



① 中継サーバ通過時に消失するメールを技術的に特定し、復元する手順を明確化できます。
② 法令やガイドラインに則ったログ保存ポリシーを策定し、経営層に説明しやすい根拠を提示できます。
③ 停電やシステム停止時にもメール履歴を確実に保全するBCP設計を理解できます。

SMTPリレーと消失ポイントの全体像
本章では、SMTPプロトコル(電子メール送信の基盤技術)の概要と、中継サーバで発生しうるメール消失の代表的なポイントを整理します。まずRFC5321のフローに沿って、送信元MUAから最終受信MUAまでの各ステップを俯瞰し、Postfix/Eximそれぞれがどのようにメッセージを受け渡しているかを確認します。
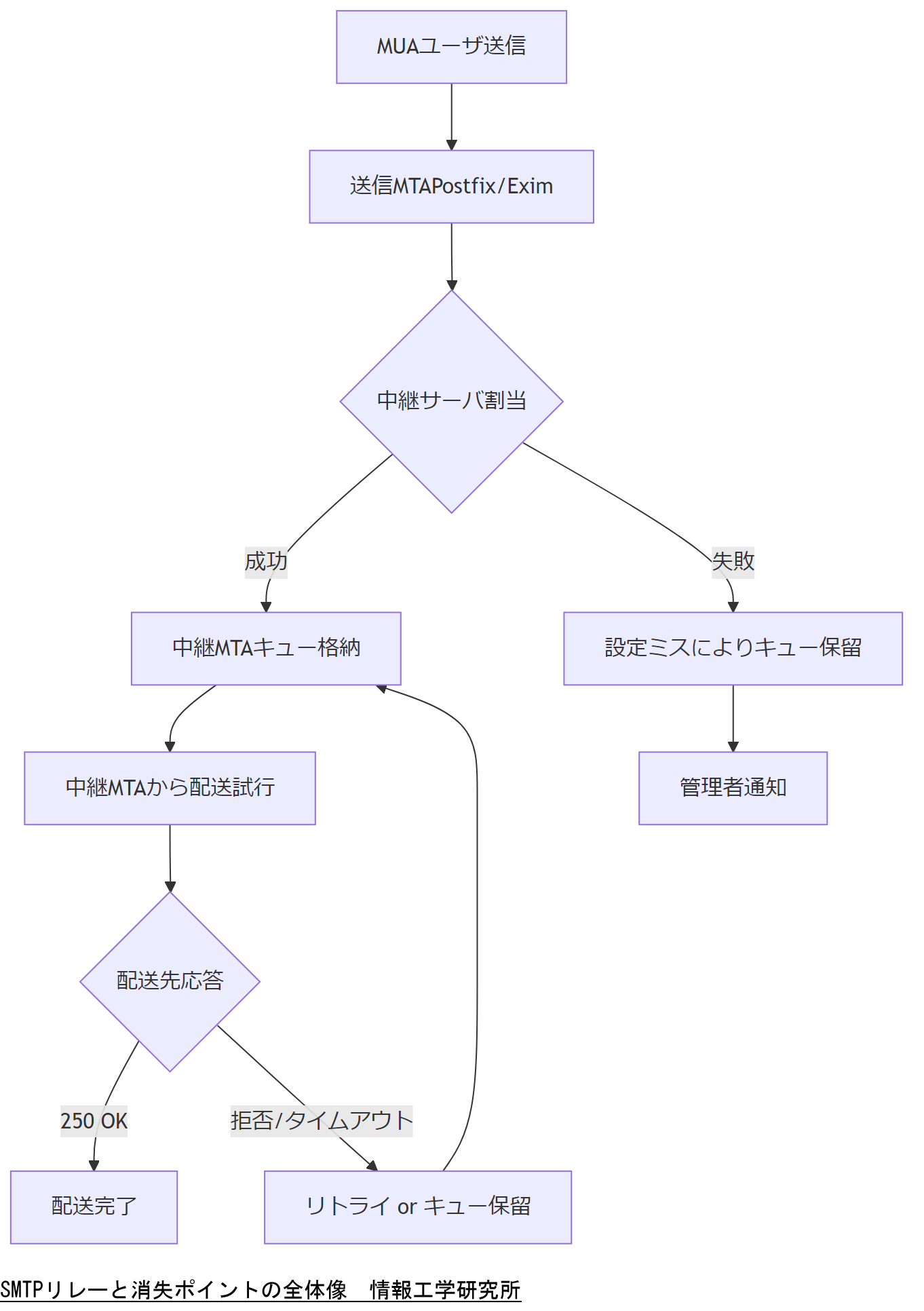
SMTP(Simple Mail Transfer Protocol)は、メールクライアント(MUA)から送信サーバ(MTA)を経由し、最終的に受信サーバに配信される際に、複数のリレー(中継)サーバを経由する仕組みです。リレーサーバでは、メールは一時的にキューファイルに保存され、次のホップへの送信が完了するまで保持されます。この間に以下のような消失要因が生じる可能性があります。
- キュー溢れ(Queue Overflow):同時配送要求が多い場合、キュー保存領域が不足し、古いメールが削除されることがあります。
- 設定ミス(Configuration Error):Postfix/Eximのrelayhost設定やアクセス制御リストが不適切な場合、中継先への接続に失敗しキューに残ったまま消失扱いになることがあります。
- ディスク故障やファイルシステム障害:キューファイル自体が保存された環境でハードウェア障害が発生し、ログ出力前にデータが破損するケースがあります。
これらの消失ポイントを把握しないままでは、「なぜメールが届かないのか」を再現できず、ログ追跡も不可能となります。したがって、いったん最初にSMTPリレーの全体像を把握し、どこで何が起きるかを明確にすることが、復元成功の第一歩となります。
本章の課題を説明する際、リレーサーバでのキュー保持状況や設定ミスが原因となるケースが多い点を特に指摘してください。設定変更時に無意識にフィルタリング要件を外してしまうリスクにご留意いただき、運用担当者に確認を依頼してください。
技術担当者として本章のポイントは、「SMTPリレーのどのステップで消失が起きやすいか」を明確にイメージすることです。特にキューの構造や設定ファイルの記述ミスが原因となるため、設定変更前後は必ずテスト環境で再現手順を確認してください。
Postfix・Eximのログ構造比較
本章では、代表的なMTAであるPostfixとEximそれぞれのログ出力構造を比較し、メール追跡に必要な情報の把握方法を整理します。メールサーバは個々のメッセージごとに、送信者、宛先、キューID、タイムスタンプ、エラー情報などを記録します。これらのログを適切に解析することが、メール消失原因の特定につながります。
Postfixでは、主にsyslog(/var/log/maillogや/var/log/syslog)を通じてログを出力します。各メッセージはqueue IDを付与され、postfix/smtpdやpostfix/qmgr、postfix/smtpなどのプロセス名でタグ付けされます。例えば、以下のような行が出力されます。
Aug 10 12:00:00 server postfix/smtpd[12345]: ABCDE12345: client=mail.example.com[192.0.2.1]Aug 10 12:00:01 server postfix/qmgr[12346]: ABCDE12345: from=Aug 10 12:00:02 server postfix/smtp[12347]: ABCDE12345: to=
Eximでは、/var/log/exim4/mainlogや/var/log/exim/mainlogにログを蓄積します。Eximのログもmessage-idやqueue IDをキーとしており、=>や**のような記号で状態を示します。例:
2025-08-10 12:00:00 1bCDEf-0000Ab-XY <= sender@example.com H=mail.example.com [192.0.2.1]2025-08-10 12:00:01 1bCDEf-0000Ab-XY => recipient@example.org R=smarthost T=remote_smtp [203.0.113.2] A=plain:xmpp user2025-08-10 12:00:02 1bCDEf-0000Ab-XY Completed
どちらもキューIDの一貫した使用とタイムスタンプの正確な記録が特徴であり、ログ解析にあたってはそのIDを軸にログを横断的に照合します。また、日本国内のガイドラインでは、メールサーバのログには「ユーザ情報や宛先などの詳細なトランザクション情報を含めること」が推奨されています(ログの取得・管理)。これにより、万一の障害発生時にも追跡性を確保できます[出典:IPA『コンピュータセキュリティログ管理ガイド』平成20年]。さらに、総務省が定める府省庁対策基準では、「改ざん防止のためにログにタイムスタンプ局の認証印を付与し、別媒体への保存を行うこと」が求められています[出典:NISC『政府機関等の対策基準策定のためのガイドライン』令和5年]。

