もくじ
- 失ったのはリソースだけじゃない:削除・改変の「なぜ」を後から説明できないつらさ
- 「誰が」「いつ」「何を変えた」を埋めるピースとしての AWS Config
- 設定項目の差分が“証拠”になる:コンソール操作とIaCの境界で起きる事故
- 記録は残っているのに戻せない:リソース削除後にハマる典型パターン
- タイムラインを作る:Configuration history と CloudTrail をどう噛み合わせるか
- 復元の土台はスナップショット:Configuration recorder と delivery の落とし穴
- 「あるはずのログがない」を潰す:記録対象・頻度・集約先の設計チェック
- 状態復元の実務:特定→差分抽出→IaC化→再適用の手順を型にする
- 本番で効く運用に落とす:Config Rules / Conformance Pack で“再発しない仕組み”へ
- 帰結:AWS Config は“復旧ツール”ではなく、復元を可能にする設計のログ基盤である
【注意】 本番環境でクラウドリソースの設定削除・改変が疑われるときは、自己判断で復元作業(設定を戻す/作り直す/IaCを当て直す)を急がず、まずログ保全と影響範囲の切り分けを優先してください。環境ごとに AWS Config / CloudTrail / IaC の前提が異なり、誤った操作で証跡や復元経路を失うことがあります。個別案件の判断は株式会社情報工学研究所のような専門事業者に相談し、被害最小化(ダメージコントロール)を図ってください。
失ったのはリソースだけじゃない:削除・改変の「なぜ」を後から説明できないつらさ
本番で「Security Group が消えた」「ALB のリスナーが変わってる」「S3 のポリシーが書き換わった」。現場はまず復旧に走りたいのに、同時に「説明責任」が刺さってきます。
「誰がやったの?」「いつから?」「同じこと起きる?」——この3つに答えられないと、対策も意思決定も止まる。しかも、レガシーな運用ほど“止めずに直す”圧が強いので、手当たり次第に触ってしまいがちです。
でも、ここで雑に触ると、あとから“何が起きたか”を再現できなくなります。復元のスピードと、証跡(ログ)の価値はトレードオフになりやすい。だから最初の30秒は「直す」より「場を整える(ノイズカット)」に寄せるのが安全です。
冒頭30秒:症状 → 取るべき行動(被害最小化の初動ガイド)
| 症状(よくある第一報) | まず取るべき行動(安全な初動) |
|---|---|
| リソースが消えた/見えない | 変更を止める(デプロイ停止・自動修復の一時停止・運用バッチ停止)。影響範囲を“読む”前に作り直さない。 |
| 設定が勝手に変わった | 当該リソースの履歴を確保(AWS Config の履歴・スナップショット、CloudTrail のイベント)。現状をメモ(ARN、タグ、関連先)。 |
| 権限まわりが怪しい(IAM/KMS/AssumeRole) | 追加の権限変更を止める(緊急の一時制限)。ログ保全のためのアクセス権だけ確保し、破壊的操作を避ける。 |
| 複数アカウント/複数リージョンで波及 | “点”で直さず“面”で把握(Organizations / 集約ログ / Config Aggregator 等)。復元方針を先に揃える。 |
今すぐ相談すべき条件(依頼判断の目安)
- 影響が本番・顧客影響に直結し、復元の手順を誤ると二次障害が起きそう
- CloudTrail / AWS Config の設定が不明、または途中から有効化された疑いがある
- IaC と手動変更が混在し、何が正なのか決めきれない(ドリフトが常態化)
- IAM / KMS / ネットワーク境界(VPC/SG/NACL)など、誤ると復元が難しい領域が絡む
判断に迷うなら、まずは状況整理からで構いません。問い合わせフォーム:https://jouhou.main.jp/?page_id=26983
電話:0120-838-831
この章のまとめ:最初にやるべきは“直す”ではなく、変更の暴走を止めてログと現状を確保することです。ここで「被害最小化(ダメージコントロール)」に寄せられるかが、あとで復元も説明もラクになります。
「誰が」「いつ」「何を変えた」を埋めるピースとしての AWS Config
現場の本音はこうです。
「CloudTrail あるし、誰が叩いたかは分かるでしょ?」
——ところが、CloudTrail は“操作(API コール)”のログであって、“その結果どんな状態になったか”を直接持っているわけではありません。操作の意図や前後の差分を読むには、別の視点が要ります。
AWS Config は、サポートされる AWS リソースの“設定状態(コンフィグレーション)”を記録し、変更履歴として追えるようにするサービスです。言い換えると、CloudTrail が「行為のタイムライン」なら、AWS Config は「状態のタイムライン」です。削除・改変の復元を考えるとき、状態のタイムラインがあるかないかで難易度が跳ね上がります。
AWS Config が得意なこと/苦手なこと
得意なことは、特定リソースの過去の設定(例:セキュリティグループのルール、S3 バケットの設定、IAM ロールの構成など)を「いつの時点でどうだったか」として追えることです。さらに、構成のスナップショットを配信しておけば、当時の状態を“材料”として取り出せます。
一方で、AWS Config は万能なバックアップではありません。Config の記録対象外の設定や、サービス特有の動的な状態(例:実行中のセッション、メモリ上の状態、アプリ内部のデータ)まで戻せるわけではない。あくまで「クラウドリソースの構成」を中心に扱う前提です。
「なるほど」と腹落ちする分担:CloudTrail と Config の噛み合わせ
| 観点 | CloudTrail | AWS Config |
|---|---|---|
| 主語 | 誰が/どの認証情報で/どの API を叩いたか | リソースが“どういう設定”だったか |
| 強み | 操作の証跡、原因追跡、権限の悪用検知 | 差分把握、復元の材料、コンプライアンス評価 |
| 復元での役割 | 「いつ誰が消したか/変えたか」を確定する | 「消える前にどう設定されていたか」を再現する |
つまり、復元に必要なのは「犯人探し」だけではなく「元の姿の特定」です。元の姿が曖昧なまま“それっぽく作り直す”と、後で別の系が壊れたり、セキュリティ境界が穴埋めできていなかったりします。ここで AWS Config が効きます。
この章のまとめ:AWS Config は“復旧ツール”というより、復元を可能にする「状態のログ基盤」です。CloudTrail と組み合わせてはじめて、説明と復元が一本の線になります。
設定項目の差分が“証拠”になる:コンソール操作とIaCの境界で起きる事故
現場の事故は、だいたい境界で起きます。
「Terraform で管理してるはず」なのに、緊急対応でコンソールから直して、そのまま放置。
「一時的に戻すだけ」のつもりが、次の apply で上書きされて再発。
