目次
- rsyncとは何か:基本機能と差分転送の仕組み
- エラーログの読み方:代表的な出力例と解析ポイント
- ブロック損失の発生原因:ネットワーク/ファイルシステム観点
- 失われたブロックの検出方法:–checksumオプション活用術
- ブロック回収コマンド実践:–partial-dir+再同期手順
- 大量データ転送時のパフォーマンスチューニング
- 運用自動化と監視:cron+監視ツール連携例
- トラブル時のBCP対応:緊急時・無電化時・システム停止時
- コンプライアンス遵守:法令・ガイドライン整理
- 外部専門家エスカレーションフロー
- 御社社内共有・コンセンサス
- まとめと今後の運用改善提案

解決できること・想定課題
- 差分同期中に発生するrsyncの「ブロック欠落」原因を徹底解析し、再転送手順を具体的に示します。
- エラーログから見落としやすい設定ミスを即発見し、ログ解析コマンドとポイントをわかりやすく解説します。
- 大規模環境におけるバックアップ運用のBCP策定と、緊急時のオペレーションフローを網羅的に提案します。
rsyncとは何か:基本機能と差分転送の仕組み
rsyncは、ローカルとリモート間で効率的にファイルを同期するためのコマンドラインツールです。初回同期時には完全コピーを行い、以降は「差分転送」方式で更新部分のみを転送するため、ネットワーク帯域と時間を大幅に節約できます。
差分転送では、まずローカルとリモートのファイルを比較し、タイムスタンプとサイズの差異を検出します。デフォルトではこれらを基準に更新ファイルを抽出し、転送を行います。rsyncの主要オプションを組み合わせることで、属性保持やパーミッションの維持も可能です。
表:rsync基本オプション比較| オプション | 説明 |
|---|---|
| -a | アーカイブモード(再帰的コピー+属性保持) |
| -v | 詳細表示モード |
| –delete | 同期元に存在しないファイルを削除 |
概要解説
この章ではrsyncの基本的な動作原理を解説しました。差分転送では、初回同期後は更新ブロックだけを転送するため効率が高い反面、設定ミスや属性の未保持があると予期せぬ欠落が発生しやすい点に注意が必要です。本章のポイントを押さえ、次章では実際のエラーログ解析へと進みます。

【お客様社内でのご説明・コンセンサス】
技術担当者はrsyncが初回完全コピー後にタイムスタンプとサイズ差で更新部分を検出する仕組みを上司へ説明し、属性保持オプションの設定漏れによる欠落リスクを共有してください。
【Perspective】
