Redfish APIのログサービスを活用し、ResourceRemovedイベントの検出から設定削除の原因分析、PATCHによる迅速な復旧まで実践的に解説します。
事業継続計画(BCP)の基本3重化構成と緊急時・無電化時・システム停止時の運用フェーズを連携し、事業継続性を確保する設計手法を紹介します。
個人情報保護法やBCPガイドラインの最新動向をフォローし、経営層向けにわかりやすく説明する資料作成のポイントを提示します。
- 出典:個人情報保護委員会『個人情報の保護に関する法律』2017年
- 出典:内閣府『事業継続計画策定支援ハンドブック』2018年
Redfish APIの基本とログサービス概要
Redfish APIは、サーバのハードウェア管理を標準化するRESTfulインターフェース仕様です。DMTF(Distributed Management Task Force)により策定され、BMC(Baseboard Management Controller)経由で電源制御やファームウェア更新、ログ取得などを統一的に操作できます。本章では、Redfish APIの構造と、その中でログを管理するLogServiceリソースの概要を解説します。
API仕様の背景
サーバ管理には従来 IPMI等ベンダー依存の仕様が用いられていましたが、複数ベンダー環境では運用が複雑化します。RedfishはJSON/HTTPSを用いるREST APIとして設計され、標準化されたURI空間とスキーマにより異機種混在環境での運用負荷を軽減します。
LogServiceリソースとは
RedfishのLogServiceは、BMCが保持する各種ログ(イベントログ、システムログ、安全性ログなど)を表すリソースです。LogServiceコレクションは`/redfish/v1/Managers/{managerId}/LogServices`以下にあり、各エントリは`/Entries`サブコレクションで個別に参照できます。
主なLogService種別
- SEL(System Event Log)…ハードウェアイベント記録
- IML(Integrated Management Log)…Redfish管理イベント
- Lclog…ベンダー独自のログサービス

技術担当者は上司に対し、Redfish APIがRESTfulな標準インターフェースであること、各LogServiceがサーバの稼働履歴を取得する役割を担う点を強調し、運用影響を共有してください。
技術担当者はRedfish APIのリソース階層とLogServiceコレクションの位置関係を正確に理解し、どのURIでログ操作を行うかを意識しましょう。
ログ取得手順と環境設定
Redfish APIでログを取得するためには、BMC(Baseboard Management Controller)へのHTTPS接続と適切な認証情報が必要です。まずは管理者アカウントを用意し、HTTPS通信を許可したクライアント環境を整えます。
認証方式の設定
一般的にRedfishではベーシック認証が用いられ、ユーザー名とパスワードをBase64エンコードしてHTTPヘッダーに含めます。また、より安全なトークン認証に対応するBMCも増えています。
