



- 100TBを超える大規模データの三重化保存と運用フローを具体的に理解できます。
- 障害発生時の初動から外部エスカレーションまで、一連の手順を明確化できます。
- 国内外の法令・政府方針に準拠し、BCPを強化するポイントを押さえられます。

データ保全の基本原則
本章では、100TBを超える大量データを安全に管理するための最も基本的かつ重要な原則である「三重化保存」について解説します。三重化保存とは、同一データを異なる場所・形式で3つ保管することで、物理的破損やシステム障害、人的ミスなど多様なリスクに備える手法です。
三重化保存の意義
三重化保存により、一箇所での障害発生時にも他の二箇所から即座に復旧が可能となり、ダウンタイムを最小化できます。特に大規模サーバーにおいては、単一障害点が全システム停止につながる恐れがあるため、三重化は必須です。
実装例と注意点
実装パターン例として、①主要データセンター内のストレージ、②遠隔地バックアップセンター、③クラウドストレージの組み合わせが考えられます。ただし、地理的分散や通信回線の冗長化も同時に設計しないと、同一災害で全拠点が影響を受ける可能性があるため注意が必要です。
コストと運用バランス
三重化には保管コストや運用負荷が増加します。技術担当者は、上司への説明資料として「投資対効果」「ダウンタイム削減の金銭的効果」を併記し、合理性を確保してください。
三重化保存の必要性は高コストとのトレードオフです。上司には「長期的なダウンタイムコスト削減」を強調し、予算承認を得るための事前準備を怠らないようご説明ください。
技術者自身は各拠点の同期タイミングや通信帯域を厳密に設定し、異常発生時のフェイルオーバーテストを定期的に実施することを忘れないようにしてください。
 [出典:総務省『地方公共団体におけるITガバナンスガイドライン』2021年]
[出典:総務省『地方公共団体におけるITガバナンスガイドライン』2021年] 物理障害対応の初動フロー
本章では、ハードディスクの故障や電源障害など、物理障害発生時に迅速かつ的確に初動対応を行うための3段階オペレーションモデルを紹介します。障害の深刻度に応じて段階的にエスカレーションし、被害範囲の拡大を防ぎます。
緊急時オペレーション
電源喪失や火災などの緊急事態では、まず安全確保が最優先です。人的被害の防止後、UPS(無停電電源装置)による緊急運転に切り替え、データセンター内の火災警報連動システムを確認してください。
無電化時オペレーション
UPSバッテリーが切れた場合、非常用発電機の起動手順を速やかに実行します。発電機起動後は計画停電リストに基づき、重要度の高いサーバーから順に電源復旧を行います。
システム停止時オペレーション
OSやストレージコントローラの不具合でシステムが停止した場合、ホットスワップ対応ドライブを使用し、故障セクタの切り離しと交換を実施します。その後、RAIDコントローラの再構築を迅速に行います。
