・短時間で多発しているか、単発・散発か。
・同じDIMM/同じチャネル/同じソケットに偏っているか。
・発生時刻に、OS再起動/カーネルパニック/アプリ例外/DB異常が重なっていないか。
・ダンプ/コア/クラッシュログが既に取れているか(再現の材料になるか)。
# Linux(例): RAS/ECC 近辺のログを時系列でまとめる journalctl -k --since "YYYY-MM-DD HH:MM" --until "YYYY-MM-DD HH:MM" | egrep -i "mce|ecc|edac|ras|memory|hardware error" BMC/SEL(例): 可能なら同時刻のSELを保存(環境によりコマンドは異なります) ipmitool sel elist
# Linux(例): 物理DIMMの手掛かり(DMI/EDAC/rasdaemon の範囲で) dmidecode -t memory | sed -n '1,220p' dmesg -T | egrep -i "EDAC|ecc|mce|hardware error" | tail -n 200 交換前に「いつ・どこに偏るか」を記録しておく(DIMM位置、チャネル、症状の再現性)
# Linux(例): クラッシュやMCE周辺を抽出
journalctl -b -1 -k | egrep -i "mce|hardware error|panic|oom|segfault"
coredumpctl list | head -n 30
Windows(例): 直近の致命イベントを確認(管理者 PowerShell)
Get-WinEvent -LogName System -MaxEvents 50 | ?{ $_.LevelDisplayName -in @("Critical","Error") } | Select TimeCreated,Id,ProviderName,Message
# 例:温度・電源・ハードウェアイベントの相関を確認(環境により取得方法は異なります) BMCのセンサー、SEL、ハードウェア監視の時系列を「ECC発生時刻」に合わせて保存 例:計画停止でメモリテストを実施(本番稼働中に長時間の負荷試験は避ける) memtest 等は保守窓で実施
# Linux(例): 同時刻の異常をざっと拾う dmesg -T | tail -n 300 journalctl -p err..alert --since "YYYY-MM-DD HH:MM" --until "YYYY-MM-DD HH:MM" ストレージ/ネットワーク/PCIeのエラーが重なると、二次障害の疑いが上がる 例: "I/O error", "EXT4-fs error", "nvme", "AER", "link down"
・ログを消してから原因切り分けを始め、偏り(DIMM位置・時刻・頻度)の根拠が失われる。
・交換対象を取り違え、再発のたびに部品を増やして調査が長期化する。
・設定変更やファーム更新をまとめて行い、どれが効いたか分からず戻せなくなる。
・Uncorrectedの後に、どのプロセスが壊れたか追い切れない。
・DIMM位置(スロット/チャネル)の特定に自信がない。
・ダンプはあるが、再現の軸(何を証明するか)で迷ったら。
・仮想基盤で、ホスト/ゲストどちらの責任切り分けか迷ったら。
・共有ストレージ、コンテナ、本番データ、監査要件が絡む場合は、無理に権限を触る前に相談すると早く収束しやすいです。
・ログ保全の範囲(SEL/イベントログ/コア/DBログ)をどこまで取るか迷ったら。
・再発を止めたいが、最小変更で進める順番が決めきれない。
もくじ
- 「また落ちた…」原因不明の再起動の裏にあるECCメモリエラーという現実
- 触る前にやる:ログ・ダンプ・時刻同期を“壊さず”確保する初動
- ECCの基礎:Correctable / Uncorrectable の違いと、どこまで信用できるか
- ログの入口:Linux(EDAC/MCE/rasdaemon)とWindows(WHEA)、BMC/IPMIの役割分担
- 「いつ・どこで・何回」:DIMM/チャネル/ランク/物理アドレスへ落とし込む手順
- パターンで読む:1bit反転・多ビット・バースト・温度依存から故障モードを推定する
- データ再現の考え方:ビット反転推定/冗長性/整合性チェックで“壊れ方”を固定する
- 実践:ダンプ採取→差分抽出→検証→再計算(ファイル/DB/ログ別の再現アプローチ)
- 判断基準:交換・隔離・再投入、そしてscrubbing/BIOS設定/電源・温度で再発を潰す
- 帰結:ECCログは“責任追跡の武器”になる——復旧と再発防止を同じ運用で回す
【注意】 ECCメモリエラーが疑われる環境で自己判断の修理・復旧作業(設定変更、検証ツールの長時間実行、強制再起動の反復など)を行うと、データ破損や証跡欠落が拡大し、原因特定と再現性の確保が難しくなることがあります。まずは通電や変更を最小化し、必要なログとダンプの確保に限定したうえで、個別案件は株式会社情報工学研究所のような専門事業者へ相談してください。
第1章:「また落ちた…」をダメージコントロールする——ECCログは“原因”ではなく“入口”
「夜間に勝手に再起動した」「たまにアプリが落ちる」「CRCが合わない」——現場は“症状”だけが積み上がり、説明責任だけが増えていきます。しかもメモリは、ディスクやネットワークと違って“目に見える壊れ方”をしません。だからこそ、最初にやるべきは原因究明の前に被害最小化(ノイズカット)です。
ECC(Error-Correcting Code)は「壊れたのに動いてしまう」を抑え込む仕組みですが、同時に「壊れ方のログ」を残します。ただしECCログ自体が“すべての真実”ではありません。ログは入口であり、再現・検証・切り分けのための観測点です。最初の30秒は、原因を断定する時間ではなく、後で断定できる材料を取りこぼさない時間です。
冒頭30秒:症状 → 取るべき行動(まず“歯止め”をかける)
| 症状(よくある入口) | 取るべき行動(まず安全側) |
|---|---|
| Correctable ECC(訂正可能)が短時間に増える | 負荷と温度を急に上げない/ログ採取を優先(OSログ+BMC/SEL)/同一DIMMに偏るかを確認し、運用上の“クールダウン”計画を立てる |
| Uncorrectable ECC(訂正不能)やWHEA fatal/MCEが出る | 書込みを伴う作業を止める/直近の変更を固定(設定変更しない)/ダンプ・イベントログ・SEL確保後、早期に専門家へ相談(稼働継続は損失拡大になり得る) |
| 突然の再起動・カーネルパニック・BSOD | 再起動を繰り返さない/再現試験を走らせない/時刻情報(NTP/タイムゾーン)を記録し、直前ログの“取り逃し”を防ぐ |
| アプリやDBの整合性エラー(CRC不一致、ページ破損、WAL異常など) | 整合性チェックは“追加の破壊”になり得るため段階的に/まず現状のスナップショット・バックアップ取得可否を検討し、影響範囲の封じ込め(漏れ止め)を優先 |
| BMC(iDRAC/iLO等)にMemory/ECC関連アラートがある | OSだけで判断しない/SEL/System Event Logをエクスポート/DIMMスロット表記をサーバ型番の命名規則で揃える(後で物理特定できる形に) |
「心の会話」:現場が最初に抱える疑いは健全
「また新しい切り分け手順?どうせ運用が増えるだけじゃないのって、正直思いますよね。」
「“原因はメモリです”って言い切れたら楽だけど、ハードとソフトの境界ってそんなに単純じゃない。」
その感情は自然です。ECCは“メモリだけ”の話に見えますが、実際は温度・電源・マザーボード配線・CPU内メモリコントローラ・ファームウェア・OSのログ経路まで絡みます。ここで雑に断定すると、後で説明も復旧も苦しくなります。
このブログのゴール:復旧と説明責任を同時に成立させる
本記事は「修理手順」を増やすためではなく、読者が具体的な案件・契約・システム構成で悩んだときに、判断の材料を整理し、株式会社情報工学研究所への相談・依頼を検討できる状態に持っていくことを目的にします。一般論でできる範囲と、個別案件で専門家が必要になる境界を、最初から明確にします。
今すぐ相談すべき条件(依頼判断の“ストッパー”)
- Uncorrectable ECC、WHEA fatal、Machine Check Exception、カーネルパニック/BSODが発生している
- 業務データ(DB、仮想基盤、ストレージ上の重要ボリューム)で整合性エラーが出始めた
- ログが散逸しやすい構成(再起動で上書き、短い保持期間、集中ログ未整備)で、証跡を残し切れていない
- 可用性要件が高く「止めて調べる」が難しい(止め方自体が設計課題)