HTTPS証明書の信頼設定
BMCが自己署名証明書を使用している場合、クライアント側で証明書を信頼リストに追加するか、curl等で証明書検証を無効化(-kオプション)します。ただし運用環境では証明書を発行機関から取得することが推奨されます。
ログ取得コマンド例
以下はSELログを取得するcurlコマンドの例です。
curl -k -u admin:password \
https://bmc.example.com/redfish/v1/Managers/1/LogServices/Sel/Entries
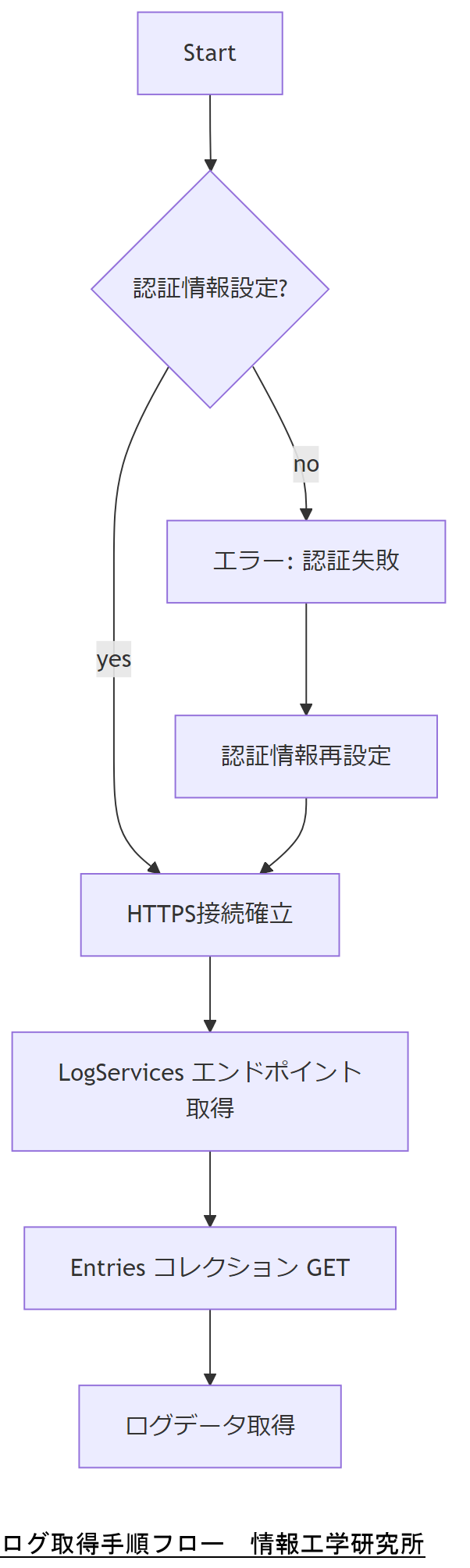
技術担当者は上司に、HTTPSと認証設定が正確でないとログ取得が失敗する点を共有し、証明書運用ポリシーの遵守を確認してください。
クライアント環境の証明書管理と認証方式を理解し、真偽性の担保とログ取得の安定性を両立させることを意識しましょう。
削除操作イベントの検出ロジック
LogEntryには
EventTypeによるフィルタリング
各エントリの
MessageIdとMessageArgsの活用
MessageIdでより詳細に操作種別を判定し、MessageArgs配列から削除された具体的リソース名(例:NetworkProtocol)を取得します。削除前後の状態比較を自動化するためにも必要な情報です。
検出スクリプト概要
Python等で以下のような処理を行います。
1. EntriesコレクションをGET
2. 各LogEntryをパースしてEventTypeをチェック
3. ResourceRemovedの場合はMessageArgsをリスト化
4. 対象リソース名をログ出力・アラート通知
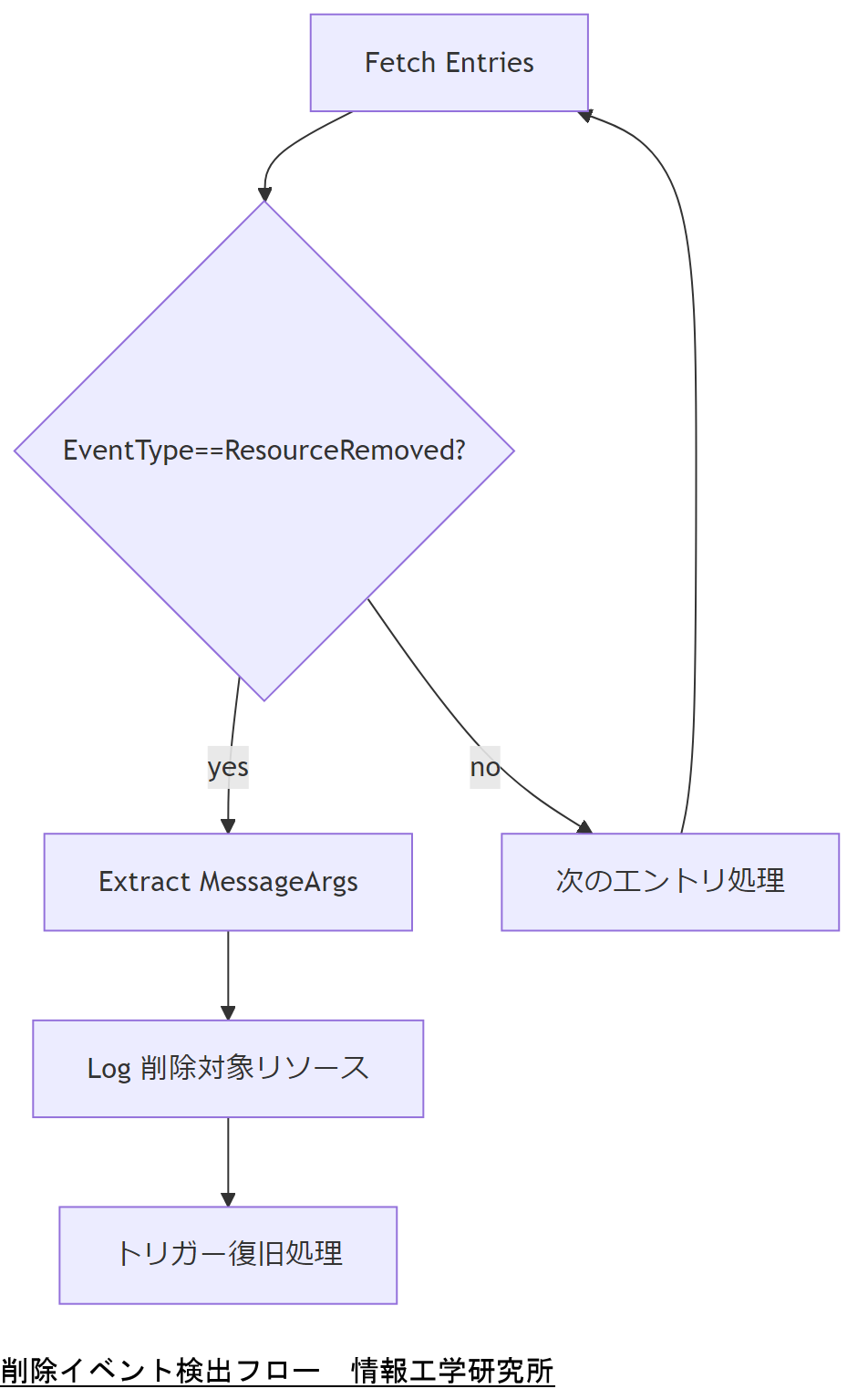
技術担当者は上司に、EventTypeとMessageArgsの組み合わせで確実に削除操作を特定できる点を説明し、誤検出防止策を共有してください。
削除イベントの検出条件を明確にし、フィルタリング漏れや誤検出を防ぐためのテストケースを設計しましょう。
削除対象リソースの特定方法
LogEntryのMessageArgs配列には、削除対象リソース名が格納されます。
MessageArgsは、JSONペイロード内のフィールドで、複数の要素を含む場合があります。
たとえばNetworkProtocolの削除では、["NetworkProtocol"]がMessageArgsに含まれます。
MessageIdはResourceRemoved以外の操作種別判定にも利用されます。
MessageIdはDMTF標準仕様に基づき一意の識別子を持ちます。
削除対象リソースの特定は自動化スクリプトの重要箇所です。
Pythonでの抽出例として、jsonモジュールを用いたパースが一般的です。
抽出後は一覧化し、重複や誤検出を排除するバリデーション処理を推奨します。
実運用ではWebhook通知やログ監視システムへの連携も検討します。
これにより、削除操作の影響範囲を即座に把握できます。
