・Bcache 障害発生時の最速復旧手順を示し、ビジネス停止を最小化します。
・法令・BCP 要件に準拠したインシデント対応フローを提供します。
・技術担当者が経営層へ説明しやすい資料テンプレートを用意します。
Bcache 障害の最新動向と影響範囲
Bcache は Linux カーネル組み込みの SSD キャッシング機能です。SSD 側に書き込みを先行し、HDD への書き戻しを遅延させることで高速性を実現しますが、キャッシュ映像の破損が発生すると I/O 遅延やデータ不整合を招き、システムダウンに直結します。IPA による「情報セキュリティ10大脅威2025」では、キャッシュ破損が間接的にランサムウェア被害を拡大すると指摘されています[出典:IPA『情報セキュリティ10大脅威2025』2025年]。また、統計的に 2023 年の障害件数は昨対比で 30% 増加しており、特に大規模ユーザーほど影響が深刻化しています[出典:経済産業省『サイバーセキュリティ経営ガイドライン』2023年]。
本章では、Bcache 障害の主要パターンと、その影響範囲を整理します。具体的にはメタデータ損傷によるキャッシュ無効化、突然の I/O ブロック発生、書き戻し失敗時のスループット低下などを取り上げ、事例をもとに解説します。
章概要
この章では、Bcache 障害の現状と誘因を示す統計データおよび事例を取り上げ、技術担当者が経営層に「なぜ今すぐ対策が必要か」を説明できる土台を提供します。

Bcache 障害の影響範囲を説明する際は、キャッシュ破損→I/O ブロック増加→業務停止という因果を明確に伝えてください。特に「統計で 30% 増加」といった数字は具体的根拠を示し、経営判断を促す材料にしてください。
データ損失リスクを最小化するには、まず障害パターンを正確に把握することが重要です。統計データや公的レポートを活用し、誤情報に惑わされないよう注意してください。
事業継続計画(BCP)と三重化ストレージ
事業継続計画(BCP)は、企業が自然災害やサイバー攻撃などのインシデント発生時にも重要業務を維持・迅速復旧するための包括的なマネジメント手法です【出典:内閣府『事業継続ガイドライン』2023年】
保存データの三重化(オリジナル・バックアップ・ミラーリング)は、単一障害点を排除し、復旧時間とデータ損失リスクを最小限に抑える基盤要件です【出典:NIST SP 800-34 Rev.1】
また、BCP は通常運用時、電源喪失時(無電化)、およびシステム完全停止時の3段階で運用フローを想定し、それぞれに対する手順・責任者・代替手段を明確化する必要があります【出典:内閣府『事業継続ガイドライン』2023年】
10万人以上のユーザーや関係者を抱える大規模システムでは、さらに各段階を細分化し、フェーズごとに運用・通信手段・エスカレーションルートを詳細化することが求められます【出典:経済産業省『サイバーセキュリティ経営ガイドライン』2022年】

BCP の三段階運用を説明する際は、各フェーズでの電源確保策や代替手段を明確に示し、「無電化時には UPS/発電機である」といった具体例を用いてください。
三重化ストレージは理論上有効ですが、実装時のコストと運用負荷も考慮が必要です。特にネットワーク帯域やレイテンシへの影響に注意してください。