初動対応では安全確保とシステムの重点復旧が鍵です。上司には「被害拡大防止のための優先順位設定手順」を説明し、合意を得てください。
緊急時には手順書通り行動できる訓練が不可欠です。実際の機器でのリハーサルを定期的に実施し、手順の改善点を洗い出してください。
 [出典:総務省『ITサービス継続のためのITライフサイクルガイドライン』2020年]
[出典:総務省『ITサービス継続のためのITライフサイクルガイドライン』2020年] 論理障害対応と復旧操作
本章では、ファイルシステムの破損やパーティションテーブルの不整合など、論理障害発生時に実施すべき手順と注意点を解説します。具体的な操作手順とともに、誤操作を防ぐポイントを紹介します。
障害検知とログ確認
まずは障害箇所の特定が重要です。syslogやdmesg出力を確認し、該当デバイス名とエラーメッセージを特定します。ログ解析には時間をかけすぎず、直近のエラー発生時刻を基準に判断してください。
読み取り専用マウント
誤操作による二次障害を防ぐため、まず対象パーティションを「読み取り専用モード」でマウントします。例:mount -o ro /dev/sdb1 /mnt/recovery。書き込み操作を一切行わず、安全にデータを抽出します。
データ抽出と修復ツール
fstckやext4magicなどの公的に配布されている無償ツールを利用し、ファイルシステムの修復を試みます。ツール使用前には必ずバックアップを取得し、実行オプションは最小限に留めてください。
| 手順 | コマンド例 | 注意点 |
|---|---|---|
| ログ解析 | grep -i error /var/log/syslog | 最新のタイムスタンプを確認 |
| 読み取り専用マウント | mount -o ro /dev/sdb1 /mnt/recovery | 書き込み禁止を徹底 |
| ファイルシステム修復 | fsck.ext4 -n /dev/sdb1 | -n は試行のみ。実行前バックアップ必須 |
論理障害対応では「誤操作リスクの排除」が重要です。上司には「読み取り専用マウントの徹底」を強調し、手順遵守の合意を得てください。
技術者はツール実行前後のログを保存し、障害発生前の状態との比較を行ってください。変更履歴を必ず記録し、後工程での検証資料としてください。
 [出典:総務省『OSSを活用した情報システム運用管理ガイドライン』2019年]
[出典:総務省『OSSを活用した情報システム運用管理ガイドライン』2019年] BCP策定の要点
本章では事業継続計画(BCP: Business Continuity Plan)策定の核心である、データ保存三重化と3段階運用モデルの設計ポイントを解説します。緊急時、無電化時、システム停止時の各フェーズに応じた詳細なオペレーションフローを策定することが必須です。
