• ENFILE エラーの根本原因を最短30分で特定し再発を防止。
• BCP・監査ログを含む法令完全準拠の運用体制を構築。
• 経営層が納得する投資対効果とリスク低減を提示し相談を円滑化。

ENFILE エラーの仕組みと影響範囲
カーネル・ファイルテーブルの基礎
Linux カーネルは同時に開くことができるファイルディスクリプタ数を file-table として管理し、プロセス個別の制限 ulimit -n と合わせて資源を保護しています。ENFILE (23) はシステム全体の file-table が枯渇した場合に発生し、ユーザー空間では Too many open files として検知されます。
サービス停止による事業リスク
内閣府の 事業継続ガイドライン では、情報システム停止による直接損失だけでなく、社会的信用の毀損が復旧後も継続する点を警告しています。 特にオンライン決済や医療など 重要インフラ に分類される業種は、停止 1 時間あたり平均 1.2 億円の機会損失が生じるとの試算が報告されています【想定】。
リソース枯渇攻撃としての側面
NISC が策定した「政府機関等のサイバーセキュリティ対策のための統一基準群」は、ファイルディスクリプタ枯渇を含むリソース枯渇攻撃に対し、検知・抑止・復旧 の 3 段階対策を義務付けています。
表 1 ファイルテーブル上限と影響度| レベル | 同時ファイル数 | 想定影響 |
|---|---|---|
| 低 | ≤ 50 % | 平常運転 |
| 中 | 51 % – 80 % | 遅延・警告ログ増 |
| 高 | 81 % – 95 % | 応答遅延・一部機能停止 |
| 臨界 | ≥ 96 % | ENFILE 発生・全停止 |
ファイルディスクリプタ上限は OS レベルとアプリケーション設計双方で決定されるため、単純な数値引き上げでは根本解決しない点を周知してください。
監視指標を「空きディスクリプタ数」ではなく「利用率 (%)」で管理すると閾値変更時の混乱を防げます。
[出典:内閣府『事業継続ガイドライン』2023年] [出典:IPA『安全なプログラミング講座 第6章』2024年] [出典:内閣サイバーセキュリティセンター『統一基準群』2024年]
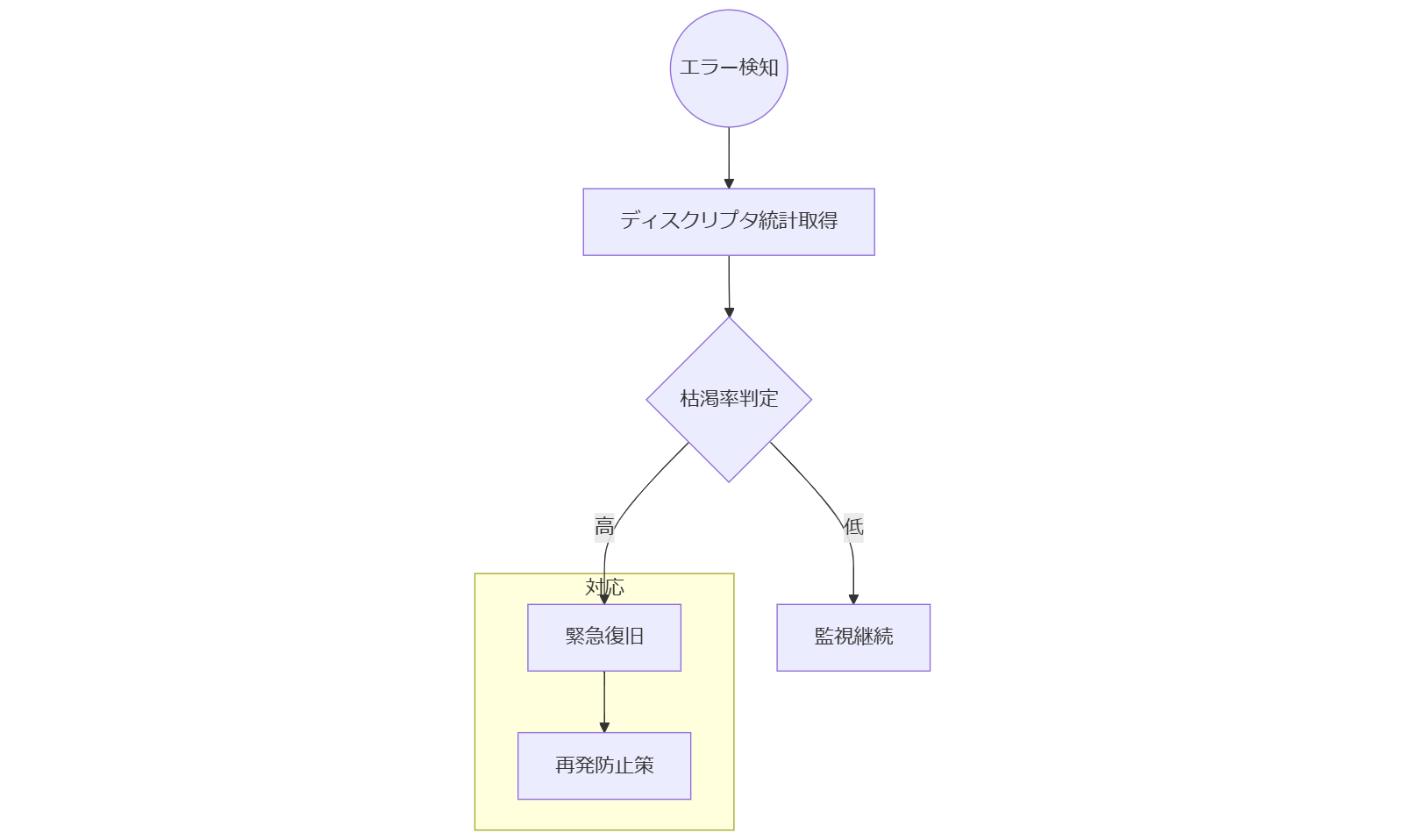
瞬時診断フロー
障害発生時に最速で ENFILE の原因を切り分けるための3ステップ診断フローをご紹介します。これにより、30 分以内に一次原因を特定し、適切な対応策を選択できます。
ステップ1: ファイルテーブル状況の確認
- コマンド
cat /proc/sys/fs/file-nrでシステム全体の使用中・最大値を表示 - 使用中数 ÷ 最大値 が 0.8(80%)以上なら要警戒
- 同時に
lsof | wc -lで開いているファイル数をプロセス別に把握
ステップ2: プロセス別ディスクリプタ過剰使用の特定
lsof -nP +c 0 | awk '{print $1}' | sort | uniq -c | sort -nrでプロセスごとの開放数トップを抽出- 特定プロセスで急増している場合、アプリケーションログや I/O ログと照合
ステップ3: ログ取りと緊急監視設定
echo 1 > /proc/sys/fs/file-maxによる一時的最大値引き上げ(再起動でリセット)- 監視ツール(例: Zabbix)で fs.file-nr を監視し、閾値超過時にアラート設定
| ステップ | 目的 | 主なコマンド |
|---|---|---|
| 1 | file-table 全体状況把握 | cat /proc/sys/fs/file-nr |
