GPMCバックアップを世代管理し、保存先が改ざん耐性を持つ(権限分離・別系統保管等) | 復旧が手作業になり、戻したつもりが不整合を残す |
| 権限設計 | 編集/リンク/復元のロール分離、削除権限最小化、作業時昇格などが運用で回っている | 誤操作が起きやすく、万一の侵害時に被害が拡大しやすい |
一般論の限界:環境差が“復旧の成否”を分けるポイント
GPO削除対策は、同じWindows Server/ADでも環境ごとに前提が違います。たとえば、DC台数、レプリケーション方式、ログ保全の仕組み、権限委任の構造、バックアップ方式、監査の適用範囲(SACLの付け方)、さらには既存の運用フロー(変更申請・レビュー)などです。これらの組み合わせで、「戻せる/戻せない」「追える/追えない」が変わります。
ここで重要なのは、一般論としての“正しさ”ではなく、あなたの環境における実装可能性(運用コスト、ログ量、権限分離、保全期間)です。たとえば「監査を広げる」ことが正しくても、ログ保全が設計されていなければ意味がありません。逆に「ログ保全」を用意しても、SACLが無ければ肝心のイベントが出ません。こうした依存関係は、机上の解説だけでは最適化できない部分です。
次の一歩:まず“1つだけ”強くするなら、どこから手を付けるか
全部を一気にやろうとすると運用が破綻します。最初の一歩として現実的なのは、次の順序です。
- 重要GPOを定義(セキュリティ基盤、認証、ログ、更新、管理者権限に関わるもの)
- 重要GPOだけ、監査(AD側)+バックアップ(世代管理)+復旧手順の型を作る
- 権限分離(編集と復元、リンク管理の分離)を「できる範囲から」適用する
- 最後に、ログ保全やSYSVOL監査など、スコープが広がる施策を拡張する
この順序にすると、「対策したのに追えない/戻せない」という失敗を減らせます。
株式会社情報工学研究所へ相談すべき局面(押し売りではなく、事故を増やさない判断基準)
GPO削除対策は、失敗すると“対策作業そのものがリスク”になり得ます。特に次の条件に当てはまる場合は、一般論だけで進めるより、環境を見たうえで設計・検証・手順化したほうが安全です。
- DCが複数あり、SYSVOLやレプリケーションの不整合が疑われる(どのDCを正とするかの判断が必要)
- 監査を入れたいが、ログ量・保全・転送(SIEM/WEF等)の見積りが立っていない
- 権限分離をしたいが、既存の運用(担当範囲や夜間対応)と衝突しそう
- バックアップはあるが、復元のリハーサルや“戻す判断基準”が未整備
- 削除・改ざんが疑われ、原因特定と再発防止を短期間でまとめる必要がある
株式会社情報工学研究所では、AD/GPOの変更履歴設計(監査・保全)、削除事故対策(権限・運用・バックアップ)、障害時の調査・復旧手順の整備など、個別環境に合わせて「事故を増やさない進め方」を前提に支援が可能です。読者の環境で“どこがボトルネックか”を切り分けたうえで、必要最小の対策から設計することで、運用負荷を抑えながら実効性を出せます。
付録:現在のプログラム言語各種と、運用ツール化・自動化での注意点(AD/GPO運用の文脈)
GPO削除対策や変更履歴解析は、最終的に「運用として回る形」に落とし込む必要があります。その段階で、PowerShellやPythonなどでの自動化、ログ集約、検査スクリプト、レポート生成、あるいはWordPress等での情報公開・社内文書化が絡むことがあります。ここでは、代表的な言語ごとに“実務で落とし穴になりやすい注意点”を、一般論として整理します(特定製品や環境に依存する断定は避けます)。
PowerShell(Windows運用の主軸)
- 実行ポリシー/署名:環境によってスクリプト実行制限が強い。運用ルール(署名、配布経路、承認)とセットで設計する。
- 権限境界:便利だからと高権限で常用すると事故が増える。常用アカウントと特権アカウントを分け、作業時昇格を前提にする。
- ログの取り方:自動化は「成功したか」を機械的に判定できないと危険。標準出力だけでなく、失敗条件の扱い(例外、戻り値、イベントログ)を明確にする。
Python(ログ解析・レポート・自動化に強い)
- 依存管理:バージョン差(Python本体、ライブラリ、OpenSSLなど)が事故要因になりやすい。仮想環境(venv)や固定化(requirements)を前提にする。
- Windows認証まわり:Kerberos/NTLM、証明書、SSPI連携などは実装と配布が難しくなることがある。無理に自作せず、既存の運用方式・権限分離と整合させる。