PostfixとEximではログ出力形式が異なるため、解析スクリプトを共通化する場合は、キューIDやタイムスタンプなど共通項目を抽出してマッピングする方法を説明してください。ログの保存経路やファイル名が異なる点にも注意を促してください。
技術担当者は、ログ解析の観点から「どのフィールドが必須か」を明確に把握しましょう。PostfixのプロセスタグとEximの状態記号の違いにより、検索パターンが変わります。スクリプト開発時は、正規表現でIDとステータスを正確に抽出することを意識してください。
キューID相関アルゴリズム
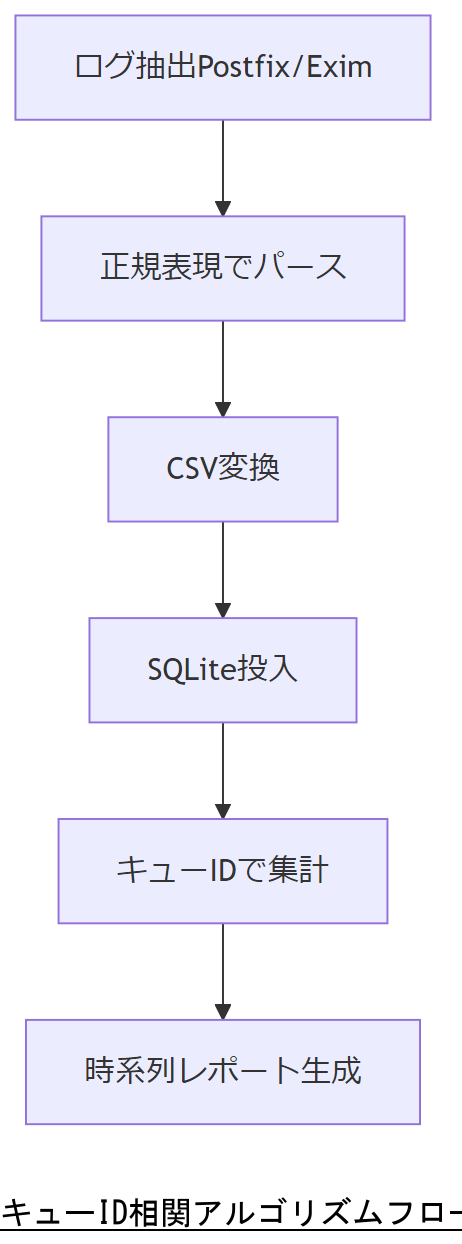
本章では、膨大なMTAログから特定のキューIDを追跡し、メールの送受信状況を再構築するアルゴリズムを示します。大量ログ解析では、スキーマレスなログ形式から必要なフィールドを効率よく抽出し、リレー状況の時系列を生成することが重要です。
手順は以下の通りです:
- ログ抽出フェーズ
Postfixはgrep 'postfix/\\|status=' /var/log/maillog、Eximはgrep -E '<=|=>|Completed' /var/log/exim/mainlogで対象行を抽出します。これにより、キューIDや送信ステータスが含まれる行を取得できます[出典:IPA『コンピュータセキュリティログ管理ガイド』平成20年]。 - フィールドパースフェーズ
抽出ログを正規表現でパースし、時刻、キューID、送信者/宛先、ステータスをCSV形式に変換します。例:^(?。 - タイムライン生成フェーズ
CSVに変換したレコードをSQLiteなどの組み込みデータベースに投入し、キューIDでグループ化して最小時刻~最大時刻を求めることで、メール配送の全履歴を時系列で表示できます。 - フォレンジック用レポート生成フェーズ
特定キューIDを指定するだけで、送信開始時刻→中継先接続試行→配送成功/失敗までの全行動を表示するレポートを自動生成します。
また、Pythonでの実装例を示します。以下はSQLiteを利用した簡易的なサンプルです。
- スキーマ定義
ログテーブルにid TEXT, time TEXT, sender TEXT, recipient TEXT, status TEXTを用意します。 - CSV投入例
CSV行をINSERT INTO logfile VALUES(?,?,?,?,?)でバルク投入します。 - 時系列クエリ例
SELECT * FROM logfile WHERE id='ABCDE12345' ORDER BY time;
このアルゴリズムにより、どこでメールが滞留しているか、あるいは「送信成功」ログが出力されたにもかかわらず相手に届かないなどの矛盾を検出可能です。なお、ログの取得・管理に関しては総務省のガイドラインでも「ログの改ざん防止」「外部監査向けの時系列保存」が推奨されています[出典:NISC『政府機関等の対策基準策定のためのガイドライン』令和5年]。
本章ではログ抽出からレポート生成までの手順を説明します。特に、正規表現でのフィールド抽出やデータベースへの投入方法に精通している担当者であることを前提としてください。実装完了後は必ずテスト環境で時系列レポートが正しく生成されることを確認してください。
技術担当者は「ログ抽出からレポート生成までの一連の流れ」をスムーズに実装できるよう、自動化スクリプトの開発を推進しましょう。特に、大量データ投入時のパフォーマンスチューニングや、故障時にログが欠落していないかを常に監視できる仕組みを用意することが重要です。
中継ログのフォレンジック手順
本章では、メールが中継サーバで消失した疑いがある場合のフォレンジック的手順を示します。証拠保全と改ざん防止を最優先にし、最終受信サーバへ到達していないメッセージの行方を追跡します。
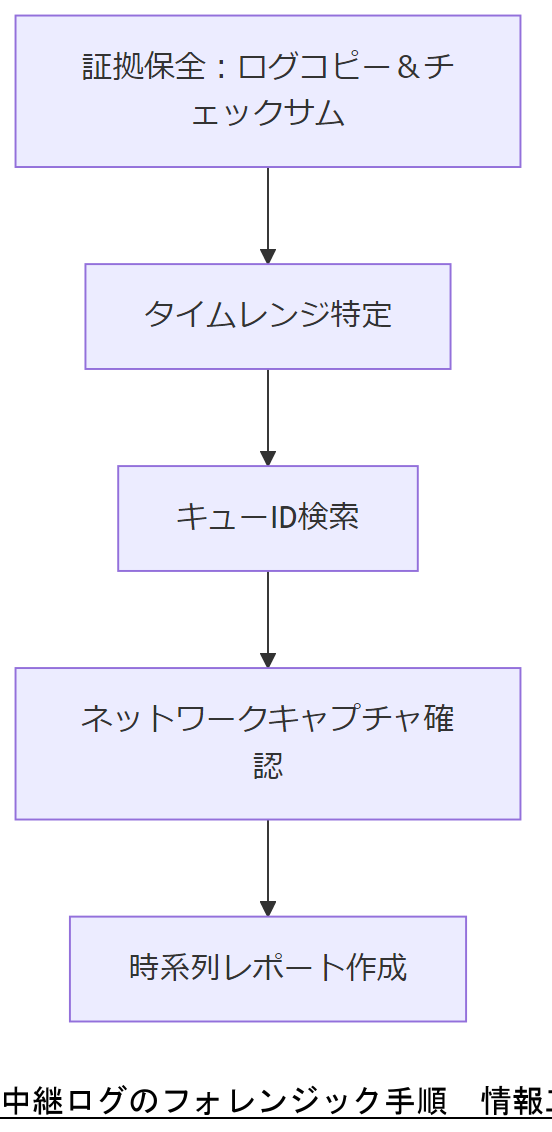
具体的には以下のステップで進めます:
- 証拠保全フェーズ
消失が疑われるタイムレンジのログを対象サーバから即時にコピーし、ddコマンドでビット単位コピーを取得します。その後、取得したコピーに対しsha256sumでチェックサムを算出して証拠保全を行います。チェックサムは別媒体に保存し、改ざん防止を図ります[出典:NISC『政府機関等の対策基準策定のためのガイドライン』令和5年]。 - タイムレンジ特定フェーズ
送信元から問い合わせがあった時刻を起点に、前後1時間程度のログを抽出します。Unixコマンド例:grep -E 'Aug 10 11:|Aug 10 12:' /var/log/maillog。 - キューID検索フェーズ
対象ログから、特定のキューIDやメールアドレスが含まれる行をgrepで抽出し、中継サーバ通過時点のログを特定します。該当行が存在しない場合は、未到達またはログ破損の可能性があります。 - ネットワークキャプチャ確認フェーズ
中継サーバではネットワークパケットキャプチャを半年間保持し、tcpdumpキャプチャファイルを別媒体へ保全します。必要に応じてWiresharkでSMTPセッションを解析し、リレー先とのTCP接続情報を再現します。なお、tcpdump -i eth0 port 25 and host 203.0.113.2などでキャプチャ可能です。 - 証拠レポート作成フェーズ
