目次
- はじめに
- データ復旧の基本概念
- Windowsサーバーにおけるデータ復旧の概要
- ハードディスク故障の種類と原因
4.1 物理的な損傷
4.2 内部不良
4.3 振動や衝撃による故障
4.4 その他の障害(過熱、ファームウェアの不具合、ロジック障害など) - 各障害種別における復旧プロセスと所要時間
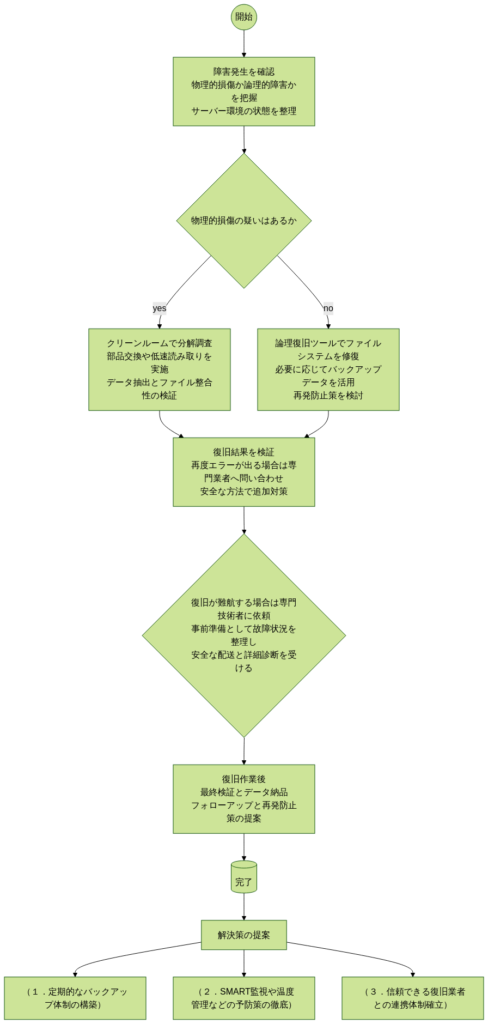
5.1 物理的損傷の場合
5.2 内部不良の場合
5.3 振動や衝撃による故障の場合
5.4 ロジック障害・その他の障害の場合 - ハードディスクの予防策と定期メンテナンス
- 信頼できるデータ復旧業者への依頼:情報工学研究所の場合
7.1 依頼前の事前準備と問い合わせ
7.2 初期診断と詳細診断
7.3 作業工程と修復作業
7.4 データ抽出、検証、納品までの流れ
7.5 アフターサポートと保証期間 - ケーススタディと成功事例
- よくあるトラブルとその対策
- おわりに
1. はじめに
Windowsサーバーは企業の業務基盤やデータセンターにおいて、重要な役割を担っています。しかし、サーバー運用においてもハードディスク故障というリスクは常に存在します。物理的な衝撃、部品の摩耗、内部不良、さらには振動や衝撃といった外部要因による故障は、データ損失の大きな要因となります。したがって、Windowsサーバーにおける定期的なメンテナンス、バックアップ体制の確立、そして万が一の場合に迅速かつ正確に対応できる復旧プロセスの構築が不可欠です。
本レポートでは、Windowsサーバー環境に特化したハードディスク故障の各種障害と、その復旧プロセス、各工程の所要時間、さらには信頼性の高いデータ復旧業者「情報工学研究所」に依頼した際の流れについて、細部にわたって解説いたします。各セクションでは、具体的な工程、対策、実施時の注意点などを豊富な副題とともにご紹介し、システム管理者や企業担当者の皆様が万全の対策を講じるための参考資料としてご活用いただける内容となっています。
2. データ復旧の基本概念
2.1 データ復旧とは
データ復旧とは、ハードディスクの故障や誤操作、ウイルス感染、自然災害などによりアクセス不能になったデータやシステムを、可能な限り元の状態に復元する技術およびプロセスです。Windowsサーバーの場合、NTFSやReFSといったファイルシステムに依存しているため、各種障害に対してファイルシステム固有の復旧手法が求められます。
2.2 物理復旧と論理復旧の違い
物理復旧
ハードウェアの物理的損傷(プラッターの傷、ヘッドクラッシュ、モーター故障など)に対する修復。専用のクリーンルーム環境や特殊装置が必要となり、非常に高度な技術が要求されます。論理復旧
ファイルシステムの破損、パーティションテーブルのエラー、ウイルス感染など、ソフトウェアレベルの問題に対する対応。専用のソフトウェアツール(例えば、Windows Server Backup、CHKDSK、第三者製のデータ復旧ソフトウェアなど)を用いて実施されます。
2.3 復旧作業におけるリスクと注意点
復旧作業は、故障ディスクに対する更なるダメージを防ぐため、慎重かつ計画的に実施する必要があります。特に、物理的損傷が確認された場合、無理な操作はかえってデータ損失のリスクを増大させるため、専門技術者による作業が推奨されます。また、論理復旧においても、作業前のディスクのバックアップや、読み取り専用モードでの作業を徹底することが重要です。
3. Windowsサーバーにおけるデータ復旧の概要
3.1 Windowsサーバー特有のファイルシステムと構成