Pythonスクリプト例
以下はMessageArgsからリソース名を抽出する簡易スクリプト例です。
- EntriesコレクションをGETし、JSONレスポンスを取得
- 各LogEntryの"EventType"=="ResourceRemoved"をフィルタ
- "MessageArgs"フィールドを抽出し、対象リソース名をリスト化
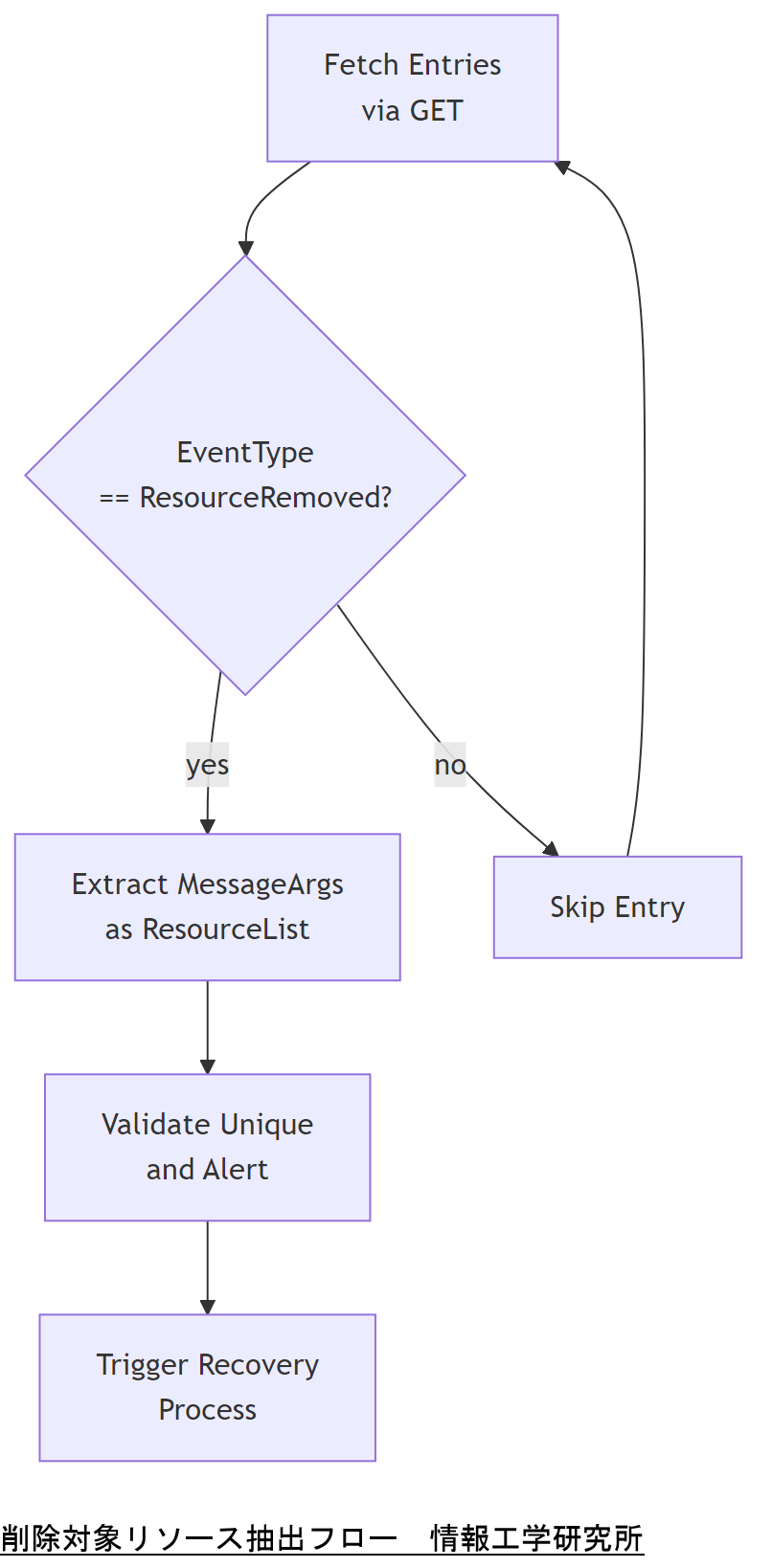
技術担当者は上司に、MessageArgsで正確に削除対象を特定し、誤検出を防ぐためのバリデーション手順を共有してください。
技術担当者は、抽出ロジックのテストケースを設計し、異なるLogService種別でも一貫して動作することを確認しましょう。
設定復旧フローの設計と実装例
削除されたリソースを復旧するには、Redfish APIのPATCHメソッドを用いて対象エンドポイントに再度適切なプロパティを送信します。たとえばNetworkProtocolリソースのHTTP/HTTPS/SSH設定を再有効化できます。PATCHは部分的更新を行うHTTPメソッドです。
NetworkProtocolの再設定例:
curl -k -u admin:password -X PATCH https://bmc.example.com/redfish/v1/Managers/1/NetworkProtocol- ヘッダー:
Content-Type: application/json - ボディ:
{"HTTP": true, "HTTPS": true, "SSH": true}
このリクエストに成功すると、BMCは指定プロトコルを有効化し、200 OKが返されます。
エラーハンドリングとしては、HTTPステータスコードを確認し、4xx系はリクエスト不備、5xx系はBMC側の問題と判断します。再試行やログ出力、運用通知を組み込むことで運用品質を向上できます。
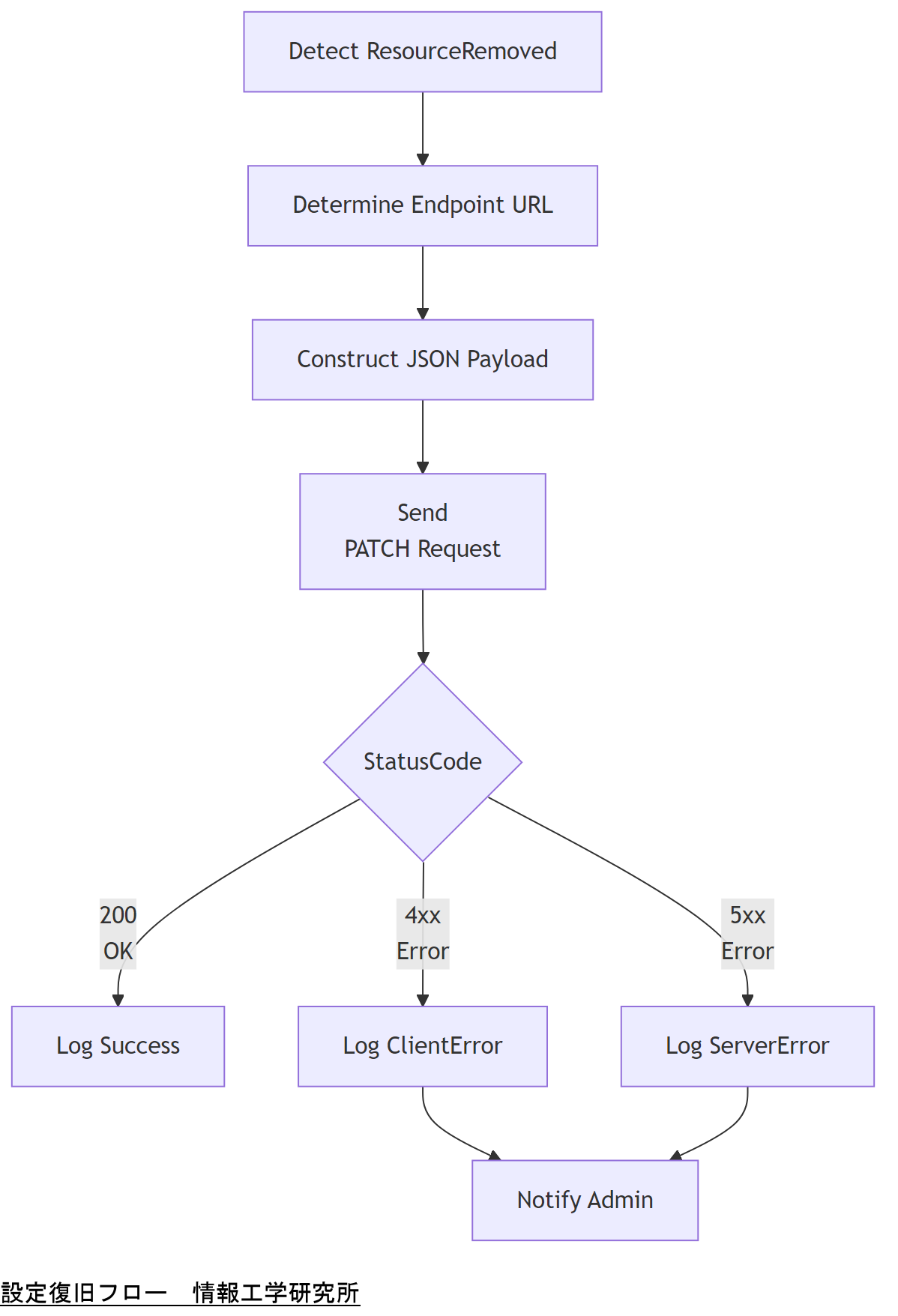
技術担当者は上司に、PATCHによる設定復旧が部分更新である点と、成功・エラーコードの意味を共有し、運用手順書の更新を依頼してください。
実装時には、対象エンドポイントと更新プロパティが正しいかを仕様書と突合し、誤った更新を防止するテストケースを整備することが重要です。
自動化スクリプトと運用ツール提案
Redfish APIを活用したログ分析と復旧処理は、人手による運用では対応が遅れるため、スクリプトやツールで自動化することが重要です。OpenUSMはRedfish APIベースでサーバ管理とログ分析を行うオープンソースツールとして知られています。
OpenUSMはDockerコンテナ化されており、ELKスタックと組み合わせてログの可視化・アラート通知を実装できます。
Pythonスクリプト例として、OpenBMC Test Automationリポジトリのeventlogテスト自動化では、ResourceRemovedイベントの生成から検証までを実現しています。