相談導線:問い合わせフォーム(https://jouhou.main.jp/?page_id=26983)/電話(0120-838-831)
第2章:触る前にやる——ログ・ダンプ・時刻を揃えて“証跡の収束”を作る初動
ECCメモリログから「エラー発生時のデータ再現」を狙うなら、最初に必要なのは“エラーの瞬間”そのものではなく、その前後関係です。ところが現実には、再起動やローテーションでログが消えます。ここで必要なのは、派手な解析よりも地味な収束(情報を一箇所に集めて欠損を減らす)です。
初動の原則:変更を増やさず、観測点を増やす
- 設定変更やファーム更新は後回し(原因の混入を防ぐ)
- 再現試験は後回し(追加のエラーで状態を変えない)
- 「何が起きたか」より先に「何を残したか」を揃える
時刻の整合:ログ同士を結びつける“接着剤”
ECC系の追跡は、OSログ(dmesg/journal、イベントログ)とBMCログ(SEL)を突き合わせます。ここで時刻がずれていると、同じ事象を別事象として扱ってしまいます。最初に以下を記録します。
- OSの現在時刻/タイムゾーン/NTP同期状態
- 再起動が絡む場合は boot id(Linuxなら /proc/sys/kernel/random/boot_id など)
- BMC側の時刻(SELのタイムスタンプがOSと一致するとは限らない)
Linuxで最低限確保したいログ(代表例)
ディストリビューションや構成で異なりますが、一般に次を確保すると後工程が安定します。
- dmesg(または journalctl -k 相当のカーネルログ)
- systemd journal(journalctl、保持期間と永続化設定も把握)
- EDAC(ECC補正の統計・デバイス情報):/sys/devices/system/edac/ など
- MCE(Machine Check)関連ログ(CPU/メモリコントローラ由来の可能性)
- rasdaemon等のRasイベント集約ログ(導入済みの場合)
“集めるだけ”が目的なので、解析ツールの追加インストールは慎重にします。導入作業自体が変更履歴になり得るためです。インストールが必要な場合は、影響の小さい順に、実行ログも含めて記録します。
Windowsで最低限確保したいログ(代表例)
- イベントビューア:System ログ(WHEA-Logger、Kernel-Power など)
- Application ログ(DBやアプリの整合性エラー、例外)
- クラッシュダンプ(設定されている場合。種類と保存先を確認)
WindowsのWHEA(Windows Hardware Error Architecture)は、ハードウェアエラーの報告経路として標準です。ECC由来のイベントもここに出ることがありますが、イベントIDや詳細は環境で差が出ます。重要なのは「イベント単体の名前」より「発生頻度と時系列」です。
BMC(iDRAC/iLO等)で確保したいもの
- System Event Log(SEL)のエクスポート
- メモリ構成情報(DIMMスロットの命名、搭載容量、交換履歴の手掛かり)
- 温度・電圧・ファンの異常履歴(メモリ単体故障に見えて電源・温度が起点のことがある)
初動で“やりがち”な失敗と、やらない判断
- メモリテストを長時間回して症状を増やす(状態を変え、ログを増やし、切り分けを難しくする)
- BIOS/ファーム更新を先に当てて事象の再現性を失う(説明責任が難しくなる)
- ログを一部だけ見て断定する(OS側とBMC側の片方だけで結論を出す)
現場の本音として「すぐ直したい」「早く落ち着かせたい(クールオフしたい)」は当然です。ただ、ECC絡みは“直す”より先に“残す”が勝ちます。ここで残せた証跡が、後でデータ再現や影響範囲推定の精度を上げます。
依頼判断の現実:一般論の限界を超えるポイント
ログの取り方が分かっても、次に立ちはだかるのは「そのログが示す物理位置が、実データ破損とどう結びつくか」です。仮想化、暗号化、圧縮、DBのページ管理、ファイルシステムのキャッシュなどが絡むと、一般論だけでは“この破損はここから来た”を安全に言い切れません。具体案件で迷った時点で、株式会社情報工学研究所のような専門家に相談する方が、結果的に損失・工数の歯止めになります。
相談導線:問い合わせフォーム(https://jouhou.main.jp/?page_id=26983)/電話(0120-838-831)
第3章:ECCの基礎——Correctable/Uncorrectableの意味と、ログの“信用できる範囲”
ECCは、メモリ上のビット反転を検出し、一定範囲なら訂正して処理を続行する仕組みです。一般的なサーバ向けでは、1bitの誤り訂正+2bitの誤り検出(実装や世代で差はあります)が基本にあります。ここで重要なのは、ECCが「壊れていない」証明ではなく、「壊れ方を抑え込み、記録した」ことを示す点です。
Correctable Error:静かに積み上がる“予兆”
Correctable(訂正可能)エラーは、ECCが訂正して処理を継続できた状態を指します。つまりアプリケーション視点では“何も起きていない”ように見えることがあります。一方で、短時間に急増したり、特定DIMMに偏ったりする場合は、物理劣化・温度・電源品質・接触不良などの兆候である可能性が上がります。
- 短時間に増える:温度上昇、電源変動、負荷変動との相関を疑う
- 特定スロットに偏る:DIMM自体、ソケット、チャネル周辺の問題を疑う
- 全体に散る:環境要因(電源、筐体温度)やプラットフォーム側の可能性も考える
Uncorrectable Error:継続運用が“被害拡大”に直結し得る
Uncorrectable(訂正不能)エラーは、訂正しきれず処理継続が危険になった状態です。OSが停止する、再起動する、WHEA fatalやMCEとして報告される、といった形になりやすく、業務データへの影響も無視できません。ここで「とりあえず動いてるから」と稼働を続けると、ディスク上のデータが“壊れた状態で正”として更新されていくリスクがあります。これは復旧を難しくする方向に働きます。
ECCログの“信用できる範囲”を整理する
ECCログは強力ですが、万能ではありません。ログが示すのは、主に「検出・訂正/検出不能」の事実と、その周辺メタ情報(物理位置、種別、回数、時刻)です。次のように、ログで言えること/言えないことを分けます。
| ECCログで言えること(比較的強い) | ECCログだけでは言い切れないこと(追加検証が必要) |
|---|---|
| 訂正可能/不能の種別、発生時刻、増加傾向 | アプリやDBの特定の破損が“そのエラー1回”で起きた断定 |
| 偏り(特定DIMM/チャネル等) | 原因がDIMM単体か、メモリコントローラ/基板/電源/温度要因かの断定 |
| 再起動や停止とエラーの時系列関係 | 暗号化・圧縮・仮想化・キャッシュを跨いだ“どのデータがどう壊れたか”の復元 |
「腹落ち」ポイント:再現とは“推定→検証→確定”の繰り返し
ECCログを見て「ビットが反転したっぽい」と言うのは簡単ですが、実務で必要なのはそこから先です。データ再現は、(1)どの領域で(2)どの種類の誤りが(3)どの頻度で起きたかを材料に、影響範囲を推定し、整合性チェックや冗長情報(CRC、チェックサム、WAL、パリティ等)で検証して、初めて“確定”に近づきます。ここを飛ばすと、復旧も説明も不安定になります。
次章以降で、Linux/Windows/BMCの具体的なログ経路と、DIMM・アドレス・データ構造へ落とし込む方法を整理し、「再現できる形」へつなげていきます。
第4章:ログの入口を揃える——Linux(EDAC/MCE/rasdaemon)とWindows(WHEA)、BMC/SELの役割分担
ECCメモリエラーの解析は「どのログを一次情報とし、どれを補助線にするか」で難易度が大きく変わります。OSログだけを見ていると、BMC(iDRAC/iLO等)に残っているハードウェアイベントを見落とします。逆にBMCだけに頼ると、アプリやファイルシステム側の整合性エラーと時系列が結びつきません。ここでは役割分担を固定し、情報を“収束”させます。
役割分担の基本(一次→補助の順で読む)
| 観測点 | 強い点 | 弱い点(補助が必要) |
|---|---|---|
| Linux: EDAC | 訂正可能エラーのカウント、メモリコントローラ/チャネル単位の傾向が掴める | DIMM特定の粒度はプラットフォーム依存、アプリ破損との直接因果は別検証 |
| Linux: MCE(Machine Check) | 訂正不能相当や深刻なハードエラーがOSへ上がる経路、アドレス等の手掛かりが残ることがある | ログ形式・項目はCPU世代/ファーム/カーネル設定で差がある |