そしてある日、削除・改変が連鎖して“元の姿”が分からなくなる。
ここで必要なのは「どの時点で IaC の定義と現実がズレたか」を追えることです。AWS Config の変更履歴があると、少なくとも“現実の状態がいつ変わったか”は追跡できます。そこに CloudTrail のイベント(どの API が呼ばれたか)を重ねると、「誰が、なぜ、どこで」まで掘れます。
差分の読み方:まず“重要な軸”だけを見る
変更履歴は情報量が多いので、最初から全部を精読すると疲弊します。復元と再発防止の観点では、まず次の軸から見ると整理しやすいです。
- 境界(Ingress/Egress):SG / NACL / ALB リスナー / WAF / バケットポリシーなど
- 認可(AssumeRole/KMS/IAM):ロールの信頼ポリシー、権限ポリシー、KMS キーポリシーなど
- 到達性(Route/DNS):ルートテーブル、VPC エンドポイント、DNS 設定など
- データ面(暗号化/公開設定):S3 公開ブロック、暗号化設定、ログバケットの保護など
「証拠」としてのログを壊さないために
差分が“証拠”になるということは、裏を返すと「ログが欠けると、復元の根拠が失われる」ということです。AWS Config が有効になっていなかった期間があれば、その期間は“状態のタイムライン”が空白になります。だからこそ、平時からの設計が効きますし、事故直後は「ログ設定まで手当たり次第に触らない」ことが重要です。
具体的には、ログの集約先(S3 など)や権限を慌てて変えると、参照できなくなったり、保全の整合性に疑義が出たりします。復元を急ぐほど、こういう二次事故が起きやすい。
この章のまとめ:コンソール操作と IaC の境界で起きる事故は、差分が追えるかどうかで“収束”の速度が変わります。AWS Config の履歴は、復元の材料であり、説明の根拠でもあります。
記録は残っているのに戻せない:リソース削除後にハマる典型パターン
削除事故でよくあるのが、「ログはあるのに戻せない」状態です。たとえば、削除イベント(誰が Delete 系 API を呼んだか)は CloudTrail で追える。でも“削除前の設定”が手元にない。あるいは、削除前の設定は断片的に分かるが、依存関係(関連する SG、ターゲットグループ、ルート、ロール)が芋づる式で抜け落ちる。
ここで AWS Config の価値が出ます。Config の変更履歴やスナップショットが揃っていれば、削除直前の構成を“再構成の材料”として引き出せます。ただし、ここにも落とし穴があります。
典型パターン1:Config は有効だが、配信・保持設計が弱い
AWS Config は、記録した内容を指定先に配信する設計(例:S3 への配信、SNS 通知)を取れます。ところが、配信先のバケットが運用で整理されていたり、ライフサイクルで短期削除されていたり、権限で参照できなくなっていたりすると、「あるはずの材料」が使えません。平時のコスト最適化が、事故時の復元を難しくする典型です。
典型パターン2:記録対象の抜け(リソースタイプ/リージョン/アカウント)
一部のアカウントだけ Config が無効、特定リージョンだけ未設定、あるいは記録対象リソースが限定的。マルチアカウント運用では特に起きます。事故は“弱いところ”から起きるので、こういう穴があると復元が局所最適になり、全体として収束しません。
典型パターン3:復元手順が「作り直し」になってしまう
ログから設定を拾って手作業で作り直すと、ヒューマンエラーが混ざります。名前、タグ、依存関係、微妙な設定値の差。復元後に別の障害が起き、「直したのにまた壊れた」状態に陥ります。だから復元は、可能な限り IaC に寄せて再現性を確保するのが安全です(ただし、IaC も現状と乖離している場合は、適用前の設計判断が必要です)。
この章のまとめ:削除後の復元は「ログがある」だけでは足りません。配信・保持・記録対象・依存関係まで揃って初めて、復元の道筋が一本になります。
タイムラインを作る:Configuration history と CloudTrail をどう噛み合わせるか
復元の会議で一番詰まるのは、「話が前に進まない」ことです。
「いつからおかしい?」「その前は?」「誰が触った?」が曖昧だと、全員が自分の仮説をしゃべり続けて、議論が過熱します。ここで必要なのは“タイムライン”です。温度を下げるには、事実の線を引く。
タイムライン作りのコツは、最初から網羅しないこと。対象リソースを絞り、「状態変化の点(AWS Config)」と「操作の点(CloudTrail)」を同じ時間軸に並べます。
最小の型:3つの問いにだけ答える
- 最後に正常だった時刻はいつか(監視・ログ・ユーザー報告から仮置き)
- その前後で、対象リソースの設定がどう変わったか(AWS Config の履歴)
- その変化に対応する操作は何か(CloudTrail のイベント)
対応関係を崩さないためのメモ(後でIaC化するために)
- リソース識別子(ARN、ID、Name、タグ)を“そのまま”残す
- 関連先(例:SG⇔ENI、ALB⇔TG、IAM Role⇔Instance Profile など)をセットで記録する
- 「変わった項目」だけでなく「変わっていないが前提になる項目」も控える(暗号化や公開ブロック等)
この段階で、復元の方針が見えてきます。たとえば「ある時刻に手動変更が入り、その後 IaC の適用で上書きされた」なら、復元は“どちらが正か”の設計判断が必要です。ここを一般論で決めると事故ります。SLO、監査要件、権限分掌、将来の運用まで含めて決めないと、同じ穴に落ちます。
この章のまとめ:タイムラインは議論のストッパーです。Config(状態)と CloudTrail(操作)を同じ時間軸に置くと、復元も再発防止も現実的な議論になります。
復元の土台はスナップショット:Configuration recorder と delivery の落とし穴
「AWS Config を有効化してあるから大丈夫」——この安心感が、いざというときに崩れるポイントはだいたい2つです。
ひとつはConfiguration recorder(何を記録するか)。もうひとつは配信(delivery)(記録をどこに、どう残すか)。この2点が噛み合っていないと、履歴が“見えているようで使えない”状態になります。
Recorder:記録対象の設計ミスが、そのまま復元不能に直結する
AWS Config はリージョン単位でリソースの設定状態を記録します。現場でハマりやすいのは、次のような抜けです。
- 対象リソースタイプの限定:コストやノイズ削減のつもりで絞った結果、事故に関係するタイプが記録されていない。
- マルチリージョンの片落ち:運用していないと思っていたリージョンにリソースがあり、そこだけ Config が無効。
- グローバル系リソースの扱い:IAM などアカウント全体に効くものは、記録の取り方を誤ると「見当たらない/重複して混乱」になりやすい。
心の会話で言うと、こうです。
「“このリージョンは使ってない”って言い切ったの、誰だっけ……」
