【注意】本記事は、Windows における ERROR_SHARING_VIOLATION(32)発生時の一般的な考え方と手順を整理した情報提供です。実環境ではアプリ実装、SMB/クラウド同期、ウイルス対策、バックアップ製品、権限設計、業務要件によって最適解が変わります。重要データを扱う場合や障害が進行している可能性がある場合は、自己判断で操作を重ねると復旧難易度が上がることがあります。必要に応じて専門家へ相談してください。
第1章:「また32か…」共有違反が“現場の神経”を削る理由
エンジニアなら、ERROR_SHARING_VIOLATION(32)を見た瞬間に、ため息が出る感覚があるはずです。「この処理、昨日まで動いてたのに」「ログには32だけ。で、掴んでるの誰?」——原因が“いまこの瞬間の競合”に依存するぶん、再現しづらく、説明しづらい。だからこそ厄介です。
そしてこのエラーは、仕様としては単純です。「共有(share)設定と実際のアクセスが噛み合っていない」だけ。にもかかわらず、現場では単純に終わりません。アプリ側のハンドル管理、OSやミドルのファイル置換方式、ウイルス対策やバックアップの介入、ネットワーク共有の遅延・リトライ、クラウド同期の“監視”。複数の要因が同時に噛むと、32は“たまたま表に出た症状”になります。
ここで最初に押さえるべき伏線は2つです。
- 伏線①:32は「ロック」そのものではなく、共有モード(ShareMode)の衝突で起きることが多い(ロック系の別エラーと混ざる)。
- 伏線②:掴んでいるのは自分のプロセスとは限らない。外部プロセス(AV/同期/バックアップ/インデクサ等)が“瞬間的に触って”発火させる。
本記事は、この伏線を回収しながら「書き出し → 伏線 → 帰結」を一本の線でつなぎます。ゴールは、競合をゼロにする理想論ではなく、競合が起きても被害最小化できる設計(ダメージコントロール)へ持っていくことです。
なお、障害対応では「今すぐ直す」だけでなく、再発時に説明できる証拠(ログ/トレース/操作履歴)を残すことが、結果的に最短ルートになります。ここからは、そのための具体策に入ります。
第2章:ERROR_SHARING_VIOLATION(32)の正体—「共有」ではなく「共有許可の衝突」
Win32 エラー 32(ERROR_SHARING_VIOLATION)は、典型的には「別プロセスが開いているせいでアクセスできない」として表面化します。Windows API で言えば、CreateFile(またはそれに相当する上位API)が失敗し、GetLastError が 32 を返す、という形です。
ここで重要なのは、ファイルアクセスには大きく2系統の“拒否”があることです。
| 観点 | よく出るエラー | 意味合い | 典型原因 |
| 共有モード | ERROR_SHARING_VIOLATION(32) | 「その開き方(ShareMode)では許可しない」 | FILE_SHARE_* の不一致、占有オープン、置換/リネーム競合 |
| ロック | ERROR_LOCK_VIOLATION(33)等 | 「領域ロック等により操作できない」 | 明示的ロック(LockFile等)、アプリ/DBの排他 |
現場では「どっちも“掴まれてる”」に見えるため混同しがちですが、共有モード衝突(32)とロック(33等)は切り分け方が違います。32の場合、“誰が掴んでいるか”に加えて、“どんな共有許可で掴んでいるか”が本質になります。
もう一つ、32が出やすい代表的パターンがあります。それが「一時ファイル→置換(rename)で安全に更新」する実装です。多くのアプリは、直接上書きせず、
- tmp に新内容を書き出す
- 既存ファイルをリネーム/削除
- tmp を本来名へ原子的に差し替える
という手順で“途中半端なファイル”を作らないようにします。これは正しい設計ですが、差し替えタイミングで別プロセスが既存ファイルを占有していると、リネーム/置換が失敗して32が出ることがあります。つまり32は「安全な更新方式」と「周辺の監視プロセス」が衝突した結果として出ることがある、という伏線です。
この章の結論はシンプルです。32は“共有許可の衝突”であり、原因はアプリ外にもある。次章から、共有モードとハンドル管理を“仕様として”読み直します。
第3章:伏線①—CreateFile の ShareMode と「ハンドル寿命」を設計として扱う
Windows のファイルアクセスは、ざっくり言えば「どう開くか(DesiredAccess)」と「他者に何を許すか(ShareMode)」をセットで決めます。ShareMode は代表的に次の3つです。
- FILE_SHARE_READ(他者の読み取りを許可)
- FILE_SHARE_WRITE(他者の書き込みを許可)
- FILE_SHARE_DELETE(他者の削除・リネーム等を許可)