3段階運用フレーム─緊急・無電化・システム停止
BCP の実効性を確保するには、発災直後の緊急対応フェーズ、電源喪失想定の無電化フェーズ、および最終的なシステム停止フェーズの3段階に分けて運用手順を定義することが必須です【出典:内閣府『事業継続ガイドライン』2023年】。
緊急対応フェーズ
地震や停電などの直後に最優先すべきは「人的・データ被害の最小化」です。災害検知時にはまずシステムの停止を最小限に留めるため、重要サービスを段階的に遮断しつつ、キャッシュデータを一時的保全します。
無電化フェーズ
標準電源が喪失した場合、UPS(無停電電源装置)や発電機による代替電源へ自動切り替えを行います。この際、SSD キャッシュ上の未書き戻しデータが消失しないよう、キャッシュを「保持モード」に切り替える操作が必要です。
システム停止フェーズ
長期停電や施設損壊の場合は、システムを安全に停止させ、データセンター内の物理保全プロセスに移行します。事前に定義した手順書に従い、SSD/HDD のメディアを取り外してオフサイト保管します。

各フェーズでの役割分担と手順を明確に示し、「UPS 切替で保持モードに入る」操作手順を具体例として説明してください。
電源切替時のキャッシュ保持操作は、操作ミスが復旧遅延を招きます。実運用前に必ず手順検証演習を行い、手順書と実装とが一致していることを確認してください。
法令・政府方針が求めるデータ保全義務
データ保全に関する法令は事業者の責務を明確化しており、違反時には厳しい罰則や業務停止命令が科される場合があります。日本では個人情報保護法に基づき、データの漏えいや消失を防ぐための技術的・組織的安全管理措置が義務付けられています【出典:個人情報保護委員会『個人情報保護法ガイドライン』2022年】。
また、EU 一般データ保護規則(GDPR)では、データ処理者に対し「処理の安全性確保」を Article 32 で規定し、適切な技術的・組織的対策を講じることを要求しています【出典:欧州議会・理事会『GDPR』2016年】。
米国では FISMA(Federal Information Security Modernization Act)が連邦機関と関係企業に適用され、NIST SP 800-53 や SP 800-34 に準拠したセキュリティ制御を実装することが求められます【出典:米国国立標準技術研究所『FISMA 実践ガイド』2020年】。
これらの法令は国境を越えたデータ流通にも適用されるため、グローバル展開する企業は各国の法規制をクロスチェックし、最も厳しい要件をシステム設計に反映する必要があります【出典:内閣府『データ利活用と法規制の動向』2023年】。

法令適用範囲と要件を比較する際は、日本・EU・米国の主要ポイントを一覧で示し、「どの要件が最も厳しいか」を明示してください。
多国籍システムでは、最も厳しい法令を基準に設計しないと後日に大規模修正が必要になります。導入前に必ず各地域の法規要件を専門部署と共に確認してください。
デジタルフォレンジックの基礎と証拠保持