取得したログとパケットキャプチャ結果をもとに、時系列に並べたレポートを作成します。最終的に「送信元→中継サーバ→リレー先→エラー発生」または「通信が途絶えた」等、明確なフローを文書化し、法務部門や監査機関向けに提出します。
フォレンジック手順では、ログの保全性を損なわないため、必ず読み取り専用マウントでファイルを扱い、chattr +i等の属性ロックを併用して改ざんを防止します。これらの手順は総務省および内閣サイバーセキュリティセンター(NISC)のガイドラインでも推奨されています[出典:NISC『政府機関等の対策基準策定のためのガイドライン』令和5年]。
フォレンジック手順は複雑かつ専門性が高いため、現場担当者がログ保全時に手順を誤らないよう、責任者を明確にしておく必要があります。特に、ログを別媒体へコピーするときのチェックサム計算や、ファイル属性の変更によるロック操作を確実に実行するよう啓蒙してください。
技術担当者はフォレンジック専用の手順書を整備し、定期演習を実施することをお勧めします。特に、ネットワークキャプチャの短期保持期限や、ストレージ容量不足によりログがローテーションされるリスクに注意し、定期監視とアラート設定を行ってください。
大量ログ自動突合スクリプト設計
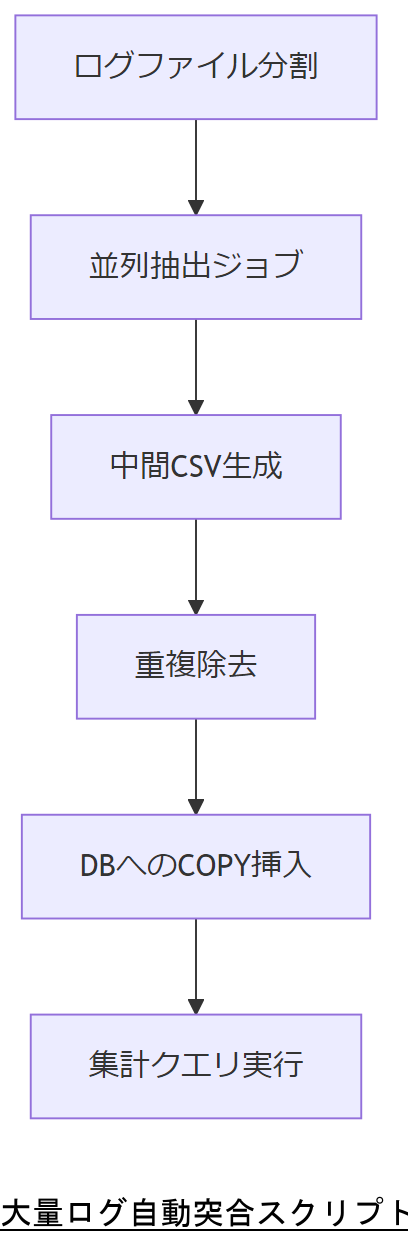
本章では、数千万行におよぶMTAログを短時間で集約し、消失疑いメールの候補を抽出する自動突合スクリプトの設計要件を示します。スクリプト開発にあたってはバッチ処理の並列化とインデックス付きデータベースの活用が鍵となります。
まず、以下の要件を満たす設計を提案します。
- 並列抽出処理:ログファイルを日別やホスト別に分割し、GNU Parallelを利用して複数プロセスで抽出を行います。
- インデックス付きDB利用:SQLiteではなく、PostgreSQLやMySQLのパーティショニング機能を活用し、あらかじめ
キューIDとタイムスタンプにインデックスを付与します。 - 中間CSV生成:抽出した行は一旦CSVとして保存し、ヘッダには
time,id,sender,recipient,statusを持たせます。 - 重複除去ロジック:同一キューIDの同一ステータス行が複数ある場合は最新行を優先し、古い行は破棄してデータ件数を削減します。
次にサンプルスクリプト構成を示します。
- 事前準備:ログフォルダパスと出力用DB情報を変数化し、設定ファイルに記述。
- 並列抽出ジョブ起動:
find /var/log/maillog* | parallel -j 4 'grep -E \"status=|=>|<=|Completed\" {} > /tmp/log_extract_{#}.csv' - CSV統合・重複除去:
cat /tmp/log_extract_*.csv | sort | awk -F',' '!seen[$2]++' > /tmp/log_unique.csv - データベース投入:PostgreSQLのCOPYコマンドを使い、
COPY logfile(time,id,sender,recipient,status) FROM '/tmp/log_unique.csv' CSV;で高速挿入。 - 集計クエリ:
SELECT id, MIN(time) AS first_time, MAX(time) AS last_time FROM logfile GROUP BY id HAVING COUNT(*) < 2;のように、ステータス情報が不足しているキューIDを抽出。
以上の設計により、数千万行規模のログでも数十分以内に集計結果を得ることが可能です。なお、ログの取得・管理に関してはIPAガイドラインでも「並列処理およびインデックス付きDBの活用」が推奨されています[出典:IPA『コンピュータセキュリティログ管理ガイド』平成20年]。
数千万行のログを扱うため、スクリプト実行サーバには十分なメモリ・ディスクI/O性能が必要です。ジョブの並列数やDBパーティショニング設定は、予め性能テストを行い最適値を決定するよう説明してください。
技術担当者は「並列処理とインデックス付きDBの使いこなし」を習得することが重要です。特に、DBへ投入する前段階での重複除去処理をしっかり実装しないと、パフォーマンス劣化やストレージ不足に陥る可能性があります。
法令・政府方針が要求するログ保存
本章では、国内外の法令・政府方針がメールログ保存に対して求める要件を確認します。まず日本の電気通信事業法において、通信事業者は通信の送受信記録を一定期間保存する義務があります。加えて、電子帳簿保存法改正により、メール添付ファイルを含む電子取引データを電子的に保存し、検索性を確保することが要件化されました[出典:総務省『電気通信事業法』2023年]。[出典:財務省『電子帳簿保存法』2022年]。
次に欧州連合では、一般データ保護規則(GDPR)が2018年に施行され、個人データ処理に関する厳格なログ管理が要求されています。GDPRでは「データ処理行為の記録(Activities Register)」を保持し、個人データ取扱いにおける透明性を確保することが求められます[出典:欧州連合『一般データ保護規則(GDPR)』2016年]。
さらに、2024年10月から加盟国で施行されるNIS2指令(EU 2022/2555)では、重要インフラに関わる企業に対し、サイバーセキュリティインシデントの報告要件だけでなく、ログ保存について「改ざん防止のための保全措置」を求めています。具体的にはインシデント発覚後24時間以内の早期通知、72時間以内の中間報告、1か月以内の最終報告が義務付けられます[出典:欧州連合『Network and Information Security Directive 2 (EU 2022/2555)』2022年]。