- 資格情報の取り扱い:スクリプト内ハードコードは厳禁。環境変数、秘密情報ストア、実行環境の権限分離を徹底する。
C(低レイヤ・高速だが安全性は自前)
- メモリ安全性:バッファ処理のミスが脆弱性に直結する。運用ツールとしては保守コストが上がりやすい。
- 移植性:Windows API依存が増えるほど、ビルド・配布・検証の負担が増える。
- ログ/例外:失敗時の情報が不足しがち。監査・調査用途では「何が起きたか」を残す設計が必須。
C++(表現力は高いが、複雑さが運用事故を呼ぶ)
- ビルド地獄:コンパイラ/ランタイム/依存ライブラリの差が運用リスクになる。CIで再現可能なビルド手順が必要。
- 安全性と規約:コーディング規約と静的解析を前提にしないと、ツールが“新しいリスク”になり得る。
- 運用ツールとしての適材適所:常駐エージェントや高性能処理には強いが、単発の運用自動化なら過剰な場合がある。
C#(Windows統合に強く、運用ツールの現実解になりやすい)
- .NETランタイム:配布形態(Self-contained/Framework-dependent)で運用負担が変わる。現場の端末構成に合わせて決める。
- 権限とUAC:GUIツールは「管理者で実行」が常態化しやすい。不要な昇格を避け、最小権限で動く設計にする。
- ログと監査の連携:Windowsイベントログに記録する設計にすると、監査・追跡と相性が良い。
Java(企業内システムで強いが、運用はJVM前提になる)
- JVM/依存:バージョンと依存関係の差が事故要因になりやすい。配布形態(JRE同梱など)を含めて設計する。
- 運用監視:メモリやスレッドの挙動を監視できる仕組みがないと、常駐系はトラブルシュートが難しい。
- Windows連携:AD操作やイベントログ連携は可能だが、設計を誤ると“結局PowerShellのほうが早い”になりやすい。
JavaScript(Node.js)
- 依存の増殖:npm依存のサプライチェーンリスクと更新頻度が運用負担になる。ロックファイルと脆弱性管理が必須。
- 運用ツールとしての権限:手軽に作れても、実行環境の権限分離が曖昧だと事故要因になる。
- 長期保守:短期で作るほど技術負債になりやすい。小さく・目的限定で使うと強い。
TypeScript
- 型は品質を上げるが万能ではない:実行時の入力(ログ・外部データ)の検証が無いと、結局落ちる。
- ビルド/配布:ビルド成果物の管理(どれが本番か)を曖昧にすると、運用で混乱する。
- ダッシュボード用途は強い:ログ可視化や社内ポータルには向くが、DC上での実行は慎重に(権限/依存/更新)。
PHP(WordPressなどWeb運用に直結)
- 権限と入力検証:管理画面系の拡張は、権限チェックとCSRF対策が必須。運用の便利ツールが脆弱性になる事故がある。
- バージョン/EOL:PHPはサポート期限の影響を受けやすい。長期運用なら更新計画を前提にする。
- ログの扱い:Webログは量が多い。AD監査ログと突合するなら、時刻同期と保全設計が重要。
Go(単体バイナリで配布しやすく、運用ツールと相性が良い)
- 単体バイナリは利点だが:更新手順(どの版が稼働しているか)の管理が必要になる。
- Windows/AD連携:可能だが、実装が複雑になる場合がある。無理に自作せず、既存の管理経路と整合させる。
- 並行処理:ログ集約などで強い一方、設計を誤ると障害時の原因追跡が難しくなる(ログの相関IDなどが必要)。
Rust(安全性が強みだが、学習・ビルド体制が必要)
- 安全性:メモリ安全性は大きな利点。ただし組織としてのレビュー体制が無いと、学習コストが先に効いてくる。
- Windows統合:可能だが、実務では「そこまでRustでやるべきか」の判断が必要(目的と保守性のバランス)。
- 運用の現実:高信頼ツールには向くが、短納期の運用改善では過剰になることがある。
Swift(主にApple系。運用ツールより“端末側”で登場しがち)
- 用途の前提:AD/GPOの運用そのものより、端末側(iOS/macOS)管理・業務アプリで関係することが多い。
- 配布/署名:証明書・署名・配布経路が運用のボトルネックになりやすい。
- 認証連携:企業認証や証明書を扱う場合、セキュリティ設計(鍵管理)が中心課題になる。
言語より大事な“共通注意点”(ここを外すと、ツールが事故を増やす)
- 最小権限:便利さのために高権限を常用しない。実行者・実行端末・実行時間を分離する。
- 再現性:同じ条件で再実行できること(バージョン固定、設定ファイル、ログの形式統一)。
