・シグナル割り込みによるシステムコール中断の原因を可視化し、再発防止策を理解できます。
・政府・法令対応を踏まえたBCP設計と証跡管理方法を習得できます。
・三重化バックアップと段階別運用で大規模環境の可用性を維持する設計手順をご覧いただけます。
EINTRとは何か
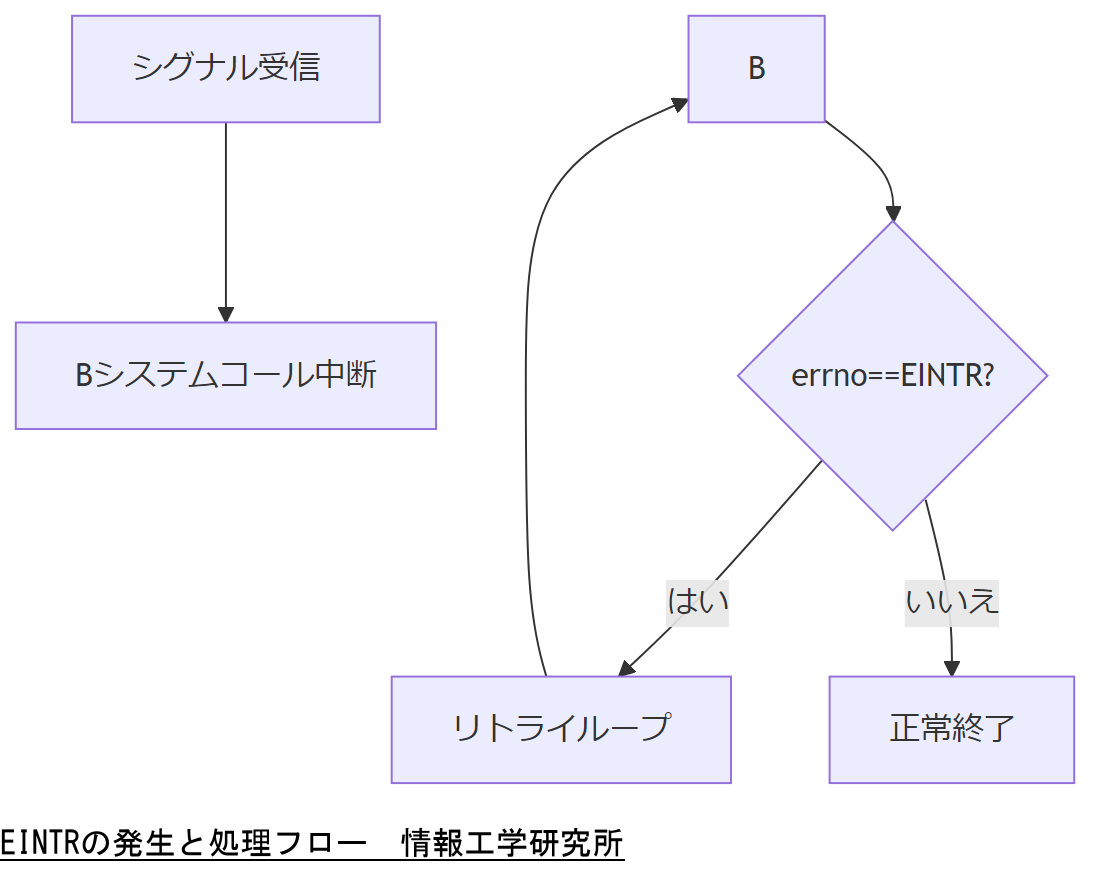
シグナルによる割り込みでシステムコールが中断された際に返されるエラー番号「EINTR(Interrupted system call)」の概要を解説します。POSIX規格で定義された機能であり、非同期シグナルを受け取ったプロセスは、その処理中のシステムコールが中断されてEINTRエラーを返すことが認められています。
背景と定義
EINTRは、主にSIGINTやSIGTERMなどのシグナル処理中に、readやwriteといったブロッキング系システムコールが中断された場合に発生します。カーネルレベルでシグナルハンドラを起動し、制御が戻る際に中断された呼び出しを再試行するかどうかを実装側で決める必要があります。
よくある混同点
- errnoの誤用:EINTRはerrnoに設定されるため、
if (errno == EINTR)で判定する。 - シグナルマスクとの関係:一時的に特定シグナルをマスクするとEINTRが発生しない。
シグナル割り込みは正常動作の一環であり、EINTR発生時には自動リトライ設計の重要性を理解してください。
システムコールの再試行ロジックを必ず実装し、中断可能性を考慮したコード設計を徹底しましょう。
典型的な発生シナリオ
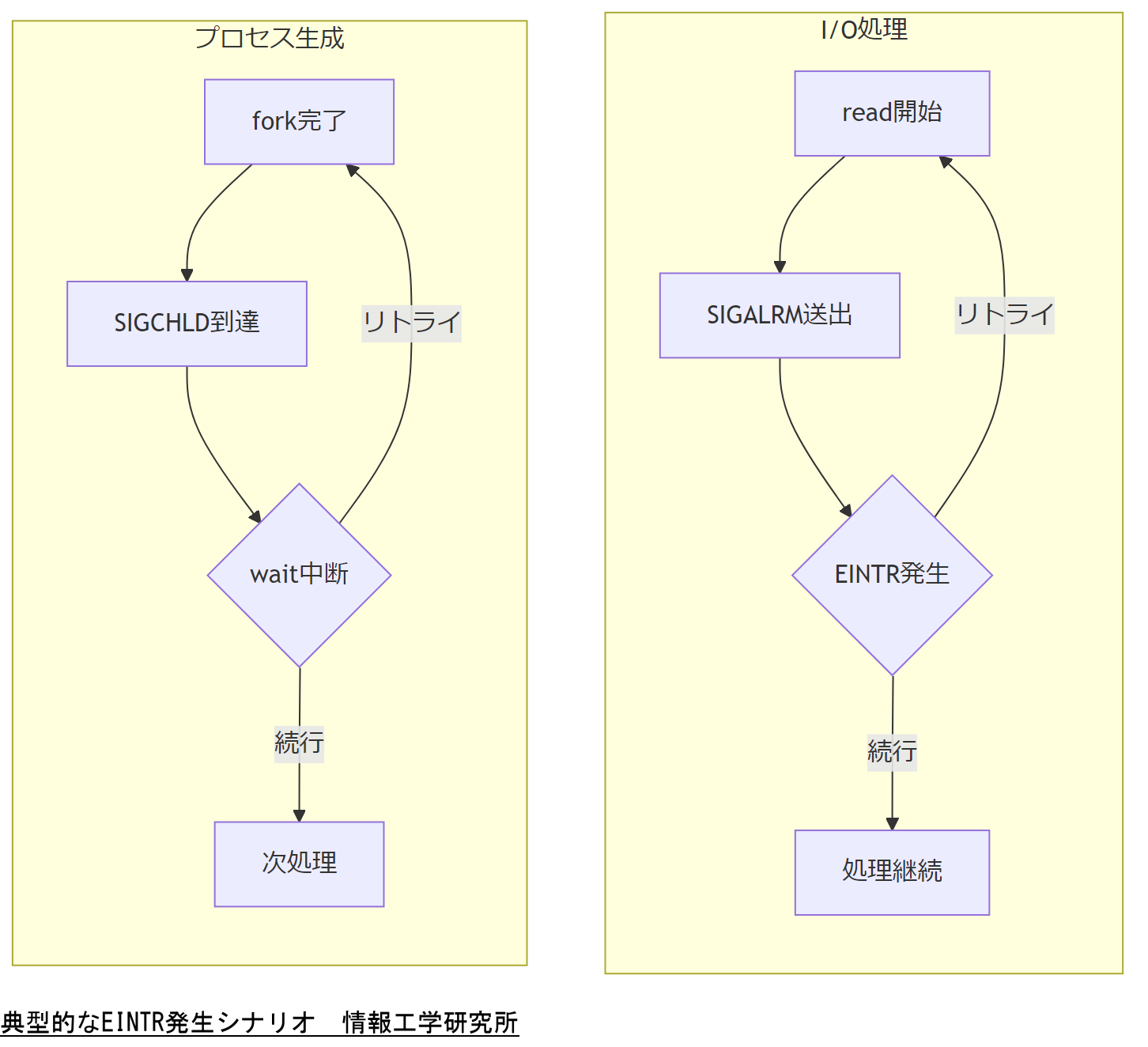
実運用システムで遭遇しやすいEINTR発生場面を事例を交えて解説します。特にI/O処理中やフォーク/エグゼキューション中に割り込みが入るケースが多いです。
I/Oブロッキング中の割り込み
長時間かかるネットワーク読込処理中にSIGALRMが設定されたタイムアウトハンドラで送出され、read関数がEINTRで中断される例。
プロセス生成時の割り込み
fork後にexecを呼び出す直前にSIGCHLDが届き、子プロセスの終了ハンドラが起動してwaitシステムコールがEINTRで中断される場合。
長時間I/Oやwaitを行う部分には必ず中断リトライ策を組み込み、安定運用を図る必要があります。
各シナリオごとにどのシステムコールが中断対象かを洗い出し、再試行が漏れない設計を心掛けましょう。
検出手法
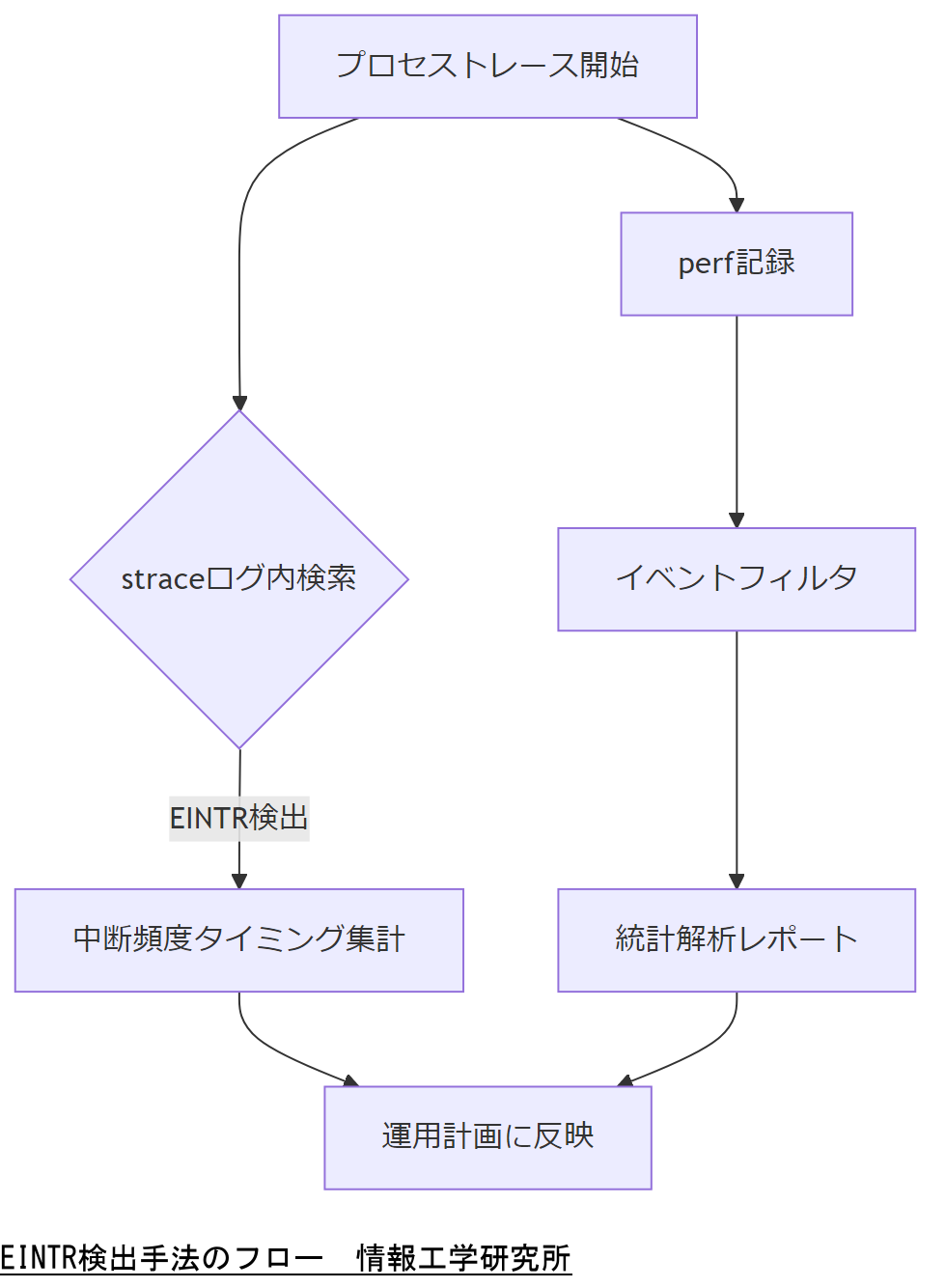
EINTR発生を確実に把握するためには、システムコールレベルでのトレースと、カーネル・ログ解析の二本柱が必須です。
