# 例:対象が本当に存在するか(ノード/実体/リンク) ls -l /dev/readlink -f /dev/disk/by-id/ 例:udev情報(想定の機器に紐づくか) udevadm info -q all -n /dev/ dmesg -T | tail -n 80
# 例:現在の実体と、設定が指している先の差分を見る blkid findmnt -a cat /etc/fstab 例:パス視点で実際のマウントを確認 findmnt -T /path/to/target mount | grep -E " /path/to/target |/dev/"
# 例:層ごとの見え方(どこで途切れているか) lsblk -o NAME,TYPE,SIZE,FSTYPE,MOUNTPOINTS,MODEL,UUID pvs; vgs; lvs cat /proc/mdstat 例:接続系(環境によって) iscsiadm -m session multipath -ll
# 例:ホストとコンテナで見えているものを揃えて比較 lsns -t mnt cat /proc/1/mountinfo | tail -n 40 例:コンテナ内からの見え方(実行環境に合わせて) ls -l /dev mount | head -n 40
- 参照先が確定しないまま修復系の操作を進め、別ディスクや別LVに変更が入って復旧難易度が跳ね上がる。
- fstabやudevの変更を広く入れてしまい、再起動後に起動経路が変わって停止時間が伸びる。
- コンテナ境界の問題を見落としてホスト側を触り続け、原因が残ったまま追加の副作用だけ増える。
- 共有ストレージや監査要件が絡むのに権限・所有者を一気に変え、後で整合性説明ができなくなる。
もくじ
- 第1章:ENXIO(6)は「宛先がある前提」が崩れたサインとして現れる
- 第2章:まず切り分けるべきは「どのパス/どの操作」でENXIOが返っているか
- 第3章:/dev の実体がズレると起きる:消えた・古い・別物を指している
- 第4章:fstab・UUID・by-id の落とし穴:正しそうに見えて違う参照先
- 第5章:LVM/RAID/multipathで「見えているつもり」が増える瞬間
- 第6章:iSCSI/NFS/SMBなど外部ストレージで起きる「到達不能」の型
- 第7章:コンテナ/chroot/名前空間でホストと見え方が食い違う理由
- 第8章:再設定の方針:最小変更で“正しい宛先”へ戻す順序を作る
- 第9章:再発防止の実装:監視・変更管理・手戻り設計に落とし込む
- 第10章:帰結:止められない現場ほど、迷った時点で相談した方が早く収束する
【注意】本記事は原因の整理と安全な初動(被害最小化・収束のための確認)をまとめたもので、自己流の修理・復旧作業を推奨するものではありません。誤操作で状況が悪化することがあるため、業務影響が大きい場合や共有ストレージ/コンテナ/監査要件が絡む場合は、株式会社情報工学研究所のような専門事業者へ相談してから進めてください。
ENXIO(6)は「宛先がある前提」が崩れたサインとして現れる
Linuxで ENXIO (6) が返る場面は、現場感としては「そこにあるはずの宛先に届いていない」状態です。メッセージの “No such device or address” は、単にファイルが無い(ENOENT)というより、指定した先が“デバイスとして成立していない”、あるいは到達できる前提が崩れているときに顔を出しやすい傾向があります。
この手の障害が厄介なのは、直したい気持ちとは裏腹に、権限や設定を広く触るほど“別の層”で問題が増えやすい点です。まずは状況の温度を下げるために、症状→取るべき行動を先に並べ、最小変更で確認できる範囲だけを扱います。
冒頭30秒:症状 → 取るべき行動(安全な初動ガイド)
| 症状 | まず見る場所(30秒) | 安全な初動(最小変更) | 今すぐ相談が良い条件 |
|---|---|---|---|
| アプリ起動直後にENXIOで落ちる | エラーログの対象パス/対象操作 | 対象パスを固定して“どこで”失敗しているかだけ特定 | 本番停止が許されない/説明責任(監査・SLA)が重い |
| /dev配下を触るとENXIOが出る | /devの実体、/dev/disk/by-id、dmesg | “存在するように見えるが実体が違う”を疑って読み取り確認 | 共有ストレージ/multipath/iSCSI/RAIDなど層が多い |
| mountや起動時に失敗し、依存サービスが連鎖停止 | /etc/fstab、findmnt、systemdの依存 | 参照(UUID/LABEL/by-id)のズレを“比較”して原因候補を絞る | 再起動が怖い/切り戻し手順が無い/夜間対応 |
| コンテナ内でだけ発生、ホストでは再現しない | コンテナの/dev、mount namespace、権限境界 | “見えている層”を揃え、ホストと差分だけ確認 | 本番データ+監査要件+権限変更が絡む |
依頼判断の導線としては、状況整理だけでも進みます。問い合わせフォームは https://jouhou.main.jp/?page_id=26983、電話は 0120-838-831 です。
ENXIOが出た瞬間に「やりがち」な誤解
ENXIOを見ると、「デバイスが無いなら作れば良い」「権限が足りないのでは」「一度設定を総入れ替えしよう」と発想しがちです。しかし実際には、参照先の“整合”が崩れている場合が多く、広い変更は別の不整合を増やします。特にストレージが階層化している環境(LVM、RAID、multipath、iSCSI、仮想化、コンテナ)では、宛先が“どれか一つ”ではなく、どの層でズレたかが重要です。
現場の説明で役立つ言い方としては、「データそのものが突然壊れた」ではなく、“参照経路が正しく繋がっていない可能性が高い”と捉えるほうが、原因調査と意思決定が前に進みます。復旧や再設定は、まず経路を正しく戻すことが先で、最後に恒久化や再発防止へ進む、という順序が安全です。
ENXIOを「収束させる」ための最低限の材料
ここで必要なのは、派手な手順ではなく、関係者が同じ事実を共有できる材料です。少なくとも次の3点が揃うと、判断がブレにくくなります。
- どのプロセス/サービスが、どのパスを触っているか
- そのパスは “本来どの実体” を指す設計だったか(UUID、by-id、LV名など)
- 今それが “何を指しているか/そもそも指せていないか”
この3点が揃うと、現場の本音である「移行コストとトラブルだけは増やしたくない」に対して、最小変更で戻す/戻せないなら切り分けて相談するという選択が取りやすくなります。
第1章のまとめ(この段階で“やらない判断”が価値になる)
ENXIOは、原因が単純でも見え方が複雑になりやすいエラーです。読み取り中心の確認で宛先ズレを絞り込み、手当たり次第の変更を避けるだけで、被害最小化に繋がります。
個別案件では、ストレージ構成・運用制約・監査要件が絡むほど一般論が外れやすくなります。迷いが出た時点で、株式会社情報工学研究所のような専門家に状況を渡し、最小変更での収束プランを作る方が結果的に早く終わります。
まず切り分けるべきは「どのパス/どの操作」でENXIOが返っているか
ENXIO対策の最初の壁は、「原因が分からない」よりも、「原因を探すために何を見れば良いかが分からない」です。しかもレガシーな既存システムほど、ログの形式が揃っていなかったり、複数チームが関与して“持ち物”が曖昧だったりします。ここでは、誰が見ても同じ結論に近づける切り分けを優先します。
1) “どのパス” を固定する(まず1点に刺す)
エラー行に出ているパスが /dev 配下であれ、マウントポイントであれ、アプリ設定のパスであれ、まずはその文字列を固定し、そこだけに紐づく事実を集めます。複数のパスが候補に出る場合でも、最初は「エラーに直接出ているもの」から始める方が、説明と共有が速いです。
この時点で大切なのは、修正ではなく“観測”です。読み取り中心で「何が指されているか」を見ていきます。
2) “どの操作” で失敗しているかを押さえる(openなのか、ioctlなのか)
同じパスでも、失敗している操作が違えば意味が変わります。例えば、openで失敗するのか、openできるが特定の制御操作(ioctl等)で失敗するのかで、疑う層が変わります。アプリのログが薄い場合でも、システムログや周辺ログから「どの段階で落ちているか」を推測できます。
ここで無理に手順を増やさずとも、次の観点だけ押さえると“温度を下げる”判断がしやすくなります。
- サービス起動直後に必ず再現するか(再現性)
- あるノード/あるコンテナだけで起きるか(局所性)
- 直前に構成変更・再起動・ストレージ経路変更があったか(トリガ)
3) 現場で多い「ログはあるのに説明が難しい」問題の整理
上司や役員への説明が難しいのは、原因が不明だからではなく、影響範囲と選択肢が言語化されていないからです。ENXIOのような“宛先ズレ”の疑いが強いエラーでは、説明の型を先に作ると合意が取りやすくなります。
| 説明したいこと | 現場の言い方(事実ベース) | 次の判断 |
|---|---|---|
| 何が起きている? | 特定のプロセスが参照する宛先が成立しておらず、ENXIOで失敗している | 宛先ズレの層(/dev、fstab、外部接続、コンテナ境界)を絞る |
| 影響はどこまで? | 再現範囲は(特定ノード/特定サービス/全体)で現時点はここまで | 停止判断・切り戻し・代替経路の検討の順で決める |
| 今すぐ直せる? | 広い変更は副作用が出やすいので、最小変更で原因確認を先行する | 個別構成を前提に、専門家に並走相談する選択肢を確保 |
この型で共有できると、「直せるか?」の議論が過熱しにくくなり、安全な初動→判断基準→必要なら相談の流れが作れます。問い合わせフォームは https://jouhou.main.jp/?page_id=26983、電話は 0120-838-831 です。
第2章のまとめ(切り分けは“作業”ではなく“合意形成”に効く)
ENXIOの初動で重要なのは、修正作業よりも「どのパス/どの操作で失敗しているか」を固めることです。これが固まると、次に見るべき層が自然に決まり、最小変更で収束させる判断が取りやすくなります。
構成要素が多いほど一般論は外れます。監査要件や本番影響が絡む場合は、株式会社情報工学研究所のような専門家に状況を共有し、観測点と判断基準を一緒に設計すると、遠回りが減ります。
/dev の実体がズレると起きる:消えた・古い・別物を指している
ENXIOの典型パターンの一つが、/dev 配下の参照が“正しいように見えて正しくない”ケースです。/dev はデバイスファイルの入口ですが、入口が同じでも、その先が同じとは限りません。特に再起動、機器の差し替え、仮想化基盤の変更、multipath構成、USBストレージの混入などがあると、名前は残っていても実体が変わることがあります。
/devのズレが生まれる代表的な背景
- デバイス番号やパスの揺らぎ(順序が変わる、古いリンクを踏む)
- by-id / by-path のリンクが想定と違う実体を指し始める
- 旧構成の残骸が残り、運用や自動起動が古い参照を使い続ける
- コンテナやchroot内で“見える/dev”が限定され、ホストの想定と食い違う
現場での“腹落ち”としては、「/devは固定名ではなく、運用の結果としての入口」という捉え方が近いです。入口が同じに見えるほど、見落としが起きやすいとも言えます。
安全に確認するポイント(読み取り中心で“別物”を見抜く)
ここでは危険な操作を増やさず、まず「そのデバイスが何者か」を確かめます。重要なのは、“この装置を触ってよい”という同定ができるまで手を広げないことです。
| 確認観点 | 見たい事実 | 判断の意味 |
|---|---|---|
| デバイスの素性 | モデル・シリアル・サイズ・接続経路が想定と一致するか | “別物を見ている”可能性を早期に下げる |
| リンクの実体 | /dev/disk/by-id 等のリンク先がどこへ解決されるか | 設定が“入口”だけを見ていないかを確認する |
| 直近の変化 | dmesg/journalの直近で接続断・再認識が起きていないか | “突然壊れた”ではなく、経路変化の線を評価できる |
この段階では、復旧や修復の話に入るより先に、同じ対象を見ていることを保証するのが先です。対象同定が曖昧なまま進むほど、意図しない箇所に変更が入って収束が遅れます。
レガシー環境で起こりやすい「入口の固定化が逆に危険」な例
古い運用では「/dev/sdb のように決め打ちしていて問題なかった」という経験則が残りがちです。しかし、仮想化・コンテナ・ストレージ階層化が進んだ現在では、決め打ちは“安定”ではなく“固定化された誤参照”になり得ます。特に、障害対応中に機器交換や経路切替が入ると、入口の名前だけが残って中身が変わることがあります。
このとき、現場の本音としては「早く直したい」ですが、正しい近道は、まず入口を疑って宛先を確定させることです。ここを飛ばすと、後で「なぜその操作をしたのか」を説明できなくなり、監査や関係者調整で詰まりやすくなります。