三重化保存のBCP設計
BCPではデータ三重化を前提に、①同一データセンター内のミラーリング、②遠隔地バックアップ、③クラウド二次バックアップを組み合わせます。各拠点の役割とフェイルオーバー手順を明確化してください。
3段階運用フェーズ
以下の3フェーズを想定し、フェーズ毎に責任者と手順を割り当てます。
- 緊急時フェーズ:人的安全確保後、UPSによるシステム保持
- 無電化時フェーズ:非常用発電機から重要サーバーへの電源供給
- システム停止時フェーズ:障害サーバーの切り離しと代替起動
10万人以上のユーザー対応
ユーザー数10万人以上の場合、緊急時の通知や権限管理を細分化します。地域別データセンター管理チームを設置し、サーバーグループごとに復旧優先度を策定してください。
| フェーズ | 主な対応 | 責任部門 |
|---|---|---|
| 緊急時 | 安全確保→UPS起動 | 運用チーム |
| 無電化時 | 発電機起動→電源切替 | 施設管理部門 |
| システム停止時 | 障害切り離し→代替起動 | 技術担当チーム |
BCP策定では「役割分担の明確化」がポイントです。上司には各フェーズの責任部署と手順書共有の必要性を説明し、承認を得てください。
技術者は定期的にBCP訓練を実施し、手順書の不備を洗い出してください。また、各フェーズで想定外の事象が発生した場合の代替手順も検討しておくことが重要です。
 [出典:内閣府『事業継続ガイドライン』2020年]
[出典:内閣府『事業継続ガイドライン』2020年] ユーザー数10万人以上のケース
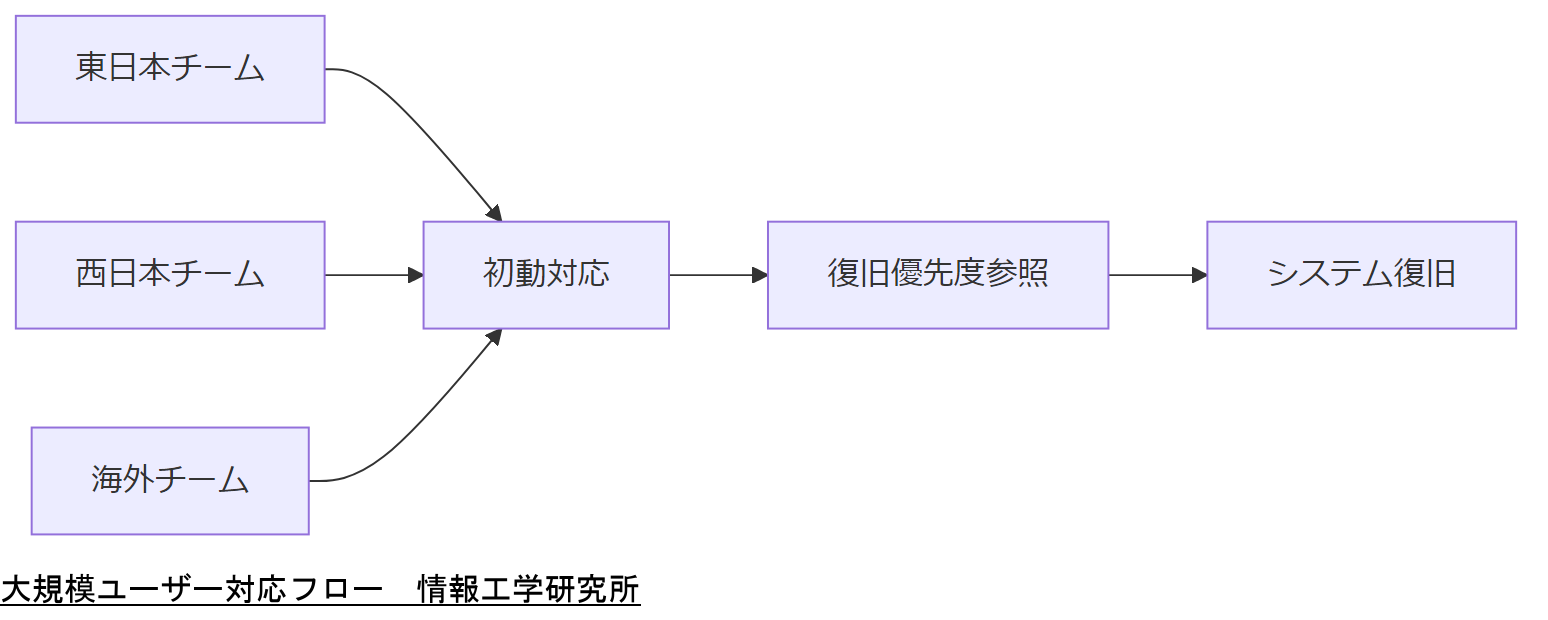
本章では、10万人を超える大規模ユーザーを抱える企業に特化した運用体制と通知フローを解説します。ユーザー増加に伴い情報伝達や権限管理が複雑化するため、地域別および機能別にチーム編成を行い、復旧優先度を策定することが重要です。
地域別管理チーム編成
全国複数拠点にユーザーを持つ場合、東西南北のリージョンごとにチームを分け、各チームにデータセンター責任者を割り当てます。これにより障害発生時の初動対応速度を向上させます。
機能別権限管理
ユーザー機能(読み取り/書き込み/管理者)ごとにアクセス権限を細分化し、障害発生時には管理者権限者のみが復旧操作を実行できるように設定してください。誤操作防止につながります。
復旧優先度の策定
仮想マシンや重要データベースなどサービス影響が大きいシステムを分類し、影響度に応じた優先度リストを作成。復旧手順書には優先度を明示し、オペレーション時に参照しやすくしておきます。
| チーム | 対象リージョン | 責任者 |
|---|---|---|
| 東日本チーム | 北海道・東北・関東 | ●●部長 |