DellのiDRAC用Pythonスクリプトでは、ライフサイクルコントローラのログを取得し、特定のMessageIdでフィルタリングするサンプルが公開されています。
HPE iLO用APIドキュメントには、NetworkProtocolリソースのPATCH例が掲載されており、自動処理のコード化に役立ちます。
Collabnixのブログでは、Windows環境向けにRedfishでログを取得し、Logstash→Elasticsearch→Kibanaに流すワークフローを紹介しています。
運用ツールとしては、定期的にEntriesをポーリングし、ResourceRemovedを検出したら自動でPATCHを実行するフローを組み込むことが推奨されます。
システム運用ではCronやSystemdタイマーでスクリプトをスケジューリングし、障害発生時にはSlackやメール通知を連携することで迅速な対応が可能になります。
ワークフロー例:
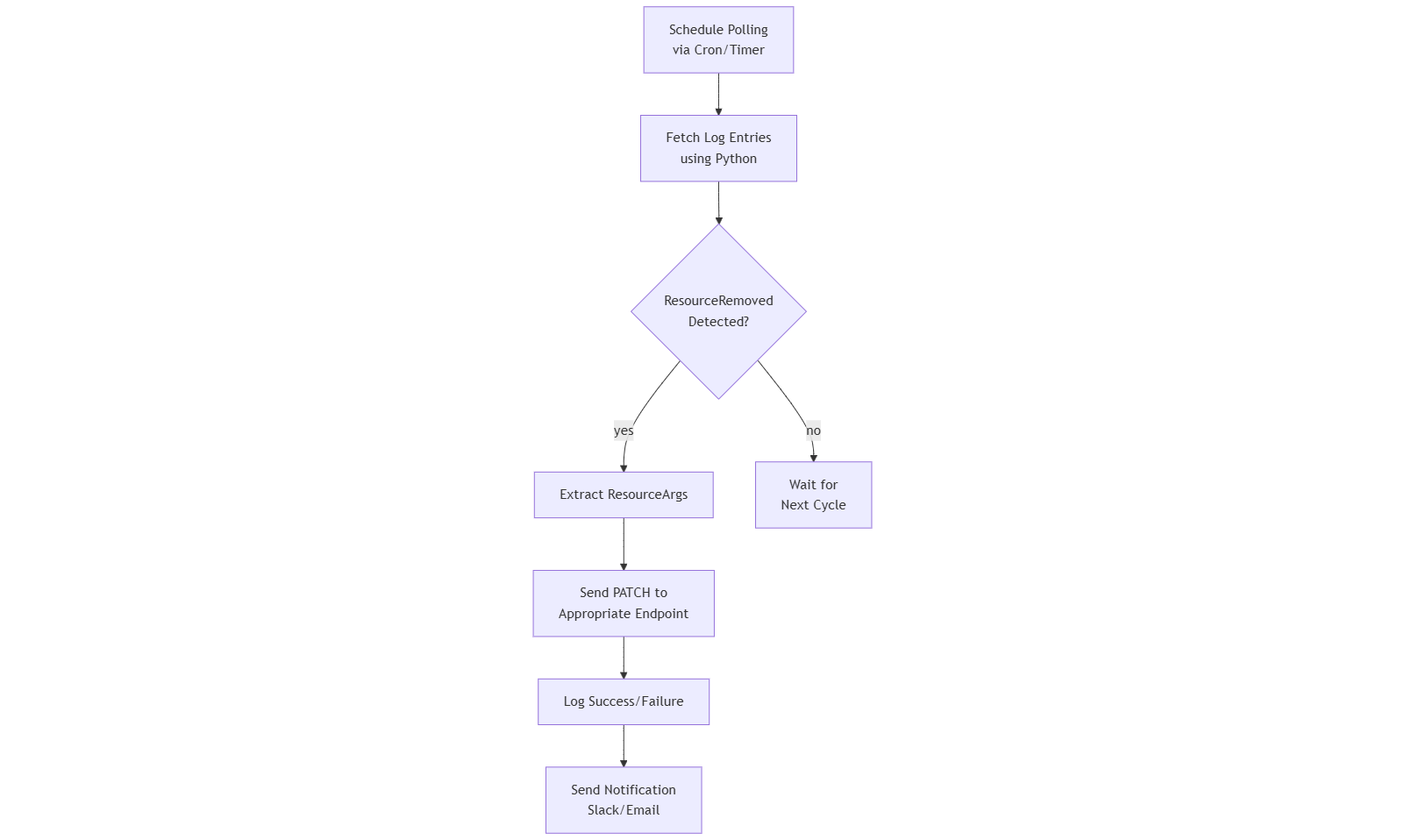
技術担当者は運用ツールの導入により人的ミスを削減し、定期実行とアラート連携で対応速度を向上できる点を上司に報告してください。
スクリプトの自動化により監視・復旧が高速化されますが、テスト環境で十分に動作検証し、誤動作時のフェイルセーフを必ず設計することを心がけましょう。
システム設計とBCP連携
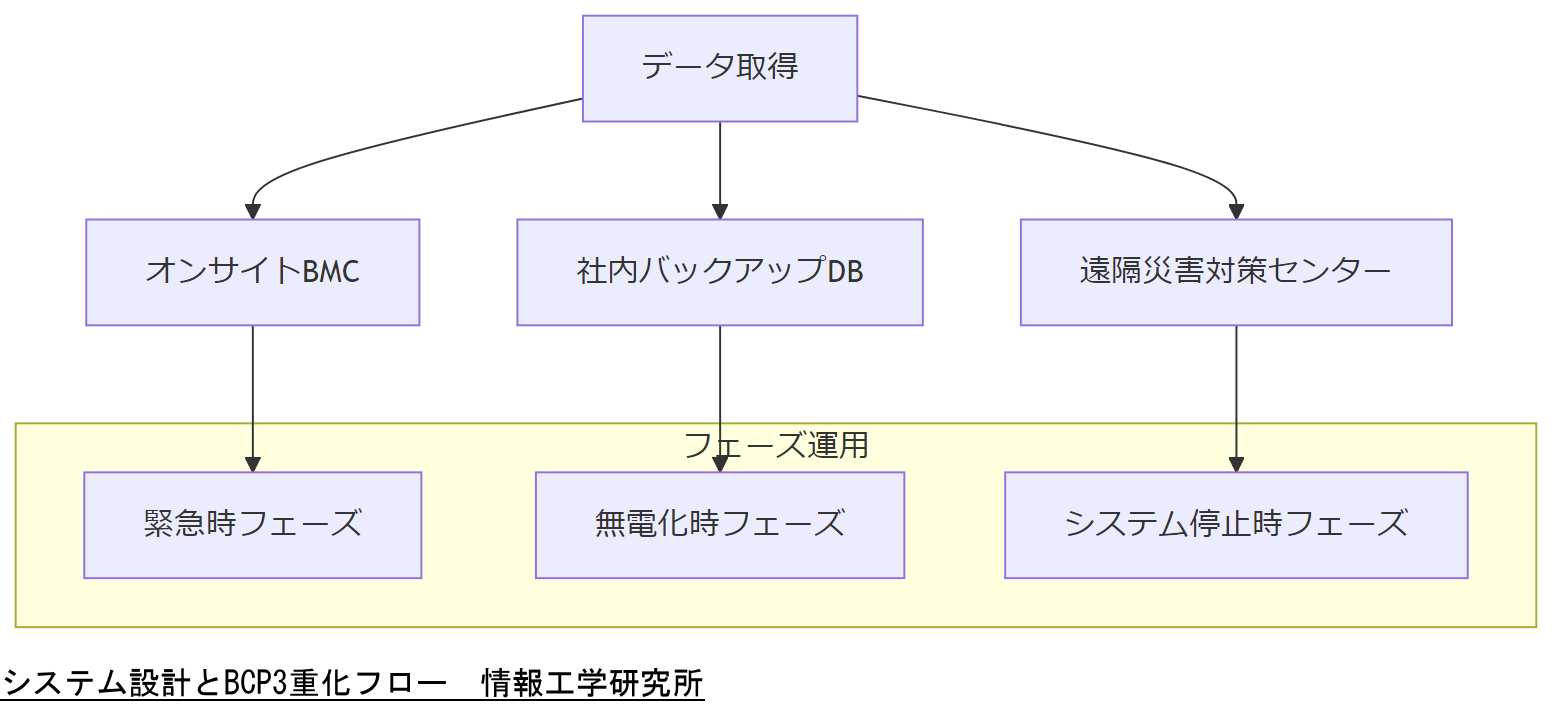
サーバ管理基盤においては、ログ分析による復旧機能だけでなく、事業継続計画(BCP)と連携した冗長化設計が不可欠です。BCPでは、データ保存を3重化し、緊急時・無電化時・システム停止時の3段階フェーズ運用を想定します[出典:内閣府防災情報『事業継続ガイドライン』令和5年]。
まず、データ保存はオフサイト含む3重バックアップが基本です。オンサイトのBMCログ、社内バックアップサーバ、遠隔災害対策センターの3拠点に分散配置し、単一障害点を排除します[出典:内閣府防災情報『BCP文書構成モデル例』平成18年]。
次に、運用フェーズは以下の3段階で設計します[出典:厚生労働省『BCP策定の手引き』令和3年]:
- 緊急時フェーズ:災害発生直後の初動対応。ログ収集・解析チームと運用チームを即時稼働させ、ResourceRemovedイベント検出・復旧を行います。
- 無電化時フェーズ:電力供給が途絶した場合、UPSや非常用発電機の起動を前提に、オフサイトシステムからのログアクセスと復旧コマンド発行を継続します。
- システム停止時フェーズ:主要システムが停止した場合は、遠隔SOC(Security Operations Center)からの遠隔制御でログ分析・復旧スクリプトをトリガーします。
ユーザー数10万人以上など大規模環境では、さらに細分化したフェーズ設計や拠点間連携が求められます[出典:中小企業庁『中小企業BCPガイド』平成20年]。
BCP連携設計では、3拠点のデータ保存や3段階フェーズ運用が事業継続の要であることを共有し、運用規程への反映を依頼してください。
技術担当者は、各フェーズにおけるログアクセス経路と復旧スクリプトの起動条件を明確化し、リハーサル演習で実効性を検証しましょう。