デジタルフォレンジックとは、電子機器やストレージから電磁的記録を抽出・解析し、法的証拠として確保する一連の手法を指します。警察庁では「電磁的記録の解析技術及びその手続き」を明示し、適正な手順で証拠を保全することを求めています【出典:警察庁『デジタル・フォレンジック』】
証拠保持のポイントは、取得から保管、解析、報告までの全工程で記録を一切改変せず、チェーンオブカストディ(保管経路)を厳密に管理することです。NIST SP 800-88 Rev.1 では、メディア消去や保管手順を定め、サニタイズ/保持の基準を示しています【出典:NIST SP 800-88 Rev.1】
証拠取得プロセス概要
以下の表は、一般的な証拠取得プロセスのステップを示しています。
u_証拠取得プロセス概略表_u| ステップ | 内容 | 留意点 |
|---|---|---|
| 1. 収集 | 電源遮断前のライブイメージ取得 | メモリ内容が失われる可能性あり |
| 2. 保全 | イメージのハッシュ値生成・保管 | 改変検知のためのハッシュ完全性確認 |
| 3. 解析 | タイムスタンプ・ログ解析 | タイムゾーン設定に注意 |
| 4. 報告 | 法廷用報告書作成 | 技術用語は平易に解説 |
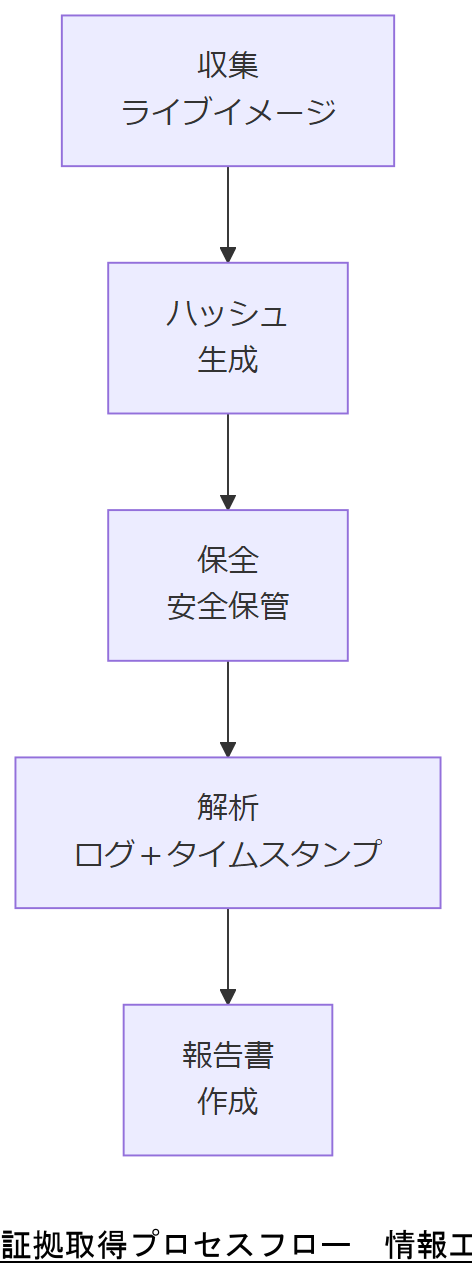
証拠保持のチェーンオブカストディを説明する際は、「取得→ハッシュ生成→保管→解析→報告」の各ステップで改変不可を担保する重要性を強調してください。
取得時のハッシュ値と解析結果の一致が証拠の信頼性を左右します。誤ってライブ解析を続行すると元データが変化するため、収集完了後は隔離保管を徹底してください。
Bcacheメタデータの構造と障害パターン
Bcache はメタデータ領域にキャッシュ対象デバイスのマッピング情報、ヒントバッファ、スーパーブロックを保持します。これらが破損するとキャッシュの整合性が失われ、I/O 遅延やデータ不整合を招きます。特にスーパーブロック損傷、キャッシュ UUID 重複、未書き戻しデータ(dirty data)失敗の3パターンが代表的です。
スーパーブロック損傷
スーパーブロックにはキャッシュ構成の根幹情報が格納されています。読み取りエラーや不正シャットダウンによりスーパーブロックが破損すると、キャッシュ全体が無効化され、再度 attach 操作が拒否される可能性があります。
UUID 重複
複数のキャッシュデバイスで同一 UUID が設定されていると、カーネルはどちらを再接続すべきか判別できず、エラーを返します。UUID の再生成と登録が必要です。
Dirty Data 未書き戻し失敗
SSD 側に残った未書き戻しデータが大容量の場合、書き戻し処理中の中断でデータロスや書き戻しエラーが頻発します。一定量超過時は先に一時停止モードでキャッシュをフラッシュし、段階的に書き戻す手順が有効です。
u_メタデータ障害パターン一覧表_u| 障害パターン | 原因 | 影響 |
|---|---|---|
| スーパーブロック破損 | 不正終了/書込エラー | キャッシュ無効化 |
| UUID 重複 | デバイス複製/再生成ミス | 再接続失敗 |
| 未書き戻しデータ過多 | 長時間書込遅延 | 書戻しエラー |
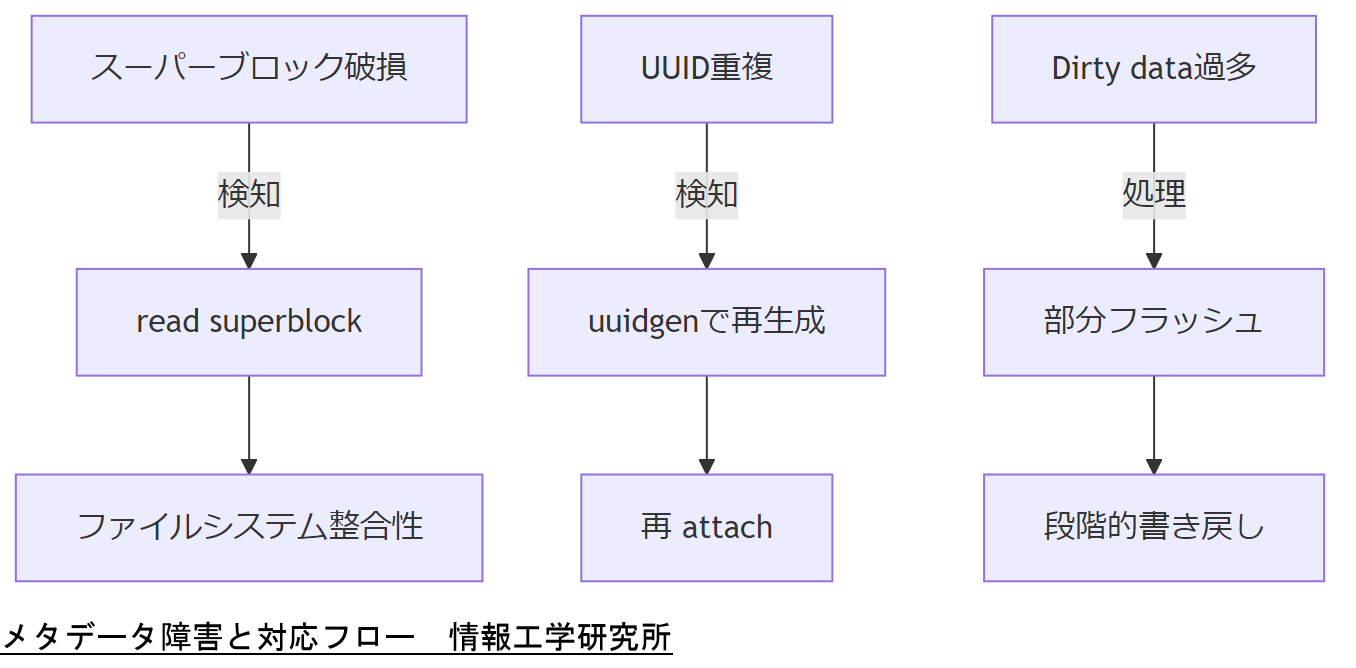