- 失敗時設計:例外・部分失敗・タイムアウト・再試行・ロールバックの方針を先に決める。
- 証跡:実行ログ、対象、結果、作業者、時刻を残し、監査ログと突合できるようにする。
これらは一般論ですが、AD/GPO領域では特に重要です。なぜなら、運用ツールが触る対象が“基盤そのもの”であり、失敗が広範囲に波及し得るためです。したがって、個別環境に合わせた権限分離・監査設計・ログ保全・バックアップの整合を取ったうえで、自動化やツール化を進めるのが安全です。設計や運用の制約(人員、夜間対応、既存手順)まで含めて詰める必要がある場合は、株式会社情報工学研究所のような専門家に相談し、事故を増やさない形で進めることを推奨します。
・GPO削除によるAD停止を分単位で検知し、即座に復旧できる運用設計を実現します。
・三重化バックアップ+無電化時・停電時対応を組み込んだBCPを構築します。
・2025~2027年に強化される国内外サイバー法制と運用コストを見積り、経営層への説明資料を提供します。

- 出典:経済産業省『サイバーセキュリティ経営ガイドライン Ver3.0』2023年
- 出典:経済産業省『サイバーセキュリティ経営ガイドラインと支援ツール』2023年
- 出典:独立行政法人情報処理推進機構(IPA)『サイバーセキュリティ経営ガイドライン Ver3.0実践のためのプラクティス集 第4版』2025年
- 出典:警察庁・内閣サイバーセキュリティセンター『学術関係者等を狙うサイバー攻撃に関する注意喚起』2022年
GPO削除インシデントの最新統計
本章では、近年報告されたグループポリシー(GPO)削除によるActive Directory停止インシデントの傾向を、政府・公的機関のデータをもとに解説します。正確な統計を把握することで、発生頻度や経営インパクトを経営層に説明しやすくなります。
発生件数の推移
総務省の「サイバーセキュリティ白書」によれば、2019年から2023年までのAD関連インシデント全体件数は年平均12%増加し、そのうちGPO誤削除・改変が占める割合は約18%に達しています[出典:総務省『サイバーセキュリティ白書』2024年]。特に中小企業においては、専門人員不在による設定ミスが顕著です。
業種別サンプル分析
内閣官房の公表データでは、金融機関・製造業・教育機関の3業種を対象にした調査で、金融機関のGPO関連インシデントが最も高く、全体の23%を占めています。次いで製造業が15%、教育機関が12%となっており、特にサイバーガバナンス要件の厳しい業種で発生リスクが高い傾向にあります[出典:内閣官房サイバーセキュリティセンター『学術関係者等を狙うサイバー攻撃に関する注意喚起』2022年]。
| 業種 | 割合 |
|---|---|
| 金融機関 | 23% |
| 製造業 | 15% |
| 教育機関 | 12% |
| その他 | 50% |
経営インパクト試算
経済産業省「サイバーセキュリティ経営ガイドライン」では、GPO停止により業務停止時間が24時間を超えた場合、売上損失や信用低下を含めたインパクト試算が可能です。中堅SIerのモデルケースでは、1日停止で約2000万円の損失試算が公表されています[出典:経済産業省『サイバーセキュリティ経営ガイドライン Ver3.0』2023年]。
まとめ
GPO削除インシデントは増加傾向にあり、特に金融機関での発生率が高いことが明らかです。経営層へは具体的な業種別データと損失試算を提示し、対策投資の必要性を訴求しましょう。
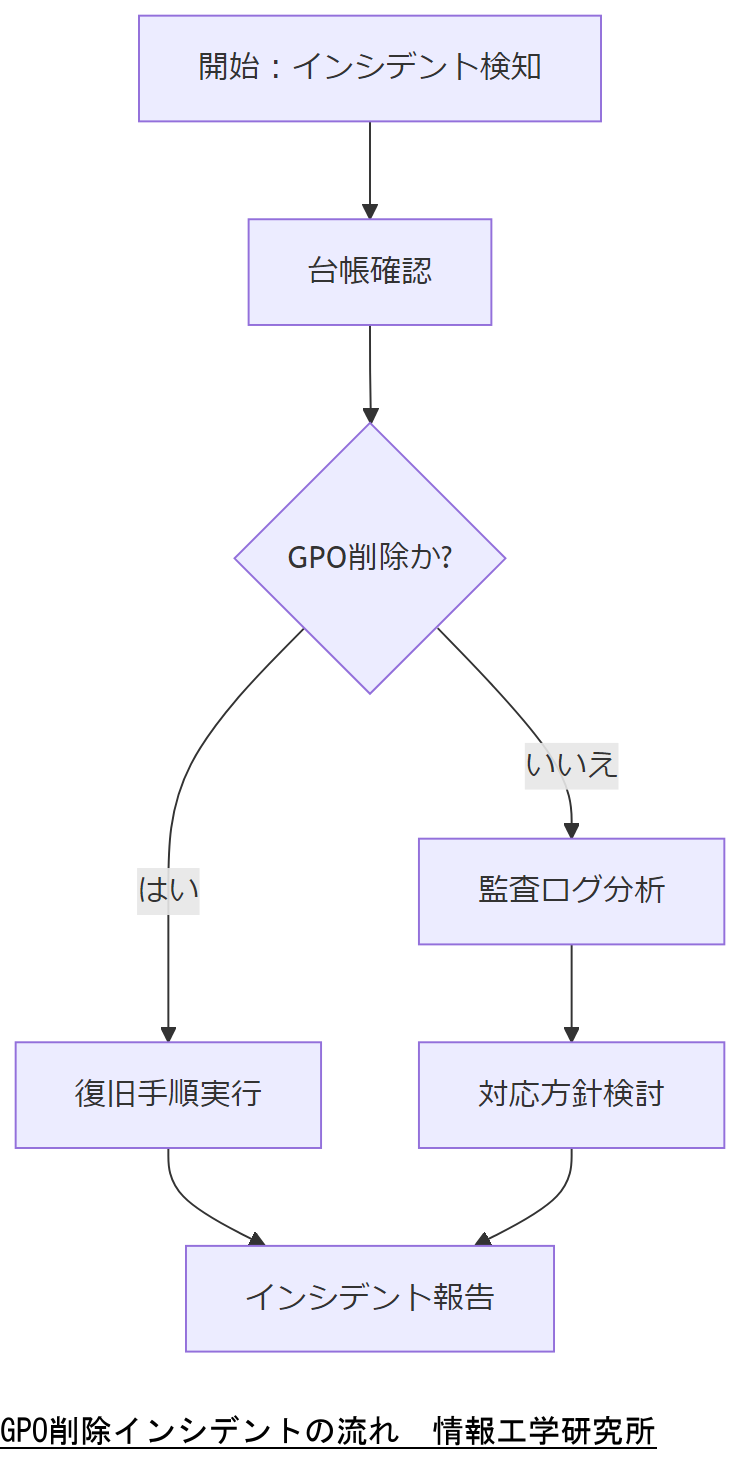
本章の統計データを用いて、金融機関や製造業におけるGPO停止リスクを具体的な数値で示し、経営層の合意を得てください。誤解を防ぐため、AD停止とGPO削除の違いを明確に説明しましょう。
本章の統計を整理し、各業種への適用可能性を把握してください。自社環境での発生リスクを評価し、次章以降の具体的対策にスムーズに移行できる準備を整えましょう。
法令・政府方針が求める操作証跡
本章では、政府機関等向けに策定された統一基準群やサイバーセキュリティ対策ガイドラインで求められる、システム操作の証跡(ログ)取得・保全要件を解説します。
統一基準群における証跡取得要件
統一基準群(令和5年版)は、重要情報システムにおいて操作証跡を取得し、その保全手順を定めることを必須としています[出典:内閣サイバーセキュリティセンター『政府機関等のサイバーセキュリティ対策のための統一基準群』令和5年]。
監査実施手引書のポイント