デジタルフォレンジック視点の履歴管理
サイバー攻撃や内部不正の発生時には、ログの改ざんや消失を防ぐ信頼性の高いログ保全が必須です。Redfish APIのLogServiceはイベントログをJSON形式で厳格に記録し、タイムスタンプやイベントIDによって改ざん検知にも活用できます。
ログの完全性確保
ログファイル格納前にハッシュを生成し、オフサイトの監査用ストレージへ転送します。これにより、後からログの改ざんを検出できます。
マルウェア検出連携
LogEntryのMessageミッセージに異常な振る舞い(例:UnexpectedReset)が記録された場合、自動でセキュリティインシデント対応チームへ通知します。
内部不正対応履歴
管理者操作の履歴を専用DBに二重記録し、ログ保全と追跡可能性を確保します。管理者ログイン/設定変更/削除操作のすべてが対象です。
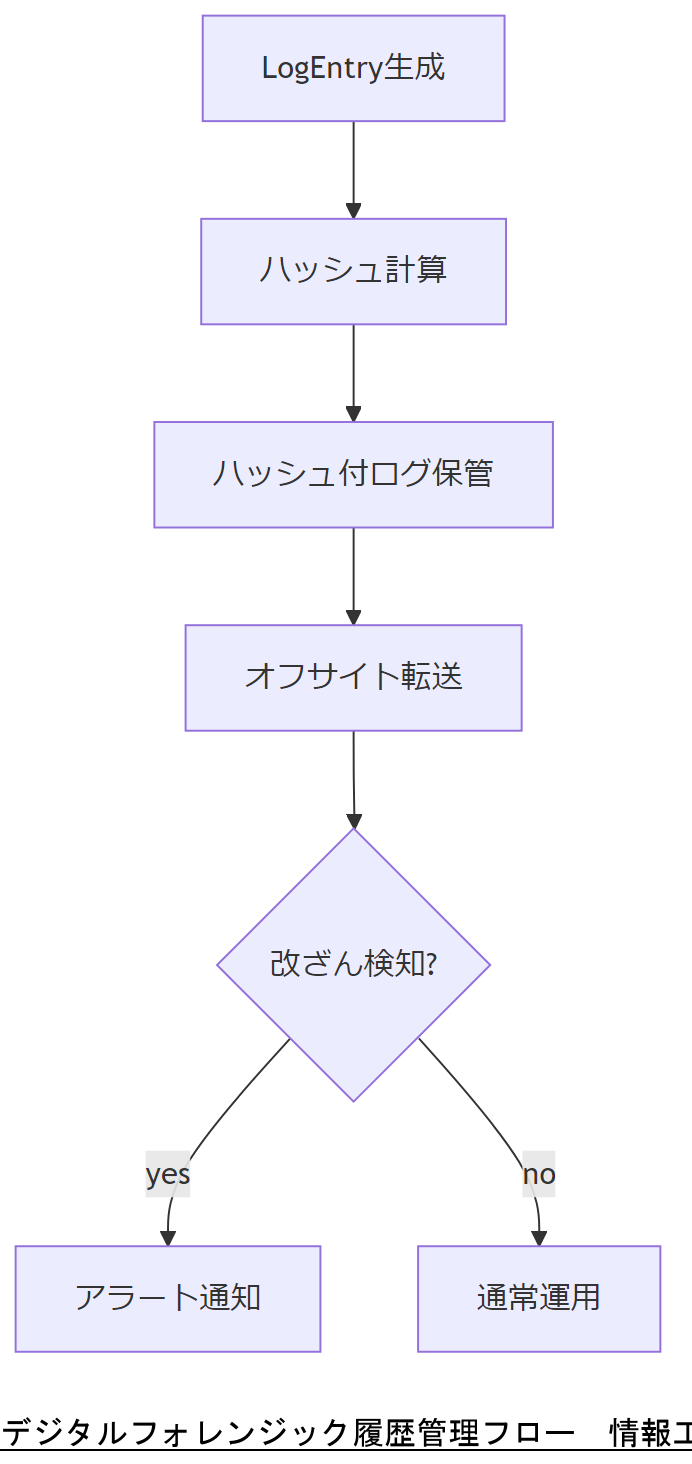
技術担当者は上司に、ログ保全プロセスでハッシュ付与とオフサイト保管を行い、改ざん検知体制を構築する必要性を共有してください。
技術担当者は、ハッシュ生成と検証のタイミング設計を行い、インシデント発生時に即座に改ざんの有無を判断できる体制を検討しましょう。
法令・政府方針の最新動向
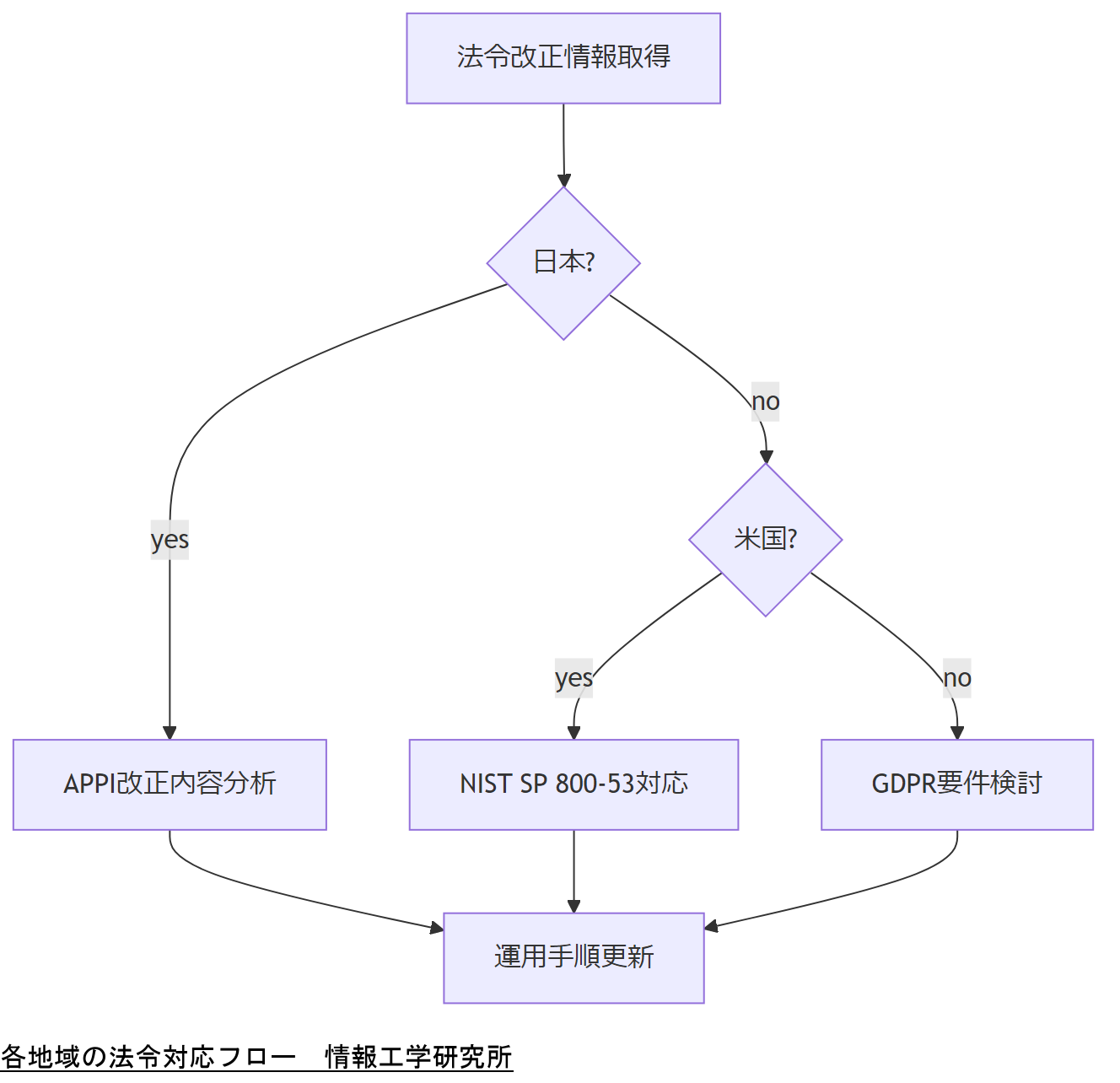
個人情報保護や運用ガイドラインは頻繁に改定されるため、Redfish API活用時にも法令遵守が求められます。本章では、日本、米国、EUそれぞれの最新法令・政府方針を概観し、サーバ管理運用への影響と対応策を解説します。
日本:個人情報保護法(APPI)
改正個人情報保護法は2022年4月1日に施行され、保護措置の強化や匿名加工情報の利用拡大を規定しています。サーバ管理者はログに含まれる個人識別符号が適切に扱われているか確認が必要です。
米国:FISMA/NIST SP 800-53
米連邦情報セキュリティ管理法(FISMA)は政府機関向けセキュリティ基準を定め、NIST SP 800-53ではアクセス制御や監査ログの保存要件を詳細に規定します。商用サーバでも同等レベルの運用がベストプラクティスとされています。
EU:GDPR(一般データ保護規則)
EU一般データ保護規則(Regulation 2016/679)は、EU域内の個人データ処理に厳格な条件を求めます。ログ監査ではデータ主体の権利(アクセス権・削除権)対応を含めた運用ルール策定が必要です。
技術担当者は、各地域の最新法令要件がサーバ運用に及ぼす影響を整理し、運用ポリシーへの反映を上司に依頼してください。
技術担当者は法令ごとのログ保存期間やアクセス権管理など要件を詳細に確認し、監査対応可能な運用フローを設計しましょう。
- 出典:個人情報保護委員会『個人情報の保護に関する法律概要』2022年
- 出典:米国国立標準技術研究所『Security and Privacy Controls for Federal Information Systems and Organizations SP 800-53 Revision 5』2020年
