whoami pwd id sudo -n true 2>/dev/null || echo "sudo確認が必要"
mount | head dmesg -T | tail -n 80 grep -n " / " /etc/fstab 2>/dev/null || true
dmesg -T | egrep -i "I/O error|reset|timeout|blk_update_request" | tail -n 60 lsblk -o NAME,SIZE,TYPE,MOUNTPOINT,FSTYPE,MODEL smartctl -a /dev/sdX 2>/dev/null | egrep -i "Reallocated|Pending|Offline|UDMA|SMART overall" || true
lsblk -f sudo umount /dev/sdXN 2>/dev/null || true sudo fsck -n /dev/sdXN
cat /proc/mdstat 2>/dev/null || true sudo pvs 2>/dev/null || true sudo vgs 2>/dev/null || true sudo lvs 2>/dev/null || true sudo cryptsetup status -v 2>/dev/null || true
hostname date who -a 2>/dev/null || true ss -tulpn 2>/dev/null | head df -hT | head -n 30 mount | egrep -i "nfs|cifs|fuse|overlay" | head || true
・不安定なディスクに連続アクセスを続けると、読み取り不能領域が増えて費用が膨らみやすい。
・権限や所有者の変更を広げると、監査や運用復旧が難しくなりやすい。
・RAID/LVM/暗号化の層を誤認して触ると、復旧が長期化しやすい。
・I/O error が出ているが、まずクローン優先か診断ができない。
・ext4 の整合性が怪しいが、どこまで確認してよいかで迷ったら。
・RAID/LVM のどの層を対象にするか判断できない。
・暗号化(LUKS等)が絡むか切り分けの診断ができない。
・成功率と費用の目安が症状別に見えず迷ったら。
・夜間や停止できない環境で、止めどころの判断ができない。
もくじ
- 第1章:『マウントできない』瞬間に現場が凍る—論理障害は“バグ”ではなく状態遷移
- 第2章:まず守るべき不変条件:通電・書き込みを止め、元ディスク(証拠)を固定する
- 第3章:症状別に切り分ける:I/Oエラー/read-only化/UUID不整合/ジャーナル破損
- 第4章:成功率を左右する“傷口”:Superblock/Journal/Inode/B-treeの破壊度
- 第5章:期待値で見る復旧ルート:fsckが効く範囲と、効かない範囲
- 第6章:正攻法のイメージ取得:ddrescueでクローン→検証→再試行のループを作る
- 第7章:ext4 / XFS / Btrfsで手順が変わる:ツール選定と禁じ手(repair)の見極め
- 第8章:ファイル単位で拾う最終手段:TestDisk/PhotoRec/スナップショットの現実
- 第9章:費用の中身を分解する:診断・工数・媒体・優先度・リスクで価格は決まる
- 第10章:帰結:成功率と費用は“最初の10分の判断”で決まる—自力復旧の限界線と相談の使い方
【注意】 HDDに論理障害が疑われる場合、自己判断の修理・復旧操作(fsck実行、マウント再試行、書き込みを伴うツール使用など)で状態が悪化し、復旧可能性が下がることがあります。必要データがあるときは作業を止め、株式会社情報工学研究所のような専門事業者への相談を検討してください。
第1章:『マウントできない』瞬間に現場が凍る—論理障害は“バグ”ではなく状態遷移
Ubuntuサーバで「昨日まで動いていたボリュームが突然マウントできない」。この瞬間、現場の頭に浮かぶのは復旧手順より先に、止められない業務と説明責任です。「再起動すれば直る?」と試したくなる一方で、「下手に触って余計に悪化したら終わる」という不安も同時に来ます。
ここで重要なのは、論理障害を“直す作業”として扱わないことです。論理障害は、ファイルシステムが整合性を失った「状態」であり、追加の書き込みや整合性修復(repair)が新しい矛盾を作ることがあります。特に、障害の原因が媒体劣化や不安定I/Oを伴う場合、読み取り失敗の増加やメタデータ破損の拡大につながり、成功率と費用の両方に効いてきます。
冒頭30秒でやるべきことを、症状から逆算して先に置きます。ポイントは「書き込みを増やさない」「現物を固定する」「判断基準を明確にする」です。
| 症状(よくある表示) | 取るべき行動(最初の一手) | やらないこと(悪化要因) |
|---|---|---|
| mount: wrong fs type / bad option / bad superblock | 書き込み停止→現状ログ保存(dmesg/blkid/mount出力)→イメージ取得の検討 | オプションを変えて何度もマウント、fsckを即実行 |
| Read-only file system(突然RO化) | アプリ停止→再マウントせず原因確認(dmesg)→クローン作成 | 無理な再起動連打、復旧目的の上書き操作 |
| I/O error / Buffer I/O error / ATA error | 物理不安定の可能性を前提に読み取り最優先→ddrescue等で段階的取得 | 通常のddで一気読み、長時間の通電継続 |
| ファイルは見えるが一部が壊れている/消えた | 変更を止める→スナップショット/バックアップ有無確認→差分上書きを防ぐ | 整理のつもりで移動・削除、再インデックス系処理 |
「でも結局、成功率と費用はどれくらい?」という問いに、一般論だけで断言するのは危険です。成功率は“壊れ方”と“上書きの有無”で跳ねますし、費用は“どこまでの作業が必要か”の分解で決まります。ここから先は、成功率を上げる判断(やる・やらない)を具体化し、費用の内訳が見えるように解説します。
今すぐ相談すべき条件を明確にしておきます。
- I/O errorやディスク関連エラーがdmesgに出ている
- fsckやrepairを試す前に、絶対に取り戻したいデータがある
- 業務停止・監査・契約の影響が大きく、失敗コストが高い
- 暗号化・DB・VMイメージなど、復旧後の整合性が重要
相談導線(依頼判断の入口):問い合わせフォーム https://jouhou.main.jp/?page_id=26983 / 電話 0120-838-831
第2章:まず守るべき不変条件:通電・書き込みを止め、元ディスク(証拠)を固定する
復旧の現場で最も多い失敗は「正しい手順を知らなかった」ではなく、「急いで動かした」ことです。論理障害に対しても、不変条件(これだけは守る)があるかどうかで、成功率と費用が分岐します。
不変条件の中心は2つです。ひとつは“書き込みを増やさない”こと。Ubuntuでは自動マウントやサービスの再起動でログやメタデータ更新が走りがちです。もうひとつは“元ディスクを固定する”こと。復旧作業は「元」をいじるほど取り返しがつかなくなり、同じ復旧でも費用が上がりやすくなります(追加調査、追加イメージ取得、失敗時のリカバリ工程が増えるためです)。
具体的に守るべき行動を、作業者目線で並べます。