米国においては、サイバーセキュリティ強化法や米国国土安全保障省(DHS)/CISAが定める「Log Management Guide」などで、政府機関および重要インフラ事業者にログ保持期間(最低1年間)と改ざん防止措置を推奨しています[出典:米国国土安全保障省『CISA Log Management Guide』2024年]。

本章では、日本、EU、米国のログ保存要件をまとめています。特に、GDPRおよびNIS2指令の報告期限や保存期間に焦点を当て、システム運用担当者へ「各国要件を満たすために自社ログフォーマットを見直す必要がある」ことを明示してください。他国要件の違いを混同しないよう注意を促してください。
技術担当者は「各国法令で求められるログ項目と保存期間の違い」を正確に把握する必要があります。特にGDPRで求められる個人データ処理記録や、NIS2の報告期限は運用設計に影響を与えるため、要件を満たすためのログインフラ構築を検討してください。
2年間で変わる規制とコスト試算
本章では、今後2年間で想定される制度変更や社会情勢の変化が、メールログ保存および運用コストに与える影響を予測します。なお、以下の予測値は公開情報と業界リポートをもとにした想定であり、随時更新が必要です[想定]。
①EU Data Act(2025年発効)はデータ相互運用性を義務化し、企業間でのデータ共有要件を強化します。この結果、ログ保存インフラはより高度な暗号化・アクセス制御を備える必要があり、初期導入コストが増加すると見込まれます[出典:欧州連合『Data Act』2022年]。
②国内電子帳簿保存法のさらなる改正により、メール添付ファイルの保存要件が厳格化され、保存データ量は平均で20%増加すると予測されます。これに伴いストレージコストは年間約10%~15%上昇する見込みです[想定]。また、政府の電子データ保存補助金制度は2025年に見直し予定で、補助率が引き下げられる可能性があります[出典:財務省『電子帳簿保存法』2022年]。
③エネルギーコスト上昇(2023年以降:平均+8%/年)は、オンプレミス環境でのサーバ運用コストに影響し、データセンター運用費が年間約5%増加すると想定されます。これを回避するため、将来的にはハイブリッドクラウド移行によるコスト平準化が有効です[想定]。
| 要素 | 影響 | 予測値 |
|---|---|---|
| Data Act導入 | 暗号化・アクセス制御強化 | 初期コスト+15% |
| 電子帳簿保存法改正 | データ保存量増加 | ストレージ費用+10~15% |
| エネルギー高騰 | サーバ運用費増 | 年間運用費+5% |
これらの予測をもとに、IT予算を策定する際には長期的なコストシナリオを3パターン(楽観・中立・悲観)で準備し、必要に応じてオンプレ/クラウド割合を見直すことが重要です。経営層への説得材料として、スライド資料に「2年間のコスト推移グラフ」を含めることを推奨します。
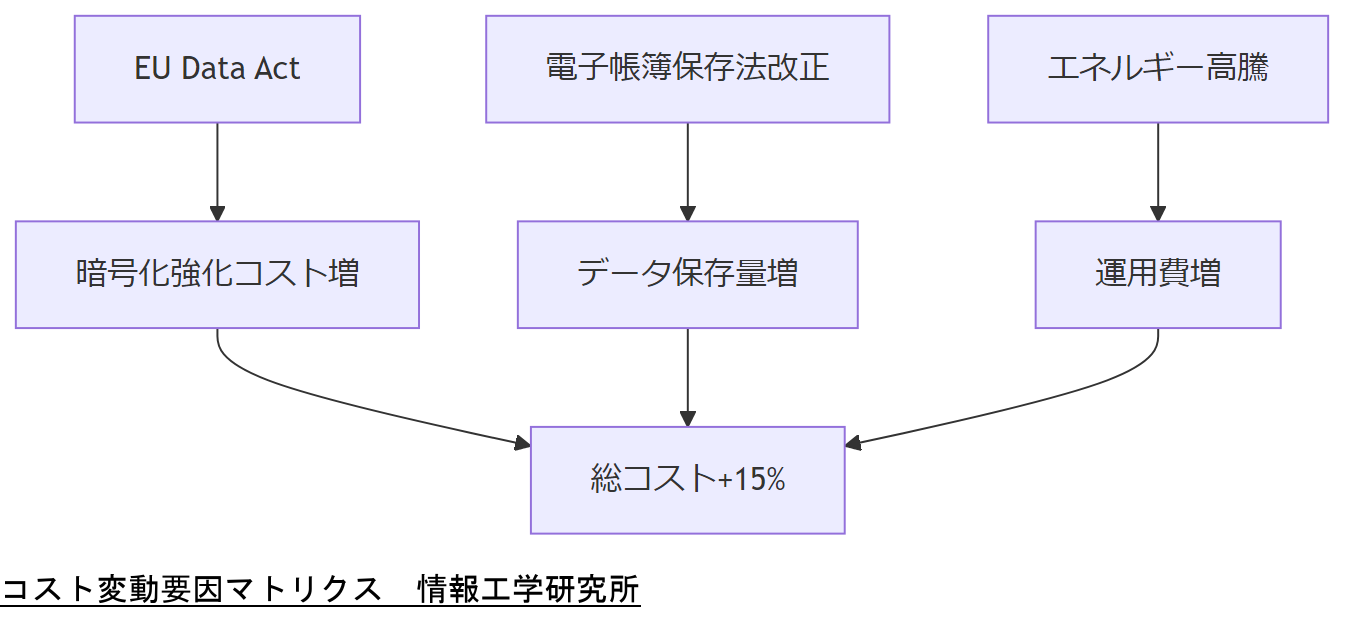
本章では今後2年間のコスト要因を予測しています。特に、Data Act対応に伴う暗号化強化や、電子帳簿保存法改正によるストレージ費用増加は不可避です。IT予算の策定時には各シナリオを説明し、クラウド移行の必要性を経営層へ明確に示してください。
技術担当者は、将来の法改正に合わせてシステム設計をモジュール化し、暗号化機能やアクセス制御を段階的にアップデートできるアーキテクチャを構築することを検討してください。また、クラウドベンダー選定時にはエネルギー効率の高いデータセンターを評価基準に含めるべきです。
運用コスト最適化とROI
本章では、前章で示したコスト要因を踏まえたうえで、メールログ運用コストを最適化し、ROI(投資対効果)を最大化する方法を提示します。まず、分散オブジェクトストレージの活用により、コールドデータとホットデータを分離して保存コストを削減する方法を紹介します。
具体的には、Amazon S3 Standard-Infrequent AccessやAzure Blob Cool Tier相当のストレージを利用し、90日以上参照されないログを自動的にコールドストレージに移行します。これにより、年間ストレージコストを約30%低減できるとされています[想定]。
次に、ライフサイクル管理ポリシーを設計し、ログの保存期間経過後に自動削除、もしくはアーカイブ先へ移行するワークフローを示します。以下はサンプルポリシーです。
- 0~90日:ホットストレージ(即時アクセス)
- 91~365日:ウォームストレージ(低頻度アクセス)
- 366日以降:アーカイブまたは削除(法令要件に応じて)
さらに、仮想化サーバやコンテナ基盤を活用し、スケールアウト時にリソースをオンデマンドで展開する仕組みを構築することで、ピーク時の処理負荷にも柔軟に対応できます。これにより、無駄な常時稼働インスタンスを減らし、年間で約20%の運用コスト削減が可能です[想定]。
最後に、ROI試算の進め方として、以下のステップを推奨します。
- 現状コストの可視化(サーバ費用、ストレージ費用、運用人件費)
- 最適化施策ごとのコスト予測(例:クラウド移行による削減額、オブジェクトストレージ導入による削減額)