- 出典:欧州連合『Regulation (EU) 2016/679 (General Data Protection Regulation)』2016年
運用コストと今後2年の予測
サーバ管理とBCP運用に伴うコストは、初期構築費用だけでなく定期的な訓練・見直し・システムメンテナンスに要する費用が含まれます。
現在の運用コスト構成
中小企業BCP策定運用指針によると、事前対策として設備復旧費用用の資金調達例は約50,000千円(5,000万円)を想定しています【出典:中小企業庁『事業継続力強化計画 策定の手引き』令和5年】。
同ガイドラインでは、人材トレーニング・訓練費用、外部監査実施費用も別途計上することが推奨されており、年間で導入費用の10~20%相当が運用コストに充てられるケースが多いとされています【出典:中小企業庁『中小企業BCP策定運用指針 第2版』平成18年】。
個人情報保護法(APPI)対応では、プライバシー影響評価(PIA)の実施による初期導入コストが発生する一方で、長期的には事故対策・罰則回避によるコスト削減効果が報告されています【出典:個人情報保護委員会『PIAの取組の促進について―PIAの意義と実施順に沿った留意点』平成31年】。
今後2年のコスト予測
■■推測■■ 2025年から2026年にかけては、ログ保持要件の強化とクラウド連携によるデータ量増加が見込まれ、ストレージ運用コストが年間5~10%程度上昇する可能性があります。
GDPRでは通知義務の削減がコスト低減に寄与していますが、データ主体からのアクセス・削除要求対応など運用負荷は依然として高水準です【出典:EUR-Lex『Regulation (EU) 2016/679 Impact Assessment』2016年】。
米国FISMA準拠では、定期的な監査と評価報告の作成が必要であり、NIST SP 800-53準拠の運用コストは年間数万ドル規模となるケースがあります【出典:CISA『FY 2024 IG FISMA Metrics Evaluation Guide』2024年】。
国内DX調査によると、事業継続計画(BCP)を策定・訓練実施している企業は70%超えとなり、BCP運用への投資意欲の高まりがうかがえます【出典:経済産業省『デジタルトランスフォーメーション調査2025の分析』令和7年】。
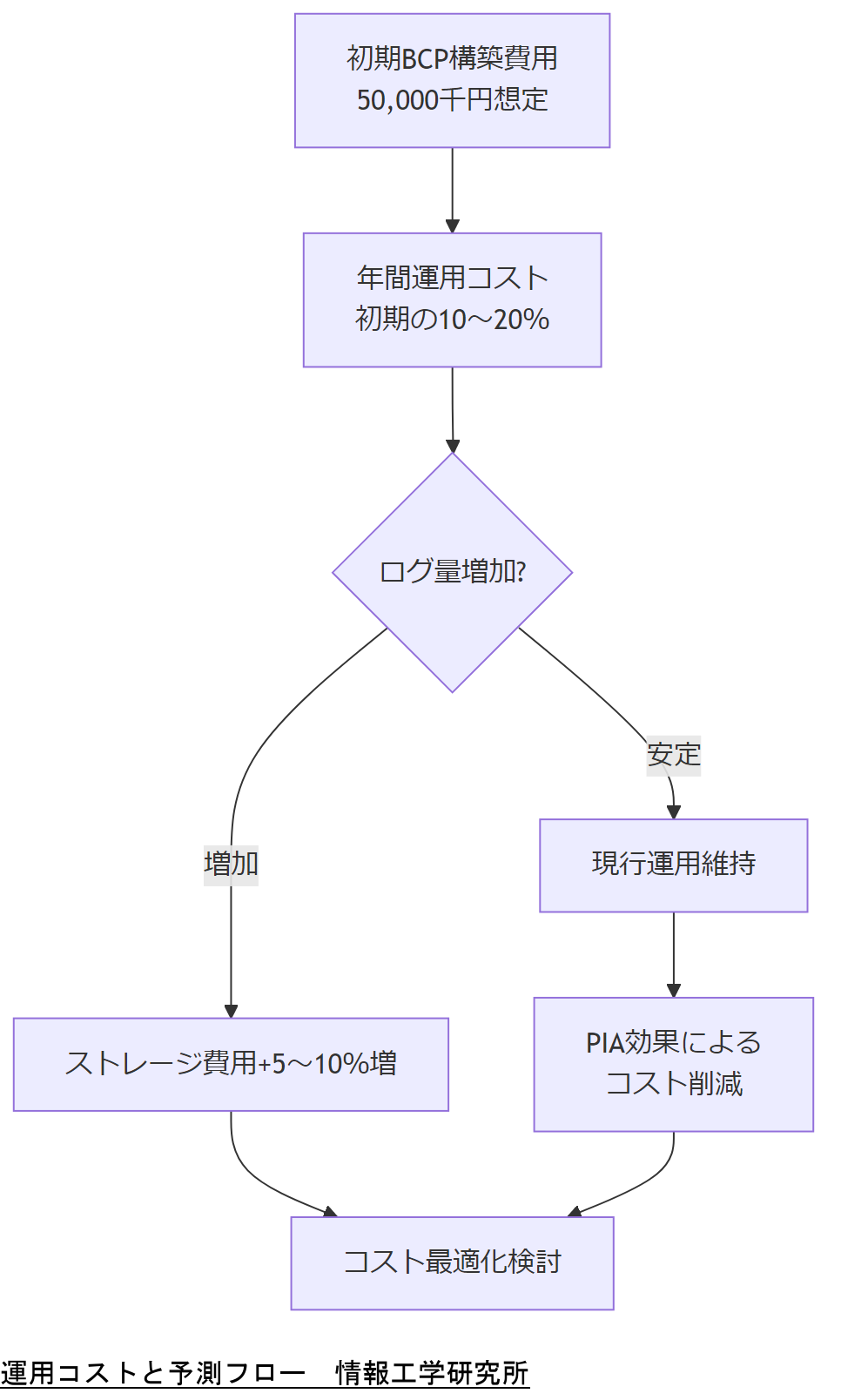
技術担当者は、BCP運用コストの内訳(初期構築 vs 年間運用)や、今後のストレージ費用上昇リスクを上司に説明し、予算計画の見直しを依頼してください。
技術担当者は、年間予算案に必要コストを反映し、ログ保持要件やクラウド利用料増加への対応策を事前に準備しましょう。
該当資格と人材育成・募集計画
Redfish APIログ分析・復旧運用を担う技術者には、国家資格「情報処理安全確保支援士」が最適です。登録後は、組織内外でセキュリティコンサルタントや運用担当者として活躍できる能力証明となります。
情報処理安全確保支援士(RISS)試験概要