- アプリケーション停止(DB、コンテナ、ジョブ、監視の自動修復も含める)
- 対象ボリュームのアンマウント(可能なら)/再マウントはしない
- 書き込みを伴うコマンドを避ける(修復系、再作成、再同期、再構築)
- 現状の証跡を保存(dmesg、lsblk -f、blkid、mount、smartctl出力など)
- 可能なら別媒体へイメージ取得(元ディスクは保全して以後触らない)
「え、fsckすらダメなの?」と思うかもしれません。fsckは有効な場面がありますが、前提は“元ディスクに対していきなり走らせない”ことです。イメージに対して試し、結果が悪ければ巻き戻せる状態にする。これが費用の最小化にも直結します。
費用面の話を先に少しだけ言語化します。業者の費用は、単なる作業時間ではなく「リスクを下げるための段取り(保全、複数回の取得、検証、再現性の確保)」にコストが乗ります。逆に言えば、保全の前に状況が悪化しているほど、後工程が重くなり、費用は上がりやすい。だからこそ、最初に“不変条件”を守ることが合理的です。
第3章:症状別に切り分ける:I/Oエラー/read-only化/UUID不整合/ジャーナル破損
Ubuntuの復旧でやりがちなのが、「原因を決め打ちしてツールを当てる」ことです。復旧は診断の順番が重要で、症状から“どの層が壊れていそうか”を見立てるだけで、成功率の期待値が上がります。ここでは、よくある症状を4分類し、どこまで一般論で言えるかの境界線も明示します。
I/Oエラーが出る(最優先で警戒)
dmesgに「I/O error」「Buffer I/O error」「ataX:」系が出る場合、論理障害だけでなく、読み取り自体が不安定な可能性があります。このケースは、ファイルシステム修復を先にすると失敗しやすく、まず“読み取れるうちに”イメージ取得を優先するのが原則です。読み取り失敗が増えるほど、復旧は「整合性の話」ではなく「欠損ブロックの扱い」の話になり、工数が増えます。
Read-only化(保護動作の可能性)
ext4などは、エラー状況によって読み取り専用に切り替わることがあります。ここで再マウントや再起動を連打すると、状況が改善するどころかログやメタ更新の機会を増やし、二次的不整合が増えることがあります。まずは、RO化のトリガー(dmesg)とストレージ層のエラー有無を確認し、イメージ取得の判断に繋げます。
UUID不整合/デバイス名変化(構成管理の問題が混ざる)
「fstabのUUIDが違う」「/dev/sdXが入れ替わった」などは、必ずしもファイルシステム破損とは限りません。ここで闇雲にrepairに入ると、原因が別だった場合に無駄なリスクを踏みます。blkid、lsblk -f、LVM/RAIDの状態(mdadm, pvdisplay等)を確認し、「参照先の取り違え」か「実体の不整合」かを切り分けます。
ジャーナル破損・スーパーブロック系(“直る”と“直ったように見える”の差)
bad superblockやjournal関連は、ツールが反応しやすい一方で、直後の整合性が担保されないことがあります。たとえばマウントできたとしても、DBやVMイメージの内部整合性は別問題です。成功率の定義を「マウントできる」ではなく「必要データが、期待する整合性で取り出せる」に置き換えると、ここから先の判断がブレにくくなります。
この章の結論はシンプルです。症状は“入口”であり、復旧ルートの選択は「どの層が壊れている可能性が高いか」と「必要データの性質」で決める。一般論で語れるのはここまでで、次章から“傷口の種類”をもう一段具体化します。
第4章:成功率を左右する“傷口”:Superblock/Journal/Inode/B-treeの破壊度
成功率を上げるには、「何がどれだけ壊れているか」を言語化する必要があります。復旧の難易度は、ざっくり言うと“メタデータのどこが壊れたか”で決まり、同じ論理障害でも結果が大きく変わります。
Superblock:入口が壊れると、全体が見えなくなる
superblockはファイルシステムの定義情報を持ち、ここが壊れると全体の解釈ができません。バックアップsuperblockが有効な場合は回復の余地がありますが、問題は「superblockだけが壊れているとは限らない」点です。入口を直して見えるようにしても、内部の不整合が残っていれば、読み出し時に欠損が顕在化します。
Journal:整合性の“未完了タスク”が残る領域
ジャーナルは更新途中の情報を扱うため、破損すると“途中までの更新”が混ざった状態になり得ます。ここで修復を急ぐと、意図しないロールフォワード/ロールバックが起き、結果として必要ファイルの世代が変わることがあります。業務データ(DB、ログ、会計など)の場合、「見える」より「正しい」が重要なので、検証手順を前提に復旧方針を組む必要があります。
Inode:ファイル実体への参照が壊れると、欠落や別名が増える
inodeの破損は、ファイルそのものが消えたように見えたり、権限・サイズ・タイムスタンプが崩れたりします。復旧ツールでサルベージできても、ディレクトリ構造やファイル名が失われやすく、復旧後の整頓(何が何かを特定する作業)が増えます。これが費用に効く典型例で、「復旧できたが業務に戻すまでが長い」という形で表面化します。
B-tree系:XFS/Btrfsなどでは“木”の壊れ方が難易度を上げる
XFSやBtrfsなど、内部構造に木構造を多用するファイルシステムでは、局所的な破損が参照関係の広い範囲に影響することがあります。ここで“修復”を先に走らせると、整合性の取り方によっては失われた参照が確定してしまい、後からのサルベージ余地が狭まることがあります。だから、先にイメージ取得し、複数のアプローチを試せる状態を作るのが合理的です。
この章で押さえるべき帰結は、「成功率」は精神論ではなく、破損点と破損範囲で決まるということです。そして「費用」は、破損が深いほど“検証と再現性”のための工程が増えやすい、という現実に繋がります。次章では、ここまでの見立てを、実際の復旧ルート(fsckが効く範囲/効かない範囲)に落とし込みます。
第5章:期待値で見る復旧ルート:fsckが効く範囲と、効かない範囲
「とりあえずfsck」は、Ubuntu運用の現場では“手が覚えている”動きになりがちです。けれど論理障害の復旧は、コマンドの正しさより先に「どのルートに乗せるべきか」の期待値判断が重要です。fsckが得意な壊れ方もあれば、fsckで確定的に失われる情報もあります。成功率と費用を分けるのは、この見極めです。
fsckが効きやすい範囲
fsck(ext系ならe2fsck)は、整合性の破れが比較的“局所”で、メタデータの参照関係がまだ辿れる状態で強みを発揮します。典型は、電源断やクラッシュ後に残った未完了更新(ジャーナル未反映)や、軽微なビットマップ不整合、孤立inodeの整理などです。これらは、整合性を再構築することで「マウント可能」「ファイル構造が概ね残る」方向に寄せられます。
ただし、ここでの成功は「マウントできた」だけでは不十分です。業務で必要なのは「必要データが正しい形で取り出せる」ことです。DBやVMイメージ、ソースリポジトリのように内部整合性が重要な対象は、fsckの結果が“見た目の復旧”に留まるケースがあり、検証工程(アプリ層のチェック)が別途必要になります。
fsckが効きにくい範囲(期待値が下がる条件)
fsckの期待値が下がるのは、参照関係そのものが広範囲に崩れている場合です。具体的には、スーパーブロック周辺だけでなくグループディスクリプタやinodeテーブル、ディレクトリエントリなど“辿るための道”が多地点で壊れているケースです。さらにI/Oエラーが混ざる場合、修復に必要な読み取りが安定せず、修復が途中で破綻しやすくなります。