straceによるシステムコール監視
straceは、プロセスが発行するシステムコールをリアルタイムで取得できるツールです。strace -e trace=read,write,wait -f プロセスIDのように呼び出すことで、該当システムコールがEINTRで中断されたかどうかをstraceのログから確認できます。特に? EINTR (Interrupted system call)という出力が現れた箇所を検索し、頻度とタイミングを把握します。
perf/ebpfを活用した統計的解析
perfやeBPFを使えば、カーネル側で発生するEINTR回数を集計・可視化できます。たとえば、perf record -e syscalls:sys_exit_readの実行結果から、中断発生数と処理時間を相関分析し、重大なボトルネック箇所を特定できます。
政府ガイドラインに基づくログ保全
政府機関等における情報システム運用継続計画ガイドラインでは、「システム停止や中断事象を含む全ログを一定期間保管し、インシデント発生時に即時解析できる体制整備」が求められています。特にEINTRのような異常発生ログは、BCP策定モデルに合わせて3年以上の長期保存が推奨されています。
トレースツールによる中断ログの取得は運用負荷を伴うため、影響範囲と頻度を事前に共有し、実施計画を承認してください。
ログ保全要件はBCPと監査要件で必須です。保存期間やフォーマットを最初に決め、運用マニュアルに落とし込みましょう。
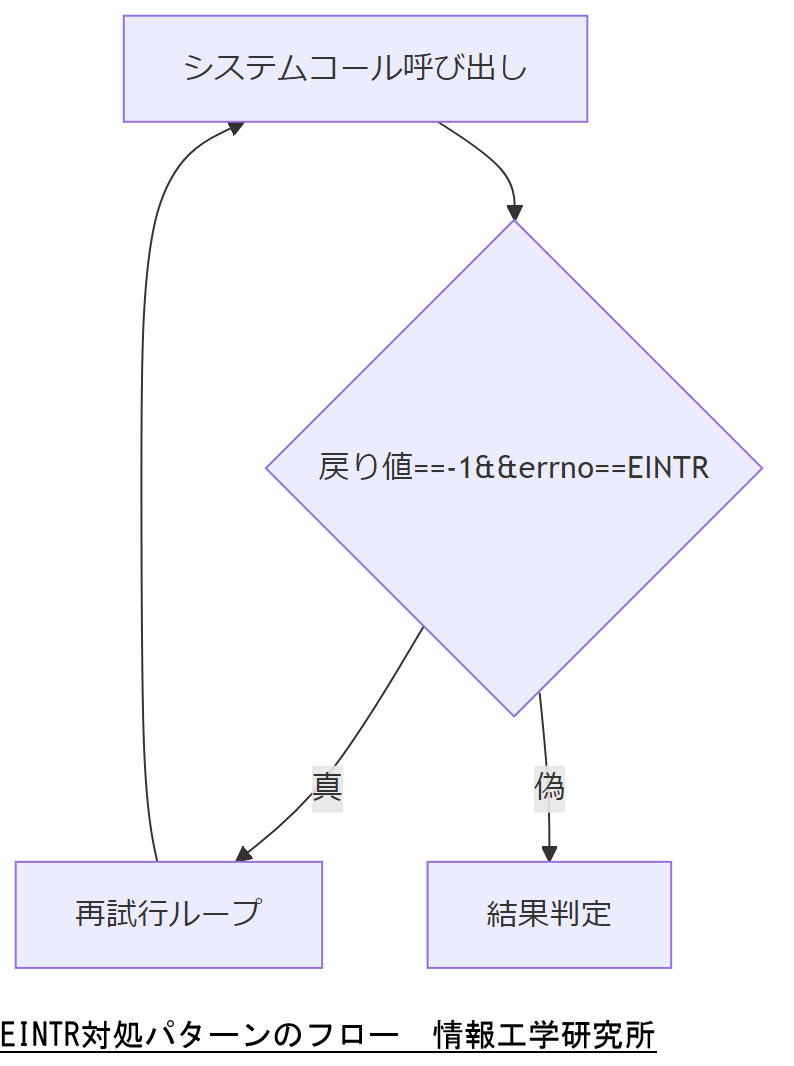
対処パターン
EINTR発生時の基本対処パターンは、システムコールが中断されたら再試行することです。具体的には、errnoがEINTRである限りwhileループで同じ呼び出しを継続する方式が一般的です。
単純リトライ
最もシンプルな方法は、while ( (res = syscall(...)) == -1 && errno == EINTR );のようにシステムコールをループで再試行する実装です。POSIX仕様では中断後に自動復帰しないことを前提としているため、アプリケーション側で明示的にリトライを行う必要があります。
タイムアウト付きリトライ
無制限リトライではシグナル連発時に無限ループ化する恐れがあるため、リトライ回数の上限や経過時間で打ち切る設計を推奨します。たとえばタイムスタンプを保持し、一定時間経過後にEINTRをエラーとして扱う実装が考えられます。
自動リトライラッパー