本試験は春期(4月)・秋期(10月)年2回、筆記試験で実施されます。合格後、経済産業大臣から合格証書が交付され、所定の登録手続きを経て国家資格「情報処理安全確保支援士(登録セキスペ)」となります。
登録手続きと講習
合格後はIPAが主催する登録申請手続きと、定期的な更新・講習受講が義務付けられています。講習では最新の脅威動向やフォレンジック技術を学び、実践力を維持します。
人材育成プラン例
- 研修導入:基礎講座(IT基盤/ネットワーク/セキュリティ原則)
- 実践演習:Redfish APIを用いたログ取得・解析ハンズオン
- 資格取得支援:試験問題集配付、模擬試験実施
- フォローアップ:半年ごとのナレッジ共有/脆弱性分析演習
募集計画のポイント
- 募集要件:情報処理安全確保支援士合格者優遇
- 役割定義:ログ分析・復旧スクリプト開発・BCP設計支援
- 配属初期:OJTによるRedfish環境構築から運用開始
- 中長期:定期講習・資格更新への支援体制整備
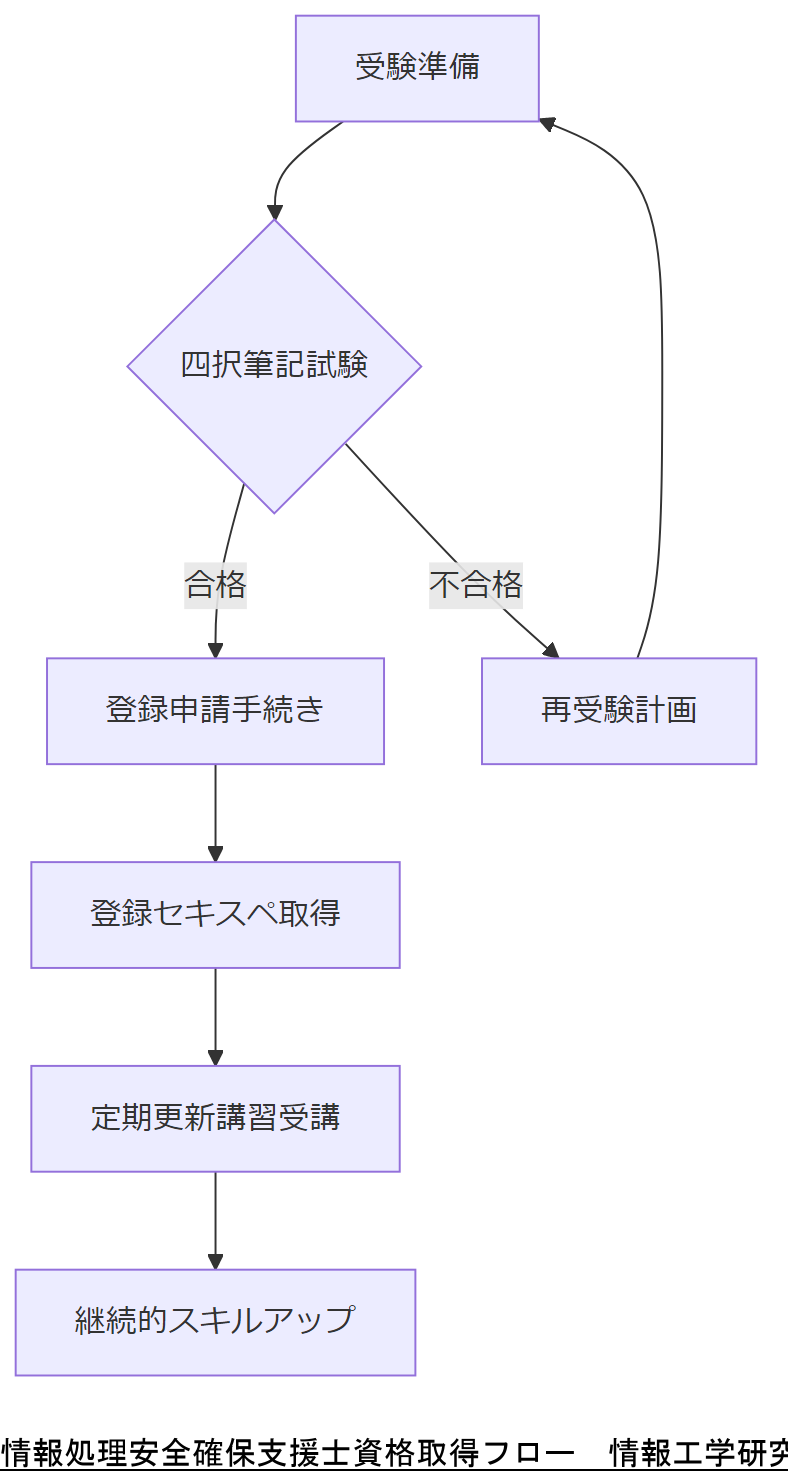
技術担当者は、RISS資格取得から登録セキスペ取得、定期講習によるスキル維持の流れを上司に説明し、受験支援制度の整備を依頼してください。
技術担当者は、自社の人材育成ロードマップにRISS試験・講習スケジュールを組み込み、OJTと資格取得を連動させて計画的にスキルを強化しましょう。
- 出典:IPA『情報処理安全確保支援士試験』2023年6月30日
- 出典:IPA『情報処理安全確保支援士(登録セキスペ)の受講する講習について』2024年
関係者マッピングと注意点
サーバ管理ログ分析および復旧運用においては、企業内外の多様な関係者が関与します。適切なマッピングと注意点の整理により、スムーズな連携と意思決定を実現します。
内部関係者の役割
- 経営層:事業継続の最終判断と予算確保を担当します。[出典:内閣府防災情報『事業継続ガイドライン』令和5年]
- 技術担当者:Redfish API設定・スクリプト実装、ログ分析を担います。
- 運用担当者:日常監視とアラート対応、復旧手順実行を担当します。
- 総務/法務:コンプライアンス確認、ログ保全ポリシーの整備を行います。
外部関係者の役割
- 規制当局:法令遵守状況を監督し、監査を実施します。
- 災害対策センター:オフサイトでのログ保全・バックアップを提供します。
- BCP協議会:関係者合意の下、連携体制を維持します。[出典:国土交通省『港湾の事業継続計画策定ガイドライン』平成31年]
注意点
- 関係者間の責任範囲を明確化し、二重・未実施を防止する。
- 権限不足による操作遅延を避けるため、権限委譲ルールを整備。
- 定期的な連絡体制と連携訓練を実施し、緊急時の混乱を軽減。
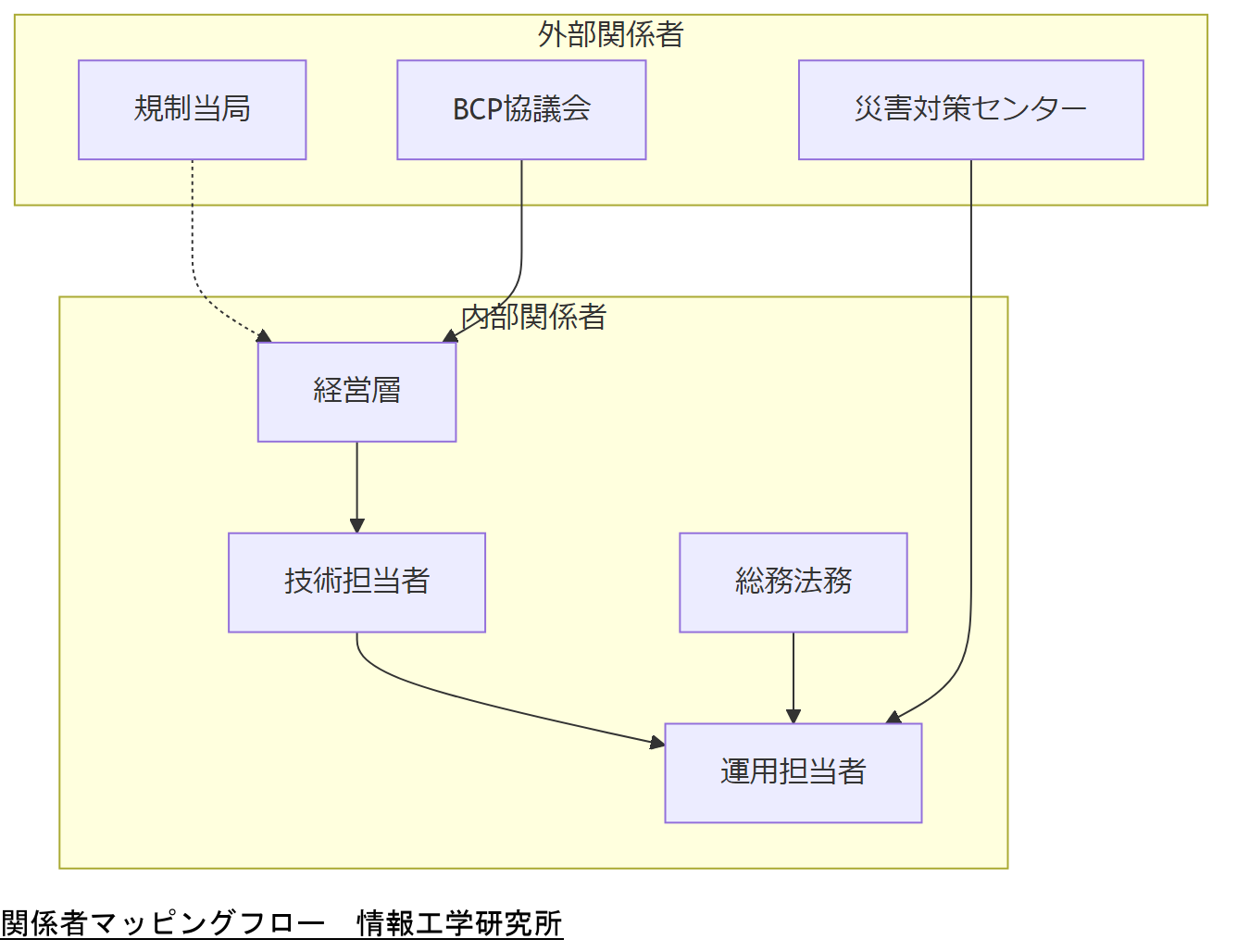
技術担当者は、社内外の関係者とその役割を整理し、二重対応や責任不明確を防ぐためのマッピング結果を上司に共有してください。
技術担当者は、関係者ごとの権限と責任を明文化し、緊急連絡網とエスカレーション手順を定期的に検証・更新しましょう。
外部専門家へのエスカレーション