第3章のまとめ(/devのズレは“気づきにくいのに影響が大きい”)
/devの問題は、見た目が単純なぶん、誤った前提のまま動きやすい領域です。だからこそ、読み取り中心の同定で対象を確定し、最小変更で次の層(fstab、外部ストレージ、コンテナ境界)へ進む順序が安全です。
共有ストレージや本番データ、監査要件が絡むほど、一般論だけでは判断が難しくなります。早期に株式会社情報工学研究所のような専門家へ相談し、対象同定と収束手順を並走で固める方が、結果的に被害最小化に繋がります。
fstab・UUID・by-idの落とし穴:正しそうに見えて違う参照先
ENXIOが「起動時」や「mountのタイミング」で表に出るとき、現場で多いのが /etc/fstab と参照子(UUID/LABEL/by-id/by-path)の不整合です。見た目は“ちゃんと書いてある”のに、実体が変わった瞬間から静かにズレ続け、ある日まとめて噴き出すタイプのトラブルです。
レガシー環境ほど「昔からこの書き方で動いている」が強く、構成変更や機器交換が入った後も同じ参照を握り続けることがあります。さらに systemd による起動順や依存関係が絡むと、単なるマウント失敗ではなく、依存サービスが連鎖的に落ちて“場が荒れる”ことがあります。ここでは、焦点を「参照が何を指しているか」に戻して、ノイズカットしながら収束させます。
“参照”がズレる典型パターン
同じ「マウントできない」でも、原因は分岐します。よくある分岐を先に可視化すると、関係者間の会話が整理されます。
| パターン | 起きやすい背景 | 観測ポイント(読み取り中心) |
|---|---|---|
| UUIDが変わった | 機器交換、再作成、復旧作業の途中で識別子が更新された | blkid のUUIDと fstab のUUIDが一致するか |
| by-idリンクが別実体へ | 接続経路変更、コントローラ差し替え、multipath経由化 | /dev/disk/by-id のリンク先解決と実デバイスの同定 |
| LABELが重複/曖昧 | クローン作成、検証用複製、複数台で同名運用 | LABELの重複有無、実際にマウントされている対象 |
まずは“現時点で何がマウントされているか”を確定する
再設定に入る前に、今の状態を正しく言語化できると、被害最小化に効きます。特に「マウントできない」と言いながら、別経路で一部がマウントされていたり、古いマウントが残っていたりすると、判断がぶれやすくなります。
この段階で役立つのは、設計情報(fstab)と実態情報(findmnt、mount、lsblk)を並べて“差分”を見ることです。差分が出た行が、そのまま争点になります。
| 見るもの | 意味 | 説明に使える言い方 |
|---|---|---|
| /etc/fstab | “設計として”どれをどこへ付けたいか | 意図(期待値)の明文化 |
| findmnt / mount | “今”何が付いているか | 現状(事実)の明文化 |
| blkid / lsblk | 識別子(UUID/LABEL)と実体の対応 | ズレの根拠提示 |
systemdの依存で“議論が過熱”しやすいポイント
起動時のマウント失敗は、関係者の体感が悪くなりやすい領域です。サービスが落ちると「アプリが壊れた」と見られがちですが、実際は「前提となるマウントが成立していない」だけ、ということもあります。ここで重要なのは、原因の責任追及に寄せず、収束に必要な争点へ戻すことです。
説明が難しい場合は、「このサービスはこのマウントに依存している」という依存関係の事実を先に共有すると、社内調整が速くなります。依存が整理できると、暫定回避の議論も“安全な範囲”に留めやすくなります。
第4章のまとめ(参照の整合が取れると、修正は最小化できる)
fstabやUUIDのズレは、修正よりも前に“差分を見せる”ことが収束に効きます。どれが設計で、どれが現状かが一致していれば、変更は一点に絞れます。逆に一致していないまま広く触ると、別の不整合を増やしやすくなります。
本番データ、共有ストレージ、監査要件が絡む場合は、一般論のまま決め打ちしにくい領域です。個別構成の前提で最小変更の方針を組み立てるなら、株式会社情報工学研究所へ相談し、争点整理から並走する方が早く収束しやすくなります。
LVM/RAID/multipathで「見えているつもり」が増える瞬間
ENXIOが長引く現場でよく出会うのが、ストレージの階層化が進み、誰もが「見えているつもり」になってしまう状態です。物理ディスク、RAID、LVM、multipath、仮想化、そしてアプリが見るマウントポイントまで、層が増えるほど“宛先”が一本に定まりにくくなります。
この状況で重要なのは、いきなり最下層まで掘らないことです。最小変更の考え方では、上の層から“成立している前提”を一つずつ確認し、崩れている層を特定してから次へ進みます。層を飛ばすと、見え方の違いで議論が荒れ、対人調整に時間を奪われます。
層が増えるほど「同じ言葉」が違う意味を持つ
例えば「ディスクが見えない」という言葉は、現場では複数の意味を持ちます。LVM担当が言う“見えない”と、SREが言う“見えない”と、アプリ担当が言う“見えない”は別物です。言葉のズレを減らすために、層ごとに観測点を決めると、空気を落ち着かせやすくなります。
| 層 | “見えている”の意味 | 争点になりやすいズレ |
|---|---|---|
| 物理/経路 | OSが装置として認識している | 別経路に変わった、断続的に落ちる |
| RAID(md/ハードRAID) | 論理ボリュームとして整合している | degraded、片系の遅延、再同期の影響 |
| LVM | PV/VG/LVが一致して提供できる | VGがpartial、LVが想定と違う |
| multipath | 複数経路の統合が成立している | 片系のみ使用、パス揺らぎ、誤った優先度 |
| マウント/アプリ | 必要な場所に読み書きできる | 違うボリュームに付いている、権限境界が違う |
“見え方”を揃えると、再設定の議論が一気に進む
層のどこで前提が崩れているかを見つけるためには、各層の「識別子」を揃えて同じ対象を追跡するのが近道です。たとえば、アプリが見ているマウントポイントを起点に、対応するデバイス、さらにその下のLVやRAIDを辿る、といった具合です。これにより「話している対象が違う」という無駄な摩擦が減ります。
ここでの再設定は、派手な置換ではなく、参照の一本化が中心になります。参照が一本化できると、ENXIOのような“宛先不成立”の症状は、説明も対応もシンプルになりやすいです。
リーダーが押さえるべき「最小変更」観点(失敗の芽を潰す)
現場リーダーの視点では、技術的な正解だけでなく、切り戻しや説明責任まで含めた“軟着陸”が重要です。階層が深いほど、変更は一つでも影響が広くなります。だからこそ、変更点のログ化、関係者への共有、想定外のときの戻し方を先に整えることが、結果として作業を早めます。
この段階で「監査要件」「共有ストレージ」「本番データ」が絡むと判断が難しくなります。ここは一般論の限界が出やすい領域で、構成の前提を誤ると損失が大きくなります。
第5章のまとめ(層が多いほど、争点整理が最大の技術になる)
LVM/RAID/multipathの環境では、ENXIOの原因が単純でも見え方が複雑になりがちです。層を飛ばさず、同じ対象を追跡できる形で“見え方”を揃えると、ノイズが減って収束が早まります。
個別案件では、運用制約や監査要件を含めた設計判断が必要になります。迷った時点で、株式会社情報工学研究所へ相談し、対象同定と最小変更の再設定方針を一緒に固める方が、被害最小化につながりやすくなります。
iSCSI/NFS/SMBなど外部ストレージで起きる「到達不能」の型
外部ストレージが絡むENXIOは、機器やネットワーク、認証、タイムアウト、経路冗長などが同時に関与し、“原因が一つに見えない”状況を作りやすいのが特徴です。しかも、本番では「止められない」「切り戻しが怖い」「関係者が多い」という条件が重なり、議論が過熱しやすくなります。
ここで意識したいのは、「外部だから難しい」ではなく、到達不能の型を分類してから確認するという考え方です。分類できると、対処の方向性も説明も整理され、クールダウンしやすくなります。
外部ストレージの“到達不能”を型に分ける
| 型 | よくある背景 | 現場での見え方 |
|---|---|---|
| ネットワーク到達 | 経路変更、FW/ACL、VLAN、DNS、MTU、ルーティング | 時々落ちる/特定ノードだけ発生/再試行で戻る |
| 認証・権限 | 資格情報更新、Kerberos/AD連携、NFS export変更 | 接続はできるが操作で失敗/一部パスだけ不可 |
| ストレージ側状態 | ターゲット停止、フェイルオーバー、LUN再割当 | 突然ENXIO/再接続まで待てば戻ることもある |
| タイムアウト・負荷 | ピーク負荷、遅延、キュー詰まり、再送増加 | 障害に見えるが実は性能劣化が先行している |
安全な初動:外部要因を“切り分ける材料”に変える
外部ストレージの障害で重要なのは、誰かの勘ではなく、再現条件とログの相関です。特に「いつから」「どのノードで」「何をした瞬間に」が揃うと、ネットワーク起因か、認証起因か、ストレージ起因かの議論が一気に整理されます。
ここで“やってはいけない方向”は、原因が未確定のまま権限・設定・認証情報を大きく動かすことです。外部要因は一つ動かすと連鎖しやすく、後から「どれが効いたのか」が分からなくなりがちです。収束のためには、まず観測点を揃えて、変更は一点に絞る流れが向きます。
説明責任が重い現場ほど、判断基準を先に置く
監査要件やSLAがある現場では、「直せます」と言い切るよりも、「この条件なら今すぐ相談が良い」という判断基準を先に置く方が、社内調整が進みます。次のような条件が重なる場合、一般論だけで“正しく怖がる”のが難しくなります。
- 共有ストレージで、影響が複数システムへ波及し得る
- 本番データで、切り戻しが難しい
- 監査・法令・契約上、変更履歴と根拠説明が必要
- コンテナや仮想化で、見え方がチーム間で一致しない
こうした状況では、問い合わせフォーム(https://jouhou.main.jp/?page_id=26983)や電話(0120-838-831)で早めに状況を共有し、収束のシナリオを作る方が、結果として損失を抑えやすくなります。
第6章のまとめ(外部要因は“型”で切ると、収束が速い)
iSCSI/NFS/SMBなど外部ストレージ絡みのENXIOは、原因が複合しやすいぶん、到達不能の型に分けて観測点を揃えると、ノイズが減って議論が落ち着きます。変更は一点に絞り、最小変更で進めるほど、説明責任も果たしやすくなります。
個別案件では、ネットワーク・認証・ストレージの境界にまたがる判断が必要になります。一般論の限界が出た時点で、株式会社情報工学研究所のような専門家へ相談し、現場に合った収束ルートを設計する方が、被害最小化につながります。
コンテナ/chroot/名前空間でホストと見え方が食い違う理由
コンテナ環境でENXIOが出ると、現場は一気にややこしくなります。ホスト側のSREは「デバイスは見えている」と言い、アプリ担当は「コンテナ内では見えない」と言う。どちらも事実なのに、会話が噛み合わないことがあります。ここで起きているのは、ホストとコンテナで“同じ名前”を使っていても、同じ世界を見ていないという現象です。
コンテナは、プロセスの分離だけでなく、マウント名前空間や/devの見え方、権限境界(cgroupやcapabilities)など、複数の境界を同時に持ちます。結果として「ホストの/devは存在するが、コンテナには出していない」「出してはいるが操作に必要な権限が足りない」「同じパスだが指している実体が違う」といった食い違いが生まれます。ENXIOは、その食い違いが“宛先不成立”として表面化した形になりやすいです。
まず押さえるべき“見え方の差分”
ここで最小変更の考え方を徹底すると、やることは「修正」より先に「差分の確定」です。差分が確定できれば、修正は一点に絞れます。
| 争点 | ホスト視点での事実 | コンテナ視点での事実 |
|---|---|---|
| /dev が出ているか | 対象デバイスが存在し、リンクも解決できる | /devが最小構成で、対象ノードが存在しないことがある |
| マウントが一致するか | ホストのマウントポイントが成立している | 別のmount namespaceで、同じパスでも実体が違うことがある |
| 権限が一致するか | rootなら操作できる前提で見てしまう | capabilitiesやseccompで操作が制限され、ENXIOに見える失敗が起き得る |
“コンテナだけで起きる”ときに、現場で見落としやすい点
コンテナのトラブルは「アプリのバグ」に寄りやすいのですが、実際には“配置と境界”の問題であることが少なくありません。特に本番でよくあるのは、ホスト側のストレージ変更やデバイス再認識が起きた後、コンテナの設定(デバイスパスやマウントの渡し方)が追随していないケースです。ホストは復旧したのに、コンテナは古い参照を握り続ける、という形です。
