【注意】本記事は、Linux の ETXTBSY (26)「Text file busy」エラーについて、一般的に知られている原因・回避策・再試行設計を整理した情報提供です。実際の最適解は、対象のファイルシステム(ローカル/共有/コンテナ)、デプロイ方式、権限、稼働状況、復旧期限などで変わります。重要システムや重要データが関わる場合は、判断を誤ると障害の長期化や二次トラブルにつながるため、株式会社情報工学研究所のような専門事業者に個別案件として相談してください。
第1章:深夜デプロイで突然の「Text file busy」――“俺のせいじゃない感”の正体
夜間のデプロイや緊急パッチ適用で、いつも通りにバイナリを差し替えたつもりなのに、突然の ETXTBSY (Text file busy)。ログには「busy」って書いてあるけど、いわゆるファイルロック(flock)を取った覚えはない。しかも失敗したり、たまに成功したりする。現場だと、これが一番つらいタイプの不具合ですよね。
頭の中では、だいたいこういう独り言が回ります。
- 「え、今それ誰が掴んでるの? プロセス? systemd? それともCI?」
- 「いつも通ってる手順なのに、なぜ今日だけ…」
- 「説明資料を作れと言われても、“たまに起きる”は通らないんだよな…」
こういうモヤモヤを、まず否定しません。むしろ健全です。なぜなら ETXTBSY は、アプリのバグというより OSが“壊れにくくするための挙動”として出てくることが多いからです。つまり「誰かが悪い」より先に、「並行実行と差し替えの設計」が問われます。
本記事のゴールは、ETXTBSYを「運が悪いエラー」から「設計で沈静化できる現象」へ変えることです。具体的には次の順で腹落ちするように進めます。
- 何が起きるとETXTBSYになるのか(ロックではなく“実行と書き込み”の衝突)
- ありがちな地雷(cpで上書き、O_TRUNC、共有ストレージ、コンテナ)
- 回避の基本(その場で書かない、原子リネーム、切替設計)
- それでも起きる前提の再試行(指数バックオフと観測可能性)
ここまでできると、上司や他部署への説明も変わります。「不具合」ではなく「運用上のレース条件」であり、被害最小化の設計で収束させられる――と筋道立てて話せるようになります。
章末まとめ
- ETXTBSYは「ロックの取り忘れ」より「実行と書き込みの衝突」で起きやすい。
- 再現が揺れるのは、並行実行のタイミング依存(レース条件)だから。
- 設計で“沈静化”できる領域が大きい(原子置換+再試行)。
第2章:ETXTBSY(26)は「ファイルロック」ではない――カーネルが守っているもの
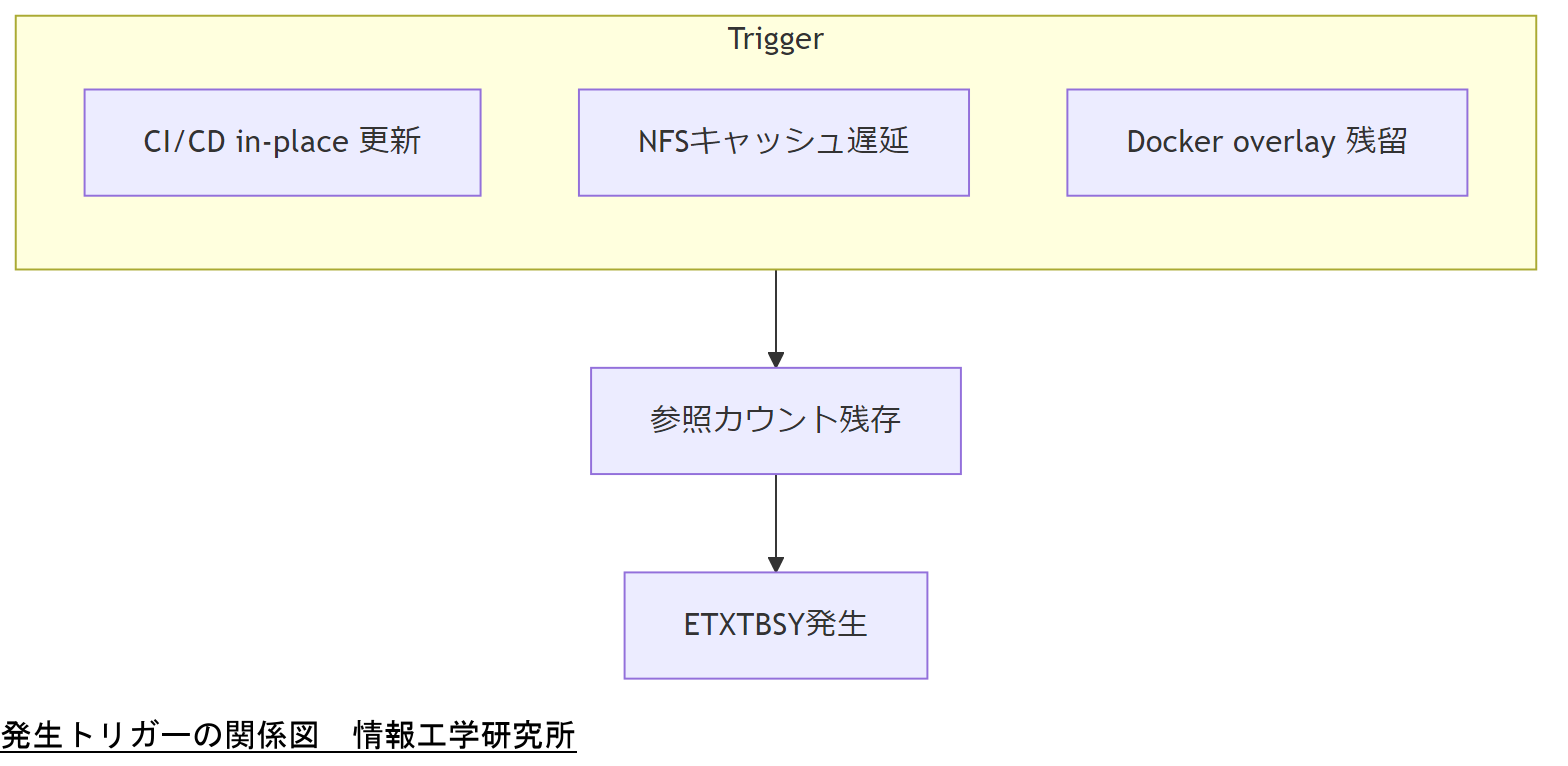
ETXTBSY は errno 26 で、メッセージとしては「Text file busy」と表示されることが多いです。ここで重要なのは、“Text”がテキストファイルを意味しているわけではない、という点です。歴史的に「実行対象(コード)として扱われるファイル」が関わるときに、このエラーが出る系譜があります。
ざっくり言うと、ETXTBSY は次のような衝突をOSが検知したときに返されます。
- 実行中のファイルを「書き込み目的で開く」(上書き・truncate・書き換え)
- 書き込み中のファイルを「実行しようとする」(execve が実行を拒否)
そしてこの「実行」と「書き込み」は、アプリが明示的に排他制御(flock)していなくても、カーネルが内部で“書き込みを拒否する/実行を拒否する”ことで整合性を守る場合があります。ここが「ロックじゃないのに busy になる」最大の理由です。
「どの操作で出やすいか」を整理する
現場では、操作と発生条件を切り分けると一気に見通しが良くなります。代表例を表にします(実際の挙動はファイルシステムや実行形式、権限、マウント方式により差が出るため、あくまで“起点”として捉えてください)。
| やろうとしたこと | 典型的なトリガ | 現場での見え方 |
| 実行中バイナリを差し替える | cp が O_TRUNC を伴う上書きをする/同一パスで書き込みオープンする | デプロイが時々失敗し「Text file busy」 |
| 生成中のファイルを即実行する | ビルド・展開直後に実行、別プロセスがまだ書き込み中 | 起動スクリプトやCIで sporadic に落ちる |
| 共有ストレージ上で同時更新 | NFS/SMB/分散FSで更新の見え方が揺れる/ロックやキャッシュの差 | あるノードだけ失敗、再試行で通る |
「unlinkできるのにbusyになる」矛盾の解消
Linux では、実行中のバイナリでも unlink(削除)や rename(名前の付け替え)ができるケースがあります。実行中プロセスはディレクトリエントリではなく “開いている実体(inode)”を参照しているため、パスが消えても動き続けられる、という性質があるからです。
一方で「その実体を、書き込み目的で開いて中身を壊す」ことまで無条件に許すと、実行中コードが途中で変わり得ます。これは安全性の観点でまずい。そこで、カーネルやファイルシステムの実装が “実行と書き込みが同時になりそうなら拒否する”場面があり、その代表的な表現が ETXTBSY です。
章末まとめ
- ETXTBSY は「flockが取れていない」ではなく「実行と書き込みの衝突」で起きやすい。
- unlink/rename と “書き込みオープン(truncate含む)” は別物。後者が危険で busy になり得る。