| Linux: rasdaemon等 | Rasイベントを集約し、後で検索しやすい形にできる | 導入状況に依存(未導入なら存在しない) |
| Windows: WHEA | ハードウェアエラーの標準報告経路、致命的エラーとの対応が取りやすい | DIMM位置情報は機種/OEM実装で差、詳細はイベント拡張情報に依存 |
| BMC: SEL/System Event Log | OSが落ちても残りやすい、メモリ交換・温度・電源など“筐体側”の事実が出る | 時刻ズレや表記揺れが起きやすい(OSログとの突合が必要) |
Linux側:EDAC/MCEを「後で突合できる形」で確保する
Linuxでは、EDACが訂正可能エラーの傾向を掴む入口になります。sysfs経由でカウンタが見える環境も多く、少なくとも「増えているか」「偏っているか」の判断材料になります。MCEは、CPUが検出したハードウェア例外がOSへ伝達される経路で、致命的な系統のエラーで手掛かりになることがあります。
重要なのは、ログを“読む”前に“突合できる単位”で保存することです。例えば次の要素が揃うと、後工程(第5章以降)のマッピングが安定します。
- 発生時刻(OS時刻)と、可能ならブート単位の識別(再起動で連続性が切れるため)
- エラー種別(訂正可能/不能、メモリ関連か、その他バス/キャッシュ等か)
- 出力に含まれる識別子(メモリコントローラID、チャネル、DIMMラベル、アドレス等)
- 同時刻近辺の温度・電圧・負荷変動の痕跡(BMC側と併せる)
Windows側:WHEAを「イベントの束」で扱う
Windowsでは、WHEA-Loggerが中心です。ここで大事なのは、イベント単体の名称やイベントIDを暗記することではなく、同じ時間帯に出るイベント群(Kernel-Power、BugCheck、ストレージやアプリ側の整合性エラー)とセットで扱うことです。
WHEAイベントの詳細には、エラー種別や、環境によっては物理アドレス、デバイス/コンポーネント情報、エラーレコードの断片が含まれます。ただしDIMMスロット特定が常に出るわけではなく、OEMの実装やファームウェアの提供情報に依存します。したがって、WHEAだけで物理特定まで完結させようとせず、BMCログや機種の命名規則と突合して“確度”を上げます。
BMC側:SELを「物理の事実」として取り込む
BMCのSELは、OSが落ちても残りやすい一方で、表記が抽象的だったり、時刻がズレていたりします。それでも、次の情報は“物理の事実”として強い材料になります。
- 「Memory/ECC」系のイベントが、どのスロット表記で出ているか
- 発生直前の温度上昇、ファン異常、電圧異常、電源系イベント
- 同日に発生した他のハードイベント(PCIe、ストレージ、電源喪失等)
ここでやるべきことは、OSログ側の時刻とBMC側の時刻を突合し、同じ事象を同じ時系列として並べ替えられる状態を作ることです。時刻のズレがあるなら、そのズレ量も記録し、以後の解析では補正前提で扱います。
「心の会話」:ログが多いほど混乱する、は普通
「ログは山ほどあるけど、結局どれが根っこなの?」
その感覚は自然です。だからこそ、入口を役割分担して“読む順番”を固定します。OS(EDAC/MCE/WHEA)で“OSが見た事実”を押さえ、BMC(SEL)で“筐体が見た事実”を押さえ、最後にアプリやストレージの整合性ログを“影響”として重ねます。この順番が、後のデータ再現(推定→検証→確定)を支えます。
次章では、これらのログに出てくる識別子を、DIMM/チャネル/ランク/物理アドレスへ落とし込み、交換・隔離・再現判断に使える形へ変換します。
第5章:「いつ・どこで・何回」を固定する——DIMM/チャネル/ランク/物理アドレスへの落とし込み
ECC解析が“作業”になる瞬間は、ログに出てくる曖昧な表現を、交換や隔離に使える単位へ落とし込めたときです。「メモリエラーっぽい」では意思決定になりません。「どのDIMMが」「どの時間帯に」「どれくらいの頻度で」起きたのかを固定し、説明と対処が同じ表を見て進む状態を作ります。
まず固定する4点セット(この順で確定させる)
- 時間:発生の時系列(単発か、継続か、急増か)
- 場所:物理位置(サーバのDIMMスロット表記、チャネル)
- 回数:訂正可能/不能の回数、増加率
- 影響:同時刻のOS停止・再起動・アプリ整合性エラーの有無
表記ゆれを潰す:DIMM命名を“機種の言葉”に合わせる
落とし込みの最大の敵は、表記ゆれです。OSが「mc0/csrow1/ch0」などの抽象的表現を使い、BMCが「DIMM_A1」のような物理スロット表記を使い、保守員は「CPU1側の2番」のように口頭で言う、といったズレが起きます。ここは最初に、機種のメモリスロット命名(サービスマニュアルや筐体ラベル)に寄せて統一します。
統一のために、最低限次の対応表を作ります(紙でもテキストでもよいですが、更新履歴が残る形が望ましい)。
| BMC表記(例) | OS表記(例) | 物理位置メモ |
|---|---|---|
| DIMM_A1 | mc0/ch0/… | CPU1側・チャネル0・スロット1(機種の命名規則に合わせて記載) |
| DIMM_B1 | mc0/ch1/… | CPU1側・チャネル1・スロット1 |
この表があると、以後の議論で「場所」がブレなくなります。特に複数台・複数ラック・リモート作業が絡むと、ここが歯止めになります。
物理アドレスが出たときの扱い:強いが、そのままデータ位置ではない
MCEやWHEAの詳細に物理アドレス(またはそれに近い情報)が出る場合があります。これは強い手掛かりですが、注意点があります。物理アドレスは、OSやアプリが扱うファイル/ページの位置と1対1で結びつくとは限りません。理由は次の通りです。
- 仮想化:ゲストOSのアドレスはホストで再配置される
- 暗号化/圧縮:ディスク上の配置とメモリ上の展開は一致しない
- キャッシュ:ファイルの内容はページキャッシュ等で別の形で滞在する
- アプリ内部構造:DBは論理ページ/バッファ管理があり、ファイルオフセットと一体ではない
したがって、物理アドレスは「影響範囲の推定」や「同一箇所に集中していないか」を見る材料として使い、データ再現の確定には、別の検証(チェックサム、ログ整合、冗長情報)を組み合わせます。
回数の見方:絶対値より“増加率”と“偏り”
訂正可能エラーの回数は、環境やログ保持の仕方で見え方が変わります。重要なのは絶対値の大小だけで判断しないことです。見るべきは増加率と偏りです。
- 増加率:一定期間あたりの増え方が急になっていないか
- 偏り:特定DIMM/特定チャネルに集中していないか
- 相関:温度、負荷、特定バッチ処理、バックアップ、GC等と同時に増えないか
影響の固定:OS停止・再起動・整合性エラーを同じタイムラインに置く
「どこで起きたか」だけでは足りません。業務上の意思決定は「影響が出ているか」で変わります。次のようなイベントを、同じ時系列に並べます。
- OS停止/再起動(Kernel-Power、panic、BugCheckなど)
- ストレージ/ファイルシステムの警告(I/Oエラー、ジャーナル再生、CRC不一致など)
- DBの整合性エラー(ページ破損、WAL/redoの異常、チェックサム不一致など)
ここまで揃うと、「DIMM交換を先にするか」「稼働を落としてでもスナップショット/バックアップを優先するか」「再現検証をどこまでやるか」の判断が、一般論ではなく案件として語れるようになります。案件の制約(止められない、契約、SLA、監査、改変禁止など)がある場合は、ここから先は一般論だけで安全に進めにくくなります。
次章では、ログの出方の“パターン”から、故障モード(1bit、複数bit、バースト、温度依存など)を推定し、交換・隔離・再投入の優先順位を作ります。
第6章:パターンで読む——1bit反転・多ビット・バースト・温度依存から故障モードを推定する
ECCログを眺めていると、同じ「メモリエラー」でも起き方が違います。起き方の違いは、対処の優先順位を変えます。ここで狙うのは、細かな断定ではなく「誤った対処を選ばないための歯止め」です。例えば、温度相関が強いのにDIMMだけを交換して終わらせる、あるいは訂正不能が出ているのに“様子見”に寄せる、といった判断ミスを避けます。
よくあるパターンと示唆(断定ではなく優先度づけ)
| ログのパターン | 示唆(可能性が上がる方向) | 次の一手(被害最小化の観点) |
|---|---|---|
| 訂正可能が同一DIMMに偏り、ゆっくり増える | DIMMの劣化、接触、局所的要因の可能性 | 交換候補を絞る/交換前にログ保持と時系列固定/温度・電圧も併せて確認 |