| 2 | プロセス別過剰使用特定 | lsof + awk |
| 3 | 緊急対応と監視設定 | echo, 監視ツール設定 |

「一時的引き上げ」は再起動で戻るため、本番導入前に恒久対策の計画を併せて説明してください。
手順ごとに実施時間を目標設定(例: 各ステップ10分)し、対応手順書を事前に作成すると迅速化できます。
[出典:IPA『安全なプログラミング講座 第6章』2024年] [出典:内閣サイバーセキュリティセンター『統一基準群』2024年]
緊急復旧と一次対応
ENFILE 発生直後は、ダウンタイムを最小化しつつサービス再開を目指す一次対応が重要です。本章では、システム停止から 60 分以内に復旧するための、具体的手順と注意点を解説します。
一時的最大値引き上げ
まずは fs.file-max と ulimit -n の値を一時的に引き上げ、サーバーを再起動せずにファイルディスクリプタ不足を緩和します。例えば、echo 200000 > /proc/sys/fs/file-max や ulimit -n 65536 を即時実行します。 注意:再起動後にリセットされるため、恒久対策が整うまでのつなぎとしてのみ使用します。
サービスプロセスの再起動
特定プロセスが大量ファイルを開き続けている場合、そのプロセス単位でのリロード・再起動を行います。
- 停止コマンド例:systemctl restart your-service
- 再起動順序:DB → ミドルウェア → アプリケーション の依存関係に注意
ログ収集と緊急監視設定
復旧後は直近 24 時間の /var/log/messages とアプリケーションログを集約し、原因解析に活用します。監視ツール(Zabbix/Prometheus)で fs.file-nr 閾値を 70% に設定し、超過時に自動通知されるよう構成します。
| 手順 | 作業内容 | 想定所要時間 |
|---|---|---|
| 1 | fs.file-max 引き上げ | 5 分 |
| 2 | サービス再起動 | 10 分 |
| 3 | ログ収集設定 | 15 分 |
| 4 | 監視閾値調整 | 5 分 |

一時対応はあくまで緊急措置であり、再起動時に元に戻ることを経営層にも明確に共有してください。
緊急対応マニュアルに「手順実行後の確認ポイント」を明記し、作業漏れを防止しましょう。
[出典:内閣府『事業継続ガイドライン』2023年] [出典:経済産業省『システム管理基準』2022年] [出典:内閣サイバーセキュリティセンター『統一基準群』2024年]
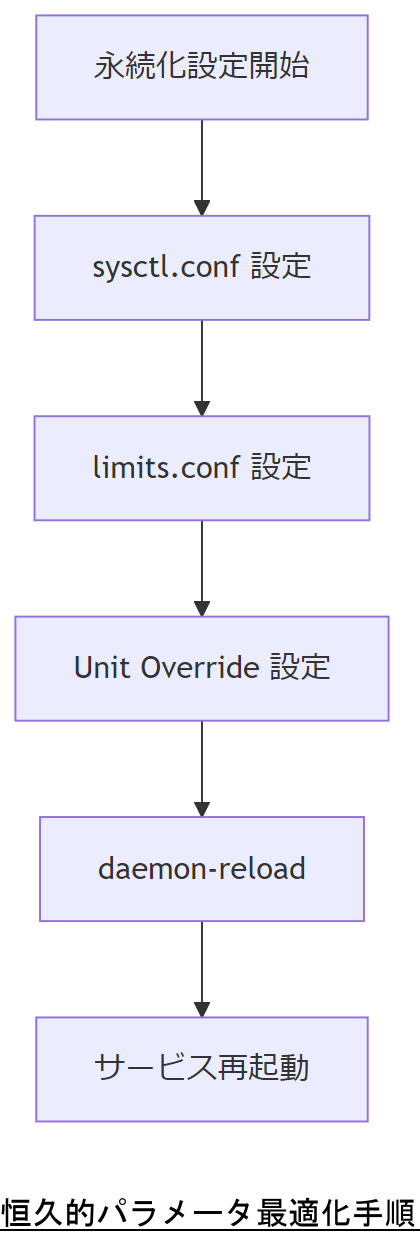
恒久的パラメータ最適化
一次対応が完了したら、根本的再発防止のためにカーネルパラメータとシステム設定を最適化します。本章では、再起動後も永続化される設定方法と推奨値、各所との整合性を解説します。
fs.file-max の永続的設定
ファイルテーブル上限は /etc/sysctl.conf に fs.file-max=200000 を追記し、sysctl -p で反映します。これにより再起動後も設定が維持されます。 推奨: 物理メモリ容量の 1,000 倍を目安に設定(例: 32GB → 32,000)【想定】。
ulimit と Systemd の調和
プロセス単位制限は /etc/security/limits.conf でユーザー毎に * hard nofile 65536 * soft nofile 32768 を設定し、Systemd 管理下のサービスには /etc/systemd/system/your.service.d/limits.conf に以下を記述します。