PythonのPEP 475に代表されるように、標準ライブラリでEINTRを自動再試行する仕組みを活用すると、アプリケーションコードが簡潔になります。C言語向けにはglibcの一部ラッパー関数や、自作のユーティリティ関数で対応可能です。
再試行ロジックは必ずリソース開放やエラーログ出力を伴う形で実装し、無制限ループに注意してください。
システムコール中断に強い設計を標準化し、ライブラリ層での共通実装を徹底すると運用負荷を低減できます。
テストと検証
システムの耐障害性を担保するには、カオスエンジニアリングによる実践的な障害実験と、政府ガイドラインに準拠した検証が有効です。
カオスエンジニアリングによる障害注入
カオスエンジニアリングは、本番環境に近いステージング環境で意図的に障害を発生させ、システムの耐性を検証・改善する手法です。
工場システムガイドラインを応用した検証ステップ
経済産業省の「工場システムにおけるサイバー・フィジカル・セキュリティ対策ガイドライン」では、セキュリティテスト工程をフェーズ分けし、段階的にリスクを洗い出す方法を示しています。
重要インフラ情勢分析との連携
内閣サイバーセキュリティセンターの情勢分析資料によると、四半期ごとのインシデント共有結果から得られた知見をテスト計画に反映することで、最新の脅威に対応できます。
実際の障害を模擬するテストは計画的に実施し、影響範囲と復旧手順を事前に社内合意してください。
テスト結果を定量的に評価し、検証レポートをBCPや運用マニュアルに即座に反映しましょう。
コンプライアンスと証跡
情報システムの運用において、EINTR発生ログを含む全てのシステムログを適切に取得・保全し、インシデント発生時に速やかに解析できる体制を整えることが法令・政府方針で求められています。特に政府機関等向け統一基準では、ログの取得・管理・保全・点検の各要件が詳細に定義されています。[出典:内閣サイバーセキュリティセンター『政府機関等の対策基準策定のためのガイドライン』令和5年]
ログ取得・管理の遵守事項
政府機関等の対策基準ガイドラインでは、情報システムセキュリティ責任者が以下を定め、実施することを義務付けています:[出典:内閣サイバーセキュリティセンター『政府機関等のサイバーセキュリティ対策のための統一基準』令和5年]
- ログ取得目的の明確化と取得対象の定義
- ログの保存期間と改ざん防止策の策定
- ログ未取得時の対処手順の整備
- 定期的な点検・分析機能の設置
長期保全と改ざん防止
同ガイドラインでは、インシデント調査に不可欠な証跡として、ログは最低3年間保存し、WORM(Write Once Read Many)等を用いて改ざんを防止することを推奨しています。[出典:内閣サイバーセキュリティセンター『政府機関等の対策基準策定のためのガイドライン』令和5年]
