# 取得前の対象確認 lsblk -o NAME,SIZE,MODEL,SERIAL,ROTA,TYPE,MOUNTPOINT sudo blockdev --getro /dev/sdX 取得(例:RAW)+ハッシュ sudo dd if=/dev/sdX of=/evidence/case01_disk.raw bs=4M conv=noerror,sync status=progress sha256sum /evidence/case01_disk.raw > /evidence/case01_disk.raw.sha256 sudo dmesg -T | tail -n 80 > /evidence/case01_dmesg_tail.txt
# 迷いどころの固定(チェック項目) 物理ドライブを選択(Logicalではなく Physical の必要性を確認) 保存先は別媒体(同一ディスクや同一NAS共有は避ける) E01 なら分割サイズを設定(例:2GB/4GB)+圧縮は控えめ MD5/SHA1/SHA256 のいずれかを必ず有効化(運用基準に合わせる) 取得ログ(ケース情報・時刻・ツール版本)を保存
# 取り込み前の最低限チェック(例) sha256sum -c /evidence/case01_disk.raw.sha256 解析は「複製(イメージ)」に対して実施 Autopsyで新規Case作成 → Data Sourceとしてイメージを追加 タイムライン/レジストリ/ブラウザ/削除痕跡のモジュールは必要分だけON
# まず決める(例) 物理ディスク単体か(RAIDメンバー個別取得が必要か) RAIDコントローラの論理ボリュームか(スナップショットが取れるか) 仮想基盤ならVMディスク(VMDK/VHDX)か、ゲスト内論理か 共有の上で作業するなら、読み取り専用の複製領域を先に用意
# 最低限の確認 書き込み抑止:Write Blocker / 読み取り専用設定 / 自動マウント無効 保存先容量:想定サイズ + 余裕(ログ/分割/ハッシュ分) 対象確認:モデル/シリアル/容量が一致しているか(sdX取り違え防止)
もくじ
- 現場はいつも「証拠を残せ」と言われるが、ディスクは待ってくれない
- まず押さえるべき前提:フォレンジックイメージは“コピー”ではなく“再現可能な証拠化”
- 失敗パターンから逆算する:触った瞬間に変わるもの(タイムスタンプ、ログ、TRIM、ジャーナル)
- ddは最小で最強:だからこそ「オプション設計」と「取りこぼし」が全てを決める
- ddrescueという現実解:壊れかけ媒体で“読む順番”を制御して回収率を上げる
- FTK Imagerの価値はUIではない:ハッシュ、E01、証跡、メモを“チームで共有できる形”にする
- Autopsy/TSKで見える化する:解析は“取得時の判断”に引き戻される
- 取得形式の選び方:RAW vs E01、圧縮、分割、暗号化、ハッシュ(二重化)のトレードオフ
- チェーン・オブ・カストディをコード化する:ログ、手順、チェックリストで「誰がやっても同じ」に寄せる
- 帰結:ツール選定は宗教ではない――要件(媒体状態・スピード・法的耐性)で“最短で正しく取れる”が正解
【注意】 本記事はフォレンジックイメージ取得ツール(dd / FTK Imager / Autopsy など)に関する一般的な情報提供です。実際の障害状況・証拠保全要件・法的要件・機器状態によって最適手順は変わるため、個別案件は株式会社情報工学研究所のような専門事業者へ相談することをおすすめします。
現場はいつも「証拠を残せ」と言われるが、ディスクは待ってくれない
「とにかく証拠を残して」「原因を説明できる形にして」――言われる側は分かっています。分かっているんですが、現場のディスクは容赦なく劣化していくし、サービスは止められないし、上からは“早く結論”も求められる。そんな板挟みで、イメージ取得はだいたい“時間との勝負”になります。
心の声としては、こんな感じではないでしょうか。
- 「また新しいツール? それ、誰が運用するの?」
- 「証拠って言うけど、まず復旧しないと仕事が止まるんだが…」
- 「触ったら壊れそう。触らなくても壊れそう。」
こう感じるのは自然です。むしろ健全な疑いです。フォレンジックの“最初の一手”は、その後の調査・復旧・説明責任をまとめて左右します。だからこそ、闇雲に手を動かすのではなく、最初に「何を守るための取得か」を言語化してから着手するのが、結果的に最短になります。
「証拠保全」と「復旧」は対立しがちだが、設計で両立できる
フォレンジックイメージは「原因究明のためのデータ複製」と同時に、「後から手順を検証できる状態」を残す行為です。一方で復旧は「動かす・取り出す」ことが目的になり、スピードや実務優先の判断が入りやすい。ここで“歯止め”がないと、あとで説明が詰む典型パターンになります。
両立のポイントは単純で、取得対象と取得範囲、そして取得手順のログ(誰が・いつ・何を・どうやって)を最初に決めることです。ddのように最小構成で取得する場合でも、ログが無いと「同じ結果を再現できるか?」が曖昧になります。
ツール紹介記事のゴールは「宗教論争」ではなく「判断基準の獲得」
ddは強い、FTK Imagerは便利、Autopsyは見える化できる――これ自体は事実です。ただ、現場で困るのは「うちの案件では何が正解か」です。媒体が壊れかけなのか、法的に厳密な証跡が必要なのか、スピード優先なのか、暗号化や個人情報をどう扱うのか。要件が違えば、同じツールでも使い方が変わります。
この記事では、ツールの機能紹介をするだけでなく、「判断の伏線」を順に積み上げて、最後に“要件で選ぶ”という結論に着地させます。もしここで「自社の条件だと判断が難しい」と感じたら、それは正常です。個別案件は一般論を簡単に飛び越えるので、株式会社情報工学研究所のような専門家に相談する価値があります。
まず押さえるべき前提:フォレンジックイメージは“コピー”ではなく“再現可能な証拠化”