ここで現場あるあるが発生します。「読み取りしかしてないのに32が出る」ケースです。これは、別プロセスがFILE_SHARE_READ を許可していない形で開いている、あるいはFILE_SHARE_DELETE を許可していないために置換・リネームが弾かれている、などが典型です。
さらに厄介なのが、いわゆるハンドルリーク/閉じ忘れです。「処理は終わったのに、掴みっぱなし」。コードレビューでは見落としやすいのに、運用では致命傷になります。
- 例外系で Close/Dispose が通らない
- 非同期処理で寿命管理が崩れる(await の外で握ったまま)
- ログ出力・監査出力がファイルを掴んだまま回り続ける
- 並列処理で“開き直し”が暴発し、占有オープンが増える
「また新しいルール増えるの?」と思うのも自然です。でもここは、ルールというより設計の前提です。共有ストレージやバックアップが絡むBtoBシステムほど、ファイルの読み書きは“単独プロセス前提”では成立しません。
実務で効くチェック観点を表にします(コードに落とし込むときの観点です)。
| チェック項目 | なぜ効くか | 典型の手当 |
| Close/Dispose の到達保証 | 例外・キャンセル時に掴みっぱなしを防ぐ | finally / using / try-with-resources 等 |
| ShareMode の明示 | 意図せぬ占有を減らし、周辺プロセスと共存 | 読み取りは share-read、更新は置換方式+share-delete検討 |
| 更新方式(原子的差し替え) | 途中状態の露出を防ぎ、障害時の整合性を守る | temp 書き込み→rename、失敗時リトライ |
この章の要点は、32の多くは“運”ではなく、共有モードとハンドル寿命の設計不足が、外部要因と衝突した結果だということです。次章では「自分のプロセス以外が掴む」現実に踏み込みます。
第4章:伏線②—犯人はアプリだけじゃない(AV/バックアップ/インデクサ/同期)
ERROR_SHARING_VIOLATION を“自分のバグ”として抱え込むと、対策が空回りします。なぜなら、Windows 環境では、業務PC/サーバの多くに「ファイルを触る常駐プロセス」が複数いるからです。
- ウイルス対策(リアルタイムスキャン)
- バックアップエージェント、スナップショット系ツール
- 検索インデックス(Windows Search など)
- クラウド同期(OneDrive 等)
- EDR/監査/ログ収集(ファイル監視を含む製品)
これらは、ファイルを「読むだけ」のつもりでも、実装次第では占有オープンやタイミング衝突を起こします。特に“差し替え更新(rename)”と相性が悪いケースがあり、一瞬だけ掴んだタイミングで32が出ることがあります。
ここで現場の心の声が出ます。「それ、こっちで止められないんだけど?」——その通りです。だからこそ、対策は2段構えになります。
- 切り分け(誰が掴んだか):原因を確定し、説明可能にする
- 回避設計(掴まれても壊れない):競合前提でリトライ・退避・原子性を設計する
切り分けができないまま「とりあえずリトライ」を入れると、運用は一時的に楽になっても、別の障害(無限待ち、ログ肥大、処理遅延、二重実行)に繋がります。ここは“楽をするために、先に一度だけ苦労する”局面です。
外部プロセス起因を疑う時の観点を、実務向けに整理します。
| 状況 | 疑う相手 | よくある兆候 |
| 夜間に多発 | バックアップ/スキャン | 定時処理と衝突、一定周期で再現 |
| 特定フォルダだけ | 同期/監視/インデックス | “監視対象パス”に依存 |
| 小さいファイル更新で発生 | AV/EDR | 更新直後に触られる、瞬間衝突 |
この章の結論は、「外部要因の可能性を最初から設計に入れよう」です。次章からは、再現性を上げて“誰が掴んでいるか”を確定するための、具体的な観測手順に入ります。
第5章:まず再現する—最小ケースで「いつ・どこで・誰が」を固定する
32対策で最も時間を浪費するのは、「現場で起きたっぽい」「たぶん競合」という曖昧さのまま手を動かすことです。最初にやるべきは、再現条件の固定です。再現ができれば、原因は“推理”から“観測”に変わります。
再現の基本は、次の3点を揃えることです。
- 操作:どのAPI/機能が、どのファイルに、どの順で触るか
- タイミング:定時・周期・イベント駆動(保存直後/起動直後/同期直後など)
- 環境:ローカルかSMBか、同期対象か、AV/バックアップの有無
具体的には、まず「問題のファイル操作を最小化したテスト」を作ります。アプリ全体ではなく、問題の更新処理だけを取り出す。ログは「32が出た」ではなく、少なくとも以下を残します。
- 対象パス(フルパス)
- 操作種別(open/read/write/rename/delete のどれか)
- 時刻(ミリ秒精度が望ましい)
- リトライ回数と待機時間
- 実行ユーザー(サービスアカウント/対話ユーザー)