差分検知の精度を上げるには–checksumオプションを併用できますが、CPU負荷と転送時間への影響を勘案し、運用環境でのテストを必ず実施してください。
エラーログの読み方:代表的な出力例と解析ポイント
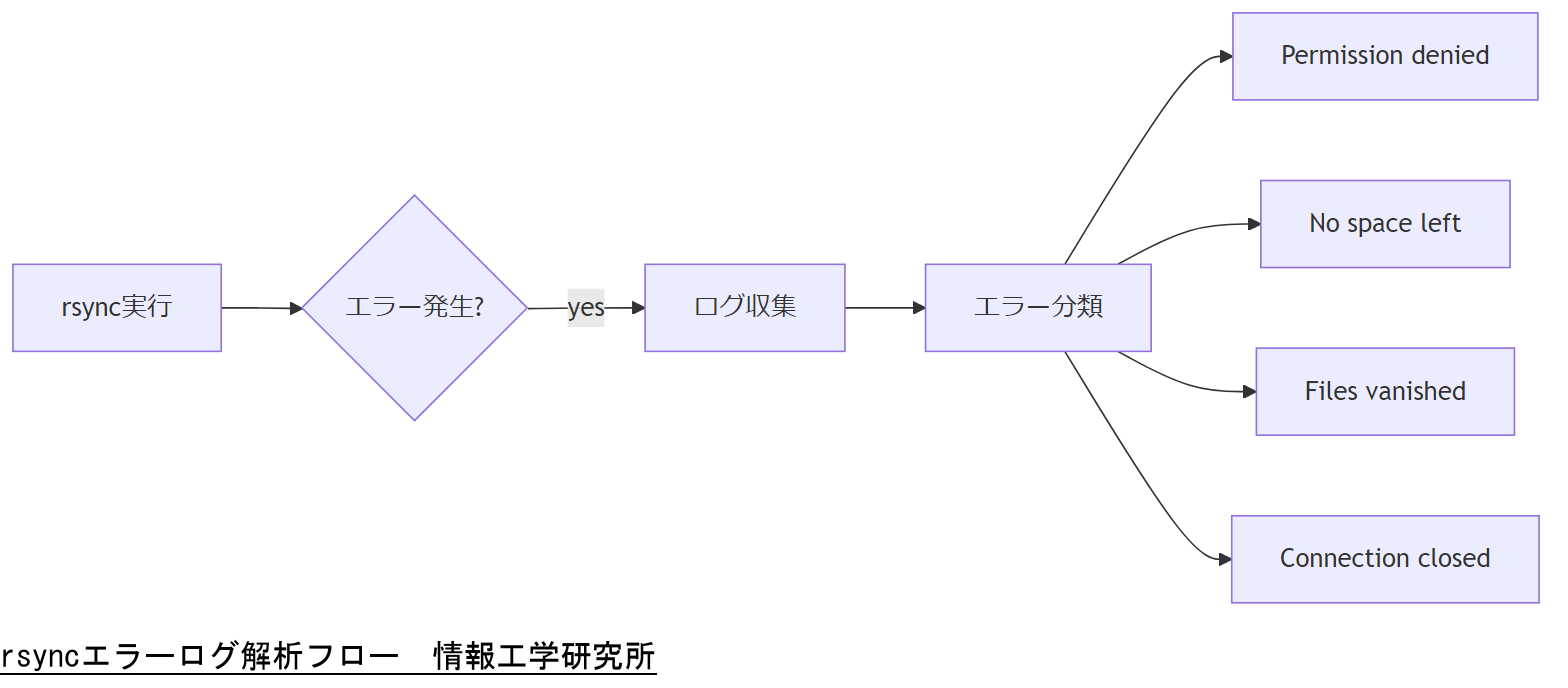
rsync実行時の標準出力・標準エラー出力には、原因を特定するための重要な情報が含まれています。本章では、頻出するエラーメッセージ例とその意味、解析のための着眼点を整理します。
表:代表的なrsyncエラーメッセージ一覧| メッセージ | 原因と意味 |
|---|---|
| rsync: mkstemp “/path/to/file.XXXXXX” failed: Permission denied (13) | 書き込み権限がないため、一時ファイル作成に失敗 |
| rsync: write failed on “/path/to/file”: No space left on device (28) | ディスク容量切れで書き込みが停止 |
| rsync error: some files vanished before they could be transferred (code 24) | 転送中にファイルが消失または移動された |
| rsync: connection unexpectedly closed (code 255) | ネットワーク切断やremote shellの異常終了 |
解析ポイント
各エラーに対し、以下の手順で原因を絞り込みます。
- 権限エラー:対象ディレクトリ・ファイルの所有者・パーミッションを確認
- 容量エラー:dfコマンドで空き容量をチェックし、必要に応じて不要ファイルを削除
- 消失ファイル:転送直前のファイル一覧をログに残し、消失タイミングを把握
- ネットワーク切断:pingやssh接続の安定性を検証
【お客様社内でのご説明・コンセンサス】
技術担当者はログ内のエラーコードと原因対応策を一覧化し、上司へ権限設定や容量計画の見直し提案を共有してください。
【Perspective】
エラー対応策を自動化スクリプトに組み込む際は、想定外エラーへのフォールバック処理を必ず追加し、再現テストを徹底してください。
ブロック損失の発生原因:ネットワーク/ファイルシステム観点
差分転送時にファイルの一部ブロックが欠落する主な要因は、ネットワーク品質の低下やリモート側のファイルシステム障害です。本章では、それぞれの観点から発生メカニズムを整理します。