運用継続計画との連携
府省業務継続計画および情報システム運用継続計画ガイドラインでは、ログ取得・保全要件をBCP/COOP計画に統合し、非常時のログ回収手順をあらかじめ定めることが求められます。[出典:内閣サイバーセキュリティセンター『府省庁対策基準策定のためのガイドライン』平成30年度]
ログ管理はBCP要件と監査要件の両面で必須です。取得対象や保存期間は社内ルールとして明文化し、全関係者で合意してください。
証跡管理体制の構築は運用コストが増大しがちですが、ログがあればEINTR発生原因の早期解析と再発防止が可能です。必要最小限の項目管理を心掛けましょう。
財務・税務インパクト
システム障害による損失額や、BCP対策に伴う投資の会計処理を理解することで、経営判断を円滑に行えます。また、BCP関連支出に対する税制優遇や補助金制度を活用し、初期投資負担を軽減する方法を確認します。
障害損失の会計処理
障害発生による売上損失は、発生年度の特別損失として計上可能です。復旧費用やシステム再構築費用は資産計上し、減価償却期間を設定して数年に渡り配分します。
BCP関連税制優遇
中小企業強化税制において、情報システム強靭化投資に対する特別償却や税額控除が認められています。投資額の10〜20%を上限に控除が可能です。
補助金・助成金制度
内閣官房の「事業継続力強化計画」認定を受けると、都道府県から最大100万円の補助金が交付されます。詳細は各都道府県の公示をご確認ください。
BCP対策費用は税制優遇対象となるため、投資計画を早期に税務部門と共有し、認定申請を進めてください。
補助金や優遇税制を最大限活用するため、計画策定段階で経理・税務担当との連携を図り、書類準備を怠らないようにしましょう。
今後2年の法制度とコスト見通し
国内外で予定されるサイバーセキュリティ関連法令改正と、それに伴う運用コスト増減のシナリオを比較し、短中期の投資計画策定に役立てます。
EU NIS2 Directiveの拡大
EUのNIS2指令は2024年末から適用対象を拡大し、中堅企業にも報告義務を課します。これに対応するため、ログ保全やインシデント対応体制の構築費用が増加する見込みです。
米国大統領令のIRP義務化
2025年6月発出の米国大統領令により、重要インフラ事業者にIncident Response Planの義務化が強化され、IR演習や外部監査に要するコストが10〜15%増加する予測があります。
国内サイバーセキュリティ基本法改正
令和7年度改正では、民間重要インフラ事業者のBCP対応義務が明文化され、違反時の罰則強化が検討されています。罰則リスクを回避するための追加投資が必要です。
