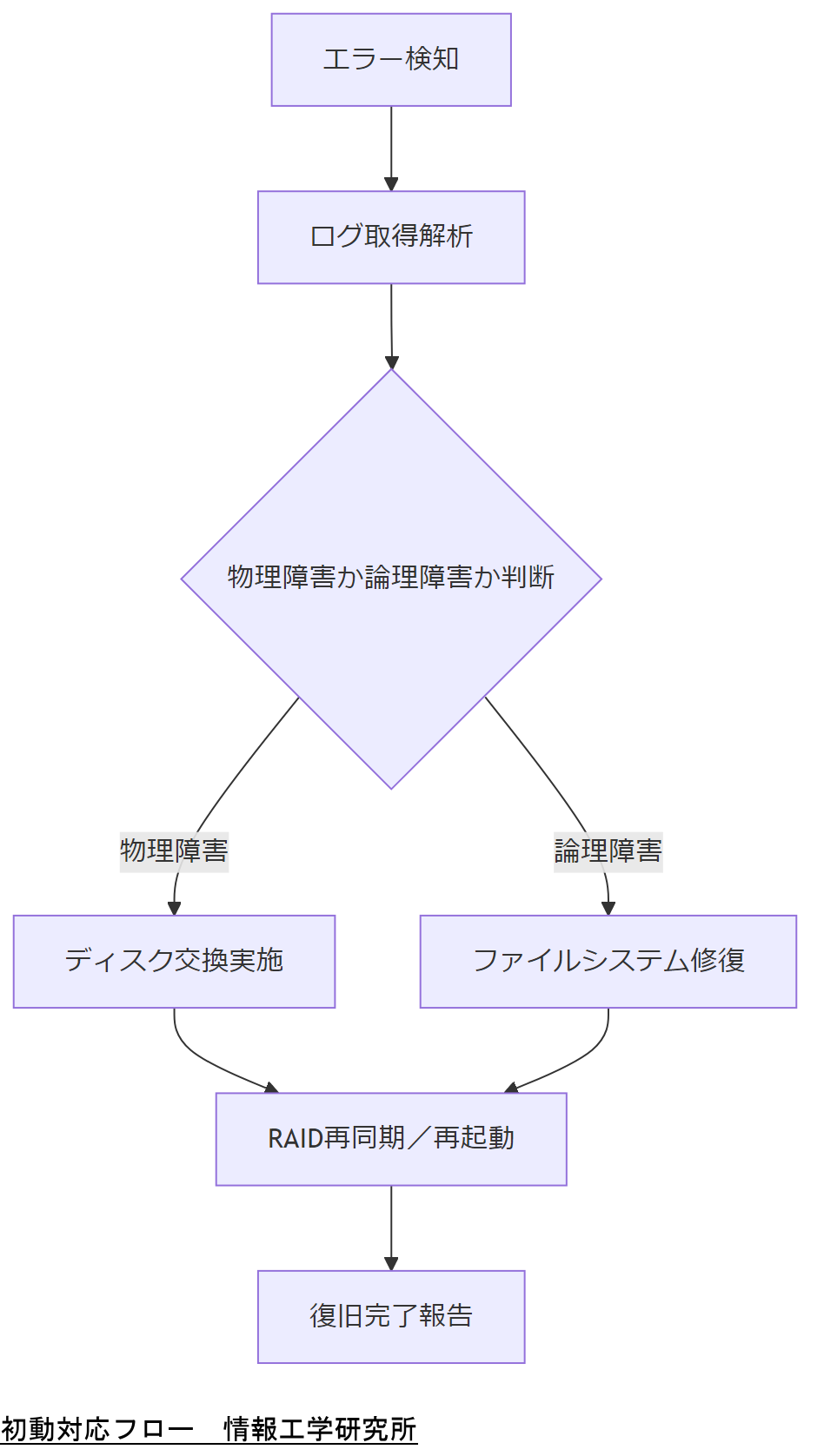
【注意】 本記事はLinuxカーネルログ解析の一般的な解説です。実環境では機器構成・負荷・ドライバ・ファームウェア・保守契約などで判断が変わります。障害の切り分けやデータ保全が必要な場合は、株式会社情報工学研究所のような専門事業者への相談も検討してください。
第1章:dmesgは「後から読むログ」ではなく、障害と会話するための“実況”である
障害対応でいちばんつらいのは、「何が起きたか」が分からないことよりも、「分かるはずの手がかりが消えている」ことです。ディスクが一瞬だけタイムアウトして復帰した、ケーブルが揺れてリンクが落ちた、コントローラがリセットをかけた──その瞬間の実況が dmesg に出るのに、後で見たら流れてしまっている。これが“削除ログ”の実態です。
ここで重要なのは、dmesg は「ログファイル」ではなく、カーネルが出力するメッセージのバッファ(ring buffer)を読むための表示手段だという点です。バッファなので容量は有限で、古いものから上書きされます。つまり、時間が経つほど“過去は消える”構造です。
「消えた」の正体:ring bufferと出力経路
Linuxのカーネルメッセージは、概ね次の経路で流れます。
| 層 | 役割 | 観測の入口 |
| kernel ring buffer | カーネル内部のメッセージ蓄積(有限で上書き) | dmesg |
| kmsg/console | kmsgデバイスやコンソールへの出力 | journalctl -k / コンソールログ |
| journald/syslog | 永続化・フィルタ・転送(設定次第) | /var/log / 集約基盤 |
「dmesgに無い=起きていない」と短絡しやすいのですが、実際には「ring bufferからは消えたが、journaldやログ集約には残っている」ケースもあります。逆もあります(出力がrate limitで抑制され、永続化側に十分残らない)。
現場の“心の会話”:後から調べるほど不利になる
「いまは復旧してるし、後でゆっくり確認でいいか」──そう思った瞬間に、調査の難易度は上がります。ring bufferは上書きされ、ドライバは同じ警告をrate limitで間引き、システムは次のイベントでログを押し流します。だからこそ、障害対応は“原因究明のための採取”を最優先に組み込む必要があります。
この章の伏線:再現とは「同じエラーを出す」ではない
本記事のテーマは「削除ログ再現」ですが、ここで言う“再現”は、同じメッセージ文字列をもう一度出すことではありません。ログが消える条件(上書き、間引き、出力経路の欠落)を理解し、同じ経路・同じ層で起きた事象を観測可能な形で再度踏むことです。次章から、その前提となる「なぜログが消えたように見えるのか」を分解します。
第2章:「消えたはずのI/Oエラー」が戻ってくる理由──カーネルは“削除”ではなく“上書き”する
「昨日の深夜、I/Oエラーが出たって聞いたのに、今 dmesg を見ても無い」──これは“証拠隠滅”ではなく、構造上の必然です。カーネルメッセージは有限バッファに蓄積され、古い順に上書きされます。つまり、観測が遅いほど、過去の痕跡は薄れます。
ring bufferの“容量”がつくる罠
ring bufferのサイズは環境・設定に依存します。大量のログが出る状況(ドライバの警告ループ、ネットワークのリンクアップダウン、ファイルシステムの再試行など)では、短時間で押し流されます。特にハード障害系は「同じ警告の繰り返し」が多く、重要な1行がノイズに埋もれて消えがちです。
一方で、journalctl -k を使うと、journaldが保持しているカーネルログを時系列で追えることがあります。つまり、dmesg しか見ていないと「消えた」と誤認しやすい。まず観測点を増やすことが第一歩です。
「戻ってくる」現象:同じ根本原因が形を変えて再発する
もう一つの典型が、「一度消えたはずのI/O問題が、別のタイミングで“別のメッセージ”として戻ってくる」ことです。例として、次のような連鎖が起こり得ます。
- 最初は軽微な遅延(timeout寸前)として現れる
- 次にコントローラやリンクのリセットとして現れる
- さらに進むと、ブロック層でI/O errorとして顕在化する
- 最終的にファイルシステムがread-only化やエラーを報告する
メッセージ文字列が変わるので、現場では「別件」に見えます。しかし根は同じ(媒体劣化、ケーブル不良、バックプレーン、HBA、電源品質、温度、ファームウェア不整合など)で、症状が段階的に悪化しているだけ、というケースが少なくありません。