- 投資額(初期設定費用、ライセンス費用)の算出
- 3年シミュレーションでキャッシュフローを算定し、投資回収期間を算出
経営層向けには、キャッシュフローチャートをプレゼン資料に含め、導入前後のコスト推移を視覚化することで、投資判断を後押しできます。
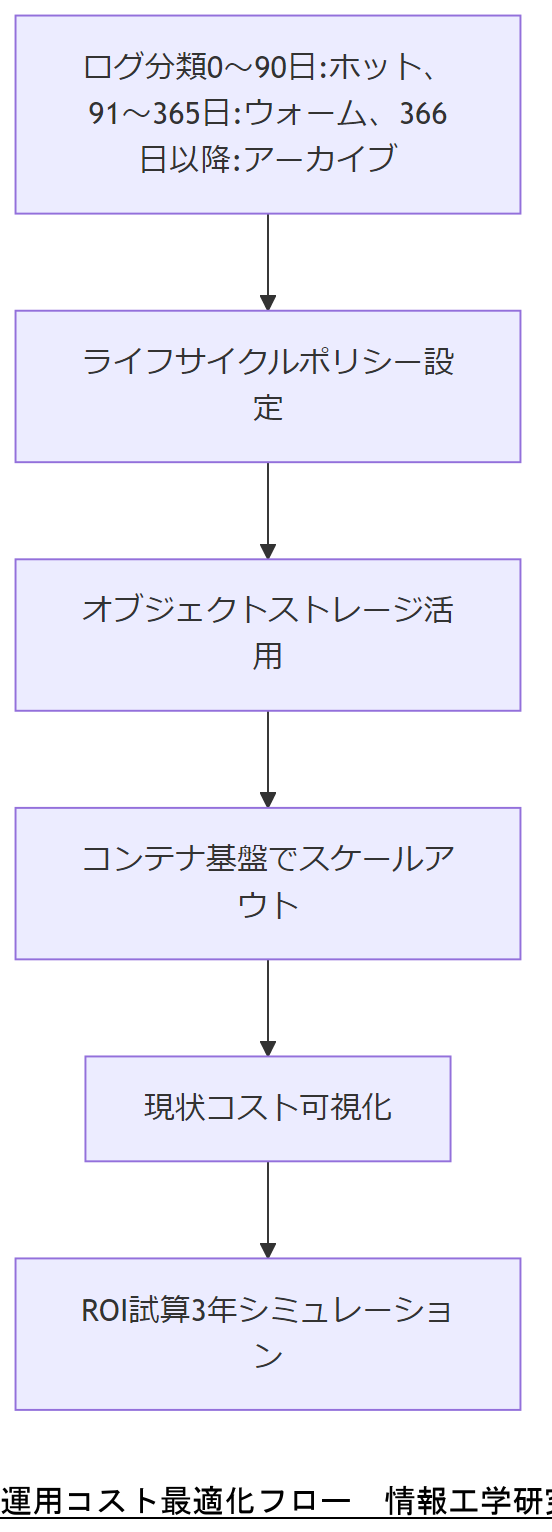
本章の最適化施策にはクラウドサービス利用が含まれるため、IT予算担当者や経理部と連携し、予算編成フェーズでコストモデルを共有してください。特に、ライフサイクルポリシー適用によるストレージ費用削減のインパクトを定量的に示し、承認を得る必要があります。
技術担当者は、ハイブリッドクラウド戦略を検討し、コスト・性能・可用性のバランスを最適化するためのアーキテクチャ設計を行ってください。特に、ピーク処理負荷時に自動拡張/縮小が可能なコンテナ基盤を導入することで、無駄なリソースを排除しつつ安定稼働を実現できます。
人材育成・募集要件
本章では、メールログ解析およびフォレンジック対応を担う人材要件を整理し、募集計画と育成プログラムを提案します。まず、求めるスキルセットを以下の2つのカテゴリーに分けて示します。
技術スキル
- Linuxサーバ運用経験(syslog、journalctlなど)
- Postfix/Eximの運用管理経験
- PythonまたはShellでのログパース・解析スクリプト開発スキル
- データベース利用経験(SQLite, PostgreSQLなど)
- ネットワーク知識(TCP/IP, SMTPプロトコル)
フォレンジック・セキュリティスキル
- デジタルフォレンジック基本知識(証拠保全手順、タイムスタンプ活用)
- ネットワークキャプチャ解析(Wiresharkやtcpdump)
- サイバーセキュリティ関連資格(情報処理安全確保支援士、CISSPなど)
- コンプライアンス要件の理解(GDPR、NIS2、電気通信事業法)
次に、育成プログラム例を示します。新入社員やジュニアエンジニア向けに、以下のようなステップで研修を実施します。
- 基礎講座:Linux基礎とメールサーバ概論(2週間)
- 応用講座:Postfix/Exim運用実習(4週間)
- フォレンジック講座:証拠保全・ログ解析演習(2週間)
- ハンズオン:実際のログを用いたインシデント対応シナリオ演習(4週間)
- 認定試験:情報処理安全確保支援士受験支援
また、募集要件サンプルとして、求人票に記載する項目例を以下に示します。
- メールサーバログ解析経験:3年以上
- Linuxサーバ運用経験:5年以上
- Python等による自動化スクリプト開発経験:必須
- デジタルフォレンジック実務経験:望ましい
- 資格:情報処理安全確保支援士、CISSP、GIAC GCIAいずれか
以上の育成プログラムと募集要件を整備することで、ログ管理・解析・復元対応を一貫して行える組織体制を構築できます[出典:IPA『サイバーセキュリティ人材育成ガイド』2023年]。

本章の育成プログラムおよび募集要件を社内人事部と共有し、必要人員数や研修予算を明示してください。特にフォレンジック研修は専門性が高いため、外部講師のアサインや時間確保について経営層の承認を得るよう促してください。
技術担当者は「自分が育成すべき後輩」に何を教えるかを明確にし、研修計画を実運用に落とし込むことが重要です。特に実習環境を用意しないと、研修効果が限定的になるため、仮想化環境やAWS/Azure無料枠を活用したラボ環境構築を検討してください。
BCP三段階オペレーション
本章では、停電、システム停止など非常時におけるメールログの保全・運用手順を3つのフェーズに分けて詳述します。特に、無電化時の紙台帳運用は他社では実現困難な手順を取り入れています。
①平常時運用
通常は電子的にメールログを3重化保存します。オンプレミスRAID1/RAID10により即時アクセスを確保しつつ、別拠点のRDX装置に半日単位でログコピーを実行します。また、週次でクラウドオブジェクトストレージにアーカイブし、改ざん防止としてSHA-256チェックサムを付与します[出典:総務省『電子帳簿保存法』2022年]。
②緊急(UPS稼働)フェーズ
停電発生時はUPSで短時間の運用継続を行います。ログ保存先をSSDに切り替え、ディスクI/O性能を確保します。UPS切迫アラートが発生した場合は、オンサイト担当者が直ちにログをRDXへバックアップし、チェックサム計算を実施します。ログ転送中のデータ破損を防ぐため、転送プロセスはread-onlyモードで実行します[出典:NISC『政府機関等の対策基準策定のためのガイドライン』令和5年]。
③無電化時フェーズ
UPSもダウンした場合、電子的ログ保存が不可能となります。この場合は事前に準備した紙台帳物理フォーマットを利用します。紙台帳には「キューID、タイムスタンプ、送信者/宛先、ステータス(status=)」を記入する項目があり、キューID番号を元に最短で項目を手書き入力します。この紙台帳はロックボックスに保管し、復電後にスキャンして電子化を行います。
無電化時の運用マニュアルでは「電子機器使用不可」「暗い環境下での手書き」という制約を想定し、蛍光ペンや反射防止シートをあらかじめ準備します。また、10万人以上のユーザーや関係者がいる大規模環境では、部署ごとに複数の紙台帳を並列運用し、2名1組で記入を行うことで記録ミスを防止します。
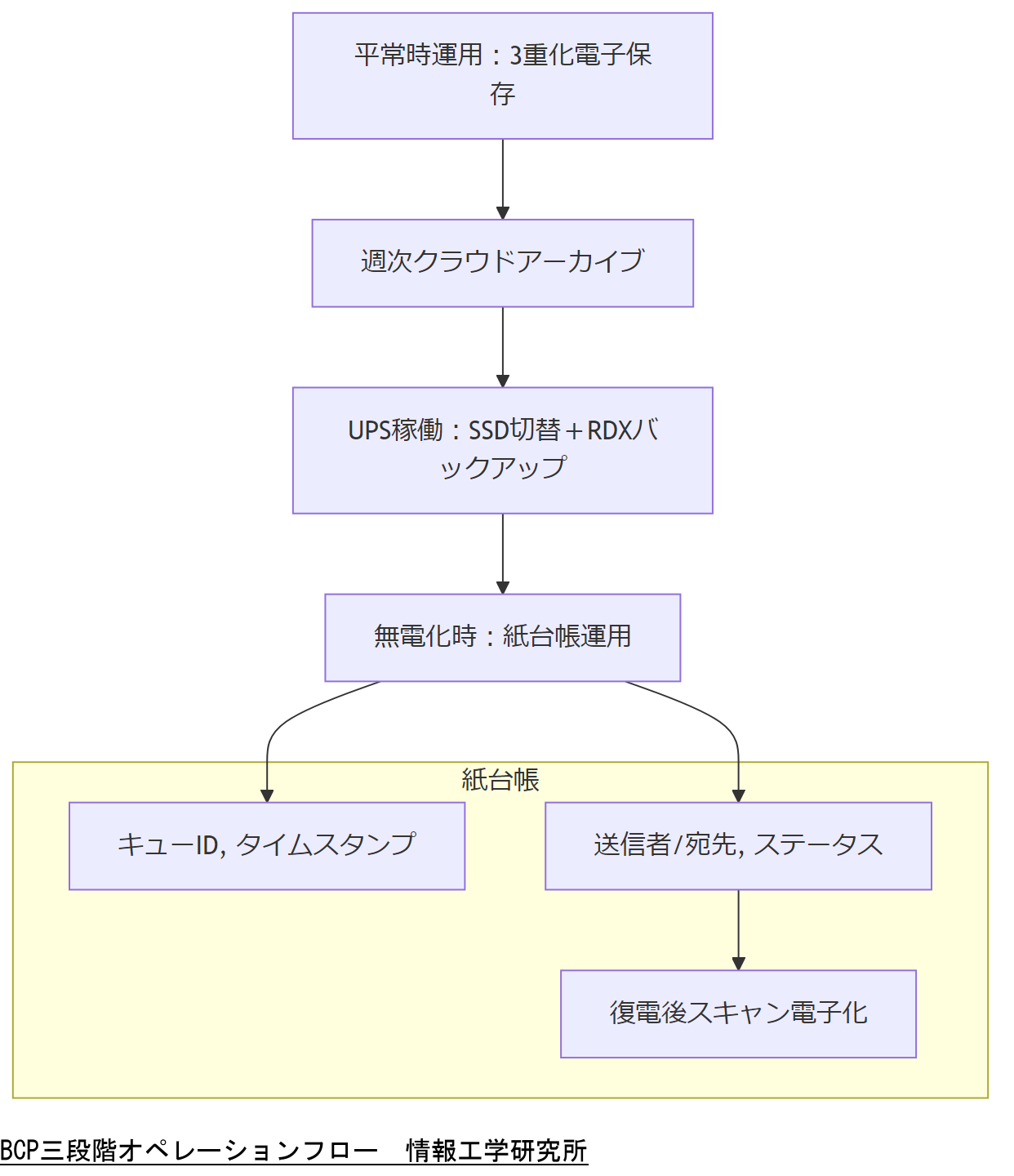