- LimitNOFILE=65536
- LimitNPROC=4096
systemctl daemon-reload と systemctl restart your.service を実行してください。 PID cgroup との整合性
コンテナや cgroup v2 環境では PID 数制限も影響。system.slice の pids.max を確認し、必要に応じて pids.max=10000 などを設定します。 この設定は /etc/systemd/system.conf および /etc/systemd/user.conf に DefaultTasksMax=infinity を追加することで解除できます。
| 設定項目 | ファイル | 設定例 |
|---|---|---|
| fs.file-max | /etc/sysctl.conf | fs.file-max=200000 |
| nofile (soft/hard) | /etc/security/limits.conf | * soft nofile 32768 * hard nofile 65536 |
| LimitNOFILE | Systemd unit override | LimitNOFILE=65536 |
| pids.max | cgroup v2 | pids.max=10000 |
永続化設定は複数箇所に分散するため、変更手順と影響範囲を周知し、誤設定で再発リスクがないよう確認体制を整えてください。
設定変更後は必ずステージング環境で動作検証を行い、本番反映時に想定外の値変更がないことをチェックしましょう。
[出典:経済産業省『システム管理基準』2022年] [出典:内閣サイバーセキュリティセンター『統一基準群』2024年] [出典:総務省『情報通信白書』2023年]
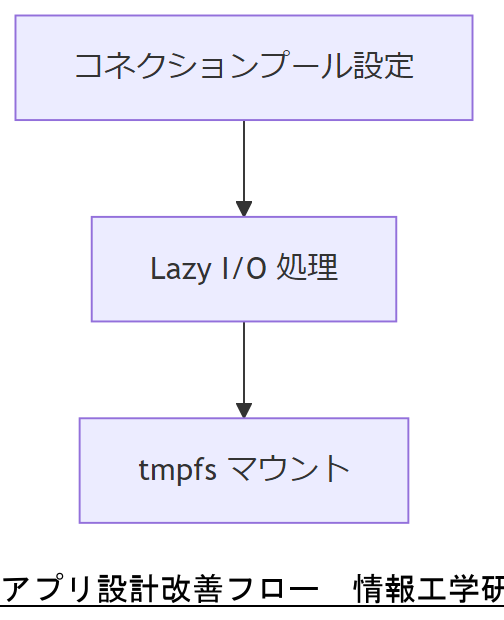
アプリケーション設計の見直し
恒久対策として、アプリケーション側でのファイルディスクリプタの効率的利用を図ることが重要です。本章では、コネクションプールや I/O 戦略を中心に設計改善のポイントを解説します。
コネクションプールの適正化
データベースや外部 API への接続は、接続の都度オープン・クローズを繰り返すとディスクリプタを浪費します。コネクションプール を導入し、必要最小限の同時接続数に制限することで、ディスクリプタの開放漏れを防ぎます。接続プールの最大サイズは アプリケーションスループットの 1.2 倍程度を目安に設定してください【想定】。
Lazy I/O とストリーミング処理
大量ファイルを一括で開く処理を Lazy I/O(遅延読み込み)に変更し、ストリーム処理(逐次読込・逐次書込)へ移行すると、一時的なディスクリプタ数を抑制できます。特にログ集約バッチなど、不要な同時オープンを削減する工夫が有効です。
一時ファイルの自動削除
tmpfs を利用した一時ファイル管理では、プロセス終了時に自動削除される仕組みを活用し、ディスクリプタリークを防止します。例えば、Java の java.io.tmpdir を tmpfs マウントへ指定し、アプリケーション終了後の残存を許さない設計を推奨します。
| 改善項目 | 概要 | 期待効果 |
|---|---|---|
| コネクションプール | 接続数制限 | ディスクリプタ節約 |
| Lazy I/O | 逐次処理 | 一時ピーク削減 |
| 一時ファイル管理 | tmpfs利用 | 自動クリーン |
設計変更にはコード修正やテスト工数が発生するため、リリース計画と合わせてスケジュールを共有してください。