ここで大事なのは責任追及ではなく、復元に必要な材料が揃う設計に戻すことです。
Delivery:配信先と保持の弱さは、事故時に“材料ロスト”になる
Config は記録した内容を外部(主に S3)へ配信しておくことで、後から確実に参照できる形にできます。ところが配信設計が弱いと、次のような事故が起きます。
- S3 側のライフサイクルで早期削除:コスト最適化のつもりで短期削除し、必要な期間が欠ける。
- バケット権限の変更で読めない:組織変更や委任でポリシーが変わり、当時のデータにアクセスできない。
- 暗号化キー(KMS)運用の不整合:キーのポリシー変更・無効化で復号できず、ログが“あるのに使えない”。
復元のための最小チェック(Recorder × Delivery)
| 観点 | 見るポイント | 事故時の影響 |
|---|---|---|
| 記録対象 | 必要なリソースタイプが含まれているか/リージョン網羅できているか | 削除前の状態が追えず、復元が“推測”になる |
| 配信先 | S3 へ確実に残るか/アクセス権と暗号化の整合があるか | 材料が読めない・欠ける・監査的に説明しづらい |
| 保持期間 | 想定する復元・監査の期間を満たすか | 「必要な期間だけ空白」が最も厄介な穴になる |
この章のまとめ:AWS Config を“復元に使える形”にする鍵は、Recorder(何を残すか)と Delivery(どう残すか)のセット設計です。ここが弱いと、被害最小化(ダメージコントロール)に必要な材料が揃いません。
「あるはずのログがない」を潰す:記録対象・頻度・集約先の設計チェック
復元の現場でいちばん消耗する言葉は、たぶんこれです。
「ログ、あるはずなんだけど……」
この状態に入ると、原因究明も復元も“場が荒れる”方向に進みます。落ち着かせるには、設計のチェックポイントを機械的に踏むのが一番です。
チェックは3段:対象 → 継続性 → 集約
- 対象(Coverage):どのアカウント/どのリージョン/どのリソースタイプを記録しているか
- 継続性(Continuity):事故の前から途切れず記録されているか(途中から有効化されていないか)
- 集約(Centralize):参照先が一本化され、事故時に確実に読めるか(権限・暗号化・保持)
マルチアカウント運用での実務ポイント
Organizations 配下で複数アカウントを運用していると、現場の“感覚”と実態がズレます。たとえば、運用チームは「本番はこのアカウント」と思っていても、実際はネットワーク境界やログ集約が別アカウントだったりします。復元に必要なログは、往々にして“別の場所”にあります。
- 集約先アカウント(ログアーカイブ)がどこかを確定する
- 参照権限が事故対応のロールに付いているか(普段の最小権限と衝突しやすい)
- ログの改ざん耐性(削除防止、バージョニング、アクセス監査)が担保されているか
「記録頻度」を誤解しない
AWS Config は“状態変化”を中心に記録しますが、すべてが同じ粒度・同じタイミングで揃うわけではありません。サービスによって更新の見え方が違いますし、削除や置換は「最後の状態」を取り逃がしやすいケースもあります。だから、復元を前提にするなら「Config だけで完結させない」設計が現実的です。
具体的には、CloudTrail(操作ログ)、S3 アクセスログ/CloudWatch Logs(周辺ログ)、IaC の実行ログ(plan/apply の記録)など、別系統のログと突き合わせて“穴”を埋めます。ここを最初から設計として持っていると、事故対応の収束が早いです。
短期でできる「穴埋め」施策(平時のうちに)
- Config の有効化状況を棚卸しし、アカウント・リージョンの抜けを潰す
- ログ集約先 S3 の保持・権限・暗号化(KMS)を、事故対応の参照要件で見直す
- IaC の実行ログ(CI/CD、Terraform、CloudFormation 等)を“後で追える形”で残す
この章のまとめ:「ログがない」は、設計の抜け(対象・継続性・集約)で説明できることが多いです。感覚ではなくチェックリストで潰すと、議論の温度を下げて収束に向かえます。
状態復元の実務:特定→差分抽出→IaC化→再適用の手順を型にする
復元作業を“職人芸”にすると、毎回つらいです。人によって判断がブレるし、夜間対応で疲れているとミスが混ざる。だから、復元の流れは型にしておくのが強いです。ここでは AWS Config を軸に、現場で回しやすい手順を整理します。
Step1:対象リソースを固定する(広げすぎない)
最初にやるのは、影響範囲の“中心”を決めることです。たとえば「ALB が落ちた」なら、ALB 本体だけでなく、ターゲットグループ、リスナー、SG、サブネット、ルート、証明書、WAF など依存が広がります。ここで重要なのは、いきなり全部を追わず、まず“壊れた入口”を1つ固定して周辺へ広げることです。
Step2:AWS Config で“最後に正常だった状態”を引く
Configuration history から、事故時刻の直前に近い「望ましい状態」を特定します。ここでのポイントは、
- 事故の直前の状態が必ずしも“正”とは限らない(すでに不正変更が混ざっている可能性)
- 監視やアプリログの異常開始時刻と突き合わせ、復元すべき時点を決める
です。復元は技術だけでなく、業務影響(いつの時点へ戻すのが妥当か)とセットになります。
Step3:差分を抽出して「人が読める形」に落とす
差分はそのままだと情報量が多く、判断がブレます。おすすめは、差分を「境界」「認可」「到達性」「データ面」の4カテゴリに振り分けて、レビューしやすくすることです。
| カテゴリ | 代表例 | 復元時の注意 |
|---|---|---|
| 境界 | SG/NACL/WAF/バケットポリシー | “開きすぎ”で一時復旧すると後で危険が残る |
| 認可 | IAM ロール、信頼ポリシー、KMS | 権限の過不足が再発・監査指摘につながる |
| 到達性 | Route、VPC エンドポイント、DNS | 復元後の疎通確認を“系統立てて”行う |
| データ面 | 暗号化、公開ブロック、ログ保存 | 復元のつもりでログや証跡を削らない |
Step4:可能な限り IaC 化して再適用する(ただし判断が要る)
「手で戻す」より「再現できる形で戻す」ほうが、長期的に事故が減ります。IaC 化は、復元を“仕組み”に変える作業です。ただし、現実の IaC が古い/ドリフトしている場合は、適用すると別の差分が出ます。ここは一般論で押し切れません。
だから実務では、次の順で安全に進めます。
- 復元対象を最小化(影響点から)
- 差分をカテゴリ分けしてレビュー
- 適用前に「何が変わるか」を明文化(チームで合意)
- 段階的に適用し、疎通確認を挟む
この章のまとめ:復元は「特定→差分→IaC 化→再適用」の型にすると、属人性が下がり、収束が早くなります。ここまで来ると、次に必要なのは“再発しない仕組み”です。
本番で効く運用に落とす:Config Rules / Conformance Pack で“再発しない仕組み”へ