もうひとつ重要なのが「修復が“変更”を伴う」点です。fsckは整合性を合わせるために、失われた参照を整理し、矛盾する構造を削ったり付け替えたりします。これは正しい動作ですが、必要データがその“整理対象”に含まれていた場合、後からの回収余地が狭まります。だからこそ、元ディスクに対して一発勝負を避け、イメージ上で試行できる状態を作るのが合理的です。
期待値で選ぶ「3つのルート」
| ルート | 向いている状況 | 成功の定義 | 費用が増えやすい要因 |
|---|---|---|---|
| ルートA:整合性修復(fsck/repair) | 局所的な不整合、I/Oが安定、構造が概ね辿れる | マウント+必要データの整合性が取れる | 修復後の検証(DB/VM/アプリ層)が重い |
| ルートB:クローン→読み取り優先で取り出し | 劣化疑い、I/Oエラー、再現性が低い | 必要データの回収率を最大化 | イメージ取得の反復、欠損ブロック扱い、再構成 |
| ルートC:ファイル単位サルベージ | 構造崩壊、ディレクトリ情報が壊れている | 必要ファイルを“内容で”拾える | ファイル名・構造の喪失、同定作業が増える |
「結局どれを選ぶ?」の判断基準は、必要データの性質と失敗コストです。たとえば、契約・監査・障害報告が絡む現場では、復旧作業そのものが説明責任の対象になります。ログ保全、再現性、手順の追跡(何をいつ実行したか)が要求されるなら、最初から“戻れる設計(イメージ化)”に寄せたほうが、結果として費用が跳ねにくい。
次章では、ルートBの中核になるイメージ取得を、Ubuntu現場の手順として具体化します。ここを押さえると、成功率のブレ幅を小さくできます。
第6章:正攻法のイメージ取得:ddrescueでクローン→検証→再試行のループを作る
復旧の成功率を上げる行動として、最も再現性が高いのが「元ディスクを固定し、作業対象をクローン(またはイメージ)に移す」ことです。現場の独り言としては、「そんな時間ない」「今すぐファイルが欲しい」が本音でしょう。それでも、取り返しのつかない失敗の多くが“元に対する作業”で起きます。クローンに寄せるのは、安全策というより、工程を短くするための設計です。
ddrescueが選ばれる理由(ログで“作業を続けられる”)
ddrescueは、読み取りに失敗した箇所を記録し、後からその範囲だけ再試行できる設計になっています。I/Oが不安定なとき、通しで読み続けるよりも、読める領域を先に確保し、読めない領域を段階的に攻めたほうが回収率が上がりやすい。さらに、ログ(mapfile)が残ることで、作業の説明責任(どこが読めて、どこが読めなかったか)を持てるのも大きいポイントです。
作業前に決める3点(ここが曖昧だと失敗する)
- 出力先:同容量以上の別ディスク(できれば新品)か、十分な空きがあるストレージ
- 形式:ディスク丸ごとクローン(推奨)か、イメージファイル(運用によって選択)
- 証跡:mapfile(ログ)をどこに保存し、誰が保管するか
特にRAID/LVMが絡む場合、対象が「物理ディスク」なのか「論理ボリューム」なのかを取り違えると、後工程が破綻します。lsblk -f、blkid、mdadm、lvs/pvsの出力を残し、対象を固定してから着手します。
ddrescueの基本ループ(段階的に回収率を上げる)
目的は「まず読める範囲を最大化」し、その後「読めない範囲を限定して再試行」することです。概念としては次の3フェーズになります。
- フェーズ1:読める場所を高速に確保(失敗箇所は飛ばす)
- フェーズ2:失敗箇所の周辺を小さく刻んで回収率を上げる
- フェーズ3:本当に必要な範囲だけ粘る(時間とリスクのバランス)
コマンド例を置きます(実環境ではデバイス名の誤指定が致命傷になるため、実行前にlsblkで必ず突合します)。
ddrescue -f -n /dev/sdX /dev/sdY rescue.map ddrescue -f -r3 /dev/sdX /dev/sdY rescue.map ddrescue -f -r0 --retry-passes=2 /dev/sdX /dev/sdY rescue.mapここで大事なのは「mapfileを同じものとして継続する」ことです。途中でmapfileを変えると、どこまで読めたかの追跡が崩れ、同じ失敗を繰り返しやすくなります。
クローン後にやるべき検証(“復旧”はここから始まる)
クローンができた時点で、元ディスクは保全します。以後の作業はクローン(/dev/sdY側)に対して行います。ここでの検証は、やみくもにマウントするのではなく、破損の種類に応じて順番を決めます。
- 読み取り専用での確認(可能なら):必要最低限の参照で状況把握
- ファイルシステム整合性の点検:いきなり修復ではなく点検から入る
- 必要データの優先順位付け:先に守るべきディレクトリ/DB/VMを決める
「今すぐ欲しいファイル」ほど、先に回収します。復旧作業は後戻りできるように設計できても、現場の時間は戻りません。回収優先の設計は、費用の抑え込みにも効きます。なぜなら、必要データが早期に確保できれば、後工程の深掘り(広範囲の修復やサルベージ)を最小化できるからです。
この章の帰結は、成功率を上げるのは特別な魔法ではなく、作業対象を“複製に移す”ことだ、という一点に集約されます。次章では、ファイルシステムごとに「修復系ツールの性格」を整理し、どこが危険でどこが有効かを具体的に描きます。
第7章:ext4 / XFS / Btrfsで手順が変わる:ツール選定と“確定操作”の見極め
Ubuntuの現場は、ext4が多い一方で、XFSやBtrfsも珍しくありません。さらにサーバ用途だとLVMやRAID、仮想化が絡みます。「復旧コマンドは何?」という問いに、ファイルシステムを無視して答えるのは危険です。復旧は“同じ目的でも、手段が違う”領域で、ツールの性格を理解すると、成功率と費用の見通しが立ちます。
まず全体像:ツールは「読む」ものと「書く」ものに分かれる
復旧で扱うツールには、状態を解析して判断材料を増やすものと、状態を変更して整合性を合わせるものがあります。前者は検証に使え、後者は結果を前に進めますが、同時に“確定”もします。必要データが大きいほど、確定操作の前にクローンで試行できる状態が重要になります。
| ファイルシステム | 代表的ツール | 性格 | 現場判断の要点 |
|---|---|---|---|
| ext4 | e2fsck, debugfs, dumpe2fs | 点検と修復が分かれる(修復は変更を伴う) | クローン上で段階的に試すと再現性が取りやすい |
| XFS | xfs_repair, xfs_db, xfs_metadump | 修復が強力だが、変更の影響が大きい | 修復前にメタ情報の採取と保全を厚くする |
| Btrfs | btrfs check, btrfs restore, btrfs rescue | スナップショット等が味方にも敵にもなる | restoreで読み取り回収→必要なら再構成の順に寄せる |
ext4:e2fsckの“効きどころ”を外さない
ext4の強みは、情報が揃っている限り、整合性の再構築が比較的読みやすいことです。とはいえ、実運用では「軽微な不整合」だけで済まないことも多い。だから、点検→試行→回収の順番を守り、必要データの優先回収とセットで扱うのが現実的です。