もう一つ厄介なのが、「コンテナを作り直せば直る」方向の短絡です。短期的には改善して見えても、根が“宛先の整合”にある場合、再発しやすくなります。収束を急ぐほど、再発防止の観点で“なぜ直ったか”の説明が必要になります。
監査要件や本番データが絡むときの依頼判断
コンテナ環境は、データの所在と責任境界が分かりにくくなりがちです。共有ストレージ、複数サービス、監査要件が重なると、「どこまでが安全な初動か」を一般論で決めづらくなります。ここで無理に権限やデバイス公開設定を広く触ると、後から説明と整合を取るコストが増えます。
個別案件の構成(コンテナランタイム、オーケストレーション、ストレージの渡し方、権限設計)まで踏み込んで収束させる必要がある場合は、株式会社情報工学研究所に相談し、観測点と変更点を一点に絞った進め方を取る方が早くまとまりやすいです。問い合わせフォームは https://jouhou.main.jp/?page_id=26983、電話は 0120-838-831 です。
第7章のまとめ(境界の違いは“事実の不一致”ではなく“見え方の違い”)
コンテナ/chroot/名前空間が絡むENXIOは、誰かが間違っているのではなく、見ている世界が違うことで起きます。ホストとコンテナで、/dev・マウント・権限の差分を確定できれば、修正は最小限に絞れます。
本番データや監査要件が絡むほど、一般論では“安全な範囲”を決めにくくなります。迷いが出た時点で、株式会社情報工学研究所のような専門家へ相談し、最小変更で収束するルートを設計する方が、結果として被害最小化につながります。
再設定の方針:最小変更で“正しい宛先”へ戻す順序を作る
ここまでで見てきたように、ENXIO(6)は「デバイスが無い」だけでなく、参照経路のどこかで“宛先が成立しない”状態が含まれます。だからこそ、再設定は一発勝負の修理ではなく、正しい宛先に戻す順序を作ることが重要です。順序があると、変更点が一点に絞れ、説明責任にも強くなります。
現場の本音としては「楽になるなら導入したいけど、移行コストとトラブルだけは増やしたくない」です。ここに効くのが、最小変更の方針です。最小変更とは、作業量を減らすだけでなく、副作用の確率を下げ、切り戻しを簡単にするという意味を持ちます。
再設定の“順序”を決める(戻す対象を一本にする)
再設定でよくある失敗は、参照子(UUID/by-id)を直したつもりで、実は別の層が不安定なまま、あるいは複数の層を同時に触って因果が分からなくなることです。順序の考え方はシンプルで、「上から下へ」または「影響が小さい層から確実に」戻します。
| 順序 | 狙い | 判断材料 |
|---|---|---|
| ① 対象同定 | “何を直すか”を確定し、別物を触るリスクを消す | サイズ・シリアル・経路・UUIDなどの一致 |
| ② 参照の一本化 | fstabや設定の参照を、安定して追跡できる形に戻す | 設計(fstab)と実態(findmnt/blkid)の差分 |
| ③ 起動・依存の整合 | systemd依存の連鎖を抑え、サービスの再開を安定化 | 起動順・依存・再試行・タイムアウトの設計 |
| ④ 外部要因の切り分け | 外部ストレージやネットワーク要因を型で切り、再発を抑える | 時間相関・ノード差・接続状態・性能劣化の兆候 |
“やらない判断”を先に決めると、収束が早くなる
再設定の局面では、「どこまで触るか」より先に「どこまでは触らないか」を決めた方が、結果として早くまとまります。特に次のような条件がある場合、一般論での決め打ちは危険になりやすいです。
- 共有ストレージで、別システムへの波及があり得る
- コンテナ環境で、権限境界が複雑
- 監査や契約上、根拠説明と変更履歴が必須
- 復旧対象が本番データで、切り戻しが難しい
この条件が重なると、最小変更の範囲を“現場の勘”だけで決めるのが難しくなります。ここで無理をすると、後から説明と整合を取る作業が増え、トラブルだけが増える結果になりがちです。
依頼判断としての再設定(一般論の限界を越える部分)
再設定は、技術だけでなく、業務影響・社内調整・監査対応を含む設計行為です。つまり「正しい設定」には、システム構成だけでなく、運用ルールやリスク許容度が含まれます。ここは一般論で“最適解”を出しづらい領域です。
具体的な案件・契約・システム構成を踏まえて収束させる必要がある場合は、株式会社情報工学研究所へ相談し、最小変更での再設定方針(何を固定し、何を観測し、何を変えるか)を一緒に組み立てる方が、現場の負担を増やさずに進めやすくなります。問い合わせフォームは https://jouhou.main.jp/?page_id=26983、電話は 0120-838-831 です。
第8章のまとめ(再設定は“順序”があると、最小変更で進む)
ENXIO(6)の再設定は、手順の派手さではなく、対象同定→参照一本化→起動依存の整合→外部要因の切り分け、という順序が収束に効きます。順序があると、変更点が一点に絞れ、切り戻しや説明責任にも強くなります。
本番データ・共有ストレージ・監査要件が絡むほど、一般論のままでは安全な範囲を決めにくくなります。迷った時点で、株式会社情報工学研究所のような専門家へ相談し、個別構成に合わせた最小変更の方針を作ることが、被害最小化につながります。
再発防止の実装:監視・変更管理・手戻り設計に落とし込む
ENXIO(6)が一度収束しても、同じ構成変更や機器交換、外部ストレージの揺らぎが再び起きれば、似た形で再発します。再発が厄介なのは、「直し方」よりも「直した後の説明」が難しくなる点です。現場としては、次に同じことが起きたときに、温度を下げて短時間で争点を絞れる状態にしておきたいはずです。
再発防止は、大掛かりな刷新でなくても始められます。ここでの狙いは、移行コストを増やさず、トラブルだけを増やさないために、観測点と変更点を管理可能な形にすることです。
再発防止は「監視」だけでは足りない
監視は重要ですが、ENXIOの本質が“宛先の整合”にある以上、監視だけでなく「参照がズレる条件」を減らす必要があります。具体的には、参照子(UUID/by-id)の運用、起動依存の設計、外部ストレージの到達性と性能の監視、そして変更管理がセットになります。
| 対策領域 | 狙い | 現場で効く理由 |
|---|---|---|
| 参照の標準化 | 誰が見ても同じ対象を追える参照に寄せる | “別物を触る”事故を減らし、調査が速くなる |
| 起動依存の設計 | マウント失敗時の連鎖を抑え、復旧手順を明確化 | 議論が過熱しにくく、社内調整が進む |
| 外部要因の監視 | 到達性と性能劣化を早期に掴む | 障害に見える前に、根拠を持って対処できる |
| 変更管理 | いつ何を変えたかを追跡可能にする | “なぜ直ったか”の説明ができ、手戻りが減る |
現場が楽になる「手戻り設計」
再発防止の中でも、現場の負担を減らすのは手戻り設計です。これは「失敗しない」ではなく、「失敗しても落ち着いて戻せる」を作る考え方です。例えば、参照の変更を一点に集約する、変更前後の状態を比較できる材料を残す、暫定回避の条件と期限を決めておく、といった運用が該当します。
この設計があると、次に似た症状が出たときも、場を整えながら収束に向けた意思決定ができます。現場リーダーの説明もしやすくなり、対人調整の摩擦が減ります。
依頼判断:一般論だけでは詰まりやすい領域
再発防止は、組織の運用・権限・監査・契約条件まで含んだ最適化になります。ここは一般論のテンプレだけでは、現場の制約に合わず形骸化しやすい領域です。特に、共有ストレージやコンテナ、本番データが絡む場合は、監視の置き方や変更管理の粒度を誤ると、かえって負担が増えます。
具体的な案件・契約・構成に合わせて、最小変更で再発確率を落とす設計が必要な場合は、株式会社情報工学研究所へ相談し、現場目線で“続く仕組み”に落とし込む方が、結果として楽になります。問い合わせフォームは https://jouhou.main.jp/?page_id=26983、電話は 0120-838-831 です。
第9章のまとめ(再発防止は“続く形”にすると効果が出る)
ENXIO(6)の再発防止は、監視だけでなく、参照の標準化・起動依存の設計・外部要因の監視・変更管理をセットで考えると、被害最小化と説明責任の両方に効きます。大規模な刷新でなくても、観測点と変更点を管理可能にするだけで、次回の収束が速くなります。
運用制約や監査要件まで含む個別最適が必要な場合、一般論の限界が出やすくなります。迷った時点で、株式会社情報工学研究所のような専門家に相談し、現場に合う形で設計することが、長期的に最も負担が少ない選択になり得ます。
依頼判断の最終章:一般論の限界と、現場が納得して動ける落としどころ
ENXIO(6)のように「宛先が成立しない」症状は、単純な設定ミスでも起きます。一方で、本番では多層構成・外部ストレージ・コンテナ・監査要件が重なり、一般論だけでは“安全な範囲”を決めにくい場面が出てきます。現場の本音は、楽になるなら導入したいが、移行コストとトラブルだけは増やしたくない。ここに対して、落としどころを作るには、技術だけでなく意思決定の型が必要です。
この最終章では「何を根拠に、どこまでを社内で進め、どこからを専門家に渡すか」を、現場リーダーが説明しやすい形に整えます。重要なのは、勇ましい復旧論ではなく、被害最小化と説明責任の両立です。
一般論が効く範囲/効きにくい範囲
一般論が効くのは、対象が明確で、影響範囲が限定でき、切り戻しが容易なときです。逆に、影響が広い・境界が多い・説明責任が重いほど、一般論は“方向性”には使えても“決定”には使いにくくなります。
| 観点 | 一般論が効きやすい | 一般論が外れやすい |
|---|---|---|
| 対象同定 | 単体サーバで対象デバイスが一意に決まる | 共有ストレージ、multipath、複数経路で“同じに見える入口”が複数ある |
| 影響範囲 | 該当サービスのみで完結し、依存が少ない | 起動依存が深く、停止が連鎖しやすい |
| 説明責任 | 社内合意が取りやすく、記録要件が軽い | 監査・契約・法令で根拠と変更履歴が必須 |
| 切り戻し | 手順が明確で、短時間で戻せる | 本番データで戻せない、戻すと損失が大きい |
依頼判断の軸:現場が「これなら納得できる」と言える条件
依頼判断は、能力の問題ではなく、リスクの構造の問題です。次の条件が重なるほど、社内だけで判断を固めるより、専門家と並走して“安全な範囲”を設計した方が収束しやすくなります。
- 共有ストレージで、別システムへ波及する可能性がある
- コンテナや仮想化で、ホストと見え方が一致しない
- 監査要件・契約条件があり、根拠と変更履歴の整合が必要
- 本番データで、切り戻しが難しい(または停止が許されない)
- 外部ストレージやネットワークの要素が絡み、関係者が多い
これらは「直せないから相談」ではなく、「損失・流出の可能性を抑え、説明責任を満たし、最小変更で収束させるために相談」という位置づけになります。問い合わせフォームは https://jouhou.main.jp/?page_id=26983、電話は 0120-838-831 です。
相談を早く収束に繋げる“渡し方”(現場の負担を増やさない)
専門家に渡すときに、現場が心配しやすいのは「余計に手間が増えるのでは」という点です。実際には、必要な材料が揃っているほど、作業は増えずに早く落ち着きます。ここでの材料は、派手な解析ではなく、争点を絞るための最低限です。
| 材料 | 目的 | 現場への効き方 |
|---|---|---|
| 発生時刻と再現条件 | 外部要因・変更との相関を取る | 議論が過熱しにくくなる |
| 対象パスと失敗操作 | どの層で宛先が崩れたかを絞る | 最小変更で済む可能性が上がる |
| 構成の要点(層の数) | 見え方の違いを前提にする | 対象同定の迷いが減る |
| 要件(監査・停止可否) | “触ってよい範囲”を先に決める | 後戻りと説明コストが減る |
締めくくり:現場エンジニア視点で“収束しやすい設計”を選ぶ
ENXIO(6)は、単発のエラーというより、参照と実体の整合が崩れたサインとして出てきます。だからこそ、最小変更で対象同定と参照一本化を進め、境界(ストレージ層・外部要因・コンテナ境界)を型で切り分けると、現場の負担を増やさずに落ち着かせやすくなります。
一方で、本番データ、共有ストレージ、監査要件が絡むほど、一般論だけで安全な範囲を決めにくくなります。具体的な案件・契約・システム構成で悩んだときは、株式会社情報工学研究所への相談・依頼を検討することが、被害最小化と説明責任の両面で合理的な選択になります。問い合わせフォームは https://jouhou.main.jp/?page_id=26983、電話は 0120-838-831 です。
補遺:プログラム言語別に起きやすい“ENXIO周辺”の実装上の落とし穴
ENXIO(6)はOSのエラーとして返ってきますが、アプリ側では例外や戻り値として見えるため、言語・ランタイム・ライブラリによって「見え方」と「扱い方」が変わります。特に、コンテナ境界や外部ストレージが絡むと、失敗が断続的になり、実装の癖が原因調査の難易度を上げることがあります。ここでは、現場でよく詰まるポイントを言語別に整理します。