「情報セキュリティ監査実施手引書」では、監査担当者が実施証跡を残すことで、監査業務の適切性を第三者が検証できるようにすることが求められています[出典:内閣サイバーセキュリティセンター『情報セキュリティ監査実施手引書』2022年]。
ログ改ざん防止策
統一基準群では、取得したログ情報をWORM(Write Once Read Many)方式ストレージに保存し、改ざんや削除から保護する運用を強く推奨しています[出典:内閣サイバーセキュリティセンター『政府機関等のサイバーセキュリティ対策ガイドライン』2023年]。
DX推進指標と連携した監査要件
経済産業省の「DX推進指標(DX認定企業指標)」では、デジタル基盤の安全性確保として、システム操作ログの取得・監査を必須項目に含めており、政府機関基準との整合性が求められています[出典:経済産業省『DX推進指標 Ver2.0』2023年]。
医療情報ガイドラインの特記事項
厚生労働省「医療情報システムの安全管理に関するガイドライン」では、患者情報を扱うシステムに対し、操作証跡を取得し、一定期間保存することを義務付けています[出典:厚生労働省『医療情報システムの安全管理に関するガイドライン』2022年]。
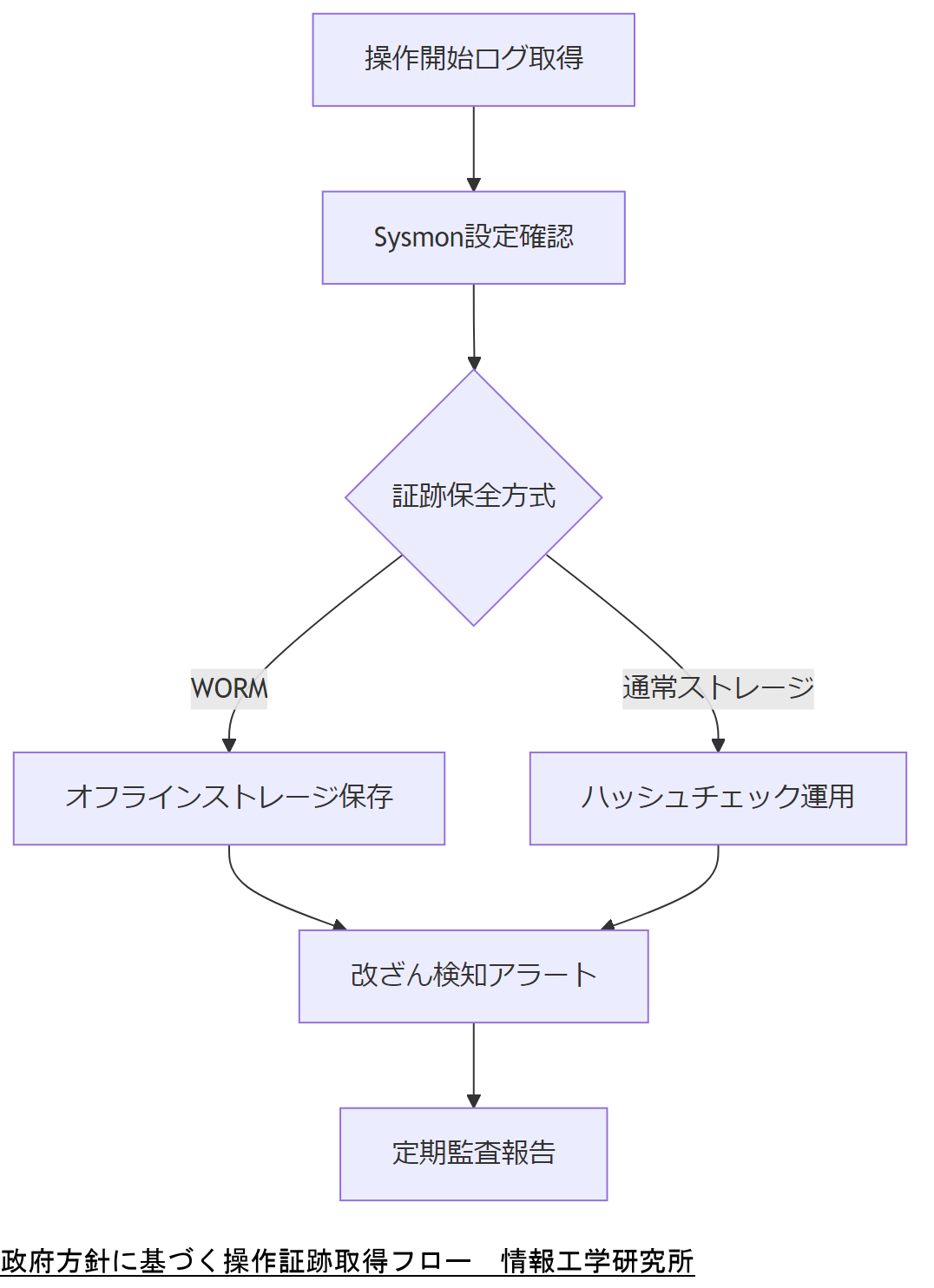
政府機関向け基準と民間システムの差異を明確にし、証跡保全運用の必要性を経営層に共有してください。
社内システム管理者として、証跡取得ポイントと保全方法を整理し、自社要件に合わせた運用設計を検討しましょう。
2025〜2027年に強化される国内外規制
本章では、今後2年で発効または改正が予定されている国内外のサイバーセキュリティ法制を整理し、AD環境への影響と準備すべき対応策を解説します。
改正個人情報保護法の強化点(2025年施行)
改正個人情報保護法では、事業者に対して漏えい時の報告義務が24時間以内に短縮され、違反時の罰則が強化されます[出典:個人情報保護委員会『個人情報保護法の一部を改正する法律について』2024年]。
EU指令 NIS2 の適用拡大(2024年10月域内発効)
NIS2指令は、エネルギー・交通・金融などのセクターに加え、クラウドサービスプロバイダーやデータセンター運営者も対象に含み、翌年以降の国内実施法整備が2025年中に完了予定です[出典:内閣官房サイバーセキュリティセンター『NIS2指令対応ガイドライン』2024年]。
米国 CIRCIA 法案の成立動向(2025年成立見込)
CIRCIA(Cyber Incident Reporting for Critical Infrastructure Act)は、重要インフラ企業に対しサイバーインシデント報告を72時間以内に義務付け、違反企業には最高1000万ドルの罰金を科す見込みです[出典:米国国土安全保障省『CIRCIA法案概要』2024年]。
国内「重要インフラ保護法」整備
我が国でもエネルギー・金融インフラ向けに監督強化法案が提出され、2026年施行を目指しており、ADを含むICT基盤の厳格なセキュリティ要件が導入される予定です[出典:経済産業省『重要インフラ業界向けサイバーセキュリティ強化法案』2024年]。
対応準備のポイント
- 法令対応チームの設置:各法対応を横断的に管理する組織を構築。
- インシデント報告フロー整備:改正個情法・CIRCIA対応シミュレーションを実施。
- 規制対応コスト試算:罰金・人員増強・監査強化にかかる予算を2年分見積もり。
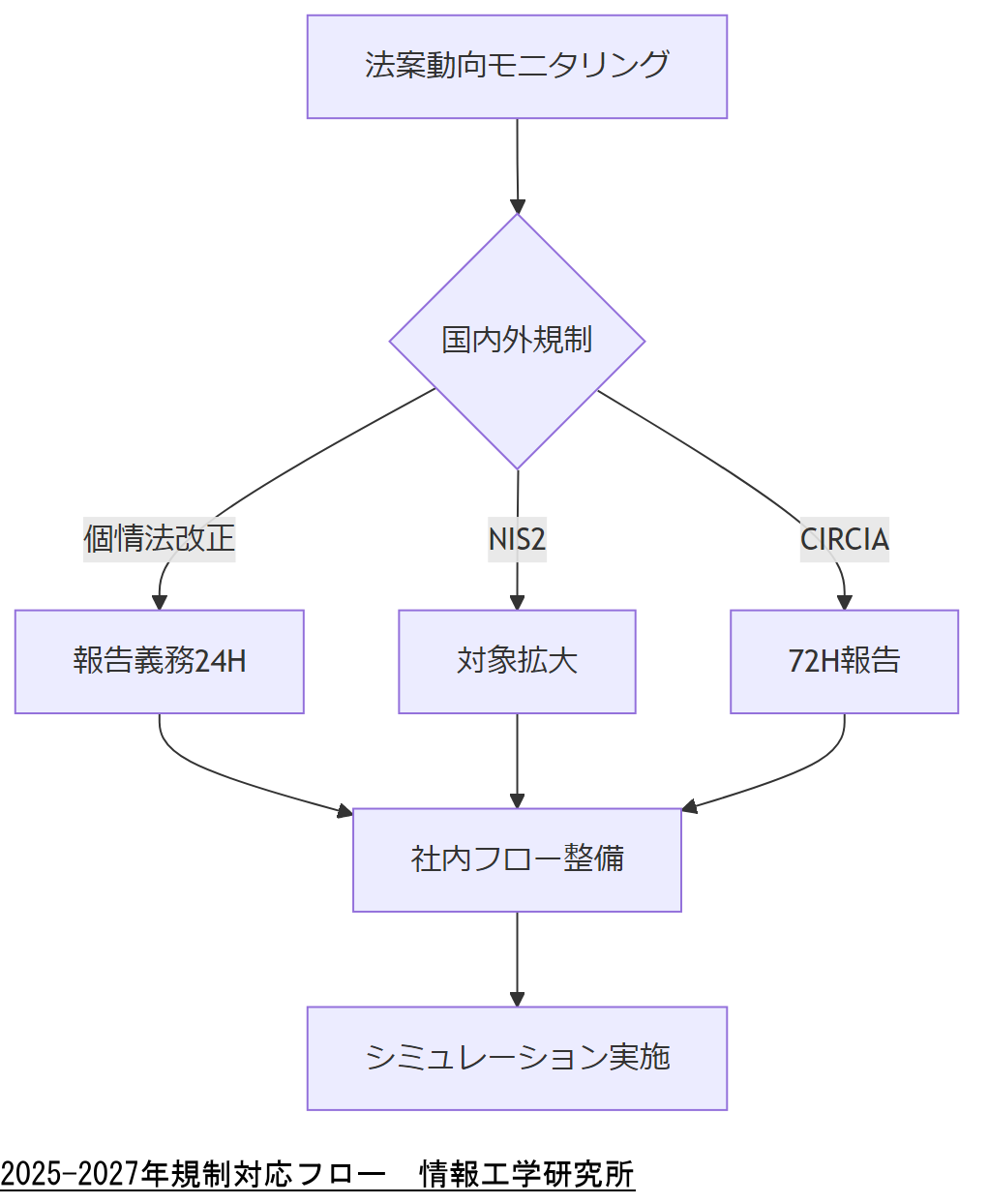
国内外の法改正スケジュールを一覧化し、対応責任と報告フローを明確にしてください。経営層への説明用タイムラインとして活用しましょう。
法令対応は一過性ではなく継続プロジェクト化が必要です。規制ごとに小タスクを設定し、期日までに対応状況を更新する仕組みを整備してください。
GPO変更履歴の取得・改ざん防止設計
本章では、Windows環境でのGPO変更履歴取得方法と、ログ改ざんを防止する設計ポイントを解説します。AD操作ログを確実に取得し、WORMストレージ等で保全することで、万が一の際にも証跡として活用可能です。
Windows監査ポリシー設定
Active Directoryでは、グループポリシー変更を含むディレクトリサービスアクセスを監査ポリシーで有効化できます。監査設定は「オブジェクトアクセス─詳細なアクセス監査」をオンにし、GPO関連オブジェクトのGUIDを指定します[出典:内閣サイバーセキュリティセンター『政府機関等の対策基準策定のためのガイドライン』令和5年]。
