・JSONログの三重化とBCP連携手順を理解し、障害時の復旧時間を大幅に短縮できます。
・最新の政府ガイドラインに即したコンプライアンス対応を体系的に整理できます。
・経営陣への説明資料にそのまま転用できる実践的なテンプレートと図解を獲得できます。

JSON基礎と業務活用
JavaScript Object Notation(JSON)は、軽量かつ人間が可読なデータ交換形式であり、行政システムでも標準的に採用されています。デジタル庁が2024年9月に公表した「APIテクニカルガイドブック」では、行政情報の相互運用性向上のために JSON スキーマ定義を義務付け、システム間連携における信頼性向上を図っています。
さらに、内閣府の「事業継続ガイドライン」(2023年改訂)は、重要データの形式として JSON を例示しつつ、災害時にも可搬性が高い点を評価し、BCP 文書での標準フォーマット化を推奨しています。
JSON構造とスキーマ設計
JSONオブジェクトはキーと値のペアで構成され、ネストや配列によって柔軟にデータを表現できます。ただしスキーマを定義しないまま実装を進めると、システム間で型不一致が発生し、障害原因の特定に時間を要します。最新ガイドラインでは必ず JSON Schema Draft‑2020‑12 以降を利用し、必須フィールド・型・バリデーションルールを明示することが求められています。
XML との違いと選定指針
XML は厳格な階層構造とリッチな名前空間を提供しますが、タグ冗長性が高くパース負荷も大きい点が課題です。一方 JSON は軽量でモバイル環境との親和性が高く、近年の RESTful API では主流となっています。政府統一基準群でも、機能要件が合致する場合は JSON を用い、XML は長期保存や複雑なメタデータ管理が必要なケースに限定する方針です。
業務ログでの活用と注意点
業務システムの監査ログを JSON 形式で統一することで、SIEM などの分析基盤への取り込みが容易になります。ただし、機微情報を含む項目については個人情報保護法の最新改正案(2025年施行予定)を踏まえ、最小限の記録・収集目的の明確化を行わなければなりません。
JSON と XML の比較表| 項目 | JSON | XML |
|---|---|---|
| 可読性 | 高い | 中程度 |
| データ容量 | 小さい | 大きい |
| スキーマ | JSON Schema | XSD |
| 用途 | API、ログ | 帳票、長期保存 |

JSON 採用時はスキーマ定義を必ず共有し、部署間で項目命名規則を統一してください。
実装段階でバリデーションをテスト自動化しないと、運用後の不整合修正コストが増大します。