| 短時間に急増し、負荷や温度変化と同期 | 温度・電源品質・冷却不足など環境要因の可能性 | 負荷をクールダウン/冷却・電源イベントをBMCで確認/原因混入を避けて段階的に切り分け |
| 訂正不能や致命的イベントが発生、OS停止や再起動を伴う | 深刻度が高い(稼働継続が損失拡大になり得る) | 変更・書込みを抑え、証跡確保を優先/復旧方針を早期に固める |
| 複数DIMM/複数チャネルに散発、同時期に他のハードイベントもある | プラットフォーム側(電源、基板、メモリコントローラ等)も視野 | BMCのSELで全体の異常履歴を確認/“DIMMだけ”に閉じない |
1bitと多ビット:意味の違い(一般的な捉え方)
一般に、1bitの訂正可能エラーが散発する段階は「予兆」として扱われやすい一方、複数bitが絡む訂正不能や致命的イベントは、停止やデータ破損リスクと結びつきやすく、優先順位が上がります。ただし、どのビット幅まで訂正するか、どう分類されるかは、プラットフォームと実装に依存します。ログに出ている分類を、その環境での一次情報として扱い、外部の一般例に無理に当てはめません。
バースト(まとまって出る)と散発(点で出る):切り分けの考え方
まとまって出るエラーは、イベント(温度上昇、ファン制御、電源瞬断、特定バッチ処理)と同期していることがあります。散発は、局所的な劣化や接触などの可能性があります。ここで重要なのは、「疑い」を絞るために追加の変更を増やさないことです。
- バーストが疑われる場合:同時刻のBMC温度/電源イベントと突合し、環境要因の有無を先に確認
- 散発で偏りが強い場合:DIMM交換候補を絞るが、交換前に必ず現状ログを確保し、交換が“原因混入”にならないよう履歴を残す
「心の会話」:原因を1本にしたくなるが、現場は複合要因が普通
「DIMM替えれば終わる話なら、もう替えて終わりにしたい。」
その気持ちは当然です。ただ、実務ではDIMMが壊れたのか、冷却や電源が壊しにいっているのか、あるいはプラットフォーム側の問題が表面化しているのか、という複合要因が起きます。ここで早い段階から“1本化”してしまうと、再発したときに説明が苦しくなります。パターン読みは、断定のためではなく、選択肢の優先順位を付けるために使います。
ここまでの帰結:次に必要なのは「データ再現」の設計図
パターンを掴めても、読者が本当に困るのは「データが壊れたのか」「壊れたならどこまで戻せるのか」です。次章以降では、ビット反転の推定を“実データ”へ繋げるときの原則(冗長情報、整合性チェック、ログの再計算)を整理し、ファイル/DB/ログそれぞれで、再現性の取り方を具体化します。
第7章:データ再現の考え方——ビット反転推定/冗長性/整合性チェックで“壊れ方”を固定する
ECCログは「メモリ上で誤りが起きた可能性」を示しますが、読者が知りたいのは「その結果、データがどう壊れたか」「どこまで戻せるか」です。ここでの鍵は、ビット反転を“想像”で終わらせず、冗長情報と整合性チェックで壊れ方を固定することです。推定→検証→確定の順番を守ると、現場の説明責任と復旧作業が同じ地図を共有できます。
再現の3本柱:推定・検証・確定
| 段階 | 狙い | 使う材料 |
|---|---|---|
| 推定 | どの範囲が怪しいかを絞る | ECCログの偏り、時刻、(あれば)物理アドレス、影響ログ |
| 検証 | 怪しい範囲に整合性不一致があるか確認 | チェックサム/CRC、DBページ検査、ログ整合、アプリの検証機構 |
| 確定 | 復旧手段(戻す/再計算/再生成)を決める | 冗長情報(WAL/redo、パリティ、レプリカ、スナップショット)、再計算可能性 |
冗長性があるデータは「戻す・再計算する」が主戦場
データ再現で最も強いのは、冗長性が組み込まれた仕組みです。ファイルシステムのチェックサム、DBのWAL/redoログ、分散ストレージの複製、アプリの二重化された検証値などがあれば、ビット反転を“推測して直す”のではなく、正しい状態へ戻す/再計算するルートを優先できます。
- レプリカがある:差分を比較し、どちらが正しいかを整合性で判断する
- WAL/redoがある:破損ページを戻し、ログで再適用して整合性を回復する
- チェックサムがある:不一致箇所を特定し、復旧対象を狭める
ここでの要点は、復旧を急いで“検証値そのもの”を壊さないことです。チェックサムを再計算して上書きすると、後で追跡できなくなります。まずは現状を保存し、検証はコピー上で行う方針が安全側になります。
冗長性が薄いデータは「影響範囲の最小化」が鍵
冗長性が弱い(または無い)データでは、すべてを完全に戻すことが難しくなります。その場合は、影響範囲を最小化し、業務として許容できる形に収束させるのが現実解になります。たとえば、ログや一時データは“完全”を追うより、欠損の位置と範囲を明確にし、監査や運用に耐える説明へつなげます。
- 欠損があることを確定し、範囲を特定する(いつからいつまで、どのテーブル/ファイルか)
- 再生成できるものは再生成(キャッシュ、サマリ、派生データ)
- 再生成できないものは復元可能性を評価(バックアップ、外部送信ログ、アーカイブ)
ビット反転推定を“作業”にする:候補を増やしすぎない
ECCログが示す誤りの情報は、環境によって粒度が異なります。粒度が粗いと、推定の候補範囲が広がります。ここでやりがちな失敗は、候補範囲を広げたまま手当たり次第に検証を走らせ、システムへの負荷や追加の書込みを増やしてしまうことです。推定が粗いほど、検証は“狭い順”に進めます。
- 影響が明確に疑われる領域(直後にエラーが出たDBや特定バッチ)
- 業務影響が大きい領域(売上、認証、課金、監査ログ等)
- 再生成が難しい領域(ユーザ投稿、証跡、契約関連)
「心の会話」:直せるかどうかより、まず“説明できる状態”が欲しい
「完璧に戻せないなら、せめて“何が壊れたか”だけでも言えるようにしたい。」
その感覚は現場にとって正しいです。再現は、完全復旧だけを意味しません。影響範囲、欠損の位置、戻せる範囲、戻せない範囲を固定し、ステークホルダーへ説明できる形にすること自体が、損失・炎上・二次被害への歯止めになります。
次章への伏線:ファイル/DB/ログで“再現の勝ち筋”は違う
同じECC由来の不整合でも、ファイル(静的データ)、DB(ページ管理とログ)、運用ログ(追記型)では、再現方法が異なります。次章では、ダンプ採取→差分抽出→検証→再計算という流れを、対象別に分解して実践に落とします。
第8章:実践——ダンプ採取→差分抽出→検証→再計算(ファイル/DB/ログ別の再現アプローチ)
ここからは、再現を実務として進めるための型を示します。ポイントは、解析を“やった感”で終わらせず、成果物(証跡・差分・検証結果・復旧判断)を残すことです。環境や制約で具体手順は変わりますが、骨格は共通です。
共通の型:4ステップを必ず分ける
- ダンプ採取:現状のスナップショットを確保し、以後の検証はコピーで行う
- 差分抽出:いつから壊れ始めたか、どこが変わったかを切り出す
- 検証:整合性チェックで不一致箇所を確定する
- 再計算:冗長情報やログから正しい状態へ戻す、または再生成する
ファイル(静的データ)の場合:チェックサムと比較が強い
静的なファイル(設定ファイル、バイナリ、成果物、アーカイブ等)は、比較とチェックサムが効きます。複製(バックアップ、アーティファクト保管、別ノードのコピー)があるなら、差分比較で壊れた箇所の特定がしやすくなります。
- 同一ファイルの複製を集め、ハッシュやサイズ、更新時刻でグルーピングする
- 一致しないグループがある場合、差分を抽出し、破損の範囲を固定する
- 正しい版が特定できるなら、その版へ戻す(戻せない場合は影響範囲を明示する)
ここで重要なのは、破損が疑われるファイルをその場で上書きしないことです。戻す場合でも、現状の退避と比較結果を残し、後から説明できる形にします。
DBの場合:ページとログの二層構造で考える
DBは、ファイルの集合でありながら、内部はページ管理とログで成り立っています。ECC由来の不整合がDBで顕在化すると、ページ破損やチェックサム不一致として出ることがあります。ここでの勝ち筋は、破損ページを“推測で修正”するより、ログやレプリカ、バックアップを使って正しい状態へ戻すことです。
| 材料 | 使い方 |
|---|---|
| レプリカ/スタンバイ | 差分比較で破損側を特定し、正しい側を基準に復旧計画を立てる |
| バックアップ | 壊れる前の状態へ戻し、ログで追いかけて整合性を回復する |
| WAL/redo等のログ | 整合性を保つための履歴。復旧の“再計算”に使う |
| DB内チェックサム | どのページが壊れたかの確定材料(対象を狭める) |