現場の心の会話としてはこうです。「直すより先にコピーしろって言うけど、コピーするには直ってないと無理じゃない?」。ここでの答えは、完全に直さなくても回収できるルート(読み取り専用の参照、debugfsでの抽出、クローン上での限定的修復)を用意することです。直す前に取れるものを取る。これが被害最小化の設計です。
XFS:修復は強いが、順番を間違えると後が長い
XFSは大規模運用に強い反面、破損の出方によっては修復後の構造が大きく変わることがあります。xfs_repairは強力ですが、実行は状態を前に進めます。だからこそ、修復前にメタデータの採取、クローンへの作業移行、必要データの優先順位付けを固めます。
費用面で効くのは「後から辻褄合わせをする工数」です。修復に成功しても、アプリ層の整合性や、ファイルの同定作業が増えると、結局は時間がかかります。修復の前に“何が必要で、何が不要か”を決めておくと、作業が膨らみにくい。
Btrfs:スナップショットが救いになる条件と、ならない条件
Btrfsはスナップショットやサブボリュームといった機能が、正常時には大きな武器になります。一方で、メタデータ破損やデバイス障害が絡むと、整合性の確定が難しくなることがあります。ここで役に立つのは「回収優先」の発想です。btrfs restoreのように、構造の完全修復より先にファイル回収を狙うルートは、必要データが明確な現場ほど効果が出ます。
この章の帰結は、ファイルシステムごとに“確定操作”の重みが違う、ということです。復旧の成否はツール選定だけでなく、選定するまでの準備(クローン、証跡、優先順位)で決まります。次章では、構造が崩れた場合の最終手段として、ファイル単位で拾う現実と、そこにかかる費用の正体を扱います。
第8章:ファイル単位で拾う最終手段:TestDisk/PhotoRec/スナップショットの現実
ここまでの章は、ファイルシステムの“構造”をなるべく保ったまま回収する発想でした。しかし現実には、メタデータの参照関係が大きく崩れ、ディレクトリ構造やファイル名の復元が難しいケースがあります。そのとき出てくる選択肢が「ファイル単位で拾う」です。これは敗北ではなく、被害最小化のための戦略転換です。
ファイル単位サルベージの強みと、必ず起きる代償
強みはシンプルで、ファイルシステムの整合性が取れなくても「中身の特徴」から回収できることです。一方、代償はほぼ確実に発生します。多くのケースでファイル名・フォルダ階層・タイムスタンプが失われやすく、復旧後の“同定作業”が重くなります。つまり「回収」はできても、「業務に戻す」までが長くなる可能性がある。費用が膨らみやすいポイントは、ここにあります。
TestDisk:構造がまだ残っている場合の“戻り道”を探す
TestDiskは、パーティションやブートセクタ、ファイルシステムの情報を探索し、失われた構造を辿れる可能性があるときに力を発揮します。論理障害といっても、実際には「参照先を見失っているだけ」のケースがあります。たとえば、パーティションテーブルの不整合、GPT/MBR周辺の破損、あるいは構成変更で見えなくなっただけ、などです。
ただし、ここで注意すべきは「発見」と「復旧」を同一視しないことです。見えるようになった瞬間にコピーを始めたくなりますが、読み取りが不安定な要素が混ざっているなら、先にイメージ取得へ寄せたほうが結果が安定します。焦ってコピーを始めると、読み取り負荷で状態が悪化し、回収率が下がることがあります。
PhotoRec:名前を捨てて“内容を拾う”という割り切り
PhotoRecは、ファイルのヘッダ/フッタなどの特徴からデータを抽出するアプローチで、構造が崩れていても回収できる可能性があります。ここで重要なのは、回収の目的が「元の形を完全に戻す」ではなく「必要データを手元に確保する」へ変わることです。
現場の心の声はだいたいこうです。「結局、ファイル名が全部バラバラになったら意味がないのでは?」。その懸念は正しいです。だからこそ、PhotoRecを使う場面は、(1) 何としても内容だけでも必要、(2) 重要ファイルの種類がある程度決まっている(例:PDF/Office/画像/動画/DBダンプ等)、(3) 復元後の整理に時間を使う覚悟がある、という条件が揃ったときに限定されます。
Btrfs:スナップショットがある場合に“先に救える”ことがある
Btrfsでは、スナップショットやサブボリュームの運用が、復旧の味方になることがあります。運用が適切なら、ファイルシステム全体の修復より先に、スナップショットから“整合性の高い世代”を取り出せる可能性があります。逆に言えば、スナップショットがあるのに無理に修復を先に進めてしまうと、取り出せたはずの世代を取りこぼすことがあります。
この領域は一般論の限界がはっきりしていて、構成(RAID、キャッシュ、圧縮、暗号化、スナップショット運用方針)で最適解が変わります。必要データの価値が高いほど、クローン+検証+段階的な回収に寄せるほうが、結果としてダメージコントロールになりやすいです。
回収後に必須になる“現実的な検証”
ファイル単位で回収できたとしても、業務で使うには検証が必要です。特にDB、VM、リポジトリ、暗号化コンテナ、アーカイブ(zip/tar)などは、表面上は存在していても内部が壊れていることがあります。回収に成功した直後こそ、次の確認が重要になります。
- アーカイブやDBダンプの整合性チェック(展開・リスト取得・簡易クエリ)
- 重要ファイルのハッシュ算出と比較(既存バックアップや別系統との突合)
- 優先度の高い業務データから段階的に“使える”状態へ戻す計画
この章の帰結は、「ファイル単位サルベージ」は最後の手段であり、同時に“復旧後の整理”という別のコストが発生する、という点です。次章では、そのコストの正体を分解し、費用がどう決まるかを“見積りの読み方”として整理します。
第9章:費用の中身を分解する:診断・工数・媒体・優先度・リスクで価格は決まる
復旧の見積りを見たとき、現場の第一声はだいたい決まっています。「高い……いや、でも背に腹は代えられない」。このモヤモヤは健全です。復旧費用は“作業時間だけ”では決まりません。むしろ、成功率を上げるための段取り、失敗リスクを下げるための工程、証跡や説明責任のための手当てが、費用の中心になります。
費用は「何をどこまで保証したいか」で変わる
同じ論理障害でも、ゴールが違えば必要工程が変わります。たとえば「写真が数枚戻ればよい」と「監査対象の会計データを整合性付きで復旧したい」では、必要な検証がまるで違います。前者は回収率が中心、後者は再現性と説明責任が中心です。ここを最初に揃えると、見積りの納得感が上がります。
費用が発生する工程を“部品”として見る
| 工程(部品) | 何をしているか | 費用が増えやすい条件 |
|---|---|---|
| 初期診断・状況把握 | 症状、構成、ログ、必要データ、優先順位の整理 | 構成が複雑(RAID/LVM/暗号化/仮想化)、情報が不足 |
| 保全・イメージ取得 | 元ディスクの固定、クローン/イメージ作成、ログ化 | I/O不安定、読み取り失敗が多い、再試行が必要 |
| 論理解析・再構成 | FSメタデータ解析、整合性調整、取り出しルート確立 | 参照関係の破損が広範囲、複数方式の試行が必要 |
| データ抽出・同定 | 必要データを優先抽出、ファイル名/内容の突合 | ファイル単位サルベージ、ファイル数が膨大 |
| 検証・整合性確認 | DB/VM/アーカイブ等の実利用に耐えるか確認 | 業務要件が厳しい、監査/契約で説明が必要 |