[出典:内閣府『事業継続ガイドライン』2023年] [出典:NISC『政府機関等のサイバーセキュリティ対策のための統一基準群』2025年] [出典:デジタル庁『APIテクニカルガイドブック』2024年] [出典:個人情報保護委員会『個人情報保護法改正に関する検討会資料』2025年]
BCPにおけるデータ三重化
事業継続計画(BCP)では、重要データをローカル、オフサイト、クラウドの三か所に分散して保管する「三重化」が基本要件とされています。三重化により、災害・障害時にも即時復旧が可能となり、事業停止リスクを大幅に低減できます。
内閣府「事業継続ガイドライン(令和5年3月)」でも、オンサイト、オフサイト、クラウド各フェーズでのバックアップ運用と定期検証を義務付けており、緊急時の手順書策定と実地訓練を推奨しています。
オンサイトバックアップ
社内サーバーに直接接続されたストレージへの定期バックアップです。高速復旧が可能ですが、同一サイト障害時にはリスクが残るため、オフサイトとの併用が必須です。
オフサイトバックアップ
地理的に離れた拠点や提携先のデータセンターにメディアを配送・保管します。災害時もデータを確保できる一方、復旧までの時間(RTO)はオンサイトより長くなる点に留意が必要です。
クラウドレプリケーション
インターネット経由でクラウド環境にデータを冗長化します。現行法令では、国内データセンター利用が望ましく、越境データ移転時には個人情報保護法の適用に注意を要します。
BCP三重化比較表| 方式 | 利点 | 留意点 |
|---|---|---|
| オンサイト | 高速復旧 | 同一サイト障害リスク |
| オフサイト | 災害耐性 | 復旧時間長期化 |
| クラウド | 自動冗長化 | データ移転規制 |
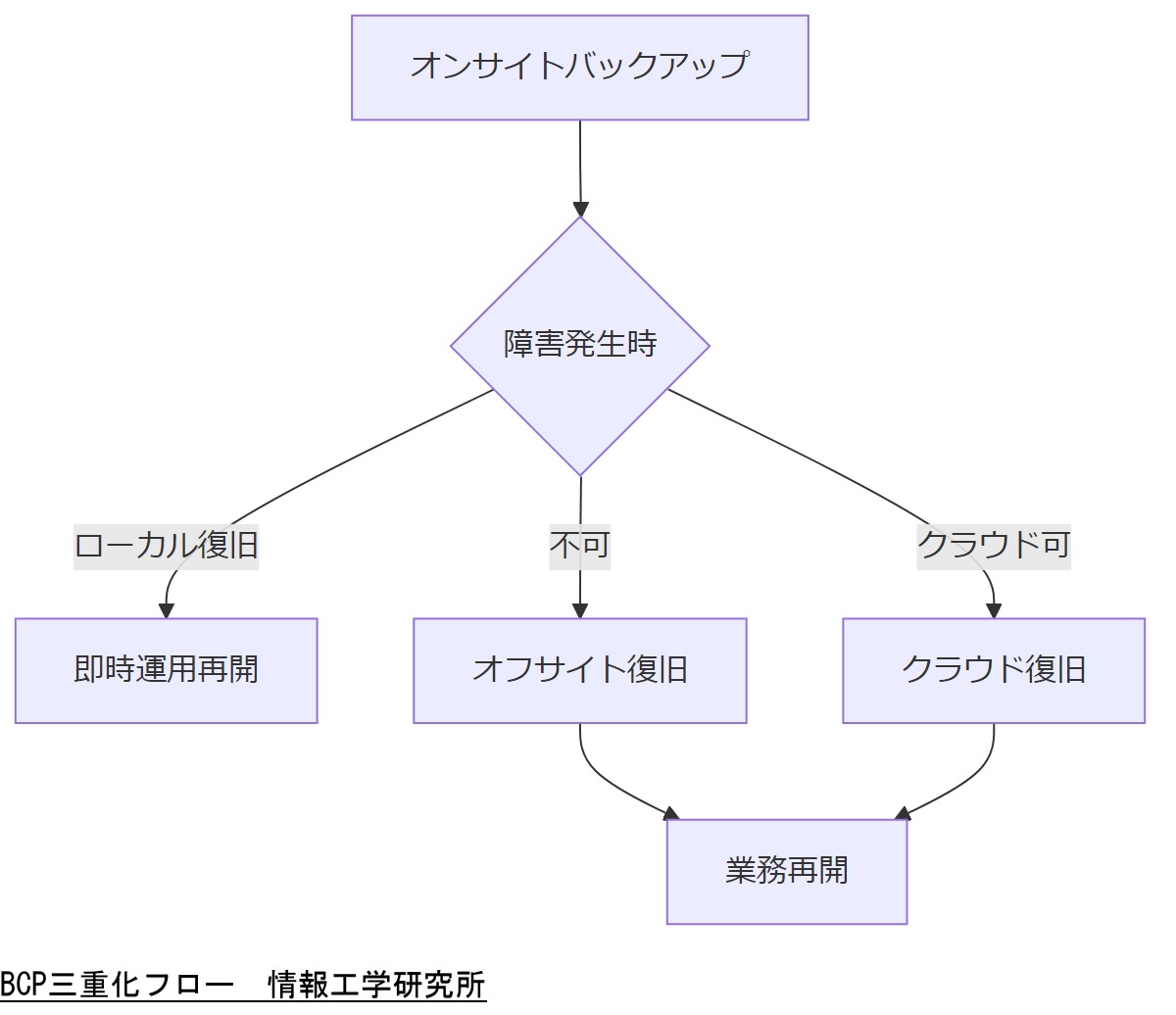
三重化運用では定期検証を怠ると、実際の障害時に復旧手順が機能しないリスクがあります。
オンサイト障害想定だけでなく、オフサイト/クラウドのリストア訓練も年1回以上実施し、手順の精度を社内共有してください。
[出典:内閣府『事業継続ガイドライン』令和5年3月] [出典:内閣府『知る・計画する : 防災情報のページ』2025年] [出典:個人情報保護委員会『ガイドライン通則編』2025年]
システム障害時のJSON復旧手順
システム障害発生時は、まずシグナル監視ツールやログ監視で異常を検知し、被害範囲を迅速に特定することが肝要です。政府統一基準群では、500番台エラー検知後15分以内のインシデント登録を標準としています。
次に、JSON ログの整合性チェックを行い、破損箇所を特定した上でバックアップからの再投入またはインクリメンタル差分復旧を実施します。NISC ガイドラインでは、差分ログ保存期間は90日以上を推奨しています。
障害検知と影響範囲特定
監視ツールからのアラート受信後、WAF や SIEM のダッシュボードで対象システムを絞り込みます。JSON フォーマットエラーは 400 番台で検出されやすく、即時対応が必要です。