最初に前提を揃えます。フォレンジックイメージ取得は、単なる「ファイルコピー」ではありません。基本は“ビット単位で媒体を複製し、取得結果が改ざんされていないことを検証できる形”にすることです。ここを曖昧にすると、後で解析しても「そのデータ、取得中に変わってない?」という疑念が残り、説明責任が重くなります。
通常コピーとフォレンジック取得の違い(最短で理解する表)
| 観点 | 通常のコピー | フォレンジックイメージ |
|---|---|---|
| 対象 | ファイル単位が中心 | 媒体(セクタ/パーティション)単位が中心 |
| 未割当領域 | 基本は対象外 | 対象に含められる(設定次第) |
| 検証 | “同じに見える”で終わりがち | ハッシュ等で整合性を確認しやすい |
| 証跡 | 作業ログが残らないことも多い | 取得条件・操作・結果をログ化しやすい |
ハッシュは“安心のため”ではなく“再現性のため”にある
ハッシュ(例:SHA-256 など)は「改ざんされていない」ことを示すために使われますが、現場で効く本質は“再現性”です。別の担当者が同じイメージを扱っても同一性を確認できる。将来、追加調査が必要になっても「当時のイメージをそのまま使っている」と言える。これが、意思決定のスピードを上げます。
ライトブロッカー(書き込み防止)の話は、結局「説明責任」に帰ってくる
媒体に対する書き込みを抑え込みたいなら、原則として書き込みを発生させない構成に寄せる必要があります。OSが自動で行う処理(マウント時の更新、インデックス、修復提案など)で“意図せず変化”することがあるからです。ハードウェア/ソフトウェアの書き込み防止(いわゆるライトブロッカー)は、その変化を避けるための代表的な手段です。
ただし、環境や媒体種類(NVMe/USBブリッジ/仮想ディスク等)によって制約があります。一般論だけで「これさえあればOK」と断言しない方が安全です。要件や機材の組み合わせで悩んだら、株式会社情報工学研究所のような専門家に相談して、最初に“場を整える”のが結局いちばん早いです。
失敗パターンから逆算する:触った瞬間に変わるもの(タイムスタンプ、ログ、TRIM、ジャーナル)
「正しい手順」を覚えるより、まず「やりがちな失敗」を知った方が、結果として安全です。フォレンジックは“失敗が静かに起きる”のが怖いところで、気づいたときには説明が難しくなります。ここでは、現場で起きやすい“温度を下げるべきポイント”を、技術的に整理します。
失敗1:とりあえずOSでマウントしてしまう
マウント=読み取り、と感覚的に捉えがちですが、OSや設定によってはメタデータ更新が走ることがあります。さらに、セキュリティソフトやインデクサ、バックアップエージェントが自動で触ることもある。ここで「いや、見ただけだから」と言っても、後から“本当に見ただけ?”の疑念が残ります。
失敗2:SSD/NVMeでTRIMやGC(ガベージコレクション)の影響を軽視する
SSDはHDDと同じ感覚で扱うと危険です。TRIMや内部の最適化処理により、未使用領域が時間経過で変化する可能性があります。ここで重要なのは「必ずこうなる」と断定することではなく、変化しうる前提で、早く・確実に・ログを残して取得するという姿勢です。案件によっては、物理障害やファームウェア要因も絡み、一般論の範囲を超えます。
失敗3:障害ディスクに“最後まで順番に読む”設計をしてしまう
劣化した媒体は、読みに行くたびに状態が悪化することがあります。ddで先頭から末尾まで順番に読む設計はシンプルですが、読み取りエラーが多いと時間が溶け、結果として回収できたはずの領域を失うこともあります。こういうときは、読み取り順序やリトライ戦略を持つツール(代表例として ddrescue など)が“被害最小化”に効く場面があります。
「やること」を減らすチェックリスト(最初の30分でやる)
- 対象・目的・優先順位(証拠性/復旧性/速度)を1枚のメモに固定する
- 取得先ストレージの容量・速度・暗号化要否を先に確認する
- ハッシュ計算・ログ保存・時刻同期(作業端末の時計)を確認する
- 可能なら“書き込みが起きない構成”に寄せる(不用意なマウントを避ける)
この段階で「うちの要件だと、どこまでやれば十分?」と迷うのは普通です。一般論のまま突っ込むより、早めに株式会社情報工学研究所のような専門家へ相談し、最初の設計を固めた方が、結果として“収束”が速くなります。
ddは最小で最強:だからこそ「オプション設計」と「取りこぼし」が全てを決める
ddは“道具としては地味”です。ですが、フォレンジックの現場では今も重要な位置にいます。理由は簡単で、OSやディストリビューションを問わず手元にあり、依存が少なく、パイプやログ設計と組み合わせて「自分の欲しい形」に仕立てられるからです。つまり、最小構成で最強になり得る。ただし、ここには落とし穴があります。最小構成ゆえに、設計ミスがそのまま結果の欠落に直結します。
ddでまず考えるべきは「入力」「出力」「ブロック」「エラー時の動き」
ddは概念としては単純です。「入力(if=)を読み、出力(of=)へ書く」。しかし実務では次の4点を必ず決める必要があります。
- 入力デバイスの特定:誤って別ディスクを読まない/書かないための確認(lsblk等)
- 出力形式:RAWファイルにするか、後段で圧縮・分割するか
- ブロックサイズ(bs):速度とエラー耐性のバランス
- 読み取りエラー時の挙動:止まるのか、欠損を埋めて進むのか
「conv=noerror,sync」は“進める”ための歯止めだが、意味を理解して使う
読み取りエラーが出たとき、ddはデフォルトで停止しがちです。そこで使われるのが、一般に conv=noerror,sync のような指定です。これにより、エラーが発生しても処理を継続し、読み取れなかった部分を所定のサイズで埋める(パディングする)挙動になります。
重要なのは、これが「完全に同一のコピーを作る魔法」ではない点です。読めないところは読めない。だからこそ、どこが欠損したかを明確に残すログ設計が必要になります。たとえば標準エラー出力の記録、途中経過(status=progress相当)を残す、取得後に別ルートで検証するといった“ダメージコントロール”が必要です。
取りこぼしが起きる典型:パーティションだけ取って満足してしまう