- 以降は、どの手順が「書き込みオープン」になっているかを具体的に潰していく。
第3章:再現パターンはだいたい2つ――“実行中の上書き”と“書き込み中の実行”
ETXTBSY の現場発生は、観測していくと大半が次の2系統に収束します。
パターンA:実行中のファイルを上書きしようとして失敗する
一番多いのがこれです。たとえば「/usr/local/bin/app を差し替える」時に、何気なく cp を使うと、cp は対象ファイルを 書き込み目的で開いて truncate(サイズを0にする) し、その上で新しい内容を書き込む流れになりがちです。この “書き込み目的で開く” の時点で、実行中と衝突して ETXTBSY になります。
心の会話で言うと、こうです。
「mvなら通ることがあるのに、cpだと落ちる。え、何が違うの?」
違いは、同じ実体を“書き換える”か、別の実体に“置き換える”かです。cp は同じパスの同じ実体を削って書き直す動きになりやすい。一方、後述する“原子リネーム(別ファイルを作って名前だけ入れ替える)”は、実行中の実体を直接書き換えないため衝突を避けられます。
パターンB:書き込み中のファイルを実行しようとして失敗する
もう一つは、生成・展開中の成果物を「できた」と見なして起動してしまうケースです。代表例は次です。
- ビルド/展開プロセスがまだ書き込み中なのに、別プロセスが起動しに行く
- コンテナのエントリーポイントが、初期化スクリプトで生成したファイルを直ちに実行する
- 共有ストレージで、あるノードから見ると“できたように見える”が、別ノードでは更新中
この場合は、実行側が execve しようとした瞬間に ETXTBSY が返り、「起動そのものが弾かれる」形で見えます。
「なぜ再試行で直ることが多いのか」
ETXTBSY が厄介なのは、同じ手順でも「通る時は通る」ことです。これは多くの場合、永続的な故障ではなく 一時的な並行状態だからです。たとえば、更新が数百ミリ秒遅れただけで衝突が解けることもあります。
ただし、ここで雑に無限リトライすると別の事故が起きます。ログが埋まる、更新が遅延する、監視が誤検知する、最悪は“更新できていないのに成功扱いに見える”などです。なので、再試行をするにしても 設計された再試行(回数・待ち・条件)が必要です。
章末まとめ
- ETXTBSY の現場パターンは「実行中を上書き」か「書き込み中を実行」が多い。
- 「通ったり落ちたり」は、並行タイミング依存で説明できる。
- 再試行は有効になり得るが、“条件付き・回数付き”で設計しないと事故る。
第4章:「cpで置き換え」は地雷になり得る――原子リネームで“被害最小化”する
ここからが実務で効く回避策です。結論から言うと、ETXTBSY を継続的に抑え込む最短ルートは、デプロイや更新で “その場で書かない” 方式に寄せることです。キャッチーに言うなら「ダメージコントロールとして、置換手順を原子化する」です。
よくある“危ない差し替え”
危ないのは、実行ファイルのパスに対して、同じ実体を直接書き換える操作です。典型は次です。
- cp new app(内部で truncate を伴う上書きになりやすい)
- cat new > app(確実に truncate してから書く)
- インプレース更新(同一ファイルを開いて内容を書き換える)
これらは、実行中と衝突すると ETXTBSY を引きやすいだけでなく、仮に busy にならずに通ったとしても「途中まで書けた状態」など、更新失敗時の姿が汚くなりやすい。運用で見ると、復旧の難易度が上がります。
安全側の基本:一時ファイルに出してから rename で置き換える
推奨パターンは次です。
- 同一ディレクトリ内に一時ファイルとして新バイナリを配置する(例:app.new)
- パーミッションや所有者を整える(実行ビットを含む)
- 必要なら fsync で書き込み完了を確実にする(要件次第)
- rename(mv)で app.new → app に切り替える
rename はディレクトリエントリの付け替えであり、更新中に中身をチマチマ書き換えるのと比べて、失敗時の状態が単純です。実行中プロセスは旧実体を参照し続け、新しい起動から新実体を参照する、という形になりやすい。結果として、衝突や不整合を“場を整える”方向に持っていけます。
実務で使える最小の例(概念)
環境に合わせて調整は必要ですが、考え方はこの程度のシンプルさから始められます。
#!/bin/sh set -eu
TARGET="/usr/local/bin/app"
TMP="/usr/local/bin/.app.new.$$"
1) 新しいバイナリを一時ファイルへ(例:配布済みのapp.newをコピー)
cp -f "./app" "$TMP"
chmod 0755 "$TMP"
chown root:root "$TMP" 2>/dev/null || true
2) 原子リネーム(同一ファイルシステム・同一ディレクトリが前提)
mv -f "$TMP" "$TARGET"
ポイントは「TARGET を開いて書き換えない」ことです。cp を使うとしても、TARGET へ直接 cp するのではなく、一時ファイルへ cp してから mv する。これだけで ETXTBSY の発生確率が大きく下がるケースが多いです。
systemd運用なら「切替」と「再起動」を分離して考える
プロセスが掴んでいる最中に上書き衝突するなら、発想を変えて「切替(ファイル置換)」と「プロセス制御(restart)」を分離します。たとえば、次のような運用に寄せると説明も簡単になります。