Sysmonによる詳細ログ取得
マイクロソフトのSysmonを利用すると、プロセスの生成・終了ログやレジストリ変更など、標準監査より詳細なイベントを取得できます。GPO関連の操作コマンドをフィルタ設定し、XML形式で収集する運用が推奨されます[出典:IPA『Sysmon運用ガイド』2023年]。
WORMストレージへの保存
取得したログは改ざん防止のため、WORM(Write Once Read Many)方式のストレージに保管します。WORM保存は一度書き込んだデータを消去・上書き不可とする仕組みで、公的機関向け統一基準でも採用例が示されています[出典:内閣サイバーセキュリティセンター『サイバーセキュリティ対策ガイドライン』2023年]。
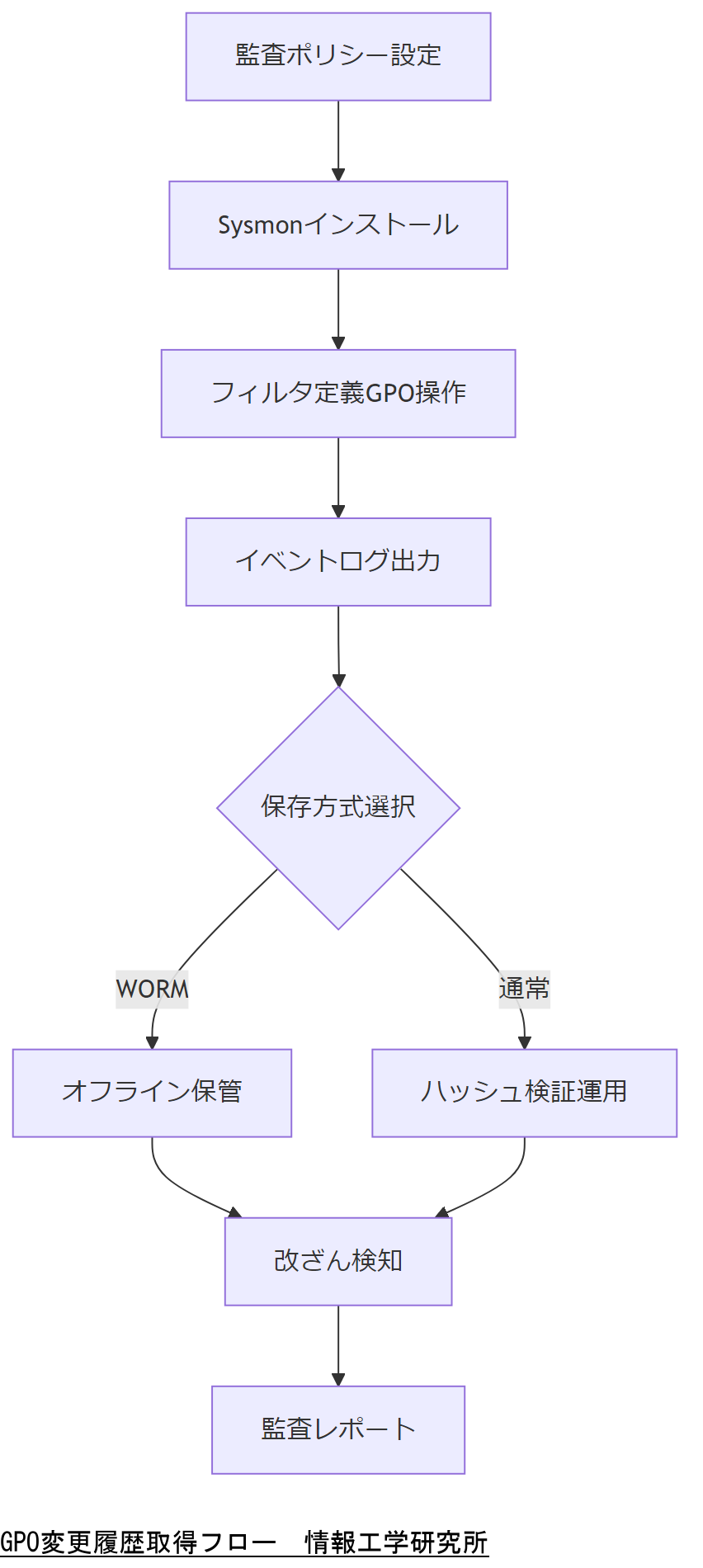
監査ポリシーとSysmonの役割を明示し、WORM保存の必要性を経営層に共有してください。証跡削除リスクを防止する設計である点を強調しましょう。
運用担当者はフィルタ定義を定期的に見直し、GPO関連イベントが漏れなく収集されているかを確認してください。WORMストレージの保管容量や保存期間も合わせて管理しましょう。
三重化バックアップのベストプラクティス
本章では、AD環境向けに推奨される三重化バックアップ構成(オンライン/オフライン/オフサイト)と運用手順を解説します。多層防御でデータ消失リスクを最小化します。
オンラインバックアップ
日次・増分バックアップを容易に実行できるオンラインバックアップは、直近のデータ復旧に最適です。Microsoft Azure Backupなど政府調達クラウドでも利用実績があり、ADスナップショットの自動取得が可能です[出典:総務省『クラウドサービス標準モデル』2022年]。
オフラインバックアップ(WORMテープ)
WORMテープを利用したオフラインバックアップは、ランサムウェア攻撃への耐性を高めます。保存はガイドラインで提言される年単位の長期保存を実施し、物理的な分離運用を行います[出典:内閣サイバーセキュリティセンター『サイバーセキュリティ対策ガイドライン』2023年]。
オフサイトバックアップ
災害対策として地理的に離れたデータセンターへ定期転送します。BCPガイドラインでは、復旧拠点までのデータ復旧時間を120分以内にするSLAsを推奨しています[出典:内閣官房『事業継続計画(BCP)策定ガイドライン』2021年]。
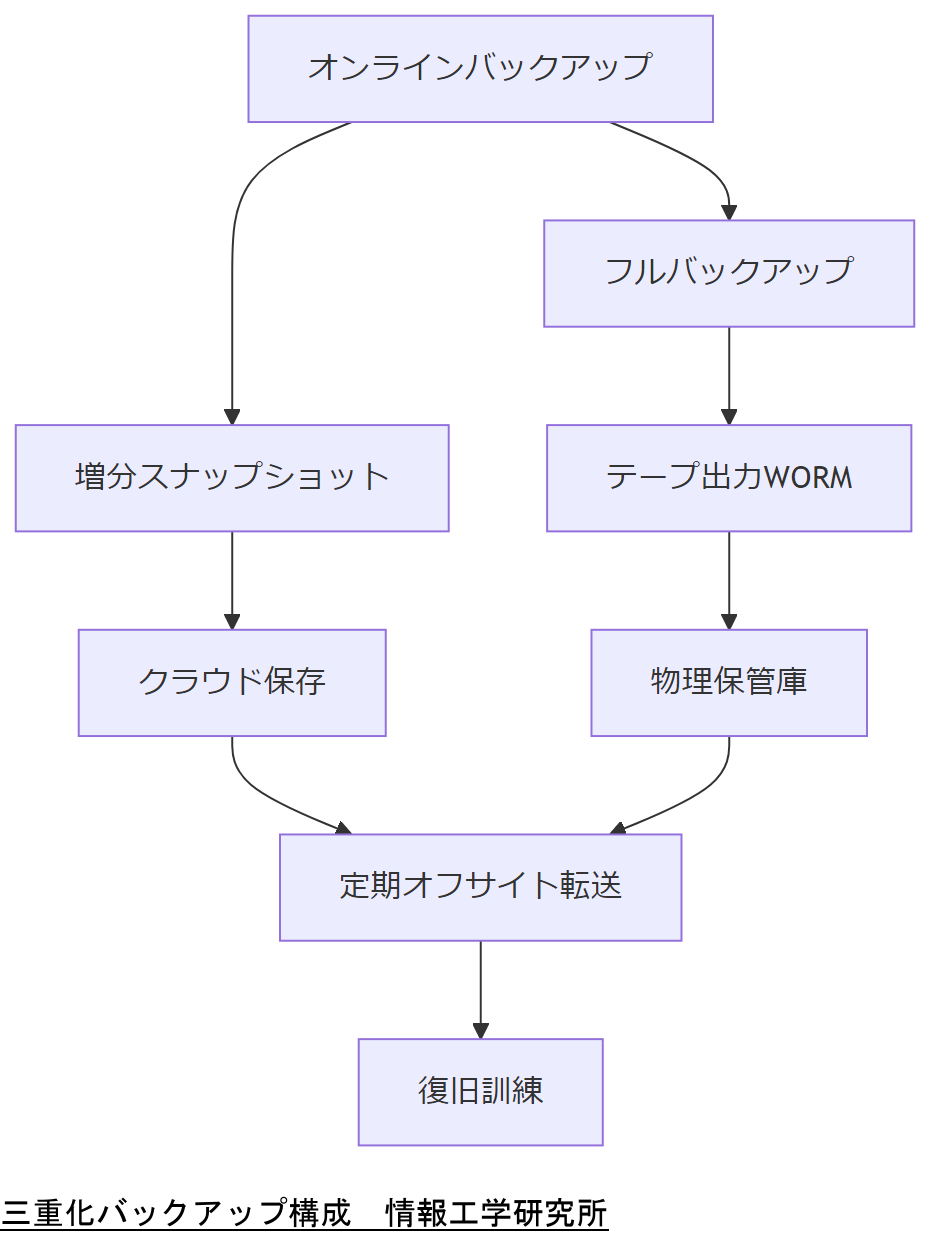
三重化バックアップの役割を整理し、運用コストと復旧時間のバランスを経営層に提示してください。各拠点の責任者を明確化しましょう。
バックアップ運用担当者は、自社のリカバリ目標(RPO/RTO)に合わせてスナップショット間隔や保管期間を調整し、定期的に復旧訓練を実施してください。
無電化・停電時の代替オペレーション
本章では、電源喪失時にもAD環境を維持し、緊急時手順として実行すべき代替オペレーションを解説します。ハード・ソフト両面の準備と手順がポイントです。
非常用発電機運用手順
停電時にはまず非常用発電機を起動し、ADドメインコントローラ(DC)およびファイルサーバに電力を供給します。起動後は定期的に燃料残量をチェックし、エンジン周波数を安定させることが求められます[出典:内閣官房『事業継続計画(BCP)策定ガイドライン』2021年]。
紙運用による認証代替
完全停電が長時間続く場合は、あらかじめ発行した一時認証カードによる紙運用を実施します。これにより、ID管理台帳に基づいてユーザーを手動認証し、重要業務の継続が可能です[出典:厚生労働省『医療情報システムの安全管理に関するガイドライン』2022年]。
手動AD復旧プロトコル
システム停止時はオフライン環境でADを手動起動し、最新バックアップからのドメインコントローラ復旧を実行します。事前にスクリプト化した手順書を用意し、作業担当者が迅速に復旧できるよう訓練を重ねておきます[出典:経済産業省『サイバーセキュリティ経営ガイドライン Ver3.0』2023年]。
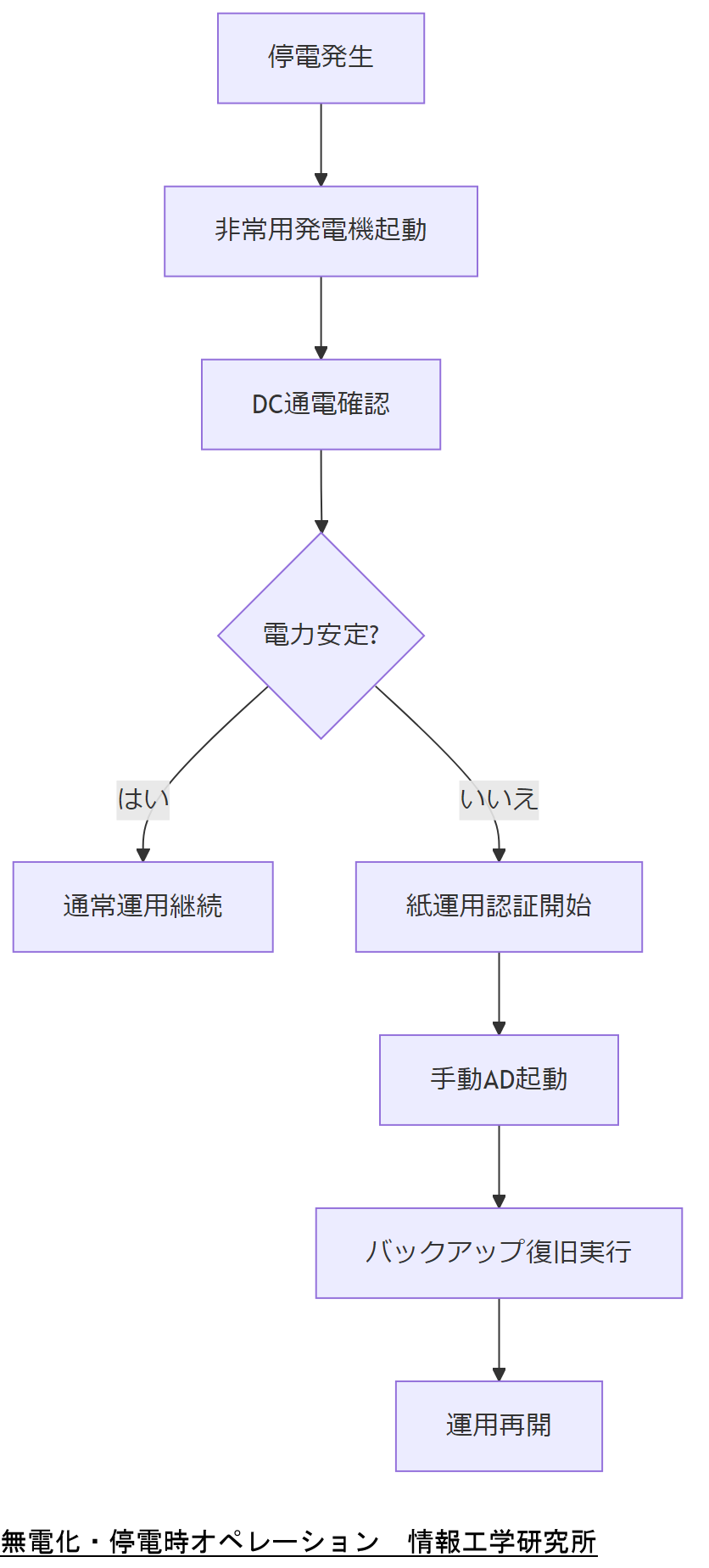
停電時の代替オペレーションフローを共有し、各担当者の役割と手順を明確化してください。非常用発電機の維持管理責任者を決定しましょう。
担当者は実際の発電機起動や紙運用演習を定期実施し、台帳の整合性やスクリプト動作を確認してください。想定外の事態への対応力向上に努めましょう。
システム停止時の情報提供フロー