「ログ増やすの、正直だるい」と感じるのも自然です。でも、ここを薄くすると、後工程(ProcMonなどの突合)が破綻します。現場の時間を守るための“前払い”だと思ってください。
そして再現テストでは、環境を段階的に増やすのがコツです。いきなり本番構成でやらず、
- ローカルディスク(同期なし)
- ローカル+AV/監視あり
- SMB共有(サーバ側要因も含む)
- SMB+同期/バックアップなど実運用条件
のように“どこで32が出始めるか”を確認します。これにより「アプリの共有モードが悪いのか」「外部プロセスが掴むのか」「SMBの振る舞い(遅延/再試行/置換の成否)が絡むのか」が見えてきます。
次章では、再現条件が整った前提で、ProcMon を中心に「掴んでいるプロセス」と「その直前の操作列」を特定する手順に進みます。
第6章:可視化の決定打—ProcMonでロック元プロセスと操作列(Create/Write/Rename)を追う
再現条件が固まったら、次は「誰が掴んだか」を推理ではなく観測に落とします。ここで強い味方になるのが、Sysinternals の Process Monitor(通称 ProcMon)です。ファイルI/Oのイベントを時系列で追えるので、ERROR_SHARING_VIOLATION(32)が“起きた瞬間”に、どのプロセスが何をしていたかを突き止めやすくなります。
現場の心の声はこうです。
「ログに32って出てる。でも、掴んでるのが誰か分からない。結局、当てずっぽうで例外処理だけ増える…」
そのモヤモヤを“鎮火”させるには、観測データが必要です。
ProcMonの基本方針はシンプルで、「対象パスに絞る」「SHARING VIOLATIONを捕まえる」「直前の操作列を見る」の3点です。使い方の要点を整理します。
- キャプチャは短時間・再現タイミングに合わせる:常時取りっぱなしにするとログが膨張し、解析が破綻しがちです。再現テストの実行直前に開始し、発生したらすぐ停止します。
- フィルタで対象パスを絞る:Path に対象フォルダ/対象ファイル名を指定してノイズカットします。まずはフォルダ単位→次にファイル単位の順で絞ると見失いにくいです。
- Resultで絞る:Result に “SHARING VIOLATION” が出るイベントは、32に直結する強い手掛かりになります。
ProcMonで見るべきポイントは、単に「どのプロセスか」だけではありません。32は“共有許可の衝突”なので、CreateFile相当のイベント詳細にある、次の情報が効きます。
| 見る項目 | 意味 | 読み取りのコツ |
| Process Name / PID | 誰が触ったか | 自プロセス以外(AV/同期/バックアップ等)が出たら伏線回収が進みます |
| Operation | 何をしようとしたか(open/rename/delete等) | rename/置換系で失敗していると“安全な更新方式”との衝突が疑えます |
| Desired Access / ShareMode | どの権限で開こうとし、何を他者に許したか | 占有(共有無し)や share-delete 不許可が見えると原因が具体化します |
| Stack(必要時) | どのモジュール経由で呼ばれたか | アプリ内部の犯行か、外部ツールの監視か、判断材料になります |
特に実務で効くのは、「SHARING VIOLATIONの直前に、別プロセスが同じパスにCreateFileしている」パターンです。たとえば、あなたのアプリが置換更新しようとした瞬間に、AVや同期クライアントが“読むだけのつもり”で開いていて、share-deleteが許可されておらず、renameが弾かれる——こういう筋書きが、ログの時系列で見えてきます。
ここまで来ると、議論が過熱しがちな「アプリが悪い/運用が悪い」の水掛け論から抜けられます。観測で言えるのは、こうです。
「この時刻に、プロセスAがこの共有許可で掴み、プロセスBのこの操作が衝突している」
次章では、ProcMonで“相手の名前”が出ても、それがサービス名や裏の親プロセスで分かりにくいときに使う、追加の特定手段(OpenFiles / handle.exe / リソースモニタ等)に進みます。
第7章:切り分けの実務—OpenFiles/handle.exe/リソースモニタで“掴んでいる手”を特定する
ProcMonでプロセス名が出ても、「それって結局どの機能?どの常駐?」となることがあります。たとえばバックアップ製品のエージェント、EDR、同期クライアントは、親子プロセスやサービス構成が複雑で、プロセス名だけでは判断が難しい場合があります。
ここで大事なのは、“一発で決める魔法”を探すより、複数の観測手段を組み合わせて、証拠の強度を上げることです。現場の心の声としては、
「また切り分け?正直めんどい。でも、これやらないと一生終わらないんだよな…」
この感覚は正しいです。ここがダメージコントロールの分岐点です。