「/dev/sdX1 だけ取ったからOK」という判断は、要件によっては危険です。未割当領域や別パーティション、ブート領域、メタ領域に痕跡があるケースもあります。一方で、全ディスクを取ると容量も時間も増え、保存先の管理も難しくなる。つまり、ここは要件で決めるしかありません。
この“要件で決める”のが難しい時点で、一般論の限界に近づいています。目的が「社内調査レベル」なのか、「第三者へ説明が必要」なのか、「訴訟・監査の可能性」があるのか。ここを曖昧にしたまま進むと、あとで“軟着陸”できません。迷ったら早めに株式会社情報工学研究所のような専門家に相談し、取得範囲と証跡を先に固めるのが安全です。
dd運用の現実:コマンドは短く、ログは厚く
現場では「コマンドは短く」「ログは厚く」が効きます。コマンドを複雑にすると、再現できない・レビューできない・事故る可能性が上がる。一方で、ログは厚く残すほど後で助かります。誰が、いつ、どのデバイスから、どの出力へ、どんなオプションで、どんなエラーが出たか。これが説明責任の土台になります。
ddrescueという現実解:壊れかけ媒体で“読む順番”を制御して回収率を上げる
ddが「最小構成で取りに行く」道具だとすると、壊れかけ媒体では「読む順番と再試行を設計する」必要が出ます。ここで現場に登場する代表格が GNU ddrescue です。ddrescueは、読み取りに失敗した領域を記録しながら、複数パスで回収を試みる設計を取りやすいのが特徴です。
“読み方”が回収率に影響する理由
劣化した媒体では、同じ領域を何度も読もうとすると状態が悪化する可能性があります。だから「最初は広く浅く読んで、読めたところを確保する」「次に読めなかったところに集中する」という戦略が合理的になります。これ自体は魔法ではなく、時間と負荷の最適化です。結果として“被害最小化”につながります。
ログ(mapfile)が“証跡”にも“作業継続”にも効く
ddrescueが現場で評価される理由の一つが、進捗と失敗領域を記録するログ(一般にmapfile)です。これがあると、途中で停止しても続きから再開でき、どこが読めてどこが読めていないかを説明しやすくなります。つまり、単に便利というだけでなく、作業の“収束”を早める要素になります。
壊れかけ媒体は「触るほど悪化する」前提でブレーキをかける
ここで重要なのは、“どこまで追うか”の判断です。読めない領域を追い続けると、残りの読めた領域まで失うリスクが増えることがあります。現場では「ここまでで一旦止める」「別手段に切り替える」というブレーキが必要です。たとえば、回収率が十分なら解析へ進む、あるいは物理障害が疑われるなら無理に読み続けない、といった判断です。
この判断は、一般論だけでは正解が出ません。媒体の状態、目的、期限、証拠性の要求レベル、そして失われた場合のビジネス影響で決まります。だからこそ、迷うなら株式会社情報工学研究所のような専門家に相談し、方針を固めてから実行するのが安全です。
ddrescueは万能ではない:だから“案件に合わせる”が必要
ddrescueは強力ですが、万能ではありません。たとえば、アクセス経路(USBブリッジやRAIDコントローラ、仮想化レイヤ)によって見え方が変わることがあります。暗号化、論理障害と物理障害の混在、ストレージのファームウェア由来の問題など、現場の条件は多様です。「ツール名」で決めるのではなく、「条件」で決める。この伏線は、最後の結論へつながります。
FTK Imagerの価値はUIではない:ハッシュ、E01、証跡、メモを“チームで共有できる形”にする
現場エンジニアの本音として、「GUIツールは便利だけど、ブラックボックスっぽいのが不安」という感覚があると思います。これも自然です。ですがFTK Imagerの価値は、単なる“ボタンで取れる”ではありません。ポイントは、取得形式(代表例:E01)とハッシュ、そして記録の残し方にあります。チームや第三者と共有しやすい形に“整える”能力が高い、というのが実務上の強みです。
E01(Expert Witness Format)を選べる意味
RAW(ddで得られるような生イメージ)は単純で互換性も高い一方、サイズが大きくなりやすく、管理の都合で分割や圧縮が必要になることがあります。E01は、圧縮・分割・メタデータ・ハッシュ等をまとめて扱える運用がしやすい形式として、調査の現場で使われてきました。形式そのものが「正義」ではありませんが、運用の“場を整える”力があるのは事実です。
「誰が見ても分かる証跡」を残すのが、結果として工数を減らす
フォレンジック対応が長引く理由の一つは、「説明コスト」です。取得手順が曖昧だと、後から確認が増え、社内調整や対人のやり取りで時間が溶けます。FTK Imagerのように、取得時の情報(ハッシュ値、取得対象、日時、メモ)を整然と残しやすいツールは、説明の“漏れ止め”になります。
GUIの落とし穴:手順が属人化しやすい
一方で、GUIには落とし穴もあります。クリック手順が担当者の頭の中にしかなく、再現性が下がることです。だから、ツール導入時には「手順書」「設定のスクリーンショット」「ログの保管場所」「命名規則」を決めておく必要があります。ここを決めないと、便利なはずのツールが属人化を加速し、チームの運用負債になります。
結局、FTK Imagerは“運用設計”とセットで効く
FTK Imagerが真価を発揮するのは、運用が決まっているときです。どの形式で保存するか、どのハッシュを使うか、保管とアクセス権をどうするか、暗号化の要否、そしてログをどこに置くか。ここまで含めて初めて「チームで扱える証拠化」になります。
もしこの段階で、「運用設計まで含めると社内で決めきれない」と感じたなら、それは一般論の限界に近いサインです。個別要件に合わせた最適化は、経験と実務知見が効きます。必要なら株式会社情報工学研究所のような専門家に相談し、設計を短期で収束させる方が結果的に早いです。
Autopsy/TSKで見える化する:解析は“取得時の判断”に引き戻される