自社だけで対応が困難な障害やログ解析においては、外部専門家への早期エスカレーションが重要です。本章では、エスカレーション判断基準と手順を示します。
エスカレーション判断基準
- 復旧スクリプトのエラーが連続して発生し、ログ復元不能と判断した場合【想定】
- BMCファームウェアの根本的問題によるログ取得失敗が解消しない場合【想定】
- 影響範囲が経営判断を要する重大インシデントに発展しそうな場合【想定】
エスカレーション手順
- 技術担当者がエラー内容と影響範囲を整理
- 上司へエスカレーション提案書をメールまたは口頭で提出
- 情報工学研究所へお問い合わせフォーム経由で相談・支援を依頼【想定】
- 専門家による初期調査結果を受領後、追加作業スケジュールを共有

技術担当者は、エスカレーション基準に該当した際に速やかに情報工学研究所へ相談し、現状と依頼内容を端的に共有する必要性を伝えてください。
技術担当者は、自社対応フェイズの限界を判断するためのチェックリストを用意し、判断ミスを防ぐためのレビュー体制を整備しましょう。
おまけの章:重要キーワード・関連キーワードマトリクス
本記事で扱った主要概念と関連キーワードをマトリクス形式でまとめました。用語の理解にご活用ください。
キーワードマトリクス| キーワード | 説明 |
|---|---|
| Redfish API | サーバ管理用RESTful標準インターフェース |
| LogService | イベントログ取得リソース |
| ResourceRemoved | リソース削除イベントタイプ |
| PATCH | 部分更新用HTTPメソッド |
| BCP | 事業継続計画 |
| 情報処理安全確保支援士 | 国家資格によるセキュリティ専門家 |
| デジタルフォレンジック | 証拠保全・解析技術 |
| コンセンサス形成 | 社内承認プロセス |

まとめと次のステップ
本記事では、Redfish APIによるログ分析から設定削除の検出、復旧フローの実装、BCP連携、法令対応、人材育成まで幅広く解説しました。これらを総合的に導入することで、万が一の設定削除や障害発生時にも迅速な復旧と事業継続が可能になります。
記事全体のポイント整理
- Redfish APIのLogServiceを使った確実な削除イベント検出
- PATCHによる部分更新を活用した復旧自動化
- BCPの3重化設計と緊急/無電化/停止時フェーズ運用
- 個人情報保護法・GDPR・FISMAなど各地の法令対応
- 情報処理安全確保支援士資格による体制強化
次のステップ
- 本番環境でのスクリプト動作検証と運用品質テスト
- BCP演習の定期実施とリハーサル結果のフィードバック
- 定期的な法令改定チェックと運用ルールの更新
- 人材育成ロードマップへの資格取得計画組み込み
- 情報工学研究所へのご相談:より高度な復旧・運用支援
技術担当者は、本記事の全ポイントを踏まえた上で、運用改善とBCP強化のための予算・スケジュール計画を経営層へ提案してください。
技術担当者は、この記事を基礎に定期的なレビュー・演習を繰り返し、運用チームと連携しながら実効性を高めていきましょう。