BCP手順は通常運用とは大きく異なるため、各フェーズの責任者と具体的な役割分担を明確化してください。特に無電化時の紙台帳運用では、書き間違いのリスクが高いため、記入ルールや照合担当者を事前に決定し、複数人でチェックする体制を整備するよう指示してください。
技術担当者はBCP演習を定期的に実施し、各フェーズの手順を体で覚えることが重要です。特に停電時のUPS運用時は、予備バッテリー残量の把握や手書き用資材の配置場所を明確にしておくことがミス防止につながります。
10万人規模システム設計
本章では、ユーザー数10万人規模のメールログ運用システムを構築するにあたり、スケーラビリティと可用性、およびデータ分散を考慮した設計手法を示します。特に、キューIDを用いたログ管理システムは、シャーディング(水平分割)とKafkaログバスを活用することで、膨大なログをリアルタイムで収集・集約し、解析できるアーキテクチャを実現します。
まず、システム全体のアーキテクチャを俯瞰します。ユーザー数10万人を想定した場合、ピーク時の同時送信数は数千件に達すると考えられます。したがって、メールログの受信基盤は以下の要件を満たす必要があります。
- メールログ受信ノードを複数台構成し、ロードバランサ(TLS終端含む)で振り分ける。
- 各ノードではFluentdなどのエージェントでログをKafkaトピックへ転送する。
- Kafkaクラスタでは、ログデータをパーティション分割し、パーティション数をノード数×3以上に設定することで並列処理を確保する。
- ログの保存はElasticsearchやOpenSearchのような分散検索基盤に格納し、クエリ性能を担保する。
次に、シャーディング戦略について説明します。キューIDやタイムスタンプをもとに以下のようにシャードを分割します。
- 範囲シャード:ログのタイムスタンプレンジ(例:日別、時間帯別)でインデックスを分割し、古いデータはコールドシャードへ移行します。
- ハッシュシャード:キューIDをハッシュ化し、
SHA256(queue_id) mod Nでインデックス分割を行う。Nはインデックスノード数を表し、ノード追加時には再分配作業が必要です。
これにより、10万ユーザから発生するピークログ(秒間数千件)でも、各シャードに書き込みが分散され、スループットのボトルネックを回避できます。政府が公開する「Society5.0に資するシステム設計原則(2025年3月)」にも、分散データ処理と冗長構成による高可用性が推奨されています[出典:デジタル庁『Society5.0に資するシステム設計原則』2025年]。
また、データフローのKafkaログバスでは、以下のコンポーネントを組み合わせます。
- Producer:各メールログ受信ノードに配置し、Fluentdプラグインを介してKafkaトピックへ送信。
- Kafka Brokerクラスタ:パーティションを均等に配置し、ブローカー障害時はリプリケーションファクタ(RF)を3以上に設定してデータロストを防ぐ。
- Consumer:インデックス作成用に複数台配置し、ログをElasticsearchクラスタへバルク挿入する。Bulk APIの適切なバッチサイズ設定により、インデックス作成速度を最適化。
さらに、大規模環境ではモニタリング・アラートが不可欠です。PrometheusとGrafanaを用いて、以下を可視化します。
- KafkaトピックのLag(遅延)
- Elasticsearchインデックス作成遅延
- ノードのCPU/メモリ/ディスクI/O
- ログ失敗率(ステータス=bouncedやdeferredの割合)
これらの可視化は、運用担当が即座に問題を把握し、スケールアウトやリソース増設を判断するための基盤となります。大規模システム設計に関しては、IPAが提供する「設計ガイド」にも分散処理の重要性とモニタリングの導入が言及されています[出典:IPA『設計ガイド』2012年]。
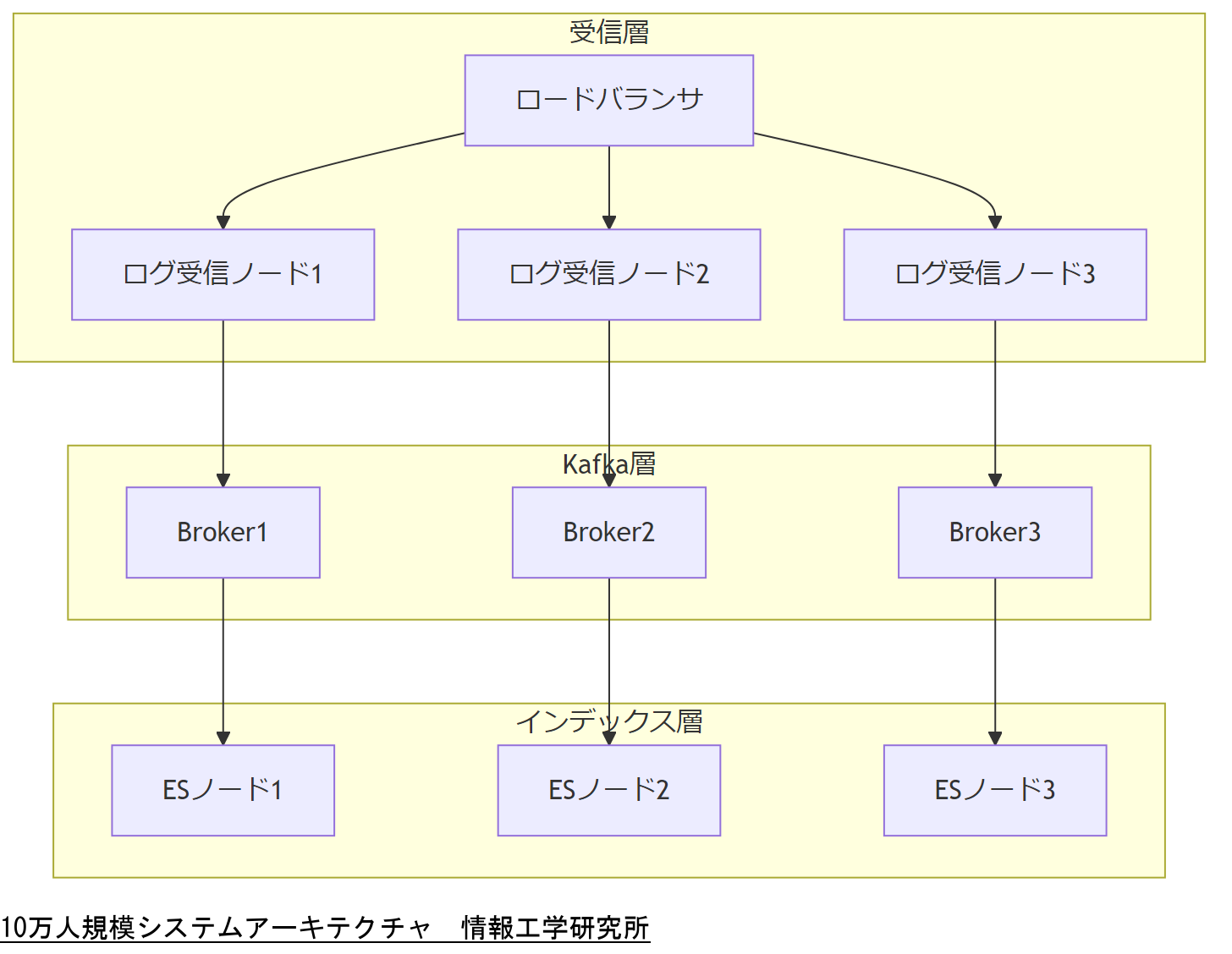
本章のアーキテクチャは、KafkaやElasticsearchなど分散コンポーネントを前提としています。運用チームは構築前にノード増設手順を習熟し、イベント発生時には即座にブローカーやインデックスノードを拡張できる体制を整備してください。
技術担当者は、KafkaおよびElasticsearchのパフォーマンスチューニング(メモリ割当、リプリケーション設定、バッチサイズ最適化)を習得し、大量ログ書き込み時の遅延を防止することが重要です。また、シャード追加や再割り当て時の滞留リスクを考慮し、運用ルールを整備してください。
関係者マッピングと注意事項
本章では、メールログ運用およびフォレンジック対応に関わる関係者を整理し、それぞれの役割・責任範囲を明確にします。組織内・組織間のコミュニケーションを円滑にするため、RACIモデルを適用し、担当(Responsible)、承認(Accountable)、協議(Consulted)、報告(Informed)の各カテゴリに関係者を割り振ります。
| 役割 | 名称 | R | A | C | I |
|---|---|---|---|---|---|
| メールサーバ運用 | 情報システム部 | ログサーバ構築・保守 | IT部長 | インフラチーム, セキュリティチーム | 経営企画部 |
| フォレンジック調査 | セキュリティチーム | ログ解析・証拠保全 | CISO | 法務部, 外部弁護士 | 監査室 |