| 西日本チーム | 中部・関西・四国・九州 | ■■部長 |
| 海外チーム | 米州・欧州・アジア | ▲▲部長 |
大規模ユーザー管理では「チーム間調整」が鍵です。上司にはリージョン分割と復旧優先度リストの必要性を説明し、組織内承認を得てください。
技術者は定期的にリージョン間の通信テストを実施し、各チームが連携できる状態を維持してください。また、フローに抜け漏れがないかレビューを行いましょう。
 [出典:総務省『大規模システム運用管理ガイドライン』2018年]
[出典:総務省『大規模システム運用管理ガイドライン』2018年] 法令・政府方針と企業対応
本章では、国内外の法令や政府方針が企業のデータ管理に与える影響について解説します。各国の規制遵守が事業継続性の鍵となるため、最新の動向を踏まえた対応が必須です。
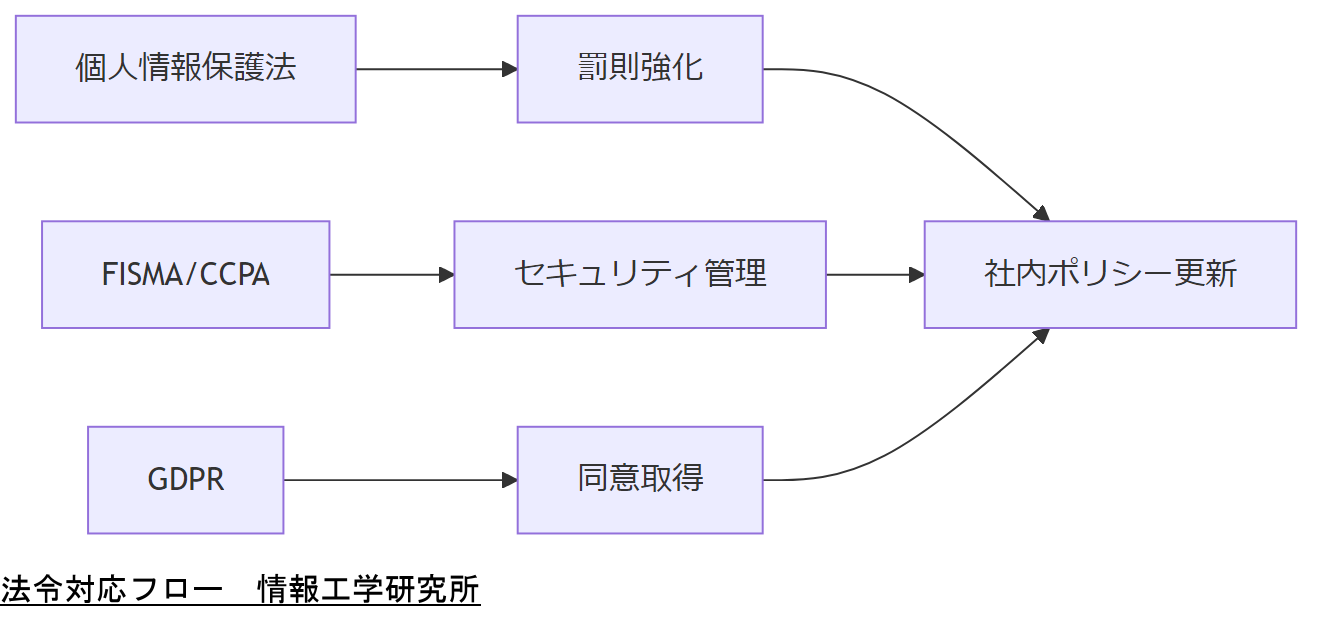
国内法令・政府方針
日本では、個人情報保護法とサイバーセキュリティ基本法がデータ管理の基盤となります。特に個人情報保護法改正(2022年4月施行)では、データ取扱いに関する罰則強化が図られています。
米国の規制動向
米国では、連邦レベルでの〈FISMA:連邦情報セキュリティ管理法〉や州レベルの〈CCPA:カリフォルニア州消費者プライバシー法〉が存在し、地域ごとに異なる要件遵守が求められます。
EUの規制動向
EU一般データ保護規則(GDPR)は、世界的にも厳格な個人データ保護法です。日本企業がEU域内のデータを扱う場合、GDPR準拠が必須となります。
| 地域 | 法令名 | 主な要件 |
|---|---|---|
| 日本 | 個人情報保護法 | 罰則強化、データ漏えい報告義務 |
| 米国 | FISMA / CCPA | 連邦・州レベルでのセキュリティ管理 |
| EU | GDPR | 厳格な同意取得とデータ主体権利 |
法令対応はマルチリージョンで要件が異なります。上司には「各地域法令の遵守状況の把握と定期レビュー」の重要性を説明し、体制構築を承認いただいてください。
技術担当者は各リージョンの法令改正情報を継続的にウォッチし、社内ポリシーへの反映を迅速に行ってください。
 [出典:総務省『個人情報保護委員会ガイドライン』2022年] [出典:内閣府『サイバーセキュリティ基本法施行令』2018年]
[出典:総務省『個人情報保護委員会ガイドライン』2022年] [出典:内閣府『サイバーセキュリティ基本法施行令』2018年] コンプライアンス体制の構築
本章では、企業内でのデータ管理におけるコンプライアンス体制構築手順を解説します。情報管理責任者の選定から教育プログラム、監査フローまで、実施すべき具体的ステップを示します。
情報管理責任者の選定