- 切替:一時ファイル→rename で原子置換(ETXTBSYを抑え込みやすい)
- 再起動:systemd で順序制御(必要なタイミングだけ restart)
このあたりから、一般論だけでは最適解が分岐します。単一ノードか、冗長構成か、共有ストレージか、夜間帯の変更許容度はどうか。要件が絡むほど、手順の“正しさ”は変わります。重要システムで「これ、うちの構成だとどこが地雷?」となったら、株式会社情報工学研究所のような専門家に構成前提で相談する方が、結果的に早いことが多いです。
章末まとめ
- ETXTBSYを避ける第一歩は「実行ファイルをその場で書き換えない」。
- 一時ファイル+原子リネーム(mv/rename)で、失敗時の状態も単純化できる。
- 運用(systemd・冗長化・共有FS)まで含めると分岐するため、個別案件では専門家相談が有効。
第5章:伏線回収①:正解は“その場で書かない”――一時ファイル+原子リネームの設計ポイント
第4章で「一時ファイル→rename(mv)」が効く、という話をしました。ただ、現場に落とすときに必ず出るツッコミがあります。
「それは分かった。でも、どこまでが“安全”で、どこからが“危ない”の?」
この問いに答えるために、原子リネームの“成立条件”を整理します。結論から言うと、原子リネームが強いのは、同一ファイルシステム・同一ディレクトリ内での rename(2) が、原子的(中途半端が見えない)という性質を前提にできるからです。逆に言えば、その前提が崩れると「mvしたのに微妙に怪しい」が起き得ます。
原子リネームの成立条件
| 項目 | 満たしたい条件 | 満たせないときのリスク |
| 配置場所 | 一時ファイルはターゲットと同じディレクトリに置く | 別FSを跨ぐと「コピー+削除」になり原子的でなくなる |
| 書き込み完了 | 一時ファイルの内容が完成してから切替 | 生成途中のものを切替すると起動失敗や不正実行に繋がる |
| 権限/所有者 | chmod/chown を切替前に確定 | 切替後に権限調整すると、実行競合や権限エラーが混ざる |
| 参照の一貫性 | 起動側が“完成済みの実体”だけを実行する | 共有FSでは「見え方」が揺れて、書き込み中に見えることがある |
“その場で書かない”を徹底するための現場パターン
原子リネームを使う更新手順は、突き詰めると「完成品だけを表舞台に出す」という設計です。具体的には次の3パターンが現場でよく使われます。
- パターン1:単純置換(一時ファイル→mvで置換)
- パターン2:世代管理(app-20251222-1 のように世代を作り、シンボリックリンクを付け替える)
- パターン3:ディレクトリ切替(/opt/app/releases/… を切替し、current を付け替える)
ETXTBSY対策としては、どれも「実行中の実体を直接書き換えない」点で共通です。違いは運用上のメリット・デメリットです。
世代管理(symlink切替)が効く理由と注意点
symlink切替は「切替点」を1箇所に集約できるので、運用が読みやすくなります。いっぽうで注意点もあります。たとえば、起動スクリプトが symlink を解決した後に別の参照をするなど、実装によっては“途中で指す先が変わる”ことがあります。設計としては、起動時にパスを確定させる、systemd の ExecStart を固定するなど、参照の一貫性を意識します。
章末まとめ
- 原子リネームの強みは「中途半端が見えない」こと。前提(同一FS/同一Dir)を外すと弱くなる。
- 実務では「完成品だけを表に出す」設計(世代管理・symlink・ディレクトリ切替)が効く。
- 共有FSや起動方式の癖で参照が揺れるので、構成前提で調整が必要。
第6章:伏線回収②:共有ストレージ/コンテナ/バインドマウントで増えるレース条件
ETXTBSY が「たまに起きる」から「頻繁に起きる」に変わる境目が、共有ストレージやコンテナ境界です。ここで大事なのは、エラーが“増えた”のではなく、“並行状態が増えた”という見方です。
共有ストレージで起きがちなこと
NFS/SMB/分散ファイルシステムなどでは、クライアント側キャッシュやロック機構、更新通知のタイミングが絡みます。すると、次のような現象が起こり得ます。
- 更新した側では「もう切り替わった」つもりだが、別ノードではまだ旧状態が見える
- 一時ファイル生成→mv のつもりが、クライアント実装や設定によっては“見え方”が揺れる
- ロックが期待通りに伝播せず、書き込み中に実行が走る
この結果、「原子リネームで完璧なはずなのに、別ノードがETXTBSYで落ちる」が発生します。ここが設計の分岐点で、一般論だけでは言い切れません。マウントオプション、キャッシュ戦略、更新の伝播、アプリの起動方式――この組み合わせで最適解が変わります。
コンテナ/バインドマウントの“地味な罠”
コンテナでは、ホスト側のディレクトリをバインドマウントしてコンテナ内で実行する構成があります。このとき、ホストで更新が走り、コンテナで実行が走る――という 別プロセス空間・別権限・別タイミングが重なります。
心の会話で言うとこうです。
「コンテナを再起動しただけなのに、起動直後にETXTBSY…え、ホスト側の更新と当たってる?」
この場合、対策の方向性は2つです。
- 更新と起動の順序を制御する(更新が終わってから起動、または起動を待機)
- 実行物をバインドマウントしない(イメージ内に取り込み、更新はイメージ更新で行う)