復元が一段落すると、次に残るのは「また起きたらどうする?」です。ここでありがちな失敗は、障害報告書を整えることに全力を使い、仕組みは何も変わらないまま日常に戻ることです。現場の心の会話はだいたいこうなります。
「結局、“気をつけよう”で終わるやつだ……」
再発を減らすには、注意喚起ではなく“仕組み”としての歯止めが必要です。
Config Rules:設定の逸脱を「検知」し、議論の起点を作る
AWS Config Rules は、リソースの設定が期待する条件に合っているかを評価し、準拠/非準拠として結果を残せます。ここで重要なのは、Rules を「監査のため」だけに置かないことです。復元やダメージコントロールの観点では、Rules は“現場が動くきっかけ”になります。
- 境界の逸脱:公開設定、広すぎるインバウンド、意図しない到達性など
- ログの逸脱:記録が止まっている、集約先が変わっている、暗号化や保持が崩れているなど
- 権限の逸脱:過剰権限、信頼ポリシーの想定外、鍵ポリシーの変更など
検知の粒度は、最初から細かくしすぎないほうが運用が続きます。ノイズが多いと、人は“見なくなる”。まずは「重大な逸脱だけに反応できる」状態にするのが現実的です。
Managed と Custom:作り込みより“継続”が勝つ局面がある
Config Rules には AWS 管理ルールと、Lambda などで実装するカスタムルールがあります。どちらが優れているかは一概には言えませんが、現場の意思決定としては次の整理がしやすいです。
| 選択肢 | 向くケース | 注意点 |
|---|---|---|
| AWS 管理ルール | まず仕組みを回したい/標準要件で十分/運用負荷を増やしたくない | 組織固有の例外や命名規約までは拾えないことがある |
| カスタムルール | 業務要件に直結した逸脱を見たい/例外ルールが多い/独自の判断軸が必要 | 実装・保守の責任が生まれる(依存関係、権限、実行失敗の監視が必要) |
“正しさ”より“継続性”を優先して、まず管理ルールで土台を作り、痛いところだけカスタムで補う、という段階的な進め方が現場では破綻しにくいです。
Conformance Pack:横断展開で「穴」を塞ぐ
アカウントやリージョンが増えるほど、「一部だけ未設定」「ここだけ例外」が増えていきます。事故はこういう弱いところから起きます。Conformance Pack は、複数のルールや設定をひとまとめにし、横断的に適用して“穴”を塞ぐための単位として使えます。
ここでの勘どころは、パックを“巨大な一枚岩”にしないことです。運用や組織の責任分界に合わせて、パックを分割し、適用範囲を明確にします。たとえば、
- ログ基盤(Config/CloudTrail/集約先/保持/暗号化)
- ネットワーク境界(公開設定、広域アクセス、到達性)
- 権限・鍵(IAM、AssumeRole、KMS)
のように“壊れたら痛い面”で区切ると、収束と再発防止が同じ線に乗ります。
自動修復(Remediation)は強力だが、いきなりは危険
Config の評価結果をトリガーに、自動修復へ繋げる設計は有効です。ただし「自動で戻せるなら全部自動で」とすると、逆に現場が疲れます。なぜなら、自動修復は“正しい状態”が確定していることが前提だからです。レガシー環境でドリフトが常態化していると、正しい状態そのものが議論中だったりします。
段階としては、
- まずは検知して通知(場を整える)
- 次に手動運用の手順を固める(判断軸を統一)
- 最後に限定的に自動化(境界・ログなど明確なものから)
という順が、安全に軟着陸しやすいです。
この章のまとめ:Config Rules と Conformance Pack は、復元を“イベント”で終わらせず、再発しない仕組みに落とすためのストッパーです。まずはノイズを減らし、重大な逸脱だけ確実に拾える形から始めると、運用が続きます。
帰結:AWS Config は“復旧ツール”ではなく、復元を可能にする設計のログ基盤である
最初の違和感は、「削除や改変が起きたのに、説明ができない」でした。そこから、状態のログ(AWS Config)と操作のログ(CloudTrail)を同じ時間軸に並べ、復元を“推測”から“根拠のある再構成”へ寄せました。ここまでの流れを一本にすると、結論ははっきりします。
AWS Config は、単体で何かを元に戻す魔法のスイッチではありません。けれど、復元の材料(当時の設定)と、説明の根拠(いつどう変わったか)を残すことで、現場のダメージコントロールを成立させる“土台”になります。
一般論で言い切れない理由:復元は「技術」+「意思決定」だから
復元の現場では、技術だけで決まらない論点が必ず出ます。
- いつの状態へ戻すか(直前の状態が正しいとは限らない)
- IaC の定義を正にするか、現実を正にするか(ドリフトをどう扱うか)
- 緊急復旧と監査要件のバランス(証跡・手順・権限分掌)
- 再発防止の落としどころ(検知だけ/手順整備/自動修復まで)
この意思決定を曖昧なまま進めると、復元は一時的に成功しても、後から別の障害や監査指摘として跳ね返ってきます。だから“正解”は環境ごとに変わり、一般論のままでは危険です。
現場で効く、最低限の設計ゴール
復元を可能にする設計として、最低限ここまでは押さえると、収束が早くなります。
| ゴール | 狙い | 代表的な手段 |
|---|---|---|
| 状態が追える | 削除・改変の前後を再現できる | AWS Config(記録対象・配信・保持の設計) |
| 操作が追える | 誰が・何を・いつやったかを確定できる | CloudTrail(集約・改ざん耐性・参照導線) |
| 議論が収束する | タイムラインで温度を下げ、復元方針を決める | カテゴリ分け(境界/認可/到達性/データ面)、レビュー手順 |
| 再発が減る | 逸脱を検知し、手順と仕組みに落とす | Config Rules / Conformance Pack(段階的に) |
締めくくり:迷ったら、まず「設計の診断」から
削除・改変の復元は、ログが揃っていても難しいことがあります。ログが揃っていなければ、なおさら判断が重くなります。ここで無理に自己判断で突っ走ると、証跡を失ったり、復元経路が壊れたりして、結果として収束が遅れます。
現場の負担を減らしつつ確実に収束させるには、株式会社情報工学研究所のような専門家と一緒に、(1) ログ基盤の穴の特定、(2) タイムライン整理、(3) 復元の手順化と IaC 化、(4) 再発防止の落としどころ、を一気通貫で進めるのが現実的です。
問い合わせフォーム:https://jouhou.main.jp/?page_id=26983
電話:0120-838-831
この章のまとめ:AWS Config は復元を“可能にする”ログ基盤です。一般論では決めきれない部分こそ、個別案件として設計・運用・監査まで含めて整える価値があります。
付録:現在よく使われるプログラム言語ごとの注意点(ログ・設定・復元の観点)