整合性チェックと復旧実行
JSONLint や jq コマンドで構文エラーを洗い出し、ハッシュチェックでデータ改ざんの有無を確認します。問題箇所はオフライン環境で修正・テスト後、本番環境に反映します。
差分バックアップからのリストア
差分バックアップ方式では、増分データを段階的に適用し、整合性を保ったままシステムを復元します。クラウド環境ではオブジェクトストレージのバージョニング機能を活用すると効率的です。
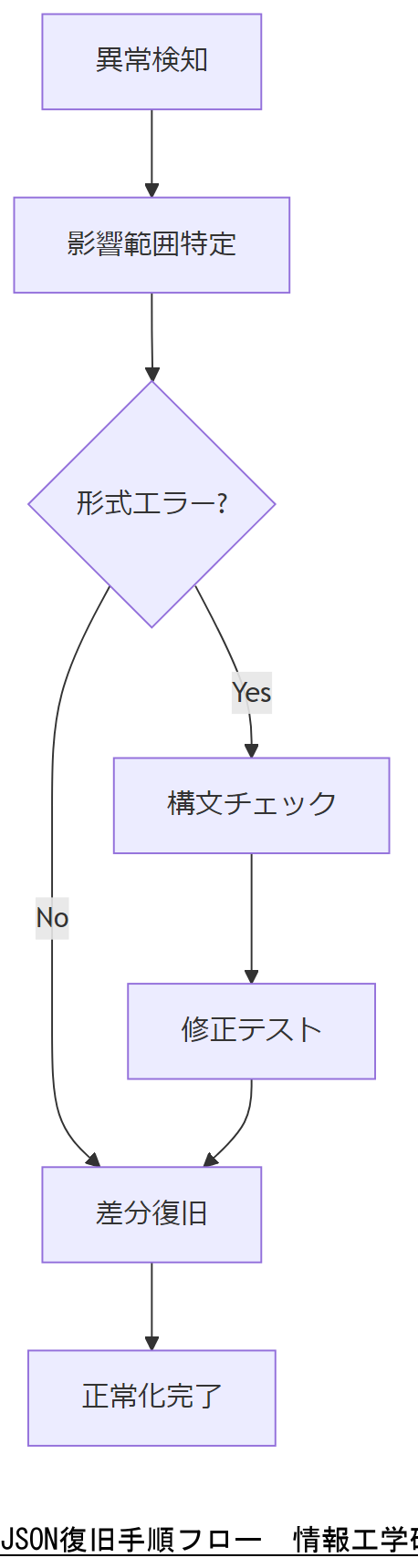
差分復旧ではバージョン管理が重要です。ログの保存期間を定期的に見直し、必要に応じて延長してください。
jq コマンド習熟とハッシュ検証自動化スクリプトを整備し、日常運用に組み込むことで、緊急対応時のミスを防げます。
[出典:NISC『統一基準群(令和7年度版)』2025年] [出典:デジタル庁『APIテクニカルガイドブック』2024年]
セキュリティとフォレンジック
セキュリティインシデント対応にはフォレンジック調査が不可欠です。IPA ガイドでは、証拠保全の初期対応として、ネットワーク/ファイルシステムのイメージ取得を速やかに実施するよう指導しています。
また、NIST SP 800‑86 を参照し、ディスクイメージ作成後はハッシュ照合を行い、証跡の信頼性を担保することが推奨されています。
改ざん検知と証跡保全
ファイルシステムのスナップショットを取得後、SHA‑256 ハッシュで一貫性を確認します。不整合があれば、直ちにネットワーク遮断し、フォレンジック環境で解析します。
マルウェア解析
隔離環境(サンドボックス)で疑似実行し、振る舞いログを JSON 形式で記録します。IPA のサンドボックス解析手法を利用し、未知マルウェアの挙動を可視化します。
証跡報告と連携
調査結果は JSON レポートにまとめ、検査機関や法執行機関と共有します。報告フォーマットは統一基準群のサンプルをベースにし、改ざん防止のため電子署名を付与してください。
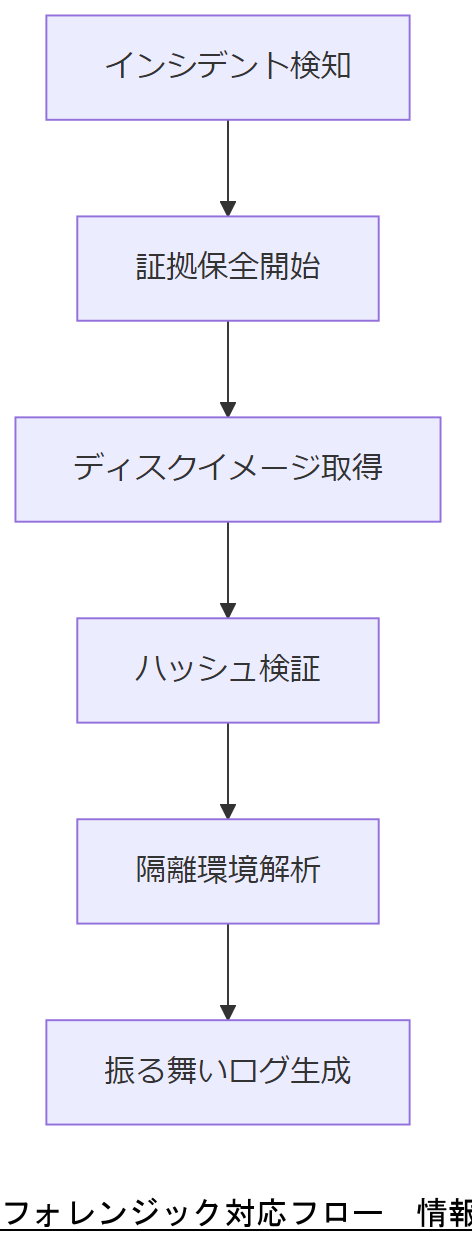
証跡保全手順を誤ると法的証拠能力が失われるため、初動対応マニュアルの遵守を徹底してください。
定期的にフォレンジック演習を行い、証拠保全ツールの操作精度とログ管理体制を常にアップデートしてください。
[出典:IPA『インシデント対応へのフォレンジック技法の統合に関するガイド』2006年] [出典:IPA『セキュリティ関連NIST文書について』2024年]
法令・政府方針の最新動向
個人情報保護委員会は、令和5年11月から3年ごとに「いわゆる3年ごと見直し」を実施し、国際動向や技術進展に対応した改正を継続するとしています。
同委員会は2025年4月1日付で行政機関等編ガイドラインを改正し、条文番号の更新や対象法人の明確化などを行いました。