表:ブロック損失発生要因一覧| 要因カテゴリ | 具体的事象 |
|---|---|
| ネットワーク | パケットロス、遅延急増、TCP再送タイムアウト |
| ファイルシステム | ジャーナリング不整合、ハードウェア障害、キャッシュ未同期 |
| リモートシェル | ssh接続途切れ、セッションタイムアウト |
原因メカニズム
パケットロスや再送遅延が繰り返されると、rsyncがブロック受信をタイムアウト扱いし、転送対象から除外する場合があります。また、リモート側でファイルシステムが不整合状態にあると、書き込みが途中でロールバックされ、データ欠落が生じます。

【お客様社内でのご説明・コンセンサス】
技術担当者はネットワーク遅延によるTCP再送やファイルシステムのジャーナリング不整合が欠落原因となる点を整理し、回線品質改善やファイルシステム保守計画の必要性を上司へ報告してください。
【Perspective】
ネットワーク監視ツールでパケットロス率を常時可視化し、ファイルシステムの定期チェック(fsckなど)を運用ルールに組み込んでください。
失われたブロックの検出方法:–checksumオプション活用術
rsyncの標準比較はタイムスタンプとサイズを用いますが、差分検知で見落とされたブロックを洗い出すには–checksumオプションを利用します。本章では、チェックサムによる全ブロック検証手順と応用例を解説します。
表:–checksumオプション活用時の検証パターン| 検証モード | 概要 | 所要時間影響 |
|---|---|---|
| デフォルト | タイムスタンプ+サイズ比較のみ | 最速 |
| –checksum | 全バイトのCRCチェックサム比較 | 遅延増大 |
| –checksum-dir | ディレクトリ単位のチェックサム比較 | 中程度 |
実践手順
1. rsyncに–checksumオプションを追加
2. 初回は完全検証モードで実行(時間がかかります)
3. 検証後に差異リストをログ化し、欠落ファイルを特定
4. 特定ファイルのみ再同期を実行

【お客様社内でのご説明・コンセンサス】
技術担当者は–checksumオプション実行後のログファイルを上司へ提示し、検証時間と精度のトレードオフを合わせて説明してください。
【Perspective】
チェックサム検証を自動化する場合、実行スケジュールを業務時間外に設定し、負荷集中を避ける運用設計を行ってください。
ブロック回収コマンド実践:–partial-dir+再同期手順