クラウドの削除・改変対応は、インフラだけの問題に見えて、実際はアプリ側の実装や運用設計が復元難易度を左右します。ここでは、主要な言語・実行基盤で「事故対応を難しくしがちな落とし穴」を整理します。
Python(Lambda / バッチ / API)
- 依存関係の固定:requirements の更新で挙動が変わると、復元後の再現性が崩れる。ロックやイメージ化で差分を減らす。
- 例外処理の握りつぶし:広い except でエラーが見えず、タイムラインが作れない。構造化ログで例外とコンテキストを残す。
- 秘密情報の扱い:環境変数や設定ファイルへの直書きが残ると、事故時に権限・鍵の見直しが困難になる。Secrets 管理を前提にする。
Java(Spring / 大規模サーバ)
- 設定の分散:プロファイルや外部設定の組み合わせが複雑になりがちで、「どの設定で動いていたか」が復元時に曖昧になる。設定のソースを一本化し、変更履歴を残す。
- ログの粒度:INFO 過多で重要イベントが埋もれる。監査・復元に必要なイベント(設定読み込み、認証、外部連携、エラー)を意図して残す。
- 依存の更新:ライブラリ更新の影響が広い。復元時は「当時のビルド成果物」を確実に再配置できる運用が効く。
JavaScript / TypeScript(Node.js / フロント / サーバレス)
- 依存の変動:ロックファイル運用が曖昧だと、同じコードでも再現できない。復元・ロールバックの観点ではロックとビルド成果物の保存が重要。
- 設定の混在:.env、ランタイム設定、ビルド時注入が混ざると、事故後に「どれが正か」判断が難しい。設定の責務分離を明確にする。
- 非同期の失敗が見えにくい:Promise の未処理例外や再試行の仕様が曖昧だと、障害の開始点が追えない。相関IDと失敗ログの統一が効く。
Go(マイクロサービス / CLI / エージェント)
- 再試行とタイムアウト:実装がシンプルな分、再試行ポリシーの設計ミスが“事故の増幅”になる。バックオフ・サーキットブレーカーの方針を明文化する。
- ログの構造化:テキストログだけだと後追い分析がつらい。復元のタイムライン作りのためにフィールド化して残す。
- 単一バイナリの管理:配布は容易だが、どのバージョンが動いていたかを取り違えると復元が崩れる。ビルド番号とデプロイ証跡を揃える。
Rust(システム系 / 高信頼コンポーネント)
- 安全性の強みを運用へ繋げる:メモリ安全でも、設定・鍵・権限の運用が弱いと事故は起きる。機密取り扱いと監査ログの設計は別途必要。
- ビルドの再現性:依存の固定と成果物保管が復元の鍵。ビルド環境差分を小さくする。
C / C++(組込み / 高性能コンポーネント)
- クラッシュ時の情報不足:コアやシンボルが無いと復元原因が追えない。ビルド成果物とシンボルの保管、ダンプ収集の運用が重要。
- 境界の不具合が影響を広げる:入力検証やメモリ破壊は、設定改変や異常挙動と区別がつきにくい。監査ログと稼働メトリクスを揃え、タイムラインを作れる状態にする。
- 依存ライブラリ:OS・ミドルの差分で再現性が崩れる。コンテナ化や固定化の方針が復元を楽にする。
C#(.NET / Windows / Azure 連携)
- 設定ソースの多重化:appsettings、環境変数、KeyVault 等が混ざりやすい。どの層で何を上書きするかを固定し、変更履歴を残す。
- 権限連携:AD/IdP とクラウド権限の境界が事故点になりやすい。認証・認可ログの相関を取れる設計にする。
PHP(WordPress / 既存Web)
- 設定変更が“画面操作”に寄る:手動変更が増えると、復元が推測になる。設定のエクスポート、監査ログ、変更者の追跡が必要。
- プラグイン依存:更新で挙動が変わりやすい。復元では「当時のバージョンの再配置」と「更新の手順管理」が重要。
- 権限・鍵の管理:wp-config や環境設定の扱いが雑だと事故時に切り分けが困難。秘密情報の分離を前提にする。
Ruby(Rails 等)
- 依存管理:Gem の更新で周辺が変わりやすい。ロックとビルド成果物の保管が復元の鍵。
- バックグラウンドジョブ:キューや再試行の仕様で障害が増幅することがある。失敗ログと相関IDを揃える。
Kotlin / Swift(モバイル・クライアント)
- クライアント更新の遅延:復元しても、古いクライアントが残ると不整合が続く。互換性と段階的切替を前提にする。
- 端末内キャッシュ:設定改変の影響が端末側に残り、復旧が遅れる。キャッシュ無効化・再同期の設計が必要。
SQL(DBクエリ・運用スクリプト)
- 破壊的クエリ:事故対応で焦って実行すると取り返しがつかない。権限分離、監査ログ、実行履歴の保管が重要。
- スキーマ変更:マイグレーションの履歴が曖昧だと復元が崩れる。マイグレーションの証跡とロールバック方針を揃える。
Bash / PowerShell(運用スクリプト)
- 手元実行の属人化:誰が何を実行したか残らないと、復元タイムラインが作れない。実行ログと承認フローを仕組みにする。
- 秘密情報の露出:スクリプト内に認証情報が残ると事故時に影響範囲が広がる。Secrets 管理と最小権限が前提。
Terraform / CloudFormation(IaC)
- 状態(state)の保全:state の取り扱いが弱いと、復元も再現性も崩れる。バックエンドと権限、ロック、履歴の設計が重要。
- ドリフトの扱い:手動変更が混ざると apply が事故を起こす。差分レビュー、段階適用、緊急時の運用手順が必要。
- “正”の合意:IaC が正なのか現実が正なのか、合意がないと復元が揉める。運用規約として決める。
付録のまとめ:どの言語でも、復元を難しくする原因は「再現性がない」「ログで追えない」「設定が散らばる」「権限と鍵が曖昧」の4つに収束しがちです。インフラ側の AWS Config と、アプリ側の実装・運用を同じ線で整えると、削除・改変事故の収束は早くなります。
技術者とAWS Config の作業と関係の概念図
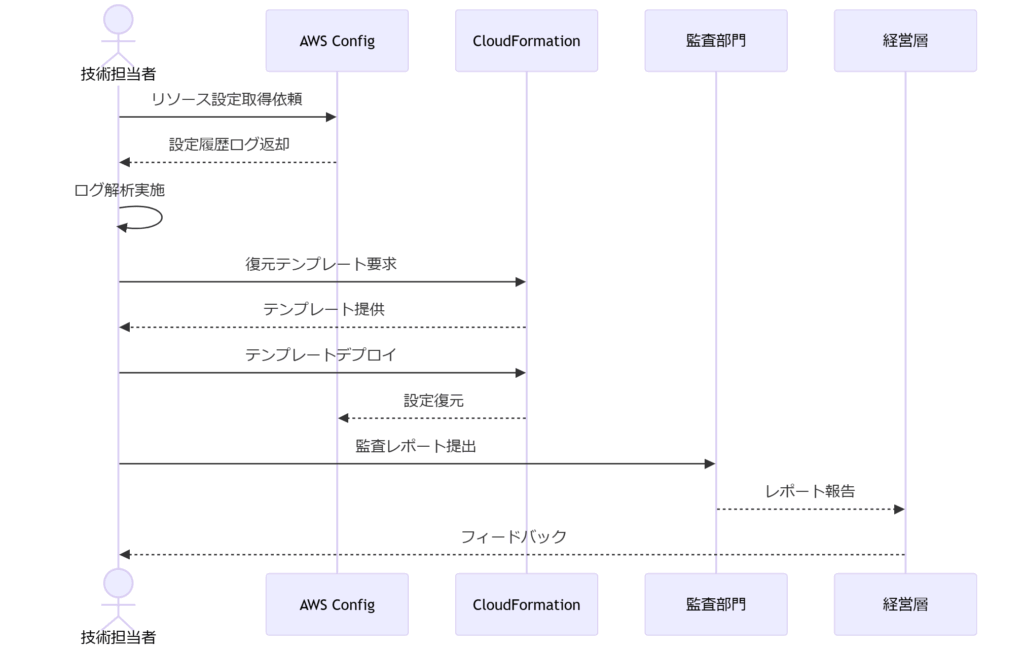
想定課題
- 誤操作や設定削除によるクラウドリソース停止からの迅速な復旧方法がわからない
- AWS Config の履歴ログ取得・検索手順が未整備で監査証跡として機能していない
- 法令・ガイドラインに則ったログ保全要件を満たせているか不安がある
- 経営層や監査部門への報告資料が準備できておらず、説明が煩雑になるリスクがある
- BCP(事業継続計画)にAWS Config を組み込む具体的なフローがない
クラウド設定削除からの復活術:AWS Config が守る貴社の重要データ
コンプライアンスの引用元
- 経済産業省『クラウドサービス利用ガイドライン』2024年(www.meti.go.jp)
- 総務省『クラウド運用セキュリティガイドライン』2023年(www.soumu.go.jp)
- 内閣サイバーセキュリティセンター『クラウドサービス安全対策基準』2022年(www.nisc.go.jp)