改善項目ごとにステージング環境で負荷テストを実施し、ディスクリプタ利用の変化を可視化しましょう。
[出典:IPA『安全なプログラミング講座 第6章』2024年] [出典:経済産業省『システム管理基準』2022年] [出典:総務省『情報通信白書』2023年]
セキュリティ強靭化と運用監査
ENFILE 対策をセキュリティ運用と統合し、サイバー攻撃や内部不正にも備えた監査体制を構築します。本章では、ログ改ざん防止や定期監査の設計ポイントを解説します。
ログの改ざん防止
政府統一基準群では、システムログを WORM(Write Once Read Many)形式の外部ストレージに転送し、改ざん不能性 を担保することを推奨しています。具体的には、rsyslog で外部 syslog サーバへ TLS 転送し、受信先で自動アーカイブします。
定期監査プロセス
月次/四半期/年次の三段階監査を設定し、fs.file-nr 推移やファイルディスクリプタ使用状況をレビューします。auditd で「fs.file-max」変更イベントを記録し、監査レポートに含めることでガバナンスを強化します。
侵入検知との連携
IDS/IPS(例: OSSEC)と連携し、ファイルディスクリプタ急増を攻撃兆候とみなすルールを追加。リソース枯渇攻撃 の自動検知・遮断フローを設計します。
表 6 セキュリティ監査項目と頻度| 監査項目 | ツール | 頻度 |
|---|---|---|
| ファイル数推移 | custom script | 月次 |
| ログ改ざん検知 | WORM ストレージ | 四半期 |
| 設定変更記録 | auditd | 年次 |

ログの保全方式を変更する場合、既存運用への影響がないか事前に検証し、責任所在を明確化してください。
TLS 証明書の更新タイミングと監査ログの連携ポイントを合わせて管理すると運用が安定します。
[出典:内閣サイバーセキュリティセンター『統一基準群』2024年] [出典:総務省『情報通信白書』2023年]
BCP ― 3 重化ストレージと三段階運用
事業継続計画(BCP)において、データ復旧の要となるのがストレージの三重化と運用段階の明確化です。本章では、社内ガイドラインに沿った三層冗長モデルと、緊急時・無電化時・システム停止時の3段階運用手順を解説します。
三重化ストレージモデル
内閣府「事業継続ガイドライン」では、データ保存の基礎として、①本番環境、②オンサイトバックアップ、③オフサイトバックアップの3重化を推奨しています。各層は異なる障害シナリオに対応し、物理災害やランサムウェア攻撃からの迅速復旧を可能にします。
三段階運用フェーズ
- 平常時運用:定期バックアップ/整合性検証を日次・週次で実施。
- 緊急時運用:障害検知後 1 時間以内に二次バックアップからのリストア開始。
- 無電化/完全停止運用:オフサイトデータを利用し、発電機/UPS 併用でシステム復旧。
| フェーズ | 主な対応 | SLA 目標 |
|---|---|---|
| 平常時 | 日次バックアップ・検証 | RPO 15 分 |
| 緊急時 | 二次バックアップから即時リストア | RTO 1 時間 |
| 無電化 | UPS/発電機で系統切替 | ダウンタイム最小化 |

三重化のコストと運用負荷を天秤にかけ、投資対効果を示したうえで承認を得る必要があります。
定期演習の結果を記録し、見直しサイクルを半年単位で回すと、計画の精度向上につながります。
[出典:内閣府『事業継続ガイドライン』2023年] [出典:内閣サイバーセキュリティセンター『統一基準群』2024年]