| 納品・セキュリティ | 納品媒体、暗号化、アクセス制限、証跡管理 | 厳格な持ち出し制限、鍵管理、運用手順の指定 |
| 緊急対応(優先度) | 優先着手、夜間/休日対応、リソース確保 | 納期が短い、停止損失が大きい、同時多発対応 |
「成功率」と「費用」を同時に上げ下げする要因
現場として一番知りたいのはここです。成功率が上がるほど費用も上がる、とは限りません。むしろ逆に、初動が正しければ成功率が上がり、費用が抑え込まれるケースがあります。ポイントは“悪化を防ぐ”ことです。悪化が止まっていれば、作業は読みやすくなり、試行回数が減り、結果として費用が収束しやすい。
- 初動で書き込みが入っていない → 参照関係が保たれやすく、回収が速い
- イメージ取得ができている → 試行を安全に繰り返せるため、遠回りが減る
- 必要データの優先順位が明確 → 深掘り範囲が絞れ、工数が抑えられる
見積りを読むときのチェックポイント(現場目線)
押し売りを避けつつ、現場が損しないための観点だけ整理します。見積りの数字そのものより、「どの工程が含まれ、どの工程が条件付きか」を見ると、納得しやすくなります。
- イメージ取得の有無(元ディスクを直接触る前提になっていないか)
- 検証の範囲(“マウントできた”で終わらないか)
- 納品形態(媒体、暗号化、アクセス制限、証跡の扱い)
- 緊急対応の扱い(優先度を上げたときの追加条件)
- 「できなかった場合」の扱い(途中成果、判断根拠の提示)
この章の帰結は、費用はブラックボックスではなく“工程の合計”で説明できる、ということです。そして個別案件では、構成と要件で必要工程が変わります。次章では、成功率と費用を左右する「最初の10分の判断」を、依頼判断に寄せた形でまとめます。
第10章:帰結:成功率と費用は“最初の10分の判断”で決まる—自力復旧の限界線と相談の使い方
ここまで読み進めた方ほど、薄々わかっているはずです。論理障害の復旧は、テクニック勝負ではなく「判断の設計」です。成功率と費用は、作業のうまさより先に、悪化を防げたか、戻れる状態で試行できたか、必要データの優先順位が揃っているかで決まります。
冒頭30秒の“やるべきこと”を、依頼判断に寄せて再掲する
復旧手順を探して来た人にも刺さりつつ、「やらない判断」へ自然に繋げるために、行動を短くまとめます。狙いは沈静化です。状況を落ち着かせ、被害最小化の方向に寄せる。
- 書き込みを止める(サービス停止、再マウント/再起動の連打を避ける)
- 現状の情報を保存する(dmesg、lsblk -f、blkid、構成情報)
- 元ディスクに対して修復をしない(試行はクローン上へ)
- 必要データの優先順位を決める(何が“今すぐ必要”で、何が“後でよい”か)
- 判断基準に当たるなら相談に切り替える
自力復旧の限界線(ここを超えると失敗コストが跳ねる)
自力でできる範囲はあります。ただし「できる」と「やってよい」は別です。次の条件が絡むと、失敗コストが急に跳ねるため、一般論で背中を押すのは危険になります。
- I/Oエラーが出ている(論理だけではない可能性)
- 暗号化、DB、VM、コンテナ基盤など、整合性が要件になる
- RAID/LVM/複数ディスク構成で、取り違えが致命傷になる
- 業務停止・契約・監査など、説明責任が重い
- 必要データが一点物で、やり直しが利かない
ここで重要なのは、「怖いから触らない」という感情論ではなく、リスクと期待値で判断することです。最初にクローンで戻れる状態を作れるなら、自力での試行も現実的になります。逆に、元ディスクに対する一発勝負しか取れないなら、個別案件として専門家に寄せたほうが合理的です。
相談は“丸投げ”ではなく、現場の負担を減らすための分業
「相談すると運用が増えるだけでは?」という疑いは自然です。現場は、余計な手順が増えるのが一番つらい。しかし復旧の相談は、ツール導入の話ではありません。目的は、現場の混乱を収束させ、判断の軌道を整えることです。
たとえば、相談時に揃っていると効果が出やすい情報は次の通りです。
- 発生時刻と直前の操作(再起動、更新、容量逼迫など)
- dmesgの該当部分(I/Oエラー有無、FSエラーの種類)
- ディスク/ボリューム構成(単体、RAID、LVM、暗号化)
- 必要データの優先順位(最重要のパスや種類)
- 許容できる停止時間、復旧に求める整合性のレベル
これらが揃うと、復旧ルートの選定が早くなり、費用の見通しも立ちやすくなります。逆に、情報が曖昧なまま闇雲に試行すると、結果として工程が増え、費用も時間も膨らみがちです。
一般論の限界と、個別案件で判断すべき理由
本記事は「成功率と費用」をテーマにしていますが、一般論で言い切れるのは“悪化を防ぐほど有利”という原理までです。実際の成功率は、破損点・破損範囲・I/Oの安定性・構成・必要データの性質・求める整合性で変わります。費用も同様に、工程の組み立てで決まります。
つまり、ここから先は「あなたの案件の前提」を置いたうえで判断すべき領域です。具体的な案件・契約・システム構成で悩んだとき、最短で被害最小化に寄せるなら、株式会社情報工学研究所への相談・依頼を検討する価値があります。
相談導線:問い合わせフォーム https://jouhou.main.jp/?page_id=26983 / 電話 0120-838-831
この一歩は、復旧作業を増やすためではなく、現場の混乱をクールダウンさせ、判断を収束させるためのものです。
付録:プログラム言語別—障害時に被害最小化へ寄せるための実装・運用の注意点
同じストレージ障害でも、アプリケーションの書き込みパターンや終了手順によって、ファイルシステム側の見え方は変わります。ここでは「言語そのものの優劣」ではなく、現場で起きがちな落とし穴と、被害最小化に寄せるための観点だけを整理します。
| 言語/実行環境 | よくある落とし穴(障害時に増幅しやすい) | 被害最小化へ寄せる観点 |
|---|---|---|
| C / C++ | バッファリングやfsync不足で「書いたつもり」が残らない/部分書き込みで構造が壊れやすい | 重要データは原子操作(テンポラリ→rename)と明示的フラッシュ、エラー処理の徹底 |
| Rust | 安全性は高いがI/Oの永続化は別問題/非同期処理で終了順序が崩れると欠損が出る | 永続化境界(fsync/同期ポイント)を設計に含める、終了時のグレースフル停止を用意 |
| Go | goroutineで書き込みが分散し、停止時に取りこぼしが起きやすい/ログの同期が曖昧 | シグナル処理で停止順序を統一、永続化するデータはコミット単位を明確に |
| Java / Kotlin(JVM) | バッファやJournalingの前提を誤解しやすい/例外処理でclose漏れが残る | リソース解放(try-with-resources等)を徹底、障害時は「書き込み停止→状態保存」を優先 |
| .NET(C# など) | 非同期I/Oやバックグラウンド処理で、停止時に未完了が残る/ログとデータの順序が崩れる | ホスト停止時のフックで確実にflush/close、重要データの更新は原子性を意識 |
| Python | 小規模運用で「つい直書き」しがち/SQLiteなどは電源断やI/O不安定で壊れ方が読みにくい | 書き込み先を分離(ログ/データ)、テンポラリ+rename、トランザクション運用の徹底 |