- 個人情報保護委員会『クラウド利用における個人情報保護の手引き』2021年(www.ppc.go.jp)
- 情報処理推進機構(IPA)『クラウドサービス安全・信頼性向上ガイド』2023年(www.ipa.go.jp)
AWS Config の概要と導入メリット
AWS Config は、AWS 上のリソース設定を自動で記録・評価するマネージドサービスです。リソースの設定変更履歴を保存し、いつ、誰が、どのような変更を行ったかを時系列で把握できます。これにより誤操作による障害原因の特定や、設定削除時の復元が可能となります。
Config とは?基本機能
- リソース設定のキャプチャ:EC2 や S3、IAM ポリシーなどの設定内容を定期的にスナップショット取得
- 変更履歴の保存:変更前後の状態を S3 バケットに保管し、証跡として保持
- ルール評価:AWS ベストプラクティスや独自ルールに沿った設定かどうかを自動判定
導入メリット一覧
- 迅速な障害原因特定:設定変更のタイムスタンプをたどり、問題発生ポイントを即時把握
- 確実な設定復元:過去の正しい設定情報をエクスポートし、再適用スクリプトを自動生成
- 監査要件の充足:内部・外部監査で求められる証跡保全を満たし、コンプライアンス強化
- 運用コスト削減:手動での設定バックアップ作業が不要となり、人的負荷を軽減
AWS Config の導入は、クラウド運用の信頼性・透明性を飛躍的に向上させ、設定ミスによる業務停止リスクを低減します。次の章では、クラウド設定削除事故のリスクと現状について解説します。
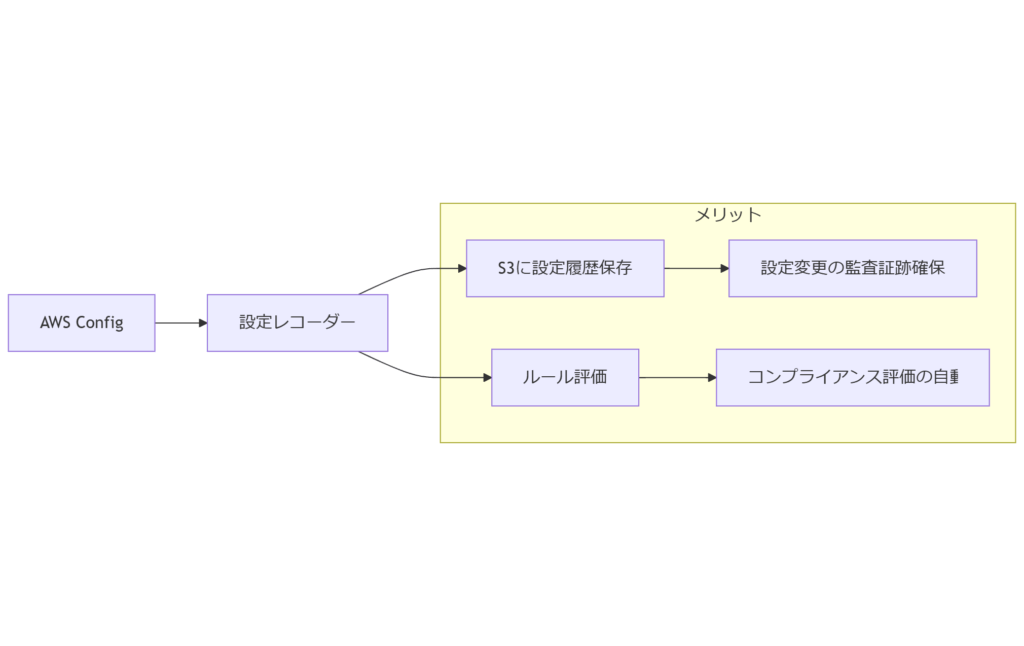
AWS Config を導入することで、設定変更履歴が自動的に保存され、設定削除時にも過去の正しい状態へ即復元できます。監査対応にも有効です。
設定管理を自動化することで、技術者の負担を軽減しつつ運用の透明性を確保できます。経営層にも安心して自社のクラウド運用体制を示せます。
クラウド設定削除事故のリスクと現状
本章では、設定誤削除や不正アクセスによるクラウドリソース停止のリスクを洗い出し、現場で発生している典型的な事故例とその影響範囲を明らかにします。
典型的な事故事例
- 誤操作によるバケットポリシー削除:アクセス制御が外れ、データ流出の恐れ
- IAM ロール誤設定:過剰権限での実行に起因する不正操作
- 自動化スクリプトのバグ:定期ジョブで無条件にリソースを削除してしまうケース
発生頻度と影響範囲
- 誤削除によるサービス停止:発生頻度は年間数回〜十数回
- 復旧に要する時間:平均 2~6 時間(設定ミスの特定+手動復旧含む)
- 監査指摘件数:ログ不足に起因する指摘が全体の約 30%を占める
現場運用の課題
- ログ取得が不完全:設定変更を記録する仕組みが未整備
- 復旧手順の不透明性:過去状態の参照方法が属人化
- 経営層への報告準備不足:定量的なインパクトデータが不足
次章では、AWS Config を用いた設定履歴ログの具体的な取得方法と保存設計について解説します。
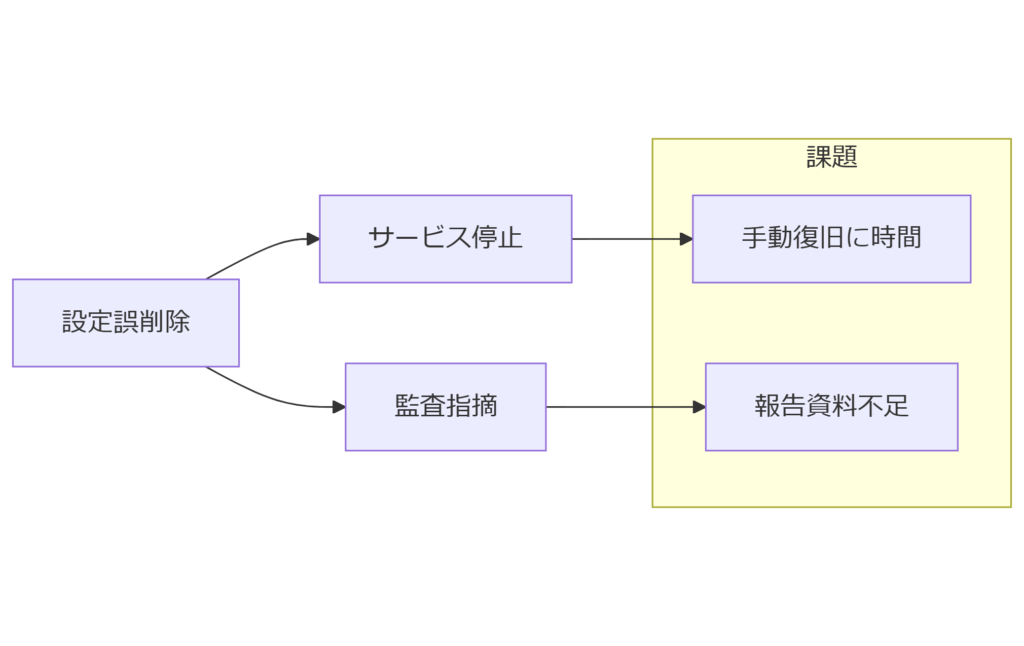
設定誤削除が起きると、サービス停止や監査指摘が同時に発生するリスクがあります。ログ取得と自動復元の仕組みが不可欠です。
発生頻度が高い事故を未然に防ぎ、万一の際には数分で復旧できる体制を整備することが、BCP の要となります。
設定履歴ログの取得方法と保存設計
本章では、AWS Config の変更履歴を確実に取得し、長期的に保管するための S3 バケット設計やライフサイクルポリシー設定を解説します。
AWS Config ログの有効化手順
- AWS Management Console で Config ダッシュボードを開きます
- 「リソース履歴の記録」を有効化し、対象リソースタイプを選択
- S3 バケットを新規作成または既存バケットを指定し、CloudTrail ログと同じバケットを推奨
- バケットポリシーで Config が書き込み可能な権限を付与
S3 バケット設計のポイント
- ログ専用プレフィックス:config-logs/ に統一し、他データと分離
- ライフサイクルルール:90日経過後に標準ストレージから低頻度アクセスに移行、365日経過後にアーカイブ
- バージョニング:バケットバージョン管理を有効化し、誤削除防止
- 暗号化設定:AWS KMS で SSE-KMS を適用し、機密性を確保
コスト最適化の考慮点
- ライフサイクル移行タイミング:使用頻度に応じて日数を調整し、コストと可用性をトレードオフ
- アクセス分析:S3 アクセスログや CloudWatch メトリクスを活用し、移行ポリシーを定期見直し
- 無駄なログ除外:不要なリソースタイプの記録を除外し、ログ量を最適化
次章では、取得したログをどのように解析し、問題原因を迅速に特定するかを説明します。
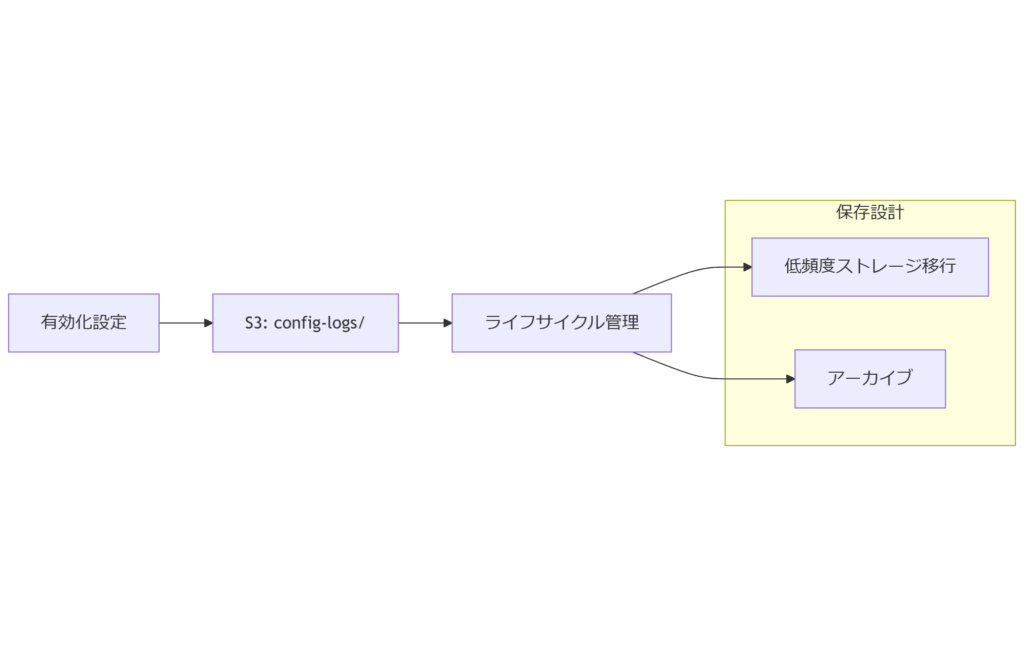
AWS Config のログは専用プレフィックスで一元管理し、ライフサイクルルールで自動的に低コストストレージへ移行することでコスト最適化が可能です。
一度設計すれば自動運用できる保存設計は、運用担当者の手間を大幅に減らしつつ、長期保全要件を満たします。
ログ解析手法──イベント履歴の読み解き方
本章では、取得した AWS Config の変更履歴ログをどのように検索・フィルタリングし、原因特定を迅速に行うかについて解説します。
CLI/Console/API を使った検索例
- AWS CLI 検索:
- コマンド例:aws configservice get-resource-config-history –resource-type AWS::EC2::Instance –resource-id i-0123456789abcdef0
- 出力された履歴 JSON から変更タイムスタンプと設定内容を確認
- Management Console:
- Config ダッシュボードの「リソース履歴」タブでリソースを選択
- 変更イベントをカレンダーやテーブル表示で確認
- API 利用:
- Programmatic に履歴を取得し、ログ分析ツールに取り込む
- Lambda 関数で特定イベントのみ抽出し、Slack 通知する例も有効
フィルタリング・時系列分析のポイント
- 変更タイプで分類:Create/Update/Delete イベントを分け、削除イベントを最優先で把握
- 時間帯指定検索:障害発生時刻前後の 30 分間に絞り込むことでノイズを排除
- リソースタグ絞り込み:重要タグ(例:Environment=Production)を指定し、対象リソースを限定
自動化スクリプトの活用
- Python や Bash で AWS CLI を呼び出し、定期的にログを取得・分析
- CloudWatch Events と連携し、特定変更発生時に自動レポート生成
- ログ解析結果を SNS 経由でチームへ通知し、初動対応を加速
次章では、解析結果を基に設定復元スクリプトを作成し、実際の復元手順を説明します。