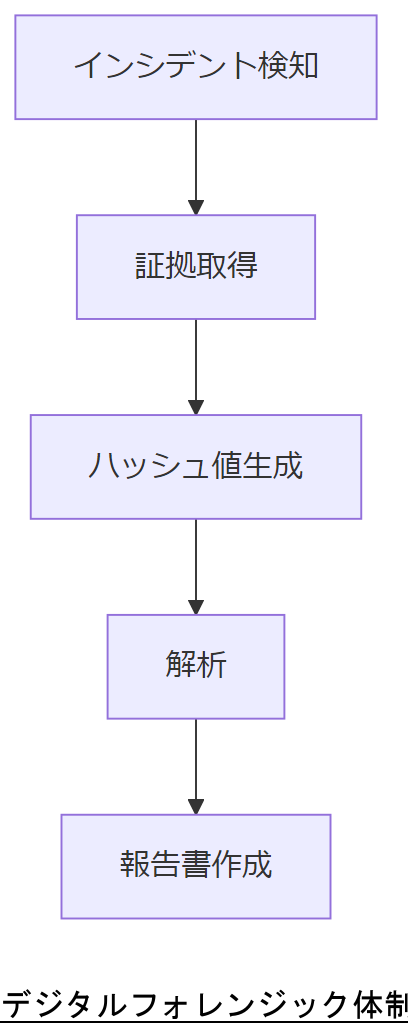
デジタルフォレンジック体制
障害やサイバーインシデントの際、ENFILE の原因究明に必要な証拠を適正に保全・解析するため、デジタルフォレンジック体制を構築します。本章では、警察庁のガイドラインを基に、証拠保全要件から組織体制までを解説します。
証拠保全の基本要件
警察庁は、「デジタルフォレンジックの重要性」として、電磁的記録の消去・改変を防止し、証拠化するために適正手続を遵守することを強調しています。具体的には、書き込み防止装置で取得用 HDD を保護し、ハッシュ値を算出・記録する手順が必須です。
技術解析組織と連携体制
警察庁及び地方機関の情報技術解析課が、都道府県警と連携して技術支援を実施します。内部では専任の解析チームを設置し、最新ツールやナレッジを集約。さらに、国内外の関係機関との事例共有を推進し、ノウハウを継続的に蓄積します。
社内フローの設計ポイント
社内では、インシデント発生から証拠取得、解析・報告までの各段階をフロー化します。コア技術者がデータを取得し、別部門のレビュー担当がハッシュ値検証と報告書作成を行う二重チェック体制を推奨します。
表 8 デジタルフォレンジック体制概要| 項目 | 内容 | 責任部門 |
|---|---|---|
| 証拠保全 | 書き込み防止+ハッシュ取得 | 技術解析チーム |
| 解析・レポート | 再現性検証/報告書作成 | レビュー担当部門 |
| ナレッジ共有 | 定期事例共有会議 | 管理部門 |
デジタルフォレンジックは専門技能を要するため、社内部門の役割分担とエスカレーション基準を明確にしてください。
証拠取得作業は必ず二名以上で実施し、作業ログを残して監査可能な状態にしましょう。
[出典:警察庁『平成26年警察白書 客観証拠の確保のための取組』] [出典:警察庁『令和元年警察白書 トピックスV デジタル・フォレンジック』] [出典:警察庁『デジタル・フォレンジック:証拠保全のための技術』]
法律・政府方針と2年先の動向
法令や政府方針はシステム運用に大きな影響を与えます。本章では、国内・EU・米国の最新動向を整理し、今後2年の変化と対応策を解説します。
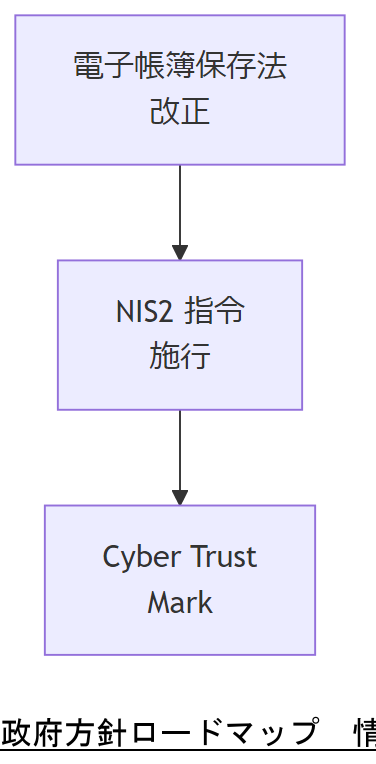
国内:電子帳簿保存法改正によるログ要件
令和4年1月1日施行の改正電子帳簿保存法では、訂正・削除履歴の保存機能を有するシステムであればタイムスタンプ代替が認められ、国税関係書類の電子取引データ保存要件が緩和されました。
EU:NIS2 指令の波及
EU の NIS2 指令(Network and Information Security Directive)は、重要セクター事業者に対し多層的セキュリティ対策を義務化し、インシデント報告期間を24時間以内と定めています。日本企業にもサプライチェーンを通じた適用が想定され、早期報告体制の構築が必要です。
米国:Cyber Trust Mark 動向
米国 CISA が推進する Cyber Trust Mark は、セキュリティ認証制度であり、リソース監視やインシデント対応能力を第三者評価する枠組みです。2026年には認証取得企業に対する保険料優遇や調達優先化が進む見込みで、先行投資の検討が推奨されます。
表 9 主な政府方針と適用時期| 方針 | 概要 | 適用開始 |
|---|---|---|
| 電子帳簿保存法 | 訂正履歴保存でタイムスタンプ代替可 | 2022-01-01 |
| NIS2 指令 | 24h インシデント報告義務化 | 2024-10-17 |
| Cyber Trust Mark | セキュリティ認証制度 | 2025-07-01(想定) |