一時ファイル保存機能(–partial-dir)を用いることで、転送途中で中断されたブロックを効率的に回収できます。本章ではpartial-dirディレクトリの設定方法と再同期実行ステップを具体例とともに示します。
表:–partial-dirオプション利用例| コマンド | 説明 |
|---|---|
| rsync -a –partial-dir=.rsync-part src/ dest/ | 中断ブロックを.rsync-partに一時保存 |
| rsync -a –partial-dir=.rsync-part –append-verify src/ dest/ | 既存部分に追記かつ検証 |
操作ポイント
partial-dirは中断データを保持し、再転送時の負荷低減につながります。また–append-verifyで部分データの整合性チェックを併用すると、欠落リスクをさらに抑制できます。

【お客様社内でのご説明・コンセンサス】
partial-dirによる一時データ保存と、append-verifyの組み合わせによる再同期フローを上司に説明し、作業手順書への反映を提案してください。
【Perspective】
一時ディレクトリの容量管理を忘れず、定期的に不要データの自動削除スクリプトを用意してディスク圧迫を防いでください。
大量データ転送時のパフォーマンスチューニング
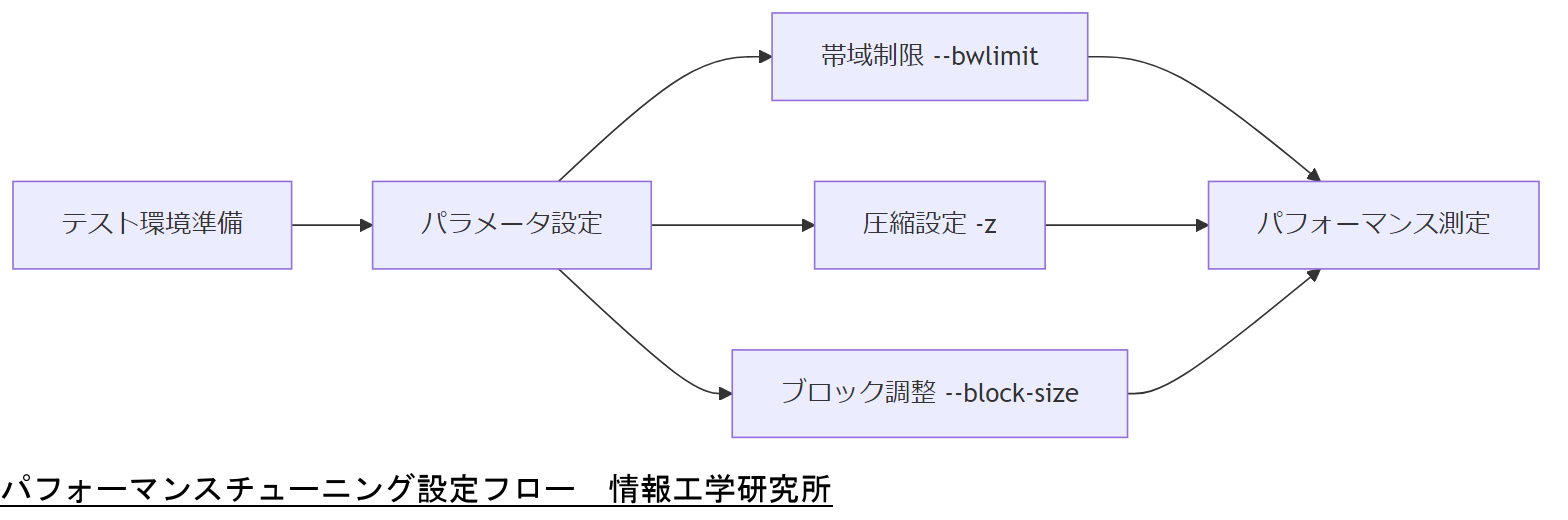
数百ギガバイト以上のデータ同期では、デフォルト設定のままでは転送時間が膨大になります。本章では、rsyncの主要チューニングパラメータと運用上のポイントを整理し、実運用での効果的な設定手順を解説します。
表:パフォーマンスチューニング項目| オプション | 役割 | 注意点 |
|---|---|---|
| –bwlimit=KBPS | 帯域使用上限設定 | 過度に絞るとスループット低下 |
| -z | 転送中圧縮 | CPU負荷増大に注意 |
| –inplace | 既存ファイル上書き | 中断時の一貫性にリスクあり |
| –block-size=SIZE | ブロック単位調整 | 大きすぎると検証時間増 |
設定フロー
まずテスト環境で各オプションを組み合わせ、転送速度とCPU負荷を測定します。次にcron等で夜間バッチ実行を設定し、運用環境のピーク時帯域への影響を最小化しながら、転送完了時間を最適化します。
【お客様社内でのご説明・コンセンサス】
技術担当者はテスト結果をまとめ、帯域制限や圧縮適用後の転送時間短縮効果を上司へ提示し、夜間バッチ運用の承認を得てください。
【Perspective】