C / C++(syscallに近いぶん、errnoの扱いが勝負になる)
- 返ってきたエラーを握りつぶすと、宛先不成立の層が見えなくなる。戻り値とerrnoを必ず対で残せる設計が重要になる。
- openできるが後続操作で失敗するケースがあり、失敗地点(openなのか、read/writeなのか、制御操作なのか)を区別できないと調査が長引く。
- ファイルディスクリプタのライフサイクル管理が甘いと、別の失敗に見える症状を誘発し、ENXIO起因の争点がぼやける。
Rust(安全性は高いが、境界のエラー表現を揃えないと混乱する)
- Resultで表現できる反面、エラーのラップが深いと現場が「どの層の失敗か」を追えなくなる。原因(source)の連鎖を辿れる形に整えると収束が早い。
- OS境界(nix等)とアプリ境界(独自エラー)で表現を分けすぎると、ログが断片化しやすい。観測点を一つに集約する設計が効く。
Go(エラーラップは強いが、現場ログが“短すぎる”ことがある)
- errorのラップを活かせる一方、ログ出力が短いと「どのパス/どの操作」かが残らない。対象パスと操作種別を定型で残すと争点が絞れる。
- 並行処理で断続的な失敗が起きると、順序が崩れて原因が見えにくい。時刻・対象・操作・ノード(コンテナ)を揃えて記録するとノイズが減る。
Python(高水準APIの背後で何が起きたかが見えにくいことがある)
- 標準ライブラリや外部ライブラリが例外を抽象化しすぎると、ENXIOが別の例外に見えることがある。元のOSError情報(番号・メッセージ)を失わない設計が重要になる。
- 実行環境差(ホストとコンテナ、権限、マウント)が原因でも、コード側の例外だけ追うと本質に届かない。環境情報をログに残せると調査が短縮する。
Java / Kotlin(例外の階層が深く、I/Oの“どこで失敗したか”が埋もれやすい)
- NIOやストレージクライアントの例外がラップされ、最終的に「入出力例外」に見えることがある。原因例外を辿れるログ設計が重要になる。
- ライブラリが再試行を内包していると、断続的な到達不能が“遅延”として表に出ることがある。タイムアウトや再試行の条件を運用と揃えないと、現場の体感が悪化しやすい。
C#(ランタイム越しのI/Oは扱いやすいが、OSエラーの粒度が落ちる場合がある)
- 例外の種類だけでは層が見えにくくなることがある。例外の内部情報(HRESULTや内包例外)を参照できる形で残すと、宛先不成立の層が特定しやすい。
- ネイティブ連携(P/Invoke等)がある場合、境界で情報が欠落しやすい。境界のログだけは薄くしない方が、収束が早い。
Node.js / TypeScript(非同期I/Oで“いつ失敗したか”が拡散しやすい)
- イベント駆動で、失敗時刻と操作の紐づきが弱いと原因追跡が難しくなる。対象パス・操作・リクエストID等を揃えると、再現条件の整理が進む。
- コンテナ内でのボリューム見え方の差が原因でも、アプリ側は単に“アクセス失敗”に見える。環境差分を前提に観測点を用意すると、議論が荒れにくい。
PHP / Ruby(高水準なI/Oの裏で、OS起因の失敗が短く見えることがある)
- 関数がfalseを返すだけ、例外メッセージが短いだけ、という形だと、層が見えず対人調整が難しくなる。失敗したパスと操作を必ず残せる設計が重要になる。
- 外部ストレージや共有ボリュームの揺らぎがあると、断続的な失敗が“アプリ不安定”に見える。時刻相関とノード差分を拾えるログが効く。
Bash / シェル(小さなスクリプトほど、失敗の根拠が残らない)
- パイプやリダイレクトで失敗箇所が見えにくいことがある。どの操作がどのパスに対して失敗したかを残せると、争点が絞れる。
- 環境変数やカレントディレクトリ差が、宛先不成立を誘発することがある。実行環境の前提を揃える運用が、ノイズカットに効く。
言語共通のポイント(最小変更で収束させるための実装観点)
どの言語でも、収束に効くのは「どのパス/どの操作/どの環境(ノード・コンテナ)で失敗したか」が一貫して残ることです。ここが揃うと、/devのズレ、fstabの参照ズレ、ストレージ層の不整合、外部要因、コンテナ境界といった争点を、型で切って整理できます。
そして、個別案件では契約・監査・停止可否の制約が“安全な範囲”を決めます。具体的な構成と要件を踏まえた判断が必要な場合は、株式会社情報工学研究所に相談し、観測点と変更点を一点に絞った進め方を組み立てることが、結果として被害最小化につながります。問い合わせフォームは https://jouhou.main.jp/?page_id=26983、電話は 0120-838-831 です。
もくじ
- まず共感:ENXIO(6)は「壊れた」より先に「ズレた」を疑う
- errno=6 を読み解く:No such device or address が指す“対象不在”の正体
- 原因トップ3:デバイス消失/ドライバ未ロード/参照パス(設定)の食い違い
- 最短で当てる切り分け:再現条件と「どのプロセスが、何を開いたか」を確定する
- ログの読み筋:dmesg・journalctl・udevadm で“現場の証拠”を揃える
- 罠その1:/dev/sdX を信じると負ける(UUID/LABEL/WWN に寄せる)
- 罠その2:起動順と依存関係(systemd / fstab / mount unit)のズレ
- 罠その3:仮想化・コンテナ・ネットワークストレージで起きる「見えているつもり」
- 再設定の型:永続化(udevルール・fstab・サービス定義)と自動回復(retry/healthcheck)
- 帰結:ENXIO(6)を“事故”から“構成ずれ検知”に変える—再発防止チェックリスト
【注意書き】本記事は、Linux で発生する ENXIO (errno=6) / “No such device or address” の原因解析と再設定について、一般的な情報提供を目的としてまとめたものです。実際の最適解は、OS/カーネル、仮想化の有無、ストレージ種別(ローカル/NAS/SAN/iSCSI 等)、起動構成、権限設計、運用要件(可用性・復旧時間)などの条件で変わります。個別案件の設計判断や障害時の対応はリスクが大きいため、必要に応じて株式会社情報工学研究所のような専門家へご相談ください。
まず共感:ENXIO(6)は「壊れた」より先に「ズレた」を疑う
現場で ENXIO(6) を踏む瞬間って、だいたい余裕がありません。「昨日まで動いてたのに」「リリース触ってないのに」「監視は緑だったのに」。しかもログに出てくるのは短い一行だけで、原因が“人間の脳内コンテキスト”に依存している。ここがいちばんしんどいポイントです。
でも ENXIO は、いきなり「ディスクが物理的に壊れた」みたいな確定演出よりも先に、構成・参照・起動順・接続のどこかがズレたことを疑うのが合理的です。なぜなら ENXIO は多くの場合、「そのデバイス(または相手先)が、今その瞬間に“存在すると言えない状態”」で返ってくるエラーだからです。
心の会話で言うと、こんな感じになります。
「また新しい障害?…いや、たぶん“新しい”んじゃなくて、前から不安定だった部分が表に出ただけだよな」
この“ズレ”を疑う姿勢は、責任転嫁ではなく、切り分けを速くします。壊れた前提で進めると交換・再構築に寄りがちですが、ズレ前提で進めると、ログと設定を並べて差分を取れるからです。
この章のゴール(次章への伏線)
次章では、ENXIO(6) がアプリケーションやカーネルにとって「何を意味しているのか」を、“どの層で返る errno なのか”という視点で整理します。ここが腹落ちすると、以降の切り分けが一直線になります。
errno=6 を読み解く:No such device or address が指す“対象不在”の正体
ENXIO は、UNIX 系で昔から使われている errno のひとつで、メッセージは一般に “No such device or address” と表示されます。重要なのは、「ファイルが無い(ENOENT)」と似て見えるけれど、意味が少し違う点です。ENXIO はしばしば、デバイスファイルは存在するのに、その背後の実体がいないときに出ます。
たとえば、/dev 以下のノードはある。けれど、そのノードが指すべきドライバが未ロードだったり、接続先(iSCSI ターゲット、テープ装置、仮想デバイス、特殊なキャラクタデバイス)が不在だったりする。すると open(2) や関連 I/O が ENXIO を返す、という流れが現場ではよく起きます。
| 観点 | よくある誤解 | 実務での読み替え |
|---|---|---|
| ENOENT | 「対象が無い」 | パスが存在しない/名前解決ができない(ファイル・ディレクトリなど) |
| ENODEV | 「デバイスが無い」 | デバイス種別やドライバとして未対応・未認識 |
| ENXIO | 「どれも同じ“無い”」 | “ノードはある/指定はできた”のに、今その瞬間に相手先が不在(背後実体がいない) |
どの操作で出やすいか(伏線)
ENXIO はアプリのログ上、「open に失敗」「read に失敗」「ioctl が返した」など、見え方がいろいろです。つまり、原因特定には「どのプロセスが」「何を参照して」「どのタイミングで落ちたか」を押さえる必要があります。次章では、その“原因の型”を上位パターンに分解して、最短ルートで当たりを付ける準備をします。
原因トップ3:デバイス消失/ドライバ未ロード/参照パス(設定)の食い違い
ENXIO(6) の原因は環境で幅がありますが、現場での再発率が高い“トップ3”に絞ると、だいたい次の3つに収束します。ここを先に疑うだけで、無駄な調査時間を大幅に削れます。
1) デバイス消失(物理・論理のどちらも)
物理的に抜けた、ケーブルが不安定、USB/SAS/HBA の瞬断、FC/iSCSI のセッション断、NAS の到達不能など。「消失」は必ずしも完全断ではなく、瞬間的に見えなくなるだけでも十分に障害になります。たとえば、起動直後の数秒だけ見えない、夜間バックアップ中だけ詰まる、リンクフラップ時だけ外れる、などが典型です。
2) ドライバ未ロード/モジュール・ファームウェア・権限の不整合
デバイスノードが作られていても、必要なモジュールがロードされていない、ファームウェアが読み込めていない、あるいはコンテナ内で /dev の見え方が変わっている、といったパターンです。特に「更新はしていない」と言いながら、再起動やカーネルアップデートのタイミングで初めて表面化することが多いので、時系列に注意します。
3) 参照パス(設定)の食い違い:/dev/sdX を固定してしまう罠
「/dev/sdb にマウントしていた」「/dev/nvme0n1p1 を前提にしている」など、デバイス名を固定してしまうと、接続順や検出順の変化で参照がズレます。その結果、“存在するはずの相手”を開きに行って、相手がいない扱いになり ENXIO 系で落ちる、という事故が起きます。ここは UUID/LABEL/WWN への寄せが王道です。
切り分けを速くする「最初の3点セット」
この3分類に当てはめるために、最初に押さえる情報は次の3つです。
- いつから:初回発生時刻、直前に起きたイベント(再起動、更新、構成変更、ネットワーク障害)
- どのプロセスが:サービス名、PID、実行ユーザー、起動タイミング(起動直後か、定期ジョブか)
- 何を参照したか:パス(/dev/〜、/mnt/〜)、UUID/LABEL、接続先(iSCSI ターゲット等)
ここまで揃うと、次章のテーマである「再現条件の確定」と「どの呼び出しで落ちたか(open/ioctl など)」に進めます。要するに、当てずっぽうの再起動ではなく、証拠ベースで“ズレ”を追い詰める準備が整います。
最短で当てる切り分け:再現条件と「どのプロセスが、何を開いたか」を確定する
ENXIO(6) を最短で潰すコツは、「推理」ではなく「特定」に寄せることです。現場の肌感として、ENXIO は“原因の候補が多い”というより、どこでズレたかが分からないと永遠に迷うタイプのエラーです。逆に言えば、ズレた場所が一つでも特定できれば、その後は設定とログの差分で一直線になります。
まずやるべきは、再現条件の確定です。毎回出るのか、起動直後だけか、定期ジョブだけか、特定ユーザーだけか、バックアップやスナップショット中だけか。ここが曖昧なままだと、対策が「再起動して様子見」になり、次の夜にまた燃えます。
“誰が、何を、いつ”を固定する(運用目線の一次情報)
障害対応で最初に揃えるべき一次情報は、次の3点です。ログが散らばっていても、この3点が揃えば検索軸が決まります。
- 誰が:サービス名(systemd unit)、実行ユーザー、PID(可能なら)
- 何を:参照したパス(/dev/*、/mnt/*、ソケット、iSCSI ターゲット等)
- いつ:初回発生時刻、直前イベント(再起動、更新、ネットワーク瞬断、ケーブル抜き差し)
心の会話で言うとこうです。
「“そのへんのディスク”って言われても困る。どの unit が、どのパスを掴みに行って死んだの?」
この疑問に答えられるだけで、調査は半分終わります。