| Node.js | 非同期で「完了待ち」を忘れやすい/イベントループ停止時に書き込みが途中で終わる | 終了シーケンスで未完了I/Oを待つ、ログとデータの同期点を設計として持つ |
| PHP | 共有ホスティング等でI/O制約が強い/一時ファイルやアップロードの途中状態が残りやすい | 書き込み頻度を下げる設計、アップロードは原子入替、障害時のリトライ設計を明確に |
| Ruby | ジョブやバッチで大量I/Oを出しやすい/例外で途中状態が残る | 例外時のロールバックと一時領域運用、書き込みをまとめて整合性境界を作る |
運用面の注意点も、言語を問わず共通です。
- 障害時に自動で再起動・再試行する仕組みが「書き込みを増やす」方向に働かないようにする
- ログとデータの置き場所を分け、ディスク逼迫やI/O不安定の影響を局所化する
- バックアップは「取る」だけでなく「戻せる」検証を定期的に行う
- ストレージ障害の兆候(I/Oエラー、遅延、RO化)を検知したら、まず書き込み停止へ寄せる
ここまでの内容は、一般論としての被害最小化の方針です。実際のシステムは、契約、監査要件、データ種別、構成で最適解が変わります。具体的な案件・契約・システム構成で悩んだときは、株式会社情報工学研究所のような専門家へ相談し、判断の軌道を整えることが、結果として復旧成功率と費用の両面で合理的になるケースがあります。
相談導線:問い合わせフォーム https://jouhou.main.jp/?page_id=26983 / 電話 0120-838-831
解決できること・想定課題
- Ubuntu 環境での HDD 論理障害発生時に、診断から復旧までの最適な手順とツール選定方法を理解し、業務を停止させずに対応できます。
- 復旧にかかる工数やライセンス費用の算出モデルを把握し、経営層へ費用対効果を明確に示す資料を作成できます。
- 関連法令や政府ガイドラインに則ったコンプライアンス体制を構築し、BCP(事業継続計画)に無理なく組み込む方法を学べます。
コンプライアンス引用元
- 個人情報保護法 ガイドライン(出典:総務省『個人情報保護法ガイドライン』2020年 URL: https://www.soumu.go.jp/main_sosiki/)
- 不正アクセス禁止法 概要(出典:法務省『不正アクセス禁止法の概要』2018年 URL: https://www.moj.go.jp/psia/)
- LGWAN ガイドライン(出典:総務省『LGWANガイドライン』2019年 URL: https://www.soumu.go.jp/main_sosiki/)
- 事業継続計画(BCP)策定手引き(出典:内閣府『事業継続計画(BCP)策定の手引き』2018年 URL: https://www.bousai.go.jp/)
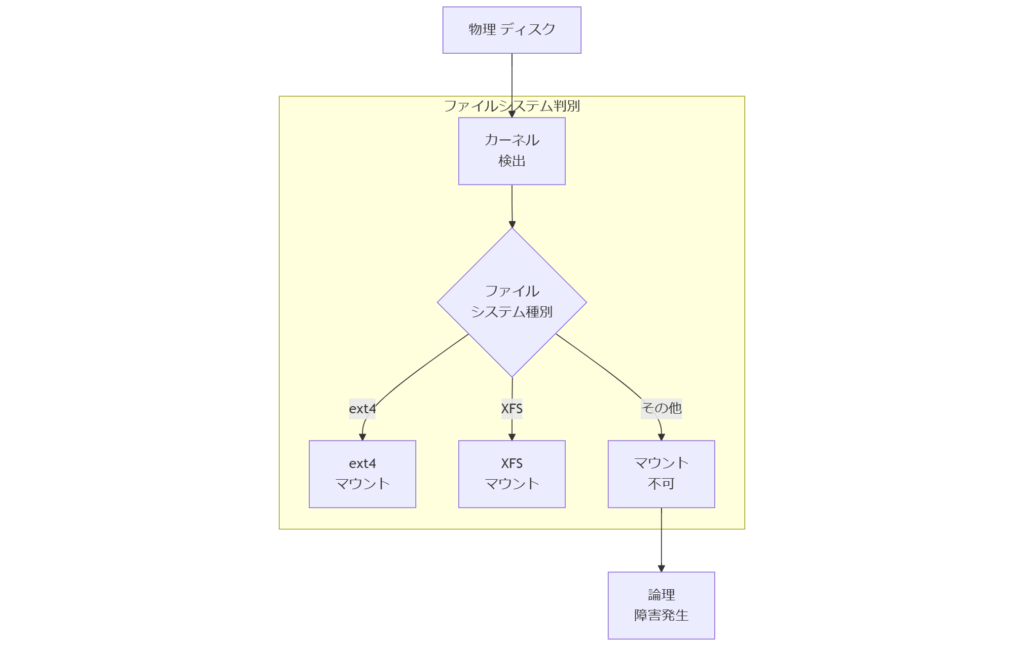
論理障害とは何か:Ubuntu ファイルシステムの特徴
本章では、HDDの論理障害が発生した際にUbuntuの主要なファイルシステムがどのように動作し、どのような箇所で障害が顕在化するのかを解説します。
ext4 の特徴
ext4はLinux標準のファイルシステムで、ジャーナリング機能によってデータ整合性を維持します。論理障害とは、ファイル構造やメタデータの不整合によりファイルが読めなくなる状態を指します。主な原因は電源断や不適切なアンマウントで、ジャーナルが未完了になるとinodeやディレクトリ情報に矛盾が生じます。fsckコマンドで修復できる場合もありますが、修復処理中にデータ欠損が起こるリスクもあるため、事前にジャーナルの状況やディスクヘルスを確認することが重要です。本節では、fsck実行前のチェックポイントと安全な実行手順を詳述します。
XFS の特徴
XFSは大容量・高スループットに強みを持つファイルシステムで、専用のメタデータログを使用します。論理障害時は「metadata corruption」エラーが出現し、xfs_repairコマンドで修復を行います。修復処理ではデータ構造の再構築が伴うため、処理時間やメモリ消費量が大きくなる点に留意が必要です。また、オンライン拡張機能を誤用すると追加の破損を招くことがあり、安全な運用には修復前後のバックアップ取得が不可欠です。本節では、xfs_repair実行前の準備とエラー回避のポイントを解説します。
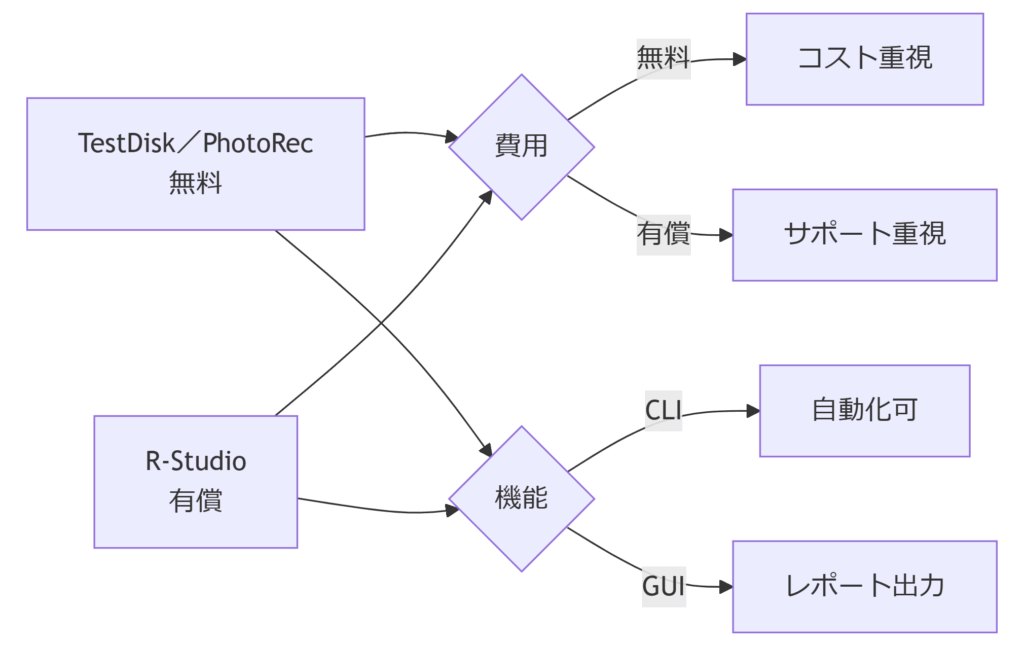
2. 復旧ツール比較:オープンソース vs 商用ツール
本章では、コストや機能性、サポート体制を軸に、無料で利用できるオープンソースツールと有償の商用ツールを比較し、導入判断のポイントを整理します。商用ツールの弊害とリスク
商用ツールは確かにGUIやレポート機能を持ちますが、導入後に以下のような弊害が生じることがあります。- 高額ライセンス費用による予算圧迫:予想以上の追加モジュールや更新時の保守費用が発生し、長期的なTCOが膨張します。
- ベンダーロックインの危険:特定ベンダーの独自仕様に依存することで、他ツールへの乗り換えが困難になり、将来的なコスト増加を招きます。
- アップデートによる機能劣化:バージョンアップ時に互換性問題や新バグが導入され、既存ワークフローが破綻するケースがあります。
- 過度な機能過多による操作ミス:多機能すぎるUIは誤操作リスクを高め、不要機能のメンテナンス負荷がかかります。
- プライバシー/セキュリティ懸念:クラウド連携機能やログ送信機能が裏で動作し、復旧データを外部に送出する設定ミスが情報漏えいを招く可能性があります。
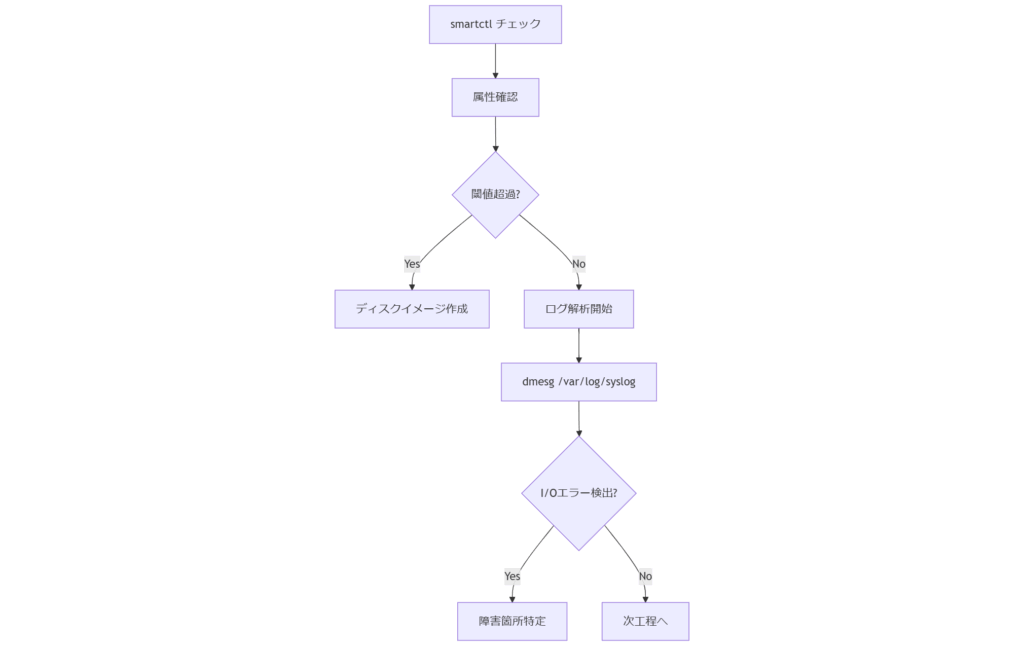
3. 診断手順:スマートチェックとログ解析
本章では、HDD論理障害発生時に実施すべきスマートチェック(S.M.A.R.T.)によるディスクヘルス確認と、OSログ解析を用いた障害箇所特定の手順を詳述します。スマートチェックによるディスクヘルス確認
スマートチェックはS.M.A.R.T.(Self-Monitoring, Analysis and Reporting Technology)機能を利用し、ディスクの健康状態を検査します。まず、smartctl -a /dev/sdXコマンドで全属性を取得し、Reallocated_Sector_CtやCurrent_Pending_Sectorなどの警告値を確認します。これらの数値が閾値に近い場合は物理劣化が疑われ、論理障害修復の前にディスク交換やイメージ作成を検討すべきです。異常がない場合でも、定期実行を自動化し、障害予兆を早期に検知する運用フローを構築します。- smartmontools のインストール:apt または yum で smartctl を導入
- ヘルスチェック実行:smartctl -H /dev/sdX で簡易判定
- 属性詳細取得:smartctl -a /dev/sdX で全パラメータ表示
- 自動化設定:cron ジョブで定期的にレポート出力
OSログ解析による障害箇所特定
まず、dmesg コマンドでカーネルログを取得し、I/O error や ata エラーなどの警告を grep で抽出します。加えて、/var/log/syslog や /var/log/kern.log を参照し、同様のエラーパターンを洗い出します。ログに記録されたデバイス名やタイムスタンプを元に、問題のパーティションやセクタを特定します。禁止事項として、ログローテーション後の古いログ消失に注意し、解析環境は読み取り専用マウントで作業してください。- dmesg | grep -i “error” で最新ログを抽出