本番適用前に必ず業務時間帯と非業務時間帯での転送ログを比較し、影響範囲を可視化した資料を残してください。
運用自動化と監視:cron+監視ツール連携例
日常のrsyncバッチ処理をcronで自動化し、NagiosやZabbixなどの監視ツールと連携することで、障害発生時に即座に通知を受け取り、対応時間を短縮します。本章では、設定例と運用フローを紹介します。
表:自動化・監視構成例| 項目 | 設定例 | 備考 |
|---|---|---|
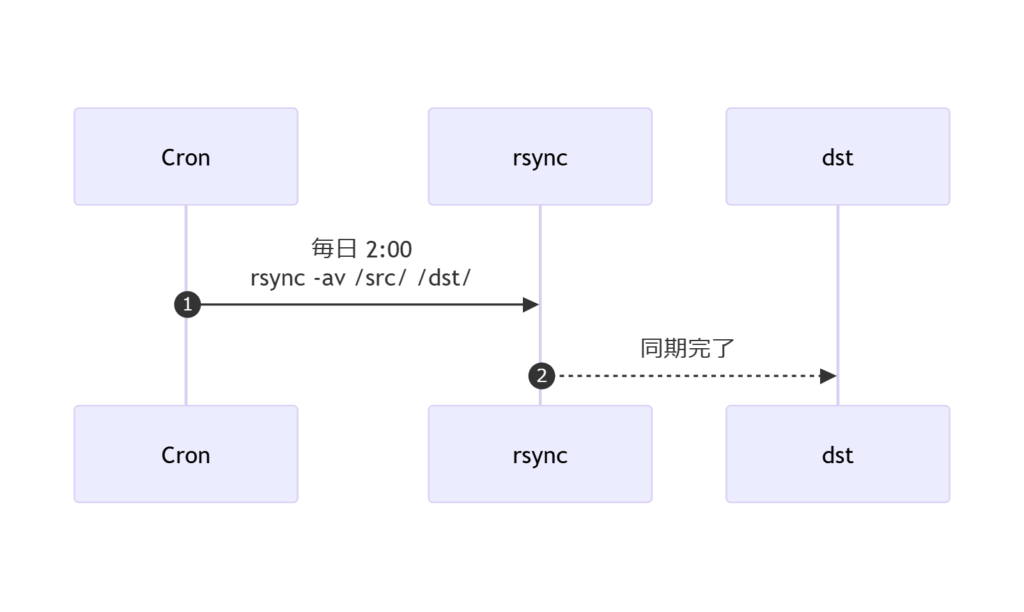
| cronジョブ | 0 2 * * * /usr/bin/rsync -a –delete /src/ /dest/ | 毎日02:00実行 |
| 監視プラグイン | check_rsync -H <ホスト> -P 873 | 接続確認+ログチェック |
| 通知手段 | メール/Slack連携 | 障害時に即時アラート |
設定手順
1. cronタブにジョブ登録
2. 監視サーバにcheck_rsyncプラグイン導入
3. 障害条件(エラーコード返却、ログ異常検知)を定義
4. 通知先(メール/Webhook)設定を完了

【お客様社内でのご説明・コンセンサス】
技術担当者はcron自動実行と監視ツールのアラート連携を説明し、ジョブ実行時間や通知フローの承認を上司へ得てください。
【Perspective】
自動化スクリプトと監視設定は別環境でテストし、本番適用前にフェイルオーバー時の動作確認を必ず行ってください。
トラブル時のBCP対応:緊急時・無電化時・システム停止時
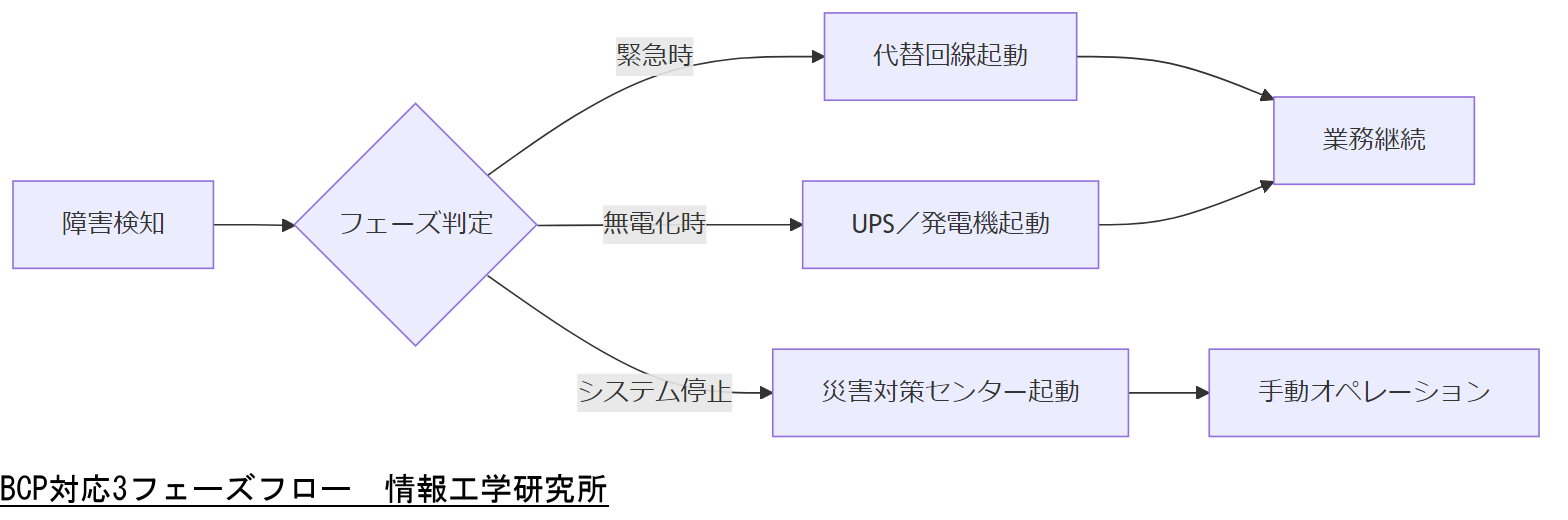
システム障害発生時には、BCP(事業継続計画)に基づき、緊急対応・無電化対応・システム停止対応の3段階でオペレーションを実行することが必須です。本章では各フェーズの役割と具体的な手順を解説します。
表:BCP対応フェーズと主なアクション| フェーズ | 主なアクション | 注意点 |
|---|---|---|
| 緊急時 | 一次復旧(代替回線切替・予備機起動) | 優先システムの定義と順序決定 |
| 無電化時 | UPS/非常用発電機起動・電源切替 | 燃料確保と起動手順の明確化 |
| システム停止時 | 災害対策センター起動・手動オペレーション実施 | 手順書の最新版配布と訓練実施 |
実践フロー
1. 緊急時発生:予備回線と代替サーバへ自動リダイレクト
2. 無電化検知:UPSアラーム→発電機自動起動→電源系統切替