よく使われる実務ツールを、用途別に整理します。
| 手段 | 強み | 向いている場面 | 注意点 |
| リソース モニター | GUIで“関連付けられたハンドル”検索ができる | 現場PCで即確認したいとき | 瞬間競合は見逃すことがある(出た瞬間に消える) |
| handle.exe(Sysinternals) | ファイルを掴むハンドルを一覧化しやすい | サーバ/バッチで繰り返し確認したいとき | 管理者権限が必要なことが多い |
| OpenFiles(管理コマンド) | 共有経由で開かれているファイルを把握しやすい | ファイルサーバ側で“誰が開いているか”を確認したいとき | ローカルの把握には設定が必要/情報が限定的な環境もある |
切り分けの進め方は、「軽い手段→強い手段」の順が失敗しにくいです。
- まずリソースモニタで、該当パスを掴んでいるプロセスが見えるか確認(手早い)
- 見えにくい/瞬間で消える場合は、handle.exe で繰り返し照会して“掴んだ瞬間”を捕まえる
- SMB共有が絡む場合は、ファイルサーバ側でOpenFiles等を併用し、クライアント起因かサーバ起因かを分ける
ここで重要な現実があります。32は“瞬間競合”で出ることがあるため、発生した時点では既に掴み手が解放しているケースが珍しくありません。つまり「今見ても掴んでない」=「無実」ではありません。
だから、ProcMonのようなイベントログと、handle.exe等の“現物確認”を突合して、証拠を強めます。たとえば、
- ProcMon:この時刻にプロセスXがこのパスをこの共有許可で開いた
- handle.exe:同プロセスXが同フォルダ配下の複数ファイルを掴みやすい挙動がある
- 運用ログ:同時刻にバックアップ/同期が走っている
こう並べると、社内調整や対人コミュニケーション(「誰の責任?」)の温度を下げながら、対策に合意しやすくなります。
この章のまとめは、「掴んでいる手」を特定することが、最短の収束につながる、です。次章では、原因が分かった前提で、設計としての回避策——リトライ・原子的差し替え・衝突に強い保存方式——を体系化します。
第8章:回避の設計—リトライ+テンポラリ書き込み+原子的リネームで衝突に強くする
原因が分かったあと、現場が本当に欲しいのは「一回だけ直った」ではなく、明日も運用が回ることです。競合はゼロにできません。AVもバックアップも同期も、業務要件として“存在してよい”ものだからです。だから帰結は、衝突しても被害最小化できる設計に寄せます。
ここでの心の会話はこうです。
「また例外処理が増えるのか…でも、夜間バッチが落ちて起こされるよりマシか」
その感覚は現実的です。ポイントは“雑に増やす”のではなく、設計として筋の良いパターンに揃えることです。
衝突に強い保存・更新の基本パターンは、次の3点セットです。
- テンポラリへ書く:本番ファイルを直接上書きしない
- 原子的に差し替える:rename/置換で一気に切り替える(途中状態を露出させない)
- 失敗時はリトライする:ただし無限ではなく、待機・回数・タイムアウトを設計する
ただし「リトライすればOK」ではありません。リトライは、設計を間違えると逆に事故を増やします。たとえば、
- 高頻度・同時多発でリトライが揃うと、競合が増幅する(スパイク)
- 無限リトライは、処理遅延やキュー滞留を起こし、別障害に波及する
- 待機が固定だと、周期処理と同調して“毎回同じタイミングでぶつかる”
そこで、実務では次のような設計がよく使われます。
| 設計要素 | 狙い | 実装方針(概念) |
| 回数上限 | “待ち続ける”事故を防ぐ | N回で打ち切り、上位で再実行可能にする |
| バックオフ | 衝突頻度を下げる | 待機を段階的に伸ばす(短→中→長) |
| ジッター | 同調を崩し、再衝突を抑え込み | 待機にランダム要素を混ぜる |
さらに重要なのが、「同一プロセス内の並列」による自己衝突です。SRE/サーバサイド視点では、並列化は正義に見えますが、ファイル更新は共有資源です。並列にすると、同じファイルに対して自分たちが32を起こすことがあります。
この場合の対策は2つに分かれます。
- プロセス内で直列化する:対象ファイル単位でキューを作り、更新を順序化する
- プロセス間で調停する:同一マシン内なら名前付きMutex等、複数マシンなら別の調停手段(DBや分散ロック等)を検討する
ここは「要件次第」です。調停の仕組みを増やすと運用コストが上がるため、まずは“対象ファイルの更新を減らす/まとめる”など、構成の工夫でブレーキをかけられないかを検討するのが現実的です。
この章の結論は、32を“例外”として扱うのではなく、競合前提の保存設計として組み込むことです。次章では、SMB共有やクラウド同期など、共有環境が競合を増幅させる条件と、運用・構成での抑え込み方を整理します。
第9章:共有環境の落とし穴—SMB・クラウド同期・オフライン機能が競合を増幅させる