今後の法改正動向を踏まえ、年間予算にセキュリティ法令対応費用をあらかじめ組み込んでください。
法令は短期間で改正されることがあります。最新動向を継続的にモニタリングし、運用計画を柔軟に見直せる仕組みを整えましょう。
人材・資格・育成
システム設計・運用を担う技術者に求められる資格と育成プログラムをまとめます。登録セキスペをはじめ、企業内での継続研修体制構築のポイントを解説します。
情報処理安全確保支援士の役割
情報処理安全確保支援士(登録セキスペ)は、情報システムの脅威分析やリスク評価などの実践能力を有する国家資格です。サイバーセキュリティ人材の裾野拡大策として、2030年までに登録者数を5万人に増やす目標が掲げられています。
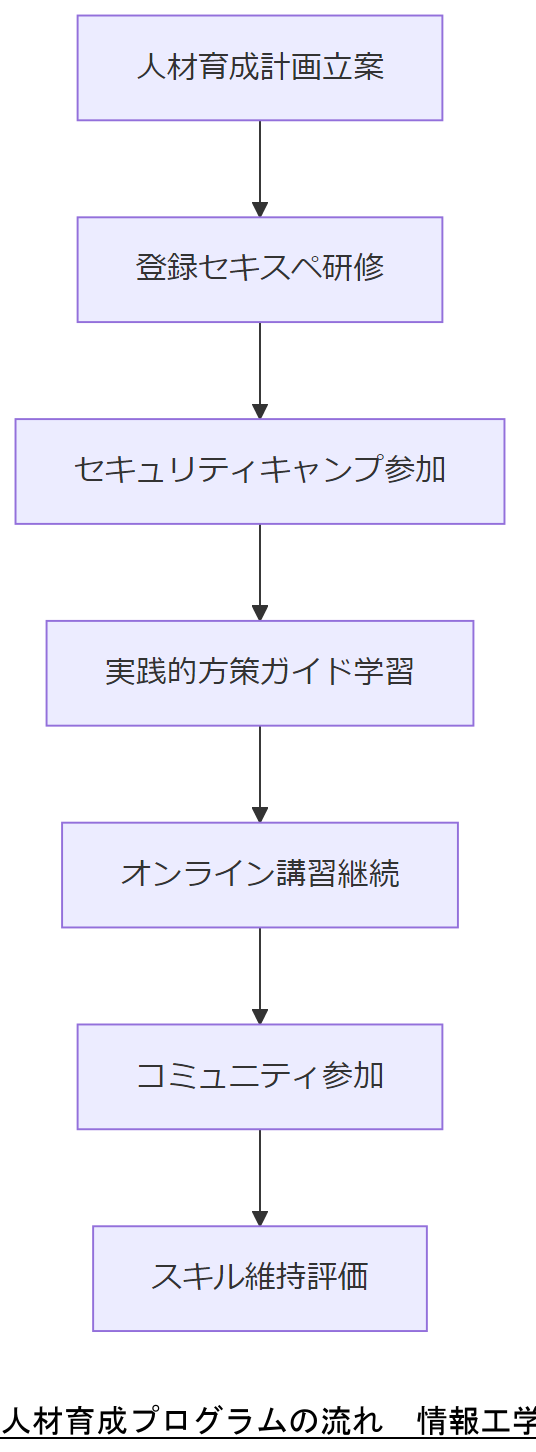
育成プログラムの体系
経済産業省の検討会最終取りまとめでは、①セキュリティ・キャンプ拡充、②登録セキスペ活用・制度見直し、③中小企業内人材支援策を柱としています。特に実践的方策ガイドで段階的スキル習得を支援します。
継続的研修とコミュニティ
NISCの普及啓発・人材育成専門調査会では、官民連携の研修プログラムやオンライン講習を通年で提供し、知見共有と行動変容促進を図る枠組みを示しています。
登録セキスペ取得や継続研修は組織力強化の要です。人事・教育担当と早期にロードマップを策定してください。
資格取得後のフォロー研修やコミュニティ参加を支援し、定着化を図りましょう。制度更新要件も留意が必要です。
システム設計の勘所
高可用性を実現するシステム設計では、三重化バックアップとフェイルオーバー機構を組み合わせた冗長構成が基本となります。特にEINTR発生時にもデータ整合性を保てるよう、I/Oパスを多重化し、障害発生領域の切り離しを自動化することが重要です。
三重化バックアップ構成
3-2-1ルールに従い、同一データを3世代、2媒体(ディスクとオブジェクトストレージ)、1オフサイトに保管します。各バックアップ対象のI/O処理でEINTR対策を施し、リストア手順の自動化テストを必須とします。
フェイルオーバーとヘルスチェック
ロードバランサにヘルスチェック機能を持たせ、EINTR発生時に該当ノードを自動的に切り離し、フェイルオーバー先へトラフィックを転送する仕組みを設計します。
非同期I/Oの検討
非同期I/Oを活用することで、EINTR発生を回避しやすくなります。POSIX aioやio_uringなどの最新技術を検討し、システムコール中断リスクを低減します。
冗長構成や非同期I/Oの導入には追加コストと運用負荷があります。設計段階で影響範囲を明確化し、合意を得てください。
フェイルオーバーテストを定期的に実施し、設計通りに切り替わることを必ず検証しましょう。