DBは止められない案件が多いため、検証をどの環境で行うか(本番でやるか、複製でやるか)自体が重要な設計になります。SLAや契約条件が絡む場合、一般論で安全な線引きが難しくなるため、早い段階で専門家の関与を検討する方が合理的です。
運用ログ(追記型)の場合:欠損範囲の確定が価値になる
運用ログは追記型が多く、破損があってもサービスが動き続けることがあります。その場合は、完全復旧よりも「欠損範囲の確定」と「外部の参照点(別システムのログ)」で補完できるかが焦点になります。
- 欠損の開始点と終端を、時刻と行番号/オフセットで固定する
- 別経路のログ(LB、WAF、監視、外形監視、クラウド側ログ)と突合する
- 監査や説明に必要な粒度まで補完できるか判断する
差分抽出の実務:同時刻に“何が変わったか”を束で見る
ECCログの発生時刻に合わせて、次の変化を束ねると、影響範囲の推定が鋭くなります。
- OS再起動・プロセスクラッシュ
- DBやミドルウェアの例外
- ストレージI/Oのエラーや遅延
- 監視指標の異常(温度、電圧、訂正可能エラー増加、遅延)
束で見た結果「本当にメモリが根っこなのか」「環境要因が背後にあるのか」「データ破損はどの層で起きたのか」の見通しが立ちます。ここまで来ると、復旧判断が“感覚”ではなく、証跡と整合性に基づく判断になります。
終盤への伏線:復旧だけで終わらせず、再発防止の設計へ繋ぐ
データ再現は“過去を戻す”作業ですが、運用としては“次を起こさない”こととセットです。次章では、交換・隔離・再投入の判断基準と、scrubbingやBIOS設定、電源・温度といった再発要因への対策を、現場の意思決定として整理します。
第9章:判断基準——交換・隔離・再投入、そしてscrubbing/BIOS設定/電源・温度で再発を潰す
ECCの解析が一段落すると、最後に残るのは意思決定です。現場が求められるのは「原因を言い当てる」こと以上に、「次に同じ損失を出さない」ことです。ここでは、交換・隔離・再投入の判断を、ログの事実と運用制約(止められない、SLA、監査、夜間体制)に接続します。やるべきことを増やすためではなく、迷いどころに歯止めをかけるための章です。
判断の軸:深刻度×再現性×影響範囲
| 軸 | 見るポイント | 意思決定に効く理由 |
|---|---|---|
| 深刻度 | 訂正不能、致命的イベント、再起動/停止、DB整合性エラー | 稼働継続が損失拡大に直結し得るため、優先順位が上がる |
| 再現性 | 同一DIMM/チャネルへの偏り、一定条件での増加 | 交換・隔離の対象を絞れるほど、停止時間とリスクを下げられる |
| 影響範囲 | どのデータが影響を受けた可能性があるか、検証結果 | 復旧の手段(戻す/再計算/再生成)と説明責任の作り方が変わる |
交換・隔離・再投入の現実的な優先順位
一般に、ログが示す偏りが強いほど、DIMM交換やスロット入れ替えによる切り分けが効きます。一方、偏りが弱い・広範囲に散る・他のハードイベントが混ざる場合は、DIMM単体に閉じる判断が危険になります。現場で使いやすい優先順位の付け方を、次のように整理します。
- 訂正不能や致命的イベントが出た:書込みや変更を抑え、証跡とバックアップ確保を優先。交換判断は早いが、先に復旧方針を固める。
- 訂正可能が特定DIMMに偏る:交換候補を絞り、交換前後のログを比較して収束を確認。
- 温度・電源と相関して増える:冷却・電源品質の問題を先に潰さないと再発する。DIMM交換だけでは収束しない可能性を織り込む。
- 複数チャネルに散る/他イベントも混ざる:プラットフォーム全体(電源、基板、メモリコントローラ)を視野に、調査計画を立て直す。
scrubbingと“検出の設計”:訂正可能を放置しない運用へ
ECC環境では、訂正可能エラーを定期的に洗い出す仕組み(patrol scrub等)が使われることがあります。狙いは「気づかないうちに積み上がる誤り」を早期に表面化させ、運用で扱える粒度にすることです。ただし、どの設定が有効か、どの程度の負荷になるかは機種や設定で異なるため、いきなり本番に適用するのではなく、影響評価と段階導入が必要になります。
| 施策 | 狙い | 運用上の注意 |
|---|---|---|
| 監視としきい値(訂正可能の増加率) | “静かに悪化”を早期に拾う | 絶対値より増加率と偏り。しきい値は環境で調整が必要 |
| scrubbing/patrol scrub | 潜在エラーの顕在化と抑え込み | 負荷・性能影響の評価。ログの増え方が変わる点も織り込む |
| メモリ冗長機能(ミラー等) | 耐障害性を上げる | 容量や性能のトレードオフが大きい。契約/SLAに沿う設計が必要 |
電源・温度:DIMM交換だけで終わらせない
現場でよく起きるのは「DIMMを替えて一旦収束したが、負荷が上がる季節に再発する」ケースです。これは、DIMMが弱っていた可能性もありますが、背後に冷却不足や電源品質が残っていることもあります。BMCの温度・電圧イベントとECC増加の相関が見えたなら、対策の主軸に冷却・電源を含めます。
- 吸排気の詰まり、ファン制御、ラック内のホットスポット
- 電源冗長構成の片系運用、UPS、瞬断・電圧降下の履歴
- 筐体内温度の偏り(特定スロット側だけ温度が高い等)
依頼判断の“境界線”:一般論が危うくなる条件
ここまでの判断は、ログの確保と基本的な読み解きが前提です。しかし、次の条件が重なると、一般論で安全に判断しきれなくなります。
- 仮想基盤・クラスタ・分散DBなど、影響範囲が層を跨ぐ
- 暗号化・圧縮・重複排除などで、データの位置関係が単純でない
- 契約・監査要件で、変更や証跡の扱いに制約がある
- 止められない前提で、検証の実行場所(本番か複製か)が設計課題になる
この境界に入った時点で、復旧と再発防止を同時に進めるには、経験則だけでは足りません。迷いが出た段階で、株式会社情報工学研究所のような専門家へ相談し、損失・工数・説明責任をまとめて収束させる方が現実的です。
相談導線:問い合わせフォーム(https://jouhou.main.jp/?page_id=26983)/電話(0120-838-831)
第10章:帰結——ECCログは“責任追跡の武器”になる。復旧と再発防止を同じ運用で回す
ECCログの価値は「メモリが悪い」と言えることではありません。価値は、事実のタイムラインを作り、影響範囲を固定し、復旧判断を支え、再発防止の設計に繋げられることです。つまり、技術者が抱える「分かってくれない」「説明がつらい」という状況を、技術で落ち着かせる道具です。
現場が欲しいのは“正しさ”より“再現性のある説明”
ステークホルダーへの説明は、原因の断定より「何が起きたか」「何が確かで、何が未確定か」「何を根拠に、どの判断をしたか」が重要になります。ECC解析は、この説明を支える材料を提供します。
| 説明に必要な要素 | ECC解析で用意できる材料 |
|---|---|
| いつ起きたか | OSログとBMC/SELの突合タイムライン |
| どこで起きたか | DIMM/チャネル/スロットへの落とし込み、偏りの可視化 |
| 何が影響したか | 整合性エラー、差分、検証結果(不一致箇所の確定) |
| 何をしたか | 証跡確保、復旧方針、交換/隔離の履歴(前後比較) |
運用に落とす:一度きりの調査で終わらせない
復旧と再発防止を切り離すと、次の障害で同じ混乱が繰り返されます。ECCログは“運用の入力”として扱うと効果が出ます。例えば、訂正可能の増加率と偏りを監視し、一定の条件で点検・交換を計画する。BMCの温度・電源イベントと合わせて、季節変動や負荷イベントとの相関を取る。こうした仕組みは、障害をゼロにするためではなく、障害の損失を最小化するために機能します。
- 監視:訂正可能の増加率、偏り、致命的イベントの有無
- しきい値:環境の平常値を把握し、逸脱を検知する
- ランブック:ログ確保、突合、影響評価、相談判断の手順を固定する
「心の会話」:また増える運用が怖い、は普通
「監視増やすと、結局アラート対応が増えるだけじゃないの?」
その懸念は健全です。だから、アラートは“全部拾う”のではなく、意思決定に直結する形に絞ります。増加率と偏り、致命的イベントの有無、BMC側の温度・電源イベントとの相関。このセットだけでも、十分にダメージコントロールになります。
一般論の限界:最後に残るのは“その案件の制約”
どれだけ体系化しても、最後は案件の制約にぶつかります。止められない本番、契約や監査の要件、データの重要度、バックアップの設計、復旧許容時間。ここは一般論では埋まりません。判断を誤ると、復旧だけでなく説明責任や再発時の損失が膨らみます。
だからこそ、具体的な案件・契約・システム構成で悩んだ段階で、株式会社情報工学研究所のような専門家へ相談し、復旧と再発防止、説明責任まで含めて一気に収束させる選択肢を持つことが重要です。