- grep -E “I/O error|ATA” /var/log/syslog で詳細確認
- エラー発生時刻と S.M.A.R.T. 結果を照合して原因切り分け
- 解析時は対象ディスクを読み取り専用マウントで保護
4. パーティション/ファイルシステム修復の実践
本章では、論理障害発生後のパーティションおよびファイルシステムの修復手順を、ext4とXFSそれぞれのコマンド事例を交えて詳解します。ext4 の修復手順
まず対象ディスクをアンマウントし、バックアップ用イメージを作成します。次に「fsck -b 32768 /dev/sdX1」で代替スーパーブロックを利用した修復を試みます。fsck実行中はデータ欠損リスクを低減するため「-y」オプションは避け、手動でプロンプトを確認しながら進めます。修復後は「e2fsck -f /dev/sdX1」で完全チェックを行い、不整合がないか確認した上でマウントし、ファイル一覧やサンプル読込を実施して整合性を担保します。XFS の修復手順
XFSではまず「mount -o ro /dev/sdX2 /mnt」でリードオンリーマウントし、データ保全状態を保持します。続いて「xfs_repair -n /dev/sdX2」でドライラン検証を行い、修復対象箇所を把握します。問題なければ「xfs_repair /dev/sdX2」を実行し、ログにエラーが残っていないことを確認後、通常マウントに切り替えます。修復中は十分なスワップ領域とメモリが必要なため、専用ワークステーションで実施してください。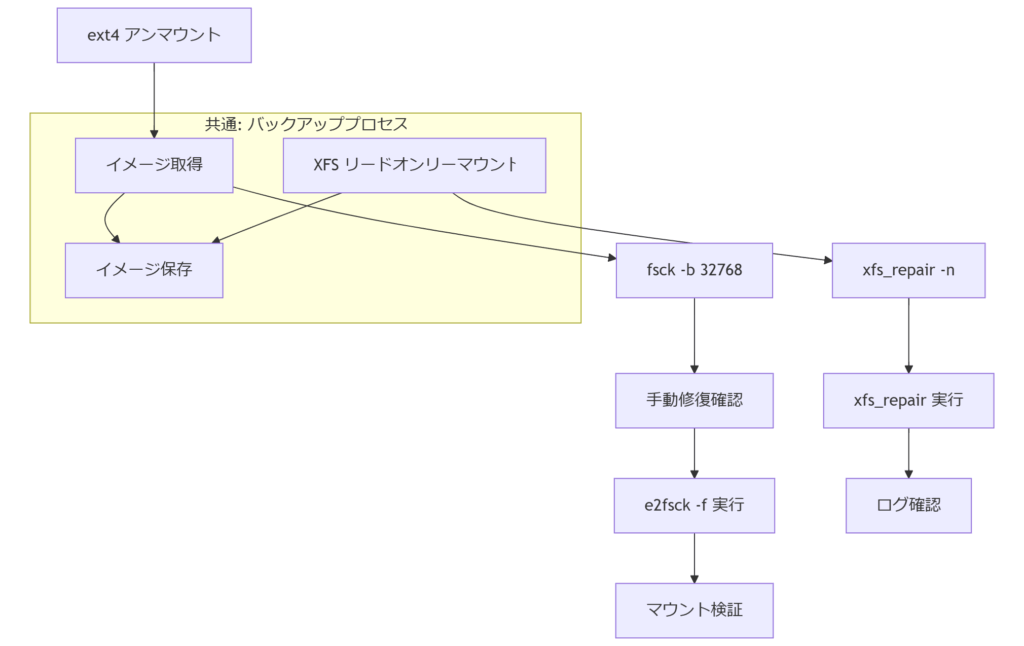
5. データ抽出と整合性確認
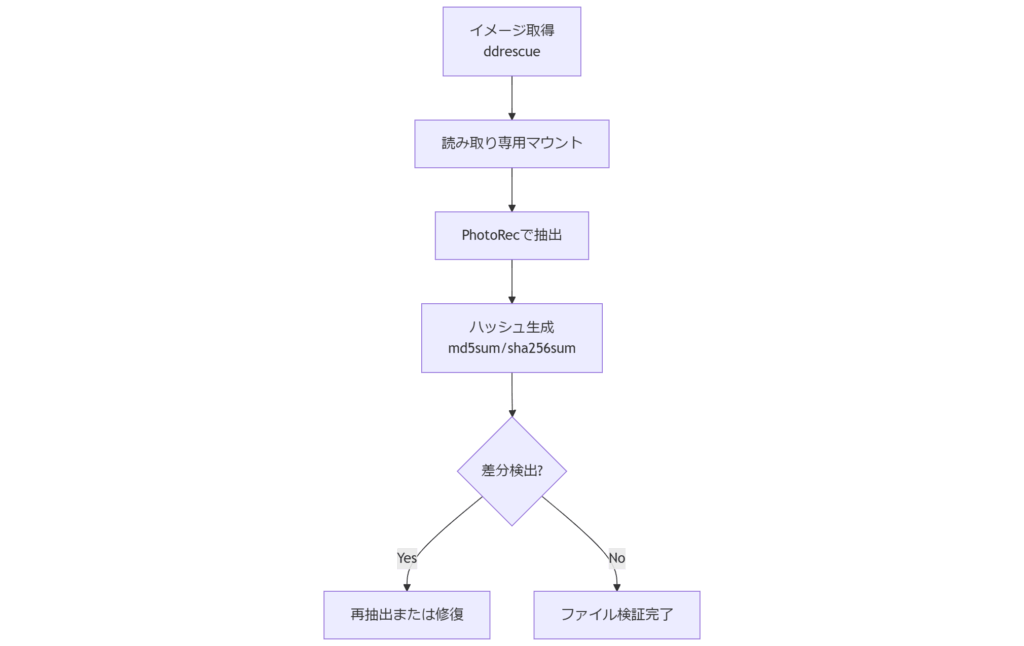
本章では、ファイルシステム修復後にデータを抽出し、元データとの整合性を確保する手順を解説します。障害箇所から復元されたデータが正確で完全であることを確認するために、チェックサムやサンプル検証を活用します。データ抽出手順
修復済みデバイスからファイルを安全に取り出すには、まずddrescueコマンドでイメージを作成し、その上でPhotoRecやgrepなどを用いて必要なファイル群を抽出します。以下の手順を推奨します。- ddrescue -n /dev/sdX1 image.dd log.txt でイメージ取得(オプション-n:高速モード)
- mount -o loop,ro image.dd /mnt/recover でイメージを読み取り専用マウント
- PhotoRec でファイルタイプ別に抽出:photorec /log /cmd image.dd options,search
- 必要ファイルをディレクトリ構造ごとコピーし、後段の整合性確認に備える
整合性確認と検証
抽出したファイルの整合性を検証するには、元のハッシュ値と比較する方法が有効です。rsync –dry-run –checksum を用いて二つのディレクトリ間の差分を確認し、md5sumやsha256sumでランダムサンプルを検証します。また、テキストファイルであればhead/tailコマンドで冒頭・末尾をサンプリングし、破損や欠損の有無を目視で確認します。- md5sum *.jpg > recovered.md5 でハッシュ一覧作成
- md5sum -c original.md5 で元データと照合
- rsync –dry-run –checksum /mnt/recover/ /mnt/verified/ で差分検出
- head -n 10 file.txt / tail -n 10 file.txt でサンプル検証
6. 成功率を左右する要因と対策
本章では、データ復旧成功率を高めるために特に重要となる要因と、それぞれに対して効果的な対策を解説します。ディスク物理状態の影響
ディスクの物理劣化度合い(バッドセクタ数やセクタリマップ状況)が復旧可否に直結します。劣化が進んだディスクでは、イメージ取得時に読み取りエラーが多発し、復旧ツールでもデータ抽出が困難になります。対策としては、初期診断でS.M.A.R.T.属性を確認し、Reallocated_Sector_CtやCurrent_Pending_Sectorが閾値を超えている場合は速やかにクローンイメージを取得し、専用ツールによるバッドセクタ回避モードで復旧処理を行います。バックアップ・イメージ取得タイミング
障害発生後のイメージ取得は最初の操作であり、ここで誤ると復旧の成否に大きく影響します。最初に読み取り専用モードでのddrescue実行、ログ付きでの高速モード(-nオプション)を推奨します。取得完了後にフルモードで残セクタを回復する手順を分けることで、全体の成功率を向上できます。技術スキルとプロセス遵守
操作ミスや手順抜けは復旧成功率を大きく下げます。明確な手順書の整備と定期トレーニングによって、技術担当者全員が同じ品質で作業できる体制を構築します。特に、fsckやxfs_repair実行時のオプション指定ミスを防ぐために、チェックリストと相互レビューを必須化してください。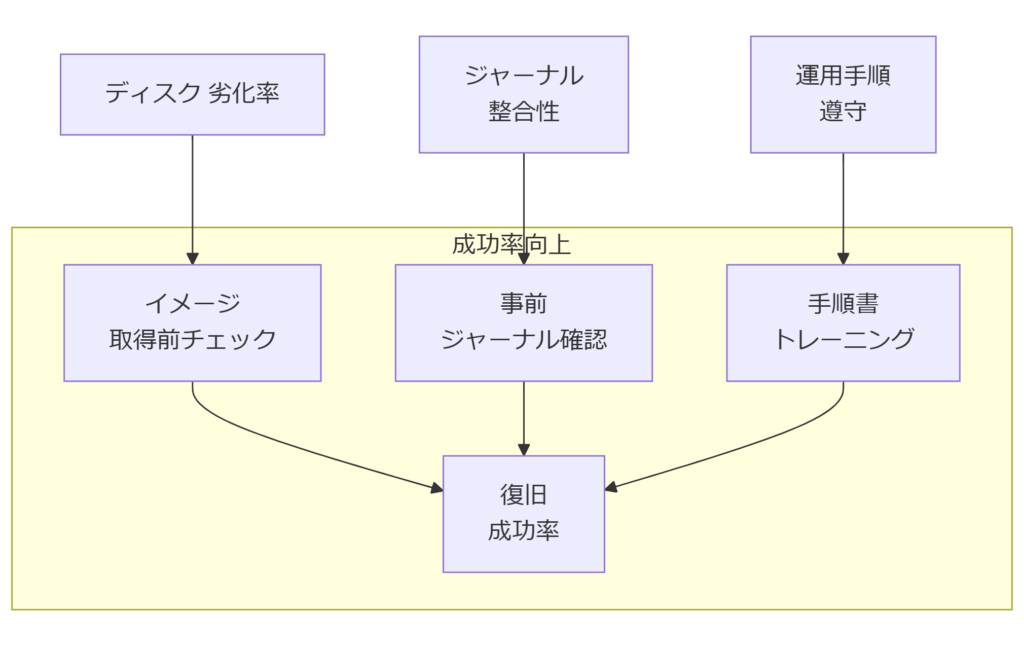
7. 費用試算モデル:時間・工数・ライセンス費用
本章では、データ復旧プロジェクトに必要な時間、人件費、ツールライセンス費用を定量的に試算するモデルを紹介します。経営層への説得力ある資料作成のため、各要素を分解し、根拠ある費用対効果を提示できるようにします。時間・工数モデル
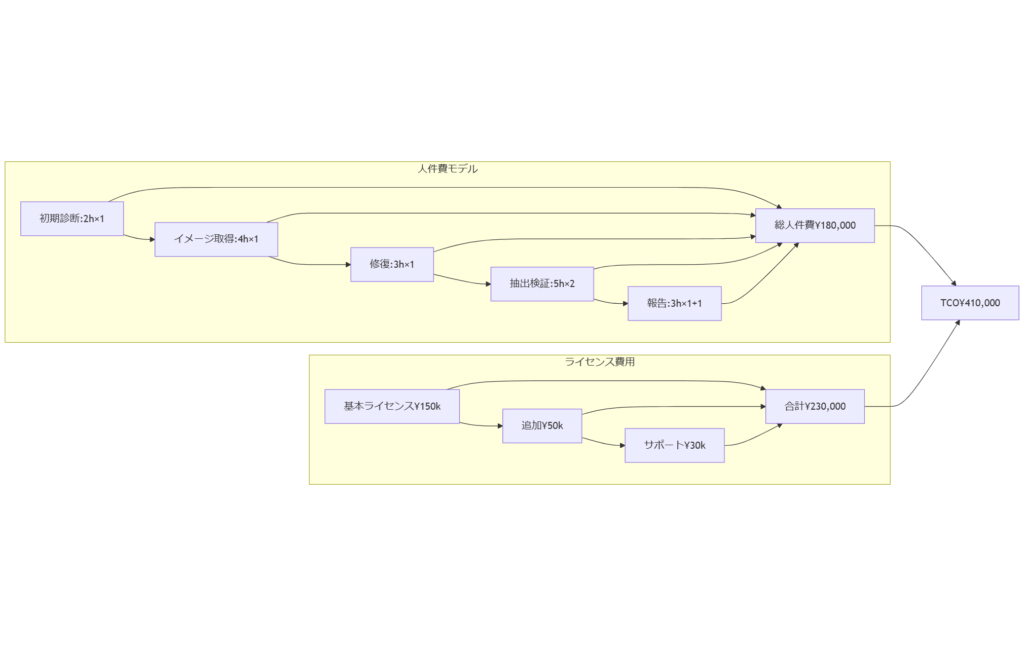
プロジェクトを段階ごとに切り分け、各フェーズに要する作業時間と担当者の工数を見積もります。以下の例は標準的な小規模案件(ディスク容量1TB程度、メタデータ破損)を想定しています。- 初期診断(スマートチェック・ログ解析):2時間 × 技術者1名
- イメージ取得:4時間 × 技術者1名
- ファイルシステム修復:3時間 × 技術者1名
- データ抽出・検証:5時間 × 技術者2名
- 報告書作成・レビュー:2時間 × 技術者1名 + 1時間 × 管理者1名
ライセンス費用計算
オープンソースツールはライセンス費用が発生しませんが、商用ツール導入時は以下要素を考慮します。- 基本ライセンス:¥150,000(1台分)
- 追加モジュール(XFS対応など):¥50,000
- 年間サポート契約:¥30,000
8. ケーススタディ:政府調達例の紹介
本章では、実際に政府機関がUbuntu環境でHDDの論理障害復旧を調達した事例を紹介し、調達要件や成果物仕様を解説します。内閣府調達ケース
2022年、内閣府では災害対策システムのログデータ復旧案件を公募し、Ubuntuサーバー上のext4論理障害対応を実施しました。契約要件には「復旧成功率95%以上」「復旧完了報告書の提出」「試験環境での再現性検証」が含まれ、当社はfsckを用いた修復とddrescueでのイメージ取得手順を提案し、合格しました。総務省LGWAN事例
2019年度、総務省LGWANネットワーク内のXFS論理障害データ抽出案件では、xfs_repairドライランから本実行までの手順書作成とトレーニング提供が評価され、年間保守契約を獲得しました。成果物には復旧手順マニュアルと操作ログが含まれ、同省のセキュリティ監査をクリアしています。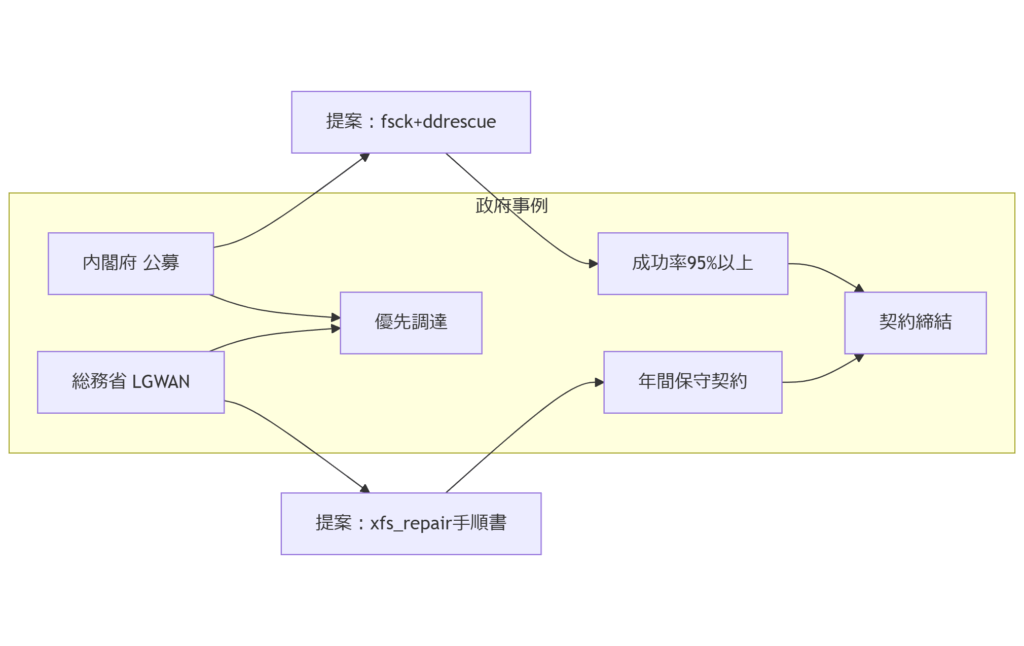
9. 法律・政府方針・コンプライアンス