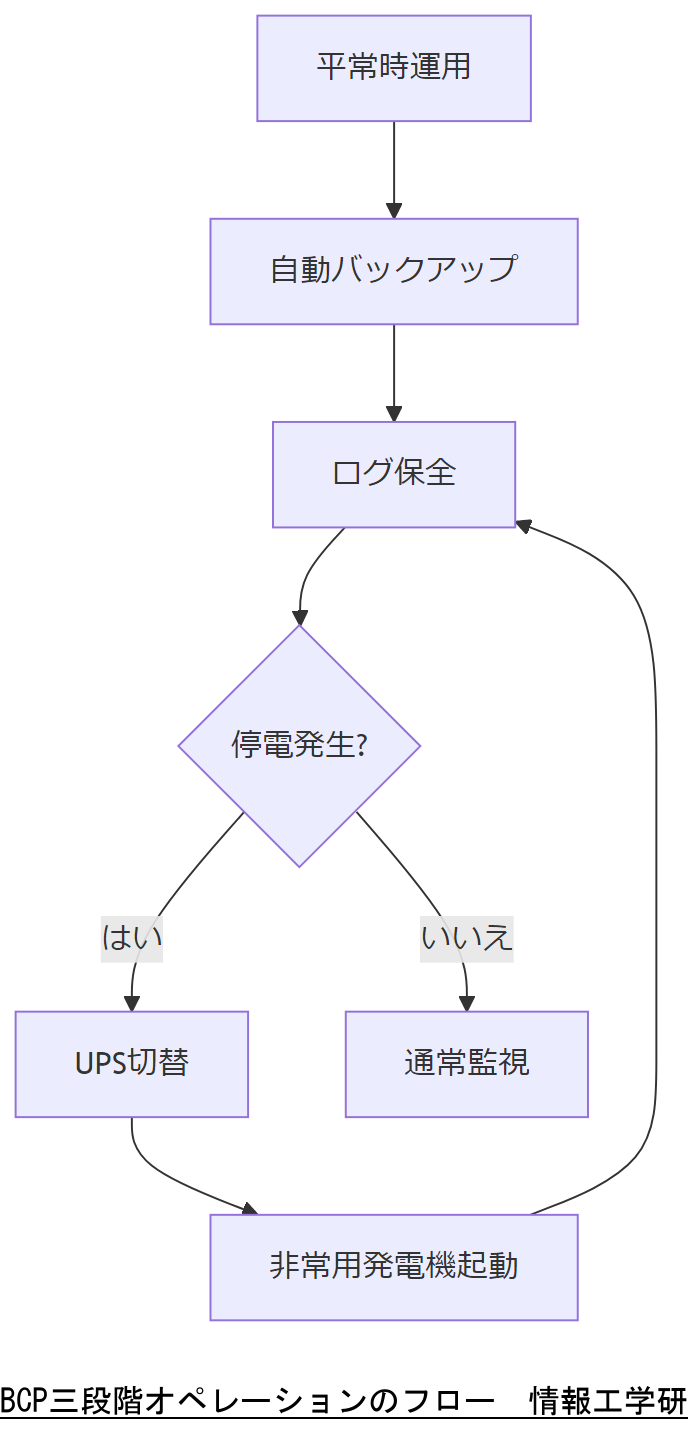
BCP三段階オペレーション
事業継続計画(BCP)では、平常時・無電化時・完全停止時の三段階で運用フローを定義します。各フェーズの手順を明確化し、EINTRによる中断発生時の対応手順も含めて運用マニュアルに記載します。
平常時オペレーション
通常運用下では、定期バックアップ、ログの自動収集、ヘルスチェックを実施します。EINTRエラー発生時には自動リトライレイヤーで一次対応を行います。
無電化時オペレーション
停電が発生した場合にはUPSと非常用発電機でシステムを維持し、ログ保全サーバへの書込みを優先設定します。EINTR中断が発生しても、書込み優先度でデータ損失を防ぎます。
完全停止時オペレーション
システム停止時には、障害切り分け手順書に則り、バックアップからのリストア手順を実行します。EINTR発生原因のログ解析を並行して行い、再発防止策を検討します。
各フェーズの手順をドキュメント化し、定期的に訓練・レビューを行いましょう。
BCP訓練ではEINTR事象をシナリオに組み込み、実際の運用感を養うことが大切です。
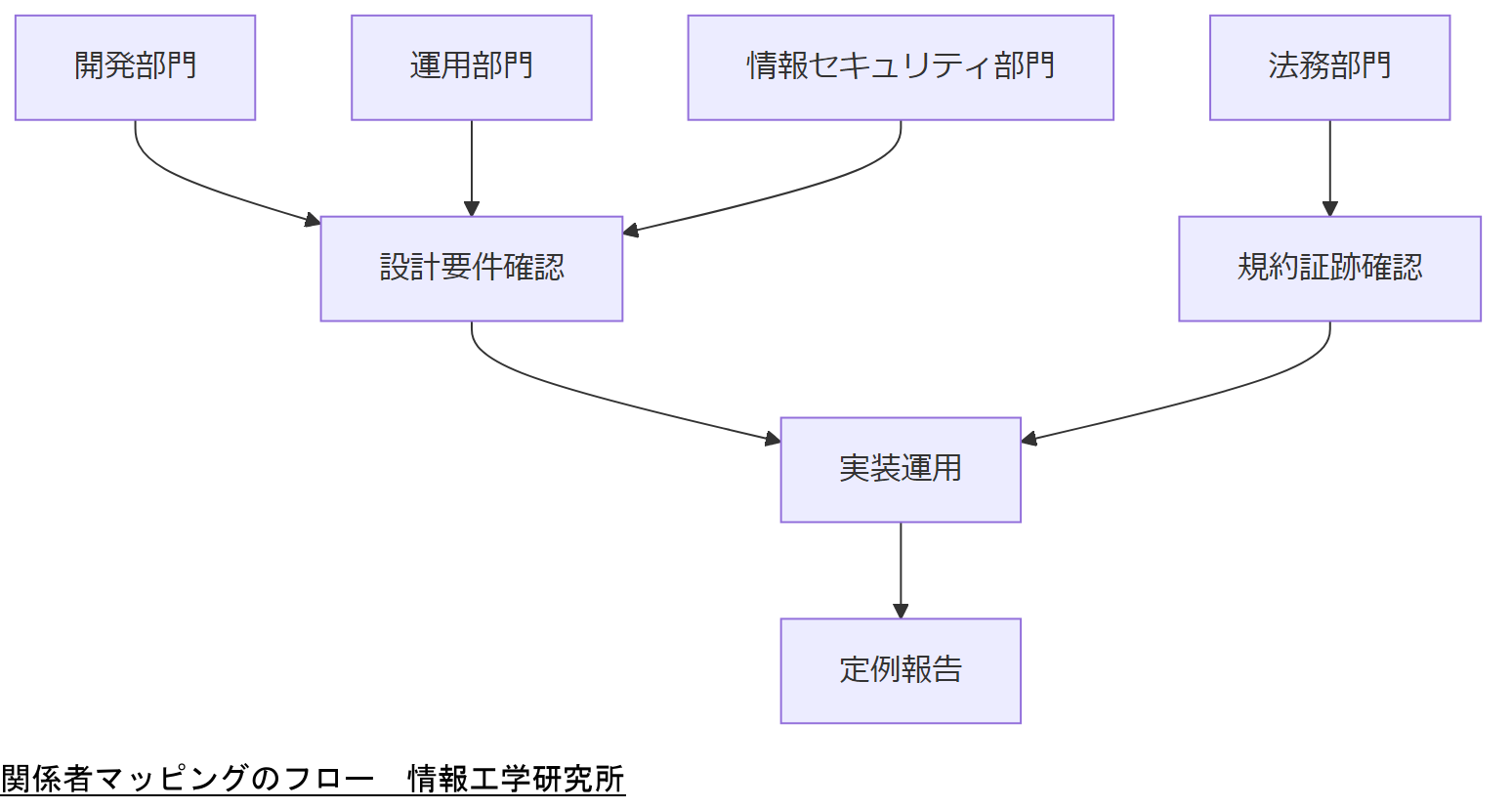
関係者分析と注意点
システム開発・運用に関わる関係者を洗い出し、それぞれの役割と注意すべきポイントを明確化します。プロジェクトの成功には、全社的な理解と協力が不可欠です。
関係者マッピング
開発部門、運用部門、情報セキュリティ部門、法務部門、経営層、監査部門、ユーザー代表の7者を想定します。それぞれが担う責務をドキュメント化し、EINTR対策の重要性を共有します。
合意形成のポイント
技術担当者は、EINTRの再発防止策をシンプルに説明し、法務や経営層からの疑問に備えたFAQを用意します。また、監査部門向けにはログ保全・証跡管理の手順書を提出し、透明性を確保します。
コミュニケーションツール
定例会議や社内ポータル、メールニュースレターなどを活用し、対策状況を定期的に報告します。技術的詳細はWikiに集約し、最新の設計図や手順を常に参照できる状態にしておきます。
各部門の責務を明文化し、定例のステータス報告を通じてプロジェクトの進捗とリスクを共有してください。
関係者毎の関心事項を整理し、説明資料を最適化することで、社内理解とスムーズな合意形成を実現しましょう。
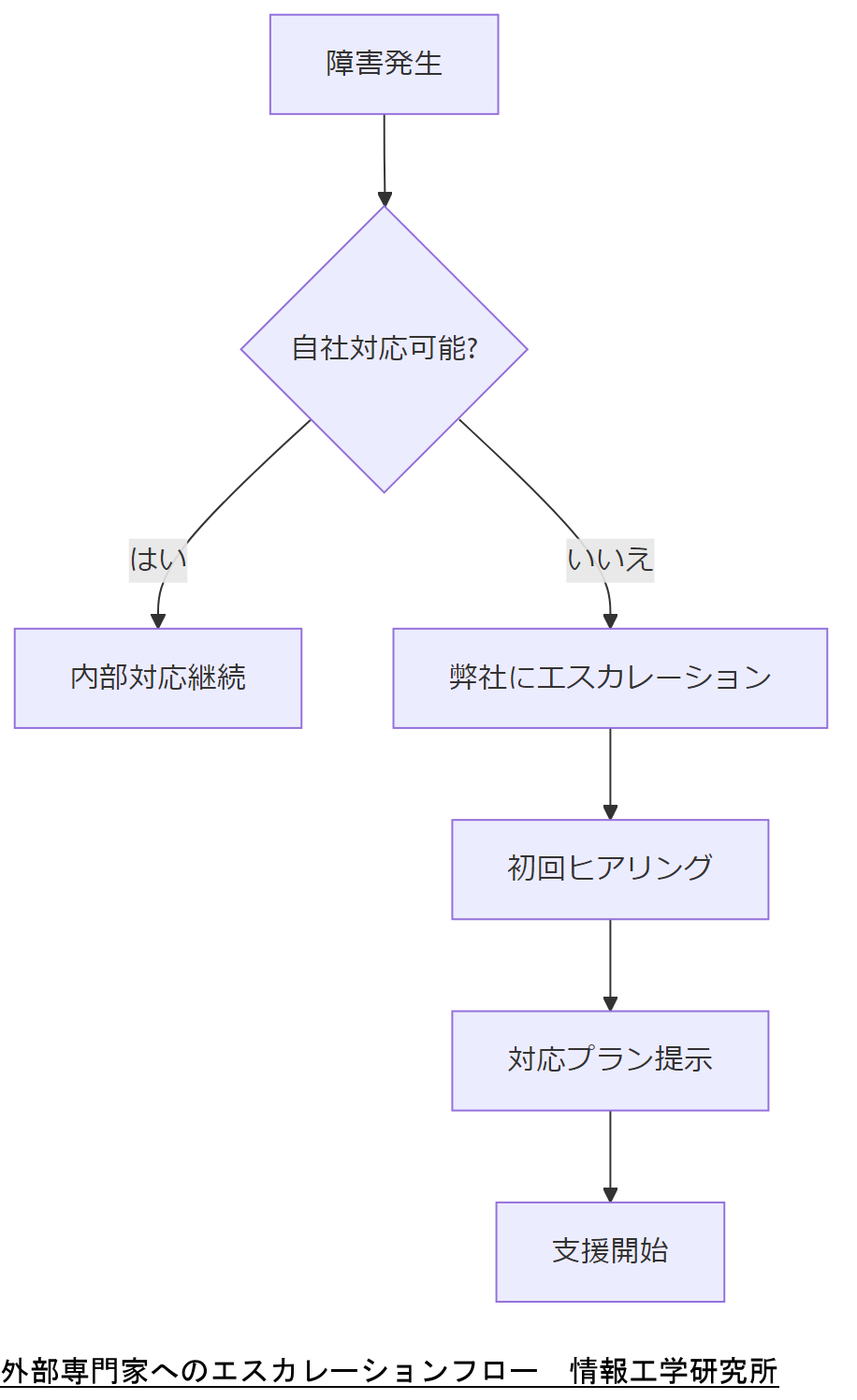
外部専門家へのエスカレーション
自社だけで対応困難な場合や、法令遵守の観点で客観的評価が必要な際に、弊社への相談フローを明示します。