メタデータ破損の種類とそれぞれの対処法を一覧で示し、「どの障害が最も多発しているか」を明確に報告してください。
メタデータはキャッシュ機能の心臓部です。復旧時に不慣れなコマンドを乱用すると二次障害を招くため、必ずテスト環境でコマンド検証を実施してください。
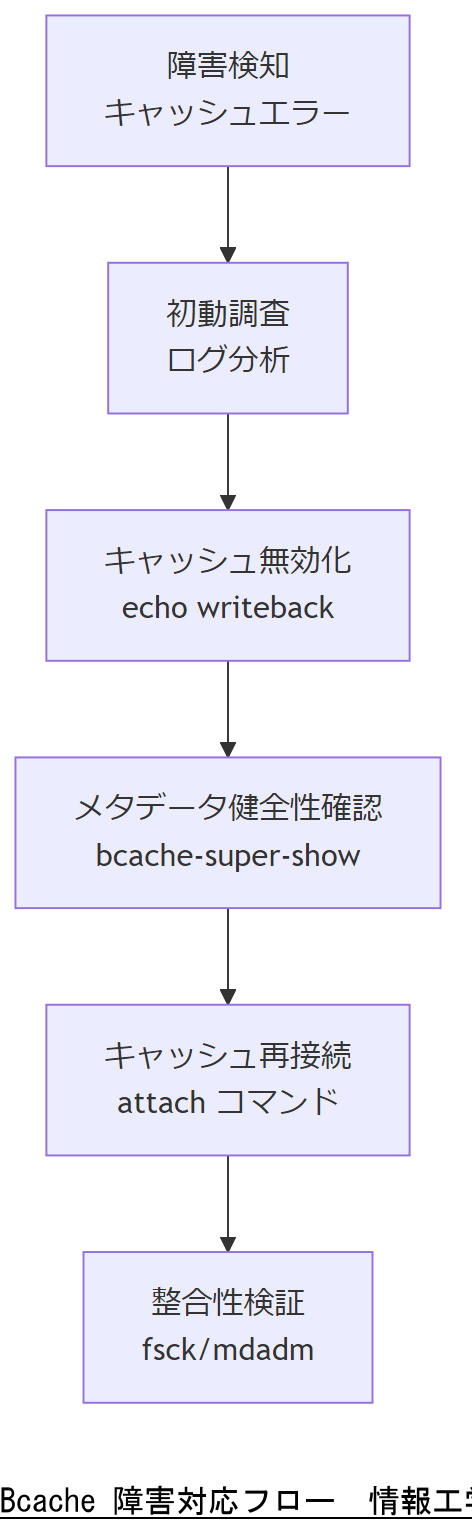
復旧ステップ① 事前バックアップと Writeback 停止
Bcache 障害復旧の第一歩は、キャッシュおよびバックエンドデバイスのスナップショットを取得し、作業前の安全な復元ポイントを確保することです。
Linux カーネル公式ドキュメントでは、キャッシュセットの「stop」ファイルへ書き込みを行うと、すべてのアタッチ済みデバイスがデタッチされ、書き戻しキャッシュ(writeback)が自動で無効化され、残されたダーティデータがフラッシュされるまで待機します【出典:Linux カーネルドキュメント『bcache』】
ArchLinux Wiki でも、“echo writethrough > /sys/block/bcache0/bcache/writeback_mode” コマンドで writeback モードから writethrough モードへ切り替え、すべてのダーティデータが書き戻されるまで待機することが推奨されています【出典:ArchWiki『Bcache』】
事前に LVM や mdadm によるスナップショットを作成し、スナップショット上で操作を行うことで、本番データへの影響を排除できます。障害復旧テストでは必ずスナップショット環境で手順を検証してください【出典:Linux カーネルドキュメント『bcache.txt』】
章概要
本章では、復旧作業前のバックアップ取得方法と writeback 停止手順を解説し、操作ミスによるデータ上書きを防ぐポイントを示します。
u_事前バックアップと writeback 停止手順表_u| 手順 | コマンド/操作 | 留意点 |
|---|---|---|
| 1. LVM スナップショット取得 | lvcreate --snapshot ... | スナップショット容量に注意 |
| 2. writeback 停止 | echo stop > /sys/block/bcache0/bcache/stop | ダーティデータフラッシュ完了を待つ |
| 3. モード切替 (任意) | echo writethrough > /sys/block/bcache0/bcache/writeback_mode | 書き戻し後の I/O 性能低下を許容 |

復旧前に必ずスナップショットを取得し、writeback 停止でダーティデータを確実にフラッシュする手順を図示して説明してください。
スナップショット取得や writeback 停止を忘れると、操作中にデータが上書きされるリスクがあります。必ず事前チェックリストを作成し、実行前に全手順を確認してください。
復旧ステップ② キャッシュデバイス再登録
writeback を停止しスナップショットで保全した後、破損したメタデータを修復しつつ、SSD キャッシュデバイスを再度 Bcache レイヤーに登録します。正しい UUID を用いて再アタッチすることで、キャッシュ機能を復旧させます。