システムコールで“何を開いたか”を捕まえる
アプリケーションログが薄いときは、OS側から “何を開こうとして失敗したか” を捕まえます。代表的には strace です。プロダクション環境では負荷や情報漏えい(引数・パス)に配慮しつつ、短時間・限定範囲で使います。
例:サービスの再起動直後だけ ENXIO が出るなら、そのタイミングで追跡します。
# 例:対象プロセスが分かっている場合 sudo strace -ff -p <PID> -o /tmp/strace_enxio
例:起動コマンドが分かっている場合(短時間の再現に限定)
sudo strace -ff -o /tmp/strace_enxio -- /path/to/command --args見たいのは、open/openat、ioctl、read/write、connect などの周辺で、戻り値が -1 になり errno=ENXIO が付く箇所です。そこに「実際に参照されたパス」が残ります。たとえば /dev/sdb を開きに行っている、/dev/disk/by-uuid/… を開けていない、/mnt/data を前提にしている、などが判明します。
“参照は正しいのに相手がいない”を見抜く
ENXIO が厄介なのは、「パスが存在している」ように見えるケースがあることです。たとえば /dev/xxx のノードはあるが、背後のデバイスが消失している。あるいは iSCSI の /dev/dm-* が残骸として残るが実体が繋がっていない。こういう場合は、次章で扱うカーネルログ(dmesg/journalctl -k)と突き合わせて、“見えているつもり”を崩します。
この章の帰結はシンプルです。再現条件 + プロセス + 参照先が確定すれば、ENXIO は「怪談」から「差分調査」に変わります。次章では、その差分の材料になるログを取りにいきます。
ログの読み筋:dmesg・journalctl・udevadm で“現場の証拠”を揃える
ENXIO 対応で一番ありがちな失敗は、「アプリのログだけ」を見て結論を出してしまうことです。ENXIO はデバイス層や接続層が絡むことが多いので、カーネル側のログとデバイスイベントをセットで見ないと、本当の原因に届きません。
まず “カーネルが何を見ていたか” を確認する
最初に見るべきは、カーネルリングバッファと systemd-journald のカーネルログです。以下は実務で使いやすい入口です(環境により出力は変わります)。
# 直近のカーネルログ(リングバッファ) dmesg -T | tail -n 200
systemd 環境なら、カーネルログを時間指定で追う
journalctl -k --since "2025-12-17 00:00:00" --until "2025-12-17 02:00:00"ここで探すのは、デバイスの切断・再接続・I/Oエラー・リンク断の痕跡です。SATA/SAS のリセット、USB の再認識、ネットワークストレージの到達不能、デバイスマッパー(dm-*) のエラー、ファイルシステムのエラーなど、ENXIO の“前段”がここに残ることが多いです。
udev イベントで「消えた/増えた」の瞬間を捕まえる
デバイスの増減や属性変化は udev が扱います。ENXIO の背景に「デバイス名がズレた」「接続順が変わった」があるなら、udev の情報は強い武器になります。
# デバイスイベントを監視(再現が取れる場合に有効) udevadm monitor --udev --kernel
既に存在するデバイスの属性を確認
udevadm info --query=all --name=/dev/sdb | lessたとえば、/dev/sdb が “本当にその機器か” を、シリアルやパス情報から確かめられます。ここで「昨日の sdb と今日の sdb が別物」だと分かれば、原因はかなり絞れます。
ブロックデバイスの“今の見え方”を統一フォーマットで確認する
lsblk/blkid は、ディスク周りを整理して眺めるのに向いています。ENXIO の調査は、最終的に「設定が参照しているもの」と「現物」を一致させる作業なので、ここを丁寧にやるほど後半がラクになります。
# ツリーで見える化(マウントポイントも) lsblk -o NAME,TYPE,SIZE,FSTYPE,UUID,LABEL,MOUNTPOINT
UUID/LABEL を確定
blkid
/dev/disk 配下の永続名(by-uuid/by-id/by-path)を確認
ls -l /dev/disk/by-uuid
ls -l /dev/disk/by-id
ls -l /dev/disk/by-pathポイントは、/dev/sdX のような“揺れる名前”ではなく、UUID や by-id のような“揺れにくい名札”で同一性を確認することです。次章では、これを前提に「/dev/sdX を信じると負ける」理由と、再設定の実例に踏み込みます。
ログが取れない/残っていないときの現実的な対処
もし「再現しない」「ログがローテート済み」「障害が瞬間で終わる」などで証拠が残らない場合は、監視設計そのものを見直す必要があります。たとえば、カーネルログの保持期間、journald の永続化、ストレージ断検知のアラート条件などです。ここは一般論だけで決めると、要件(性能・保持・監査)に合わないことが多いので、運用設計とセットで検討するのが安全です。
罠その1:/dev/sdX を信じると負ける(UUID/LABEL/WWN に寄せる)
ENXIO 対応で、再発防止まで含めて効く“王道”がこれです。/dev/sdX に依存した構成をやめる。現場感として、これだけで「月に1回燃える謎障害」が「年に1回の点検項目」くらいに落ちるケースが珍しくありません。
/dev/sdX は、接続順・検出順・コントローラの状態・リブート時のタイミングなどで変わり得ます。つまり、/dev/sdb を前提にしている構成は、未来の自分に“当たりくじ”を引かせ続ける設計になってしまいます。
なぜ /dev/sdX がズレるのか(事実ベースの前提)
Linux は起動時にデバイスを列挙し、ドライバの初期化や udev の処理の流れの中で /dev のノードが作られます。この順序は、物理構成だけでなく、起動時の時間差やドライバのロード順でも影響を受けます。したがって、同じ筐体でも「今日は sdb、明日は sdc」ということが起こり得ます。
心の会話としては、これです。
「昨日の sdb が今日も sdb だと思うのは、人間の願望でしかない…」
置き換え先の選択肢:UUID / LABEL / by-id / WWN
実務では、用途に応じて“安定名”を使い分けます。
| 方式 | 特徴 | 向いている場面 |
|---|---|---|
| UUID | ファイルシステム単位の一意ID。ズレに強い。 | fstab のマウント、永続化の第一候補 |
| LABEL | 人間が読めるが、重複・変更の運用事故が起きやすい。 | 小規模で運用ルールが固い環境 |
| /dev/disk/by-id | 機器固有に寄る(シリアル等)。物理同一性に強い。 | 物理ディスク単位の追跡、交換運用がある環境 |
| WWN | SAN/FC などでの識別に使われることが多い。 | エンタープライズストレージ、マルチパス構成 |
fstab の再設定例(/dev/sdX → UUID)
再発防止の定番は /etc/fstab の参照を UUID に置き換えることです。以下はあくまで形の例です(実際のUUID・マウントオプションは環境で異なります)。
# 悪い例(ズレる可能性がある) /dev/sdb1 /data ext4 defaults 0 2
典型的な改善例(UUIDに寄せる)
UUID=xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx /data ext4 defaults 0 2ここで大事なのは、「設定を変えたら終わり」ではなく、起動順・依存関係・復旧挙動まで見て設計することです。たとえばネットワークストレージなら、ネットワークが上がる前にマウントしようとして失敗し、サービスが巻き込まれて ENXIO を誘発することがあります。次章以降で扱う systemd 依存関係やマウントユニット設計は、まさにこの伏線の回収になります。
一般論の限界(次の章への伏線)
UUID 化は強い一手ですが、すべての環境で万能ではありません。暗号化(LUKS)、LVM、iSCSI、マルチパス、コンテナ、クラウドディスクなど、階層が増えるほど“どの層の安定名を採るか”が設計問題になります。次章では、起動順と依存関係(systemd / fstab / mount unit)が絡むケースを、ENXIO の再発パターンとして整理し、設計として潰す方法を解説します。
罠その2:起動順と依存関係(systemd / fstab / mount unit)のズレ
ENXIO(6) の再発で多いのが、「設定は直したはずなのに、再起動したらまた出た」というパターンです。これは、参照先(UUID化など)そのものは正しくても、“その参照先が使える状態になる前にプロセスが動いてしまう”ことで起きます。つまり、デバイスやマウントが“まだ準備中”なのに、アプリが当然のように I/O しに行って落ちる。現場ではこれが一番イライラします。
心の会話にすると、こうです。
「起動直後だけ落ちるの、いちばん嫌い。監視も緑→赤→緑で、説明が面倒なんだよ…」
よくあるズレの発生点
- /etc/fstab に書いたマウントが、ネットワークやセッション確立より先に走る(iSCSI、VPN、NAS 等)
- systemd サービス が、マウント完了やデバイス出現を待たずに起動する
- 自動マウント の遅延(automount)を前提にしていないアプリが、起動直後に即アクセスして失敗する
- デバイスの安定化待ち(HBA 初期化、マルチパス確立、暗号化解除、LVM 有効化)が必要なのに待っていない
fstab と systemd の“設計としての回答”
再発を防ぐために、単に「マウントできるはず」にせず、待つ・遅らせる・失敗時の挙動を定義するのがポイントです。代表的な考え方を、用途別に整理します(環境により採否は変わります)。
| 目的 | 代表的な手段 | 注意点 |
|---|---|---|
| 起動を止めずに進めたい | fstab の nofail、systemd の条件分岐(Condition*) | “落ちないがデータに書けない”状態を許容する設計になり得る(アプリ側の扱いが重要) |
| アクセス時に自動で起こしたい | x-systemd.automount(オンデマンド) | 初回アクセスで待ちが発生する。タイムアウト設計が必要 |
| デバイス出現まで待たせたい | x-systemd.device-timeout、サービス側で依存関係を明示 | 待ち時間を無制限にすると起動遅延が事故になる。現実的な上限が必要 |
| 特定マウントが必須 | サービス unit に RequiresMountsFor=、After= を設定 | 「必須」にすると障害時にサービスが起動しない。運用上の判断が必要 |
“ENXIOを出さない”より“ENXIOが出ても壊さない”
依存関係の設計で重要なのは、「エラーをゼロにする」より、エラー時にどこで止め、どこで諦め、どう復旧するかを明確にすることです。たとえば、ログ収集系は多少の遅延やリトライで吸収できる一方、DB のデータ領域は曖昧にすると整合性事故になります。
ここは一般論だけで決めると危険です。RTO/RPO、監査要件、夜間無人運用、保守体制などで最適解が変わります。次章では、仮想化・コンテナ・ネットワークストレージが絡むときに「見えているつもり」でハマるポイントを整理します。
罠その3:仮想化・コンテナ・ネットワークストレージで起きる「見えているつもり」
ENXIO(6) の調査が長引くのは、「見えている範囲」が層によって違うからです。ホストでは見える、VM では見えない。VM では見える、コンテナでは見えない。あるいはデバイスノードはあるけど、I/O できない。こういう“見えているつもり”が、判断を狂わせます。
仮想化(VM)の典型:デバイスの種類が変わる/切断が抽象化される
VM 環境では、物理ディスクではなく仮想ディスク(virtio-blk、SCSI エミュレーション等)として見えます。ホスト側ストレージの瞬断やパス障害が、ゲスト側では別の形で現れます。結果として、ゲストは「指定した相手がいない」状態になり、I/O が ENXIO を返すことがあります(特にブロックデバイスやデバイスマッパー層が絡むと追いにくい)。
このとき重要なのは、ゲストだけで完結させようとしないことです。ゲストのログ(journalctl -k 等)と、ホスト/基盤側(ハイパーバイザ、ストレージ装置、パス管理)のログを突き合わせないと、“どこで消えたか”が見えません。
コンテナの典型:/dev はあるが使えない(権限・デバイス許可・マウント)