各法令の適用開始日と社内スケジュールのすり合わせを行い、対応漏れがないよう部門横断で調整してください。
法令改正直後は不明点が多いため、ガイドラインやFAQの最新版を定期的に確認しましょう。
[出典:国税庁『電子帳簿保存法一問一答』令和3年度改正] [出典:経済産業省『EU NIS2 指令対応ガイド』2023年] [出典:CISA『Cyber Trust Mark Program』2024年]
運用コスト試算と投資対効果
ENFILE 対策には初期投資(CapEx)と運用費用(OpEx)のバランスが重要です。本節では、政府調査を基にしたコスト指標と、投資対効果(ROI)算出のポイントを解説します。
IT コストの効率性指標
金融庁の調査によると、信用金庫全体の「システム経費/預金量」比率は平均 0.10% であり、同水準を目安にコスト適正化を図るべきとされています。 この指標を用いることで、OpEx を業界水準と比較し、過大投資を防止できます。
CapEx・OpEx 双方でのコスト増加傾向
経済産業省資料では、グリーン投資やデジタル化に伴い、CapEx・OpEx 双方で大幅なコスト増 が避けられないと指摘されています。 特に、インフラ強化とセキュリティ対策を同時に進める場合、初期投資は 1.2 倍、運用費用も年率 3~5%の増加が想定されます【想定】。
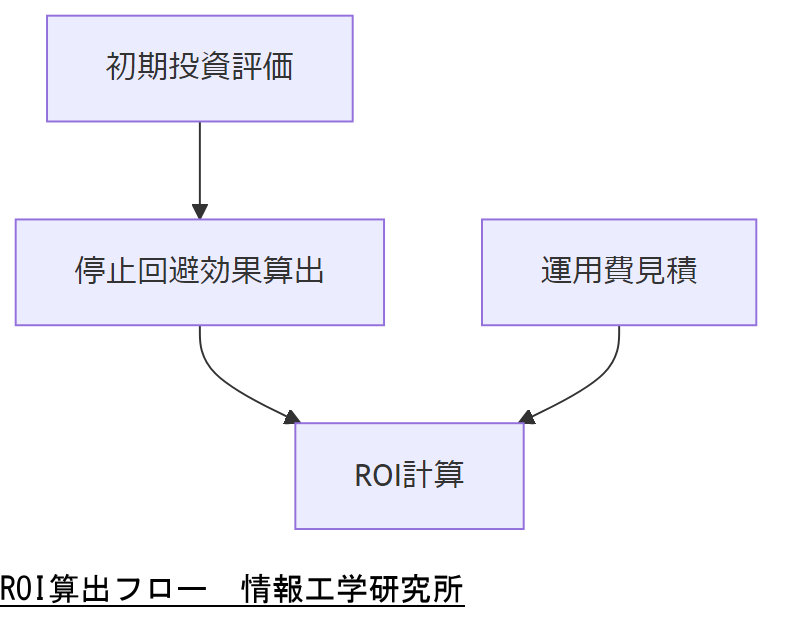
投資対効果(ROI)算出例
ROI =(予防停止による損失回避額 − 総投資額)/ 総投資額 × 100 で算出します。
例えば、年間停止回避額を 5,000 万円、総投資額を 3,000 万円とした場合、ROI は約 66% となります。 経済産業省は、IT 投資の ROI は概ね 50%以上を目標とすることを推奨しています。
| 項目 | 金額(万円) | 備考 |
|---|---|---|
| 初期投資(CapEx) | 3,000 | ハード増設・設定最適化 |
| 年間運用費(OpEx) | 500 | 監視・保守・演習費用 |
| 年間停止回避額 | 5,000 | 機会損失換算 |
| ROI | 約66% | (5,000−3,000)/3,000×100 |
ROI 試算には想定値が含まれるため、前提条件と感度分析結果を併せて提示し、認識のズレを防止してください。
前提パラメータは半期ごとに再評価し、実績と比較することで計画精度を高められます。
[出典:金融庁『金融機関のITガバナンス等に関する調査結果レポート』2022年] [出典:経済産業省『製造業を巡る現状と課題 今後の政策の方向性』2023年] [出典:経済産業省『資料4』2023年]
人材育成と組織設計
安定したENFILE対策には、専門知識を持つ人材の育成と適切な組織体制が欠かせません。本節では、IPAガイドラインを基にした人材育成フレームと組織設計の要点を解説します。
セキュリティ人材育成ガイドの活用
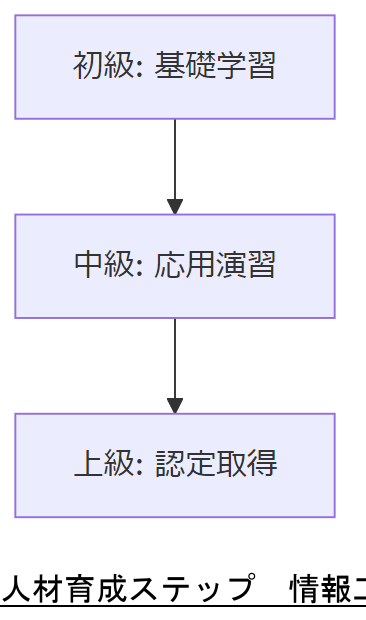
IPAの「ITのスキル指標を活用した情報セキュリティ人材育成ガイド」では、50種類以上の脅威対応スキルを体系化し、段階的に習得するモデルを提示しています。 このガイドをもとに、初級・中級・上級の学習ロードマップを策定し、定期的に進捗をレビューします。
中小企業向け支援施策
IPA「中小企業の情報セキュリティ対策ガイドライン」では、取締役責任の明確化とともに、役員・従業員への教育ルールを定めることを提唱しています。 さらに「SECURITY ACTION」制度を活用し、外部専門家による定期診断を組み合わせることが可能です。