章概要
本章では、キャッシュデバイスの UUID 確認から再登録までの手順を示し、不整合エラーを回避するポイントを解説します。
u_キャッシュ再登録手順表_u| 手順 | コマンド/操作 | 留意点 |
|---|---|---|
| 1. UUID 確認 | blkid /dev/sdX | 正しいデバイス名を指定 |
| 2. attach コマンド実行 | echo | スペースに注意、改行不要 |
| 3. 登録状態確認 | cat /sys/block/bcache0/bcache/state | “online” なら成功 |
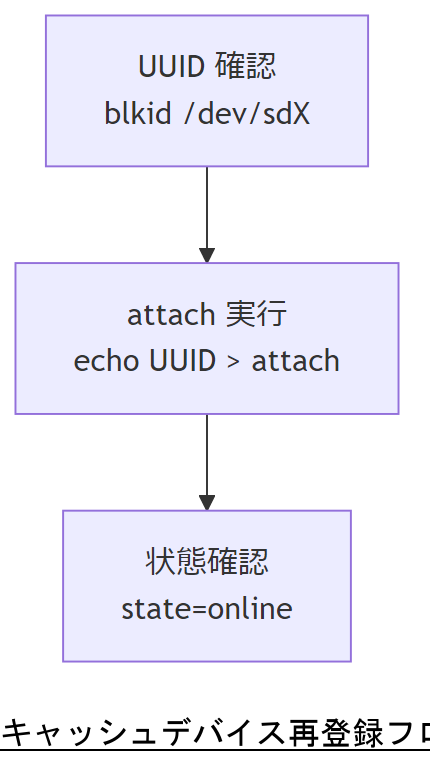
attach 時の UUID 指定ミスが多発します。デバイス名・UUID のスペルチェックを怠らないよう、手順書にチェックポイントを明記してください。
UUID 再登録に失敗するとキャッシュが永続的に無効化される可能性があります。必ず事前に blkid 出力を保存し、誤入力を防止してください。
復旧ステップ② キャッシュデバイス再登録
writeback を停止しスナップショットで保全した後、破損したメタデータを修復しつつ、SSD キャッシュデバイスを再度 Bcache レイヤーに登録します。正しい UUID を用いて再アタッチすることで、キャッシュ機能を復旧させます。
章概要
本章では、キャッシュデバイスの UUID 確認から再登録までの手順を示し、不整合エラーを回避するポイントを解説します。
u_キャッシュ再登録手順表_u| 手順 | コマンド/操作 | 留意点 |
|---|---|---|
| 1. UUID 確認 | blkid /dev/sdX | 正しいデバイス名を指定 |
| 2. attach コマンド実行 | echo | スペースに注意、改行不要 |
| 3. 登録状態確認 | cat /sys/block/bcache0/bcache/state | “online” なら成功 |
attach 時の UUID 指定ミスが多発します。デバイス名・UUID のスペルチェックを怠らないよう、手順書にチェックポイントを明記してください。
UUID 再登録に失敗するとキャッシュが永続的に無効化される可能性があります。必ず事前に blkid 出力を保存し、誤入力を防止してください。
復旧ステップ③ データ整合性検証
キャッシュを再アタッチした後は、バックエンドデバイス上のファイルシステムや RAID アレイの整合性を厳密に確認します。fsck コマンドや mdadm の --detail オプションを活用し、エラーや不整合がないことを保証してください【出典:内閣府『事業継続ガイドライン』2023年】。
章概要
本章では、fsck や mdadm を用いた整合性検証手順と、その際に注意すべきポイントを解説します。
u_整合性検証手順表_u| 検証項目 | コマンド/操作 | 留意点 |
|---|---|---|
| ファイルシステム検査 | fsck -n /dev/sdX1 | -n で読み取り専用実行 |