コンテナ(Docker/Kubernetes 等)では、ホストの /dev をそのまま使えるわけではありません。デバイスを渡していない、cgroup の device 制限で許可されていない、あるいは rootless 実行で権限が足りない、などで「デバイスノードは見えるのに open できない/I/Oできない」状況が起きます。ここで返るエラーは環境や操作によって変わりますが、ENXIO を含め“対象不在”系に見えることがあります。
特に注意したいのは、ホスト上で動くと問題ないツールを、そのままコンテナ化して「同じはず」と思ってしまうことです。コンテナは“プロセス分離”であって“ハードウェアが等価”とは限りません。
ネットワークストレージの典型:上位は“パス”に見えるが下位は“セッション”で死ぬ
ネットワークストレージ(iSCSI、SAN、NAS 等)が絡むと、上位(アプリ)は単なるパス(/data など)として扱っていても、下位ではセッション・パス・認証・名前解決が絡みます。たとえば iSCSI の再接続が間に合わない、マルチパスが収束していない、ターゲットが一時的に落ちた、などで、ブロックデバイスが“いない扱い”になり得ます。
ここでのポイントは、「ネットワークが生きているか」だけでは不十分なことです。DNS は引ける、Ping は通る、でもセッションが確立していない、というのは普通に起こります。だからこそ、前章の依存関係設計(network-online、セッション確立待ち、timeout 設計)が効いてきます。
“境界”を跨ぐと一般論の限界が早い
仮想化・コンテナ・ネットワークストレージを跨ぐと、最適な監視点や復旧手順は環境依存になります。どこでログを取るか、どの層でリトライするか、どの層でフェイルオーバーするかは、システム構成と契約(SLA、保守範囲)で決まるからです。次章では、ENXIO を単発対応で終わらせず、永続化と自動回復まで含めて“再設定の型”としてまとめます。
再設定の型:永続化(udevルール・fstab・サービス定義)と自動回復(retry/healthcheck)
ENXIO(6) の対処は、(1)今すぐ復旧させる、(2)次の再起動でも崩れない、(3)次に崩れても自動で戻る、の三段階で考えると失敗しにくいです。現場の本音は「二度と夜中に起こされたくない」だと思います。だから“永続化”と“自動回復”までを設計に含めるのが重要です。
ステップ1:一時復旧(事故を止血する)
まずは「何が見えていないか」を特定し、対象を復旧させます。例としては、デバイスの再認識、セッションの再確立、マウントの再実行、サービスの再起動などです。ただし、ここで注意が必要です。止血は大事ですが、止血の手順が“本番データを壊す手順”になってはいけません。
- 書き込み先が本当に正しいか(別ディスクに書く事故を防ぐ)
- ファイルシステムチェックや修復は、根拠と手順を持つ(無根拠な fsck は事故になり得る)
- 暗号化・LVM・マルチパスなど階層がある場合は、下位から順に整合を取る
ステップ2:永続化(次の再起動で崩れない)
ここが“再発防止”の本丸です。前章までの内容を踏まえると、永続化の軸は次の通りです。
- 識別子の安定化:/dev/sdX から UUID/by-id/WWN へ寄せる
- 依存関係の明示:サービスが「マウント完了後」に起動するようにする(RequiresMountsFor 等)
- 失敗時の挙動:nofail/timeout/automount 等で“止め方”を設計する
必要に応じて、udev ルールでデバイスの命名や権限を安定化させることもあります。ただし、udev ルールは強力な反面、誤ると別デバイスに適用されるリスクもあるため、検証と運用ルール(レビュー、変更管理)が不可欠です。
ステップ3:自動回復(次に崩れても戻る)
ENXIO を「発生させない」設計だけでは、現実には限界があります。瞬断や上位基盤障害はゼロにできないからです。そこで、壊れたときに“どう戻るか”を決めます。代表的な考え方は以下です。
| 対象 | 自動回復の例 | 注意点 |
|---|---|---|
| systemd サービス | Restart=on-failure、StartLimit の調整、依存関係の明確化 | “無限リトライ”は症状を隠す場合がある(監視とセット) |
| マウント | automount、timeout、再マウント手順の自動化 | データ整合性の要件次第では自動復旧が危険になる |
| 接続(iSCSI等) | セッション監視と再確立、マルチパスの健全性監視 | 保守範囲(基盤/ネットワーク/ストレージ)と責任分界が重要 |
運用ドキュメントが“防波堤”になる
ENXIO 対策は、結局のところ「設計・設定・運用」の三点セットです。だから、再発防止チェックリスト(どのログを見るか、どの識別子で固定しているか、依存関係はどうなっているか)を残すだけで、次回の復旧速度が変わります。ここまで来ると、ENXIO は“謎の障害”ではなく、“構成ずれを検知するイベント”として扱えるようになります。
次章では、ここまでの伏線を回収して、ENXIO(6) を「事故」から「設計改善」へつなげる結論と、読者が取りやすい次の一歩をまとめます。
帰結:ENXIO(6)を“事故”から“構成ずれ検知”に変える—再発防止チェックリスト
ENXIO(6) は、現場にとっては“嫌なエラー”ですが、見方を変えると「構成がズレた」ことをOSが教えてくれているとも言えます。だから、闇雲に消そうとするより、ズレが起きても安全に止まり、戻り、説明できるように整える。そのほうが、現場の負担は確実に減ります。
導入の共感に戻ると、こうです。
「また新しいツール?どうせ運用が増えるだけじゃないのって、正直思いますよね。」
その疑いは健全です。だからこそ、ENXIO 対策も“ツール追加”ではなく、いまあるLinuxの仕組み(識別子・ログ・依存関係)で、運用を減らす設計として組み立てるのが筋です。
再発防止チェックリスト(要点だけ先に)
- 識別子:/dev/sdX 依存を排除し、UUID/by-id/WWN で固定できているか
- 依存関係:サービス起動は「マウント完了後」「セッション確立後」になっているか
- ログ:dmesg/journalctl -k を障害時刻で追えるように保持設計できているか
- 境界:VM/コンテナ/ネットワークストレージの責任分界と調査手順が決まっているか
- 復旧:自動回復(再起動/再マウント/再接続)の範囲と危険域が定義されているか
- 説明:上司・顧客に「何がズレたか」を説明できる材料(ログと設定差分)が揃うか
一般論の限界:ここからは“システムの個別事情”で決まる
ただし、ここまでの話はあくまで一般論です。実際の現場では、次のような“個別事情”が絡みます。
- 可用性要件(止めてよいのか、止めたらいけないのか)
- データ整合性(自動復旧してよい範囲、手動確認が必要な範囲)
- 基盤の契約・保守範囲(オンプレ、クラウド、ストレージベンダ、ネットワーク事業者)
- 監査・セキュリティ(ログ保持、アクセス権限、変更管理)
たとえば「nofail にして起動は通す」が正解の現場もあれば、それが致命傷になる現場もあります。だから、“何を守るべきか(データか、可用性か、運用負荷か)”を先に決め、その上で設定を落とし込む必要があります。
次の一歩:困った時は、構成と運用をセットで相談するのが最短
ENXIO(6) を繰り返す環境は、単に「設定が間違っている」のではなく、構成・運用・保守体制の境界で無理が出ていることが多いです。ログの保持や依存関係の見直し、ストレージ構成の整理、復旧手順の標準化まで含めて設計すると、障害対応の回数そのものが減ります。
具体的な案件・契約・システム構成(仮想化の種類、ストレージ方式、SLA、変更管理、監査要件)で悩んだときは、一般論を積み上げるより、株式会社情報工学研究所のような専門家に相談し、現物のログと設定を根拠にした設計判断を行うほうが結果的に安全で早いケースがあります。
現在のプログラム言語各種:ENXIO/デバイスI/Oを扱うときの注意点(実装・運用の落とし穴)
ENXIO(6) はOSが返すエラーなので、最終的にはアプリケーションがどう扱うか(ログ、リトライ、終了判断)が現場品質を左右します。ここでは主要言語ごとに、デバイスI/Oやマウント依存の処理で起きやすい落とし穴を整理します(言語の優劣ではなく“失敗パターン”の話です)。
| 言語 | 注意点(要点) |
|---|---|
| Python | 例外で握りつぶすと原因が消える。OSError の errno を必ずログに残す設計にする。リトライは無制限にせず上限・待機・中断条件(整合性)を決める。マルチスレッドはI/O待ちに強いが、起動順やマウント未完了を“偶然通る”ことで再現性が悪くなりやすい。 |
| Java | IOException で抽象化され errno が見えにくいことがあるため、原因(メッセージ/stack trace/対象パス/タイムスタンプ)を構造化ログに残す。起動時に必要リソースが揃っている前提のアプリは、systemd依存関係とセットで設計する。スレッド/プールでリトライが雪だるま化しないよう制御が必要。 |
| C | errno はスレッドローカルだが、ログ出力の直前に別APIを呼ぶと上書きされ得るため、失敗直後に errno を退避して記録する。ポインタ/バッファ扱いの事故がENXIOと混在すると切り分け不能になるので、I/Oエラーは戻り値・errno・対象を必ずセットで出す。 |
| C++ | 例外設計(throw)と errno/戻り値の境界を曖昧にするとログが分断される。RAIIでリソース管理は強いが、例外で途中終了したときに「どのデバイスを開いていたか」が分からない設計になりやすいので、識別子(パス/UUID)を常にログに載せる。 |
| C# | .NET の例外は情報量が多い一方、OS errno が直接見えないケースがあるため、対象パス・呼び出し箇所・環境情報(コンテナ/ユーザー権限)を必ず添える。Windows/WSL/コンテナなど実行基盤が混在すると“見えているつもり”が起きるので、実行環境を固定して診断する。 |
| JavaScript(Node.js) | 非同期I/Oでエラーがイベントとして流れるため、await/Promiseチェーンで握りつぶすと再現不能になる。fs系エラーは code/errno/path を構造化して残す。再接続・再試行を実装する場合、並列にリトライが走りすぎると逆に復旧を遅らせる(スロットリングが重要)。 |
| TypeScript | 型で安全になる一方、運用上の“外部状態”(マウント未完了、デバイス不在)は型で守れない。結果型(成功/失敗)を明示し、エラーに対象・時刻・再試行回数を必ず付加する。コンテナ前提なら、/devや権限制約の前提をドキュメント化する。 |
| PHP | ファイルI/Oエラーが警告として出て終わる構成だと、監視が拾えず静かに失敗する。例外化・ログ統一が重要。長時間プロセス(キュー/ワーカー)では、マウント切断後の“古いハンドル”を握り続けて症状が拡散しやすいので、失敗時に再初期化する設計が必要。 |
| Go | error が値として返るため扱いやすいが、ラップ(fmt.Errorf, errors.Wrap等)で原因が追えなくならないよう、元エラー(syscall.Errno)と対象(パス/デバイス)を保持する。並行処理が簡単な分、リトライの同時多発で復旧を妨げないよう、制御(バックオフ/単一フライト)が必要。 |
| Rust | Result で失敗を表現できるが、運用ログが薄いと結局追えない。io::ErrorKind だけでなく raw_os_error(errno)と対象を必ず記録する。安全性は高いが、“外部世界”(デバイス消失)の失敗は普通に起きるため、復旧戦略(再試行/中断/フェイルセーフ)を先に決める。 |
| Swift | 例外・エラー表現が環境(Linux/Apple)で差が出るため、Linux上のサーバ用途では errno を含むログ設計を意識する。ファイル・ソケット・デバイスの扱いで、失敗時に“どのパスを触っていたか”が残らないと解析が止まるため、対象情報の付与が重要。 |
最終的には、どの言語でも「OSが返した失敗を、運用で使える形(対象・時刻・層・回数・環境)にして残す」ことが、ENXIOの再発防止に直結します。一方で、どこまで自動回復させ、どこで止めるべきかは、データ整合性・可用性・契約条件で変わります。一般論で迷い続けるより、現物ログと構成を前提に、株式会社情報工学研究所へ相談しながら“設計としての答え”に落とし込むことをおすすめします。
ENXIOエラー概要とリスク
LinuxにおけるENXIO(6)エラーは、指定されたデバイスまたはアドレスが存在しない場合に発生します。本章ではエラーの定義、想定される要因、および組織が直面する法的・運用上のリスクを概説します。
概要
ENXIOエラーはカーネルが該当するデバイスファイルを開けなかった際に返されるエラーコードであり、物理デバイスの故障やデバイスノードの設定ミス、カーネルモジュール未ロードなどが原因です。本エラーを適切に管理しないと、サービス停止やログ監査義務の不履行につながりかねません。【想定】