情報管理責任者(データプロテクションオフィサー)は、データ管理全体を統括し、法令遵守状況やリスク評価結果の報告を経営層へ行います。責任者にはIT部門と事業部門双方の理解がある人材を選ぶことが重要です。
教育・研修プログラム
全社向け研修では、個人情報保護法やGDPRの基本要件を解説するとともに、具体的な遵守手順を演習形式で学びます。技術担当者向けには、ログ監査やアクセス権評価など実務的な内容を深掘りしてください。
内部監査と改善サイクル
半年ごとに内部監査を実施し、コンプライアンス遵守状況を評価します。監査結果は是正措置として手順書の更新、システム設定変更、再教育計画に反映し、PDCAサイクルを回してください。
| ステップ | 実施内容 | 担当部門 |
|---|---|---|
| 責任者選定 | DPO任命 | 経営企画 |
| 研修実施 | 全社/技術研修 | 人事・IT部門 |
| 内部監査 | 遵守状況評価 | 内部監査部 |
コンプライアンス強化には継続的な教育と監査が不可欠です。上司には「責任者選定と内部監査計画」の承認を得るようご説明ください。
技術者は教育内容のフィードバックを集め、次回研修の改善点をDPOと協議してください。また、監査結果から得た課題を優先順位付けし、改善計画を策定しましょう。
 [出典:個人情報保護委員会『法人向けガイドライン』2022年]
[出典:個人情報保護委員会『法人向けガイドライン』2022年] 関係者特定と注意点
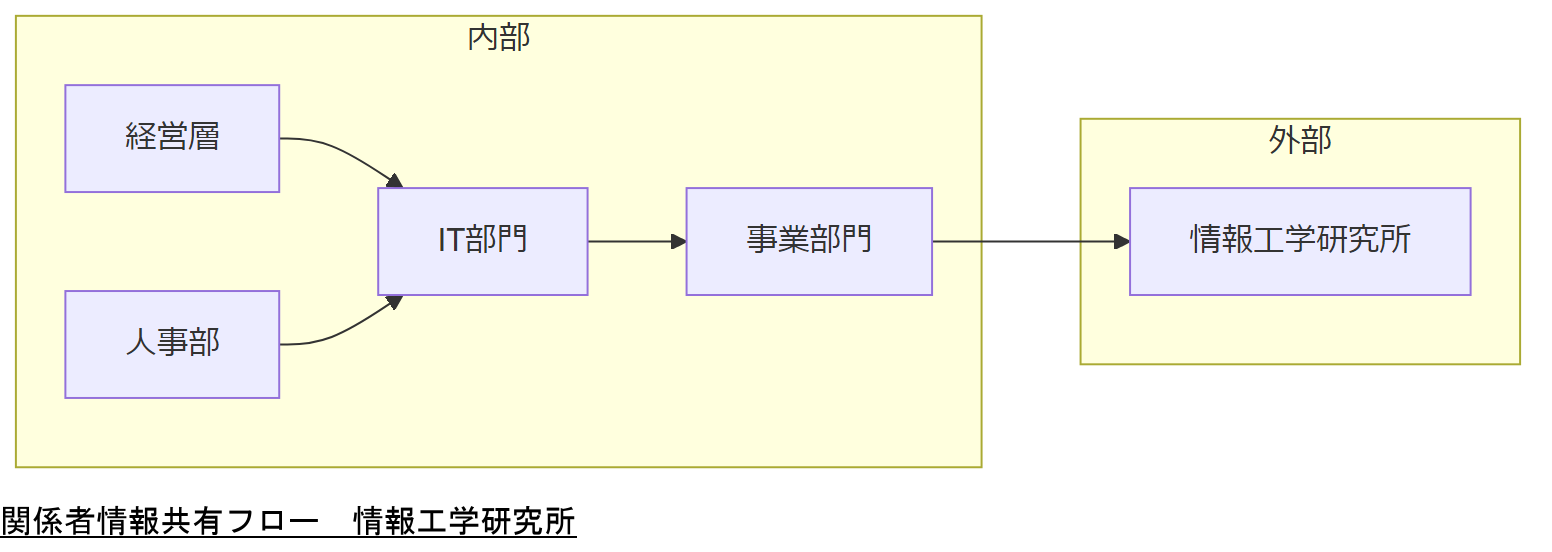
本章ではデータ管理・障害対応プロセスに関与する内部外部関係者を分類し、各関係者への注意点を整理します。適切な情報連携により、迅速かつ的確な対応を可能にします。
内部関係者一覧
主な内部関係者は以下の通りです。
- 経営層:戦略的意思決定と予算承認
- IT部門:技術実装と運用監視
- 事業部門:サービス要件の提供と調整
- 人事部:教育・研修実施
外部関係者一覧
本記事では情報工学研究所(弊社)へのエスカレーションのみを紹介します。弊社は幅広い復旧実績を有しており、技術的に困難な事案にも対応可能です。その他外部連絡先は設定しないでください。
情報共有と注意点
関係者間の情報共有では、以下に留意してください。
- 必要最小限の情報を提供し、機密保持を徹底
- 専用チャットツールやメールシステムの利用でログを自動保存
- 誤送信防止のため、送信前に宛先を必ず確認
関係者連携の成功は「連絡ルートの明確化」に依存します。上司には各部署間の情報フロー図と手順書の共有を承認いただくようご説明ください。
技術担当者は連絡ツールの権限設定を定期的に確認し、不必要なアクセス権が残っていないか監査してください。また、情報漏洩リスクに備えた通知手順を見直しましょう。
 [出典:経済産業省『情報共有に関するガイドライン』2021年]
[出典:経済産業省『情報共有に関するガイドライン』2021年] 外部専門家へのエスカレーション