削除ログ“再現”に必要な設計:消える前提で保全する
ここまでで分かるのは、「ログが無い」こと自体が診断材料になる、という点です。ログが無いのは、起きていないからではなく、保持される設計になっていないからかもしれません。再現に向けては、少なくとも次のどれかが必要になります。
- 永続化:journaldの永続化設定、syslogへの転送、ログ集約(外部送信)
- 即時採取:障害の兆候を検知した瞬間に
dmesg/journalctl -k を退避 - 帯域の確保:ログが押し流されないよう、ノイズ源(ループログ)を抑え、観測点を整理
ただし注意点として、ハード障害が疑われる局面で「ログを取りたいから」と負荷を上げすぎるのは危険です。媒体が不安定なら、追加の読み書きが障害を進行させる可能性があります。後半章では、この“採取と安全”のバランスを具体的に扱います。
この章の伏線:次は「ノイズ」を見分ける
削除ログ再現をやるなら、次に必要なのは「何を本線として追うか」です。現場のカーネルログはノイズだらけで、重要な兆候は短く、言い回しもドライバ依存です。次章では、まず“ノイズの種類”を分類し、追うべきシグナルを取りこぼさないための読み方に落とします。
第3章:まず押さえる3種類の現場ノイズ──ring buffer、rate limit、driverの言い回し
「ログは見た。でも確証が持てない」──この状態を作る最大の要因がノイズです。特にハード障害の初期兆候は、派手な“故障宣言”ではなく、地味な遅延・再試行・リセットとして現れます。その上に、ログの仕組み由来のノイズが乗ります。
ノイズ1:ring bufferの上書き(重要ログが物理的に残らない)
第1章・第2章で触れた通り、dmesg の元になるring bufferは有限です。障害時はログが増えやすく、重要な瞬間が押し流されがちです。したがって、障害解析は「いつ見たか」が品質を左右します。
- まず
journalctl -k で永続側に残っていないか確認する - 残っていないなら、次回に備えて永続化・転送・即時採取の設計を入れる
ノイズ2:rate limit(同じ警告が“間引かれて”見えなくなる)
カーネルやjournaldには、ログの洪水を防ぐためのrate limit(出力制限)が存在します。これにより、同じ種類のメッセージが大量に出ている状況ほど、「最初の数件だけが見えて、肝心の後半が消える」ことが起きます。結果として、原因の進行度合いや頻度を誤認しやすくなります。
ここでの実務的な対策は「rate limitを解除して全部取る」ではありません。障害時にログを増やすと、観測自体が重くなり、さらにバッファを圧迫します。むしろ、次のように設計するのが安全です。
- 本番ではログを“取れる形”に整える(永続化・転送・時刻同期)
- 再現環境ではrate limitの影響を見越して、複数の観測点(ドライバ、ブロック層、FS層)を同時に取る
ノイズ3:driverの言い回し(同じ事象が別名で出る)
ハード障害に関するログは、層とドライバで表現が変わります。たとえば「タイムアウト」一つでも、SATA/ATA、SCSI、NVMe、RAIDコントローラで文言が違います。さらに、上位層(ファイルシステム)には「I/O error」や「read-only remount」など別の形で現れます。
| 観測層 | よく出る兆候 | 解釈のポイント |
| ドライバ/リンク層 | link down/up、reset、timeout | ケーブル/バックプレーン/コントローラ/電源品質の疑い |
| ブロック層 | I/O error、request timeout、abort | 再試行の結果として表面化。頻度と対象LBA/デバイスを追う |
| ファイルシステム層 | ext4/xfsのエラー、read-only化 | “被害最小化”のための保護動作。原因は下位層にあることが多い |
ここまでの伏線回収:再現の前に「何を再現するか」を決める
削除ログを再現したいとき、やりがちなのが「同じメッセージを出すテスト」ですが、これは本質から外れます。大事なのは、どの層で、どの種類の兆候が最初に出たのかを特定し、その層を中心に観測を組むことです。たとえば「リンクリセットが最初」ならケーブル・バックプレーン・HBAの観測が主役になりますし、「特定LBAでの読み取り遅延が最初」なら媒体劣化・再配置・SMART/NVMeログが主役になります。
次章では、層の関係(block層・SCSI/ATA層・ファイルシステム層)を“頭の中で図にできる”形に整理し、ログの読み違いを減らします。そこから先で、再現環境の作り方と、観測の束ね方に進みます。