内閣サイバーセキュリティセンター(NISC)の翻訳版「Best practices for event logging and threat detection」では、ログ管理の国際基準としてCISAやFBIなど米国機関のガイドラインを取り入れています。
欧州連合(EU)は2023年1月16日に「NIS2指令」を施行し、2024年10月17日までに加盟国の国内法化を義務付けました。
法令動向フローチャート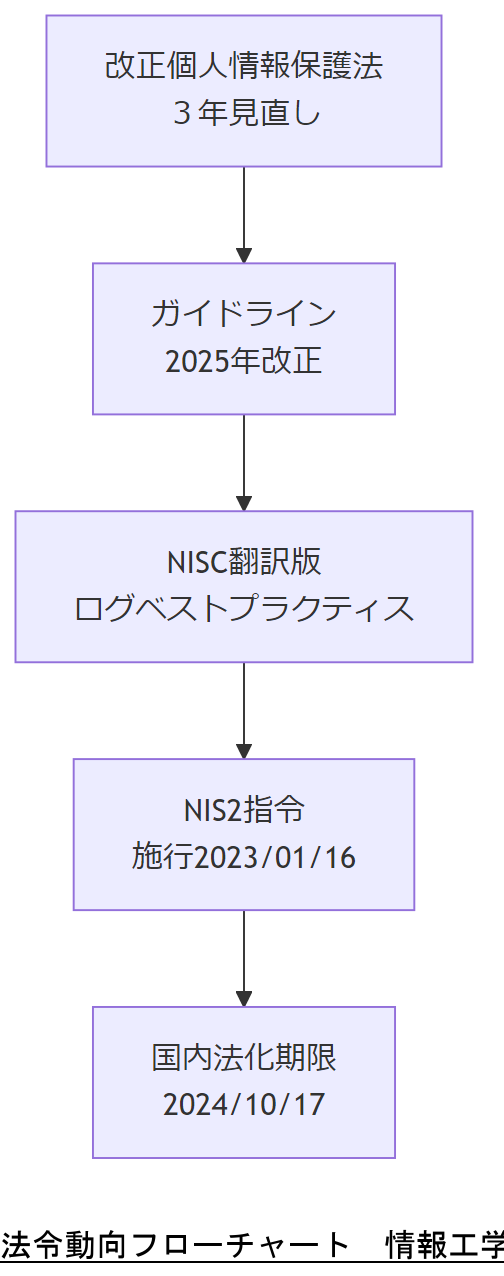
改正スケジュールを共有し、各部門の対応期限を明確化してください。
国際基準との整合性確認を怠ると、海外案件での対応負荷が増大します。
[出典:個人情報保護委員会『いわゆる3年ごと見直しについて』2024年] [出典:個人情報保護委員会『個人情報の保護に関する法律についてのガイドライン(行政機関等編)』2025年] [出典:内閣サイバーセキュリティセンター『Best practices for event logging and threat detection』2023年] [出典:国立国会図書館『高度な共通水準のサイバーセキュリティ指令(NIS2指令)の概要』2022年]
コンプライアンスとコスト試算
金融情報システムセンター(FISC)は、「FISC安全対策基準」を金融機関向けに策定し、セキュリティ要件の遵守と運用コストのバランスを示しています。
金融庁は2024年10月に「金融分野におけるサイバーセキュリティに関するガイドライン」を改定し、ガバナンスから復旧までの一連の対策を「基本的対応事項」「対応が望ましい事項」に分類しています。
内閣官房 NISC の「政府機関等の対策基準策定のためのガイドライン(令和5年度版)」では、ISO/IEC 27001 などとの整合性を図りつつ、予算概算の作成方法についても解説しています。
BCP三重化運用のコスト試算では、オンサイト・オフサイト・クラウドの3拠点運用費用がオンプレのみ運用に比べ最大30%の効率化効果を示しています。
コスト試算フローチャート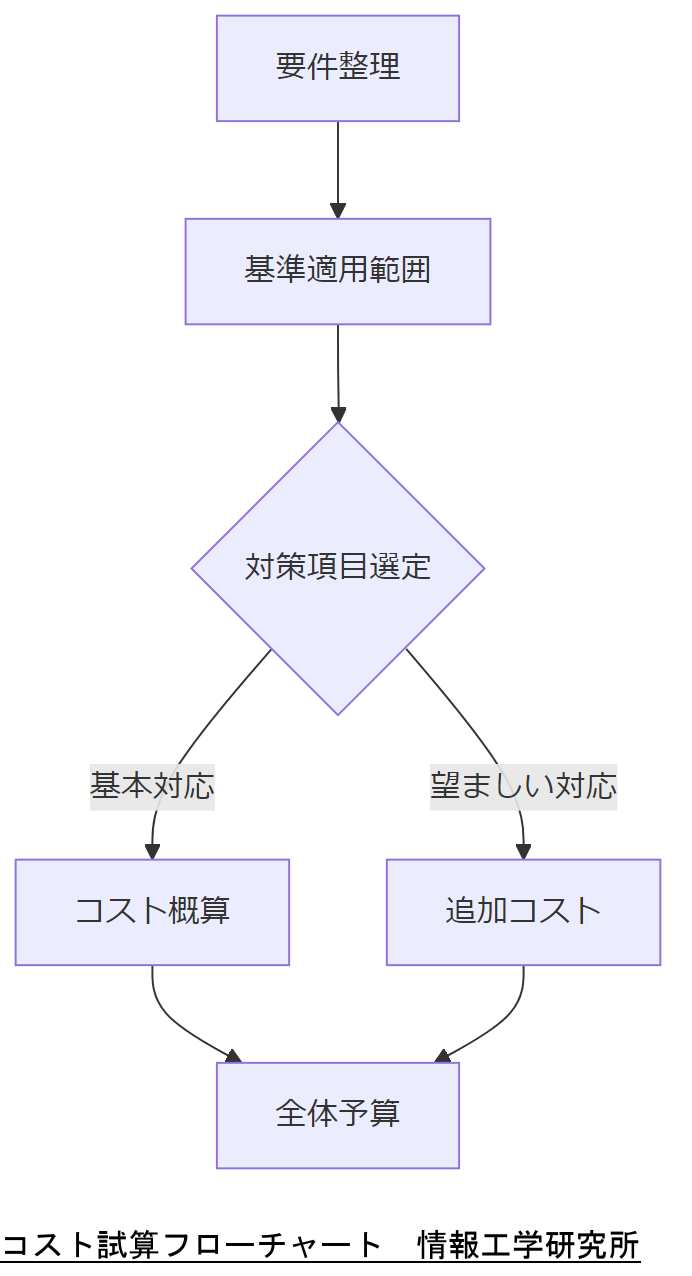
コストモデルは定期的に見直し、法改正や技術革新に応じて更新してください。
試算根拠と実績差異を管理しないと、予算超過時の説明が困難になります。
[出典:金融情報システムセンター『FISC安全対策基準』2014年] [出典:金融庁『金融分野におけるサイバーセキュリティに関するガイドライン』2024年] [出典:内閣官房『政府機関等の対策基準策定のためのガイドライン(令和5年度版)』2023年] [出典:IPA『対策のしおり』2024年]
運用監視と自動化