Windowsサーバーは、NTFS、ReFS、FAT32などのファイルシステムを採用しており、また、RAID構成やストレージプール、仮想ディスク(VHD/VHDX)など、多彩なストレージ構成が存在します。これらの構成は、復旧作業において各ファイルシステムやストレージ技術固有の対応が必要となるため、専門知識と最新の復旧ツールが要求されます。
3.2 復旧ツールとソフトウェアの活用
Windowsサーバー環境では、CHKDSK、Windows Server Backupなどの各種復旧ツールが利用されています。これらは、論理復旧に対して有効である一方、物理的損傷の場合は専用設備やクリーンルーム環境での作業が不可欠となります。
3.3 復旧成功率の向上要因
復旧成功率は、障害の発生状況、故障からの経過時間、サーバーのハードウェア構成、そして定期バックアップの有無に大きく依存します。迅速な対応と正確な診断、さらに最新の復旧技術の活用が、成功率の向上に寄与します。
4. ハードディスク故障の種類と原因
Windowsサーバーにおいても、ハードディスク故障の原因は多岐にわたります。以下に、主な故障原因とその特徴を解説します。
4.1 物理的な損傷
概要
外部からの衝撃、落下、異物混入、摩耗やヘッドクラッシュなどにより、ディスク内部のプラッター、ヘッド、アクチュエータなどの物理部品が直接損傷を受ける場合を指します。主な原因
- 落下・衝撃による外部力の作用
- 長期間の使用による摩耗・経年劣化
- 異物侵入や不適切な取り扱いによる内部損傷
影響
プラッター表面の傷、ヘッドの損傷、モーターの停止などにより、データ読み取りが不可能となり、データ自体が破損する可能性がある。
4.2 内部不良
概要
電子部品の故障(基板、コネクタ、回路部品など)が原因で、ディスク全体の認識ができなくなる、または断続的にエラーが発生する場合。主な原因
- 電圧変動や電源不安定による電子部品の劣化
- 製造時の微細な欠陥
- 長期間使用による部品の自然劣化
影響
基板の不良により、ディスク自体がOSに認識されなくなる、または内部のセンサーが正しく動作しなくなるため、データ抽出が困難に。
4.3 振動や衝撃による故障
概要
サーバー搬送時や設置環境での継続的な振動、衝撃が蓄積し、ヘッドとプラッターの微妙な位置ズレや接触が発生することで、局所的な損傷が引き起こされる。主な原因
- 運搬中の振動・衝撃
- 設置場所の振動(工場内、データセンターの床振動など)
- 長期間にわたる小さな衝撃の積み重ね
影響
特定のセクタに対して読み取りエラーが頻発、局所的なデータ損失、断続的なアクセス不能が発生する。
4.4 その他の障害(過熱、ファームウェアの不具合、ロジック障害など)
概要
ハードウェアの物理的損傷が見られない場合でも、過熱やファームウェアのバグ、ソフトウェアレベルでの論理エラーなどが原因で発生する障害も存在します。主な原因
- 過熱による部品の一時的な不調
- ファームウェアの不具合、バグ、アップデートミス
- 不適切なシャットダウンや電源障害によるファイルシステムの破損
影響
ディスク自体は正常に動作しているように見えても、ファイルシステムの論理エラーやパーティションの不整合により、データへのアクセスが困難になる。
5. 各障害種別における復旧プロセスと所要時間(1日~数日)
ここでは、Windowsサーバーで発生する各種ハードディスク故障に対して、復旧に必要な具体的な工程とおおよその作業時間について詳述します。なお、実際の作業時間は故障の状態、作業環境、技術者の熟練度、さらには使用する機材やソフトウェアの性能により変動するため、以下はあくまで一般的な目安です。
5.1 物理的損傷の場合
5.1.1 初期診断と現物確認
- 内容
・ディスク外観検査(ケースの損傷、異音、振動の有無)
・SMART情報やログの確認