3. システム停止:手動操作チーム招集→災害対策センター運用開始→人力バックアップ運用
【お客様社内でのご説明・コンセンサス】
技術担当者はBCPの3段階フェーズと主要アクションを上司へ共有し、優先システムや代替資源のリストを承認してください。
【Perspective】
それぞれのフェーズで使用する代替資源(回線・電源・人員)の可用性を定期的に検証し、訓練結果をBCP文書に反映してください。
コンプライアンス遵守:法令・ガイドライン整理
rsync運用では、データ転送・保存に関わる法令遵守が不可欠です。本章では、個人情報保護法や電子帳簿保存法など、主要な法令とガイドラインを整理します。
表:関連法令・ガイドライン一覧| 名称 | 概要 | 留意点 |
|---|---|---|
| 個人情報保護法 | 個人データの収集・管理基準を規定 | 暗号化・アクセス制御の実装必須 |
| 電子帳簿保存法 | 電子データの保存要件を規定 | タイムスタンプ付与が必要 |
| サイバーセキュリティ基本法 | 組織のセキュリティ対策を義務化 | リスクアセスメントの実施必須 |
実践ポイント
各法令に基づき、データ格納先への暗号化設定やタイムスタンプ取得の運用手順をマニュアル化してください。ログ保管期間や権限管理ポリシーも合わせて整備し、内部監査体制を強化します。

【お客様社内でのご説明・コンセンサス】
技術担当者は関連法令ごとに必要な技術要件(暗号化、タイムスタンプ、監査ログ)を整理し、上司への承認資料として提出してください。
【Perspective】
法令更新時には改正ポイントを即反映できるよう、社内手順書とチェックリストを常に最新化してください。
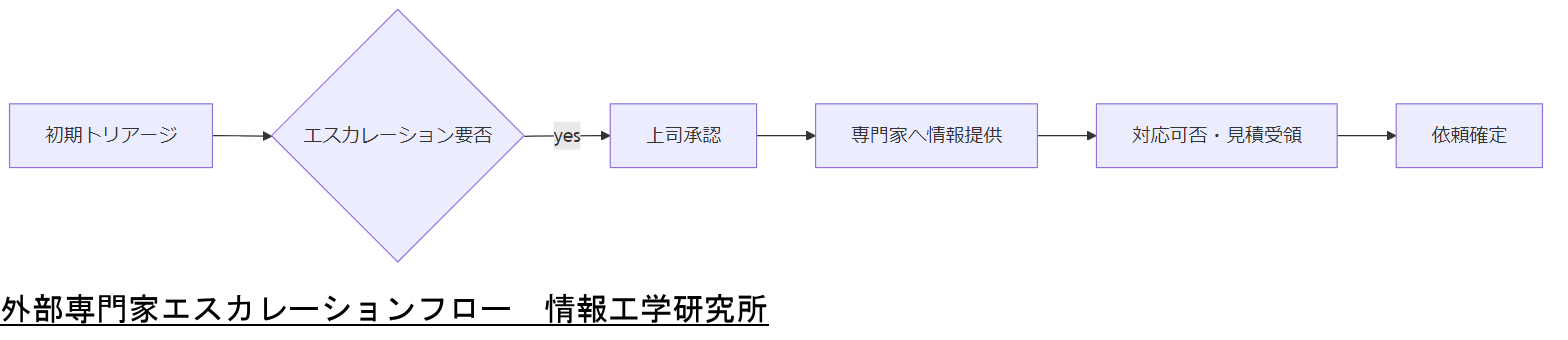
外部専門家エスカレーションフロー
自社内で対応困難な障害や高度な調査が必要な場合、外部専門家へのエスカレーション手順を定めておくことが重要です。本章では、判断基準と情報提供項目、連携ステップを整理します。
表:エスカレーション判断と提供情報| 判断基準 | 提供情報 | 対応期限 |
|---|---|---|
| 障害範囲不明 | エラーログ全文/システム構成図 | 2時間以内 |
| 復旧試行失敗 | 試行コマンド一覧/結果ログ | 1時間以内 |
| データ整合性懸念 | チェックサム結果/ファイルリスト | 即時 |
連携ステップ
1. 内部チームで初期トリアージ実施
2. 上司承認後、専門家コンタクト先に情報一式を送付
3. 24時間以内に対応可否と見積りを受領
4. 依頼確定後、進捗報告を定期的に実施