ローカルディスクでは再現しないのに、共有フォルダ(SMB)や同期フォルダでだけ32が出る——これは珍しくありません。理由は単純で、共有環境には関与者(プロセス/端末/サーバ)が増え、タイミングが読めなくなるからです。
「現場の大変さ分かってくれてない」瞬間が、ここで起きやすいです。アプリ担当は「うちの処理は正しい」、インフラ担当は「共有はみんな使ってる」、セキュリティ担当は「監視は外せない」。この状態で必要なのは、責任追及ではなく、競合を抑え込み、被害最小化するための“合意できる設計点”です。
共有環境で32が増えやすい代表要因を整理します。
- サーバ側スキャン/バックアップ:ファイルサーバ自身のAVやバックアップが、クライアント更新と衝突する
- クライアント側同期:OneDrive等が更新直後にファイルを検査・アップロードし、瞬間的に掴む
- 置換更新(rename)が多い:安全な更新方式ほど、rename/置換イベントが増え、競合ポイントが増える
- 運用上の“集中時間帯”:定時バッチ、締め処理、夜間バックアップが同じ窓に集まる
対策は「アプリ」だけでは完結しないことが多いです。ここで効くのは、アプリ設計+運用設計+構成設計の“三点セット”です。
| レイヤ | 対策例 | 狙い |
| アプリ | テンポラリ→原子的差し替え、バックオフ+ジッター、更新の直列化 | 衝突しても壊れない・再実行できる |
| 運用 | バックアップ窓の調整、重い同期対象からの除外、集中バッチの分散 | 衝突頻度そのものを下げる |
| 構成 | 共有と更新の役割分離(更新はローカル→成果物だけ共有へ)、専用領域の用意 | “触る主体”を減らし、複雑性を抑える |
特にBtoBで効くのは、「更新する場所」と「参照する場所」を分ける発想です。たとえば、更新はローカルの作業領域で行い、確定した成果物だけを共有へコピーする。共有側では“読み取り中心”に寄せると、共有許可の衝突が減り、32が出にくくなります。
また、クラウド同期フォルダを“業務データの正”にする設計は、利便性と引き換えに競合要因を増やします。ここは組織の方針次第ですが、少なくとも更新頻度が高い中間生成物(tmp・ログ・作業ファイル)を同期対象から外すと、かなり収束しやすいことがあります。
この章のまとめは、共有環境では「正しさ」だけでは足りず、関与者を減らす設計で競合を抑え込むのが近道、ということです。次の章(最終章)では、ここまでの伏線を回収して、一般論の限界と、個別案件で専門家に相談すべき判断軸を整理し、自然に次の一歩へつなげます。
第10章:帰結—競合はゼロにできない。「衝突しても壊れない運用」で収束を最短にする
ここまでの伏線を回収すると、ERROR_SHARING_VIOLATION(32)の本質はこう整理できます。
- 32は“ファイルが開けない”という結果であり、原因は「共有許可(ShareMode)と実アクセスの衝突」であることが多い。
- 犯人は自分のプロセスとは限らない。AV、バックアップ、同期、インデクサなど“触ってよい立場のプロセス”が、タイミング衝突を起こす。
- 正しい更新方式(テンポラリ→原子的差し替え)であっても、周辺プロセスと噛み合わないと32は出る。
この整理が腹落ちすると、ゴールは「32を根絶する」ではなく、32が出ても“壊れない・戻せる・説明できる”状態へ持っていくことだと分かります。ここが、現場の温度を下げて収束させる一番の近道です。
1) まず“いま直す”:障害対応としてのダメージコントロール手順
本番で32が出た瞬間、やりがちなのが「とりあえず無限リトライ」「手当たり次第に再起動」です。気持ちは分かります。ですが、ファイル操作の障害では、同じ操作を重ねるほど、状況が悪化することがあります(ログ肥大・二重実行・更新競合の増幅など)。そこで、現場向けに“安全側”の基本手順を整理します。
- 発生点を固定する:どの処理が、どのパスで、どの操作(open/write/rename/delete)で失敗したかをログに残す(時刻はできればミリ秒)。
- 二次被害を抑え込み:同一ファイルを更新するジョブを一時停止・直列化する(同時多発を避ける)。
- “掴んでいる手”を観測する:ProcMon等で SHARING VIOLATION の直前に誰が触ったかを確認する(第6〜7章)。
- 対象ファイルの状態確認:更新途中の可能性がある場合は、サイズ・更新時刻・ハッシュ等で「更新前/後/途中」を判断する。
- 復旧ルートを確保:バックアップ、スナップショット、過去バージョン等から戻せるかを確認する(戻せるなら、まず“戻して動かす”)。
ここで大事なのは、32そのものを“悪”と決めつけないことです。32はしばしば、「同時に触っている主体が複数ある」という事実を知らせます。つまり、エラーが出た瞬間は、システムが既に“協調設計”を要求している状態です。
2) “復旧編”の具体:更新途中・不整合のリスクに備える