相談導線:問い合わせフォーム(https://jouhou.main.jp/?page_id=26983)/電話(0120-838-831)
付録:現在のプログラム言語各種における注意点(ECC由来の不整合を“検出できる設計”に寄せる)
ECCが訂正してくれる世界でも、訂正不能や周辺要因が絡めば、アプリ層で不整合が顕在化します。言語ごとの罠は「壊れたときに、壊れ方が分かるか」です。ここでは“速く直す”より、“後で説明できる”設計に寄せる観点で整理します。
C / C++
- 未定義動作が多く、メモリ破損が起きると原因位置が飛びやすい。整合性チェック(CRC/チェックサム)や不変条件の検証をデータ境界に入れる。
- バッファ管理の境界が曖昧になりやすい。シリアライズ/デシリアライズは長さ検証とバージョン管理を必須にする。
Rust
- 安全領域は強いが、unsafeやFFIが入るとC/C++同様の破損リスクが生まれる。unsafe境界に検証(チェックサム、範囲、アラインメント)を集中させる。
- panicで落ちる設計は“落ち方が分かる”点で有利だが、本番でのログ確保と再現性(コンテキスト情報)を残す仕組みが必要。
Go
- ランタイム管理でメモリ安全性は上がるが、cgoや外部ライブラリで破損が混入し得る。境界データ(バイト列、構造体)に整合性検証を置く。
- エラーは値として扱えるため、破損検知時に“どの入力で壊れたか”を残す設計がしやすい。ログ相関IDを徹底すると復旧と説明が楽になる。
Java / Kotlin(JVM)
- 管理メモリで直接破損は起きにくいが、JNI/ネイティブ依存、ストレージ層、ネットワーク層の不整合は普通に起きる。永続化フォーマットにチェックサムやスキーマ検証を入れる。
- “例外で落ちる”のは悪ではなく、壊れた状態で進まないためのストッパーになり得る。例外時のダンプと周辺ログ(直前リクエスト、トランザクションID)を確実に残す。
C#(.NET)
- JVM同様に管理メモリは強いが、ネイティブ相互運用やドライバ/ミドル依存で不整合は起きる。外部境界の検証と、永続化データのチェックを重視する。
- 例外処理で握りつぶすと、壊れ方が分からなくなる。検出した不整合は“静かに無視”せず、監視とアラートに繋げる。
Python
- 本体は安全寄りだが、C拡張(NumPy等)や外部プロセス、バイナリI/Oで破損が混入し得る。重要データは読み込み時に検証(署名/チェックサム/スキーマ)を入れる。
- 例外とログで壊れ方を残しやすい反面、運用でログが散りやすい。相関ID、入力の要約、再現用の最小データを残す設計が効く。
JavaScript / TypeScript(Node.js含む)
- 型は実行時に消える(TSはコンパイル時)ため、入出力境界でスキーマ検証を入れないと破損や欠損が静かに伝播する。JSON等はスキーマ検証を標準化する。
- バイナリ(Buffer/TypedArray)を扱う箇所は、長さ・範囲・バージョンの検証が必須。ログには“どのバージョンのフォーマットか”を残す。
PHP
- 型のゆるさと暗黙変換で、破損データが“別の値”として通ってしまうことがある。入力の検証と、重要フィールドの整合性チェックを強める。
- ログと監視が分散しやすい。エラーの相関と、障害時に必要な証跡(リクエストID、ユーザ影響範囲)を固定する。
Ruby
- 動的型で柔軟だが、破損データが混ざると“静かに進む”ことがある。境界の検証(契約、スキーマ、チェックサム)を重視する。
- 例外が出たときの周辺情報(入力、処理段階)を残す仕組みが、復旧と説明に直結する。
Swift / Objective-C(主にクライアントや組込み寄り)
- 端末側の不整合はサーバ側ログだけでは追えない。クライアントイベントの相関と、送信データの検証(署名、リプレイ耐性)を入れる。
- Objective-Cやネイティブ境界が混ざる場合、破損がアプリ層で不定形に出ることがある。境界での検証とクラッシュログの確保が重要。
言語に共通する“壊れ方を分かるようにする”設計の要点
- 永続化データにはチェックサム/署名/スキーマ検証のいずれかを必ず入れる(検出できない破損が一番つらい)。
- ログは相関IDで束ねる(OS/BMC/アプリのタイムラインを結びやすくする)。
- 破損検知時は“静かに継続”しない(壊れた状態で正として更新されるのを防ぐ)。
具体案件では、言語の話だけでなく、暗号化・仮想化・バックアップ・監査・契約条件が絡み、一般論だけでは安全な判断が難しくなります。迷いが出た段階で、株式会社情報工学研究所への相談を選択肢に入れることで、復旧・再発防止・説明責任を同時に収束させやすくなります。
相談導線:問い合わせフォーム(https://jouhou.main.jp/?page_id=26983)/電話(0120-838-831)
・ECCメモリログの読み方が分からず、障害原因究明が進まない。・再発防止投資の根拠資料を経営層に示せない。・BCP・法令・人材計画の一元的フレームが社内にない。
- ECCメモリとは何か──ハード故障・ソフトエラーの基礎知識
- ログに残るCE/UEの意味──障害パターンと影響度マッピング
- 監視設計:障害フラグ3点の追加ポイント
- データ再現アルゴリズム:パリティ+ジャーナル+スナップショット統合
- BCP設計① 三重バックアップと三段階運用
- BCP設計② 10万人以上ユーザー向け細分化
- 法令・政府方針の最新動向と今後2年の予測
- コンプライアンス対応:証跡保全とフォレンジック
- 運用コスト試算:ハード更新・クラウド転送・教育費
- 人材戦略:資格・育成計画・採用広報
- エスカレーションフロー:役割分担と外部専門家
- まとめ──情報工学研究所へのご相談メリット
- おまけの章:重要キーワード・関連キーワードマトリクス

ECCメモリとは何か──ハード故障・ソフトエラーの基礎知識
ECC(Error-Correcting Code)メモリは、ビット単位のエラーを検出・訂正する技術を備えたサーバー用メモリです。物理的な故障だけでなく、宇宙線や電気ノイズによるソフトエラー(ビット反転)にも迅速に対応し、データ整合性を維持します。本章では、ハードウェア故障とソフトエラーのメカニズム、それぞれの発生頻度・影響範囲・対応手順を解説し、ECCログに見る重要指標を整理します。
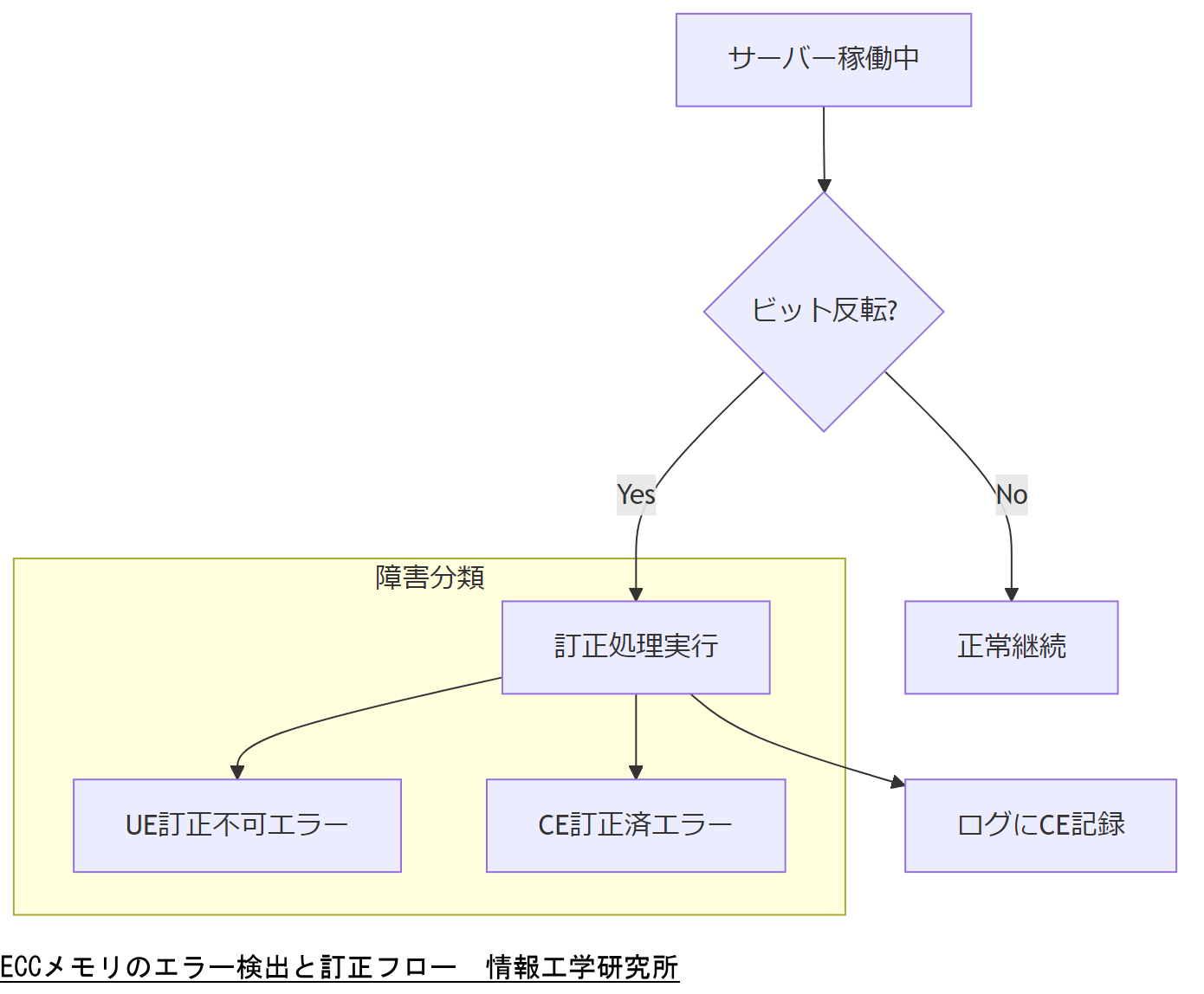
ログに残るCE/UEの意味──障害パターンと影響度マッピング
ECCログにはCorrectable Error(CE)とUncorrectable Error(UE)が記録されます。CEはビット訂正可能な軽微エラーで、累積するとシステム安定性に影響を与える可能性があります。UEは訂正不能エラーで、即時データ破損やシステム停止を招く重大な障害です。本節では、両者の発生頻度・影響範囲を把握し、ログ解析によるパターン分類と優先度付け手法を解説します。
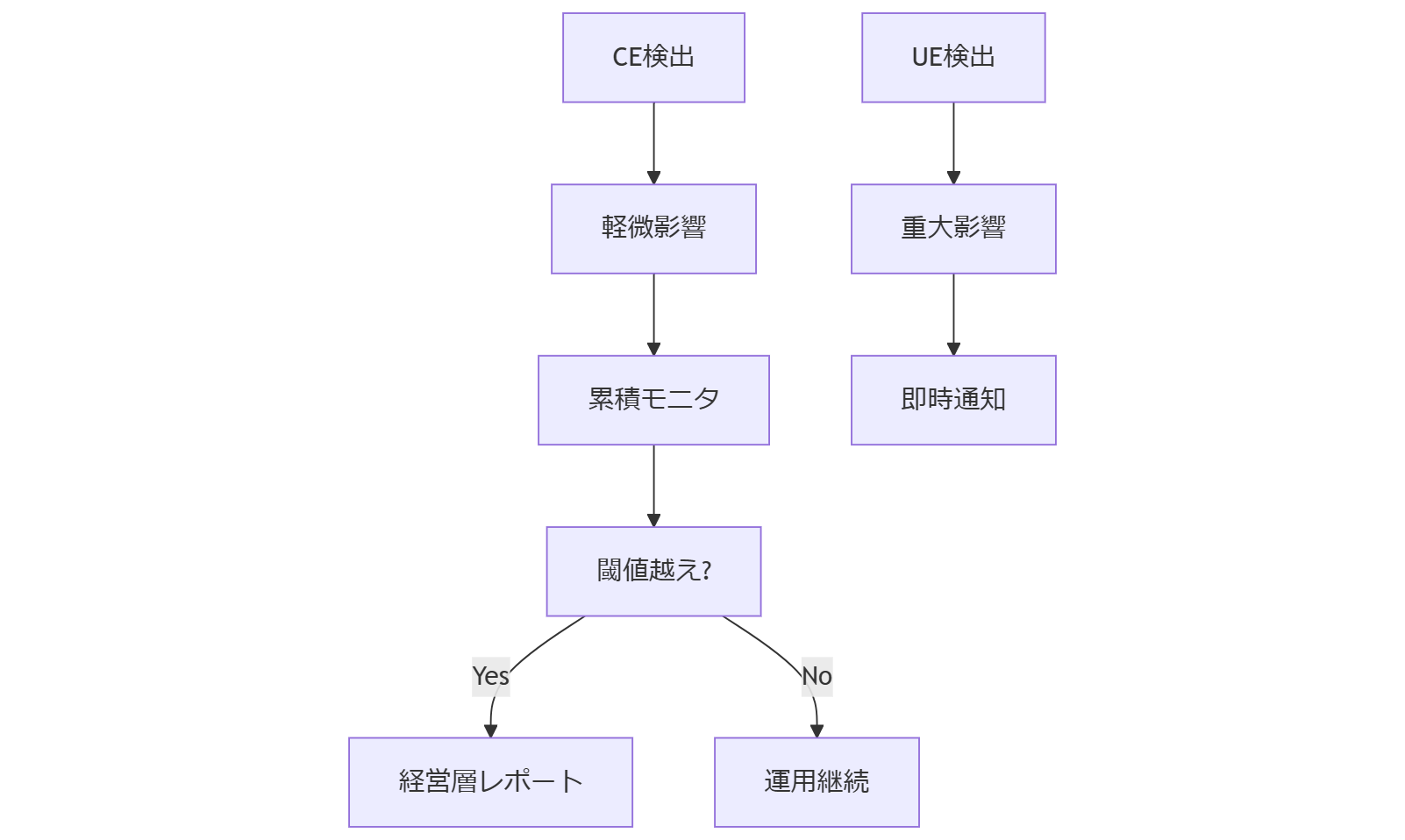
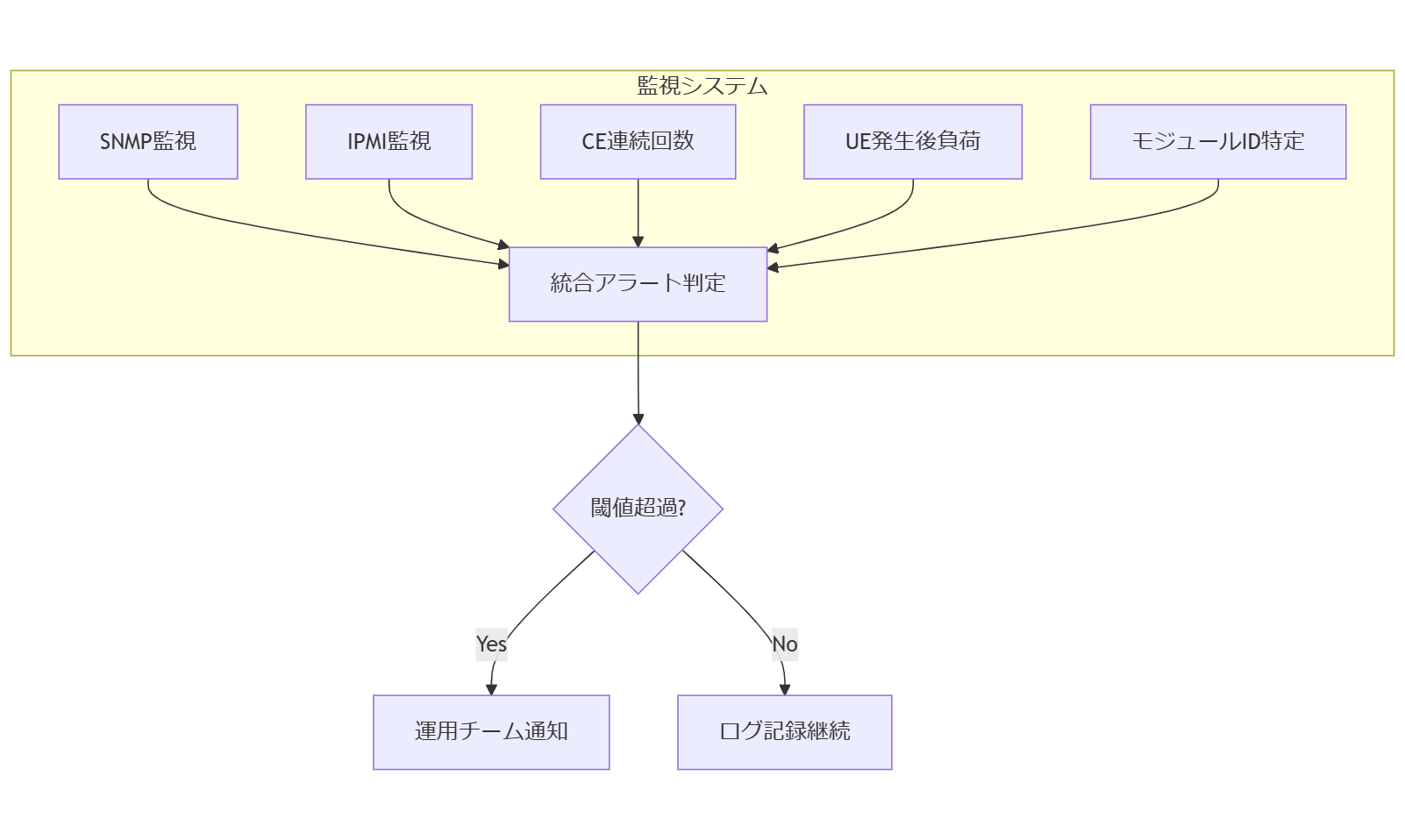
監視設計:障害フラグ3点の追加ポイント
既存のSNMPやIPMI監視に加え、ECCメモリ専用の障害フラグを3つ追加します。①CE連続発生回数、②UE発生直後のシステム負荷、③エラー発生モジュールの特定ID。これらを組み合わせたアラートルールにより、 **予兆検知** と **即時復旧起動** を両立させる監視アーキテクチャを提案します。
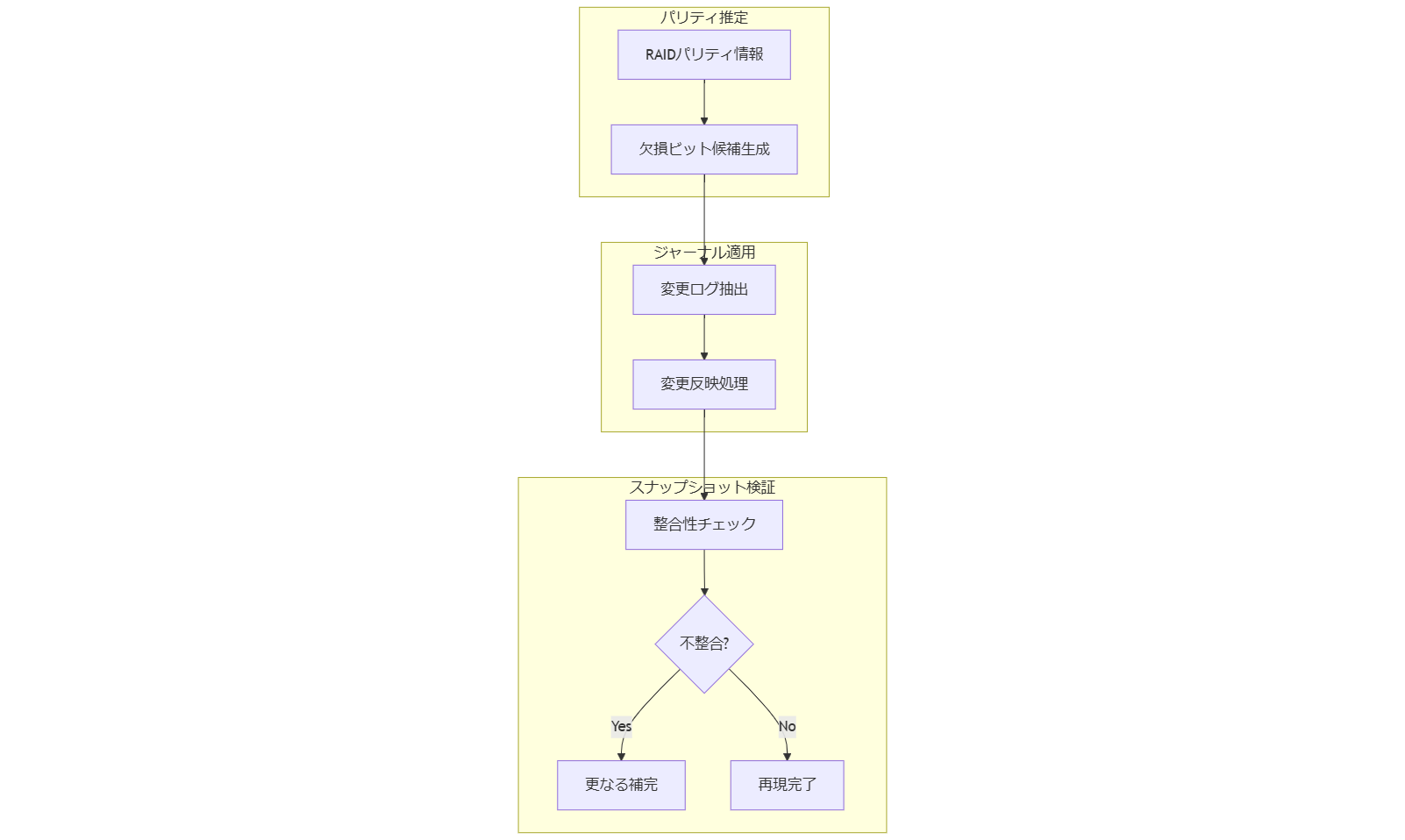
データ再現アルゴリズム:パリティ+ジャーナル+スナップショット統合
障害発生時に失われる前後数秒間のデータは、単一の技術では完全に再現できません。本章では、RAIDパリティ情報、ジャーナルログ、定期スナップショットを組み合わせることで、エラー発生ポイント前後のデータ整合性を最大化する手法を紹介します。まずパリティ参照で欠損ビットを推定し、その後ジャーナルから変更履歴を適用、最後にスナップショットで整合性を検証・補完します。
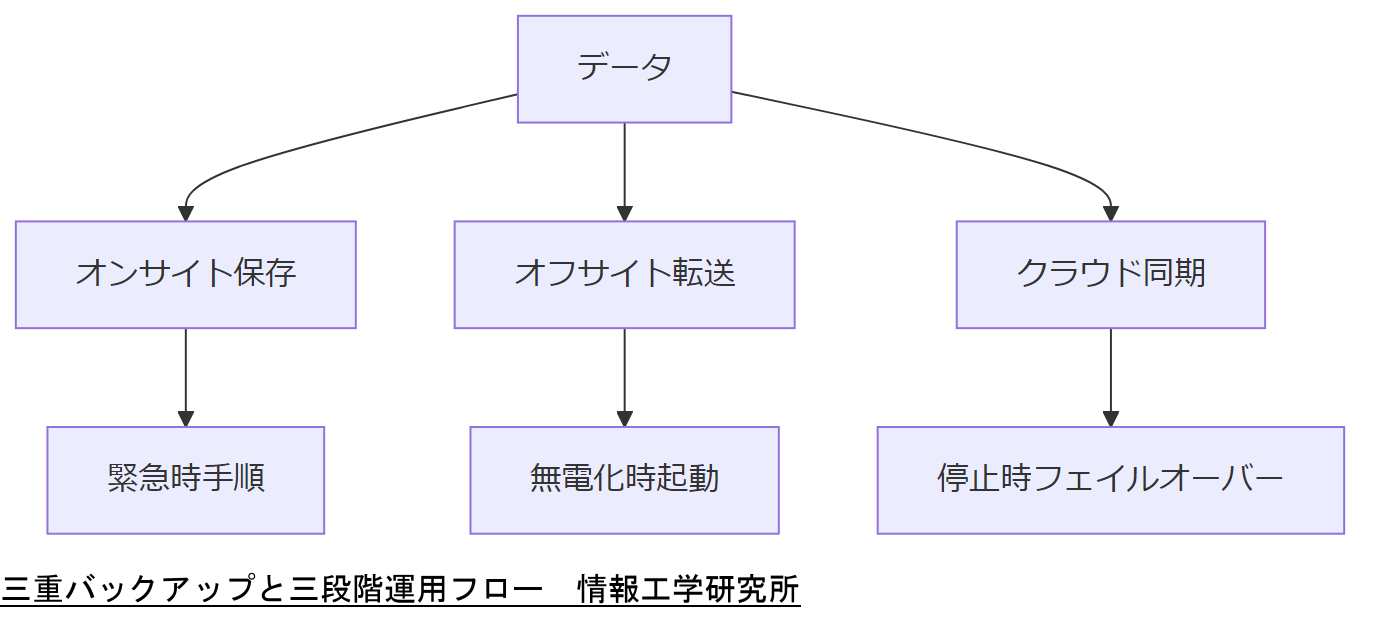
BCP設計① 三重バックアップと三段階運用
データ保全の基本は「三重バックアップ」です。オンサイト、オフサイト、クラウドの3層に保存し、地理的・インフラ障害に備えます。さらに運用は「緊急時(即時復旧)」「無電化時(UPS・発電機運用)」「システム停止時(手動フェイルオーバー)」の三段階を想定し、手順書と定期演習を通じて全員が共通理解を持つことが必須です。
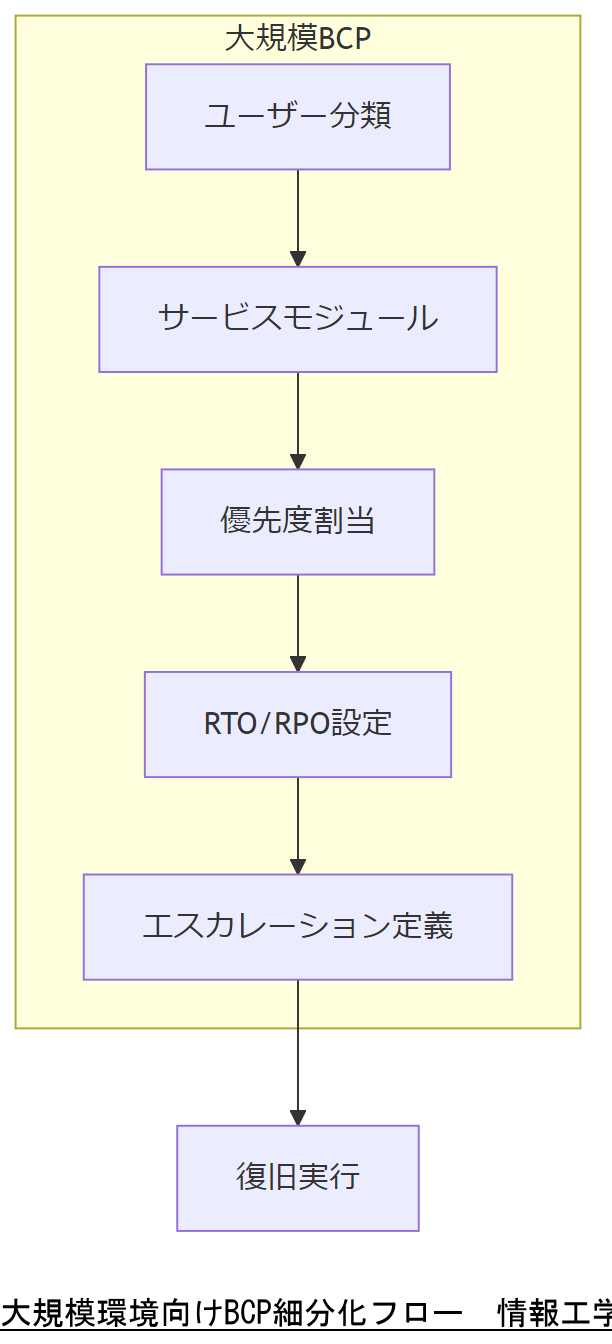
BCP設計② 10万人以上ユーザー向け細分化