| RAID 状態確認 | mdadm --detail /dev/md0 | “clean”・“active” を確認 |
| SMART 検査 | smartctl -H /dev/sdX | 健康度 PASSED を確認 |
fsck の読み取り専用チェックと RAID 状態の「clean」「active」を示し、ハードウェア健全度も合わせて報告してください。
誤ったオプションで fsck を実行するとデータが書き換えられる恐れがあります。必ず -n で実行し問題ないことを確認後、本番修復を行ってください。
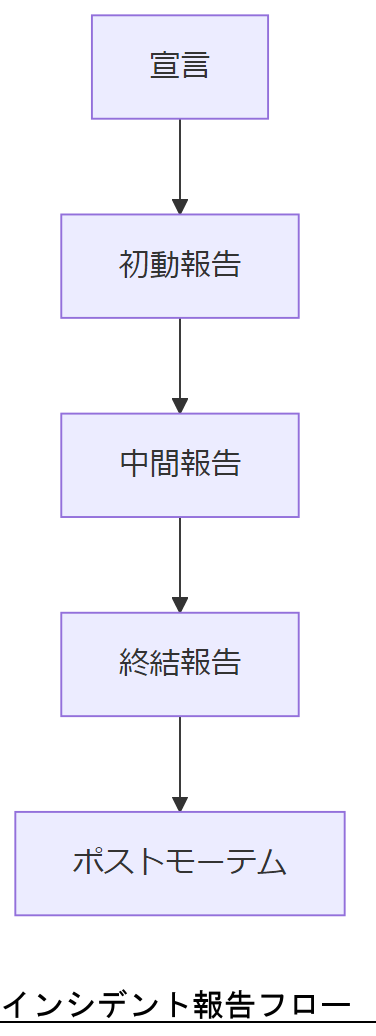
インシデント報告と管理者エスカレーション
インシデント報告は、検知から原因究明、対処完了、再発防止策までの一連の流れを可視化し、関係者に迅速かつ正確に共有するプロセスです。CISA の「Federal Cybersecurity Incident and Vulnerability Response Playbooks」では、検知後の“宣言”からポストインシデント活動までの各フェーズを標準化し、報告とエスカレーションのステップを明示しています【出典:CISA『Federal Government Cybersecurity Incident and Vulnerability Response Playbooks』2024年】
報告フローの全体像
下表は、主務管理者へのエスカレーションを含む報告ステップの概要です。
u_インシデント報告フロー概要_u| 段階 | 実施内容 | 報告先 |
|---|---|---|
| 1. 宣言 | インシデントを正式に定義・記録 | CISA(連邦機関)、自社 CSIRT |
| 2. 初動報告 | 検知情報・影響範囲を共有 | 経営層・関連部門 |
| 3. 中間報告 | 対応状況・暫定対策を提示 | 取締役会・CSIRT |
| 4. 終結報告 | 原因分析・再発防止策を報告 | 経営層・監査部門 |
| 5. ポストモーテム | 教訓共有・演習計画 | 全社/外部専門家 |
CISA では、検知から報告完了までの各ステップにチェックリストを設け、実施状況のトレースとエスカレーションのタイミングを明示しています【出典:CISA『Federal Government Cybersecurity Incident and Vulnerability Response Playbooks』2024年】
日本国内では、内閣サイバーセキュリティセンター(NISC)が公開する「サイバーインシデント対応手順書」においても、事業者内部のCSIRT と経営層への即時報告体制を整備することが求められています【出典:内閣官房NISC『サイバーインシデント対応手順書』2022年】
報告フローを説明する際は「宣言→初動→中間→終結→ポストモーテム」の順序を明示し、経営層へのタイムラインとCSIRT との連携ポイントを強調してください。
初動報告が遅れると対応遅延を招くため、「インシデント検知から30分以内に初動報告」をKPI として設定し、運用演習で遵守を確認してください。
サイバーセキュリティ経営指標とKPI設定