後者は運用が大きく変わるので、システム要件(更新頻度、ロールバック、監査、保守体制)に合わせて判断します。
章末まとめ
- 共有FSやコンテナ境界では「並行状態」が増え、ETXTBSYが顕在化しやすい。
- “原子リネームだけ”で解決しないときは、順序制御や配置設計まで含めて見直す。
- 構成依存が強い領域なので、重要案件ほど専門家レビューがコスパ良い。
第7章:運用設計で潰す――systemd・ローリング更新・切替の手順化
ここまでの話で、「やり方を変えればETXTBSYは抑え込める」ことは見えてきたと思います。次に問われるのは、“個人の腕”ではなく“手順として再現できるか”です。事故はだいたい、属人化した更新手順の境目で起きます。
運用としての“場を整える”ポイント
ETXTBSYを収束させる運用設計の要点は、次の3つに集約されます。
- 切替(ファイル置換):一時ファイル/世代管理/ディレクトリ切替で原子的に
- 起動(プロセス制御):systemd などで順序と再起動を制御
- 分散(複数ノード):ローリング更新で同時衝突を避ける
systemdの再起動は“何でも解決”ではない
ETXTBSYが出ると「とりあえず再起動しよう」となりがちですが、再起動だけで解決しないケースがあります。なぜなら、原因が「更新中」や「別プロセスの書き込み」と衝突している場合、再起動は衝突を増やすこともあるからです。
設計としては、更新完了を確認してから再起動、または再起動側が一定時間待機してから起動する、という順序制御が効きます。これが次章の「再試行設計」に繋がります。
ローリング更新が“ETXTBSY耐性”を上げる理由
複数ノードがあるなら、同時に全台更新するより、順番に更新していく方が衝突が減ります。さらに、障害時の影響範囲も限定できます。これは運用の観点では“被害最小化”そのものです。
ただし、ロードバランサ、セッション、ジョブの偏り、依存関係などが絡むので、ここも一般論だけで正解が一つにはなりません。更新の単位・停止許容時間・冗長度・監査要件など、システムの前提を揃えて設計する必要があります。
章末まとめ
- ETXTBSY対策は“手順化”して初めて強い。属人手順は事故の温床。
- 再起動は万能ではなく、更新と起動の順序を制御する設計が重要。
- 分散環境はローリング更新で衝突と影響範囲を抑え込める。
第8章:それでも起きる前提で作る――待機+指数バックオフ+最大試行回数
ここからが「再試行編」の本丸です。どれだけ設計を整えても、実運用では“完全にゼロ”にできないことがあります。特に、共有FS・複数プロセス・CI/CD・自動復旧が重なると、レース条件は残ります。
そこで重要なのが、再試行を“雑にやらない”ことです。再試行は正しくやれば沈静化に効きますが、雑にやると火に油です。
再試行設計の基本(ルール化)
ETXTBSYの再試行は、次の3点をセットにして運用に組み込みます。
- 待機:一定間隔または指数バックオフで待つ
- 上限:最大試行回数や最大待機時間を決める
- 条件:本当に“待てば解けるタイプ”かを判定する(後述)
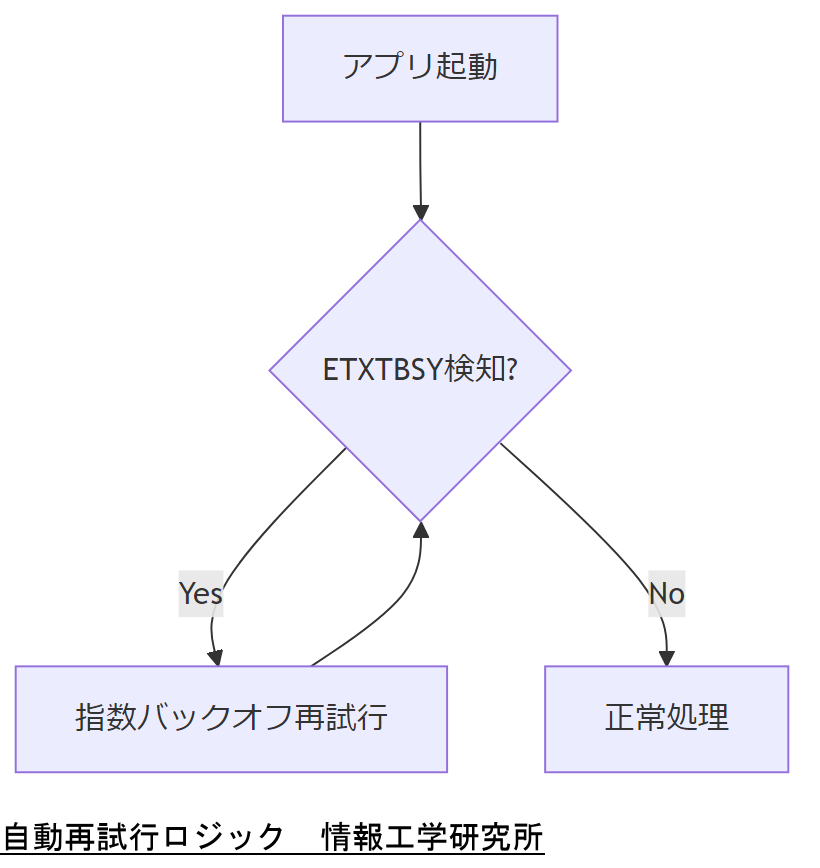
指数バックオフが効く理由
ETXTBSYは多くの場合「短時間の衝突」です。固定間隔で高速に叩くと、衝突し続ける(=同時起動が増える)可能性があります。指数バックオフは、最初は早くリカバーを試みつつ、衝突が続くなら徐々に間隔を広げて“空気を落ち着かせる”方向に持っていけます。
最大試行回数を設けるのは“逃げ”ではない
「成功するまで無限にやればいいじゃん」と言いたくなる気持ちは分かります。ただ、無限リトライは監視・運用・人の判断を壊します。失敗を明示しないと、復旧判断(切り戻し、隔離、手動介入)が遅れます。
重要なのは、“失敗として止める条件”を決めることです。これが次章の「観測と判定」に繋がります。
章末まとめ
- ETXTBSYはゼロにできないことがある。だから再試行を設計する。
- 待機+指数バックオフで衝突を抑え込みやすい。
- 最大試行回数と停止条件がない再試行は、運用を壊す。
第9章:見える化すると腹落ちする――ログ設計と「再試行が効く条件」の判定
再試行を“安全に”する鍵は、観測可能性です。ETXTBSYが出た瞬間に「今は待てばいいのか」「これは設計ミスで永続的に失敗するのか」を判定できると、現場は一気に楽になります。
ログに残したい最低限の項目
- 対象パス(どの実行物/どのリンクを更新しようとしたか)
- 操作(上書き/rename/起動/権限変更など)
- エラー番号とメッセージ(errno=26, ETXTBSY)
- 試行回数と待機時間(何回目で何秒待ったか)
- 同時実行の手掛かり(PID、ユニット名、ホスト名、コンテナID等)
「待てば解ける」か「待っても無理」か
ETXTBSYが返ってくる状況は、短時間で解けることが多い一方で、設計として永続的に衝突している場合もあります。例を挙げます。
| 分類 | 典型 | 判断 |
| 一時衝突 | デプロイ直後に起動が重なった/別プロセスの短い書き込み | 指数バックオフで再試行の価値が高い |
| 設計衝突 | 同一パスに常に上書きする設計/共有FSで更新伝播が崩れている | 上限到達で止め、手順・構成を改修すべき |
| 権限/配置ミス | ディレクトリ跨ぎでmvがコピーになっている/権限不備が併発 | ETXTBSY以外も混ざるので、再試行だけで解かない |
ここで「一般論の限界」が出る