イメージを取得したあと、次に現場が欲しくなるのは「見える化」です。フォレンジックの現場は、いきなり“結論”を出せるほど単純ではありません。だからこそ、Autopsy(内部で The Sleuth Kit / TSK を活用することが多い)などの解析ツールで、ファイルシステムやタイムラインを俯瞰し、「何が起きた可能性が高いか」を絞り込んでいきます。
ここで大事なのは、解析が進むほど「取得時の判断」が効いてくることです。たとえば、パーティション単位の取得にした場合、未割当領域や他パーティション由来の痕跡は追えない可能性があります。逆に全ディスクを取っていれば、時間はかかっても解析の自由度が上がります。つまり、解析は“取得の設計”に引き戻される。この伏線が、後半の「要件で選ぶ」という帰結に効いてきます。
Autopsyでよく見るポイント(現場での使いどころ)
Autopsyのようなツールは、次のような作業を一箇所で進めやすくします(具体的な機能名やUIはバージョンで変わり得るため、ここでは考え方に絞ります)。
- ファイルシステムの整理:ディレクトリ構造、削除ファイルの扱い、属性情報などを俯瞰しやすい
- キーワード探索:膨大なデータから特定文字列を起点に当たりを付ける
- タイムライン:時刻情報を軸に「いつ何が起きたか」の候補を並べる
- アーティファクトの抽出:OSやアプリが残す痕跡(ログや設定)を手がかりにする
ただし、ここでも“万能”ではありません。時刻情報はタイムゾーン、時計ずれ、アプリ固有の記録形式などで簡単に誤読します。削除ファイルや未割当領域は、SSDの挙動や上書き状況に左右されます。解析の結果を「断定」にしないためには、取得条件と限界を同時に記録しておく必要があります。
「見える化」が生む誤解を、ログで“漏れ止め”する
見える化ツールは便利ですが、便利なほど「見えている範囲が世界の全て」に見えてしまう危険があります。たとえば“表示されない=存在しない”とは限りません。取得範囲に含まれていない、復号の前提が揃っていない、破損で読み取れない、など理由はいくらでもあります。
この誤解を抑え込み、議論が過熱しないようにするには、取得範囲・取得形式・欠損領域・検証(ハッシュ等)を最初からセットで提示することが効きます。社内説明や対外説明が必要な案件ほど、ここが“防波堤”になります。
解析が詰まったら、追加取得より先に「要件の再確認」をする
解析が詰まると、「追加で別ツールを回そう」「もう一度取り直そう」となりがちです。でも、そこで一歩引いて「この案件のゴールは何か」を再確認するのが、結果として早いことが多いです。原因究明なのか、影響範囲の特定なのか、復旧優先なのか、法的に耐える説明が必要なのか。ここが曖昧なまま追加取得をすると、時間もコストも膨らみやすい。
判断が難しい場合は、一般論の限界です。個別要件を踏まえた“軟着陸”の設計は、経験が効きます。必要なら株式会社情報工学研究所のような専門家に相談し、取得と解析の方針を最短で整えるのが現実的です。
取得形式の選び方:RAW vs E01、圧縮、分割、暗号化、ハッシュ(二重化)のトレードオフ
「ddでRAWを取るか、FTK ImagerでE01を取るか」。この問いはよく出ますが、正解は一つではありません。現場の制約(保存先容量、転送速度、保管ポリシー、第三者提供の可能性、暗号化の要否)で決まります。ここを“宗教”にすると揉めるので、判断軸を表に落とします。
| 項目 | RAW(例:dd出力) | E01(例:FTK Imager等) |
|---|---|---|
| 単純さ/互換性 | 概念が単純で扱いやすい。後段のツール互換も取りやすい傾向 | フォーマット対応が必要。対応ツールが揃うと運用はしやすい |
| サイズ/転送 | そのままだと大きい。圧縮や分割は別工程になりやすい | 圧縮/分割を運用に組み込みやすい場合がある |
| メタデータ/証跡 | ログやメモは別で設計する必要がある | 取得情報や検証情報をまとめやすい運用が組みやすい |
| 暗号化/保管 | 暗号化は別工程になりやすい(運用で統制) | 暗号化を含む運用設計がしやすい場合がある(環境依存) |
圧縮は“便利”だが、CPU・時間・検証手順を増やす
圧縮すれば保管・転送は楽になります。ただし、圧縮はCPU時間を消費し、失敗時の切り分けも増えます。さらに重要なのは「圧縮後の検証」をどうするかです。ハッシュをどの段階で取るのか(生データ、コンテナ、両方)、分割時にどう扱うのか。ここを詰めないと、便利さの代償として説明が難しくなります。
分割は“運用の現実”だが、命名規則と整合性が命
大容量のイメージは分割せざるを得ないことがあります。分割は悪ではありません。ただし、分割ファイルの欠落や順序違い、混在が起きると復元不能になることがあります。ここで効くのが、命名規則(連番・日時・媒体ID)と、保管場所のアクセス制御、そして受け渡し時のチェックリストです。地味ですが、これが“堤防を築く”作業です。
ハッシュは「一つ決めて終わり」ではなく、二重化が効く場面がある
ハッシュアルゴリズム自体は要件に応じて選びますが、実務的には「取得直後」と「保管/受け渡し時」に同一性確認をする運用が効くことが多いです。つまり、ハッシュは一回取って終わりではなく、工程の節目で“同じものを同じものとして扱えている”ことを確認するためのブレーキになります。
ここまでを設計に落とすと、どうしても「自社だけでは決めきれない」論点が出ます。保管ポリシー、個人情報、委託契約、監査要件などが絡むからです。一般論で押し切らず、必要なら株式会社情報工学研究所のような専門家に相談し、最短で運用を整える方が安全です。
チェーン・オブ・カストディをコード化する:ログ、手順、チェックリストで「誰がやっても同じ」に寄せる
フォレンジックで一番しんどいのは、技術そのものより「説明と合意形成」かもしれません。現場の本音としては、「調査のために夜中まで頑張ったのに、後から“その手順で本当に大丈夫?”って言われるのが一番つらい」ですよね。だから、最初から“疑われにくい形”に寄せるのが大事です。
チェーン・オブ・カストディ(証拠の取り扱い記録)は、法廷のためだけの概念ではありません。社内の監査・顧客説明・委託先管理でも、同じ構造が役に立ちます。ポイントは、難しい言葉を掲げることではなく、手順とログをテンプレ化して再現性を上げることです。