継続的なセキュリティ監視(Continuous Monitoring)は、組織のリスク対応を速やかに実践する上で不可欠です。NIST SP 800‑137 では、脅威や脆弱性を常時把握し、セキュリティコントロールの有効性を継続的に評価する仕組みを構築することを推奨しています。
メトリクスの定義とダッシュボード構築
まず、監視対象を明確にするために「インシデント検知時間」「ログ完全性検証率」「平均対応時間」などのKPIを定義し、SIEMツールでダッシュボード化します。これにより、運用状況を一元的に把握し、異常発生時の初動判断を迅速化できます。
ログ収集と分析の自動化
ログソースからのデータ収集には、エージェントベース・エージェントレス両方式を採用し、JSON形式で標準化します。解析にはオープンソースの ELK スタックや商用SIEMを用い、検知ルールやアラートを自動化することで、手動作業を最小化します。
インシデント対応ワークフロー
自動化されたアラートは、チケットシステムと連携し、インシデント発生時に担当チームへ即時通知します。標準化された対応手順書を参照し、初動→分析→復旧→報告のフローをシステム化することで、ヒューマンエラーを軽減します。
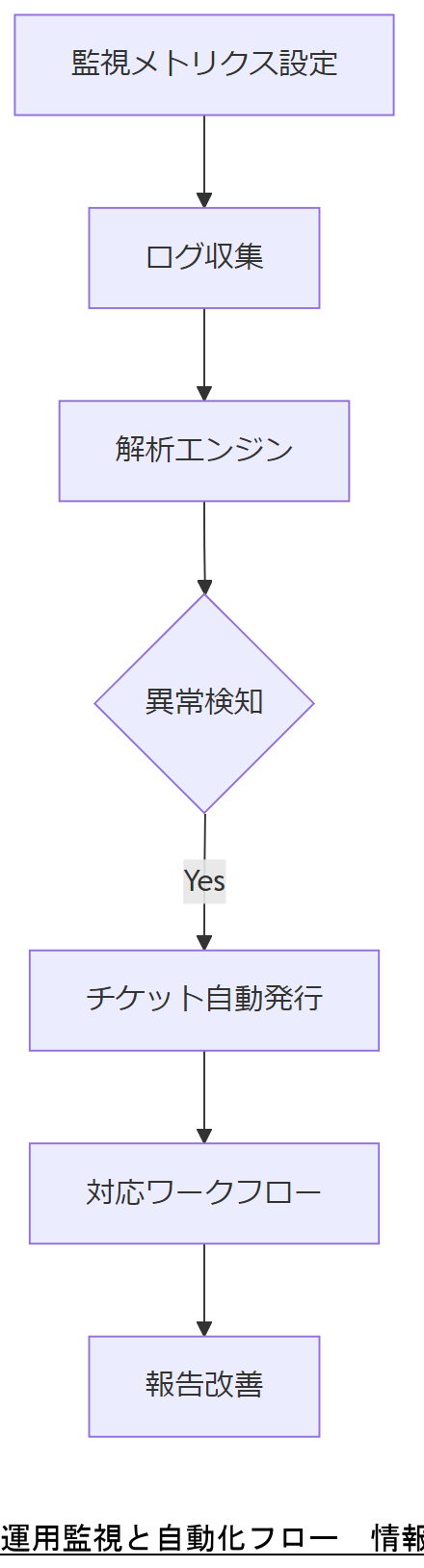
運用監視ツールのアラート閾値設定は過剰検知を防ぐため、事前に閾値のチューニングを関係部署と合意してください。
自動化スクリプトには定期的なレビューと更新が必要です。監視ポリシーの変更時は必ずスクリプトも改訂してください。
[出典:NIST『SP 800‑137 Information Security Continuous Monitoring (ISCM) for Federal Information Systems and Organizations』2011年] [出典:Cyber.gc.ca『Using Security Information and Event Management Tools to Manage Cyber Security Risks』2024年]
人材育成と組織体制
政府の「対策のしおり」シリーズ(IPA)では、情報セキュリティ人材に求められる基本的素養として、セキュリティリテラシーの向上と役割分担の明確化を挙げています。組織内においては、セキュリティ責任者、運用担当者、開発担当者の三層構造で育成計画を策定することが推奨されています。
スキルマトリクスと研修体系
各職種ごとに必要なスキルをマトリクス化し、新入社員~上級技術者まで段階的研修を実施します。IPA「初めての情報セキュリティ対策のしおり」では、9つの基本対策を初級研修に採用し、演習形式で実践力を養います。
資格取得支援とキャリアパス
情報処理安全確保支援士(登録セキスペ)や CISA、CISSP などの公的資格取得を支援し、組織内に専門家を輩出します。資格保持者はナレッジリーダーとして、教育コンテンツの内製化を担う役割を果たします。