/
第4章:ハード障害のシグナルはここに出る──block層・SCSI/ATA層・ファイルシステム層の関係
ハード障害を示すカーネルメッセージは、単発の「I/O error」だけで完結しません。むしろ多くの場合、複数の層が連鎖してログが出ます。ここを理解しているかどうかで、「見えているログから何が言えるか」が変わります。
まず全体像:下位の異常が上位に“翻訳”される
Linuxストレージのログは、大まかに次の層で出ます。
- 物理〜リンク層:SATA/SAS/NVMeのリンク、ケーブル、バックプレーン、HBA、電源品質などの影響が出やすい
- デバイス/プロトコル層:SCSI(SAS/FC/iSCSIなど含む)、ATA、NVMeなどのコマンド処理・エラー報告
- ブロック層:I/O要求(request)のタイムアウト、再試行、失敗が集約される
- ファイルシステム層:ext4/xfs/btrfs等が整合性を守るために警告やread-only化を行う
- アプリ層:最終的にread(2)/write(2)がEIO等で失敗し、アプリやDBが異常を示す
ポイントは、上位に行くほど抽象化され、原因の情報が削れていくことです。たとえばアプリが「Input/output error」を出しても、それが媒体劣化なのか、リンク不安定なのか、コントローラのリセットなのかは分かりません。原因に近い情報は下位層にあります。
“どこを起点に読むか”の実務ルール
現場で迷いがちな読み方を、判断しやすい形に落とします。
| 最初に目についたログ | 次に当たる層 | 狙うべき追加情報 |
| ext4/xfsの整合性警告 | ブロック層 → デバイス層 | 同時刻のI/O error、timeout、reset、対象デバイス名(sda/nvme0n1等) |
| I/O error / request failed | デバイス層(SCSI/ATA/NVMe) | sense key/ASC/ASCQ、ATA error、NVMe status、reset履歴 |
| link down/up / controller reset | 物理〜リンク層 | ケーブル/バックプレーン/電源/温度、同一ポートでの再発、別ディスクへの波及 |
「削除ログ再現」の伏線:層ごとに“再現の目的”が違う
ここで重要な伏線があります。削除ログを“再現”すると言っても、層によって再現の狙いは変わります。
- リンク層が主因なら:同一ポートでリンクの瞬断やリセットが起きる条件(ケーブル・振動・温度・電源)を再現し、同時に観測する
- 媒体/デバイス層が主因なら:特定の読み取り遅延やエラー報告(SMART/NVMeログ含む)を観測できる状態で、危険な負荷を避けつつ兆候を捉える
- ファイルシステム層が主因に見えるなら:実際は下位のI/O問題が起点か、メモリ/バグ/設定(例:突然の電断、キャッシュ破損)が起点かを切り分ける
次章では、現場でよく見る「I/O error」という一言の中身を分解し、何を見れば“どの種類の異常か”を言えるのかを整理します。
第5章:「I/O error」の正体を分解する──timeout/reset/medium error/link down
「I/O errorが出ました」と言われたとき、エンジニアは反射的にこう思います。「で、どのI/O?」「どの層?」「再試行は?」「同時刻に何が起きてる?」。この章では、その“腹落ち”に必要な分解軸を、ログの読み方としてまとめます。
よくある4分類:現場の判断が速くなる
同じI/O失敗でも、背景が違うと対処が変わります。実務上は次の4分類が有用です。
| 分類 | 典型的な兆候 | 疑う範囲 |
| timeout系 | request timeout、command timeout、I/Oが完了しない | 過負荷、キュー詰まり、デバイスの応答遅延、ファームウェア、温度 |
| reset系 | controller reset、bus reset、link reset、device reset | リンク不安定、コントローラ/HBA、電源品質、ケーブル/バックプレーン |
| medium error系 | 読み出し不可、uncorrectable、reallocated増加など(S.M.A.R.T.側にも兆候) | 媒体劣化、NAND/磁気面の劣化、ECC限界、寿命 |
| link down系 | link down/up、PHY reset、CRC errorに関連する兆候 | ケーブル、コネクタ接触、バックプレーン、振動、温度、電源ノイズ |
「心の会話」:交換すべきはディスク?それとも周辺?