最低限のログ項目(ここが“漏れ止め”になる)
- 作業日時(タイムゾーン含む)、作業端末、担当者
- 対象媒体の識別情報(型番/シリアル、接続経路、OSからのデバイス名)
- 取得範囲(全ディスク/パーティション/論理ボリューム等)
- 取得コマンド/ツール名とバージョン、主要オプション
- 保存先(パス、分割の有無、暗号化の有無、アクセス権)
- エラーの有無と概要、欠損が疑われる範囲(分かる範囲で)
- ハッシュ値(どの段階で、何を対象に計算したか)
「コード化」とは、手順を機械的に再現できる形に落とすこと
ここで言う“コード化”は、必ずしもプログラムを書くことではありません。チェックリスト、テンプレ、ログの書式、命名規則を決め、誰が担当しても同じ粒度で記録が残る状態にすることです。これができると、担当者が変わっても調査の継続がしやすくなり、議論が過熱しても事実ベースで沈静化しやすくなります。
保管とアクセス制御は、技術より「運用」で崩れやすい
イメージは高機密になりやすいデータです。個人情報、顧客データ、認証情報、秘密情報が含まれる可能性がある。だから、保管先のアクセス権、持ち出し制限、暗号化、ログの保全など、運用の“防波堤”が必要です。ここを軽視すると、調査を進めるほどリスクが増える状態になります。
このあたりは、技術だけで決めきれない要素(契約、社内規程、監査、委託範囲)が絡みます。一般論で片付けず、必要に応じて株式会社情報工学研究所のような専門家と一緒に、運用の落とし所を作るのが安全です。
帰結:ツール選定は宗教ではない――要件(媒体状態・スピード・法的耐性)で“最短で正しく取れる”が正解
ここまでの伏線を回収します。ddは強い。ddrescueは壊れかけに強い。FTK Imagerは運用を整えやすい。Autopsy/TSKは解析と見える化がしやすい。全部、本当です。だからこそ結論は単純で、ツール名で選ばず、要件で選ぶが正解です。
現場エンジニアのモヤモヤ――「また新しいツール?」「運用が増えるだけでは?」――これに対してロジックで答えるなら、こうなります。ツールを増やすのではなく、要件に対して最短で収束する手順を作る。そのために必要な道具を選ぶ。これが“ダメージコントロール”として一番効きます。
要件別の“ざっくり”選び方(一般論としての目安)
| 状況/要件 | 取り得る方針(例) | 注意点 |
|---|---|---|
| 媒体が健全、速度優先 | シンプルに取得(dd等)+ハッシュ+ログ | 誤デバイス防止、範囲(全体/一部)の判断が重要 |
| 媒体が不安定、回収率優先 | 読み順・再試行を設計(ddrescue等) | 追いすぎると悪化の可能性。止め時のブレーキが必要 |
| チーム運用/第三者説明が重い | 形式・証跡・分割運用を整えやすい構成(E01等) | 手順の属人化防止(テンプレ/チェックリスト)が鍵 |
| 解析で早く当たりを付けたい | Autopsy/TSK等で見える化し、仮説を絞る | 「見えている範囲の限界」を常に併記する |
一般論の限界:現場は“複合要因”で簡単に前提が崩れる
実案件は、暗号化・仮想化・RAID・クラウド同期・エンドポイント保護・ログの欠落・SSD特有の挙動などが重なります。ここで一般論だけで進めると、途中で「想定外」が連発し、時間もコストも増えやすい。つまり、要件で選ぶといっても、その要件の把握自体が難しいことがあります。
次の一歩:悩んだ時点で、相談した方が早いことがある
「何を取るべきか」「どこまで証跡が必要か」「この媒体は追加で触って良いのか」――ここで迷うなら、すでに“専門性が価値を出す局面”に入っています。無理に自社だけで抱え込むより、株式会社情報工学研究所のような専門事業者に相談し、案件に合わせた取得・保全・解析の設計を一緒に作った方が、結果として早く、リスクも下げられます。
付録:現在のプログラム言語各種で「フォレンジック実装」をするときの注意点(落とし穴の指摘)
最後に、実装する側の視点での注意点をまとめます。フォレンジック領域は「データが壊れている」「境界条件が多い」「触ると変化する可能性がある」という、いわば仕様外入力の宝庫です。プログラム言語や実装スタイルごとに落とし穴が違うので、“歯止め”として押さえておきます。
共通の注意(言語に関係なく事故るポイント)
- 読み取り専用を徹底:誤ってマウントや修復を走らせない。作業端末の自動処理(インデックス等)も含めて抑え込みを考える
- 境界条件とエラー処理:破損ヘッダ、途中欠損、サイズ不整合、文字コード不正などを“想定内”として扱う
- 時刻の扱い:タイムゾーン、DST、時計ずれ、ファイルシステムの時刻粒度差を前提にする
- ハッシュの対象を明確化:何に対して計算した値か(生データ/コンテナ/分割単位)をログに残す
- 再現性の確保:依存ライブラリのバージョン、ビルド条件、実行環境の差異を記録する
Python(スクリプトで回しやすいが、再現性と性能の罠)
- ライブラリの版差で挙動が変わりやすい(依存を固定し、実行環境を記録する)
- 巨大ファイルの扱いでメモリ/速度が破綻しやすい(ストリーム処理、バッファ設計、例外処理が必須)
- 文字列処理が便利な反面、バイナリ境界を壊しやすい(bytesとstrを厳密に分ける)
Go(配布しやすいが、I/O設計とエラー見落としに注意)
- 並列化しやすい反面、I/Oが増えると媒体への負荷が上がる(壊れかけ媒体では特に“読みすぎ”が危険)
- エラーを握りつぶす実装になりやすい(戻り値の徹底とログ設計が重要)
Rust(安全性は強いが、学習コストと実装速度のトレードオフ)
- メモリ安全性は強いが、現場での即応性(短期実装)とのバランスが課題になることがある
- バイト列パースは堅牢に書ける一方、仕様外入力へのリカバリ設計は別途必要
C/C++(性能は出るが、フォレンジックでは“安全側の設計”が必須)
- 破損データを食わせる前提だと、境界チェック不足が即クラッシュ/脆弱性になる
- 未定義動作や整数オーバーフローが解析結果の誤りに直結しやすい(徹底した検証が必要)
Java / C#(エンタープライズ運用に強いが、バイナリ処理と性能に注意)