観測可能性を整えると、逆に“分岐点”も見えます。共有FSの設定、コンテナの起動順序、実行物の配置、冗長構成、監査要件。これらは組織ごとの前提で最適解が変わり、「ブログで一般解を断言」すると危険になります。
だからこそ、終盤でははっきり言います。重要システムほど、観測ログを持って専門家に相談した方が早い。株式会社情報工学研究所のような事業者に、ログと構成を前提に「どこが衝突点か」を見てもらう方が、無限リトライで消耗するより合理的です。
章末まとめ
- 再試行の安全性は観測可能性(ログ設計)で決まる。
- ETXTBSYには「待てば解ける」と「待っても無理」がある。判定できると腹落ちする。
- 分岐点が多い領域なので、個別案件では専門家相談が最短になることがある。
第10章:帰結:ETXTBSYは“ミス”ではなく“並行実行の仕様”――置換と再試行を設計に組み込む
ここまで読んで、たぶん結論はこう腹落ちしているはずです。
ETXTBSYは、誰かの不注意というより「並行実行がある世界で、実行物をどう更新するか」という設計問題だ、と。
現場のつらさは「正しいことをしているつもりなのに、たまに落ちる」点にあります。これは精神的に削られます。でも、仕組みとして分解すれば、対策は整理できます。
最終的に押さえるべき“3点セット”
- 置換の設計:その場で書かず、完成品を原子的に切替(rename、世代管理、symlink、ディレクトリ切替)
- 順序の設計:更新と起動のタイミングを分離し、systemd/ローリング更新で衝突を抑え込み
- 再試行の設計:指数バックオフ+上限+停止条件、そしてログで判定できるようにする
「一般論の限界」を越えるタイミング
ここで強調したいのは、一般論はここまでだ、という点です。ETXTBSYの最適解は、システム構成に依存します。
- ローカルディスクか、共有ストレージか
- 単一ノードか、冗長化/クラスタか
- コンテナの有無、バインドマウントの有無
- 更新頻度、停止許容時間、監査・セキュリティ要件
これらが絡むと、単純な「mvでOK」では終わりません。むしろ、ここを誤ると、ETXTBSYを抑え込むどころか別の事故(更新不整合、ロールバック不能、監査不備)に繋がります。
ですので、最後は自然にこうなります。具体的な案件・契約・システム構成で悩んだら、株式会社情報工学研究所のような専門事業者に相談すべきです。ログや構成を前提に「何を原子化し、どこを待機し、どこで止めるか」を一緒に設計した方が、現場の疲弊が早く収束します。
章末まとめ
- ETXTBSYは“並行実行の仕様”として理解すると、対策が設計に落ちる。
- 置換・順序・再試行の3点セットで、現場のモヤモヤを収束させられる。
- 構成依存が強いので、個別案件は専門家相談が合理的。
付録:現在のプログラム言語各種における「Text file busy」的な落とし穴と注意点
最後に、運用現場でよくある「言語ごとのハマりどころ」をまとめます。ここで言う注意点は、“ETXTBSYが起きる/起きない”を断言するものではなく、実行物の更新・生成・起動が並行しやすい箇所に焦点を当てます。実際の挙動はOS・ファイルシステム・配置方式で変わるため、重要案件では検証と設計が必要です。
Shell(sh/bash)
- スクリプト生成→即実行(chmod直後に実行)を自前でやると、並行起動で衝突しやすい。
- 「cat > 実行ファイル」は truncate を確実に発生させるため、実行中差し替えと相性が悪い。
- 一時ファイル→mv、という原則を徹底しやすい一方、雑に書くと一番地雷を踏みやすい。
Python
- デプロイで .py を上書きしつつ、別プロセスが import するような並行があると、読み込み不整合や起動失敗の原因になる。
- 実行物を「スクリプト直置き」で更新するより、パッケージ化+リリースディレクトリ切替の方が安定しやすい。
- gunicorn/uwsgi 等のプロセス管理と、コード更新の順序(reload、graceful)を設計しないと事故る。
Node.js(JavaScript/TypeScript)
- ビルド成果物(dist)生成中にプロセスが参照すると、起動失敗や中途半端な読み込みが起きやすい。
- PM2 や systemd、コンテナ再起動とビルド/展開のタイミングが当たると、稀に「できた直後に実行」で衝突する。
- 世代ディレクトリ方式(releases)+切替、またはイメージ更新に寄せると収束しやすい。
Go
- 単一バイナリのため、更新対象が明確で“その場で上書き”をやりがち。ここがETXTBSYの温床になりやすい。
- 原子リネームや世代管理との相性は良いので、運用設計でかなり抑え込める。
- systemdの再起動と更新の順序制御をセットにしないと、更新競合が残ることがある。
Java / JVM系(Kotlin含む)
- jar/war の差し替えを「同一ファイルへ上書き」でやると、起動・クラスロード・展開タイミングで不整合が混ざりやすい。
- アプリサーバのデプロイ機構やローリング更新に乗せる方が、順序制御と観測が整いやすい。
- コンテナ化してイメージ更新に寄せると“完成品だけを実行”しやすいが、運用要件(監査、ロールバック)を要確認。
C/C++
- 実行バイナリを直接置換する運用になりがちで、cp上書き・truncate系の地雷を踏みやすい。
- 共有ライブラリ(.so)の差し替えは、プロセスがロード済みかどうかで挙動が変わり、説明が難しくなる。
- 世代管理+再起動の順序制御で“場を整える”方が、障害時の切り戻しも含めて安定する。
Rust