32が出た時に最も怖いのは、「書き込みが途中で止まって不整合が残る」ケースです。これはファイル種別によって影響が大きく変わります。
| ファイル種別 | 不整合が起きた時の典型影響 | 復旧の考え方 |
| 設定ファイル(JSON/YAML/INI等) | 起動不能、読み取り例外、誤設定で誤動作 | 原子的差し替え+バックアップ世代管理/パース検証で“壊れた設定”を採用しない |
| ログ(追記型) | 欠損・重複・順序乱れ、解析不能 | 追記は共有許可・ローテーション設計が重要/解析は欠損前提で強くする |
| バイナリ(独自形式) | 部分破損で読み出し不能、復旧工数増 | チェックサム・ヘッダ整合性・世代バックアップ/安全更新方式の採用が鍵 |
復旧の要点は、「壊れた可能性があるものを、そのまま正としない」ことです。具体的には、
- 読み込み時に検証する(JSONならパース、スキーマ、必須キー、値域)。
- 世代を持つ(直近N世代を残し、最新が壊れていたら1つ前へ戻す)。
- 置換の原子性を担保する(途中状態が“正”として見えないようにする)。
この3点が揃うと、32が出ても“復旧は筋が良い”状態になります。逆に、ここが薄いと、32が出た瞬間に「壊れたかも」という恐怖が増幅し、対人調整が難しくなります。
3) “再発を抑え込み”:競合頻度を下げる構成と運用の落とし所
現場が本当に困るのは、32が「週1回」ではなく「毎日」「特定窓で多発」する状態です。この場合、対策は“技術”だけではなく、運用と構成の落とし所を決める必要があります。
典型的な落とし所は次の3つです。
- 更新主体を減らす:更新はローカルで完結し、共有には成果物のみ配置する(第9章の要点)。
- 衝突窓を避ける:バックアップ窓・スキャン窓と、更新バッチを同じ時間帯に置かない。
- 例外時の挙動を設計する:リトライ上限、バックオフ、ジッター、失敗時のロールバック、アラート条件を決める。
ここで「また運用が増えるだけじゃないの?」と感じるのは自然です。ですが、運用が増えるのではなく、“火種が増えないように場を整える”ための最小限の設計です。実際、何も決めないまま放置すると、対応が属人化し、夜間対応の頻度が上がり、結果として運用が増えます。
4) 一般論の限界:本当に効く対策は“案件の条件”で変わる
ここまでの話は、あくまで一般論として筋の良い道筋です。ただし、実際の対策で勝負を分けるのは、個別案件の条件です。たとえば次のような条件で、最適解が変わります。
- 対象がローカルか、SMB共有か、クラウド同期領域か(関与者の数が変わる)
- 対象ファイルが設定・成果物・ログ・データ(独自形式)など何か(壊れ方が違う)
- 更新頻度と同時実行数(衝突の確率が変わる)
- AV/EDR/バックアップの要件(止められない前提がある)
- 監査・BCP・復旧時間目標(RTO/RPO相当の要求)
つまり、32を“収束”させるには、コードだけ直しても足りないことが多い。逆に、運用だけ変えても足りないこともあります。アプリ・運用・構成のどこにブレーキをかけるのが最も効くかは、案件固有の判断になります。
5) 次の一歩:相談すべきタイミングと、相談で決まること
次のような状態なら、一般論の対策を試すより、早めに専門家へ相談した方が、結果としてトータル工数が減ります。
- 32が特定窓で多発し、夜間対応や手戻りが発生している
- 共有・同期・バックアップ・監視など関与者が多く、原因が一つに絞れない
- 更新対象が重要(設定・マスタ・成果物)で、破損時の影響が大きい
- 「責任の押し付け合い」になり、意思決定が止まっている
株式会社情報工学研究所であれば、単に「ツールを入れましょう」で終わらせず、現場の観測(ProcMon等)→再現条件の固定→原因の特定→衝突に強い設計への落とし込みまで、案件条件に合わせて整理できます。契約・体制・運用制約(止められない監視、BCP要件、夜間バッチなど)を前提に、“現場が回る”ところへ軟着陸させるのが、最終的な価値になります。
「今すぐ大改修は無理。でも、これ以上の夜間対応は増やしたくない」——その本音は健全です。だからこそ、まずは現状の観測と、最小の抑え込み(被害最小化)から始めるのが現実的です。
付録:現在よく使われるプログラミング言語別—ERROR_SHARING_VIOLATION(32)を増やさないための注意点
この付録は「言語ごとの癖で32を引き起こしやすい点」を、一般論として整理します。注意してほしいのは、同じ言語でもランタイム/標準ライブラリ/利用APIによって挙動が変わることです。ここでは「確認すべきポイント」を中心に書きます(断定しすぎないためです)。
C / C++(Win32 API 直叩き・CRT経由を含む)
- ShareModeの指定を“意識して確認”:CreateFile を使うなら、他プロセスに何を許すか(read/write/delete)を決めないと、占有オープンになりやすいです。
- 例外・早期returnでのクローズ漏れ:RAIIでハンドル寿命を管理し、異常系でも確実にCloseされる形にします。