- ログ・運用は整えやすいが、大容量バイナリを雑に扱うとGC負荷が跳ねる
- 文字列/バイト変換ミスで証拠性を損ないやすい(エンコーディングの固定とテストが重要)
JavaScript / Node.js(周辺ツールは豊富だが、証拠性の“揺れ”に注意)
- 依存パッケージ更新が速く、再現性確保が難しくなりやすい(lockfile運用とバージョン固定)
- バイナリ処理は可能だが、ストリームやBufferの扱いを誤ると欠損や順序ミスが起きる
Shell(bash等)/PowerShell(現場で強いが、細部の誤りが事故になる)
- ワンライナーは便利だが、レビュー・再現性が落ちやすい(手順書とログをセットにする)
- パスやワイルドカードの誤爆、文字コード、改行コードの差で静かに壊れることがある
SQL(調査で使うなら、証拠の“加工”をどこまで許すかを明確に)
- クエリでデータを整形すると「加工済みの結果」になる(原本の保持と、加工手順のログが必要)
- 時刻・NULL・文字コードの扱いで解釈が変わる(前提を固定し、出力条件を記録する)
締めくくり:一般論は地図、個別案件は地形
ここまで述べたのは、あくまで一般論としての地図です。実案件は媒体状態、要件、期限、説明責任、契約条件が絡み、地形が急に変わります。だからこそ、「このケースはどこまでやるべきか」「この手順で証拠性は足りるか」「復旧と調査をどう両立するか」で悩んだときは、無理に自己完結させず、株式会社情報工学研究所への相談・依頼を検討してください。結果として、リスクを抑えながら早く“収束”させられる可能性が高まります。
解決できること・想定課題
- 証拠能力を損なわないイメージ取得フローを理解できる
- 政府ガイドラインに沿った社内フォレンジック手順を策定できる
- 経営層へ投資対効果を示す資料雛形を入手できる
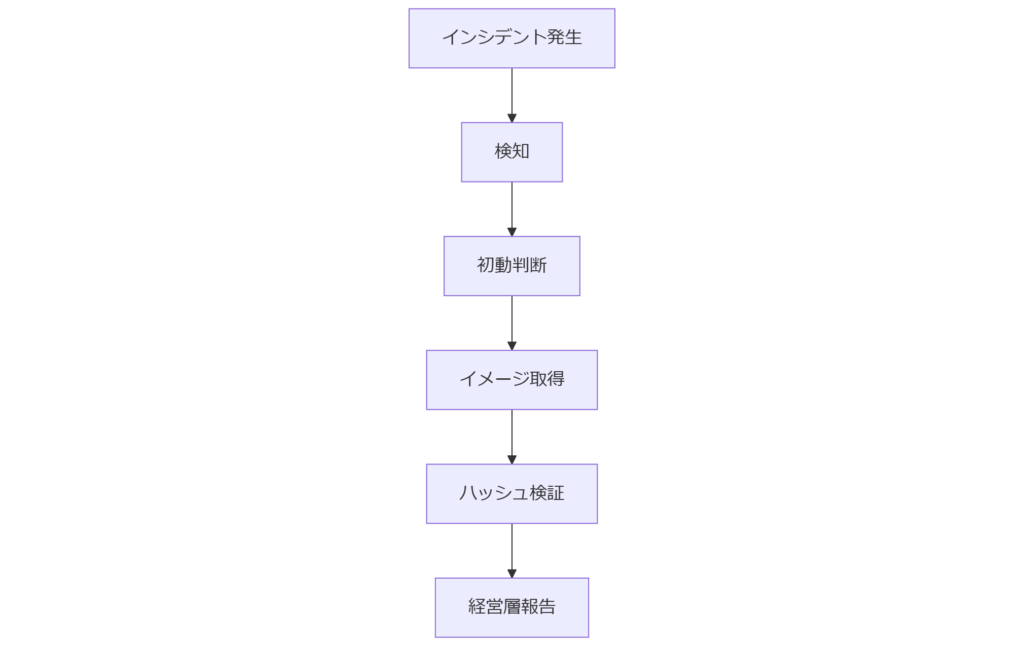
インシデント初動と証拠保全の重要性
インシデント対応の成否は最初の24時間に集約されます。総務省「サイバーセキュリティ体制構築ガイドライン」では、発生直後の証拠確保を怠ると真因解明が著しく困難になると指摘しています。本章では、初動対応の全体像と、イメージ取得をいつ・誰が・どのように実施すべきかを整理します。初動対応フローと関係者の責務
技術担当者はネットワーク隔離やログバックアップと並行してストレージの完全コピーを取得しなければなりません。経営層は意思決定の迅速化、総務・広報は情報公開方針の調整など、それぞれ役割が明確です。時間軸で見る初動タスク
表1 初動対応タスクと推奨完了時間| 経過時間 | 主担当 | 主要作業 |
|---|---|---|
| T+0〜1h | CSIRT | アラート確認・影響範囲特定 |
| T+1〜4h | CSIRT/情報システム | ネットワーク隔離・dd等でイメージ取得開始 |
| T+4〜8h | 情報システム | ハッシュ検証・保全完了報告 |
| T+24h以内 | 経営層 | 対外公表方針決定、再発防止策検討 |
ハッシュ検証で担保する証拠能力
イメージ取得後にSHA‑256など安全なハッシュ関数で検証し、結果をログと併せて保管することで改ざんリスクを排除します。警察庁の「デジタル証拠の取扱要領」はハッシュ値の二重管理と担当者二名による署名を推奨しています。
[出典:総務省『サイバーセキュリティ体制構築ガイドライン』2023年 https://www.soumu.go.jp/main_content/000825674.pdf]
フォレンジックイメージ取得の基礎
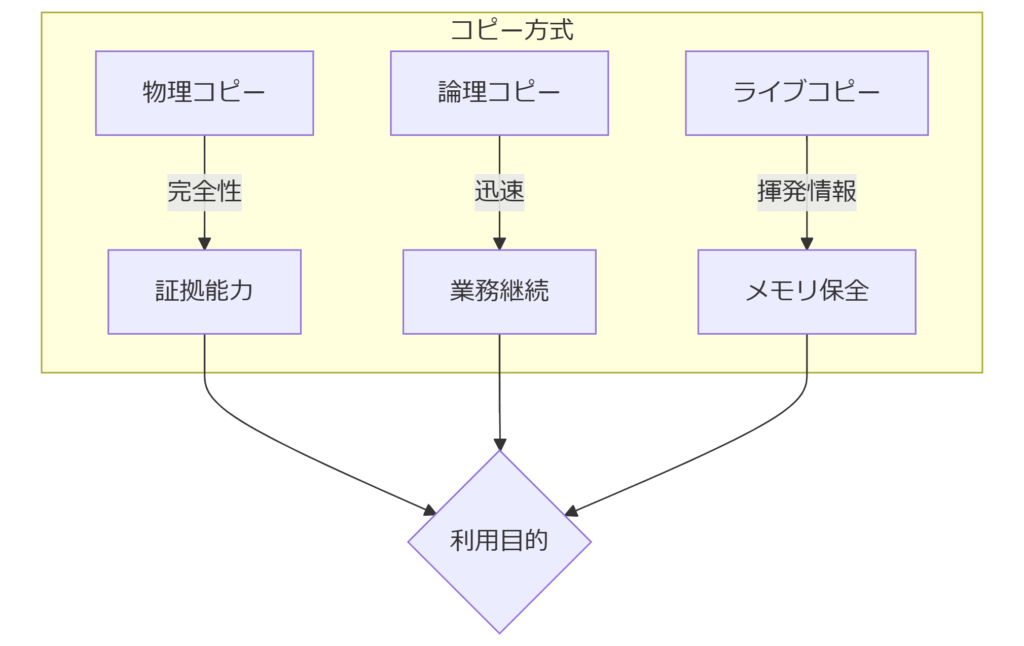
フォレンジック調査の成否は完全性と再現性に依存します。本章では、経済産業省「デジタル・フォレンジックガイドライン」で定義されるイメージ取得の原則を解説し、物理コピー・論理コピー・ライブレスキューの違いと選択基準を整理します。取得レベルの分類と用途
物理コピーはディスク全セクタを対象とし、削除ファイルやパーティション外領域まで解析可能です。一方、論理コピーはファイルシステムレベルで必要最小限のデータを抽出するため、取得時間を短縮できます。ただし改ざん検知の範囲が狭まるため、裁判証拠としては物理コピーが望ましいとされています。ツール選択の決め手:ハードウェアサポート
近年のNVMe SSDはコントローラ依存のウェアレベリングにより不良ブロックの再配置が頻繁に発生します。物理コピー時にTRIMが実行されるとデータ欠損リスクが高まるため、write blocker機能を備えた専用リーダーの利用が推奨されます。 表2 コピー方式とリスク比較| 方式 | メリット | デメリット |
|---|---|---|
| 物理コピー | 完全性・復元性が高い | 取得時間と媒体容量に比例して長時間 |
| 論理コピー | 迅速取得・影響範囲限定 | 隠しパーティションを取得できない |
| ライブコピー | 稼働中システムのメモリ情報保持 | 証拠汚染リスクが最も高い |
[出典:経済産業省『デジタル・フォレンジックガイドライン』2022年 https://www.meti.go.jp/policy/netsecurity/df_guideline.pdf]
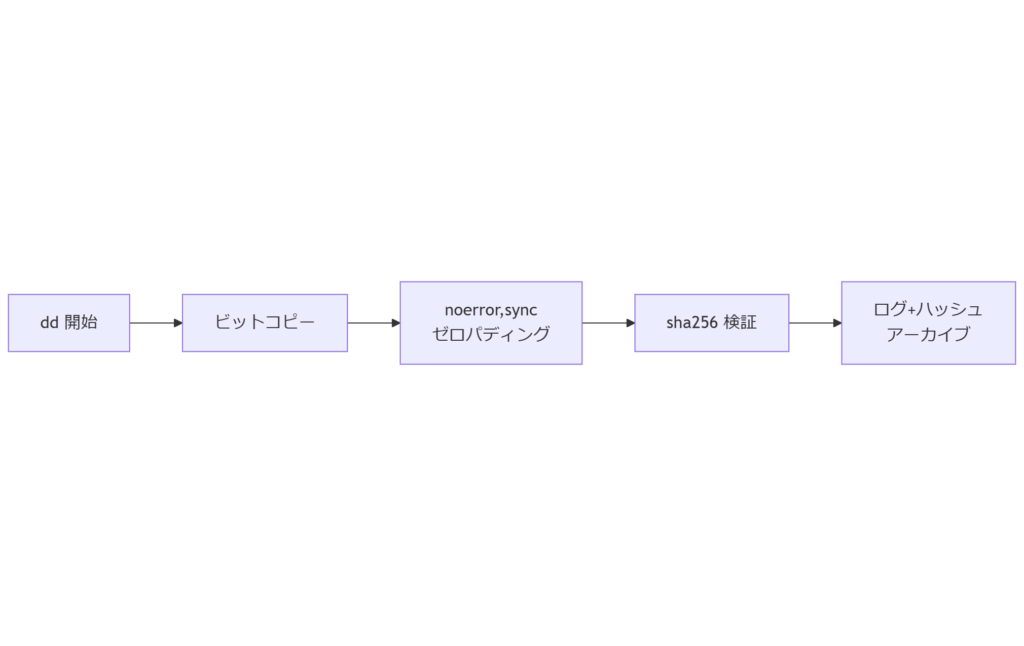
ビット単位コピー:dd の活用法
Unix系OSに標準搭載される dd コマンドは、追加ソフト不要で物理コピーを行える汎用ツールです。ここでは、ブロックサイズ指定やエラー処理オプションとともに、警察庁「デジタル証拠の取扱要領」に準拠したログ取得方法を示します。基本構文と主要オプション
dd if=/dev/sdX of=/mnt/forensic/drive.img bs=4M conv=noerror,sync status=progress 重要なのはconv=noerror,syncで、不良セクタをゼロパディングしイメージ長を保ちます。status=progress を付けると進行状況が標準エラーに出力され、取得速度と残時間が把握できます。ハッシュ値の同時取得スクリプト