・専用診断ツールによる初期状態の把握 - 所要時間:30分~1時間
※現場で大まかな故障状況を把握するための初期評価。
5.1.2 クリーンルームでの分解および内部検査
- 内容
・専用クリーンルーム環境下でディスクの分解
・プラッター、ヘッド、アクチュエータの状態検査
・異物混入や埃、傷の有無の確認 - 所要時間:2~3時間
※静電気対策や厳重な管理下で実施するため、慎重な作業が求められる。
5.1.3 損傷部品の修復・交換
- 内容
・物理的に破損したヘッド、プラッターの一部、基板部品の特定
・同一規格部品との交換作業、もしくは修復処置
・微細な調整作業によるヘッド位置の補正 - 所要時間:3~6時間、場合により1日以上
※部品調達の状況や交換作業の複雑さにより時間が変動。
5.1.4 低速読み取りモードでのデータ抽出
- 内容
・修復後、専用読み取り装置によりプラッターからデータをセクター単位で抽出
・エラーリトライや冗長読み取りにより断片的データの確保
・抽出データの初期統合作業 - 所要時間:半日~2日
※ディスクの状態およびデータ量に依存。
5.1.5 データ整合性の検証とバックアップ作成
- 内容
・抽出したデータのファイルシステム整合性チェック
・必要に応じた再補完、エラー訂正作業
・最終的なバックアップの作成と検証 - 所要時間:1日~場合により2日
5.1.6 最終レビューと納品準備
- 内容
・全工程の総合レビュー、作業報告書の作成
・ユーザーとの最終確認、納品メディアへの書き込み
・最終検査および動作確認 - 所要時間:数時間~1日
5.2 内部不良の場合
5.2.1 電子基板および回路の初期診断
- 内容
・外観検査と専用診断ツールによる基板の電圧・信号チェック
・部品の焦げ跡や断線、変色の確認 - 所要時間:30分~1時間
5.2.2 不良部品の交換および再調整
- 内容
・故障したコンデンサ、IC、その他回路部品の交換
・部品交換後の再調整と動作確認 - 所要時間:2~4時間
※部品供給状況により変動することもある。
5.2.3 ファームウェアの再書き込みおよび更新
- 内容
・ファームウェアの不具合が疑われる場合、最新安定版への再書き込み
・制御プログラムの再同期とテスト - 所要時間:1~2時間
5.2.4 読み取り環境の構築とデータ抽出
- 内容
・部品交換後、ディスク認識の正常化を確認
・低速モードでの安全なデータ抽出作業 - 所要時間:半日~1日
5.2.5 論理エラーの修復とデータ検証
- 内容
・CHKDSK、専用復旧ソフトによるファイルシステム検証
・論理エラーの修正、欠損データの補完作業 - 所要時間:1日~2日
5.2.6 最終検査とユーザーへの納品
- 内容
・修復後のディスクおよびデータの最終検証
・報告書作成と納品メディアへの書き込み、ユーザー環境への移行サポート - 所要時間:数時間~1日
5.3 振動や衝撃による故障の場合
5.3.1 初期診断および不良セクターの特定
- 内容
・ディスク全体の読み取りテスト、特定セクターにエラーが集中しているかを確認
・イベントログの解析により振動や衝撃の影響箇所を特定 - 所要時間:1~2時間
5.3.2 ヘッドとプラッターの状態評価
- 内容
・専用検査装置によるヘッド位置、プラッター表面の微細な損傷の確認
・測定機器によるセクターごとの状態評価 - 所要時間:1~2時間
5.3.3 補正および微調整作業
- 内容
・ヘッド位置の微調整、セクターごとの読み取りパラメータの最適化
・低速読み取りモードでの再試行によるエラーの最小化 - 所要時間:2~4時間
5.3.4 複数回読み取りによるデータ抽出
- 内容
・影響セクターのデータを、複数回の読み取りにより冗長性を確保しながら抽出