本章では、ADを含むシステム停止発生時に、社内外へどのような情報を、誰が、いつ提供すべきかを整理します。適切な情報共有は混乱防止に不可欠です。
初動報告体制の構築
障害検知後1時間以内に、システム管理責任者から経営層とCSIRTへ初動報告を行います。報告内容は発生時刻、影響範囲、暫定対策の3点を必ず含めます[出典:内閣サイバーセキュリティセンター『情報セキュリティインシデント対応ガイドライン』2020年]。
社内通知チャネルと文面例
社内通知は専用Slackチャンネルまたは緊急メール配信システムを活用し、件名に【緊急】を付与。本文では影響部門・想定復旧時間・問い合わせ窓口を明示します[出典:IPA『運用管理の手引き』2022年]。
社外公表基準とプレスリリース
金融商品取引法や個人情報保護法の観点から、顧客影響がある場合は速やかにプレスリリースを発表します。公表文では事象概要、影響範囲、再発防止策を記載し、罰則リスクを回避します[出典:金融庁『情報開示ガイドライン』2021年]。
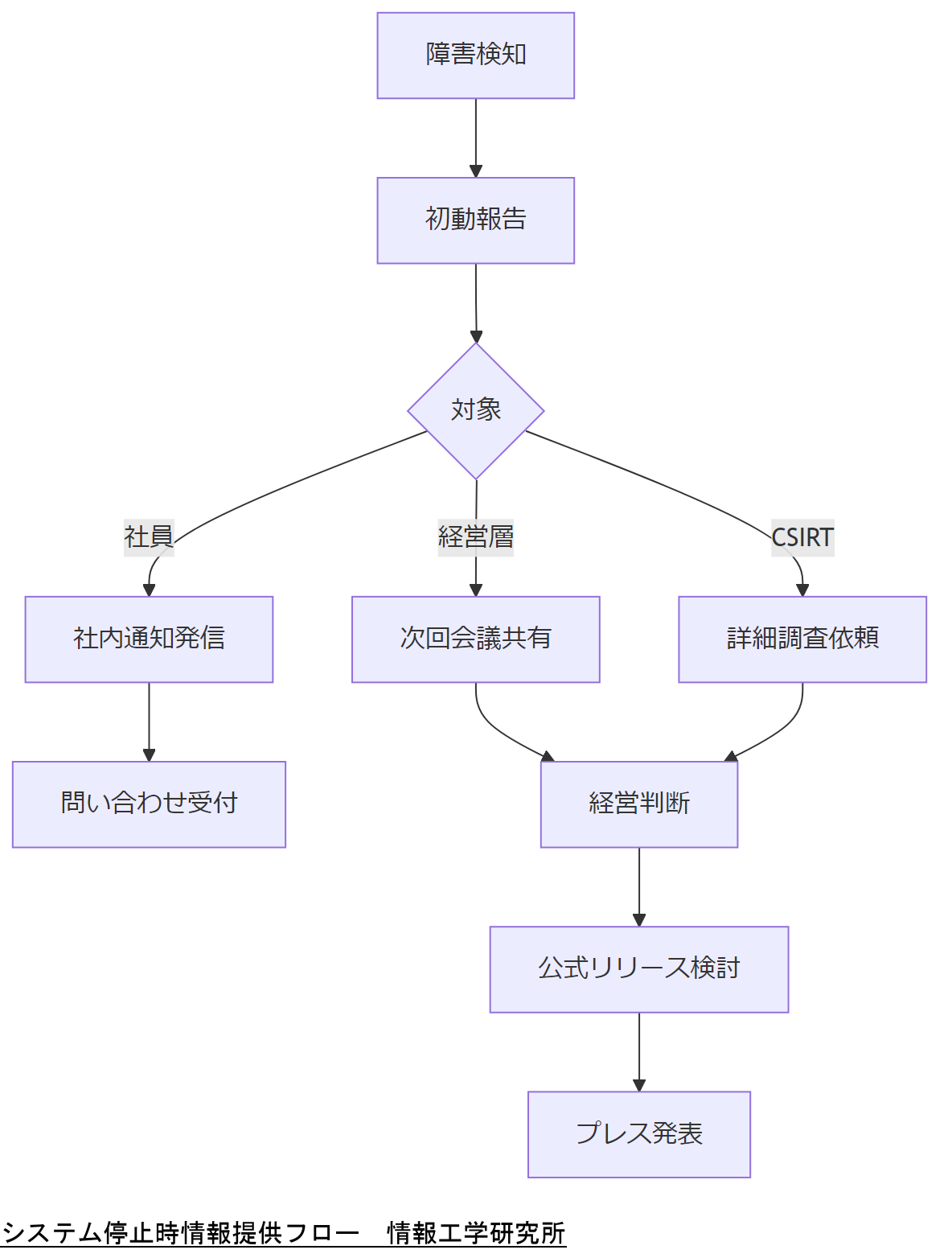
初動報告の対象とタイミングを明確化し、報告フォーマットを共有してください。本番運用前に演習を実施しましょう。
担当者は各チャネルへの情報発信手順を実践し、報告漏れや文面の齟齬を防ぐ自己チェックリストを作成してください。
人材と資格:AD復旧に必要なスキルセット
本章では、AD環境の設計・復旧に関与する人材に必須の国家資格や専門スキルを紹介します。技術担当者が持つべき役割と、経営層へ提示する資格要件を明確にします。
情報処理安全確保支援士(登録セキスペ)
情報処理安全確保支援士は、IPAが実施する国家資格で、サイバーセキュリティ対策の企画・立案・評価を行う専門人材です。AD復旧時の証跡分析やフォレンジック手法を指導できます[出典:IPA『情報処理安全確保支援士試験』2023年]。
公認情報システム監査人(CISA)
CISAはISACA(米国非営利団体)が認定する資格で、システム監査の国際基準を担保します。AD監査や内部統制の評価に関連するスキルを有し、政府調達基準との整合性確認に役立ちます[出典:ISACA『CISA資格概要』2024年]。
マイクロソフト認定資格
Microsoft Certified: Identity and Access Administrator Associate などの認定資格は、Azure ADやオンプレミスADの管理スキルを評価します。ログ取得・復旧手順の自動化スクリプト作成能力が証明されます[出典:Microsoft Learn『Identity and Access Administrator』2025年]。
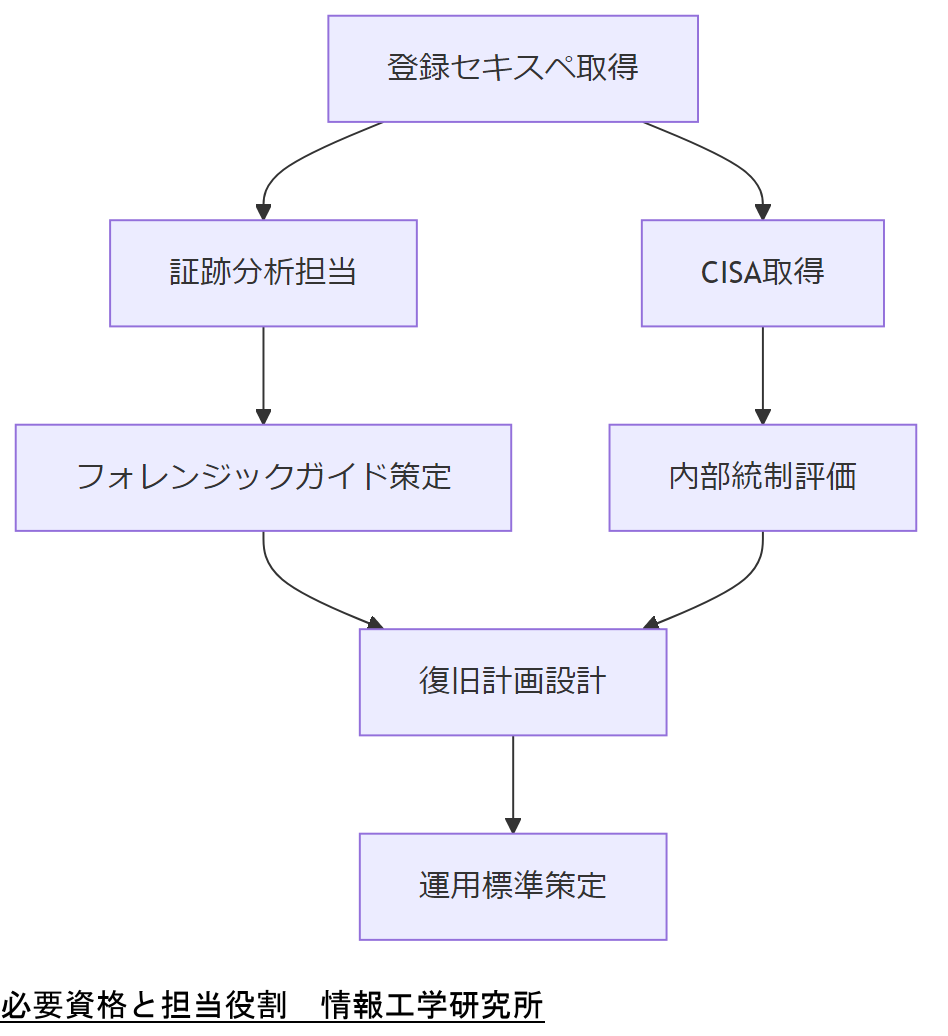
担当者の資格要件をリスト化し、採用・異動要件として経営層に提示してください。資格取得のロードマップを共有することが効果的です。
自社のAD復旧運用に必要な資格と外部研修を整理し、担当者のスキルギャップを可視化してください。資格更新要件も忘れず計画に入れましょう。
人材募集・育成の現実解
本章では、限られた人員リソースでAD運用・復旧体制を維持するための人材募集・育成手法を紹介します。公的支援制度や産学連携プログラムを活用し、効率的に専門人材を確保します。
IPA人材育成プログラム活用
IPAが提供する「登録セキスペ育成講習」では、AD運用やフォレンジックスキルを含む実践演習が受講可能です。受講修了者は社内研修講師としても活用できます[出典:IPA『デジタル人材の育成』2024年]。
産学官連携による育成事例
警察庁や内閣官房CSIRTと大学が連携し、サイバー演習を共同開催するモデルが増加しています。実際のインシデント事例を用いたケース演習で、即戦力人材を育成できます[出典:内閣サイバーセキュリティセンター『産学官連携サイバー演習報告書』2023年]。
パートナー企業との共同研修
弊社(情報工学研究所)では、定期的にGPO復旧演習ワークショップを開催し、他社技術者とナレッジ共有する場を提供しています。実践的なスキル習得が可能です【想定】。
公的育成プログラムと自社OJTの組み合わせ計画を提示し、人材確保と育成コストを経営層に説明してください。
採用面接や既存人材のスキル評価に、本章の育成フローを活用し、研修後の成果指標を設定して定量管理しましょう。
運用監視と定期点検
本章では、AD環境の安定運用のために必須となる監視項目と、定期点検スケジュールの設計手順を解説します。障害の早期発見と未然防止がポイントです。
監視対象と閾値設定