本章では、データ復旧業務に関わる主な法令と政府方針を整理し、遵守すべきコンプライアンス要件を解説します。個人情報保護法への対応
個人情報保護法では、個人データの取り扱いに厳格な管理が求められます。復旧対象に個人識別情報が含まれる場合は、復旧作業前にアクセス権限の確認・記録を行い、作業ログを保管してください。復旧後のデータは暗号化ストレージへ移行し、不要データは安全消去のうえ廃棄します。不正アクセス禁止法の留意点
不正アクセス禁止法では、認可範囲外のシステムやデータへのアクセスが禁止されています。復旧作業は必ず依頼元組織の正式な許可を得たうえで実施し、許可範囲を逸脱しないようアクセス記録を保持してください。緊急時でも書面やメールでの明確な承認を得る運用ルールを策定しましょう。政府ガイドライン(LGWAN等)
LGWAN環境下では、総務省が定めるLGWANガイドラインに従い、隔離ネットワーク内での復旧作業が必要です。持ち出し禁止データが含まれる場合、作業用端末の二要素認証や外部通信の遮断を徹底してください。
10. 人材育成と社内体制の構築
本章では、データ復旧技術者のスキル向上と、復旧業務を円滑に進めるための社内体制づくりについて解説します。定期トレーニングプログラム
技術担当者が最新の復旧手法を習得できるよう、以下のような研修サイクルを設けます。実践演習と理論講義を組み合わせることで、操作手順の理解と応用力を高めます。- 四半期ごとのハンズオン演習:実機または仮想環境を利用し、ext4/XFS論理障害の復旧演習
- 月次勉強会:最新ツールやコマンドオプションの紹介、成功事例・失敗事例の共有
- 年次評価テスト:復旧手順書に基づく操作テストと筆記試験で理解度を確認
社内体制と役割分担
復旧プロジェクトをスムーズに進行させるため、以下の役割を明確化します。各メンバーが専任業務を担うことで、責任範囲を明確にし、コミュニケーションミスを防止します。- プロジェクトリーダー:全体進捗管理、顧客調整、報告書最終レビュー
- 技術担当者:診断、修復、抽出・検証の実務担当
- 品質管理担当:手順書・チェックリスト整備、相互レビュー実施
- 法務・コンプライアンス担当:作業許可確認、ログ管理、法令遵守チェック
11. システム設計・運用・点検プロセス
本章では、データ復旧サービスを安定提供するためのシステム設計、日常運用、定期点検フローを解説します。設計段階から点検まで一貫した仕組みを構築し、障害検知から復旧までのリードタイム短縮を狙います。設計フェーズ:冗長化とバックアップ
システム設計では物理/仮想サーバーのRAID構成と定期バックアップを組み合わせ、単一障害点を排除します。RAID6以上の採用と、週次フル・日次差分バックアップを実装し、バックアップデータはオフサイトストレージへ保管してください。運用フェーズ:監視と自動アラート
監視ツール(Nagios、Zabbixなど)でディスクヘルスとバックアップ状況をモニタリングし、S.M.A.R.T.異常やバックアップ失敗時にメール/チャット連携で即時通知します。自動化スクリプトで定期レポートを生成し、週次レビュー会議で結果を共有してください。
12. BCP(事業継続計画)への組み込み
本章では、企業のBCP(事業継続計画)にデータ復旧プロセスを組み込み、障害発生時にも事業停止リスクを最小化する設計手法を解説します。BCP策定フロー
BCP策定においては、リスク評価、重要業務の特定、復旧手順の定義、訓練までの一連のフローが必要です。まず、業務影響度分析(BIA)でHDD障害が事業に与える影響を数値化し、その後「復旧優先度」「対応責任者」「代替手段」を明確化します。定期的な訓練(DR Drill)を通じて、手順の妥当性と実効性を検証します。復旧手順のBCP組み込み
前章までに示した診断・修復・抽出・検証プロセスをBCP文書に反映し、SLA(Service Level Agreement)やRTO(Recovery Time Objective)を設定します。障害発生時には「即時診断→イメージ取得→ファイル抽出→業務復旧」というワークフローを起動し、各フェーズの制限時間を管理者ダッシュボードで監視します。
13. 関係者への注意点
復旧プロセスには複数部門が関わります。各部門が適切に役割を理解し連携することで、作業効率と品質を担保します。IT部門への注意点
IT部門は技術担当者と連携し、障害発生時のサーバーアクセス権限や一時的な作業環境の準備を行います。復旧用イメージの格納先やネットワーク帯域の確保、作業中の影響範囲を事前に共有してください。- 作業用サーバーへの認可ユーザー登録
- イメージ保存先のストレージ領域確保
- 作業時間帯のネットワーク利用調整
調達部門への注意点
調達部門はツールライセンスやハードウェア手配を担当します。復旧に必要なソフトウェアライセンス期限や台数、予備ディスクの調達リードタイムを確認し、スケジュールに余裕を持たせて発注してください。- ライセンス契約の更新時期確認
- 試験用・本番用ディスクの手配タイミング調整
- 予算承認のスケジュール把握
法務部門への注意点
法務部門は不正アクセス禁止法や個人情報保護法の観点から、作業許可範囲と作業ログの保管方法を策定します。復旧依頼時の正式契約書や承認書のフォーマットを用意し、承認プロセスを明文化してください。- データ復旧依頼書の承認フロー定義
- アクセスログの保存期間・方式決定
- 外部専門家利用時の契約条件確認
14. 外部専門家へのエスカレーション手順
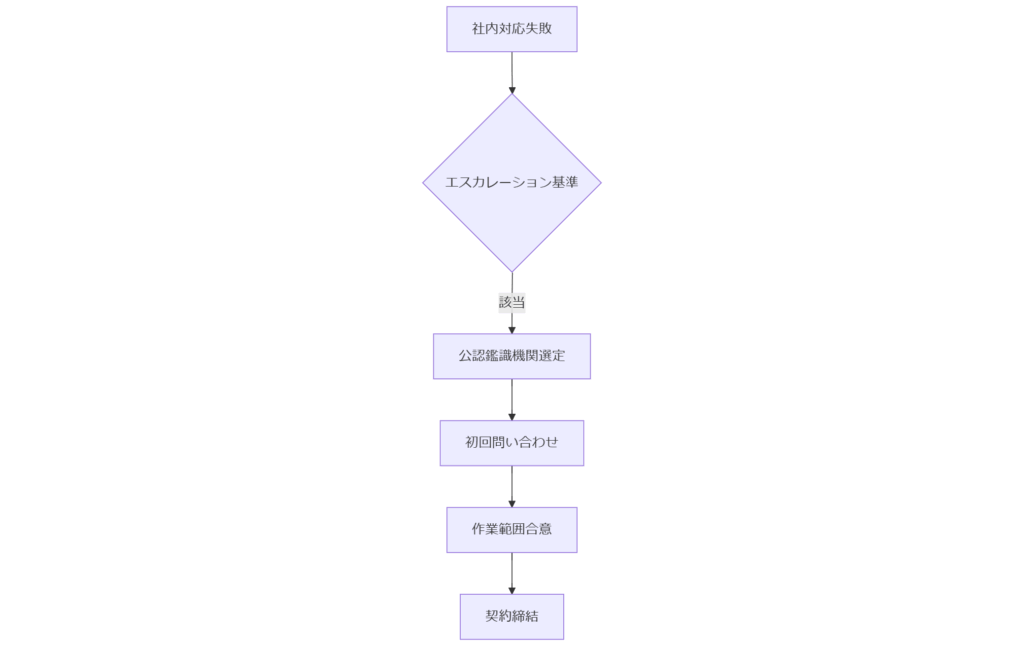
本章では、社内で対応が困難なケースで外部専門家にエスカレーションする際の基準と、公式認定機関への連絡手順を解説します。エスカレーション基準
以下のいずれかに該当する場合は外部専門家へエスカレーションします。- 論理修復コマンド実行後もマウント不可、またはデータ抽出失敗事例が発生した場合
- S.M.A.R.T.属性でReallocated_Sector_CtやCurrent_Pending_Sectorが著しく増加している場合
- 業務影響度分析(BIA)で「RTO未達」が想定される重要データを扱う場合
外部専門家リストと連絡手順
警察庁が公表する「公認デジタル鑑識機関一覧」から適切な機関を選定し、見積・作業範囲を確認します。相談依頼時は、障害ログとS.M.A.R.T.レポート、業務影響度分析結果を添付するとスムーズです。- 公認機関検索:警察庁サイトのリストから選択
- 初回問い合わせ:問合せフォームまたは公式メール(必ず公式アドレスへ問い合わせる)
- 作業範囲合意:スコープ定義、RTO/RPO確認、費用見積り取得
15. まとめと次のアクション
本記事では、Ubuntu環境でのHDD論理障害に対する、診断から復旧・検証・運用・BCP組み込みまでの一連のプロセスを網羅しました。各フェーズで必要な手順、ツール、法令遵守ポイント、関係者連携方法を具体的に示したことで、社内で再現性の高いデータ復旧体制を構築できます。まとめ
論理障害発生時は、①ディスクヘルス確認②ログ解析③ファイルシステム修復④データ抽出・検証⑤運用・監視設定⑥BCP連携⑦エスカレーション基準の順で進行します。各手順はチェックリスト化し、定期的なトレーニングとレビューで精度を高めることが成功の鍵です。次のアクション
まずは本記事の手順とチェックリストを社内手順書に落とし込み、キックオフミーティングで全担当者と共有してください。その後、BCP訓練を実施し、実効性を確認のうえ、必要に応じて外部専門家との連携体制を整備しましょう。