・エラーリトライ機能を活用した断片データの収集 - 所要時間:半日~1日
5.3.5 データ統合とファイルシステム再構築
- 内容
・断片的なデータの統合、補完処理によるファイルシステムの再構築
・整合性チェックおよびエラーチェックの実施 - 所要時間:1日~2日
5.3.6 納品前の最終検査とバックアップ作業
- 内容
・ユーザー引渡し前の最終チェック、バックアップの作成
・報告書作成とユーザーへの中間連絡 - 所要時間:数時間~1日
5.4 ロジック障害・その他の障害の場合
5.4.1 ファイルシステム整合性チェックと論理検証
- 内容
・CHKDSK、ReFS修復ツールなどを用いて、論理的なエラーや不整合の検出
・システムログ、イベントビューワーによるエラー解析 - 所要時間:30分~1時間
5.4.2 論理復旧ツールの適用とデータ抽出
- 内容
・専用ソフトを使用して、破損パーティションやファイルシステムの復元
・必要に応じた手動介入によるデータ抽出の補正 - 所要時間:数時間~1日
5.4.3 抽出データの統合とエラー訂正
- 内容
・断片データの統合、欠損部分の補完、エラー訂正処理の実施
・ファイルシステムの再構築およびデータ検証 - 所要時間:1日~2日
5.4.4 最終検証とユーザー環境への移行準備
- 内容
・最終的なデータ整合性のチェック、復旧ディスクの再フォーマットと新規パーティション作成
・ユーザーへの納品準備と動作確認 - 所要時間:数時間~1日
6. ハードディスクの予防策と定期メンテナンス
ハードディスクの故障リスクを最小限に抑えるためには、日常的な予防措置と定期メンテナンスが極めて重要です。ここでは、Windowsサーバー環境における予防策について、具体的な対策とその実施方法を詳述します。
6.1 定期バックアップの実施と検証
- 概要
障害発生前のデータ保全が最も効果的な対策です。Windows Server Backupやサードパーティ製バックアップソフト、クラウドバックアップサービスなどを活用し、定期的なバックアップとリストアテストを実施します。 - 実践方法:
・スケジュール設定による自動バックアップ
・定期的なバックアップデータの整合性チェック
・オフサイトバックアップの活用 - 所要時間:
初期設定に数時間~1日、検証作業は月単位で数十分~数時間
6.2 SMART監視システムの導入
- 概要
Self-Monitoring, Analysis and Reporting Technology(SMART)を利用し、ハードディスクの健康状態を常時監視します。異常値が検出された場合は、速やかに対策を講じることができます。 - 実践方法:
・専用ツール(CrystalDiskInfo、smartmontools等)による自動監視
・定期レポートの作成と管理者へのアラート通知 - 所要時間:
初期設定は数十分~数時間、運用は自動化で管理負荷を軽減
6.3 適切な温度・湿度管理と設置環境の整備
- 概要
過熱や高湿度はハードディスクの寿命を著しく短縮させるため、サーバールームの空調設備や環境モニタリングシステムの導入が不可欠です。 - 実践方法:
・室内温度、湿度の常時監視と自動調整
・防振材の使用による振動対策 - 所要時間:
初期設備導入に数日~数週間、定期点検は月単位で数十分
6.4 定期的なファームウェア・ドライバーの更新
- 概要
Windowsサーバーや接続されるストレージデバイスは、最新のファームウェアおよびドライバーに更新することで、既知のバグやセキュリティリスクを低減できます。 - 実践方法:
・メーカー提供のアップデート情報の定期確認
・テスト環境での事前検証後、本番環境への反映 - 所要時間:
アップデート自体は数十分~数時間、テスト含めると数日
| 対応策 | メリット | デメリット |
|---|---|---|
| 定期バックアップの実施と検証 | ・データ損失リスクの低減 ・迅速なシステム復旧が可能 |
・運用コストがかかる ・定期的なチェックやテストが必要 |
| SMART監視システムおよび診断ツールの活用 | ・初期異常の早期検知 ・事前対策の立案が可能 |
・ツールの精度に限界がある ・誤検知のリスクが存在 |
| 基本的な復旧ツール(CHKDSK、Windows Server Backup等)の使用 | ・簡易な論理障害なら低コストで対応可能 ・ツール利用で手順が明確 |
・物理的損傷や複雑な障害には対応不可 ・誤操作によりさらなるデータ損傷の恐れ |
| 読み取り専用モードでのデータ抽出試行 | ・元ディスクへの追加ダメージを防止 ・セーフなデータ抽出が可能 |
・抽出に失敗する可能性がある ・専用機器や知識が必要な場合も |
| 冷静な状況判断と、必要時に専門業者へ依頼する準備 | ・状況把握により最適な対応策が選択可能 ・問題拡大を防ぐ |
・自己判断で状況を悪化させるリスク ・専門知識不足の場合、適切な判断が困難 |
7. 信頼できるデータ復旧業者への依頼:情報工学研究所の場合
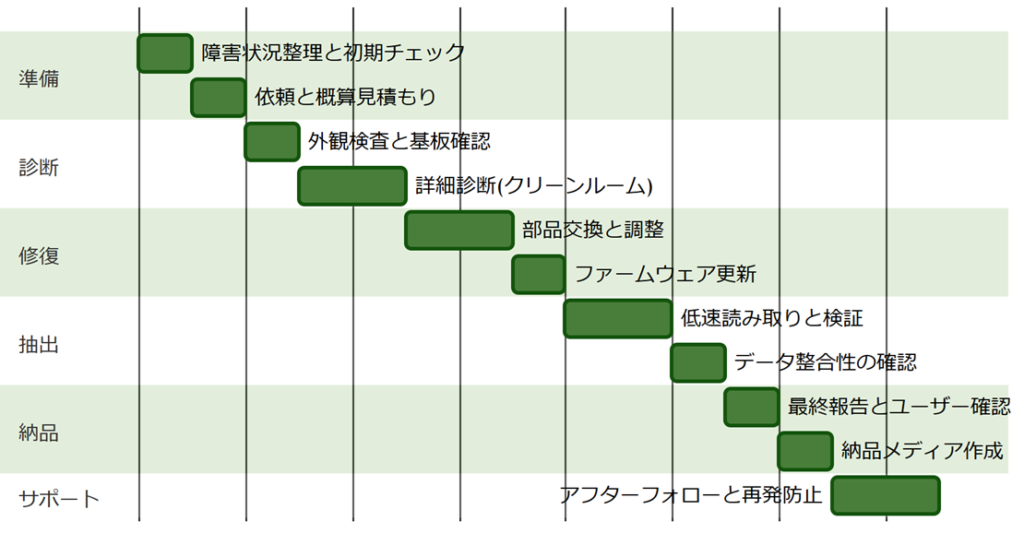
ハードディスク故障が深刻な場合、専門業者によるデータ復旧が最も安全で確実な手段となります。ここでは、非常に信頼性の高いデータ復旧業者「情報工学研究所」に依頼する際の、依頼前の準備から納品までの一連の流れを、できるだけ多くのステップと要素を盛り込みながら詳細に解説します。
7.1 依頼前の事前準備と問い合わせ
7.1.1 障害状況の詳細整理と初期チェック
- 内容
・故障の症状、発生時刻、前後の状況(例えば、システムエラー、異音、ブルースクリーン等)の記録
・自己診断ツール(Event Viewer、SMARTレポート等)による初期検査結果の収集 - 所要時間:数十分~1日
7.1.2 問い合わせと初回相談の予約
- 内容
・情報工学研究所の問い合わせ窓口(電話、メール、Webフォーム)への連絡
・故障状況の説明、初回相談日時の調整、概算見積もりの提示 - 所要時間:問い合わせ自体は即時~数十分、初回相談は1~2日以内に実施
7.2 初期診断と詳細診断の工程
7.2.1 梱包と安全な配送手配
- 内容
・ディスクの静電気対策、振動防止策を施した専用梱包材でのパッキング
・信頼できる配送業者による追跡可能な配送手配 - 所要時間:梱包作業は1~2時間、配送期間は地域により1~3日
7.2.2 業者側での初期診断と状況評価
- 内容
・受領後、情報工学研究所の専門技術者による外観検査、電子診断装置での初期評価
・障害原因の大まかな分類(物理的、内部不良、論理的など)の確定 - 所要時間:1~2日以内に初期診断報告を提出
7.2.3 詳細診断および原因の特定
- 内容
・クリーンルーム環境下での分解・詳細検査
・各部品の個別チェック、読み取りテスト、障害箇所の特定
・診断結果を詳細レポートとしてまとめ、ユーザーへのフィードバック - 所要時間:1~3日(場合によりさらに精密な診断が必要なケースもあり)
7.3 作業工程と修復作業の進行
7.3.1 作業計画の策定と見積もり提示
- 内容
・詳細診断結果に基づいた復旧作業計画の策定
・各工程ごとの作業期間、費用見積もり、リスク管理計画の提示
・ユーザーとの打ち合わせを経て最終的な作業計画を確定 - 所要時間:診断完了後、1日以内に提示
7.3.2 ユーザーとの同意・契約締結
- 内容
・見積もりと作業計画に対するユーザーの確認および同意