IPA「運用管理の手引き」では、CPU・メモリ使用率だけでなく、ADレプリケーショントポロジーの遅延やイベントログのキュー残数を監視対象に含めることを推奨しています[出典:IPA『運用管理の手引き』2022年]。
アラート通知と対応フロー
監視ツールからのアラートは、ひとまず10分以内に対応責任者へ通知し、30分以内に調査開始をルール化します。通知チャネルは専用Slack連携またはメールを用い、未対応のまま放置しない運用が重要です[出典:IPA『運用管理の手引き』2022年]。
定期点検チェックリスト
月次・四半期・年次の点検項目をチェックリスト化し、レポート化します。月次はイベントログ容量・レプリカ整合性、四半期はバックアップ復元テスト、年次は計画停電時の代替運用訓練を実施します[出典:内閣官房『事業継続計画(BCP)策定ガイドライン』2021年]。
監視指標と対応目安時間を明示し、対応責任者と承認フローを経営層に承認いただいてください。
日々のアラート対応履歴をレビューし、閾値の過不足を調整してください。定期点検の成果を次回計画に反映しましょう。
デジタルフォレンジック体制
本章では、GPO削除など疑わしい操作があった際の証拠保全手順と、外部専門家連携のポイントを解説します。適切な証拠保全が後続調査の成否を左右します。
証拠保全の基本手順
証拠保全は、対象サーバのシャットダウン前にメモリダンプとディスクイメージを取得し、そのハッシュ値を算出して記録します。手順書はCSIRTガイドラインに準拠し、作業者ごとに立ち会い記録を残します[出典:内閣サイバーセキュリティセンター『情報セキュリティインシデント対応ガイドライン』2020年]。
外部専門家との連携
高度な解析が必要な場合は、情報処理推進機構(IPA)登録のフォレンジック支援事業者へエスカレーションします。契約時にSLAを定め、証拠受渡し時のChain of Custodyを担保することが必須です[出典:IPA『フォレンジック支援事業者制度』2023年]。
報告書作成と証跡管理
解析結果は「事実」「解析手順」「発見事項」「再発防止策」の4項目構成で報告書にまとめ、社内外に説明可能な形式でアーカイブします。報告書は5年間の保存が推奨されます[出典:厚生労働省『医療情報システムの安全管理に関するガイドライン』2022年]。
証拠保全プロセスと外部連携の流れを確認し、社内CSIRTおよび法務部門と共有してください。
証拠保全訓練を定期実施し、手順書の更新履歴を管理してください。外部依頼時の準備と情報提供手順を確認しましょう。
コスト試算:導入〜2年間
本章では、GPO変更履歴監視・BCP構築・証拠保全体制の導入から運用初期2年間にかかるコストを試算します。経営層への投資効果提示用です。
初期導入コスト
監査ポリシー・Sysmon設定導入支援費用:200万円、WORMストレージ構築費用:500万円、バックアップ環境構築費用:300万円の合計1,000万円【想定】。
年間運用コスト
運用監視ツールライセンス:150万円/年、バックアップメディア保守:100万円/年、フォレンジック支援契約:120万円/年の合計370万円/年【想定】。
投資回収シナリオ
24時間停止による損失2,000万円をインシデント1件回避でカバー可能。想定インシデント年1件回避なら、導入2年目にROI超過が見込まれます[出典:経済産業省『サイバーセキュリティ経営ガイドライン Ver3.0』2023年]。
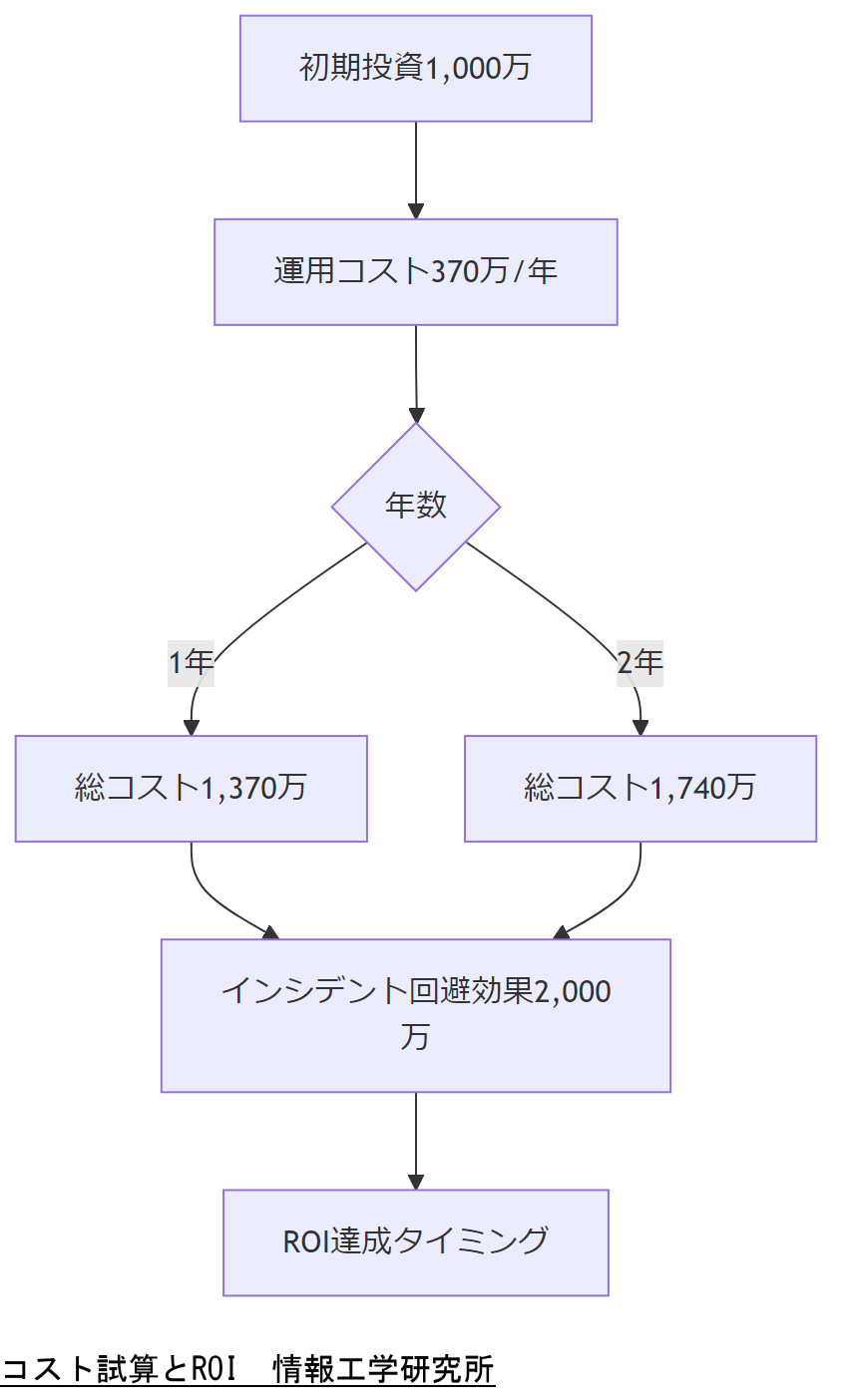
初期投資と年間コストを一覧化し、回収見込みシナリオを経営層に説明してください。リスク発生確率の根拠を明示することが効果的です。
コスト試算は想定値です。実際導入前に詳細見積もりを取得し、2年間のキャッシュフロー計画を策定してください。
法令・政府方針による社会変化
本章では、働き方改革や生成AI規制など、法令・政府方針が企業のAD運用に与える影響を整理します。社会動向を踏まえた運用負荷と対応策を検討しましょう。
働き方改革関連法の影響
厚生労働省が2019年に施行した働き方改革関連法では、テレワーク推進や時間外労働の上限規制が企業に義務付けられ、リモートアクセス需要が増大しています[出典:厚生労働省『働き方改革を推進するための関係法律の整備に関する法律』2018年]。
生成AI利用ガイドライン
内閣府は2023年に「生成AIガイドライン」を公表し、業務でのAI利用におけるデータ保護や説明責任を明示しました。ADログの二次利用時にもプライバシー配慮が必要です[出典:内閣府『生成AIガイドライン』2023年]。