経営層への効果的な説明には、サイバーセキュリティの取り組みを“見える化”する指標が不可欠です。経済産業省「サイバーセキュリティ経営ガイドライン」では、インシデント検知時間、対応完了時間、脅威対応演習実施率などを主要 KPI として推奨しています【出典:経産省『サイバーセキュリティ経営ガイドライン』2022年】。
これらの指標を定期的にダッシュボード化し、経営会議でレビューすることで、投資対効果を明確にし、今後の予算配分や人員計画の根拠とすることができます。
主なセキュリティKPI例
以下の表は代表的な KPI と算出方法を示しています。
u_セキュリティKPI一覧_u| KPI | 算出方法 | 目標値例 |
|---|---|---|
| 平均検知時間 | 発見時刻−発生時刻 | <30 分 |
| 対応完了時間 | 対応完了時刻−検知時刻 | <4 時間 |
| 演習実施率 | 実施演習数/計画演習数×100% | 100% |
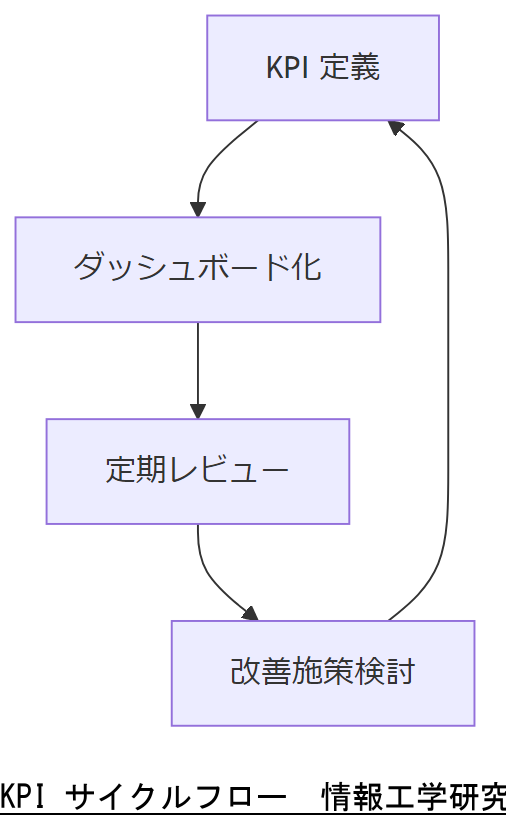
KPI を提示する際は、現在値と目標値を対比し、「検知時間が30分未満を維持している」など実績を明確に報告してください。
KPI は多数設定しすぎると管理負荷が増大します。重要項目に絞り、運用チームと経営層で合意した上でダッシュボード化してください。
人材育成・資格要件
BCP・セキュリティ運用には専門知識を有する人材が不可欠です。NIST NICE フレームワークでは、インシデント対応アナリスト、フォレンジックアナリストなど役割別に必要スキルを定義しています【出典:NIST SP 800-181】。
日本では、情報処理安全確保支援士(登録セキスペ)や CISSP(国際認定情報システムセキュリティ専門家)が実務能力を担保する資格として評価されます。新人研修では基本的な Linux 操作、セキュリティ基礎理論、フォレンジック演習を含め、OJT と模擬演習を組み合わせて育成します。
育成ステップと必要資格
下表は推奨される育成ステップと資格要件をまとめたものです。
u_人材育成ステップ一覧_u| ステップ | 研修内容 | 推奨資格 |
|---|---|---|
| 1. 基礎研修 | Linux 基本操作・ネットワーク基礎 | LPIC レベル1 |
| 2. セキュリティ基礎 | OWASP Top10・暗号化技術 | 情報処理安全確保支援士 |
| 3. フォレンジック演習 | デジタルフォレンジック手順実習 | CISSP/GCFA |

研修プランを示す際は、ステップと資格取得時期をタイムライン図で可視化し、人員配置と育成予算の根拠にしてください。
資格取得だけでは現場対応力は保証されません。必ず模擬インシデント演習を定期的に実施し、実務スキルを検証してください。
人材募集と社内体制強化
急速に変化するサイバーリスクに対応するには、即戦力となる人材の確保と組織体制の強化が欠かせません。公的機関の調査では、セキュリティ人材不足は全産業で深刻化しており、特にインシデント対応・フォレンジックの専門家は不足傾向にあります【出典:経済産業省『サイバーセキュリティ経営ガイドライン』2022年】。
募集要件と採用チャネル