ここで現場が悩むのは、「ディスクを交換して終わりにしたい」気持ちと、「周辺が原因なら交換しても再発する」現実の間です。たとえばlink down系が出ているのにディスクだけ交換すると、同じポートで次のディスクも落ちます。逆にmedium error系でディスクが劣化しているのに、ケーブルを疑って時間を使うと、劣化が進んで救出難易度が上がります。
“削除ログ”があっても確度を上げるコツ:時刻・対象・頻度
ログが消えていたり間引かれていたりしても、確度を上げるためのコツがあります。ここでは、事実ベースで積み上げる方法に限定します。
- 時刻:同じタイムウィンドウ(±数分〜十数分)で、下位層→上位層の連鎖がないかを見る
- 対象:デバイス名(sda/sdb、nvme0n1等)と、その背後(RAID仮想か、物理か)を一致させる
- 頻度:単発か、周期的か、負荷に比例するか。単発でも“兆候”として扱う
特に、周期性や負荷依存は再現の設計に直結します。たとえば「バックアップ時間帯にだけ出る」なら、I/Oが増えたときにキューや温度が上がる条件が関与している可能性があります。
次章への伏線:再現は“同じエラー”ではなく“同じ経路”
ここまでで、「I/O error」と一口に言っても背景が違うことが分かりました。次章では、削除ログ再現の考え方として、同じメッセージを出すのではなく、同じ経路(層)で同じ種類の異常が起きる状況を作るという方針に落とします。そのために必要な、再現環境・観測設計の最小構成を提示します。
第6章:削除ログを“再現”する発想──同じエラーを出すのではなく「同じ経路を踏む」
「削除されたログを再現する」と言うと、どうしても“同じログ行を出す”方向に引っ張られます。しかし、それは危険です。ハード障害の兆候を無理に出そうとして、ディスクに過剰な負荷をかけたり、運用環境で不必要な操作をしたりすると、被害が拡大する恐れがあります。
ここでの再現は、あくまで解析のための再観測です。目的は「メッセージ文字列の復元」ではなく、「因果の確定」にあります。
再現の定義:観測可能な形で因果の鎖をもう一度作る
実務での再現は、次の3点が揃って初めて意味があります。
- 条件が固定されている(負荷、温度、構成、ファームウェア、ケーブル、HBAなど)
- 観測が同時に取れている(dmesg/journalctlだけでなく、SMART/NVMe、I/O統計など)
- 安全が担保されている(データ保全が優先。危険な書き込みや長時間の連続負荷を避ける)
これが揃わない再現は、「派手なログが出た/出ない」に引きずられて結論がぶれます。
再現を設計するための“最小セット”
まずは、環境差分で議論が崩れないように、最低限押さえる要素を表にまとめます。
| 要素 | 固定/記録する理由 | 例 |
| デバイス経路 | 同じ物理経路でないと別原因になる | 同一スロット/同一ポート/同一HBA |
| 負荷特性 | 症状が負荷依存の場合が多い | ランダム/シーケンシャル、read多め/write多め |
| 温度・電源 | 境界条件で不安定化しやすい | 夜間だけ出る、ピーク時だけ出る |
| ソフト層 | ドライバ/FS設定で出方が変わる | kernel/driver、RAID、FS種別、mountオプション |
「一般論の限界」を先に言っておく:再現は環境依存が大きい
ここは誤解が起きやすいので明確にします。ハード障害の兆候は、ストレージ構成(直結、RAID、SAN、仮想化)、ドライバ、ファームウェア、機器世代によって現れ方が違います。同じ「timeout」でも、ログの文言や上位への波及は変わります。したがって、再現と因果確定は個別案件の設計問題です。
このブログでは、どの環境でも通用する「層の見方」と「観測設計」を示しますが、実際の案件で「どこまで負荷をかけてよいか」「どこでデータ保全を優先すべきか」は、保守契約・RPO/RTO・データ重要度で変わります。ここが、後半で株式会社情報工学研究所のような専門家への相談が意味を持つ理由でもあります。
次回への伏線:再現環境の作り方(安全設計)に入る
次章では、再現環境の作り方を「危険を増やさない」観点で具体化します。負荷・温度・ケーブル・電源・コントローラ差分をどう固定するか、そしてdmesgに頼らず観測を束ねて“消える前提”で証拠を残す方法へ進みます。
第7章:再現環境の作り方──負荷・温度・ケーブル・電源・コントローラ差分を固定する
ハード障害の兆候を追うとき、いちばん危険なのは「とりあえず同じ操作をもう一回やってみる」です。偶然再発することもありますが、再発しなければ“問題なし”と誤認しがちですし、再発させようとして負荷を上げると、データ保全の観点で取り返しがつかない場合があります。ここでは、安全に再観測するための再現環境を、要素分解して固定する考え方を示します。
固定すべき4軸:差分が残ると結論が揺れる
再現で本当に必要なのは「同じ機器」より「同じ条件」です。最低限、次の4軸を固定・記録します。
| 軸 | なぜ重要か | 固定・記録の例 |
| 負荷 | 症状が負荷依存で出たり消えたりする | read/write比率、ランダム/シーケンシャル、I/O深度、同時ジョブ数 |
| 温度 | 境界条件で不安定化しやすい | 筐体吸排気、ファン回転、季節/時間帯、SMART温度 |
| 物理経路 | ケーブル/ポート/バックプレーンで症状が変わる | 同一スロット、同一ポート、同一ケーブル、同一HBA |
| 電源品質 | 瞬断・電圧降下・ノイズがリセットを誘発することがある | UPS有無、電源系統、PDU、冗長電源の片系運用有無 |
安全設計の基本:再現より「保全」が優先
現場の“心の会話”としてよくあるのが、「原因を突き止めたいけど、これ以上悪化させたくない」という葛藤です。これは健全な疑いです。再現の前に、まず次の優先順位を明文化します。
- データ保全(最優先):必要なら即時に読み取り中心の保全計画へ移る
- サービス継続:冗長構成ならフェイルオーバーや退避で影響を抑える
- 原因究明:安全な範囲で観測と切り分けを行う