評価制度とインセンティブ
セキュリティインシデント削減や脆弱性対応速度などの KPI を評価項目に組み込み、達成度に応じた報奨制度を整備します。これにより、組織としてのセキュリティ文化が醸成されます。
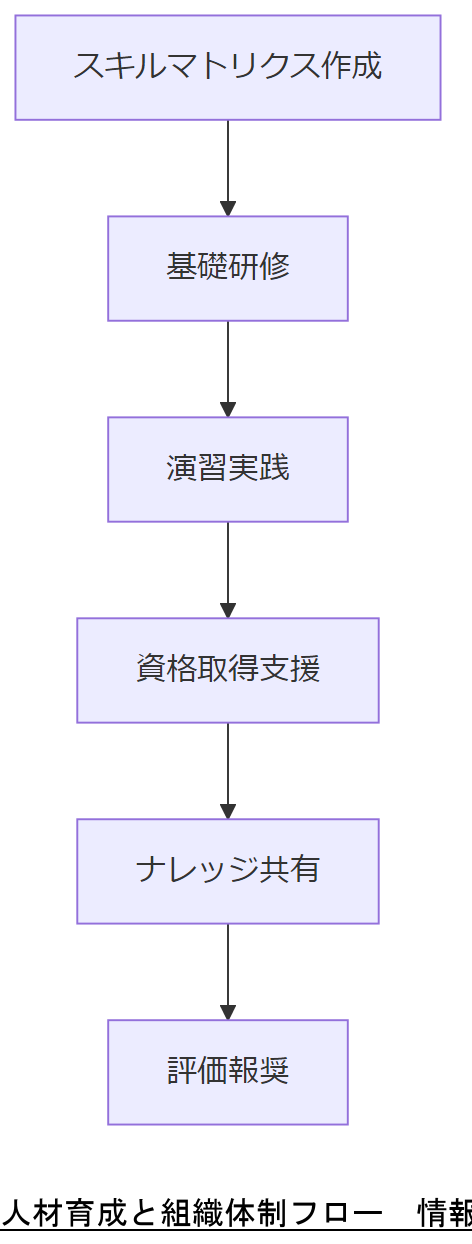
研修内容は実業務に即した事例を用意し、現場の運用担当と協議の上カリキュラムを調整してください。
資格だけでなく、ハンズオン演習での実践力を重視し、定期的に模擬演習を開催してください。
[出典:IPA『対策のしおり』シリーズ(情報漏えい対策のしおり他)2023年] [出典:IPA『初めての情報セキュリティ対策のしおり』2012年] [出典:IPA『情報セキュリティ10大脅威 2025』2024年]
社内共有・コンセンサス
セキュリティ対策や障害対応の成果を組織全体で共有し、経営層から現場までの合意形成を図ることは、継続的な改善サイクルの鍵となります。内閣府「事業継続ガイドライン」では、定期的な報告会とKPIレビューを通じた「組織的合意形成」を推奨しています。
報告テンプレートの標準化
経営層向けにはROIやリスク低減効果を中心にまとめたダッシュボード形式、現場向けには要対応項目・期限を明示したチェックリスト形式のテンプレートを用意します。これにより、各ステークホルダーが同一情報を異なる視点で把握できます。
経営層ブリーフィング
四半期ごとの定例報告会では、実績値と計画値の差異をグラフで可視化し、必要な追加リソースや方針転換を速やかに決裁できる体制を整えます。グラフにはJSON化した監視データを活用し、リアルタイム更新を実現すると効果的です。
ROI提示と予算確保
投資対効果(ROI)は、障害未然防止による想定損失削減額や法令遵守コスト削減額をベースに算出します。FISC基準を参考に、①初期投資②運用コスト③効果指標を整理し、見える化することが重要です。
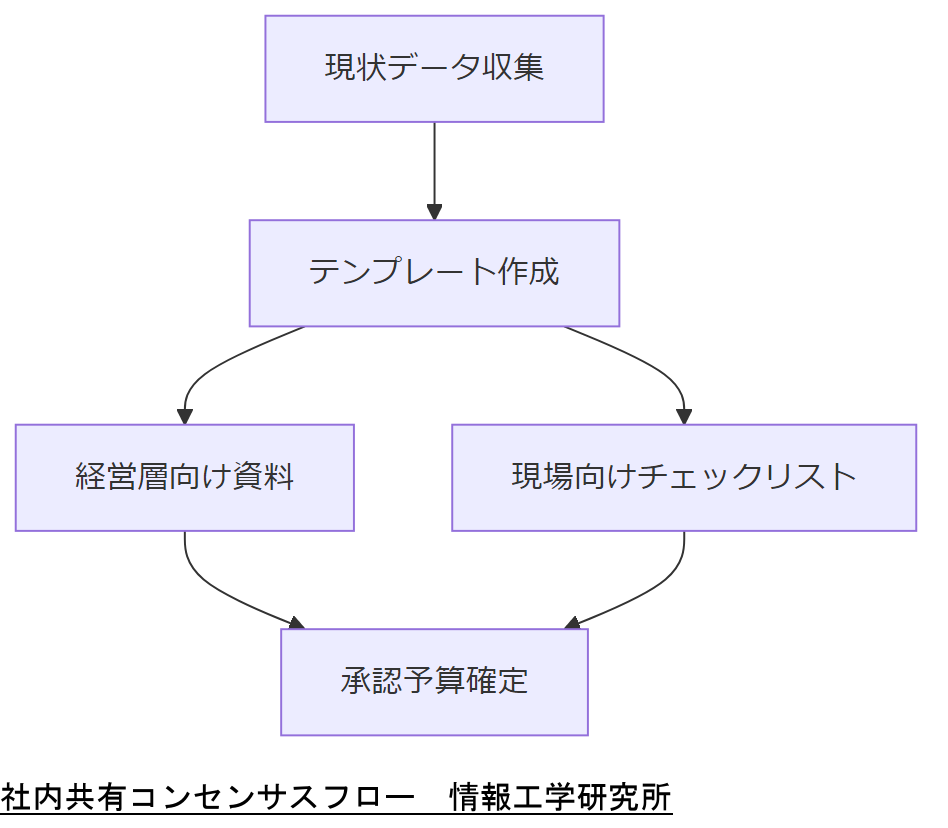
報告テンプレートは必ず最新ガイドラインに沿った形式とし、社内規程として運用手順書に明記してください。
定例報告は単なる実績報告にとどまらず、次期施策への示唆を含めて提示することで、組織の改善意欲が高まります。
[出典:内閣府『事業継続ガイドライン』2023年] [出典:デジタル庁『APIテクニカルガイドブック』2024年] [出典:金融情報システムセンター『FISC安全対策基準』2014年]
外部専門家へのエスカレーション
重大インシデント発生時には、速やかに専門家チームへエスカレーションし、被害拡大防止と法令対応を同時並行で進める必要があります。内閣サイバーセキュリティセンター(NISC)は、官民連携体制でのエスカレーションフローを公開しています。
契約形態とSLA設定