【お客様社内でのご説明・コンセンサス】
技術担当者はエスカレーション判断基準と提供情報項目を整理し、上司の承認プロセスを明確化してください。
【Perspective】
エスカレーション先の対応可能時間帯や連絡手段を事前に確認し、契約内容に基づく対応SLAs(サービスレベル合意)を把握しておいてください。
御社社内共有・コンセンサス
技術担当者が本記事で示した各章のポイントを社内で共有し、経営層や関係部署との合意を得るためのフレームワークを解説します。円滑な合意形成により、迅速な対策実行とBCP強化を実現します。
表:社内共有資料の構成例| 資料項目 | 内容 |
|---|---|
| 障害概要と影響範囲 | 発生事象の時系列、影響システムリスト |
| 原因分析と対策案 | 各章で提示した解析手順とコマンド |
| 承認依頼事項 | 予算、人員、スケジュール |
合意形成フロー
1. 技術チーム内部レビュー
2. 関係部署ヒアリング(総務・経理・法務)
3. 経営層向け資料レビュー
4. 最終承認と改善計画策定

【お客様社内でのご説明・コンセンサス】
技術担当者は合意形成フローを関係者に提示し、レビュー日程と責任者を明確に調整してください。
【Perspective】
合意プロセスはドキュメント化し、レビュー履歴を残すことで、後続の監査や改善時に活用できる証拠資料となります。
まとめと今後の運用改善提案
本記事で解説したrsyncの差分転送運用とエラー解析手順を総括し、継続的な信頼性向上のための運用改善提案を示します。定期的な検証と手順書の更新、監視自動化の強化により、障害発生時の復旧時間をさらに短縮できます。
表:運用改善提案一覧| 改善項目 | 内容 |
|---|---|
| 定期チェック自動化 | checksum検証とファイルシステム検査を週次実行 |
| 手順書の定期更新 | 法令改正や環境変化に合わせて半年ごとにレビュー |
| 監視アラート強化 | 障害閾値の細分化と通知ルート多重化 |
| 教育訓練実施 | 年1回のBCP訓練と障害時対応演習 |
次のステップ提案
まずは改善項目を優先度順に社内承認し、パイロットテストを実施します。テスト結果を踏まえた運用フロー改定後、全社展開および定常レビューサイクルを確立してください。

【お客様社内でのご説明・コンセンサス】
技術担当者は改善提案の優先順位とテスト計画を資料化し、上司および関係部署への承認取得を行ってください。
【Perspective】
改善サイクルを継続的に回すためにKPIを設定し、評価結果を四半期ごとに可視化して経営層へ報告してください。