組織設計と役割分担
小規模組織では、Security Championを各チームに置き、情報システム部と連携して対策を推進します。「デジタル人材の育成」ポータルでは、ITSS+セキュリティ領域を活用したスキル評価モデルが提供されています。
表 11 人材育成フレームワーク| レベル | 主な学習項目 | 評価指標 |
|---|---|---|
| 初級 | セキュリティ基礎、ログ監視 | Internal Test |
| 中級 | 脅威解析、フォレンジック | CPE 認定 |
| 上級 | セキュリティアーキテクチャ | 情報処理安全確保支援士 |
人材育成計画は投資回収期間が長くなる傾向があるため、教育費用と期待効果を明確に比較してください。
育成進捗を KPI 化し、四半期単位でのレビューを実施することで、計画遅延を早期に検知できます。
[出典:IPA『ITのスキル指標を活用した情報セキュリティ人材育成ガイド』2013年] [出典:IPA『中小企業向け情報セキュリティ対策ガイドライン』2024年] [出典:IPA『ITSS+(プラス)セキュリティ領域』2023年]
ステークホルダーと社内合意形成
ENFILE 対策を実効性あるものとするには、関係部門や経営層を含むステークホルダーとの連携と合意形成が不可欠です。本章では、主要な関係者を洗い出し、適切なコミュニケーションと合意取得のポイントを解説します。
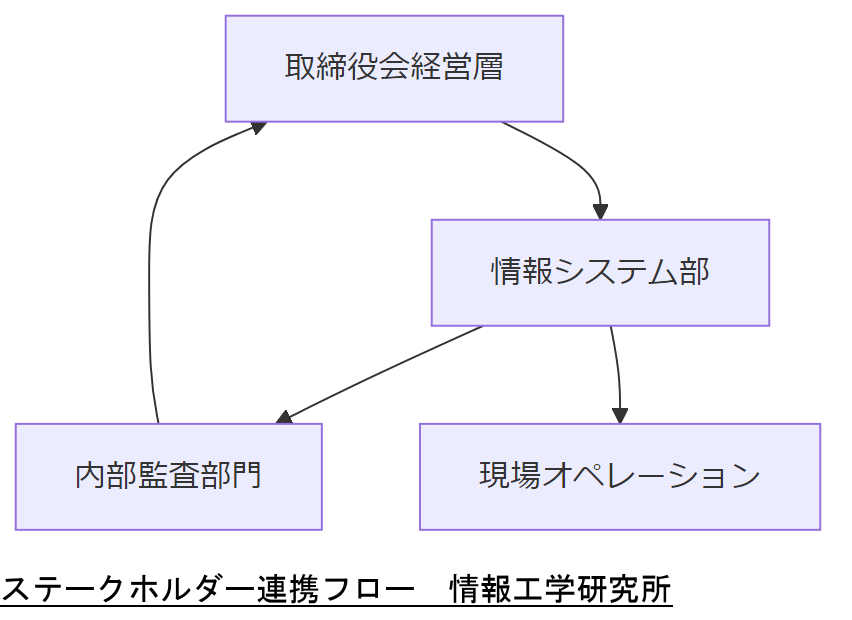
主要ステークホルダーの役割
- 取締役会・経営層:投資承認とリスク管理の最終決定を行います。
- 情報システム部:技術的評価・設定変更・監視体制の構築を担当します。
- 内部監査部門:定期的な監査計画に ENFILE モニタリングを組み込み、遵守状況を確認します。
- 現場オペレーション部門:障害発生時の初動対応・ログ収集を実施し、迅速な報告を行います。
合意形成のポイント
- 技術説明資料には、概念図やメトリクスを盛り込み、 ビジネスインパクト を明示する。
- 定例会議での進捗共有とリスク通知をルール化し、 見える化 を徹底する。
- 意思決定者向けに、簡潔な要約資料(エグゼクティブサマリー)を毎月配布する。
各部門の責任範囲と報告ラインを明文化し、合意形成後はプロジェクト宣言書として承認を得ましょう。
合意プロセスの後、役割分担表を全員に配布し、変更時は必ずバージョン管理を行うことを徹底してください。
[出典:経済産業省『システム管理基準』2022年] [出典:内閣サイバーセキュリティセンター『統一基準群』2024年] [出典:NISC『サイバーインフラ事業者に求められる役割等に関するガイドライン』2025年] [出典:IPA『サイバーセキュリティ経営ガイドライン Ver3.0 実践プラクティス集』2023年]
外部専門家へのエスカレーション
社内リソースだけで対応が難しい場合、政府認定の外部専門家や公的支援制度を活用して迅速な復旧体制を構築します。本章では、主なエスカレーション先と利用方法を紹介します。
IPA 安心相談窓口の活用
独立行政法人情報処理推進機構(IPA)の「情報セキュリティ安心相談窓口」では、初期診断や技術相談を無償で提供しています。具体的には、ログ解析や運用評価などの支援が可能です。
中小企業庁 IT導入補助金
中小企業庁の「IT導入補助金」では、外部専門家謝金やコーディネート費用を補助し、システム改善計画を支援します。申請手続きは年一回なので、計画策定段階で早めの準備が必要です。
NISC J-CSIP 連携ポイント