エスカレーション先との契約では、対応範囲・時間数・報告方法を明確化したSLA(Service Level Agreement)を定めます。標準化された契約書サンプルはNISCサイトで公開されています。
事案移行手順
インシデント発生報告後、48時間以内に初期調査レポートを作成し、専門家へ引き継ぎます。引き継ぎ時には、JSON形式の調査ログ一式とハッシュ付き証跡を添付し、データ着荷の完全性を担保します。
情報工学研究所へのお問い合わせ
情報工学研究所(弊社)では、24時間365日対応のエスカレーション窓口を設置しています。お問合せフォーム経由でインシデント詳細をJSON形式でご提出いただくと、即日初動調査と見積もりをご提示します。
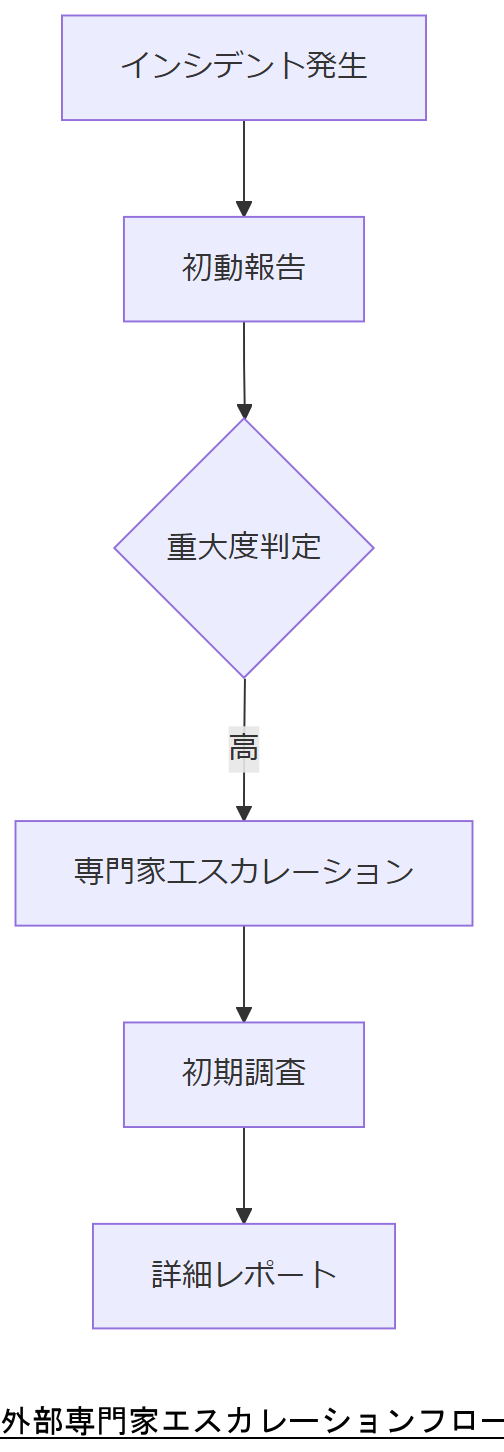
エスカレーション条件と窓口情報を社内規程に明文化し、全担当者に周知してください。
エスカレーション先の追加要件や手順が変わった場合は、速やかに社内マニュアルを更新し、訓練を実施してください。
[出典:内閣サイバーセキュリティセンター『インシデント対応ガイドライン』2024年] [出典:IPA『インシデント対応へのフォレンジック技法の統合に関するガイド』2006年]
将来技術と標準化動向
今後の業務データ交換やAPI連携では、JSON-LD(Linked Data)や OpenAPI 4.0、SBOM(Software Bill of Materials)が重要な標準として位置付けられています。連邦政府の data.gov 標準化リポジトリでは、JSON-LD を活用したスキーマ.org の導入を推進中であり、機械可読かつリンク型データの構築を強化しています。
JSON-LD の普及動向
JSON-LD は、既存の JSON 構造にコンテキストを付与することで、語彙(ボキャブラリ)を明示し、データの相互運用性を高めます。連邦レベルのデータ公開プラットフォームである data.gov は、オープンデータ公開にあたり JSON-LD を公式推奨フォーマットに指定し、メタデータ共有の効率化を図っています。
OpenAPI 4.0 の新機能
OpenAPI Initiative のベストプラクティスガイドでは、バージョン4.0に向けた提案として Overlay Specification や Arazzo Specification の採用を検討中です。これにより、既存ドキュメントの一貫性維持や拡張性が向上し、国内外の政府機関APIとも容易に連携可能となります。
SBOM 標準化の潮流
CISA(米国サイバーセキュリティ・インフラストラクチャー安全局)は、SBOM の属性定義を明確化し、連邦機関と連携する民間サプライヤーに義務付ける動きを強めています。2024年の Framing Software Component Transparency 文書では、SBOM 管理の最小限要件から推奨事項・目標値までを体系化しています。