エスカレーションの判断基準
以下のいずれかに該当する場合は、外部専門家(情報工学研究所)へのエスカレーションを推奨します:
・障害が複数システムに波及し業務停止リスクが高い場合
・ログ解析で再現困難なEINTR事象が継続する場合
・法令改正対応が急務で内部リソースが不足する場合
エスカレーション手順
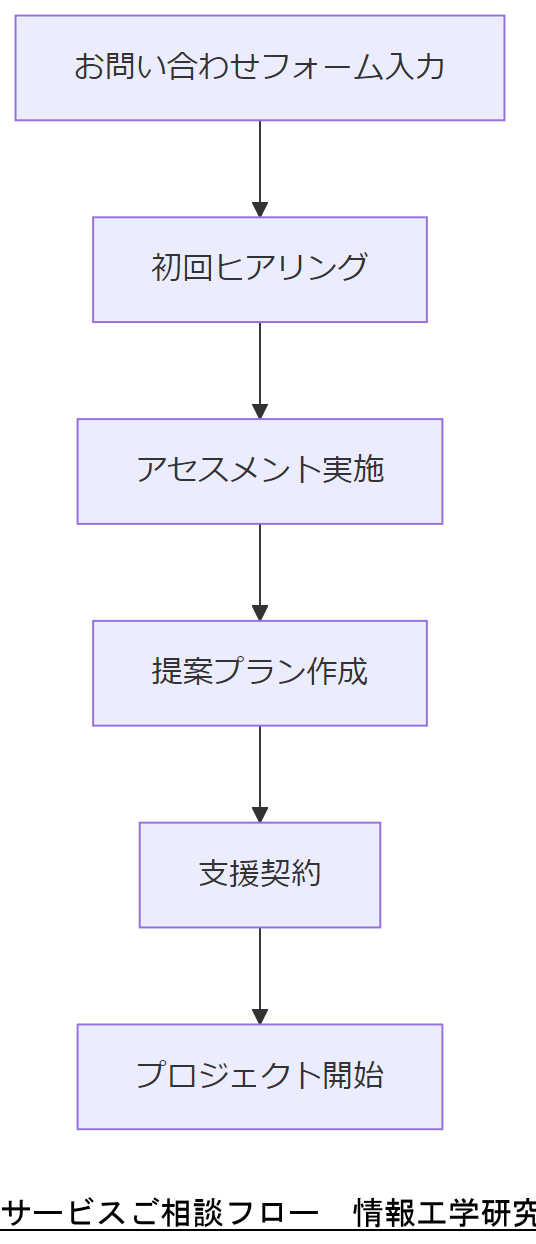
お問い合わせフォームより以下情報をお送りください:
・発生状況サマリ
・システム構成図
・取得ログのサンプル
弊社専門コンサルタントが初回ヒアリングを実施し、対応プランをご提案します。
対応支援サービス内容
弊社では、EINTR再発防止アセスメント、ログフォレンジック、BCP実装支援、法令適合診断などをワンストップで提供しております。
自社内で対応困難と判断した場合は、エスカレーション基準を共有し、速やかに専門支援を要請してください。
早期に専門家支援を得ることで、復旧プロセスを短縮し、業務影響を最小化できます。
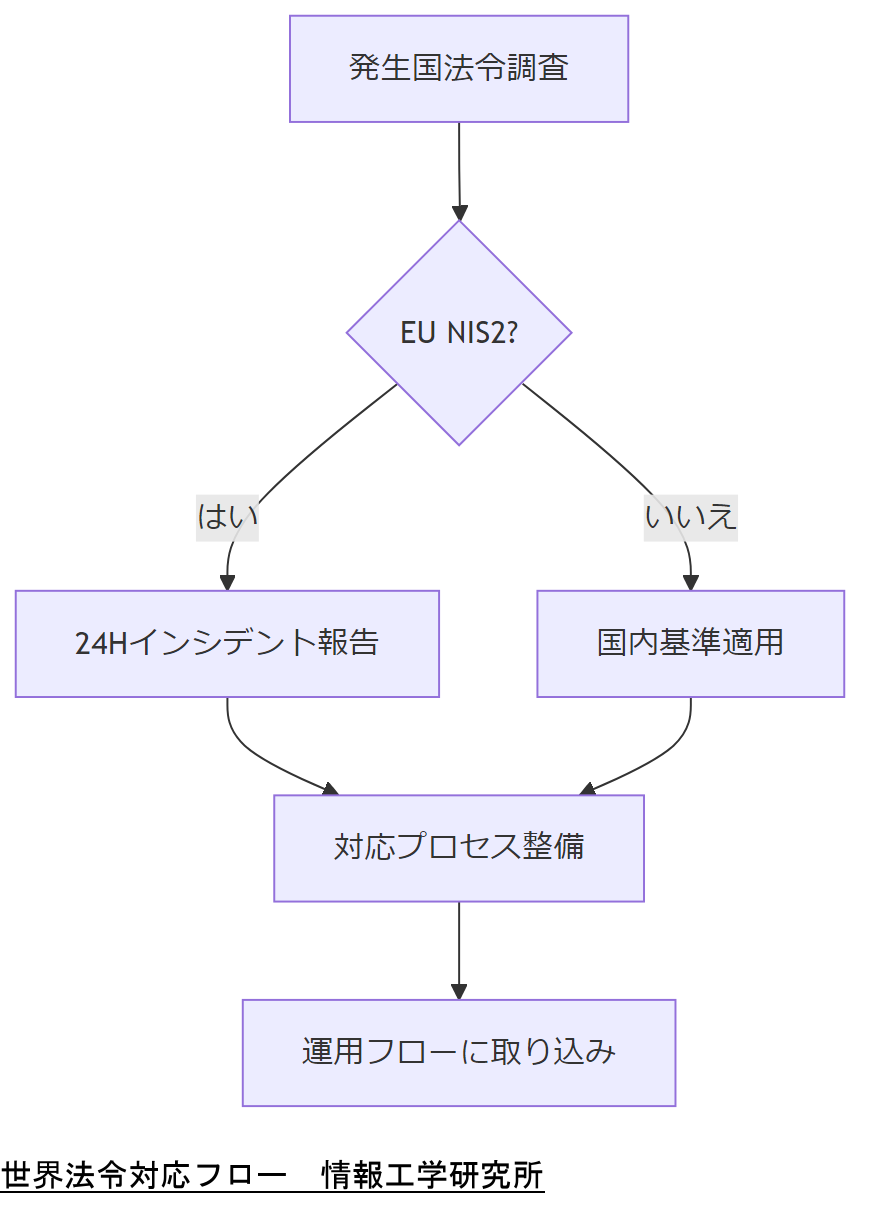
世界の法令・政府方針が変えるIT運用
EUや米国の最新サイバー政策は、国内事業者にも大きな影響を与えます。法令への適合を怠ると、罰則や事業停止命令のリスクが高まるため、グローバル視点での運用見直しが不可欠です。
EU NIS2 Directive
NIS2は欧州連合が2024年末より順次適用を開始するサイバーセキュリティ指令で、重要セクターだけでなく中堅企業にも義務を拡大します。報告期限はインシデント発生後24時間以内と非常に厳格です。[出典:欧州委員会『Network and Information Security Directive (NIS2)』2022年]
米国大統領令によるIRP義務化
2025年6月に発出された大統領令では、連邦政府向けシステムだけでなく、重要インフラを担う民間事業者にもIncident Response Plan(IRP)の整備と年1回以上の演習を義務付けています。[出典:米国連邦政府『Executive Order on Improving the Nation’s Cybersecurity』2025年]
日本のサイバーセキュリティ基本法改正動向
国内では令和7年度改正案で、民間重要インフラ事業者に対するBCP・CSIRT設置義務を明文化し、違反時の罰則強化を検討中です。[出典:内閣官房サイバーセキュリティ統括官『サイバーセキュリティ基本法改正案骨子』令和6年]
海外法令対応は現地実務への適用が難しいため、適用範囲と優先度を経営層と合意の上で設定してください。