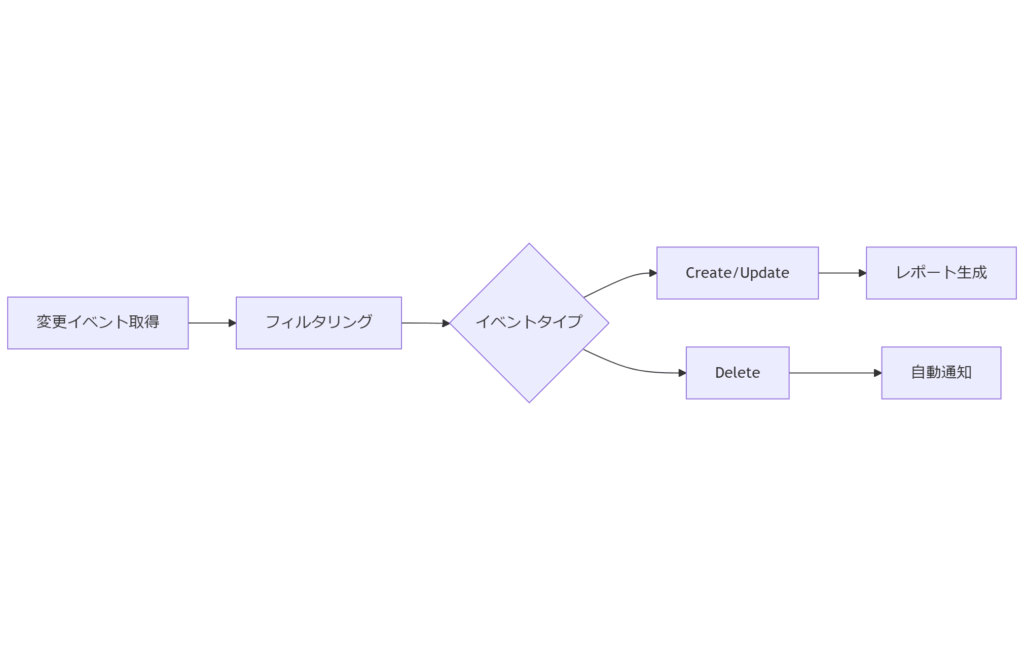
CLI や API、Console を組み合わせることで、変更イベントの発生から原因特定までを効率化できます。自動化スクリプトで初動対応を加速しましょう。
ログ解析の自動化により、オペレーションミスによる長時間復旧を防ぎ、技術者はより高度な検証や改善に注力できます。
設定復元プロセスの実践ステップ
本章では、解析で特定した変更イベントを基に、AWS Config の履歴から元の設定をエクスポートし、CloudFormation や CLI を用いて自動的に復元する具体的な手順を解説します。
ステップ1:変更前の設定差分抽出
- AWS CLI を用いて対象リソースの履歴を JSON 形式で取得
- aws configservice get-resource-config-history –resource-type AWS::S3::Bucket –resource-id your-bucket-name –limit 2
- 最新2件の設定を比較し、Delete イベント前の設定を抜き出す
- jq コマンドで必要なフィールドのみ抽出
- jq ‘.configuration’ config-history.json > original-config.json
ステップ2:復元用テンプレート作成
- 抽出した JSON を元に CloudFormation テンプレートを作成
- 原設定を Resources セクションに反映し、YAML/JSON ファイルを準備
- テンプレートのパラメータ化
- BucketName や IAM Role 名など、環境ごとに変わる部分を Parameters で定義
ステップ3:自動適用と検証
- AWS CLI でテンプレートをスタックとしてデプロイ
- aws cloudformation deploy –template-file restore-template.yaml –stack-name restore-stack –parameter-overrides BucketName=your-bucket-name
- 適用後の設定を再度 AWS Config で確認し、差分がないことを検証
- 自動テストスクリプトを実行し、サービス正常性を確認
次章では、法令・ガイドラインに沿った運用体制の構築と遵守ポイントを解説します。
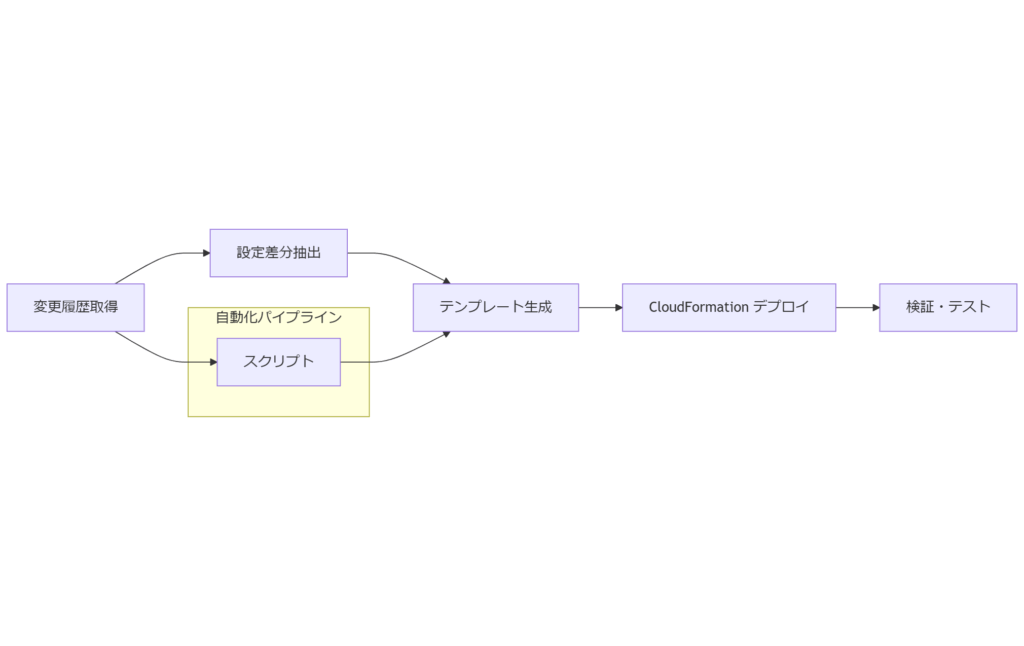
設定復元は「設定差分抽出→テンプレート化→自動デプロイ→検証」の流れで実施します。自動化スクリプトを用いることで復旧時間を大幅に短縮できます。
復元プロセスをコード化し、自動化することでヒューマンエラーを排除し、復旧品質およびスピードを安定的に確保できます。
法令遵守とガイドライン対応
本章では、AWS Config を運用するうえで遵守すべき主要な法令や政府ガイドラインを整理し、具体的にどのように社内規程へ落とし込むかを解説します。
関連法令の概要
- 個人情報保護法:クラウド上に保管される個人情報の取扱い基準を規定
- アクセスログの取得・保存要件
- 暗号化・アクセス制御の実装
- 電気通信事業法:通信サービスの提供事業者に対する運用基準を定める
- 障害発生時の報告義務
- 再発防止策の策定・提出
- 不正アクセス禁止法:不正アクセス検知およびログ保全義務を規定
- 侵入検知ログの長期保存
- 定期的なログ監査
政府ガイドラインのポイント
- 経済産業省クラウド利用ガイドライン:安全管理措置の具体例
- 多要素認証強制
- 定期アクセス権レビュー
- 総務省クラウド運用セキュリティガイドライン:運用手順とインシデント対応フロー
- インシデント通報フローの整備
- ログ分析の頻度・担当者明確化
- 個人情報保護委員会ガイド:クラウドサービス利用時の個人情報保護措置
- 委託先管理の要件
- 定期監査の実施方法
社内規程への落とし込み
- ログ保存ポリシー:保存期間、アクセス権限、アーカイブルールを文書化
- インシデント対応手順書:AWS Config ログ活用による初動対応フローを記載
- 権限管理規程:Config 閲覧・設定権限の最小化・定期見直しルール
次章では、システム設計と運用体制の要件について詳しく説明します。
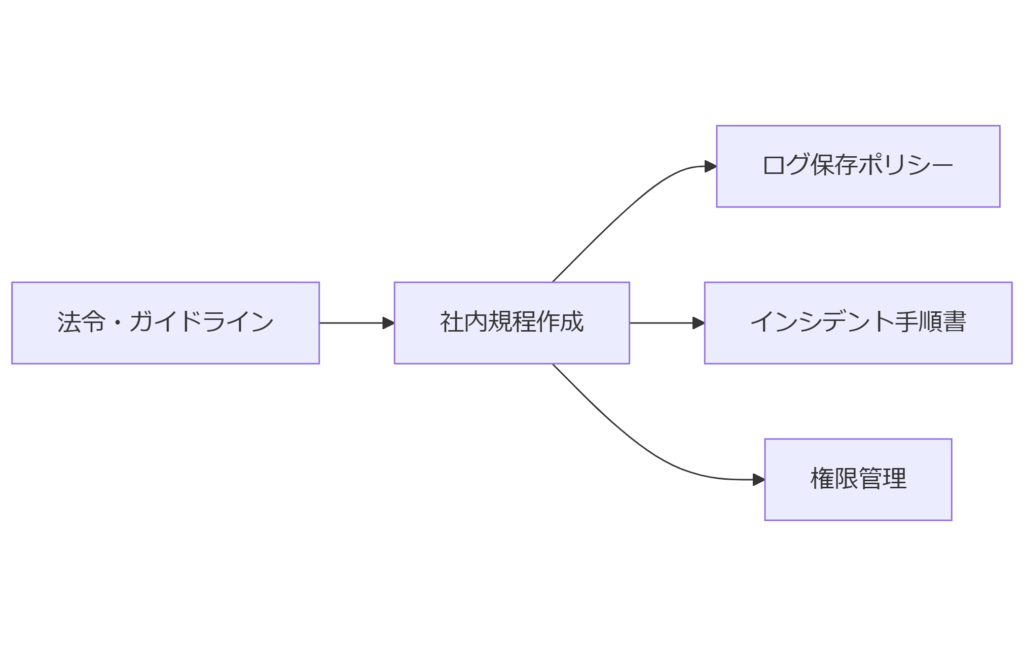
個人情報保護法や電気通信事業法などの法令・ガイドライン要件を社内規程へ明確に落とし込み、AWS Config ログ活用ルールを策定します。
社内規程を整備し遵守を徹底することで、監査対応を効率化し、リスク管理体制を強化できます。
システム設計と運用体制の要件
本章では、AWS Config を有効活用するための運用体制設計と役割分担、アクセス権限設計、定期トレーニングについて解説します。
役割・責任の明確化
- システム管理者:AWS Config の導入設定、S3 バケットの管理
- 運用担当者:日常の変更履歴確認、インシデント初動対応
- セキュリティ担当者:ガイドライン遵守状況の監査、ログレビュー
- 経営層/監査部門:定期レポート受領、リスク評価および意思決定
アクセス権限と最小権限設計
- IAM ポリシーで Config リソース閲覧・書き込み権限を分離
- タグベースアクセス制御(例:Environment=Production タグ付きリソースのみ閲覧可)
- 定期的なアクセス権レビューを実施し、不要権限を速やかに削除
監視・アラート体制の構築
- CloudWatch Events で特定の Delete イベントを検知し、SNS で即時通知
- Config Rules が違反を検出した際の自動修復(Remediation)を設定
- 月次ダッシュボードで評価ステータスを可視化し、経営層レポートに組み込む
定期トレーニングと訓練
- 四半期ごとに AWS Config 復元演習を実施し、手順の有効性を検証
- 新人教育プログラムに Config 利用方法を組み込み、理解度チェックを実施
- インシデント発生時の模擬訓練を年1回以上行い、改善ポイントをレビュー
次章では、定期点検と監査準備の具体的なチェックリストと手順を提示します。
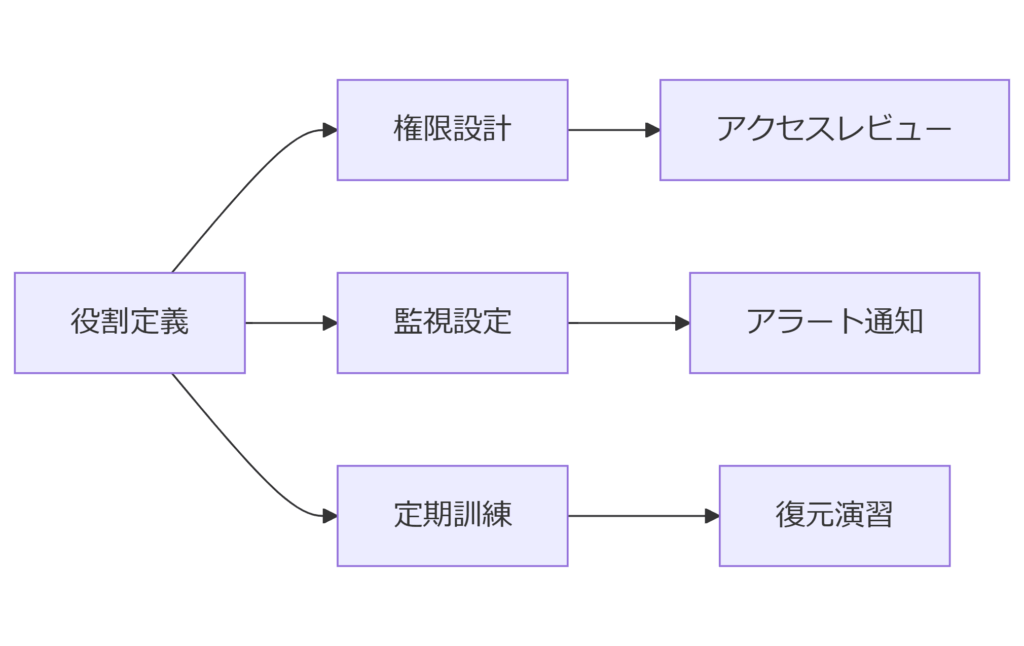
役割分担とアクセス権限を明確にし、監視アラートと定期訓練を組み合わせることで、運用品質を維持向上できます。
運用体制と権限設計を整備することで、日常の業務効率とセキュリティレベルを同時に高めることが可能です。
定期点検と監査準備
本章では、AWS Config 運用の定期点検項目と監査対応フローを整理し、インシデント発生前後に必要な手順を明確化します。
四半期チェックリスト
- Config ルール評価ステータスの確認
- S3 バケットへのログ出力状況の検証
- CloudWatch アラートログの履歴確認
- ライフサイクルポリシーの適用状況チェック
監査資料の準備手順
- 変更履歴ログから対象期間のイベント一覧を抽出
- インシデント報告書に Config ログを添付