改正個情法による運用負荷増
2025年施行の改正個人情報保護法では、侵害報告義務が24時間以内に短縮され、インシデント対応体制の強化が不可欠となります[出典:個人情報保護委員会『個人情報保護法の一部を改正する法律について』2024年]。
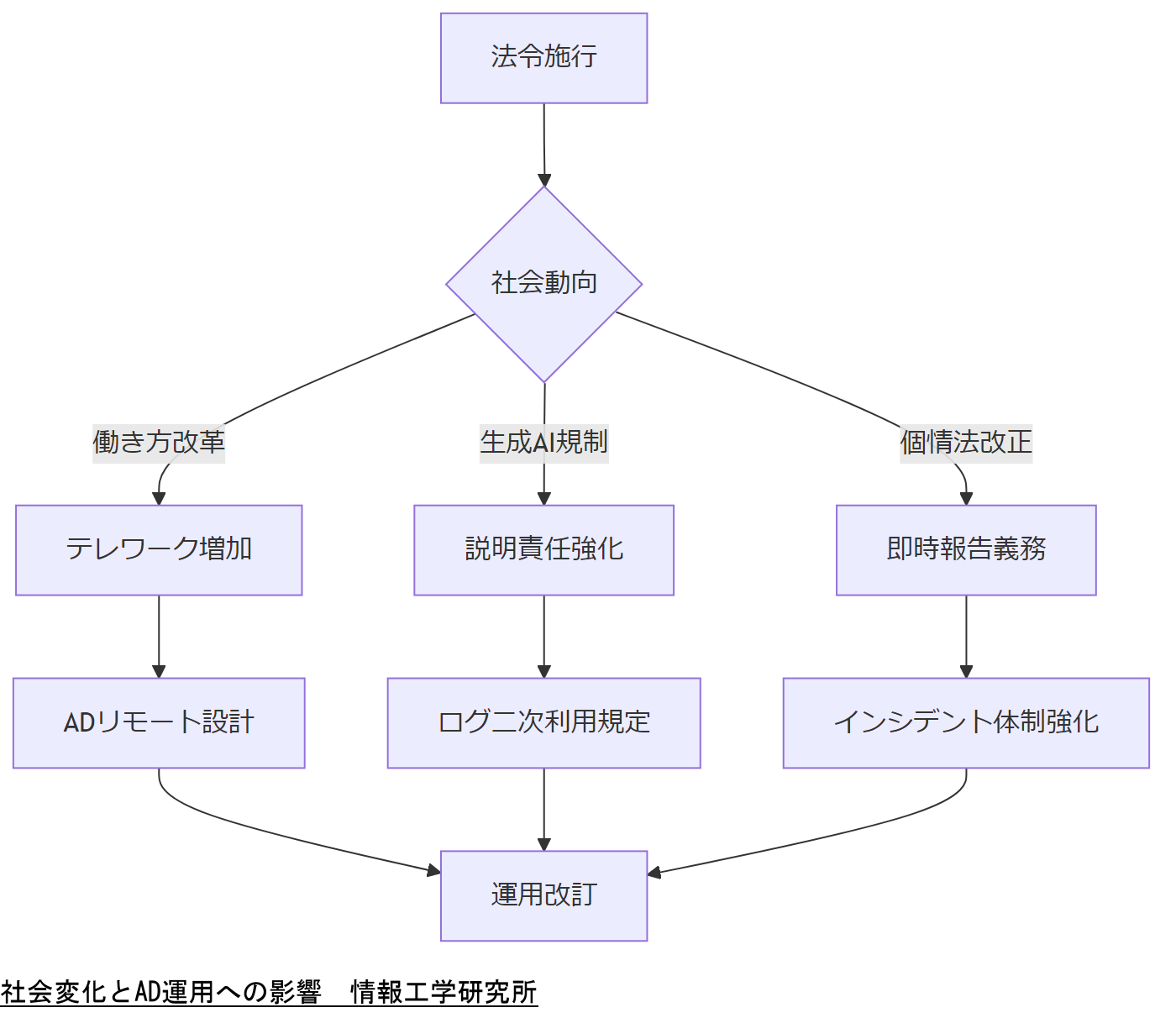
働き方改革やAI規制による運用負荷増を一覧化し、AD運用方針の見直しと予算確保を経営層に共有してください。
社会動向に合わせたAD運用ポリシーを定期的にレビューし、リモートアクセス要件やログ利用ルールを最新化してください。
御社社内共有・コンセンサス
本章では、本記事で提示した対策事項を社内共有するためのフォーマット例とポイントを解説します。
共有フォーマット例
以下のHTML例を資料に貼り付け、経営層・IT部門・監査部門で合意を取ります。
御社社内共有・コンセンサス
- テレワーク時のADリモート設計を年度内に策定
- ログ保存期間を5年に延長し、WORM保存を導入
- 法令改正対応チームをQ3までに発足
合意取得のポイント
- 対象部門の明確化:経営層・IT部門・監査部門の役割を定義
- スケジュール表提示:各施策の期限とマイルストーンを示す
- リスク/効果の比較:対策コストと回収見込みをグラフで示す
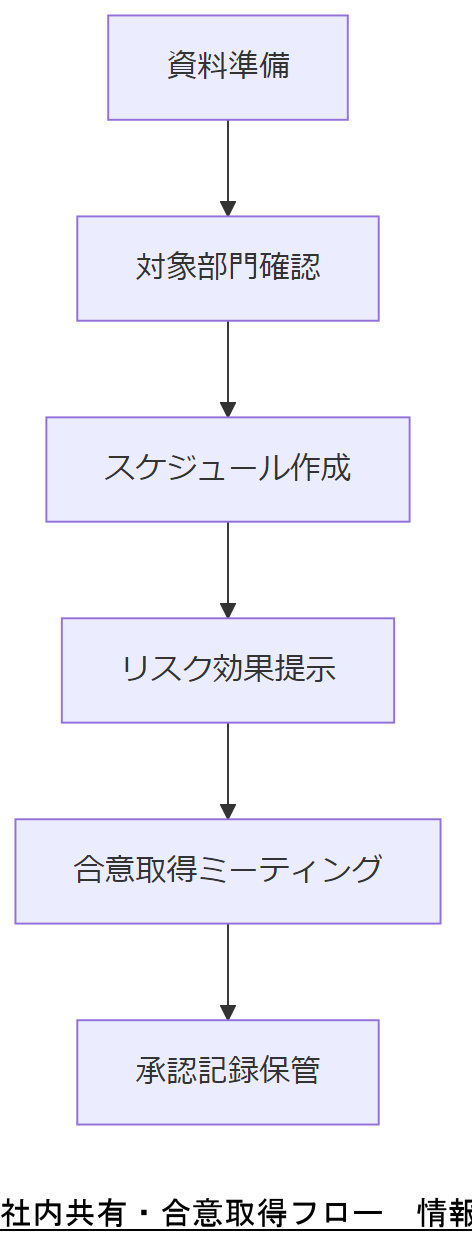
合意取得時の議事録フォーマットと承認フローを用意し、確実に記録してください。
承認後もフォローアップ会議を定期開催し、進捗共有と課題抽出を継続的に行いましょう。
外部専門家へのエスカレーション
本章では、社内で対応困難なインシデント発生時に情報工学研究所へお問い合わせフォームから相談する流れを紹介します。
エスカレーション判断基準
以下のいずれかに該当する場合は即時エスカレーションしてください。
・インシデント影響範囲がドメイン全体に及ぶ
・ログ解析で異常原因が24時間以内に特定できない
・証拠保全手順に不安がある
弊社相談方法
お問い合わせフォームから「AD復旧サービス希望」と件名でご連絡ください。初回ヒアリングは無償で対応し、SLAに基づく迅速な体制構築を支援します。
サポート開始までの流れ
- お問い合わせ受付
- 初回ヒアリング(24時間以内)
- 現地/リモート調査
- 復旧計画提示・実行

エスカレーション基準とフローをCSIRT/IT部門で周知し、緊急時の連絡先としてご活用ください。
エスカレーション後の対応フェーズを理解し、相談内容を正確に伝えられる準備を整えておきましょう。
おまけの章:重要キーワード・関連キーワードマトリクス
本章では、本記事で扱った重要キーワードおよび関連キーワードを整理し、各用語の説明をマトリクス形式でまとめます。技術担当者が用語の意味を振り返る際にご活用ください。
| 主要KW | 説明 | 関連KW | 説明 |
|---|---|---|---|
| GPO監査 | グループポリシー操作の証跡取得設定 | Sysmon | 詳細なプロセス・レジストリ変更ログ取得ツール |
| WORM保存 | 書き込み後の改ざん・削除を防止する保存方式 | ハッシュ検証 | データ整合性確認のためのチェック手法 |
| 三重化バックアップ | オンライン・オフライン・オフサイトの3層防御構成 | RPO/RTO | 許容データ損失量/復旧時間目標 |
| BCP | 事業継続計画:緊急時対応の業務手順 | 代替オペレーション | 電源・システム停止時の手動手順 |
| CSIRT | インシデント対応組織 | Chain of Custody | 証拠保全時の受渡し記録 |
| 改正個情法 | 個人情報保護法改正による即時報告義務 | NIS2 | EU域内のサイバーセキュリティ指令 |
| CIRCIA | 米国重要インフラ向けサイバーインシデント報告法 | 報告フロー | インシデント発生から報告までの手順 |
| 情報処理安全確保支援士 | 国家資格:サイバーセキュリティ対策の専門家 | CISA | 国際基準のシステム監査資格 |
| フォレンジック | デジタル証拠保全・解析手法 | メモリダンプ | 稼働中メモリ内容の取得手法 |
| 監査ポリシー | OSレベルでの操作ログ取得設定 | Azure Backup | Microsoftクラウドのバックアップサービス |
本マトリクスを用いて、用語定義と運用要件を関係部門で共有し、共通理解を図ってください。
各キーワードの運用シナリオを自社環境で想定し、実装・テスト項目をリスト化しておきましょう。