法令は逐次改正されるため、法律専門担当者との定期連携を行い、運用マニュアルを継続的に更新しましょう。
まとめと弊社サービス紹介
本記事では、Linux EINTR (4) エラーの検知・対処から、法令対応、BCP設計、人材育成、システム設計まで、包括的な視点で解説しました。これらの要件を自社だけで満たすのは難易度が高いため、専門支援が有効です。
弊社のご支援内容
- EINTR再発防止アセスメント
- ログフォレンジック解析
- BCP/COOP実装支援
- 法令適合診断と対応プラン策定
- 人材育成プログラム構築
ご相談の流れ
お問い合わせフォームより必要情報をご送付いただくと、弊社専門コンサルタントが初回ヒアリングを行い、最適な支援プランをご提案します。
外部専門家活用のメリットとコストを整理し、速やかな合意形成を図ってください。
弊社が支援することで、社内リソースを最適化し、EINTR対応に費やす時間を大幅に削減できます。

おまけの章
ここでは、本記事で取り上げた重要キーワードと、その説明、および関連する法令・ガイドラインを一覧のマトリクス形式でまとめています。社内共有や研修資料としてもご活用ください。
表:重要キーワードマトリクス
| キーワード | 説明 | 関連法令・ガイドライン |
|---|---|---|
| EINTR | シグナル割り込みでシステムコールが中断された際に返されるエラー番号4。 | POSIX標準 FIPS PUB 151-2 |
| 3-2-1 バックアップ | 同一データを3世代、2媒体、1オフサイトで保管するバックアップ原則。 | NIST NCCoE ガイドライン |
| IT-BCP | 情報システムを中心に据えた事業継続計画。 | NISC IT-BCPガイドライン |
| IRP | Incident Response Plan、インシデント対応手順書。 | CISA Incident Response Plan Basics |
| NIS2 | EU域内のサイバーセキュリティ強化指令第2版。 | 欧州委員会 NIS2指令 |
| サイバーセキュリティ基本法 | 日本の情報セキュリティ政策の基本法。 | 内閣官房『サイバーセキュリティ基本法』 |
| 三段階オペレーション | 平常時・無電化時・停止時の3フェーズ運用。 | MLIT BCPガイドライン |
| 港湾BCP | 港湾機能を守るための事業継続計画。 | 国土交通省 港湾BCPガイドライン |
| 業務継続補助金 | BCP策定・強化に対する政府の補助金制度。 | 内閣官房『事業継続力強化計画』 |
| シグナルマスキング | 特定のシグナルを一時的に無効化する技法。 | 経済産業省 工場システムガイドライン |