取得終了後ただちに sha256sum drive.img > drive.img.sha256 を実行し、さらに取得ログとハッシュを一体でアーカイブします。ファイル属性をchattr +iで変更不可に設定することで、誤操作による改変を防止します。 表3 dd 運用チェックリスト| ステップ | 指示内容 | 確認者 |
|---|---|---|
| デバイス確認 | lsblk で対象ドライブ特定 | 担当者A |
| 書込みキャッシュ無効化 | hdparm -W0 /dev/sdX | 担当者B |
| dd 実行 | オプション conv=noerror,sync 使用 | 担当者A |
| ハッシュ検証 | sha256sum 一致確認 | 担当者B |
[出典:警察庁『デジタル証拠の取扱要領』2021年 https://www.npa.go.jp/cyber/policy/evidence_guideline.pdf]
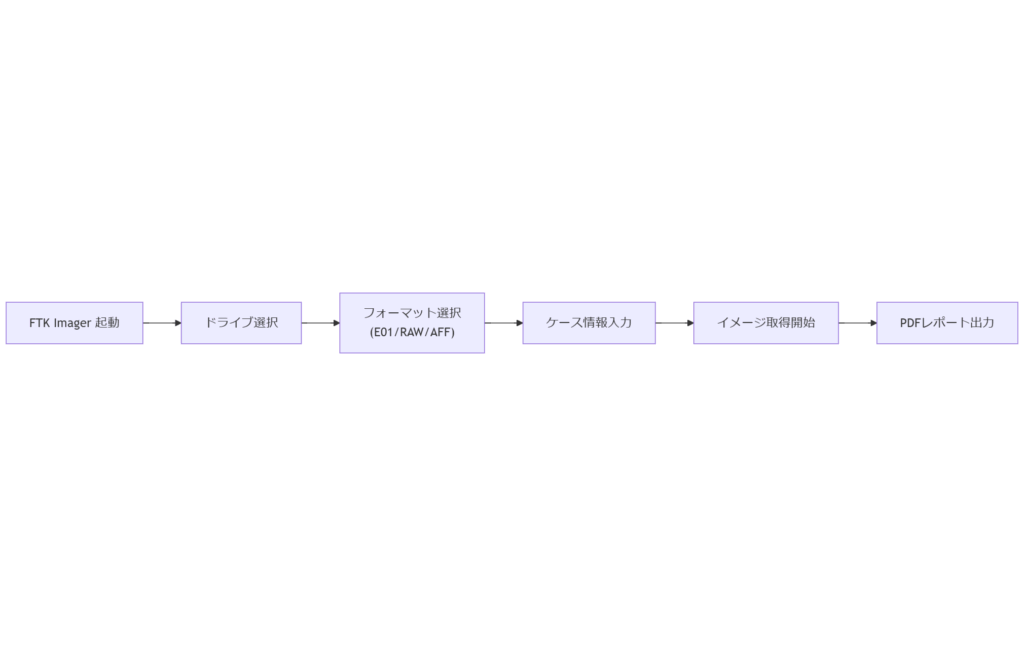
GUI派に最適:FTK Imager の機能と手順
FTK Imager はティーベック・システムズ製の無償ツールで、GUI操作によりイメージ取得とログ管理が容易です。本章では、ソフト起動から preuve(証拠)生成までのステップを、画面イメージ例とともに解説します。イメージ作成ウィザードの流れ
「Create Disk Image」を選択し、対象ドライブを指定。保存先とフォーマット(E01, RAW, AFF)を選び、ケース情報を入力します。E01形式はメタデータ保持と分割出力が可能で、大容量媒体でも管理しやすい点がメリットです。証拠完結レポートの出力
取得後「Evidence File Hash リスト」によりSHA-1およびMD5ハッシュ値が自動生成され、PDFレポートに記録されます。複数ケース管理画面からイメージとレポートを一元閲覧可能です。 表4 FTK Imager主要画面と操作ポイント| 画面 | 機能 | 注意事項 |
|---|---|---|
| ドライブ選択 | 対象媒体の確認 | ←誤選択リスク |
| フォーマット選択 | E01/RLX/AFF | ←圧縮率と互換性 |
| ケース情報入力 | チェーンオブカストディ記録 | ←必須入力項目 |
| レポート出力 | PDFレポート生成 | ←保存先確認 |
[出典:経済産業省『デジタル・フォレンジックガイドライン』2022年 https://www.meti.go.jp/policy/netsecurity/df_guideline.pdf]
統合解析ツール:Autopsy での取得と管理
Autopsy はオープンソースのフォレンジックプラットフォームで、取得したディスクイメージのインポートから詳細解析、レポート生成までを一元管理できます。本章では基本機能と活用ポイントを整理し、社内ワークフローへの組み込み方法を示します。ケース管理とイメージインポート
起動後に「New Case」を選択し、ケース情報を入力するとストレージ上に専用フォルダが作成されます。「Add Data Source」でディスクイメージ(E01, RAWなど)を指定すると、自動的にハッシュ検証が行われ、準備完了後に解析モジュールが有効化されます。解析モジュールとタイムライン解析
ファイルシステム解析、タイムライン生成、キーワード検索など豊富なモジュールを標準搭載。特にタイムライン解析を使えば、イベント発生順にデータを可視化でき、調査報告の説得力を高めます。 表5 Autopsy 主要機能と活用ポイント| 機能 | 用途 | 注意点 |
|---|---|---|
| Case Management | 複数イメージの一元管理 | ディスク容量の確保が必須 |
| Keyword Search | 特定文字列の高速抽出 | インデックス作成時間が長い |
| Timeline | ログ・ファイル操作履歴の可視化 | タイムゾーン設定に留意 |
| Reporting | HTML・PDFレポート自動生成 | テンプレートのカスタマイズ要 |
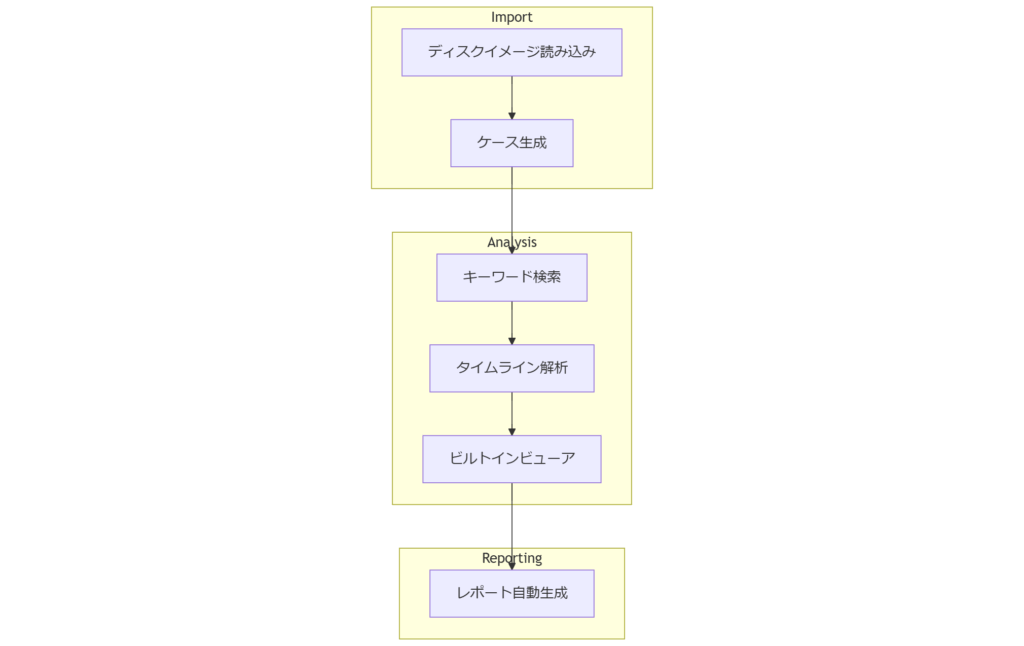
[出典:経済産業省『デジタル・フォレンジックガイドライン』2022年 https://www.meti.go.jp/policy/netsecurity/df_guideline.pdf]
クラウド環境の証拠保全
オンプレミスとは異なり、クラウド環境ではAPIを通じたスナップショット取得や監査ログの保全が鍵となります。本章では、IPA「クラウドセキュリティに関するガイドライン」に沿い、クラウドコンソール操作とログエクスポートの手順と留意点を解説します。スナップショット取得と保全
仮想ディスクのスナップショットは、実データの整合性を維持しつつイメージを取得する手法です。取得時は必ず増分取得モードを避けずフルスナップショットを選び、APIレスポンスのタイムスタンプを記録しておきます。クラウド監査ログの収集
操作履歴はAPI監査ログとして自動生成されるため、エクスポート設定を有効化してログをオブジェクトストレージ等に出力します。API呼び出し元IPやタイムスタンプを保管し、後から証拠として照合可能な状態にしておきます。 表6 クラウド証拠保全手法比較| 手法 | メリット | デメリット |
|---|---|---|
| フルスナップショット | 完全性保証 | コストと取得時間増大 |
| 増分スナップショット | 迅速・低コスト | 差分のみで完全性欠如 |
| 監査ログエクスポート | 操作履歴の証拠化 | 保存ポリシー管理の手間 |
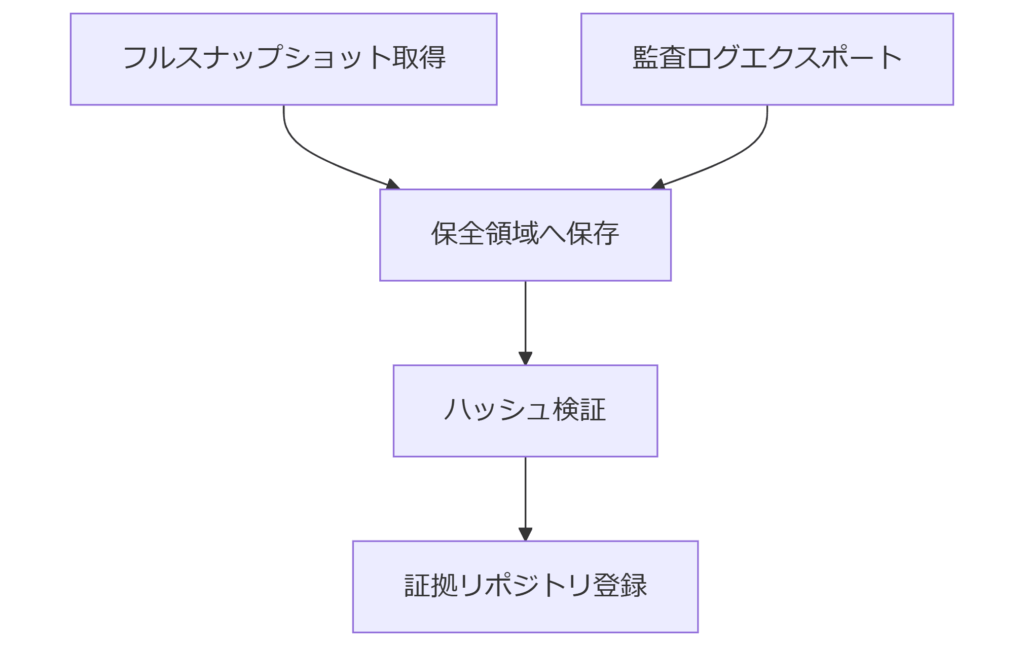
[出典:情報処理推進機構『クラウドセキュリティに関するガイドライン』2021年 https://www.ipa.go.jp/security/ciaguide/]
ハッシュアルゴリズムと改ざん防止
イメージ取得後の改ざん防止は、ハッシュアルゴリズムの選定と管理方法が鍵を握ります。本章では、警察庁や総務省が推奨するSHA-2/SHA-3とMD5の特徴を比較し、社内運用での取り扱いルールを解説します。推奨ハッシュ関数の概要