この優先順位が曖昧だと、「ログを取りたい」気持ちで危険な負荷試験に進んでしまいます。特に媒体劣化が疑われる場合、再現試験は“壊す試験”になり得ます。ここは一般論では線引きできず、データ重要度・バックアップ状況・保守契約・復旧目標で決まります。
再現環境の現実解:本番と同等にせず、比較可能にする
理想は「本番と同じ構成で再現」ですが、現実には難しいことが多いです。そこで実務では、次の方針が有効です。
- 同等構成が無理なら、差分を減らす(同型筐体、同型HBA、同型ケーブル)
- 差分が残るなら、差分を記録して解釈に織り込む(世代差・ファーム差)
- 再現で得たいのは“派手な故障”ではなく、兆候の層と種類(timeout/reset/link/medium)
次章では、再現環境で「何を同時に取るべきか」を具体化します。dmesgだけを見ていると、また“消える”からです。
第8章:観測の設計──dmesgだけで終わらせず、smartctl・nvme-cli・journalctl・iostatを束ねる
削除ログ再現の実務で最重要なのは、「ログが消える前提」で観測を設計することです。dmesgは便利ですが、有限バッファであり、障害時ほど押し流されます。したがって、複数の観測点を束ねて同じ時刻に並べることが基本になります。
観測は“層ごと”に揃える:一つの証拠に依存しない
最小構成として、少なくとも次の4系統を揃えると、因果が追いやすくなります。
| 観測系統 | 目的 | 例 |
| カーネルログ | リセット、タイムアウト、エラー報告の一次情報 | journalctl -k、必要に応じてdmesg退避 |
| デバイス健全性 | 媒体劣化やエラー蓄積の兆候 | SATA/SAS: SMART(smartctl)、NVMe: SMART/ログ(nvme) |
| I/O統計 | 負荷依存・詰まり・遅延の可視化 | iostat、pidstat、vmstatなど |
| サービス側ログ | アプリへの影響の時刻合わせ | DBログ、アプリログ、監視アラート時刻 |
観測で絶対に外せない前提:時刻の整合
“同じ時刻に並べる”ために、時刻がズレていると解析が崩れます。NTP/chrony等で同期されているか、タイムゾーンが一致しているか、ログのタイムスタンプ形式が混在していないかを確認します。これは地味ですが、事実ベースの解析では致命的な差分になります。
ログが消える状況の典型:洪水と間引き
障害時にログが消えるのは、次の2パターンが多いです。
- 洪水(flood):同じ警告が大量に出て、ring bufferが短時間で上書きされる
- 間引き(rate limit):同じメッセージが抑制され、頻度や連鎖が見えにくくなる
この状況では、dmesg単独に頼ると「何も起きていないように見える」ことすらあります。そこで、観測を束ねます。たとえば、カーネルログが間引かれていても、I/O統計(待ち時間の上昇)やデバイス健全性(エラー累積)が同時刻に動いていれば、兆候は追えます。
“束ねる”とは何か:1本の線にする
束ねるとは、単にデータを集めることではなく、次のように「同時刻の出来事」を一つの線として読める形にすることです。
- 監視・アラートの発火時刻を起点にする
- 同時刻の
journalctl -kを抜き出す - 同じ窓でI/O統計(待ち時間/スループット)を確認する
- デバイス健全性(SMART/NVMe)で累積兆候を確認する
この手順により、ログが部分的に欠落していても「どの層が先に異常を出したか」を推定できます。推定は推定ですが、根拠が並びます。根拠が並べば、次章の「因果確定」に進めます。
伏線:終盤で効いてくる「一般論の限界」
ここで一つ、後半につながる伏線を置きます。観測が整ってくると、次に必ず出る問いがあります。「で、これは交換?それとも周辺?」「データ保全はどこまで急ぐ?」。ここは一般論が通用しづらい領域です。だからこそ、観測の事実を基に、個別案件として意思決定できる状態が必要になります。次章では、その“意思決定可能な因果”を作る手順に入ります。
第9章:因果を確定する手順──「疑わしい順」ではなく「壊れる順」で切り分ける
障害対応でありがちな落とし穴は、「経験則で疑わしいもの」から手を付けて、結果的に証拠を壊してしまうことです。ここで目指すのは、推測ではなく、観測された事実の順序で因果を積み上げることです。言い換えると、「壊れる順」に切り分けます。
切り分けの軸:先に出た層を起点にする
因果の確定は、次の問いに答える作業です。
- 最初に異常を示したのはどの層か(リンク/デバイス/ブロック/FS/アプリ)
- その層の異常が、上位層のエラーにつながる連鎖になっているか
- 同じ対象(同じ物理ディスク/同じポート)で再発しているか
ここが揃うと、単発ログが欠けていても「筋の通った説明」が可能になります。
実務手順:証拠を壊さずに“候補を潰す”
ここでは、安全側に倒した実務手順を提示します。環境により順序は入れ替わり得ますが、考え方は共通です。
ステップ1:まず「波及範囲」を確認する
同じ筐体で複数ディスクに兆候が出ているのか、特定ディスクだけなのかを確認します。複数に出るなら、ディスク単体よりも周辺(バックプレーン、HBA、電源、温度、筐体)を疑う根拠になります。
ステップ2:リンク系の兆候があるなら“先に”扱う
link down/upやリセットが先に出ている場合、ディスク交換だけでは解決しない可能性があります。ここで重要なのは「同じポートで再発するか」です。同じポートで再発するなら、物理経路の問題が濃くなります。
ステップ3:媒体劣化の兆候は“時間の味方をしない”
medium error系(読み出し不能、訂正不能、エラー累積)が疑われる場合、判断を先延ばしすると状況が悪化し得ます。ここでのポイントは、過剰な再現試験で追い込まないことです。観測の範囲で兆候が出ているなら、データ保全を優先する判断が現実的です。
「心の会話」:上司への説明が難しいのは、一般論では決められないから
現場の本音として、「交換すれば直ると言い切れない」「でも交換しない理由も説明しづらい」という苦しさがあります。これは、一般論では線引きできないからです。どこまでを“被害最小化”として優先するかは、RPO/RTO、保守契約、データ価値、停止許容時間、バックアップ状況で変わります。