- 置換更新(rename/MoveFileEx等)との相性:置換を使うなら、周辺プロセスが掴んでいて失敗する前提で、リトライ・ロールバックの筋道を用意します。
- マルチスレッドでの自己衝突:同じパスに対して並列でopen/renameが走ると、味方同士で32を作ります。対象ファイル単位の直列化が有効です。
C# / .NET(ASP.NET、Windowsサービス、バッチ等を含む)
- FileStream等の共有指定を確認:既定の共有許可は呼び出し方で変わり得ます。読み取り・書き込み・置換のどれかで、必要な共有(特に削除/リネーム許可)を検討します。
- using / Dispose の徹底:ガベージコレクション任せにすると、解放タイミングが読めず、掴みっぱなしが起きやすくなります。
- 原子的差し替えの採用:テンポラリへ書いて置換する、壊れた中間状態を“正”として見せない、が基本です。失敗時の復旧(旧版へ戻す)もセットで設計します。
- 監視(FileSystemWatcher)と更新の干渉:更新イベントをトリガに別処理が同じファイルを触り、衝突することがあります。監視側の遅延・デバウンス、処理の直列化が重要です。
Java / Kotlin(JVM系、Spring等を含む)
- NIOのmove/renameで“原子的”を期待しすぎない:原子的移動を指定しても、環境(ファイルシステムや共有)によって成立しないことがあります。例外時のフォールバック手順が必要です。
- ストリームのクローズ保証:try-with-resources を使い、例外や途中returnでもクローズされる形にします。
- ログ/一時ファイルの置き場所:同期・監視される領域へ中間生成物を置くと、外部プロセスとの衝突を増やします。更新頻度が高いものほど配置を再検討します。
Python(バッチ、運用スクリプト、ETL等を含む)
- “簡単に書ける”ぶん、クローズ漏れが埋もれやすい:with 構文でファイル寿命を明確にします。
- 共有許可や低レベル制御が必要なら要検討:標準のopenだけで制御しきれない場合があります(案件によってはWin32 APIを叩く/専用ライブラリを使う判断になります)。
- リトライは無限にしない:運用スクリプトほど“待ち続ける”事故が起きやすいです。回数上限・バックオフ・ログの残し方を決めます。
- CSV/JSON更新は置換方式+検証:書き込み途中の破損に備え、テンポラリ→差し替え+パース検証+世代管理を揃えると復旧が楽になります。
JavaScript / Node.js(サーバサイド、CLI、ビルド処理等を含む)
- 非同期I/Oで“終了したつもり”になりやすい:await漏れやコールバックの取り回しで、ハンドルが生き残ることがあります。I/O完了とクローズ完了を明確にします。
- watch系(監視)と生成物の更新が衝突:監視が生成物を即座に読み、置換更新と競合することがあります。監視側の遅延や、生成物の置き場所分離が有効です。
- ビルド/デプロイの並列化に注意:同じ成果物パスに同時出力すると自己衝突します。出力先の分離・ロック・直列化を検討します。
Go
- defer Closeの徹底:エラー分岐が多いとClose漏れが起きがちです。deferで寿命管理を統一します。
- 原子的差し替え+失敗時の後始末:テンポラリファイルの残骸が蓄積すると、運用事故(ディスク圧迫や誤読)につながります。失敗時に掃除する設計を入れます。
- 並列処理の自己衝突:goroutineで簡単に並列化できるぶん、同一パス更新が競合しやすいです。対象キー(ファイル)単位の直列化が有効です。
Rust
- 所有権で“メモリは安全”でも、I/Oは別:ファイル共有競合は外部要因で起きます。Close保証、置換更新、リトライ方針は別途設計が必要です。
- 一時ファイル運用:テンポラリを使う場合は命名規則・掃除・権限を決め、運用で迷子にならないようにします。
- サービス化(常駐)時のログ出力:ログファイルを掴みっぱなしにする設計は、ローテーションやバックアップと衝突しがちです。ログ運用の設計を前提にします。
PHP(Webアプリ、バッチ、CMS周辺を含む)
- 同時リクエストで同一ファイル更新が起きる:Webは並列です。ファイルを“DB代わり”に使うと競合しやすいので、更新箇所の設計を見直します。
- ファイルロックの使い方に注意:ロックは万能ではなく、共有許可衝突(32)と混ざると切り分けが難しくなります。目的(直列化か、破損防止か)を明確にします。
- アップロード/生成物の置き場所:同期対象やバックアップ窓と衝突しない配置・権限設計を行います。
Ruby
- ブロックでクローズ保証:ブロック構文でファイル寿命を明確にし、例外時も解放される形にします。
- ジョブ実行基盤(Sidekiq等)での同時実行:同じパスを複数ワーカーが触ると自己衝突します。ジョブ設計と直列化が重要です。