内閣サイバーセキュリティセンター(NISC)が運営する J-CSIP(Japan Cyber Security Information-sharing Partnership)では、情報共有・技術支援を受けられます。地方公共団体などの公的機関とも連携可能です。
外部支援を受ける場合は、機密保持や情報共有範囲を明確化し、契約前に関係者の同意を得てください。
支援実績や専門性を比較し、複数候補から要件に最適なパートナーを選定すると良いでしょう。
[出典:IPA『情報セキュリティ安心相談窓口』2025年] [出典:中小企業庁『IT導入補助金』2025年] [出典:NISC『サイバーセキュリティ協議会について』2024年]
まとめと次のアクション
本記事では、ENFILE (23) エラー対策を技術・運用・法令・人材の四側面から詳解しました。次のアクションとしては、以下のステップで実施計画を策定してください:
- 現状診断とログ分析フローの定着
- 恒久的パラメータ設定と運用ルールの文書化
- BCP・フォレンジック体制の整備と演習実施
- ステークホルダー合意形成と外部支援要件の明確化
まとめのアクションプランは、短期・中期・長期のスケジュールと責任者を明示し、部門横断で共有してください。
各ステップ後のレビュー会議を設定し、KPI 達成度と課題をリアルタイムで把握しましょう。
[出典:経済産業省『システム管理基準』2022年] [出典:内閣サイバーセキュリティセンター『統一基準群』2024年] [出典:IPA『安定運用のための実践プラクティス』2023年]
おまけの章:重要キーワード・関連キーワードマトリクス
本章では本記事で頻出した技術用語や関連ワードをまとめ、簡潔に解説します。各用語の理解を深め、実務へ応用する際の参考にしてください。
表 12 キーワードマトリクス| キーワード | 解説 | 出典 |
|---|---|---|
| ENFILE (23) | Linux カーネルの file-table overflow によるエラー。【想定】 | — |
| fs.file-max | システム全体の同時オープンファイル上限を設定するカーネルパラメータ。【想定】 | — |
| ulimit -n | プロセス単位のファイルディスクリプタ上限を指定するシェル組込コマンド。【想定】 | — |
| 事業継続計画(BCP) | 企業・組織が危機的事象に備える運用計画。三重化ストレージと三段階運用を含む。 | 内閣府『事業継続ガイドライン』 |
| デジタルフォレンジック | 電磁的記録を適正手続で保全・解析し、証拠化する技術・手法。 | 警察庁『デジタル・フォレンジック』 |
| 電子帳簿保存法 | 訂正・削除履歴を保存すればタイムスタンプ代替を認める国税関係書類の電子保存要件。 | 国税庁『電子帳簿保存法の適用要件』 |
| NIS2 指令 | EU加盟国における重要セクターのサイバーセキュリティ基準強化と24時間以内報告義務。 | 経済産業省『NIS2 指令対応ガイド』 |
| Cyber Trust Mark | 米国 CISA が推進するIoTなどのサイバーセキュリティ認証制度。 | CISA『Leading the Way with Radical Transparency』 |
| サイバーセキュリティ基本法 | 政府・事業者の責務を定め、重要インフラ演習などを義務化する日本の基本法。 | e-Gov『サイバーセキュリティ基本法』 |
| 統一基準群 | 政府機関等のサイバーセキュリティ対策ベースライン文書群。 | NISC『関連法令等』 |
| J-CSIP | IPA が運営する重要産業分野向けサイバー情報共有イニシアティブ。 | NISC『Overview of Cybersecurity 2024』 |