- 単一バイナリ配布が多く、Go同様「その場で上書き」になりやすい。置換設計を最初から入れるのが重要。
- CIでビルド→配置→起動が高速な分、並行タイミングの衝突が表に出やすい。
付録まとめ
- 言語差よりも「実行物の配置・切替・起動順序」の設計が本質。
- “完成品だけを実行する”形(原子切替、世代管理、イメージ更新)に寄せると、収束しやすい。
- 重要案件では、構成とログ前提で設計する必要があるため、株式会社情報工学研究所のような専門家への相談が合理的。
第5章:伏線回収①:正解は“その場で書かない”――一時ファイル+原子リネームの設計ポイント
第4章で「一時ファイル→rename(mv)」が効く、という話をしました。ただ、現場に落とすときに必ず出るツッコミがあります。
「それは分かった。でも、どこまでが“安全”で、どこからが“危ない”の?」
この問いに答えるために、原子リネームの“成立条件”を整理します。結論から言うと、原子リネームが強いのは、同一ファイルシステム・同一ディレクトリ内での rename(2) が、原子的(中途半端が見えない)という性質を前提にできるからです。逆に言えば、その前提が崩れると「mvしたのに微妙に怪しい」が起き得ます。
原子リネームの成立条件
| 項目 | 満たしたい条件 | 満たせないときのリスク |
| 配置場所 | 一時ファイルはターゲットと同じディレクトリに置く | 別FSを跨ぐと「コピー+削除」になり原子的でなくなる |
| 書き込み完了 | 一時ファイルの内容が完成してから切替 | 生成途中のものを切替すると起動失敗や不正実行に繋がる |
| 権限/所有者 | chmod/chown を切替前に確定 | 切替後に権限調整すると、実行競合や権限エラーが混ざる |
| 参照の一貫性 | 起動側が“完成済みの実体”だけを実行する | 共有FSでは「見え方」が揺れて、書き込み中に見えることがある |
“その場で書かない”を徹底するための現場パターン
原子リネームを使う更新手順は、突き詰めると「完成品だけを表舞台に出す」という設計です。具体的には次の3パターンが現場でよく使われます。
- パターン1:単純置換(一時ファイル→mvで置換)
- パターン2:世代管理(app-20251222-1 のように世代を作り、シンボリックリンクを付け替える)
- パターン3:ディレクトリ切替(/opt/app/releases/… を切替し、current を付け替える)
ETXTBSY対策としては、どれも「実行中の実体を直接書き換えない」点で共通です。違いは運用上のメリット・デメリットです。
世代管理(symlink切替)が効く理由と注意点
symlink切替は「切替点」を1箇所に集約できるので、運用が読みやすくなります。いっぽうで注意点もあります。たとえば、起動スクリプトが symlink を解決した後に別の参照をするなど、実装によっては“途中で指す先が変わる”ことがあります。設計としては、起動時にパスを確定させる、systemd の ExecStart を固定するなど、参照の一貫性を意識します。
章末まとめ
- 原子リネームの強みは「中途半端が見えない」こと。前提(同一FS/同一Dir)を外すと弱くなる。
- 実務では「完成品だけを表に出す」設計(世代管理・symlink・ディレクトリ切替)が効く。
- 共有FSや起動方式の癖で参照が揺れるので、構成前提で調整が必要。
第6章:伏線回収②:共有ストレージ/コンテナ/バインドマウントで増えるレース条件
ETXTBSY が「たまに起きる」から「頻繁に起きる」に変わる境目が、共有ストレージやコンテナ境界です。ここで大事なのは、エラーが“増えた”のではなく、“並行状態が増えた”という見方です。
共有ストレージで起きがちなこと
NFS/SMB/分散ファイルシステムなどでは、クライアント側キャッシュやロック機構、更新通知のタイミングが絡みます。すると、次のような現象が起こり得ます。
- 更新した側では「もう切り替わった」つもりだが、別ノードではまだ旧状態が見える
- 一時ファイル生成→mv のつもりが、クライアント実装や設定によっては“見え方”が揺れる
- ロックが期待通りに伝播せず、書き込み中に実行が走る
この結果、「原子リネームで完璧なはずなのに、別ノードがETXTBSYで落ちる」が発生します。ここが設計の分岐点で、一般論だけでは言い切れません。マウントオプション、キャッシュ戦略、更新の伝播、アプリの起動方式――この組み合わせで最適解が変わります。
コンテナ/バインドマウントの“地味な罠”
コンテナでは、ホスト側のディレクトリをバインドマウントしてコンテナ内で実行する構成があります。このとき、ホストで更新が走り、コンテナで実行が走る――という 別プロセス空間・別権限・別タイミングが重なります。
心の会話で言うとこうです。
「コンテナを再起動しただけなのに、起動直後にETXTBSY…え、ホスト側の更新と当たってる?」
この場合、対策の方向性は2つです。
- 更新と起動の順序を制御する(更新が終わってから起動、または起動を待機)
- 実行物をバインドマウントしない(イメージ内に取り込み、更新はイメージ更新で行う)
後者は運用が大きく変わるので、システム要件(更新頻度、ロールバック、監査、保守体制)に合わせて判断します。
章末まとめ
- 共有FSやコンテナ境界では「並行状態」が増え、ETXTBSYが顕在化しやすい。
- “原子リネームだけ”で解決しないときは、順序制御や配置設計まで含めて見直す。
- 構成依存が強い領域なので、重要案件ほど専門家レビューがコスパ良い。