- 法令・ガイドライン遵守状況の一覧表作成
改善サイクルの実行
- 点検結果に基づきルールやポリシーを更新
- 次回点検までの改善項目をタスク登録
- 結果を経営層へレポートし、承認を取得
次章では、BCP(事業継続計画)への AWS Config 組み込み方法を解説します。
| 項目 | 実施頻度 | 担当者 |
|---|---|---|
| Config ルール評価 | 四半期 | セキュリティ担当 |
| ログ一元管理状況 | 四半期 | 運用担当 |
| 報告書作成 | インシデント発生後 | システム管理者 |
四半期点検で AWS Config の運用状況をレビューし、監査時に必要なログや報告書を迅速に準備します。改善サイクルを回し、継続的な運用品質向上を図ります。
定期点検と監査準備を標準化することで、コンプライアンス対応が迅速かつ確実になり、リスク管理体制を強固にします。
BCP(事業継続計画)への組み込み
本章では、AWS Config を事業継続計画(BCP)に組み込み、障害発生時に確実に復旧手順を実行できる体制づくりを解説します。
BCP シナリオ訓練の実施
- 設定削除事故訓練:誤削除発生から復元完了までの手順をシミュレーション
- 不正アクセス検知訓練:Delete イベント検知後の対応フローをウォークスルー
- 自然災害シナリオ:データセンター停止を想定し、Config ログを用いたリモート復旧訓練
組織内手順フローの明確化
- インシデント発生通知→Config イベント確認→復元スクリプト実行→検証→報告
- 責任者と連絡先、報告先を一覧化したインシデント応答マトリクスの作成
- 手順書は定期レビューし、最新の AWS Config 設定に合わせて更新
ドキュメント管理と共有
- 手順書・演習結果は社内 Wiki またはバージョン管理システムで一元管理
- 変更履歴を記録し、過去演習の所要時間・課題一覧を参照可能にする
- 経営層への報告資料テンプレートを用意し、迅速な意思決定を支援
| シナリオ | 実施頻度 | 担当部署 |
|---|---|---|
| 設定削除事故 | 年2回 | 運用部門 |
| 不正アクセス検出 | 年1回 | セキュリティ部門 |
| 自然災害想定 | 年1回 | 全社 |
次章では、技術担当者、管理部門、経営層それぞれへの説明ポイントと注意点をまとめます。
BCP 訓練を定期的に実施し、インシデント対応手順が確実に実行できる体制を整備します。手順書・報告テンプレートも明確に管理しましょう。
BCP フローを社内に浸透させることで、緊急時でも混乱なく復旧作業を遂行し、事業の継続を確実に支援します。
関係者別注意点と説明ポイント
本章では、技術担当者、管理部門、経営層それぞれが抱える関心事と説明すべき要点を整理し、効果的なコミュニケーション方法を解説します。
技術担当者向けポイント
- AWS Config の設定有効化手順およびログ取得方法を明示
- 自動化スクリプトや復元テンプレートの利用方法をマニュアル化
- エラー発生時のトラブルシュートフローを図解で提供
管理部門向けポイント
- 監査証跡としてのログ保全ルールと保持期間を明示
- 法令・ガイドライン対応状況の一覧表を付与し、遵守状況を可視化
- インシデント報告書テンプレートを用意し、報告フローを定型化
経営層向けポイント
- 導入メリットとしてリスク低減効果やコスト削減見込みを定量的に提示
- BCP への組み込み状況と訓練結果を要約し、安心感を強調
- ROI や稼働率向上など、経営判断に必要な指標をダッシュボードで提示
| 関係者 | 説明内容 |
|---|---|
| 技術担当者 | 設定手順・自動化スクリプト・トラブルシュート |
| 管理部門 | ログ保全ルール・監査証跡・報告テンプレート |
| 経営層 | リスク低減効果・BCP 組込状況・ROI 指標 |
次章では、具体的な復旧成功事例を紹介し、実践イメージを深めていただきます。
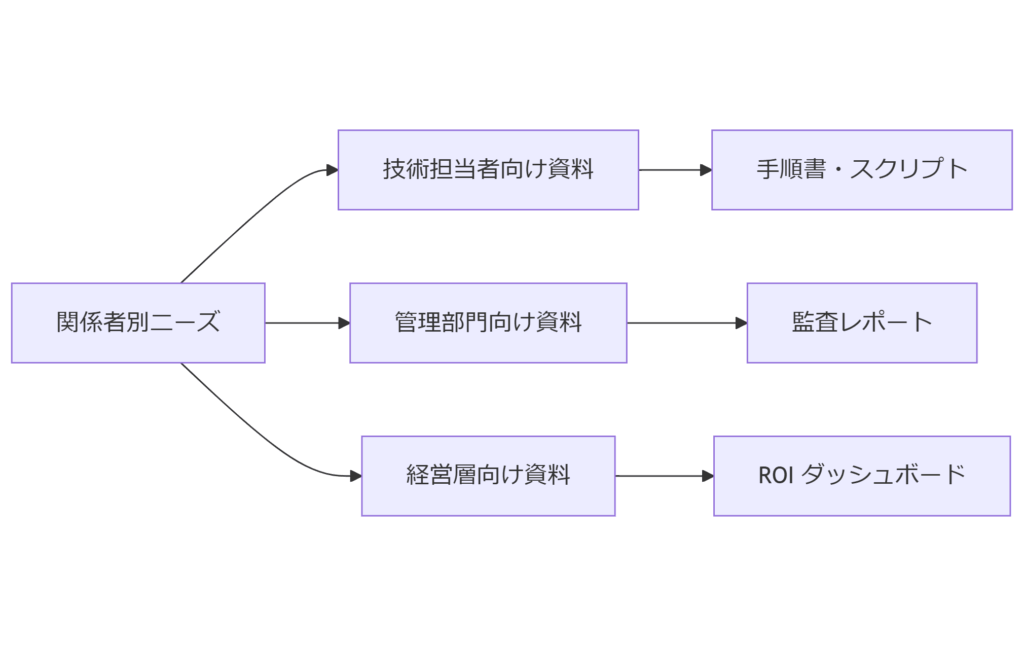
関係者ごとに求める情報を整理し、技術資料・監査資料・経営指標をそれぞれ提供することで、社内合意を迅速に得られます。
適切な情報を適切な相手に提供するコミュニケーション設計が、クラウド運用の信頼性向上と迅速な意思決定を支えます。
ケーススタディ──復旧成功事例紹介
本章では、実際に AWS Config を活用して短時間で設定復旧を実現した2つの事例を紹介し、導入効果を具体的にイメージいただきます。
事例A: S3 バケットポリシー削除から10分で復旧
- 発生状況:誤操作により本番 S3 バケットの公開設定が削除され、サービス停止
- 対応手順:
- AWS CLI で削除前の設定を履歴から抽出
- CloudFormation テンプレートを自動生成
- テンプレートをデプロイし、ポリシーを再適用
- 所要時間:約10分(調査3分+自動復元5分+検証2分)
- 成果:停止時間を最小化し、SLA への影響を回避
事例B: IAM ロール誤削除から無停止復旧
- 発生状況:運用スクリプトの不具合で IAM ロールが誤って削除
- 対応手順:
- AWS Config の履歴 API で削除前のロール定義を取得
- Terraform テンプレートを作成し、ロールを再作成
- 関連ポリシーを自動アタッチして権限を復元
- 所要時間:約15分(分析5分+テンプレート生成7分+適用・検証3分)
- 成果:ユーザー業務への影響ゼロで復旧完了
| 事例 | 発生原因 | 復旧時間 | 成果 |
|---|---|---|---|
| A | S3 ポリシー削除 | 10分 | サービス停止回避 |
| B | IAM ロール誤削除 | 15分 | 業務継続無停止 |
AWS Config で取得した履歴から自動スクリプトを生成し、10~15 分以内にポリシーやロールを復元できます。サービス停止や業務影響を最小化します。
実際の運用事例を通じて、短時間での復旧が可能であることを経営層に示すことで、投資対効果を具体的に訴求できます。
弊社サービスのご案内とお問い合わせ促進
本章では、株式会社情報工学研究所(以下「弊社」)が提供する AWS Config 関連支援メニューとお問い合わせ方法をご案内します。
弊社支援メニュー
- AWS Config 導入コンサルティング
- ログ保存設計およびライフサイクル設定支援
- 自動復元スクリプト/テンプレート開発
- 定期訓練・BCP 演習プログラム
- 監査対応レポート作成支援
無料相談のご案内
導入前の不安点や構成確認、運用設計のご相談はすべて無料で承ります。お気軽にお問い合わせください。
お問い合わせ方法
- お問い合わせフォーム:下部にお問い合わせフォームがございます
- 電話:043-422-4240(平日 9:00–18:00)
無料相談から導入支援、運用サポートまで一貫して対応いたします。初期構築や定期訓練まで、弊社が全面的にサポートします。
弊社の豊富な実績と専門知識により、運用担当者の不安を解消し、経営層へは確かな ROI とセキュリティレベル向上をお約束します。