SHA-256(SHA-2系)は現状最も広く使われ、衝突耐性に優れています。一方、SHA-3は将来の耐量子性を見据えた設計です。MD5は速度重視ですが衝突が容易なため、証拠保全では併用のみ許容され、単体利用は避ける必要があります。ハッシュ管理とログ保存
ハッシュ値はイメージ取得時に生成し、タイムスタンプ付きログとともに保全リポジトリへ登録します。書込禁止属性(chattr +i 等)を付与し、変更履歴を監査ログに記録することで不正改ざんを防止します。 表7 ハッシュ関数比較| 関数名 | 衝突耐性 | 速度 | 用途 |
|---|---|---|---|
| SHA-256 | 高 | 中 | 証拠保全の標準 |
| SHA-3 | 非常に高 | やや低 | 将来対応 |
| MD5 | 低 | 高 | 補助検証 |

[出典:警察庁『デジタル証拠の取扱要領』2021年 https://www.npa.go.jp/cyber/policy/evidence_guideline.pdf]
ログ取得とタイムスタンプ管理
証拠保全には、操作履歴を正確に記録する監査ログと、取得時刻の真正性を担保するタイムスタンプが不可欠です。本章では、ログ設定要件とNTP同期の手順、証明書発行・検証方法を整理し、ログ保全ポリシー策定のポイントを解説します。監査ログの種類と保全方法
OS標準のシステムログ(syslog)やアプリケーションログ、クラウドAPI監査ログなど取得対象は多岐にわたります。ログ出力先は改ざん防止のためリモートサーバ保存を原則とし、ファイル権限変更やWORM(Write Once Read Many)ストレージ活用を推奨します。時刻同期とタイムスタンプ証明
サーバはNTP(Network Time Protocol)で政府運営のNTPサーバ(ntp.nict.jp 等)と同期し、取得ログにタイムスタンプ署名を付与します。情報通信研究機構「電磁的記録に係る時刻証明ガイドライン」では、証明書の有効期限管理と鍵保管体制を厳格化しています。 表8 監査ログ保存設定要件| 項目 | 設定例 | 留意点 |
|---|---|---|
| ログ転送先 | rsyslog → リモートSyslogサーバ | TLS暗号化必須 |
| ファイル属性 | chmod 640, chattr +i | 管理者のみ書換不可 |
| NTP同期 | server ntp.nict.jp | 定期同期(hourly) |
| タイムスタンプ署名 | RFC3161 準拠 | 有効期限と鍵管理 |
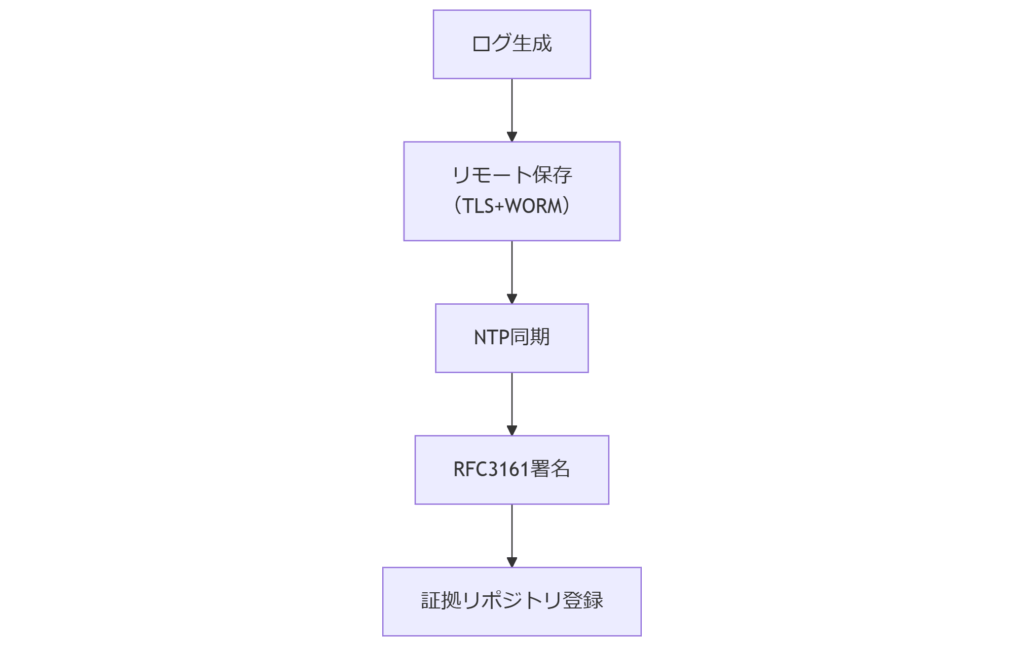
[出典:情報通信研究機構『電磁的記録に係る時刻証明に関するガイドライン』2020年 https://www.nict.go.jp/publication/timestamp_guideline.pdf]
人材育成と内部統制
フォレンジック体制を継続的に維持するには、技術スキルだけではなく内部統制と人材育成の両輪が必要です。本章では、IPA「情報セキュリティ人材育成指標」に沿った社内教育プログラムと役割分担モデルを解説します。教育プログラムの設計
基礎研修から、実機演習、外部認定(GCFE:GIAC Certified Forensic Examiner)取得支援まで段階的に実施します。社内演習では、インシデントシナリオを定期的にロールプレイし、取得手順とログ検証の一貫性を確認します。内部統制フレームワーク
役割分担は分離の原則を基本とし、取得者・検証者・証拠保管担当を分けます。四眼原則(Two-Person Rule)を導入し、すべての操作ログを第三者監査部門と共有することで不正リスクを抑制します。 表9 人材育成・内部統制モデル| フェーズ | 対象者 | 主な内容 |
|---|---|---|
| 基礎研修 | 新人技術者 | フォレンジック基礎理論 |
| 実機演習 | 中堅担当者 | dd/FTK/Autopsy演習 |
| 認定支援 | リーダークラス | GCFE取得サポート |
| 監査レビュー | 管理部門 | 操作ログ・レポート検証 |
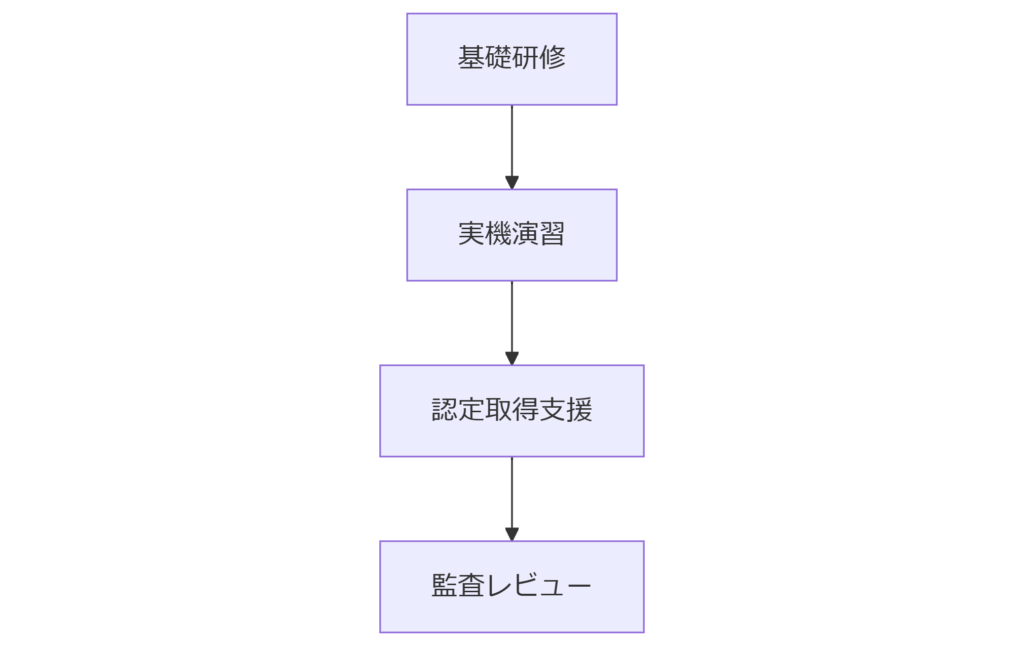
[出典:情報処理推進機構『情報セキュリティ人材育成指標』2020年 https://www.ipa.go.jp/security/education/index.html]
BCPと外部専門家へのエスカレーション
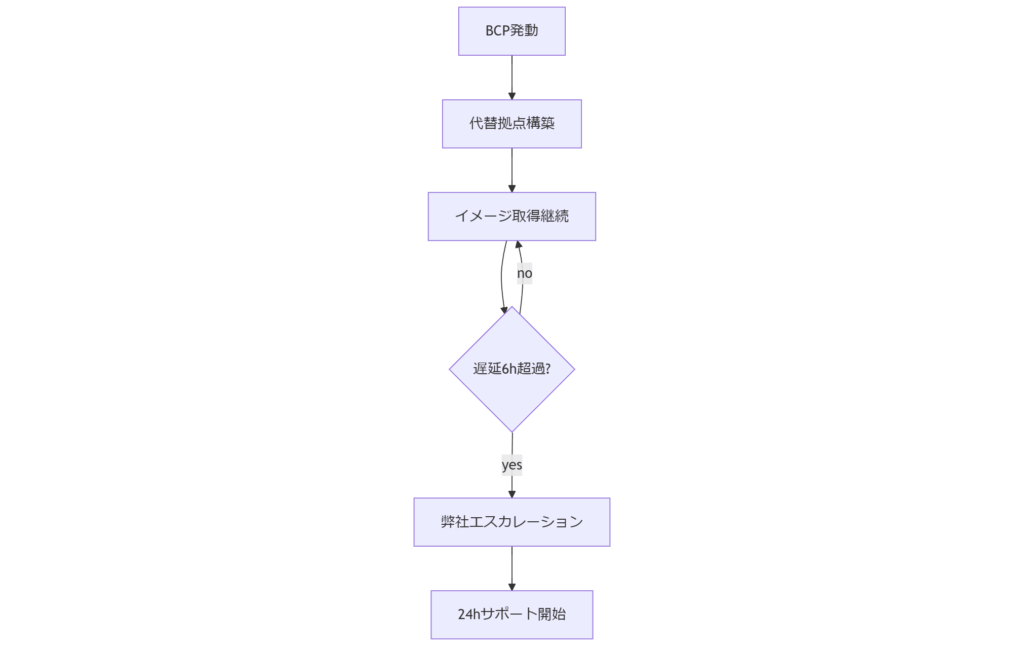
災害や大規模インシデント時にも、証拠保全活動を中断せず継続するため、BCP(事業継続計画)と専門家エスカレーションの手順が重要です。本章では、内閣府「事業継続ガイドライン」に準拠して、BCP発動から弊社へのエスカレーションまでのフローを解説します。BCP発動後の証拠保全手順
BCP発動時は、まず①物理的安全確保、②代替拠点でのイメージ取得環境構築、③オンライン/オフライン両面でのログ収集体制継続を同時並行で開始します。特に代替拠点のネットワーク隔離を事前に定義しておくことが、混乱時の対応スピードを左右します。エスカレーションの判断基準と連携先
自社対応限界を超えた場合、早期に弊社フォレンジック専門チームへエスカレーションすることで、24時間体制のサポートと最新技術の活用が可能です。判断基準は「取得遅延」「ハードウェア故障」「法的対応要件変更」の三点で、いずれか発生時点でエスカレーションを推奨します。 表10 BCPとエスカレーションフロー比較| フェーズ | 主な作業 | エスカレーション条件 |
|---|---|---|
| 通常時 | オンプレ証拠保全 | ― |
| 災害発生 | 代替拠点構築・イメージ取得 | 拠点障害・ネットワーク断 |
| 取得遅延 | ログバックアップ継続 | 6時間以上遅延 |
| 技術限界 | 弊社専門チーム連携 | 取得手法不具合全般 |
[出典:内閣府『事業継続ガイドライン』2021年 https://www.bousai.go.jp/taisaku/keikaku/index.html]