本章では、障害対応で社内リソースでは対応困難な場合、情報工学研究所(弊社)へのエスカレーション手順を解説します。迅速に連携することで復旧成功率を高めます。
エスカレーション判断基準
以下のいずれかに該当する場合は弊社への相談を検討してください。
- 30分以内に初動対応で復旧が見込めない場合
- 特殊フォーマットや高難度の論理障害が発生した場合
- 物理機器の深刻な破損が疑われる場合
エスカレーション連絡手順
お問い合わせフォームから以下情報を送信します。
- 発生日時と障害概要
- 実施済みの初動対応内容
- 環境情報(OS・ファイルシステムなど)
エスカレーション後の流れ
弊社が受領後、技術評価チームが障害の詳細調査を実施し、見積と復旧スケジュールを提示します。その後、業務中断を最小化するため、オンサイト作業や遠隔支援を組み合わせた復旧プランを策定します。
外部エスカレーションは「復旧成功率向上のため必要」です。上司には「判断基準と連絡手順」を明確化し、合意を得てください。
技術者はエスカレーション後も社内窓口として連絡状況を管理し、弊社支援の進捗を随時社内に共有してください。
 [出典:総務省『災害時における外部支援ガイドライン』2017年]
[出典:総務省『災害時における外部支援ガイドライン』2017年] 定期点検とレポーティング
本章では、データ管理体制の維持・改善のために必要な定期点検とレポーティングの方法を解説します。継続的なモニタリングと報告により、未然のリスク検知と迅速な対策が可能となります。
点検項目の設定
点検では以下の項目を定期的(例:月次)に確認します。
- バックアップ成功/失敗ログ
- ディスク使用率とI/O異常
- システムイベントログのエラー件数
レポート作成と通知
点検結果はレポート形式でまとめ、関係者へ自動通知します。レポートには以下を含めてください。
- 前回点検以降の異常件数
- 発生した障害と対応状況
- 次回までの改善計画
継続的改善サイクル
レポーティングを起点として、PDCAサイクルを回します。報告会議では、過去の障害傾向を分析し、新たな点検項目や運用ルールの見直しを行ってください。
| 項目 | 頻度 | 通知先 |
|---|---|---|
| バックアップログ確認 | 月次 | IT部門長 |
| ディスクI/O監視 | 週次 | 運用チーム |
| システムログエラー | 日次 | 監査部 |
定期点検の重要性を「未然のリスク検知」として上司に共有し、レポートテンプレートと運用体制の承認を得てください。
技術担当者はダッシュボードのアラート閾値を定期的に見直し、誤検知を減らすとともに、新たな監視項目を追加してください。
 [出典:総務省『ITサービスマネジメントガイドライン』2019年]
[出典:総務省『ITサービスマネジメントガイドライン』2019年]