第7章:運用設計で潰す――systemd・ローリング更新・切替の手順化
ここまでの話で、「やり方を変えればETXTBSYは抑え込める」ことは見えてきたと思います。次に問われるのは、“個人の腕”ではなく“手順として再現できるか”です。事故はだいたい、属人化した更新手順の境目で起きます。
運用としての“場を整える”ポイント
ETXTBSYを収束させる運用設計の要点は、次の3つに集約されます。
- 切替(ファイル置換):一時ファイル/世代管理/ディレクトリ切替で原子的に
- 起動(プロセス制御):systemd などで順序と再起動を制御
- 分散(複数ノード):ローリング更新で同時衝突を避ける
systemdの再起動は“何でも解決”ではない
ETXTBSYが出ると「とりあえず再起動しよう」となりがちですが、再起動だけで解決しないケースがあります。なぜなら、原因が「更新中」や「別プロセスの書き込み」と衝突している場合、再起動は衝突を増やすこともあるからです。
設計としては、更新完了を確認してから再起動、または再起動側が一定時間待機してから起動する、という順序制御が効きます。これが次章の「再試行設計」に繋がります。
ローリング更新が“ETXTBSY耐性”を上げる理由
複数ノードがあるなら、同時に全台更新するより、順番に更新していく方が衝突が減ります。さらに、障害時の影響範囲も限定できます。これは運用の観点では“被害最小化”そのものです。
ただし、ロードバランサ、セッション、ジョブの偏り、依存関係などが絡むので、ここも一般論だけで正解が一つにはなりません。更新の単位・停止許容時間・冗長度・監査要件など、システムの前提を揃えて設計する必要があります。
章末まとめ
- ETXTBSY対策は“手順化”して初めて強い。属人手順は事故の温床。
- 再起動は万能ではなく、更新と起動の順序を制御する設計が重要。
- 分散環境はローリング更新で衝突と影響範囲を抑え込める。
第8章:それでも起きる前提で作る――待機+指数バックオフ+最大試行回数
ここからが「再試行編」の本丸です。どれだけ設計を整えても、実運用では“完全にゼロ”にできないことがあります。特に、共有FS・複数プロセス・CI/CD・自動復旧が重なると、レース条件は残ります。
そこで重要なのが、再試行を“雑にやらない”ことです。再試行は正しくやれば沈静化に効きますが、雑にやると火に油です。
再試行設計の基本(ルール化)
ETXTBSYの再試行は、次の3点をセットにして運用に組み込みます。
- 待機:一定間隔または指数バックオフで待つ
- 上限:最大試行回数や最大待機時間を決める
- 条件:本当に“待てば解けるタイプ”かを判定する(後述)
指数バックオフが効く理由
ETXTBSYは多くの場合「短時間の衝突」です。固定間隔で高速に叩くと、衝突し続ける(=同時起動が増える)可能性があります。指数バックオフは、最初は早くリカバーを試みつつ、衝突が続くなら徐々に間隔を広げて“空気を落ち着かせる”方向に持っていけます。
最大試行回数を設けるのは“逃げ”ではない
「成功するまで無限にやればいいじゃん」と言いたくなる気持ちは分かります。ただ、無限リトライは監視・運用・人の判断を壊します。失敗を明示しないと、復旧判断(切り戻し、隔離、手動介入)が遅れます。
重要なのは、“失敗として止める条件”を決めることです。これが次章の「観測と判定」に繋がります。
章末まとめ
- ETXTBSYはゼロにできないことがある。だから再試行を設計する。
- 待機+指数バックオフで衝突を抑え込みやすい。
- 最大試行回数と停止条件がない再試行は、運用を壊す。
第9章:見える化すると腹落ちする――ログ設計と「再試行が効く条件」の判定
再試行を“安全に”する鍵は、観測可能性です。ETXTBSYが出た瞬間に「今は待てばいいのか」「これは設計ミスで永続的に失敗するのか」を判定できると、現場は一気に楽になります。
ログに残したい最低限の項目
- 対象パス(どの実行物/どのリンクを更新しようとしたか)
- 操作(上書き/rename/起動/権限変更など)
- エラー番号とメッセージ(errno=26, ETXTBSY)
- 試行回数と待機時間(何回目で何秒待ったか)
- 同時実行の手掛かり(PID、ユニット名、ホスト名、コンテナID等)
「待てば解ける」か「待っても無理」か
ETXTBSYが返ってくる状況は、短時間で解けることが多い一方で、設計として永続的に衝突している場合もあります。例を挙げます。
| 分類 | 典型 | 判断 |
| 一時衝突 | デプロイ直後に起動が重なった/別プロセスの短い書き込み | 指数バックオフで再試行の価値が高い |
| 設計衝突 | 同一パスに常に上書きする設計/共有FSで更新伝播が崩れている | 上限到達で止め、手順・構成を改修すべき |
| 権限/配置ミス | ディレクトリ跨ぎでmvがコピーになっている/権限不備が併発 | ETXTBSY以外も混ざるので、再試行だけで解かない |
ここで「一般論の限界」が出る
観測可能性を整えると、逆に“分岐点”も見えます。共有FSの設定、コンテナの起動順序、実行物の配置、冗長構成、監査要件。これらは組織ごとの前提で最適解が変わり、「ブログで一般解を断言」すると危険になります。
だからこそ、終盤でははっきり言います。重要システムほど、観測ログを持って専門家に相談した方が早い。株式会社情報工学研究所のような事業者に、ログと構成を前提に「どこが衝突点か」を見てもらう方が、無限リトライで消耗するより合理的です。
章末まとめ
- 再試行の安全性は観測可能性(ログ設計)で決まる。