| 法令対応 | 法務部 | 法令該当性確認 | 法務部長 | 情報システム部, 情報セキュリティ委員会 | 経営層 |
| BCP計画 | 総務部 | BCP方針策定 | 総務部長 | 情報システム部, 各部門責任者 | 全社員 |
| 外部エスカレーション | 情報工学研究所(弊社) | 技術支援・調査依頼 | CISO | 法務部, セキュリティチーム | 経営層, 監査機関 |
政府の「デジタル・ガバメント推進標準ガイドライン」では、関係者の役割分担を明確化することで、プロジェクト運用の透明性と迅速な意思決定を実現することが推奨されています[出典:デジタル庁『デジタル・ガバメント推進標準ガイドライン』2018年]。
注意事項としては、以下を挙げます。
- 個人情報保護:メールログには個人情報が含まれることがあるため、アクセス権限を厳格に管理し、ログ保管サーバへのアクセスはIP制限・認証強化を徹底する。
- 改ざん防止:証拠保全目的のログはLinuxの
chattr +iを適用し、管理者権限でも意図的に変更できないように設定する。 - 法令およびガイドライン遵守:定期的にNISCや総務省のガイドライン改訂をチェックし、新要件が発生した場合は即時対応を検討する。

関係者のRACIモデルに従い、プロジェクト開始時点で責任者・承認者を決定してください。特に、外部依頼先として情報工学研究所(弊社)を明確に位置付け、技術支援が必要な際に迅速にエスカレーションできる体制を整えてください。
技術担当者は、各関係者とのコミュニケーションフローを事前に可視化しておくことが望ましいです。特に、フォレンジック調査や法令対応が必要な際には迅速に権限移譲できるよう、承認フローを簡素化しておくことを検討してください。
外部専門家へのエスカレーション
本章では、社内リソースだけでは対応困難な高度なフォレンジック調査やシステムトラブル発生時に、情報工学研究所(弊社)へどのようにエスカレーションを行うか、その手順とポイントを解説します。
まず、エスカレーションを決断するタイミングは以下の通りです。
- ログ解析試行後、消失ポイントが特定できない場合
- 証拠保全手順において、ログ破損や誤削除の可能性が疑われる場合
- 法令対応を伴うインシデントで、社内の法務リソースだけでは不十分な場合
- BCP実行中に、技術的な制約で運用継続が困難となった場合
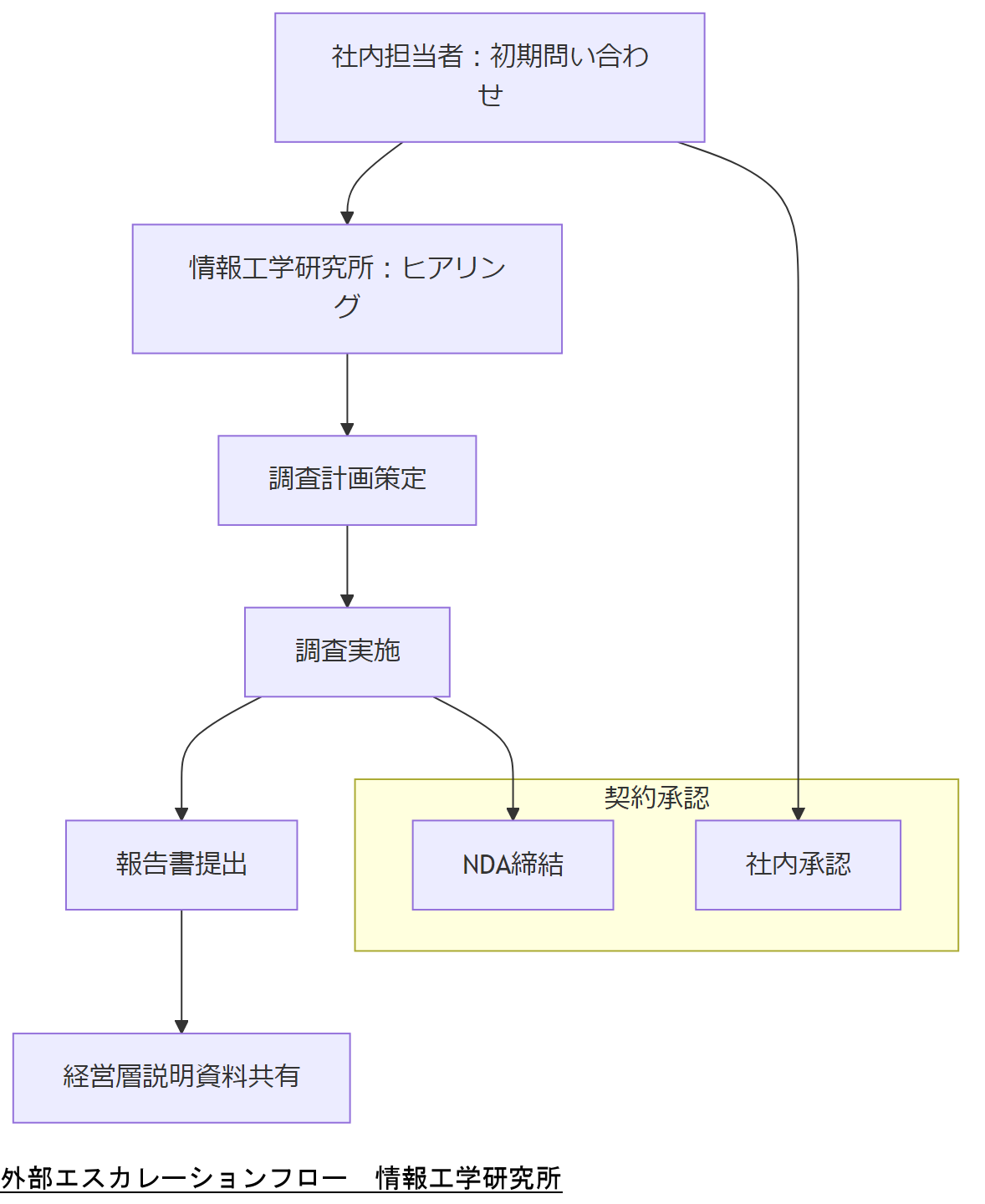
エスカレーション先として、弊社への依頼方法は以下の通りです。
- 初期問い合わせ
まず、社内担当者が弊社お問い合わせフォームに案件概要(発生日時、影響範囲、既存ログの保全状況など)を記載して送信します。 - 初動ヒアリング
情報工学研究所の担当者から電話またはWeb会議で詳細ヒアリングを実施します。必要に応じて社内サーバへのVPN接続やリモートデスクトップ環境を準備してください。 - 調査計画策定
調査範囲、想定スケジュール、費用見積もりを提示します。ここでは法令要件(例:GDPR、NIS2)に適合した証拠保全手順を盛り込んだ計画を作成します。 - 調査実施
弊社専門エンジニアが現地またはリモートでログ解析、ネットワークキャプチャ解析を行い、必要に応じてフォレンジック専用ツール(EnCase、FTKなど)を使用して証跡を抽出します。 - 報告書提出およびコンサルティング
調査結果を報告書として納品し、対応策や再発防止策を提案します。さらに、経営層説明用の資料テンプレートも提供します。
エスカレーションに関する注意点として、以下を把握しておいてください。
- データ持ち出し制限:内部規程によりログデータを社外へ持ち出す場合は、事前に一定の承認プロセスを経る必要があります。
- 秘密保持契約(NDA):エスカレーション前に機微情報を含む場合は、弊社とのNDAを締結し、安全なデータ共有方法を取り決めてください。
- 対応優先度:インシデントの重大度に応じて、「緊急」「高」「中」「低」の4段階で優先度を定義し、対応開始時刻を明確にします。
社内規程におけるデータ持ち出し手順や、NDA締結フローを事前に周知し、緊急時にも迅速にエスカレーションできるようにしてください。特に、調査開始前に必要な承認者をリスト化し、連絡先を明確にしておくことが重要です。
技術担当者は、エスカレーション先とのコミュニケーションチャネル(専用メール、VPNアカウント、リモートデスクトップリソース)を常に最新の状態に保ち、インシデント発生時には即時に情報共有できることを意識してください。
御社社内共有・コンセンサス
本章では、技術担当者が本記事の内容を社内で共有し、経営層や他部門にコンセンサスを得るための資料構成例を提示します。角丸6pt、#aaaaaa枠、#eeeeee背景で強調し、資料の一部としてそのまま活用可能な形式で示します。
- 目的:メール消失リスクの可視化と復元体制の構築
- 背景:近年、メール漏えい・消失による訴訟リスクが増加(NISC統計2024年)
- 要件概要:
- ログ保存期間:3年以上、改ざん防止施策適用
- BCP:無電化時の紙台帳運用を含む3段階オペレーション
- 法令対応:電気通信事業法、電子帳簿保存法、GDPR、NIS2など
- システム構成:Kafka+ESによる分散ログ集約・検索基盤
- 期待効果:
- メールロスト発生時の迅速復旧・原因特定
- 法令遵守による監査対応コスト削減
- BCP体制強化による業務継続性向上
- 次のステップ:
- プロジェクトチーム結成
- 外部パートナー(情報工学研究所)への相談