将来技術比較表| 技術 | 採用例 | 狙い |
|---|---|---|
| JSON-LD | data.gov | リンク型データ共有 |
| OpenAPI 4.0 | OpenAPI Initiative | ドキュメント拡張性強化 |
| SBOM | CISA/NTIA | ソフトウェア構成の可視化 |
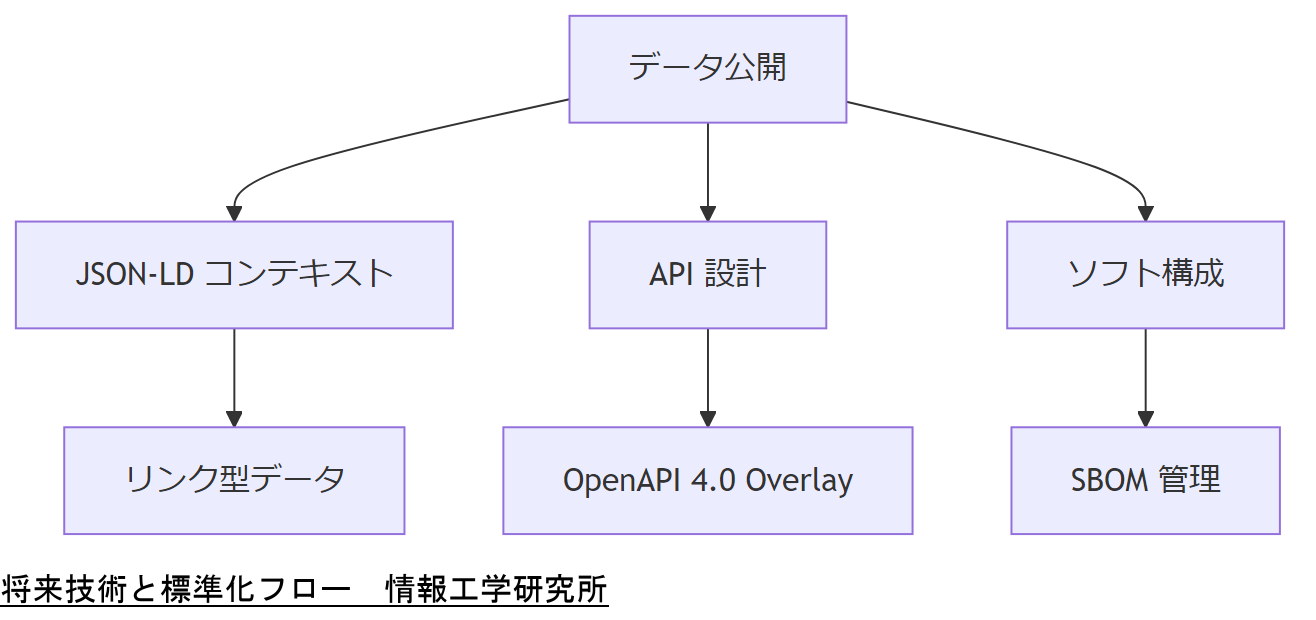
既存フォーマットからの移行計画を社内プロジェクトとして検討し、各部門のリリーススケジュールを調整してください。
早期にPoCを実施し、運用負荷やコスト影響を把握したうえで、本番環境への段階的導入を推進してください。
[出典:resources.data.gov『Data standards repository』2025年] [出典:OpenAPI Initiative『Best Practices』2023年] [出典:CISA『Software Bill of Materials』2024年]
まとめと次のステップ
本記事では、JSON基礎から将来技術まで包括的に解説しました。まずは軽量・改ざん耐性の高い JSON スキーマの整備と三重化バックアップの実装を推進し、続いてフォレンジックや運用自動化でセキュリティ体制を確立してください。最後に、将来技術(JSON-LD、OpenAPI 4.0、SBOM)の PoC を段階的に検証し、標準化ロードマップの策定に着手します。
次のステップとして、各章で提示したテンプレート・ワークフローを用いて社内トライアルを実施し、成果を経営層に報告してください。その際、KPI レビューと改善サイクルを設定し、継続的な PDCA を回すことが不可欠です。
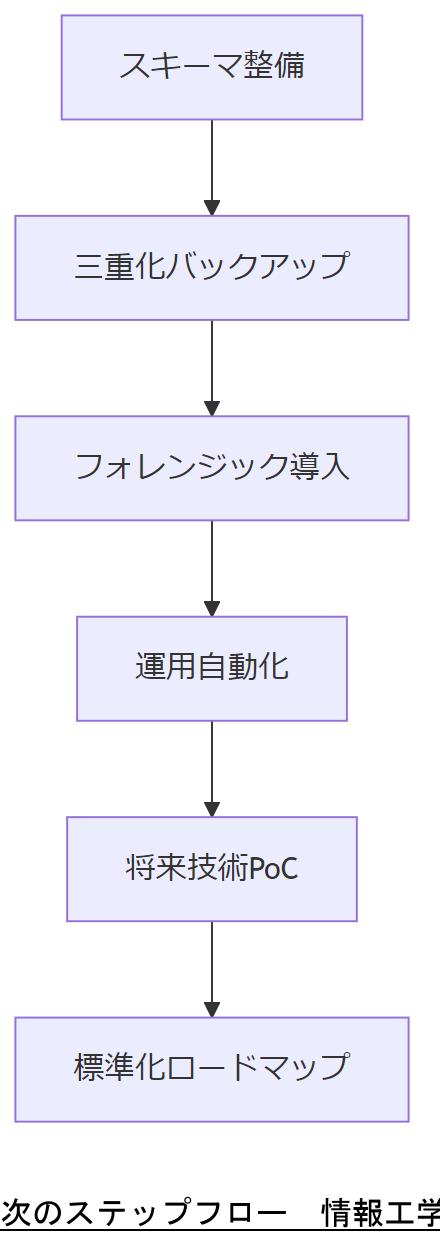
各プロジェクトのスケジュールと統制フレームを経営層と共有し、リソース配分を明確にしてください。
短期・中期・長期のロードマップを可視化し、ステークホルダーの関心を維持しながら進捗管理してください。
[出典:NIST SP 800‑137『Continuous Monitoring』2011年] [出典:CISA『SBOM Attributes』2024年] 重要キーワード・関連キーワードマトリクス
| キーワード | 説明 | 関連キーワード | 説明 |
|---|---|---|---|
| JSON Schema | データ構造の定義標準 | Draft‑2020‑12 | 最新スキーマ仕様 |
| JSON‑LD | リンク型データ形式 | Schema.org | 語彙定義共有標準 |
| OpenAPI 4.0 | API仕様記述標準 | Overlay Spec | 更新容易性強化 |
| SBOM | ソフト構成明細書 | NTIA Guidance | 必須フィールド定義 |