だからこそ、説明の軸は「勘」ではなく「観測された順序」です。たとえば「リンクリセット→I/O timeout→FS警告」という順序が取れていれば、周辺起因の可能性を根拠付きで説明できます。逆に「特定ディスクの媒体エラー兆候→I/O error→FS read-only」という順序なら、ディスク起因の説明が可能です。
次章への伏線:終盤は“意思決定”の章になる
ここまでで、ログが消えても因果を作れる骨格ができました。次に必要なのは、「では現場として何を選ぶか」です。終盤では、導入・移行・保守・契約・構成の話に踏み込みます。一般論の限界を認めた上で、個別案件として設計し直す──そのときに、株式会社情報工学研究所のような専門家に相談する意味が自然に出てきます。
第10章:帰結:ログが消えても壊れた事実は消えない──“消える前提”で運用を組み替える
ここまでの結論はシンプルです。ログが消えたことは、原因が消えたことを意味しません。消えるのは「観測設計」がそうなっているからで、ハード障害やリンク不安定といった事象は、別の形でまた現れます。だから、やるべきことは「dmesgを頑張って読む」だけではなく、消える前提で運用を組み替えることです。
運用を組み替える3本柱:永続化・即時退避・相関
“削除ログ再現”が必要になる現場は、多くの場合、次の3つが不足しています。
- 永続化:カーネルログが後から追える形で保持されていない
- 即時退避:兆候が出た瞬間に、必要な範囲を切り出して退避できない
- 相関:I/O統計・デバイス健全性・アプリ影響が同じ時刻で並ばない
この3本柱が揃うと、「ログが少し欠けた」程度では結論が崩れにくくなります。
永続化:dmesg依存から脱却する
dmesg はring bufferの表示であり、保持の仕組みではありません。したがって、運用では「カーネルログを永続側に残す」設計が重要です。代表例としては、journaldでカーネルログを保持し、必要に応じてsyslogやログ集約へ転送します。
ただし、ここにはトレードオフがあります。ログを“全部”残そうとすると、障害時の洪水でストレージやCPUを圧迫し、別の問題を誘発することがあります。よくある対処は次のバランスです。
- 保持期間・容量を決める(「いつまで遡れれば意思決定できるか」)
- 重大度の高いイベントは外部に退避し、詳細はローカルに短期保持する
- rate limitの影響を前提に、別系統の観測(I/O統計、健全性)も併走させる
即時退避:障害対応の“最初の一手”を手順化する
現場の苦しさは、「後で見よう」と思った時点で、観測が不利になることです。したがって、障害時の最初の一手は「復旧作業」だけでなく、「証拠の退避」を含む手順にする必要があります。
ここで言う退避は、過剰な作業ではありません。たとえば「同時刻のカーネルログ抜き出し」「I/O統計のスナップショット」「デバイス健全性の要約取得」といった、短時間で終わる採取です。ポイントは、後で相関できる粒度で残すことです。
相関:時刻で“1本の線”にする
意思決定を可能にするのは、ログ単体ではなく「連鎖」です。たとえば次のように、同じ時間窓で揃っていると、因果の説明がしやすくなります。
| 観測 | 同時刻に見えると強い根拠 | 示唆 |
| カーネルログ | timeout / reset / link down などの一次兆候 | どの層が先に異常を示したか |
| I/O統計 | 待ち時間の上昇、キュー滞留、スループット低下 | 負荷依存か、詰まりか、瞬断か |
| 健全性情報 | エラー累積、寿命指標の悪化、温度上昇 | 媒体劣化か、環境要因か |
| アプリ影響 | 同時刻の遅延/失敗、再試行の増加 | 業務影響と優先度判断 |
“一般論の限界”を正面から扱う:運用設計は契約と要件で決まる
ここで必ず出るのが、「結局どうすれば安全か」という問いです。しかし、これは一般論で一刀両断できません。データが重要でバックアップが薄いなら、再現より保全が優先です。冗長が強く交換が容易なら、周辺を含めた段階的交換で“歯止め”をかけられることもあります。監視・ログ保持の強化も、保持コストやセキュリティ要件(機密情報の扱い)で線引きが必要です。
だからこそ、ここまで積み上げた「観測→相関→因果」の枠組みが意味を持ちます。事実ベースで説明できれば、現場の判断が孤立しにくくなり、組織として“場を整える”ことができます。
次章への伏線:最後は「意思決定」と「相談」の章になる
終盤では、具体的に「どのパターンなら何を優先すべきか」を整理し、一般論の限界を認めた上で、個別案件として設計し直す導線を作ります。そのとき、株式会社情報工学研究所のような専門家に相談する価値が、押し付けではなく自然に浮かび上がる形にします。
第11章:終盤の実務整理──パターン別に「優先順位」と「次の一手」を決める
ここからは、現場が実際に悩む「次の一手」を、観測パターン別に整理します。重要なのは、“正解探し”ではなく、被害最小化の優先順位を明確にして、意思決定を前に進めることです。
パターン別:観測された事実から優先順位を決める
| 観測パターン | 示唆 | 優先すべき次の一手(例) |
| link down/up や reset が先行し、複数ディスクに波及 | 周辺(ケーブル/バックプレーン/HBA/電源/温度)起因の可能性が高い | 物理経路の点検・差し替え、同一ポート再発の確認、ログ相関の強化 |
| 特定ディスクで timeout が増え、I/O待ちが伸びる | デバイス応答遅延(負荷・温度・寿命・FW要因)の可能性 | 負荷条件の把握、温度/電源の確認、健全性情報の確認、保全計画の検討 |
| 媒体劣化を示す兆候が累積し、I/O error が出る | 媒体起因の可能性が高く、時間経過で悪化し得る | 安全側へ(保全優先、不要な負荷を避ける、復旧手順の確立) |
| FSがread-only化/整合性警告、下位層にI/O兆候 | FSは保護動作。原因は下位層にあることが多い | 下位層ログの収集、影響範囲の確認、復旧と保全の両立設計 |
「心の会話」:結局、交換?保全?どっち?