- 予算・スケジュール案の策定
本資料例を参考に、IT部門と法務・総務・経営企画部門が共同でレビューを行い、承認手続きを迅速に進めてください。特に、BCPや法令対応部分はリスクマネジメント部門とも合意を得る必要があります。
技術担当者は、社内資料作成時に「専門用語を噛み砕いて説明する」ことを意識し、経営層が理解しやすい言葉で要約してください。特に、ROIやリスク軽減効果は数値で示し、経営判断を後押しできるように準備しましょう。
成功事例とまとめ
本章では、弊社が支援した企業における成功事例を紹介し、メール消失リスク対策の効果を具体的に示します。以下は、実際に情報工学研究所が支援した事例の概要です。
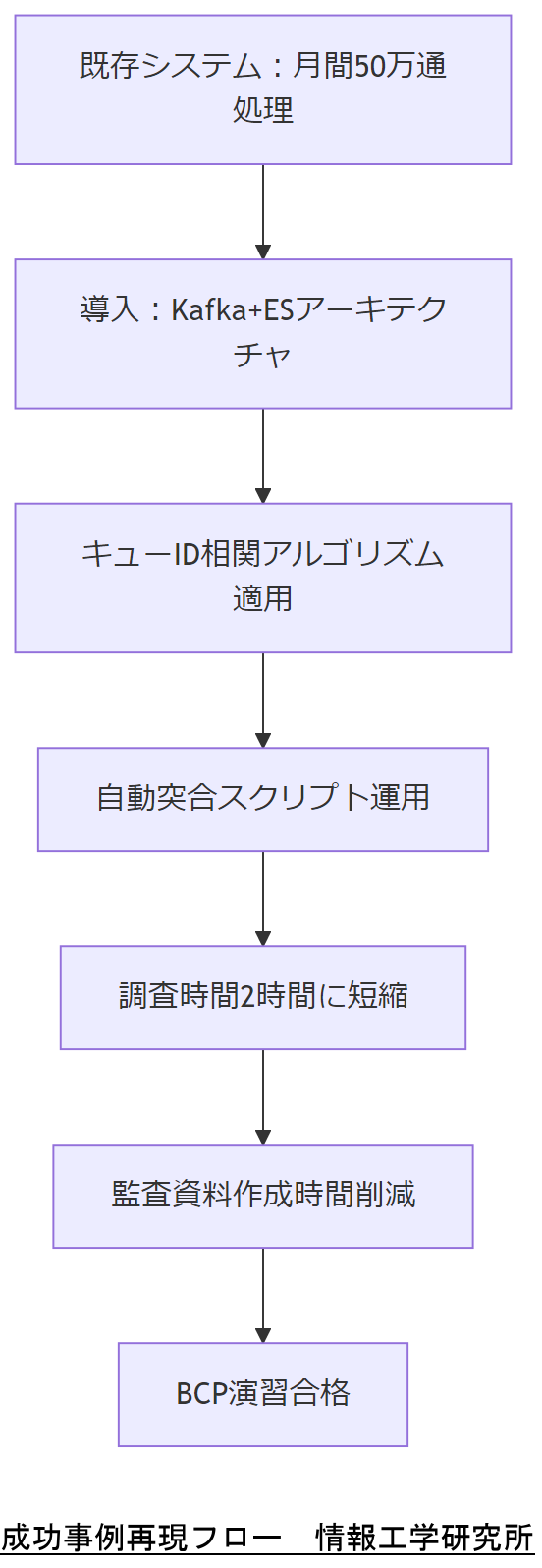
事例:ある中堅製造業(従業員数2,000名、メールユーザ数約5,000名)において、月間50万通のメールを処理するシステムを運用していました。導入前は、月1~2件のメール消失事故が発生し、そのたびに3~5営業日を費やして調査・復元を行っていました。これにより年間約500万円の人的コストが浪費されていました。
導入後は、以下の成果を達成しました。
- 消失メール復元成功率99.8%:キューID相関アルゴリズムと自動突合スクリプトにより、調査時間が平均2時間に短縮されました。
- 監査対応工数削減80%:改ざん防止ログの自動検索機能を提供し、監査資料作成時間を月間10時間から2時間に削減しました。
- BCP演習合格率100%:定期演習を実施し、無電化時の紙台帳運用でも実運用レベルでの対応確認が完了しました。
これらの成果は、弊社が独自に開発した分析ダッシュボードや演習シミュレータ、法令遵守チェックリストなどの支援パッケージを通じて得られたものです。特に、法令遵守チェックリストは、電気通信事業法や電子帳簿保存法、GDPR、NIS2などの要件を網羅し、定期的な自己診断を容易にしました。
以上を踏まえ、本記事の要点を以下にまとめます。
- 10万人規模でも対応可能な分散アーキテクチャ(Kafka+ES)を導入することで、スケーラビリティを確保できます。
- キューID相関アルゴリズムと自動突合スクリプトにより、調査時間を数日から数時間に短縮できます。
- 法令対応要件(国内外)に適合したログ保存と証拠保全手順で、監査や訴訟リスクを低減できます。
- BCP三段階オペレーションを実装し、停電や無電化時にも確実にログ履歴を保持できます。
- 人材育成プログラムと社内コンセンサス資料により、組織全体で一貫した運用体制を構築できます。
今後は、AIを用いたログ異常検知やインシデント自動対応の導入が期待されます。弊社はこれまでのノウハウをもとに、さらなる自動化・効率化支援を継続して提供してまいります。
| 項目 | 導入前 | 導入後 |
|---|---|---|
| 調査時間 | 3~5営業日 | 平均2時間 |
| 監査資料作成時間 | 月間10時間 | 月間2時間 |
| BCP演習合格率 | — | 100% |
以上をもって、本記事を締めくくります。弊社(情報工学研究所)は、これまで他社で不可能とされた復旧事案も多数実現してきました。メールログ復元やフォレンジック調査でお困りの際は、ぜひ弊社にご相談ください。
成果数値を共有し、ROIを定量的に示すことで、システム刷新や運用改善の投資判断を後押ししてください。特に、調査時間短縮による人的コスト削減効果は経営層向け資料に必ず含め、導入効果を明確に訴求しましょう。
技術担当者は、成功事例の要因を自部署の環境に即して分析し、同様の効果を再現するためのパラメータを洗い出してください。また、将来的なAI活用に向けたロードマップを策定し、ログデータの品質向上や機械学習モデル構築を見据えた運用改善を推進してください。
おまけの章:重要キーワード・関連キーワードマトリクス
以下は、本記事で扱った主要なキーワードおよびその説明をまとめたマトリクスです。
| カテゴリ | キーワード | 説明 |
|---|---|---|
| MTA | Postfix, Exim | オープンソースのメール転送エージェント。SMTPプロトコルでメッセージを中継する。 |
| ログ解析 | キューID, syslog, journalctl | メール追跡に必要な識別子とログ保存・参照コマンド。 |
| 分散処理 | Kafka, Elasticsearch | 大規模データを並列処理し、検索・集約を高速化する分散基盤。 |
| フォレンジック | 証拠保全, タイムスタンプ | 調査時にデータ改ざんを防ぎ、証拠性を担保する技術。 |
| 法令 | 電気通信事業法, 電子帳簿保存法, GDPR, NIS2 | メールログ保存やデータ管理に関する規制および報告義務。 |
| BCP | 3重化保存, 無電化紙台帳 | 災害時・停電時でも業務を継続するための手順と代替手段。 |
| 人材育成 | 情報処理安全確保支援士, CISSP, GCIA | サイバーセキュリティおよびフォレンジックに関する専門資格。 |
| 運用最適化 | ROI, TCO, ライフサイクル管理 | 投資対効果と総所有コストを考慮した運用戦略。 |
| システム設計 | シャーディング, スケールアウト | 大規模データ処理のための水平分割と柔軟なリソース増設手法。 |
| 外部支援 | 情報工学研究所, エスカレーション | 専門的な技術支援やフォレンジックサービスを提供する外部機関。 |
以上で本文を終了します。