ユーザー数が10万人を超える大規模環境では、フェーズごとの役割範囲をさらに細分化します。地域/サービス/システムモジュール単位で優先度を設定し、リカバリ優先順位リストを作成。各チームに対して具体的なRTO(復旧時間目標)・RPO(復旧地点目標)を割り当て、エスカレーションルートと連絡網を定義することが求められます。
法令・政府方針の最新動向と今後2年の予測
日本ではサイバーセキュリティ基本法改正に伴い、クラウド事業者へのログ保持義務延長や情報共有強化が進行中です。2024年度には「サイバーセキュリティ2024年次計画」で、ECCエラー検知の運用ガイドライン策定が明記され、2026年度までに製品ファームウェア要件に反映予定です。今後2年間で改正法案の閣議決定、施行規則の制定が見込まれ、BCP要件の厳格化と報告義務の拡大が予測されます。[出典:内閣サイバーセキュリティセンター『サイバーセキュリティ2024年次計画』2024][出典:経済産業省『クラウドセキュリティガイドライン活用ガイドブック』2023] 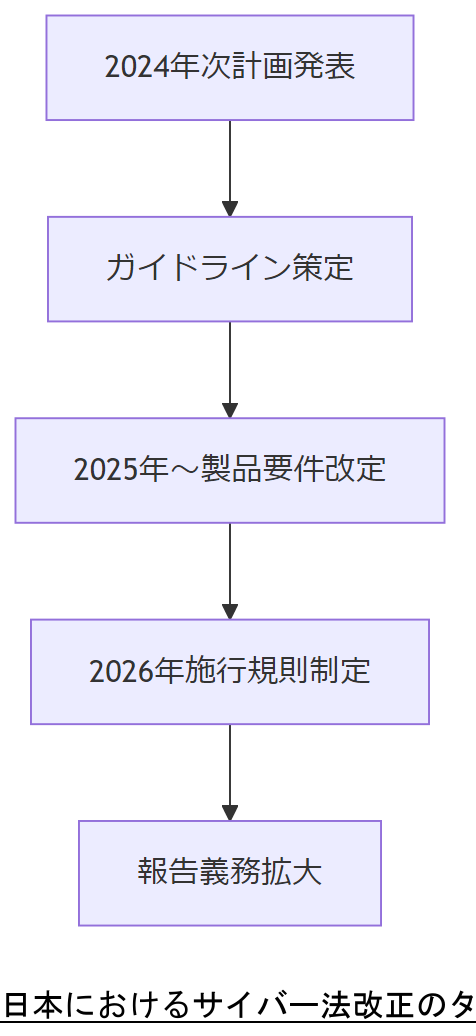
コンプライアンス対応:証跡保全とフォレンジック
障害発生時のログや証跡は、法令遵守と事故調査に不可欠です。機密性を維持しつつ、変更履歴を完全保全するためのWORM(Write Once Read Many)ストレージ利用と、デジタルフォレンジック手法を組み合わせた証跡管理フローを解説します。本節では証跡保全要件、保存期間、アクセス制御のベストプラクティスを整理します。[出典:経済産業省『クラウドサービスの信頼性に関するガイドライン』2022] 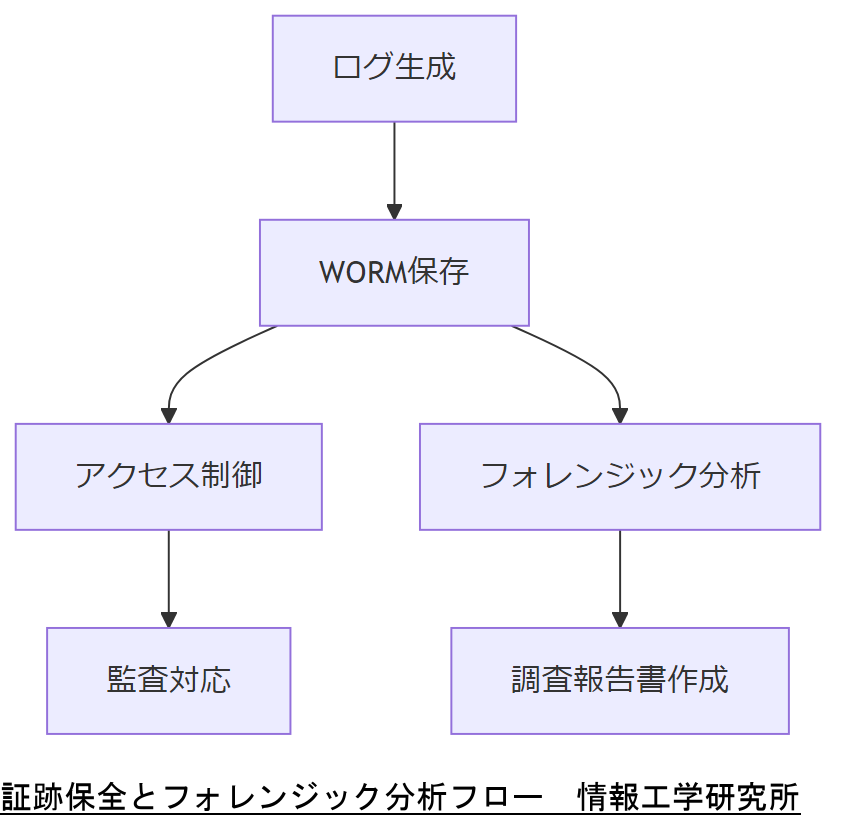
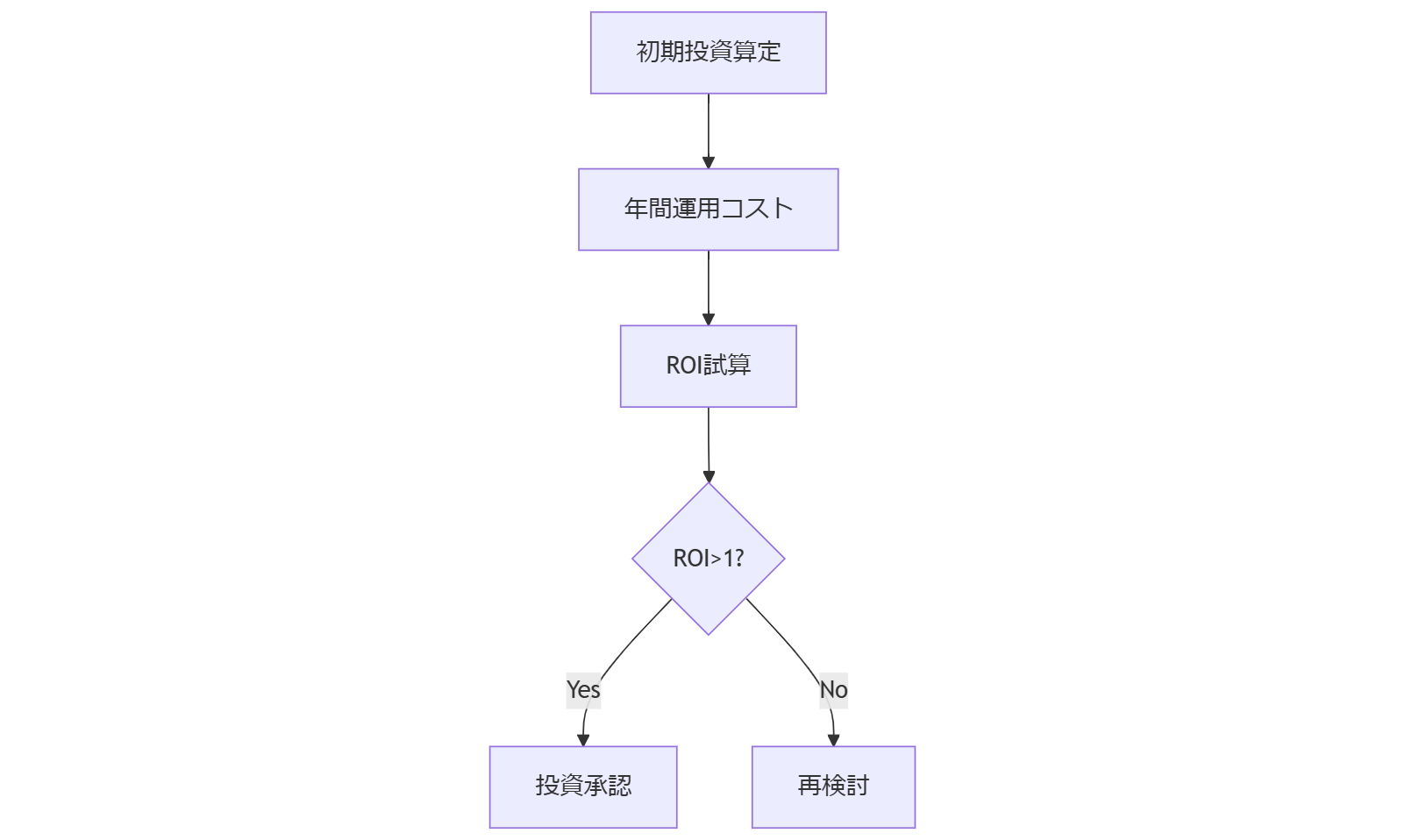
運用コスト試算:ハード更新・クラウド転送・教育費
ECC対応ハードウェア更新費用、クラウドへのログ転送料金、運用担当者の教育費を3軸で試算します。初期投資と年間運用コストを一覧化し、ROI試算を行う手順を提示。特にクラウド転送量増加によるランニングコスト上昇リスクと、教育頻度によるOPEX変動要因のモデリング方法を解説します。
| 項目 | 内容 | 金額目安 |
|---|---|---|
| ハード更新 | ECC対応メモリモジュール交換 | ■■万円【想定】 |
| クラウド転送 | ログデータ月間転送量 | ■■万円【想定】 |
| 教育費 | 社内研修・演習実施 | ■■万円【想定】 |
人材戦略:資格・育成計画・採用広報
ECCメモリ解析とBCP運用に携わる人材には、情報処理安全確保支援士(登録セキスペ)などの資格取得を推奨します。社内研修では実機演習とハンズオンを組み合わせ、事前演習で問題発生シミュレーションを実施。採用広報では「次世代システム信頼性エンジニア」など職種ブランディングを行い、大学や専門学校への情報提供を強化します。[出典:総務省『情報処理安全確保支援士制度概要』2023] 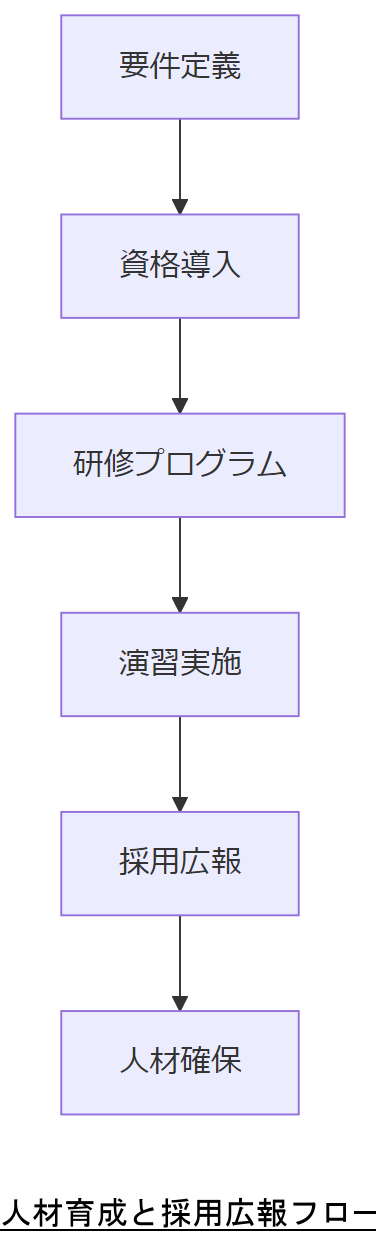
エスカレーションフロー:役割分担と外部専門家
障害発生時の初動対応後、社内関係部署と外部専門家への連携が鍵となります。本節では、第一線の運用チームから内部統制部門、さらに情報工学研究所へのエスカレーション方法をフロー化し、各ステップの責任者と対応時間目標を定義します。[出典:内閣サイバーセキュリティセンター『サイバーセキュリティ2024年次計画』2024] 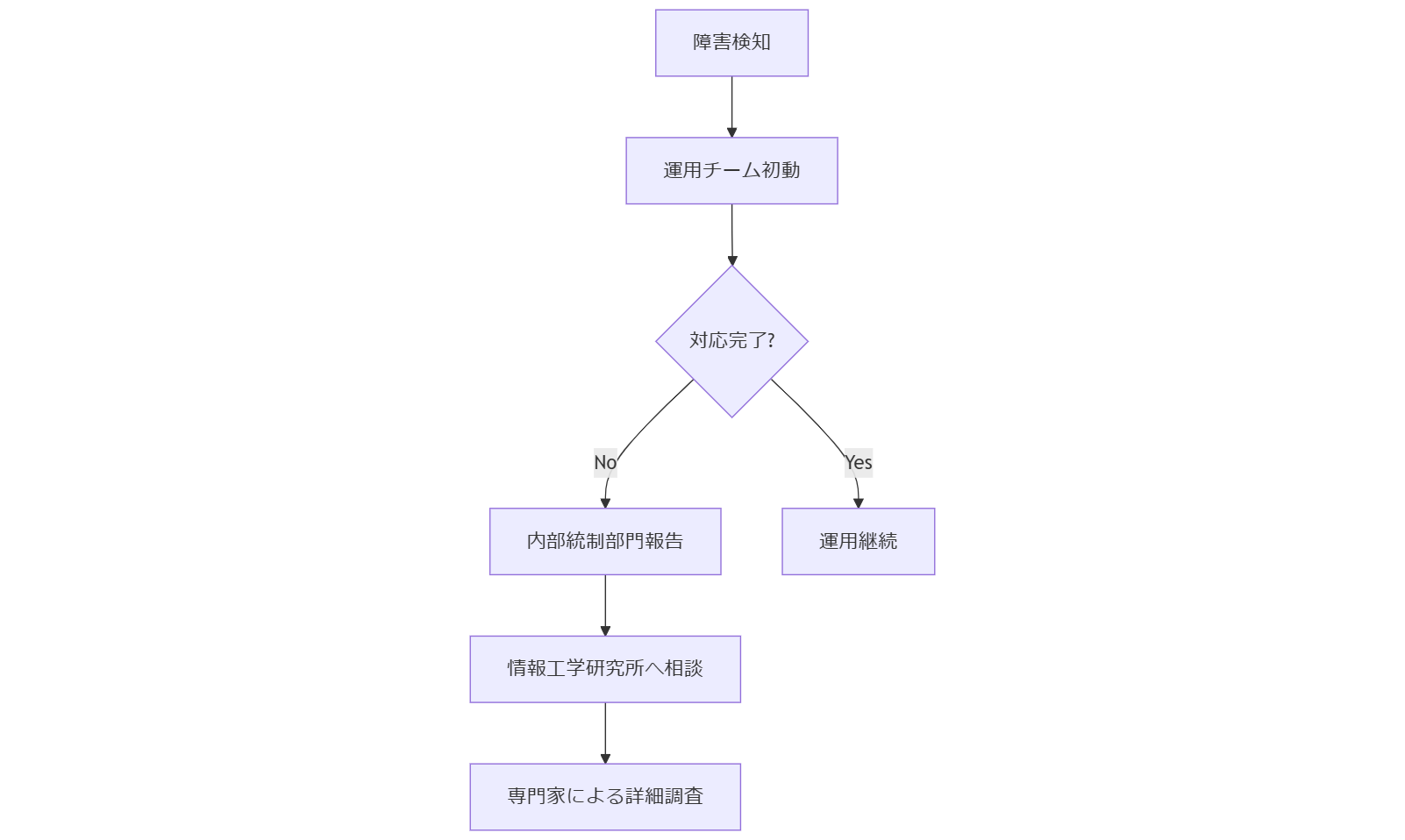
まとめ──情報工学研究所へのご相談メリット
本記事では、ECCメモリログ解析からデータ再現、BCP設計、法令動向、コンプライアンス対応、人材戦略、エスカレーションまで一貫したフレームを提示しました。特に情報工学研究所は、他社では困難とされた復旧事案も成功実績多数です。お問い合わせフォームからご相談いただければ、御社環境に最適な支援プランをご提供します。
おまけの章:重要キーワード・関連キーワードマトリクス
以下は本記事で扱った専門用語を整理したマトリクスです。
| キーワード | 説明 |
|---|---|
| ECCメモリ | Error-Correcting Codeを搭載し、ビット誤りを検出・訂正するメモリ技術 |
| ソフトエラー | 宇宙線やノイズで発生する一時的なビット反転現象 |
| CE/UE | Correctable/Uncorrectable Error。訂正可・不可エラーの分類 |
| 三重バックアップ | オンサイト・オフサイト・クラウドの三層保存モデル |
| BCP三段階運用 | 緊急時・無電化時・システム停止時の運用モード |
| デジタルフォレンジック | 証跡保全と解析を通じて法的証拠を取得する技術 |
| RTO/RPO | 復旧時間目標(Recovery Time Objective)・復旧地点目標(Recovery Point Objective) |
| 情報処理安全確保支援士 | 総務省認定のセキュリティ専門資格 |
| WORMストレージ | Write Once Read Many。改ざん不可の証跡保存方式 |
| お問い合わせフォーム | 情報工学研究所への相談窓口(フォーム経由) |

はじめに
メモリエラー解析の重要性と目的 メモリエラー解析は、企業のITインフラにおいて非常に重要な役割を果たします。特に、ECC(Error-Correcting Code)メモリのログを活用することで、エラー発生時のデータ再現が可能になります。ECCメモリは、メモリ内のデータの整合性を保つために設計されており、エラーを検出し、修正する能力を持っています。このため、ECCメモリから得られるログデータは、システムの健全性を把握するための貴重な情報源となります。 企業のIT部門や経営陣にとって、メモリエラーが発生すると、業務運営に大きな影響を及ぼす可能性があります。データの損失やシステムのダウンタイムは、経済的な損失を引き起こすだけでなく、顧客の信頼を損なう要因にもなり得ます。そのため、メモリエラーの早期発見と効果的な対応が求められます。 本記事では、ECCメモリログを用いたメモリエラー解析の方法と、エラー発生時のデータ再現の具体的な手法について詳しく解説します。これにより、IT管理者や経営者が持つべき知識と対策を明確にし、安心してシステムを運用できる環境を提供することを目指します。メモリエラー解析の重要性を理解し、実践することで、企業のデータ保全と業務の安定性を高めることができるでしょう。
ECCメモリの基本とその役割
ECCメモリは、データの整合性を確保するために特別に設計されたメモリタイプです。ECCは「Error-Correcting Code」の略で、メモリ内のデータにエラーが発生した際に、そのエラーを検出し、修正する機能を持っています。一般的なメモリと異なり、ECCメモリはデータの読み書き時に追加のビットを使用して、エラーの発生を防ぐ仕組みを採用しています。 この機能により、ECCメモリは特にサーバーやデータセンターなど、ミッションクリティカルな環境で広く利用されています。例えば、企業のデータベースや財務システムでは、一瞬のエラーが重大なデータ損失やシステム障害につながる可能性があるため、ECCメモリの導入が推奨されます。 ECCメモリは、ビットエラーを検出するだけでなく、単一ビットエラーを自動的に修正する能力も持っています。これにより、システムの信頼性が向上し、業務の継続性が確保されます。さらに、複数のビットエラーが同時に発生した場合でも、ECCメモリはその影響を最小限に抑えるための対策を講じています。 このように、ECCメモリは企業のITインフラにおける重要な要素であり、データの安全性とシステムの安定性を支える役割を果たしています。ECCメモリの特性を理解することで、IT管理者は適切なシステム設計や運用戦略を立てることができ、エラー発生時の迅速な対応が可能になります。企業全体のデータ保全に寄与するECCメモリの導入は、今後ますます重要な選択肢となるでしょう。
エラー発生時のログデータの収集方法
エラー発生時のログデータの収集は、ECCメモリの解析において重要なステップです。まず、ECCメモリがエラーを検出した際には、特定のログが生成されます。このログには、エラーの種類や発生時刻、影響を受けたメモリのアドレス情報などが記録されています。これらの情報は、問題の原因を特定し、適切な対策を講じるために不可欠です。 ログデータを収集するためには、まずシステムの管理ツールや監視ソフトウェアを活用します。これらのツールは、ECCメモリの状態をリアルタイムで監視し、エラーが発生した際に自動的にログを生成する機能を持っています。例えば、Linux環境では、`dmesg`コマンドや`/var/log/messages`ファイルをチェックすることで、ECCメモリのエラーログを確認することができます。 また、Windows環境では、イベントビューアを使用して、システムログやアプリケーションログからECCメモリに関連するエラー情報を抽出できます。これにより、発生したエラーの詳細を把握し、必要な対応を迅速に行うことが可能です。 さらに、ログデータを定期的にバックアップし、分析することも重要です。これにより、過去のエラー傾向を把握し、将来的な問題を予測するための基礎データを得ることができます。ログデータの収集と分析を徹底することで、IT管理者はメモリエラーの早期発見と適切な対策を講じることができ、企業のシステムの安定性を向上させることができるでしょう。