「交換すれば早い。でも交換しても直らなかったら?」
「保全したい。でも保全のための作業が業務を止めるかも…」
こういう迷いは自然です。ここで大事なのは、迷いを“気合い”で押し切らず、意思決定の材料を揃えることです。材料とは、観測された順序と、影響の範囲と、データの重要度です。どれかが欠けると、結論が揺れ続けます。
終盤で効く現実:個別案件では判断基準が変わる
同じログでも、判断は案件で変わります。たとえば、バックアップが直近で確認できていて復元手順も確立しているなら、切り分けの自由度は上がります。逆に、バックアップが不確実でデータ価値が高いなら、再現試験よりも保全を優先する判断が合理的になります。さらに、保守契約や冗長構成の有無によって、交換やフェイルオーバーの選択肢が変わります。
相談が必要になる境界:一般論で決めると事故るところ
ここまでの枠組みで多くのケースは整理できますが、現場には「一般論で決めると危ない境界」があります。たとえば次のような状況です。
- 症状が断続的で、再現条件が複数要因(負荷×温度×経路)にまたがる
- 仮想化やSAN、RAID、暗号化などで、物理と論理の対応が複雑
- 業務影響が大きく、止められないまま原因究明と保全を両立する必要がある
- 法務・監査・BCPの観点で、証跡性(ログの保持と説明責任)が求められる
この領域では、「正しそうな一般論」を当てはめるだけだと、判断ミスのリスクが上がります。観測設計、構成理解、保全手順、説明資料まで含めて、個別案件として設計する必要があります。
次回への伏線:最終章で“自然な次の一歩”へつなぐ
次の章で、本記事を締めくくります。締めくくりでは、一般論の限界を認めた上で、読者が「じゃあ自分の案件ではどう設計し直す?」に進めるよう、相談の観点(準備すると話が速い情報、見落としやすい論点、契約・構成の整理)を提示します。そこで、株式会社情報工学研究所への相談・依頼を“押し売りではなく合理的な選択肢”として検討できる形にします。
第12章:締めくくり──「消えるログ」に振り回されないために、現場の意思決定を“整流”する
本記事で一貫して伝えたかったのは、「dmesgを上手に読む」より前に、ログが消える前提で意思決定できる状態を作ることです。ring bufferは有限で、障害時ほど押し流されます。rate limitで間引かれ、ドライバの言い回しで同じ事象が別名に見えます。だから、dmesgだけで勝負すると、どうしても「見えなかったもの」に引っ張られます。
一方で、層(リンク/デバイス/ブロック/FS/アプリ)を意識して、同時刻にカーネルログ・I/O統計・健全性情報を束ねれば、たとえ一部のログが欠けても「壊れる順」で因果が作れます。因果が作れれば、現場の説明が通りやすくなり、無駄な疑心暗鬼や“勘のぶつかり合い”が減ります。ここが、実務での被害最小化につながります。
一般論の限界:最後は「案件の条件」で結論が変わる
ただし、最後の一手(交換か、保全か、構成変更か、運用強化か)は、一般論で決め切れません。バックアップの確実性、停止許容時間、冗長構成、保守契約、データ価値、法務・監査・BCP上の制約で、合理的な判断は変わります。
たとえば、同じ「timeout」でも、業務停止が許されない環境では“場を整える”ために段階的な退避・フェイルオーバー・ログ相関の強化を先に打つことがあります。逆に、媒体劣化が強く疑われ、データが最重要なら、再現より保全を優先するのが合理的です。ここは、現場の事情を織り込んだ設計問題であり、単純なテンプレ回答が危険になる領域です。
次の一歩:相談が速く進む「準備チェックリスト」
もし「自分の案件では、どこから手を付けるべきか」で悩んだら、次の情報を揃えるだけで、相談や切り分けが一気に前に進みます(すべてを完璧に揃える必要はありません)。
- 発生時刻の窓:影響が出た時刻(±10〜30分程度の範囲)
- 構成情報:物理(筐体/HBA/ケーブル/スロット)と論理(RAID/SAN/VM/暗号化/FS)の対応関係
- 観測の3点セット:同時刻のカーネルログ(可能ならjournalctl -k相当)、I/O統計の傾向、デバイス健全性(SMART/NVMeログの要点)
- 影響範囲:単一ディスクか、複数ディスク/複数ホストに波及しているか
- 運用条件:バックアップ状況、復元手順の有無、RPO/RTO、停止の可否
- 変更履歴:直近のファーム更新、ケーブル交換、負荷増、カーネル/ドライバ更新、筐体移設など
この情報がそろうと、「ログが消えている」こと自体を前提に、因果を組み直して、現場にとって現実的な選択肢(交換・保全・構成変更・運用強化)を並べられます。
相談・依頼を検討するタイミング:判断が“揺れ続ける”とき
次のような状態に入っているなら、個別案件として整理する価値が高いです。
- 症状が断続的で、再現条件が複合(負荷×温度×経路)になっている
- 仮想化/SAN/RAID/暗号化などで、物理と論理の対応が複雑