組織はBCP(事業継続計画)において、デバイス未検出時の復旧手順と監査証跡の確保を定義しなければなりません。特に、電子帳簿保存法等の法令ではログ保存義務が課されており、対応不備は罰則対象となる可能性があります。[出典:国税庁『電子帳簿保存法の概要』令和5年] 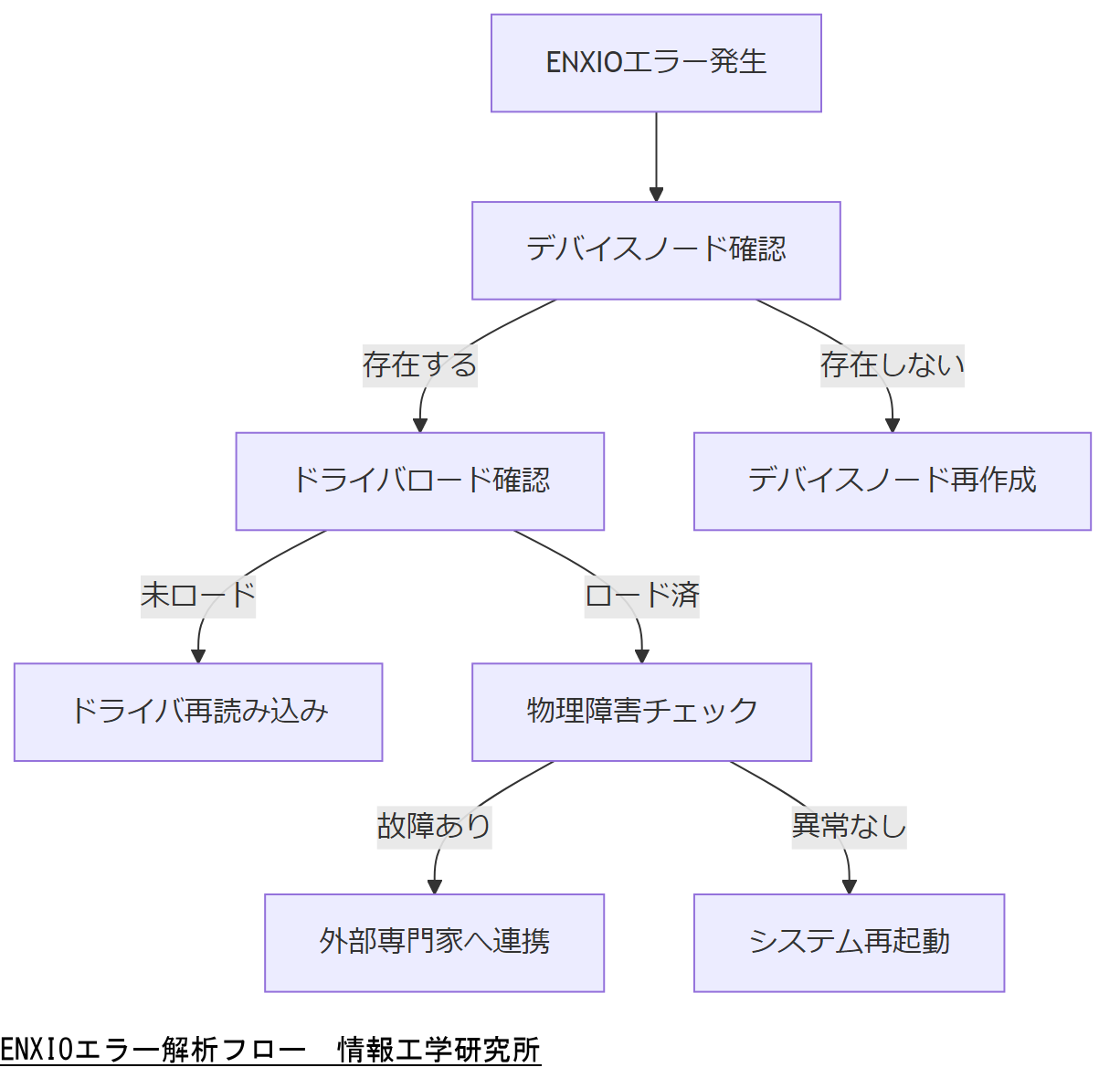
ENXIOエラーの背景には複数要因があるため、一つの要因に絞らず幅広く確認する必要があることをご説明ください。
デバイスノードやドライバの状態確認では、見落としがちな権限設定やsysfsの更新タイミングに注意してください。
原因特定のステップバイステップ
ENXIOエラーを確実に解消するためには、システムログ解析、デバイス情報取得、テスト手順の順序化が重要です。本章では具体的なコマンド例と手順を示します。
ログ解析
まずはdmesgコマンドでカーネルログを確認します。該当時刻のメッセージから、どのデバイスが認識されていないかを特定します。【想定】
デバイス情報取得
次にudevadm infoコマンドでデバイスノードの情報を確認し、設定ミスやルールの抜け漏れを検出します。【想定】
物理および仮想デバイス調査
物理デバイスの場合はsmartctl等でディスクのヘルスチェックを、仮想環境の場合はホスト側の設定・パーミッションを検証してください。【想定】
BCP対応
復旧手順については、内閣府『事業継続ガイドライン』に基づく3重化保存と3段階オペレーションを参考にマニュアルを作成してください。[出典:内閣府『事業継続ガイドライン-あらゆる危機的事象を乗り越えるための戦略と対応-』令和3年] 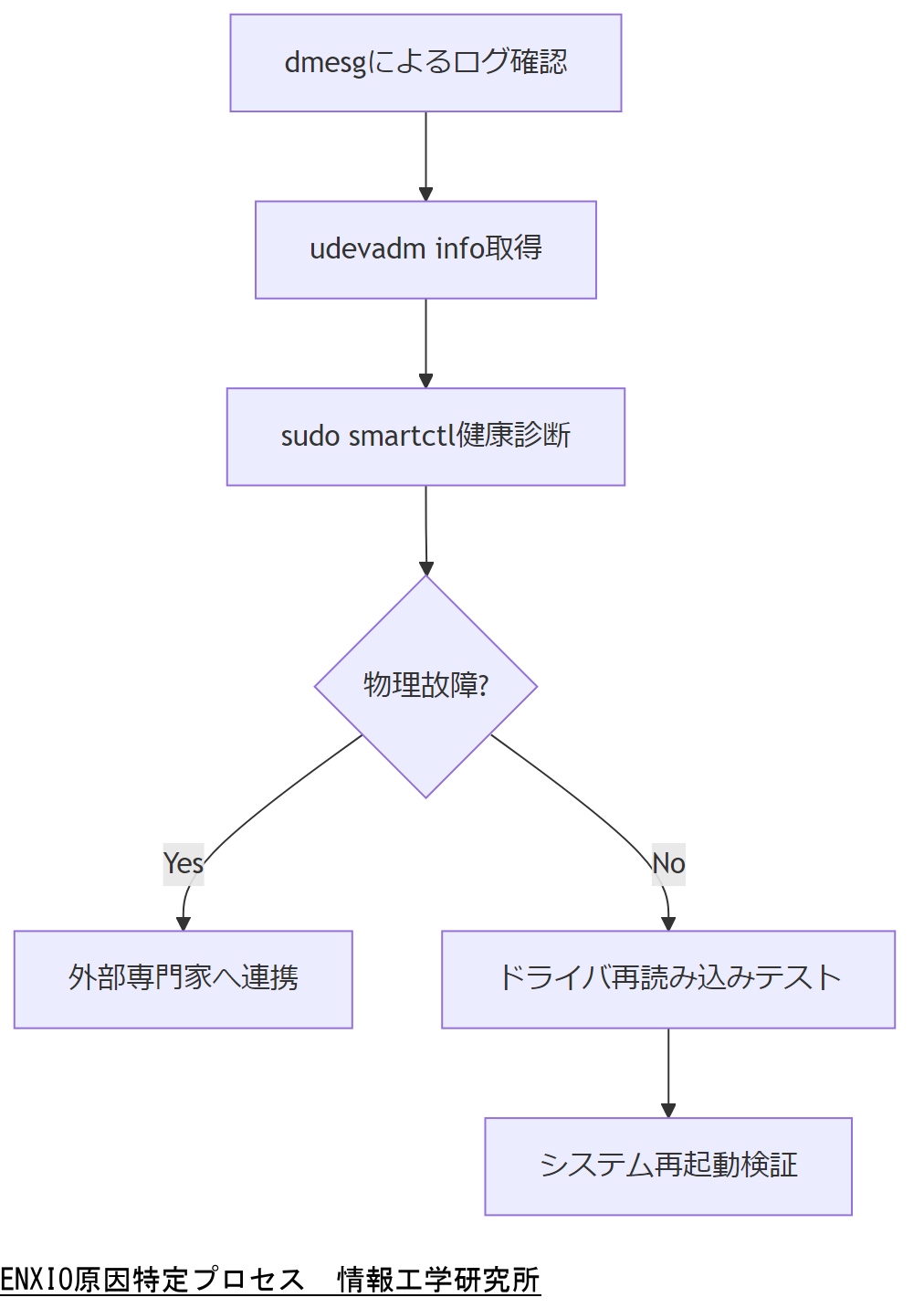
ログ解析やデバイス情報取得は複数担当でダブルチェックし、見落としリスクを低減するようご説明ください。
smartctlの結果解釈やudevルールの適用順序に誤りがあると再発するため、手順を文書化しステークホルダーで共有してください。
再設定と検証
デバイス未検出後の復旧では、ストレージやネットワークの再設定を行い、確実にシステムが再認識することを検証します。
LVM/RAIDの再構築
障害デバイスが論理ボリューム管理(LVM)やRAID上で動作している場合、該当ディスクの再アセンブルおよびRAIDアレイのリビルド手順を実行してください。
ネットワークデバイスのリセット
ネットワークインタフェースでENXIOが発生する場合は、ipコマンドで該当インタフェースを一旦DOWNにしてからUPし、ethtoolでリンク状態を確認してください。
操作手順の文書化と訓練
内閣官房「事業継続ガイドライン」に基づく3重化保存と3段階オペレーション手順をマニュアル化し、定期的に訓練・点検を実施することが推奨されます。[出典:内閣官房『すそ野の広いBCP普及のためのノウハウ集』平成29年] 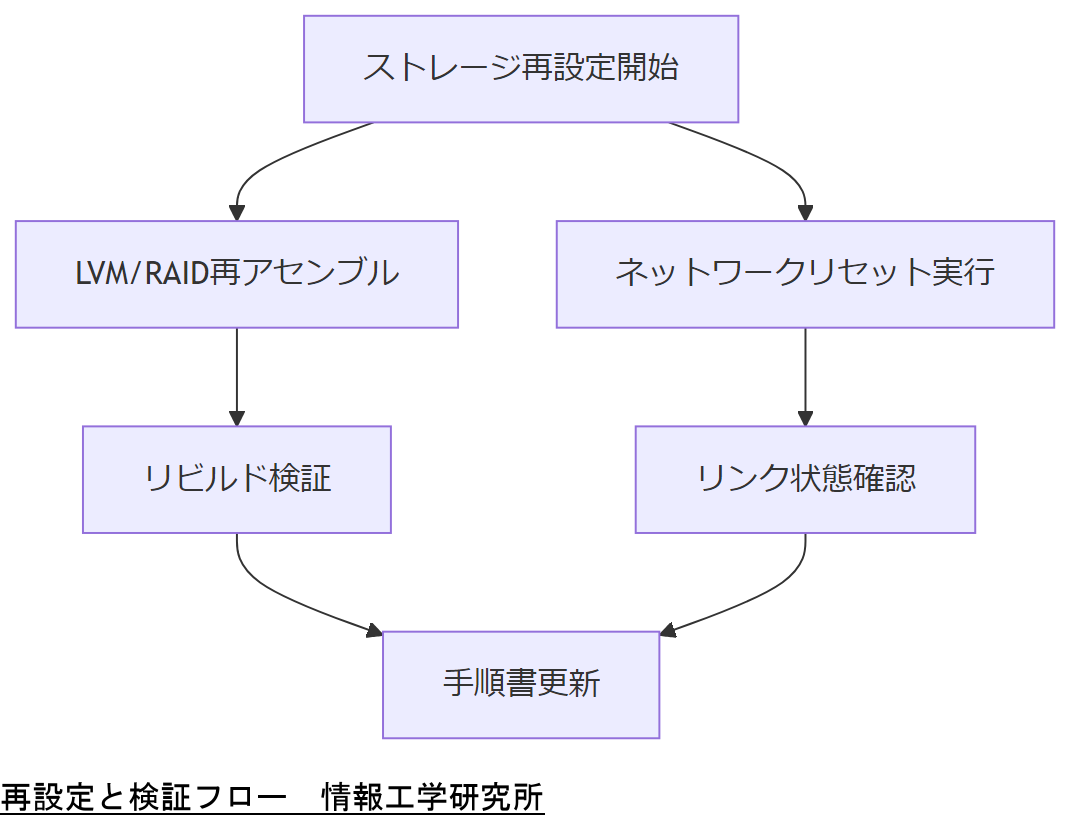
再構築手順では、手順書と実際の操作順序が一致しているかを必ずダブルチェックするようご説明ください。
ストレージ再構築時のRAIDレベルやパーティション設定を誤るとデータ損失リスクが高まるため、事前にバックアップ取得と検証環境でのテストを必ず行ってください。
コンプライアンス要件と監査証跡の確保
システムログや監査証跡は、法令やガイドラインに則り一定期間保存し、税務調査や監査に対応できる状態を維持する必要があります。
電子帳簿保存法の要件
電子取引データ保存には、改ざん防止措置および検索機能の確保が求められます。システムはタイムスタンプ付与や履歴管理機能を備え、所轄税務署からのダウンロード要求に応じられるようにしてください。[出典:国税庁『電子帳簿保存法の概要』令和5年]
ログ保存義務
個人情報保護法や電子帳簿保存法では、ログの保存期間やアクセス記録の保持が規定されています。ログフォーマットや保管先を標準化し、監査時に迅速に提示できる体制を整備してください。[出典:国税庁『電子帳簿等保存制度特設サイト』令和6年]
監査証跡の定期点検
監査証跡は定期的に照合し、欠落や不整合がないかをチェックするプロセスを設けることが重要です。証跡保全の運用ルールを事前に定め、社員教育を実施してください。
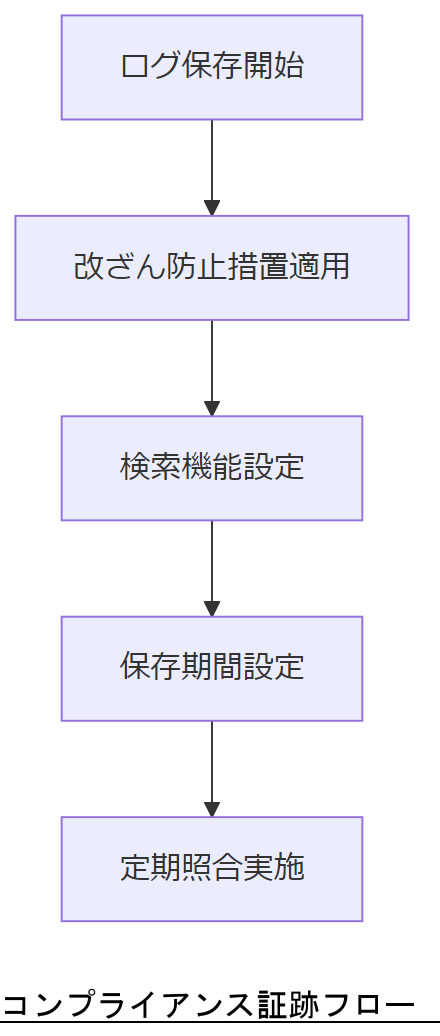
監査証跡はシステム部門だけでなく総務・経理部門とも連携し、保存要件と運用ルールを共有するようご説明ください。
ログの改ざん防止には専門知識が必要な場合があるため、システム開発と運用部門で連携し、外部ツール導入も検討してください。
BCP再設計:3重化と3段階オペレーション
事業継続計画(BCP)は、平常時から緊急時まで一貫したマネジメント活動が求められます。内閣府のガイドラインでは、システムやデータの3重化保存と、平時・無電化時・停止時の3段階オペレーションを明確に定義することが推奨されています。
具体的には、主要データを地理的に分散した3か所に保存し、定期的に復旧テストを実施します。また、各段階での対応責任者、連絡網、手順書を整備し、教育・訓練を通じて全社的なBCM体制を構築する必要があります。
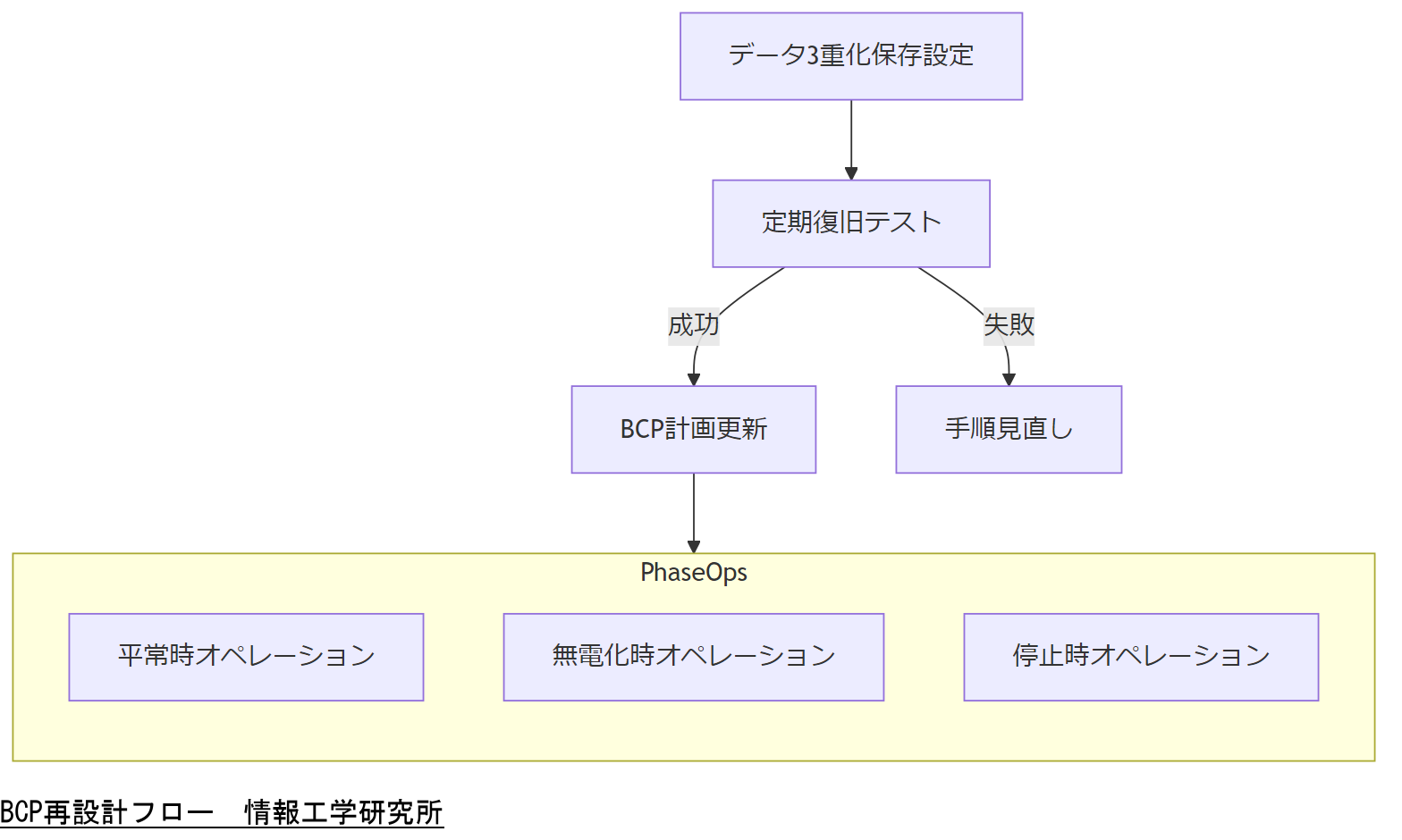
BCP再設計では、各フェーズの責任分担と手順の整合性を必ず確認し、全社で共有する必要があることをご説明ください。
3重化保存の運用では、バックアップウィンドウやネットワーク帯域の制限を考慮し、復旧テストを定期的に実施する負荷を管理してください。
10万人超ユーザー対応の多段階BCPモデル
ユーザー数10万人を超える大規模システムでは、BCPをさらに細分化し、地域別避難所モデルや通信制限モデルを組み合わせた多段階シナリオが必要です。EUのNIS2指令では、重要インフラ事業者においてリスク管理とインシデント報告体制の強化を義務付けています。
具体的には、第一段階でユーザーへの通知・代替手段提供、第二段階で業務調整・通信優先制御、第三段階で代替サーバーへの切り替えと段階的サービス復旧を実施します。各段階での対応指標(RTO/RPO)を設定し、定量的に管理することが求められます。
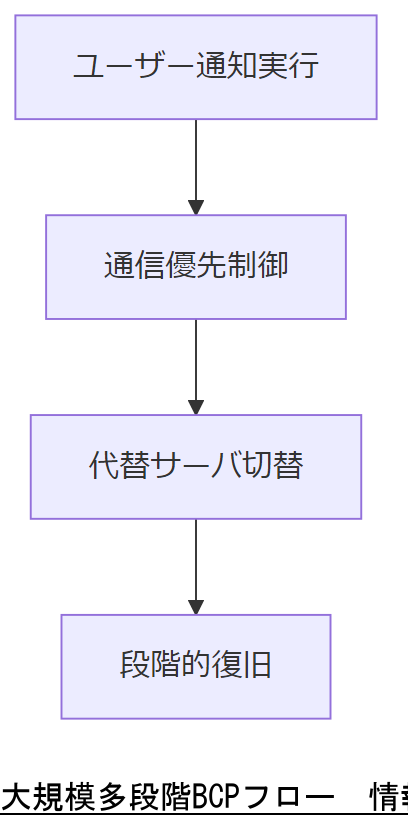
大規模システムでは多段階シナリオのテストが複雑になるため、ステークホルダー間で実施頻度と対象範囲を合意しておくことをご説明ください。
多段階復旧では、各フェーズの切り替え条件や優先順位を適切に定義しないと、誤った切り替えが発生するリスクがあるため注意してください。
デジタルフォレンジック体制構築と人材育成
デジタルフォレンジックは電磁的記録を証拠化する技術で、警察庁のガイドラインに基づき適正な手続きを経て解析・保全します。弊社は証拠保全から解析レポート作成、人材育成までワンストップで支援可能です。
組織内にCSIRT(Computer Security Incident Response Team)を設置し、定期的な研修・演習を実施します。また、外部研究機関との技術情報共有を行い、最新攻撃手法や解析手法をキャッチアップすることが重要です。
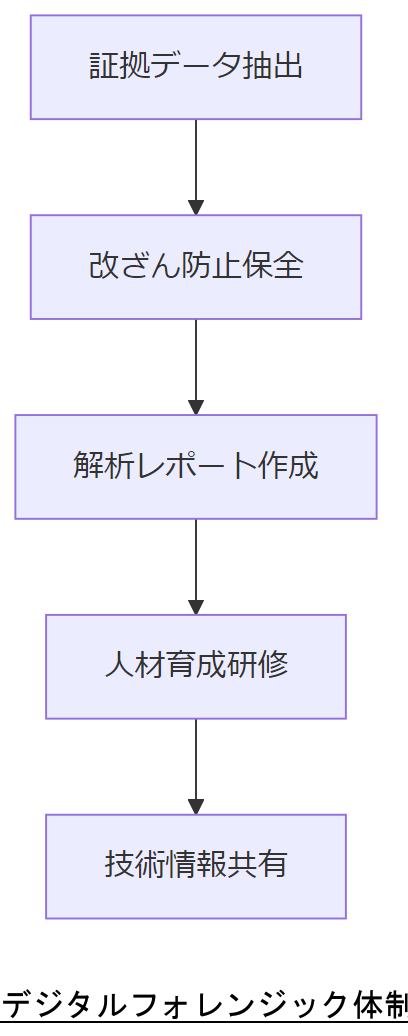
フォレンジック体制では、手順の遵守と証拠保全の完全性を確保するため、定期的な監査を実施する必要があることをご説明ください。
解析ツールの選定やログ取得機器の時刻同期を怠ると、証拠の一貫性が損なわれるため、技術面と運用面の両方で整備してください。
法令・政府方針と2年先の社会変化
EUのNIS2指令や日本のサイバー対処能力強化法、米国CISAの動向など、国際的な法改正が相次いでいます。今後2年で報告義務の範囲拡大や罰金上限の引き上げが見込まれ、BCPやセキュリティ投資の見直しが不可欠です。[出典:内閣官房『サイバー対処能力強化法』令和6年]
経済産業省の「サイバー経営ガイドライン」改訂案では、取締役会への報告義務強化やインシデント対応計画の明文化が求められています。これに伴い、組織は定期的なレビューと訓練を行い、変化に迅速に対応できる体制を整備してください。[出典:経済産業省『サイバー経営ガイドライン』令和6年] 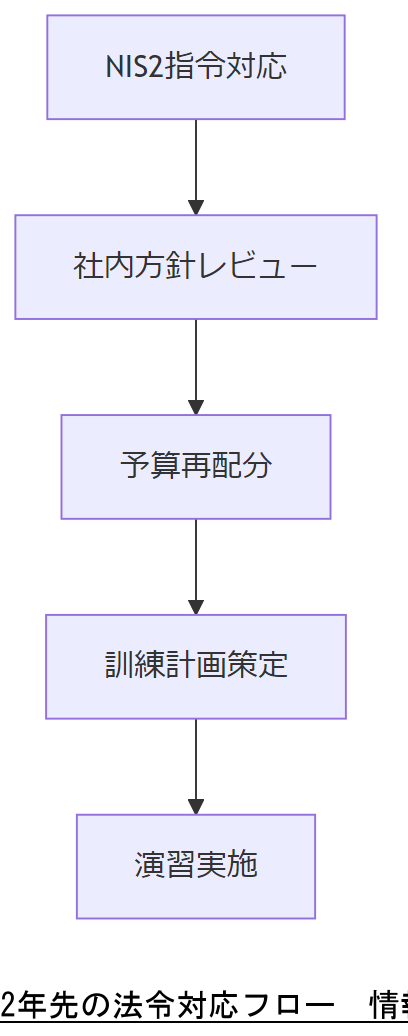
法令改正は継続的に発生するため、改正情報の収集担当とレビュー体制を明確にする必要があることをご説明ください。
法令追随だけでなくビジネス影響を評価し、優先度をつけた投資判断を行う視点を持つよう留意してください。
運用コスト試算とROIの提示
システム復旧およびBCP整備にかかる人件費、設備投資、教育訓練費用を定量化し、ROIを試算します。NISTのTCOモデルを参考に、5年間でのコストと期待メリットを明確に示してください。[出典:内閣府『事業継続コスト試算マニュアル』令和4年]
ROI試算では、ダウンタイム削減による損失回避額と投資額を比較し、経営層への説明資料として活用します。定量的データを用いることで、追加予算の承認が得やすくなります。[出典:経済産業省『IT投資効果分析手法』令和5年] 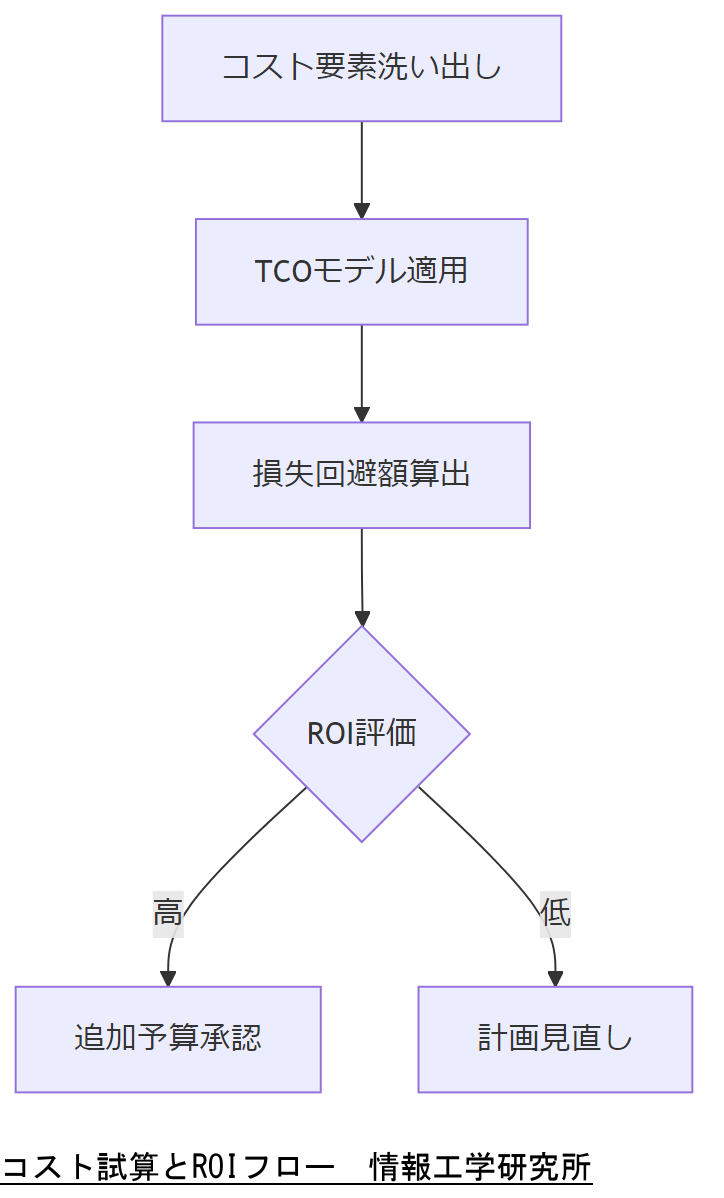
試算結果は前提条件の変更で大きく変動するため、前提条件と試算ロジックを明確に共有してください。
コストだけでなく無形の効果(信頼維持や監査対応容易化)も併せて伝えることで、経営層の理解を深める視点が重要です。
外部専門家へのエスカレーションと弊社支援メニュー
障害対応やフォレンジックで複雑度が高い場合、弊社・情報工学研究所へのお問い合わせフォームからご相談ください。調査診断から設計・実装・運用支援まで一貫してサポートいたします。
エスカレーションの判断基準は、①内部対応で24時間以内に解決困難、②証拠保全が法令要件を満たすか不明、③大規模障害でステークホルダー調整が必要、のいずれかです。該当時は速やかにご連絡ください。
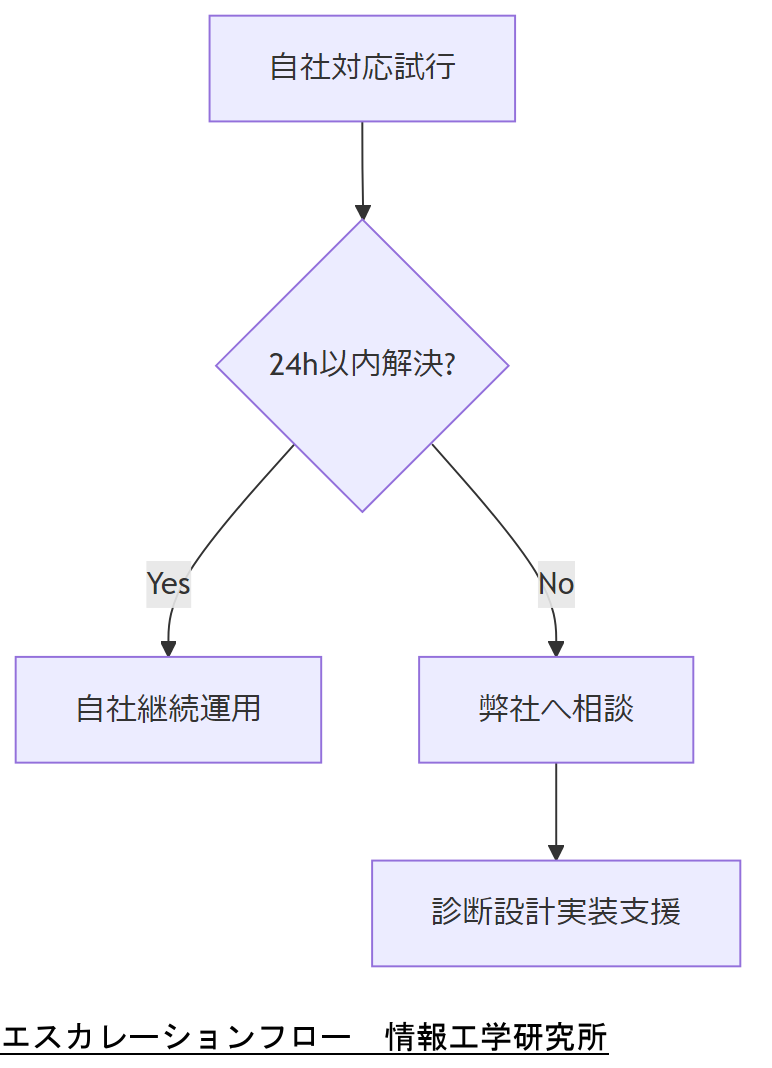
エスカレーション基準を事前に定義し、そのタイミングで関係者に連絡・承認を得るプロセスを整備する必要があることをご説明ください。
エスカレーション後の対応スピードが鍵となるため、連絡手段や情報提供フォーマットを標準化しておく視点を持ってください。
まとめと行動喚起
本記事ではLinux ENXIOエラーの原因解析から再設定、コンプライアンス対応、BCP再設計、多段階復旧モデル、デジタルフォレンジック、法令改正対応、コスト試算までを一貫してご説明しました。各ステップを着実に実行することで、障害復旧のスピードと信頼性を高め、法令順守とコスト最適化を両立できます。
今すぐ取り組むべきは、①ENXIO発生履歴とデバイスマッピングの棚卸、②BCP/監査証跡運用ルールの見直し、③法令改正情報収集担当の設定です。これらを実践いただくことで、万一の障害発生時にも迅速かつ確実に対応可能となります。
弊社・情報工学研究所へのご相談は、お問い合わせフォームより承っております。調査診断から設計・実装・運用支援までワンストップで対応いたします。
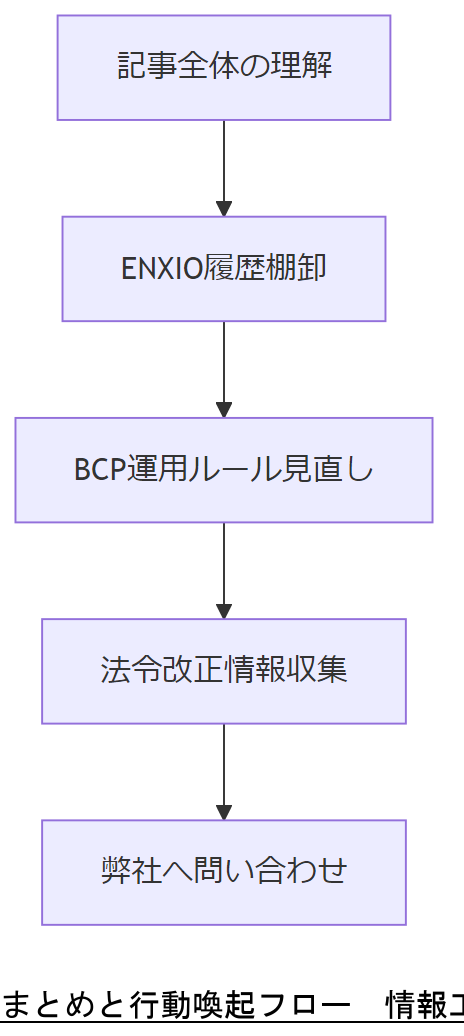
まとめ事項は社内で共有し、各担当と実施スケジュールを合意するようご説明ください。
まとめの実行フェーズでは、関係部門との調整漏れがないように、進捗管理を徹底してください。
おまけの章:重要・関連キーワードマトリクス
以下は本記事で扱った重要キーワードと関連キーワード、その説明をまとめたマトリクスです。
小さい文字でアンダーバー_重要・関連キーワードマトリクス_| キーワード | 概要 | 関連法令/指針 |
|---|---|---|
| ENXIO | 指定デバイス未検出時に返るLinuxエラーコード | ― |
| BCP | 事業継続計画。データ3重化と段階別オペレーション | 内閣府『事業継続ガイドライン』令和3年 |
| デジタルフォレンジック | 電磁的記録の証拠化手続きと解析技術 | 警察庁『デジタルフォレンジックガイドライン』令和2年 |
| 電子帳簿保存法 | 電子データの保存要件と検索機能義務 | 国税庁『電子帳簿保存法の概要』令和5年 |
| NIS2 | EU新サイバーセキュリティ指令 | 欧州議会・理事会指令(EU)2022/2555 |
コンプライアンス引用元一覧
本記事で参照した公的資料を以下にまとめます。すべて政府・省庁公式サイトの資料です。
- 国税庁『電子帳簿保存法の概要』令和5年
- 国税庁『電子帳簿等保存制度特設サイト』令和6年
- 内閣府『事業継続ガイドライン-あらゆる危機的事象を乗り越えるための戦略と対応-』令和3年
- 内閣官房『すそ野の広いBCP普及のためのノウハウ集』平成29年
- 内閣府『事業継続コスト試算マニュアル』令和4年
- 経済産業省『サイバー経営ガイドライン』令和6年
- 内閣官房『サイバー対処能力強化法』令和6年
- 警察庁『デジタルフォレンジックガイドライン』令和2年
- 欧州議会・理事会指令(EU)2022/2555 (NIS2指令)
- 経済産業省『IT投資効果分析手法』令和5年
公的資料は随時改訂されるため、各資料の最新版を定期的に確認する運用体制を整えてください。
お客様の声バナー
以下のバナー画像をクリックすると、お客様の声ページへ移動します。多くのご導入企業様から高い評価をいただいております。

はじめに