- ETXTBSYには「待てば解ける」と「待っても無理」がある。判定できると腹落ちする。
- 分岐点が多い領域なので、個別案件では専門家相談が最短になることがある。
第10章:帰結:ETXTBSYは“ミス”ではなく“並行実行の仕様”――置換と再試行を設計に組み込む
ここまで読んで、たぶん結論はこう腹落ちしているはずです。
ETXTBSYは、誰かの不注意というより「並行実行がある世界で、実行物をどう更新するか」という設計問題だ、と。
現場のつらさは「正しいことをしているつもりなのに、たまに落ちる」点にあります。これは精神的に削られます。でも、仕組みとして分解すれば、対策は整理できます。
最終的に押さえるべき“3点セット”
- 置換の設計:その場で書かず、完成品を原子的に切替(rename、世代管理、symlink、ディレクトリ切替)
- 順序の設計:更新と起動のタイミングを分離し、systemd/ローリング更新で衝突を抑え込み
- 再試行の設計:指数バックオフ+上限+停止条件、そしてログで判定できるようにする
「一般論の限界」を越えるタイミング
ここで強調したいのは、一般論はここまでだ、という点です。ETXTBSYの最適解は、システム構成に依存します。
- ローカルディスクか、共有ストレージか
- 単一ノードか、冗長化/クラスタか
- コンテナの有無、バインドマウントの有無
- 更新頻度、停止許容時間、監査・セキュリティ要件
これらが絡むと、単純な「mvでOK」では終わりません。むしろ、ここを誤ると、ETXTBSYを抑え込むどころか別の事故(更新不整合、ロールバック不能、監査不備)に繋がります。
ですので、最後は自然にこうなります。具体的な案件・契約・システム構成で悩んだら、株式会社情報工学研究所のような専門事業者に相談すべきです。ログや構成を前提に「何を原子化し、どこを待機し、どこで止めるか」を一緒に設計した方が、現場の疲弊が早く収束します。
章末まとめ
- ETXTBSYは“並行実行の仕様”として理解すると、対策が設計に落ちる。
- 置換・順序・再試行の3点セットで、現場のモヤモヤを収束させられる。
- 構成依存が強いので、個別案件は専門家相談が合理的。
付録:現在のプログラム言語各種における「Text file busy」的な落とし穴と注意点
最後に、運用現場でよくある「言語ごとのハマりどころ」をまとめます。ここで言う注意点は、“ETXTBSYが起きる/起きない”を断言するものではなく、実行物の更新・生成・起動が並行しやすい箇所に焦点を当てます。実際の挙動はOS・ファイルシステム・配置方式で変わるため、重要案件では検証と設計が必要です。
Shell(sh/bash)
- スクリプト生成→即実行(chmod直後に実行)を自前でやると、並行起動で衝突しやすい。
- 「cat > 実行ファイル」は truncate を確実に発生させるため、実行中差し替えと相性が悪い。
- 一時ファイル→mv、という原則を徹底しやすい一方、雑に書くと一番地雷を踏みやすい。
Python
- デプロイで .py を上書きしつつ、別プロセスが import するような並行があると、読み込み不整合や起動失敗の原因になる。
- 実行物を「スクリプト直置き」で更新するより、パッケージ化+リリースディレクトリ切替の方が安定しやすい。
- gunicorn/uwsgi 等のプロセス管理と、コード更新の順序(reload、graceful)を設計しないと事故る。
Node.js(JavaScript/TypeScript)
- ビルド成果物(dist)生成中にプロセスが参照すると、起動失敗や中途半端な読み込みが起きやすい。
- PM2 や systemd、コンテナ再起動とビルド/展開のタイミングが当たると、稀に「できた直後に実行」で衝突する。
- 世代ディレクトリ方式(releases)+切替、またはイメージ更新に寄せると収束しやすい。
Go
- 単一バイナリのため、更新対象が明確で“その場で上書き”をやりがち。ここがETXTBSYの温床になりやすい。
- 原子リネームや世代管理との相性は良いので、運用設計でかなり抑え込める。
- systemdの再起動と更新の順序制御をセットにしないと、更新競合が残ることがある。
Java / JVM系(Kotlin含む)
- jar/war の差し替えを「同一ファイルへ上書き」でやると、起動・クラスロード・展開タイミングで不整合が混ざりやすい。
- アプリサーバのデプロイ機構やローリング更新に乗せる方が、順序制御と観測が整いやすい。
- コンテナ化してイメージ更新に寄せると“完成品だけを実行”しやすいが、運用要件(監査、ロールバック)を要確認。
C/C++
- 実行バイナリを直接置換する運用になりがちで、cp上書き・truncate系の地雷を踏みやすい。
- 共有ライブラリ(.so)の差し替えは、プロセスがロード済みかどうかで挙動が変わり、説明が難しくなる。
- 世代管理+再起動の順序制御で“場を整える”方が、障害時の切り戻しも含めて安定する。
Rust
- 単一バイナリ配布が多く、Go同様「その場で上書き」になりやすい。置換設計を最初から入れるのが重要。
- CIでビルド→配置→起動が高速な分、並行タイミングの衝突が表に出やすい。
付録まとめ
- 言語差よりも「実行物の配置・切替・起動順序」の設計が本質。
- “完成品だけを実行する”形(原子切替、世代管理、イメージ更新)に寄せると、収束しやすい。
- 重要案件では、構成とログ前提で設計する必要があるため、株式会社情報工学研究所のような専門家への相談が合理的。