- 一時ファイル→置換の後始末:失敗時のtmp残りは、後で別処理が拾って事故になります。掃除を設計に入れます。
PowerShell(運用自動化、管理スクリプト)
- “簡単に書ける”ぶん、リトライの作り込み不足が起きやすい:回数上限・待機・ログを明示し、失敗時に人が判断できる出力にします。
- CSV/ログを共有領域に直接書かない:共有への直接更新は衝突要因を増やします。ローカル生成→確定後コピー、などが収束しやすいです。
- 管理者権限での強制操作は慎重に:掴んでいるプロセスの強制終了やサービス再起動は、他影響が大きいので“手順化”と“影響範囲の明確化”が必要です。
Bash / シェル(WSL含む運用、CI/CD)
- Windowsファイルシステム境界の挙動差:WSLや共有マウントを挟むと、期待通りに置換できない・タイミングがズレるなどが起き得ます。対象パスの実体(どのFSか)を確認します。
- 並列実行(xargs -P等)での自己衝突:同じ成果物へ同時書き込みしない設計(出力先分離)が重要です。
- 失敗時の復旧手順:CI/CDほど「途中で止まった成果物」が残ると混乱します。中間生成物と最終成果物を分けます。
まとめ:言語差より先に“設計の共通項”を押さえる
言語ごとの癖はありますが、32を抑え込むための共通項はブレません。
- ハンドル寿命を明確にする(Close/Dispose保証)
- 共有環境を前提にする(更新主体を減らし、衝突窓を避ける)
- 壊れない更新方式(テンポラリ→原子的差し替え+検証+世代)
- 観測して説明できる(ProcMon等で原因を確定し、対策の合意を取りやすくする)
そして最後に、一般論だけでは決められない部分(共有の要件、監視/バックアップの制約、RTO/RPO相当の要求、契約上の責任分界)があります。そこは、案件の条件を揃えて判断する領域です。もし「この条件でどうするべきか」で悩んだら、株式会社情報工学研究所のような専門家に相談し、観測と設計をセットで整理するのが、結果として最短の収束につながります。

 [出典:総務省『情報通信白書』2024年]
[出典:総務省『情報通信白書』2024年] 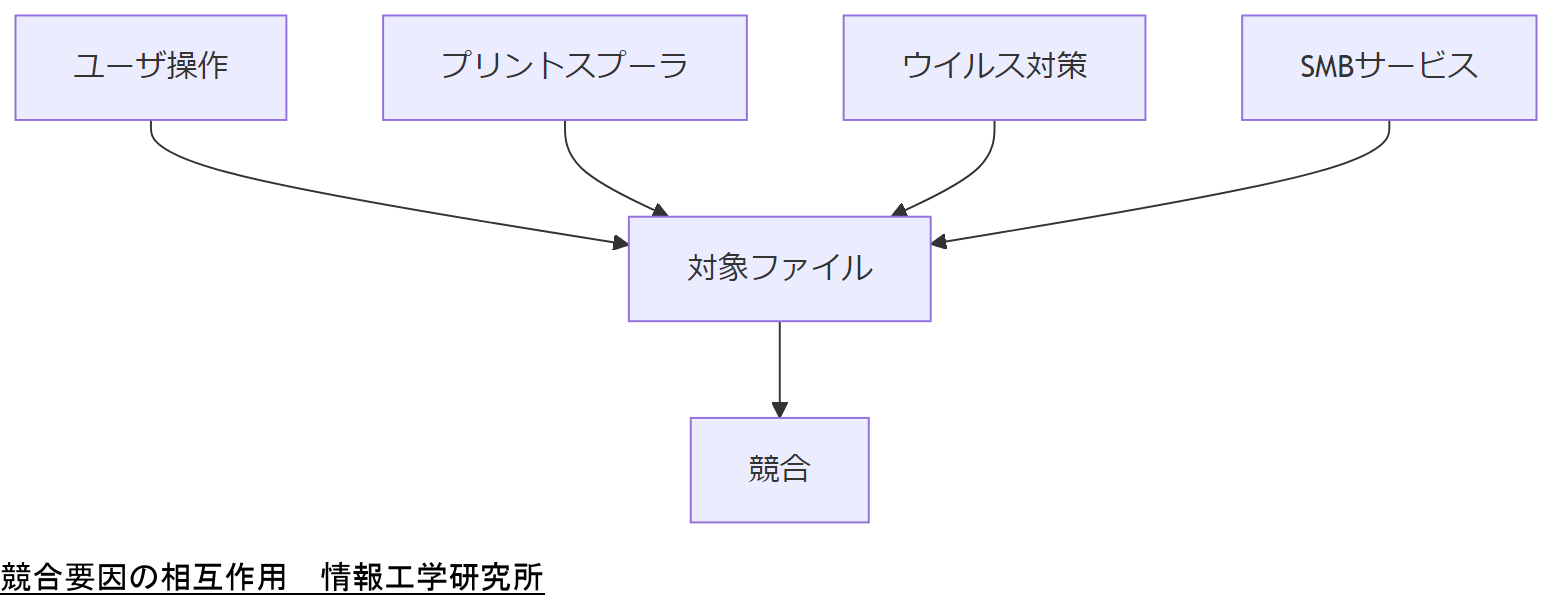 [出典:経済産業省『サイバーセキュリティ動向調査』2024年]
[出典:経済産業省『サイバーセキュリティ動向調査』2024年]  [出典:内閣府『事業継続ガイドライン』2023年]
[出典:内閣府『事業継続ガイドライン』2023年]  [出典:総務省『ICTシステム設計指針』2022年] [出典:デジタル庁『システム運用管理ガイドライン』2023年]
[出典:総務省『ICTシステム設計指針』2022年] [出典:デジタル庁『システム運用管理ガイドライン』2023年]  [出典:内閣サイバーセキュリティセンター『統一基準群』2024年] [出典:EU NIS2 Directive 2022/2555]
[出典:内閣サイバーセキュリティセンター『統一基準群』2024年] [出典:EU NIS2 Directive 2022/2555]  [出典:IPA『IT人材白書』2023年]
[出典:IPA『IT人材白書』2023年]  [出典:内閣サイバーセキュリティセンター『サイバーセキュリティ基本法概要』2024年] [出典:内閣府『災害対策基本法』2023年] [出典:EU『Directive (EU) 2022/2555』]
[出典:内閣サイバーセキュリティセンター『サイバーセキュリティ基本法概要』2024年] [出典:内閣府『災害対策基本法』2023年] [出典:EU『Directive (EU) 2022/2555』]  [出典:国税庁『中小企業経営強化税制の概要』2024年] [出典:経済産業省『サイバーセキュリティ対策推進補助金要領』2023年]
[出典:国税庁『中小企業経営強化税制の概要』2024年] [出典:経済産業省『サイバーセキュリティ対策推進補助金要領』2023年]  [出典:内閣府『事業継続ガイドライン』2023年] [出典:総務省『情報通信白書』2024年]
[出典:内閣府『事業継続ガイドライン』2023年] [出典:総務省『情報通信白書』2024年]  [出典:警察庁『サイバーセキュリティ戦略』2022年]
[出典:警察庁『サイバーセキュリティ戦略』2022年]  [出典:総務省『情報通信白書』2024年]
[出典:総務省『情報通信白書』2024年]  [出典:中小企業庁『IT導入補助金ガイドライン』2024年]
[出典:中小企業庁『IT導入補助金ガイドライン』2024年]  [出典:内閣府『事業継続ガイドライン』2023年]
[出典:内閣府『事業継続ガイドライン』2023年]  [出典:経済産業省『産業動向レポート』2024年]
[出典:経済産業省『産業動向レポート』2024年]  [出典:内閣府『事業継続ガイドライン』2023年]
[出典:内閣府『事業継続ガイドライン』2023年]