・契約書の作成、保証内容、トラブル発生時の対応策等の明記 - 所要時間:即時~1日、契約書の確認には数時間~1日
7.3.3 復旧作業の開始
- 内容
・クリーンルーム内での物理修復作業、部品交換、ファームウェア更新
・各工程の進捗状況を中間報告としてユーザーへ連絡
・作業中のリスク管理と適宜対応策の実施 - 所要時間:物理修復の場合は1~3日、内部不良の場合は半日~1日
7.4 データ抽出、検証、納品までの工程
7.4.1 修復後のデータ抽出作業
- 内容
・修復完了後、専用装置を用いたセクター単位でのデータ読み取り
・エラーリトライおよび低速読み取りモードでの断片データ抽出
・初期統合処理によるデータの再配置 - 所要時間:半日~2日
7.4.2 抽出データの検証および品質チェック
- 内容
・抽出データに対するファイルシステム整合性チェック
・不足部分の補完作業、論理エラー修正のための再抽出
・最終的な品質検証とテスト環境での動作確認 - 所要時間:1日~2日
7.4.3 中間報告とユーザー連絡の実施
- 内容
・各工程完了時に進捗報告、現状データの状態をユーザーへ詳細に説明
・ユーザーからのフィードバックを反映し、柔軟な対応を実施 - 所要時間:各工程ごとに数時間~1日以内
7.4.4 最終検査と納品準備、納品作業
- 内容
・全工程完了後、最終検査によるデータ完全性の確認
・納品メディア(外付けディスク、クラウドストレージ等)への書き込み
・納品報告書の作成とユーザーへの発送、オンラインでの最終打合せ - 所要時間:数時間~1日
7.5 アフターサポートと保証体制
7.5.1 納品後のサポート体制の整備
- 内容
・納品後、ユーザー側でのデータ検証やシステム復旧状況の確認サポート
・サポート窓口の設置、問い合わせ対応、追加調整が必要な場合の迅速な対応 - 所要時間:納品後1ヶ月~3ヶ月の保証期間中に対応
7.5.2 定期フォローアップおよび再発防止策の提案
- 内容
・業務完了後、定期的なフォローアップ訪問またはオンラインミーティング
・再発防止策、予防メンテナンスのアドバイス、システム運用の改善提案 - 所要時間:保証期間内に数回のフォローアップ実施
8. ケーススタディと成功事例
8.1 ケーススタディ1:物理的損傷による完全破損からの復旧
- 背景
長期間稼働していたWindowsサーバーで、突発的な落下事故によりハードディスクが物理的に激しく損傷。プラッターに多数の傷が確認され、ヘッドクラッシュの疑いが強い状況。 - 工程概要:
・初期診断にて物理的損傷の確証
・クリーンルーム内でのディスク分解と内部検査
・ヘッドアセンブリの交換およびプラッター部分修復
・低速読み取りモードを複数回適用したデータ抽出
・最終検証でシステム起動に必要なファイルを完全復元 - 所要時間:全体で約1週間程度
- 成功要因:迅速な初期診断、最新のクリーンルーム設備、専門技術者による正確な修復作業
8.2 ケーススタディ2:内部不良によるディスク認識不良の修復
- 背景
Windowsサーバーで内部不良により、ディスクがOS上で全く認識されず、SMARTエラーが多数報告された事例。 - 工程概要:
・電子基板の不良部品の特定と交換
・ファームウェアの再書き込みによるディスク認識の回復
・低速読み取りモードでのデータ抽出および論理エラーの修正
・最終検証にてシステムファイルの完全復元 - 所要時間:全体で約3日~5日
- 成功要因:内部不良の迅速な特定と、基板交換後の精密な再調整
8.3 ケーススタディ3:振動や衝撃による部分的データ損失からの復旧
- 背景
サーバー搬送時の振動が原因で、特定セクターが読み取り不能となったWindowsサーバー。イベントログに複数の読み取りエラーが記録される。 - 工程概要:
・初期診断により振動影響領域を特定
・ヘッド位置の微調整およびパラメータ最適化による補正作業
・複数回の読み取りによる断片データの抽出と統合
・ファイルシステム再構築および最終検証 - 所要時間:約4日~1週間
- 成功要因:集中エリアの正確な特定と、複数回の読み取りによるデータ冗長性確保
9. よくあるトラブルとその対策
9.1 途中でのデータ破損リスクの管理
- 対策:
・初期診断前に、ディスクへの不要なアクセスを完全に遮断
・読み取り専用モードでの作業を徹底し、元ディスクへの書き込みを一切行わない
・各工程ごとにバックアップを取得し、作業中のデータ損傷リスクを最小限に
9.2 予期せぬエラー発生時の対応策
- 対策:
・エラー発生時には即時作業を中断し、詳細なログとエラーメッセージを記録
・工程ごとの見直しと、再試行のための柔軟な作業計画の策定
・必要に応じて、別の復旧手法やツールの併用を検討
9.3 ユーザーとのコミュニケーション不足への対応
- 対策:
・各工程完了時に詳細な中間報告を実施し、ユーザーとの定期連絡を確保
・疑問点や追加要求に対し、迅速かつ透明性のある説明を実施
・復旧進捗状況の定期的な報告と、必要時のオンラインミーティングの開催
9.4 再発防止策の提案不足とフォローアップ
- 対策:
・納品後も定期的なフォローアップを行い、システム全体の健康状態のアドバイスを提供
・再発防止のための定期メンテナンス、バックアップ体制の再確認と改善提案
・ユーザーからのフィードバックを基に、将来的なリスク対策の詳細なレポートを作成
10. おわりに
本レポートでは、Windowsサーバーにおけるハードディスク故障の原因、各種障害に対する復旧プロセス、各工程ごとの具体的なステップおよび所要時間、さらに信頼性の高いデータ復旧業者「情報工学研究所」に依頼した際の一連の流れについて、可能な限り多くの副題と要素を盛り込みながら詳細に解説いたしました。
Windowsサーバー環境は、企業の重要データを保持する基盤であり、万が一の故障発生時に迅速かつ的確な対応が求められます。特に、物理的損傷や内部不良、振動・衝撃による局所的な故障、さらには論理的なファイルシステムエラーなど、各種障害に対しては、適切な復旧手法と予防策が不可欠です。各工程における作業時間はあくまで一般的な目安ですが、迅速な対応、正確な診断、そして最新技術の活用が、復旧成功率の向上に大きく寄与することが確認されています。
また、自己対応が困難な場合は、信頼できるデータ復旧業者に依頼することが最善の選択肢となります。情報工学研究所のような専門業者は、最新の設備と高度な技術を駆使して、極めて困難なケースにおいても高い復旧成功率を誇ります。依頼前の事前準備から初期診断、詳細診断、各工程ごとの修復作業、データ抽出、検証、納品に至るまで、透明性の高いコミュニケーションと緻密な作業計画が、ユーザーとの信頼関係を築く上で非常に重要です。
本レポートが、Windowsサーバー運用における万全のリスク管理と、万一の障害発生時に迅速な復旧対応を実現するための一助となれば幸いです。システム管理者および企業担当者は、定期的なバックアップ、SMART監視、環境管理、ファームウェアの更新など、予防措置の徹底を常に心がけ、トラブル発生時には専門家と連携して被害を最小限に抑えるための体制を構築することが不可欠です。
最後に、データは企業や組織にとって最も貴重な資産であり、万全のバックアップ体制と、信頼性の高い復旧パートナーとの連携が、業務継続性の確保と将来的なリスク低減につながります。今後も技術の進化に伴い、復旧手法や対策は更新され続けるため、常に最新情報をキャッチアップし、継続的なシステム改善に努めることを強く推奨いたします。