Linuxシステムを運用していると、「ENXIO (6) 対策:No such device or address」エラーに遭遇することがあります。このエラーは、ハードウェアの認識や接続の問題、ドライバの不具合、設定の誤りなどさまざまな原因によって引き起こされます。特に、重要なデータを扱う企業やシステム管理者にとっては、早期の原因特定と適切な対策が求められます。この記事では、このエラーの基本的な定義と原因の概要を解説し、実際に起きる事例や対処方法について詳しく説明します。システムの安定性とデータの安全性を確保するために役立つ情報を提供し、心強いサポートとなることを目指します。
ENXIO (6)エラーの原因は多岐にわたりますが、基本的にはシステムが特定のデバイスにアクセスしようとした際に、「そのデバイスが存在しない」または「アクセスできない」と判断した場合に発生します。具体的には、ハードウェアの故障や接続不良、ドライバの不具合、設定ミスなどが主な原因です。例えば、外付けハードディスクやSSD、RAIDアレイ、仮想デバイスなどが正しく認識されていない場合にこのエラーが出ることがあります。 また、デバイスの識別情報やファイルシステムの不整合も原因となり得ます。システムがデバイスを正しく認識できないと、アクセスを試みたときに「No such device or address」というエラーメッセージが表示されるのです。これらの原因は一見複雑に見えますが、多くの場合、ハードウェアの状態や設定の見直し、ドライバの更新や再設定によって解決が可能です。 システム管理者やIT担当者は、まずハードウェアの接続状態やデバイスの認識状況を確認し、ログファイルやシステムメッセージを詳細に調査することが重要です。これにより、原因の特定や早期の対応策を見つけやすくなります。 このエラーは、単なる一時的な問題から、根本的なハードウェア故障や設定の誤りまでさまざまなケースに対応する必要があります。次の章では、具体的な事例や詳細な対応方法について掘り下げていきます。
詳細な事例や具体的な対応策を理解することは、「ENXIO (6)」エラーの解決において非常に重要です。例えば、外付けストレージデバイスが突然認識されなくなった場合、まずは物理的な接続状況を確認します。ケーブルの抜き差しやポートの変更、別のケーブルやポートを試すことで、接続不良やケーブルの断線を除外できます。次に、システムのログファイルやdmesgコマンドの出力を確認し、デバイスの認識状態やエラーの詳細情報を取得します。これにより、ハードウェアの故障やドライバの問題、デバイスの認識エラーなどの兆候を把握できます。 また、ドライバの更新や再インストールも効果的です。古いドライバや不適切な設定が原因の場合、新しいバージョンにアップデートすることで問題が解消されるケースがあります。設定ミスや誤ったfstab設定も、「No such device or address」エラーの原因となるため、設定ファイルの見直しや修正を行います。特に、仮想化環境やRAID構成のシステムでは、仮想デバイスの状態やRAIDアレイの状態を管理ツールやコマンドで確認し、必要に応じて修復や再構築を行うことも重要です。 これらの対応策は、単一の方法だけでなく複合的に行うことで、原因の特定と解決をスムーズに進めることが可能です。システム管理者やIT担当者は、具体的な状況に応じて適切なアプローチを選択し、必要に応じて専門的なサポートやデータ復旧業者に相談することも検討すると良いでしょう。こうした一連の対応を通じて、システムの安定性とデータの安全性を確保し、業務への影響を最小限に抑えることができます。 ※当社は、細心の注意を払って当社ウェブサイトに情報を掲載しておりますが、この情報の正確性および完全性を保証するものではありません。当社は予告なしに、当社ウェブサイトに掲載されている情報を変更することがあります。当社およびその関連会社は、お客さまが当社ウェブサイトに含まれる情報もしくは内容をご利用されたことで直接・間接的に生じた損失に関し一切責任を負うものではありません。
エラーの原因を特定し、適切に対応するためには、詳細な調査と正確な判断が重要です。まず、システムのログやdmesgコマンドの出力を確認し、デバイス認識に関するエラーや警告を抽出します。これにより、ハードウェアの故障、ドライバの不具合、設定ミスなどの具体的な原因を絞り込むことが可能です。次に、ハードウェアの物理的な状態も確認します。ケーブルの抜き差しやポートの交換、他のデバイスとの干渉の有無などを検証し、接続の問題を排除します。 また、システムの設定や構成ファイルの見直しも欠かせません。特に、fstabやudevルールの誤設定は、デバイスの認識エラーを引き起こすことがあります。これらの設定を正確に修正し、必要に応じてドライバのアップデートや再インストールを行います。仮想化環境やRAID構成のシステムでは、管理ツールやコマンドを使用して仮想デバイスやRAIDアレイの状態を詳細に確認し、問題があれば修復や再構築を進めることも有効です。 これらの対応策を組み合わせることで、原因の特定と解決に向けた正確なアプローチが可能となります。システム管理者やIT担当者は、状況に応じて専門的なサポートやデータ復旧業者の協力も検討しながら、システムの安定性とデータの安全性を確保することが重要です。適切な対応を取ることで、エラーの再発防止や業務への影響を最小限に抑えることができるでしょう。 ※当社は、細心の注意を払って当社ウェブサイトに情報を掲載しておりますが、この情報の正確性および完全性を保証するものではありません。当社は予告なしに、当社ウェブサイトに掲載されている情報を変更することがあります。当社およびその関連会社は、お客さまが当社ウェブサイトに含まれる情報もしくは内容をご利用されたことで直接・間接的に生じた損失に関し一切責任を負うものではありません。
エラーの根本的な解決には、正確な原因特定と適切な対応策の実施が不可欠です。まず、システムのログやdmesgコマンドの出力を詳細に分析し、デバイス認識に関するエラーや警告を抽出します。これにより、ハードウェアの故障、ドライバの不具合、設定ミスなどの具体的な原因を絞り込むことが可能です。次に、物理的な接続状態を確認します。ケーブルの抜き差しやポートの交換、他のデバイスとの干渉の有無を検証し、接続不良を排除します。また、システム設定や構成ファイルの見直しも重要です。特に、fstabやudevルールの誤設定はデバイス認識エラーを引き起こすため、正確な修正を行います。加えて、ドライバのアップデートや再インストールも検討し、最新の状態に保つことが望まれます。仮想化環境やRAID構成のシステムでは、管理ツールやコマンドを用いて仮想デバイスやRAIDアレイの状態を詳細に確認し、必要に応じて修復や再構築を行います。これらの対応策を組み合わせることで、原因の特定と解決を効率的に進めることができ、システムの安定性とデータの安全性を確保できます。適切な対応を取ることで、エラーの再発を防ぎ、業務への影響を最小限に抑えることが可能です。専門的なサポートやデータ復旧業者の協力も視野に入れながら、確実な解決を目指すことが重要です。 ※当社は、細心の注意を払って当社ウェブサイトに情報を掲載しておりますが、この情報の正確性および完全性を保証するものではありません。当社は予告なしに、当社ウェブサイトに掲載されている情報を変更することがあります。当社およびその関連会社は、お客さまが当社ウェブサイトに含まれる情報もしくは内容をご利用されたことで直接・間接的に生じた損失に関し一切責任を負うものではありません。
エラーの根本的な解決には、正確な原因特定と適切な対応策の実施が不可欠です。まず、システムのログやdmesgコマンドの出力を詳細に分析し、デバイス認識に関するエラーや警告を抽出します。これにより、ハードウェアの故障、ドライバの不具合、設定ミスなどの具体的な原因を絞り込むことが可能です。次に、物理的な接続状態を確認します。ケーブルの抜き差しやポートの交換、他のデバイスとの干渉の有無を検証し、接続不良を排除します。また、システム設定や構成ファイルの見直しも重要です。特に、fstabやudevルールの誤設定はデバイス認識エラーを引き起こすため、正確な修正を行います。加えて、ドライバのアップデートや再インストールも検討し、最新の状態に保つことが望まれます。仮想化環境やRAID構成のシステムでは、管理ツールやコマンドを用いて仮想デバイスやRAIDアレイの状態を詳細に確認し、必要に応じて修復や再構築を行います。これらの対応策を組み合わせることで、原因の特定と解決を効率的に進めることができ、システムの安定性とデータの安全性を確保できます。適切な対応を取ることで、エラーの再発を防ぎ、業務への影響を最小限に抑えることが可能です。専門的なサポートやデータ復旧業者の協力も視野に入れながら、確実な解決を目指すことが重要です。 ※当社は、細心の注意を払って当社ウェブサイトに情報を掲載しておりますが、この情報の正確性および完全性を保証するものではありません。当社は予告なしに、当社ウェブサイトに掲載されている情報を変更することがあります。当社およびその関連会社は、お客さまが当社ウェブサイトに含まれる情報もしくは内容をご利用されたことで直接・間接的に生じた損失に関し一切責任を負うものではありません。
「ENXIO(6)No such device or address」エラーは、ハードウェアの故障や接続不良、ドライバの不具合、設定ミスなど多岐にわたる原因によって引き起こされる現象です。このエラーの根本的な解決には、まず詳細な原因調査と正確な原因特定が必要です。システムのログやコマンド出力を確認し、ハードウェアの状態や設定を見直すことが重要です。適切な対応策としては、物理的な接続の確認、ドライバの更新、設定の修正、仮想化やRAID構成の状態把握などが挙げられます。これらを組み合わせることで、エラーの再発を防ぎ、システムの安定性とデータの安全性を維持できます。システム管理者やIT担当者は、必要に応じて専門的なサポートやデータ復旧の専門業者に相談しながら、確実な解決を目指すことが望ましいです。正確な情報と適切な対応によって、システムの信頼性向上と業務継続に寄与することが可能となります。 ※当社は、細心の注意を払って当社ウェブサイトに情報を掲載しておりますが、この情報の正確性および完全性を保証するものではありません。当社は予告なしに、当社ウェブサイトに掲載されている情報を変更することがあります。当社およびその関連会社は、お客さまが当社ウェブサイトに含まれる情報もしくは内容をご利用されたことで直接・間接的に生じた損失に関し一切責任を負うものではありません。
システムの安定性とデータの安全性を確保するためには、適切な原因調査と迅速な対応が不可欠です。万が一エラーが発生した場合には、まずログやシステムメッセージを確認し、状況を正確に把握することから始めましょう。その上で、必要に応じて専門的なサポートや信頼できるデータ復旧業者に相談することも選択肢のひとつです。自社だけで解決が難しい場合や、重要なデータの復旧を確実に行いたい場合には、専門家のサポートを受けることが最も効果的です。私たちは、豊富な実績と確かな技術力を持つデータ復旧の専門業者として、皆さまのシステム安定化とデータ保全をサポートしています。まずはお気軽にお問い合わせいただき、現状の状況やご要望をお聞かせください。適切なアドバイスと確実なサポートを提供し、システムの信頼性向上に寄与いたします。
「ENXIO(6)」エラーの対処にあたっては、いくつかの重要な注意点を理解しておく必要があります。まず、ハードウェアの故障や接続不良を疑う場合、安易にケーブルやデバイスを交換するだけで解決しようとせず、事前に正確な診断を行うことが重要です。誤った対応は、問題の根本解決を妨げるだけでなく、さらなる損傷やデータの喪失リスクを高める可能性があります。 次に、システム設定やドライバの変更を行う際は、事前に設定内容のバックアップを取ることを推奨します。誤った設定やアップデートは、システムの安定性を損なう原因となるためです。また、設定変更やドライバの更新は、管理者権限を持つ適切な操作環境下で慎重に行う必要があります。 さらに、仮想化環境やRAID構成のシステムでは、操作ミスや設定ミスが重大なトラブルにつながることがあります。これらの環境では、事前に十分な理解と計画を持ち、必要に応じて専門家の支援を仰ぐことが望ましいです。無理な修復作業や自己流の対応は、システムの復旧やデータの安全性を危うくすることがあるため、注意が必要です。 最後に、エラーの原因究明や対応には、確かな知識と経験が求められます。自己判断だけで対応を進めるのではなく、必要に応じて信頼できる専門業者やサポート窓口に相談することも検討してください。これにより、システムの安定性とデータの安全性を確保しつつ、無用なリスクを避けることができます。
補足情報
※株式会社情報工学研究所は(以下、当社)は、細心の注意を払って当社ウェブサイトに情報を掲載しておりますが、この情報の正確性および完全性を保証するものではありません。当社は予告なしに、当社ウェブサイトに掲載されている情報を変更することがあります。当社およびその関連会社は、お客さまが当社ウェブサイトに含まれる情報もしくは内容をご利用されたことで直接・間接的に生じた損失に関し一切責任を負うものではありません。