- 止められない前提で、保全と原因究明を同時に進める必要がある
- 監査・BCP・説明責任の観点で、証跡性(保持と説明)が求められる
この領域では、一般論を当てはめるだけだと事故リスクが上がります。観測設計・構成理解・保全計画・説明資料まで含めて組み立てる必要があります。そういう局面では、株式会社情報工学研究所のような専門家に相談して、状況に合った“歯止め”の打ち方を一緒に設計するのが現実的です。
付録:現在のプログラム言語各種にそれぞれの注意点(I/O障害・ログ欠落に強い実装のコツ)
カーネルやハードの問題はアプリだけでは直せません。ただし、アプリ側の作り次第で「被害最小化」や「原因追跡のしやすさ」は大きく変わります。ここでは、言語別に“やりがちな落とし穴”を事実ベースで整理します。
| 言語/実行環境 | 注意点(障害時に差が出るところ) |
| C / C++ | - read/writeは部分読み書きやEINTRがあり得るため、戻り値とerrnoの扱いを厳密にする
- fsync/flushの有無で「書けたつもり」問題が起きる(要件に合わせて明示する)
- ログにデバイス/オフセット/対象ファイル/errnoを残さないと、後から相関できない
|
| Rust | - Resultの伝播でエラーは扱いやすいが、原因特定には「どのI/O(パス/オフセット/対象)」かを付加情報として持たせる
- 非同期(tokio等)ではキャンセルやタイムアウトがI/Oエラーに見えることがあるため、境界(timeoutか実I/Oか)をログで区別する
|
| Go | - defer closeは便利だが、エラー処理が流れやすいのでclose/fsyncの失敗を拾う設計にする
- contextのタイムアウト/キャンセルと実I/O失敗が混ざると原因が曖昧になるため、ログで分離する
- goroutineの並行I/Oは“詰まり”を増幅し得る。障害時の再試行は雪だるまになりやすい
|
| Java(JVM) | - NIO/ファイルチャネルはバッファリングやflush/forceの扱いで永続化のタイミングが変わる(要件で明示)
- 例外のラップで根本原因が見えにくくなることがあるため、最下層例外とメッセージを保持する
- GCやスレッドプール枯渇がI/O遅延と同時に起きると誤認しやすいので、I/O統計と相関する
|
| Python | - バッファリングが強いので、flush/fsyncの要否を要件で決める(ログや重要データは特に)
- 例外を握りつぶすと後から追えない。例外種別とOSエラー(errno相当)をログに残す
- 多重スレッド/プロセスで同一ファイルを扱う場合、ロックやclose漏れで“別問題”を作りやすい
|
| Node.js(JavaScript/TypeScript) | - Streamはbackpressureの扱いが重要。詰まりが増えると障害時の遅延を増幅し得る
- エラーイベントを取りこぼすと「静かに壊れる」形になるので、error/closeの扱いを徹底する
- 再試行は“同時に増やす”より“間引いて整列させる”ほうが被害最小化につながりやすい
|
| PHP | - 警告/例外の扱いを統一し、I/O失敗時に黙って進まないようにする
- fwrite等の戻り値(書けたバイト数)を確認しないと部分書き込みを見落とす
- ロックや同時実行でファイル破損リスクが上がるため、運用(実行タイミング)も含めて設計する
|
| Ruby | - 例外処理を握りつぶさず、I/O系例外は必ず記録・通知につなげる
- バッファやflush/fsyncの要否を要件で決め、ログや重要ファイルは曖昧にしない
|
| .NET(C#) | - using/Disposeでクローズはされるが、Flush/Flush(true)/fsync相当の要否を要件で明示する
- 非同期I/Oではキャンセルと実I/O失敗が混ざることがあるため、ログで分けて残す
- 例外の内側(InnerException)に原因があることが多いので、必ず保持して記録する
|
どの言語でも共通して重要なのは、(1)I/O失敗を握りつぶさない、(2)「どの対象で何が起きたか」をログに残す、(3)再試行は無制限に増やさず“整列”させる、(4)カーネル/ハード起因の兆候が出たらアプリ側の対処に過信しない、の4点です。これができていると、dmesgが押し流されても、後から相関して説明できる確率が上がります。
最後に:読者の悩みが「構成・契約・運用」の領域に入ったら
ここまで読んで、「自分の案件は一般論では決められない」と感じたなら、その感覚は正しいです。構成が複雑だったり、止められなかったり、証跡性が必要だったりするほど、判断は“設計”になります。そういうときは、株式会社情報工学研究所への相談・依頼を検討し、観測設計から保全、説明資料まで含めて、現場が納得できる形で“歯止め”を打つことをおすすめします。