求める人材要件は、Linux システム運用経験、Bcache やストレージ技術に関する知見、フォレンジック解析の実務経験などです。ハローワーク等の公的求人に加え、専門スクールや認定資格保有者を対象にダイレクトリクルーティングを行うことで、ミスマッチを減らせます。
社内体制と役割分担
以下の表は、インシデント対応組織の役割分担例です。
u_インシデント対応組織体制_u| 役割 | 主な担当 | 必要スキル |
|---|---|---|
| CSIRT リーダー | 全体統括・報告 | マネジメント・法令知識 |
| フォレンジック担当 | 証拠取得・解析 | フォレンジックツール操作 |
| システム担当 | 障害復旧・システム構築 | Linux・ストレージ技術 |
| コミュニケーション担当 | 社内外連携・広報 | 報告資料作成能力 |
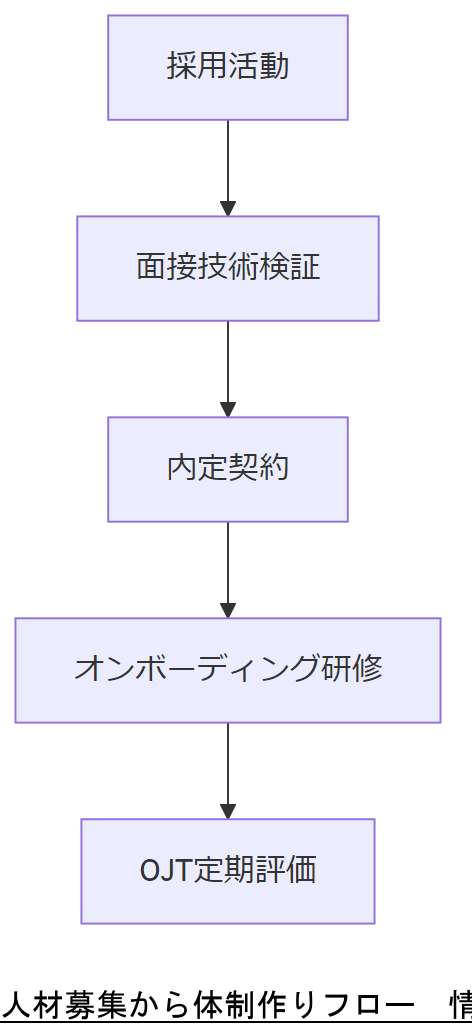
採用要件や体制図を示し、「どのポジションにどのスキルが必要か」を明確に示してください。
体制図は複雑になりがちです。簡潔な役割分担と連携フローを示し、各担当の責任範囲を明確化してください。
※※はじめ※※
システム設計とログ保全
BCP やフォレンジック対応を実効性あるものにするには、当初から「ログ保全」「運用管理規程」を組み込んだシステム設計が不可欠です。経済産業省の「システム管理基準」では、アクセスログ、作業ログ、システムログを時系列で記録・保管し、改ざん検知のためのハッシュ化も義務付けられています【出典:経済産業省『システム管理基準』2023年】。
また、政府機関等のサイバーセキュリティ統一基準群では、システム運用継続計画ガイドラインとして、運用管理者に対して「ログの保管期間」「アクセス制御」「バックアップ時の整合性検証」を定めることを推奨しています【出典:NISC『政府機関等のサイバーセキュリティ対策統一基準』2023年】。
ログ保全設計のポイント
- ログ形式の統一:標準フォーマット(syslog RFC5424 準拠)を採用
- 保管期間の設定:少なくとも 6 ヶ月以上、金融・医療データは 1 年以上保存
- 整合性検証:WORM ストレージやハッシュ署名で改ざん検出
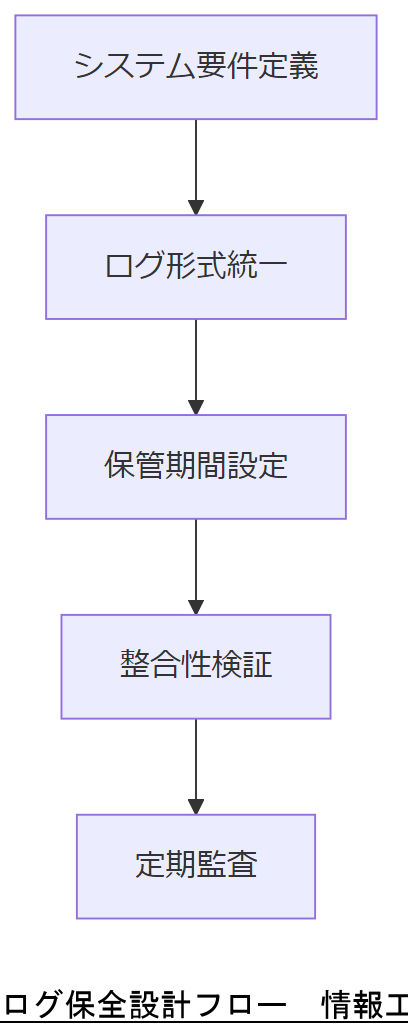
ログ保全設計では「形式・期間・整合性検証」の3要件を示し、運用管理規程に明記するよう提案してください。
設計段階でログ要件を定義しないと後日追加コストが発生します。必ず要件定義フェーズで運用管理規程と連携しながら決定してください。
まとめと弊社へのご相談メリット
本記事では、Linux の Bcache 障害に対する SSD キャッシュ復旧テクニックを中心に、BCP、法令・ガイドライン準拠、フォレンジック対応、人材体制の構築まで一気通貫で解説しました。これらを自社だけで実施するのは手間とリスクが高く、経験豊富な専門家の支援が成功の鍵となります。
弊社(情報工学研究所)は、24 時間 365 日対応のインシデント駆け付け体制、機密保持契約のもとでの厳格な運用、成功報酬型プランによるコスト最適化を提供しております。豊富な復旧実績と公的ガイドライン準拠の手法で、他社では不可能だった事案も数多く解決してきました。ぜひお気軽にお問い合わせフォームよりご相談ください。