データ再現のための手法とアプローチ
データ再現のための手法は、ECCメモリから得られるログデータを活用することで、エラー発生時の状況を詳細に分析し、損失を最小限に抑えることを目的としています。まず、エラーが発生した際のログを解析し、どのデータが影響を受けたのかを特定します。この際、エラーログに記録されたメモリアドレスやエラーの種類をもとに、どのデータが損なわれたかを判断することが重要です。 次に、影響を受けたデータのバックアップを確認します。企業では、定期的にデータのバックアップを行っていることが一般的ですが、バックアップのタイミングや方法によっては、最新のデータが失われてしまう可能性があります。したがって、バックアップデータを用いて、エラー発生前の状態にデータを復元することが必要です。 さらに、データ再現のためには、特定のツールやソフトウェアを活用することが有効です。これらのツールは、ログデータを解析し、エラー発生時のデータの状態を再現するための手助けをします。特に、エラーの発生パターンを学習し、将来的なエラーを予測する機能を持つツールは、企業のITインフラの安定性を高める上で非常に役立ちます。 最後に、データ再現後は、再発防止策を講じることが重要です。エラーの原因を突き止め、必要なハードウェアやソフトウェアのアップデートを行うことで、同様の問題が再発するリスクを低減させることができます。このように、データ再現の手法とアプローチを適切に実施することで、企業はメモリエラーによる影響を最小限に抑え、業務の継続性を確保することができるでしょう。
ケーススタディ:実際のエラー解析の事例
実際のエラー解析の事例を通じて、ECCメモリがどのように企業のデータ保全に寄与するかを見ていきましょう。ある企業では、サーバーのECCメモリにおいて、特定のタイミングでエラーが頻発する事象が発生しました。ログデータを解析した結果、特定のアプリケーションがメモリの過剰な使用を引き起こし、ビットエラーが連鎖的に発生していたことが判明しました。 この企業は、まずエラーの詳細を把握するために、ECCメモリのログを精査しました。エラーメッセージには、影響を受けたメモリアドレスやエラーの種類が明示されており、これを基に問題の根本原因を特定しました。次に、影響を受けたデータのバックアップを確認し、エラー発生前の状態に復元する作業を行いました。 さらに、エラーの再発防止策として、メモリの使用状況をモニタリングするツールを導入し、アプリケーションのメモリ使用量を最適化するための設定変更を行いました。この結果、エラーの発生頻度は大幅に減少し、企業のシステムの安定性が向上しました。 このケーススタディから得られる教訓は、ECCメモリのログを活用することで、エラーの根本原因を迅速に特定し、適切な対策を講じることができるという点です。エラー解析のプロセスを確立することで、企業はデータ保全の向上と業務の安定性を実現することが可能となります。
今後の展望と技術の進化
メモリエラーデバイス解析の分野において、今後の展望と技術の進化は非常に重要なテーマです。近年、データ量の増加とともに、システムの複雑化が進んでいます。このため、ECCメモリを含むメモリデバイスのエラー解析技術も進化し続けています。特に、AI(人工知能)や機械学習技術の導入により、エラー検出やデータ再現のプロセスが効率化されることが期待されています。 AIを活用することで、過去のエラーログからパターンを学習し、将来的なエラーの予測が可能になります。また、リアルタイムでのモニタリングシステムが進化することで、エラー発生の兆候を早期にキャッチし、迅速な対応が可能になるでしょう。これにより、システムの安定性が向上し、業務の継続性がさらに確保されることが期待されます。 さらに、クラウドコンピューティングの普及に伴い、データのバックアップや復元の手法も変化しています。クラウドベースのソリューションを利用することで、データの保全が容易になり、災害時の復旧速度も向上します。このような技術の進化により、企業はより高いレベルでのデータ保全とリスク管理が可能となります。 今後、ECCメモリの解析技術は、より一層の進化を遂げることでしょう。IT部門や経営陣は、これらの技術を積極的に取り入れ、システムの健全性を保つための新たな戦略を構築することが求められます。技術の進化を活用し、メモリエラーに対する理解を深めることで、企業はより安全で安定したIT環境を実現できるでしょう。
分析結果の総括と今後の課題
本記事では、ECCメモリを活用したメモリエラー解析の重要性と、エラー発生時のデータ再現手法について詳しく解説しました。ECCメモリは、データの整合性を保つための強力なツールであり、特に企業のITインフラにおいては、その機能が欠かせません。エラーが発生した際には、ログデータの収集と分析が重要であり、これにより問題の根本原因を特定し、迅速な対応が可能となります。 また、データ再現のための手法を通じて、企業はエラーによる損失を最小限に抑えることができます。実際の事例を通じて、ECCメモリのログを活用した効果的な対策がどのように実現されたかを示しました。さらに、今後の展望として、AIや機械学習技術の導入が期待されており、これによりエラー検出やデータ再現のプロセスが一層効率化されることが見込まれています。 今後の課題としては、技術の進化に伴う新たなリスクへの対応や、データ保全のための戦略の見直しが挙げられます。企業は、これらの課題に対処するために、最新の技術を積極的に取り入れ、システムの健全性を保つ努力を続ける必要があります。ECCメモリの特性を理解し、適切に活用することで、企業はより安全で安定したIT環境を構築できるでしょう。
さらなる情報を得るためのリソースへのリンク
メモリエラーデバイス解析に関する知識を深めることは、企業のIT環境をより安全に保つために非常に重要です。ECCメモリのログ解析やエラー再現の手法について、さらに詳しい情報を得たい方は、専門的なリソースやガイドを活用することをお勧めします。これにより、実際の事例や最新の技術動向を理解し、効果的な対策を講じるためのヒントを得ることができます。 また、データ復旧や保全に関する専門家の意見を参考にすることで、より具体的なアプローチを学ぶことができるでしょう。是非、信頼できる情報源を通じて、メモリエラー解析のスキルを向上させてください。あなたの企業のデータ保全とシステムの安定性を向上させるための第一歩として、これらのリソースを活用してみてはいかがでしょうか。
解析時の留意事項と注意すべきポイント
メモリエラーデバイス解析を行う際には、いくつかの重要な留意事項があります。まず、ログデータの収集と解析を行う際には、正確なタイムスタンプやエラーコードを確認することが不可欠です。これにより、エラー発生の前後関係を明確にし、根本原因の特定に役立ちます。また、複数のエラーが同時に発生することもあるため、それぞれのエラーの関連性を考慮する必要があります。 次に、収集したログデータは適切に保管し、定期的にバックアップを行うことが重要です。データの損失を防ぐため、特に重要なログデータは、安全な場所に保存しておくことが推奨されます。また、ログデータの解析には専門的な知識が求められるため、必要に応じて専門家の助言を受けることも考慮しましょう。 さらに、解析結果に基づく対応策は、迅速かつ効果的に実施することが求められます。エラーの原因を特定した後は、再発防止策を講じることが重要ですが、これには適切なハードウェアやソフトウェアのアップデートが含まれます。最終的に、解析と対応策の実施は継続的なプロセスであるため、定期的なレビューと改善を行うことが企業のシステムの安定性を保つ鍵となります。
補足情報
※株式会社情報工学研究所は(以下、当社)は、細心の注意を払って当社ウェブサイトに情報を掲載しておりますが、この情報の正確性および完全性を保証するものではありません。当社は予告なしに、当社ウェブサイトに掲載されている情報を変更することがあります。当社およびその関連会社は、お客さまが当社ウェブサイトに含まれる情報もしくは内容をご利用されたことで直接・間接的に生じた損失に関し一切責任を負うものではありません。