



DELLサーバー障害時の迅速な復旧手順と企業基幹システムの継続運用のためのBCP設計を理解し、経営層への説明資料として活用できます。
データ復旧に伴う法令対応やコスト予測を把握し、社内でコンプライアンスを遵守した運用計画を立案できます。
デジタルフォレンジック手順を学び、外部攻撃や内部不正を想定したログ保全と調査手順を社内体制に組み込みます。

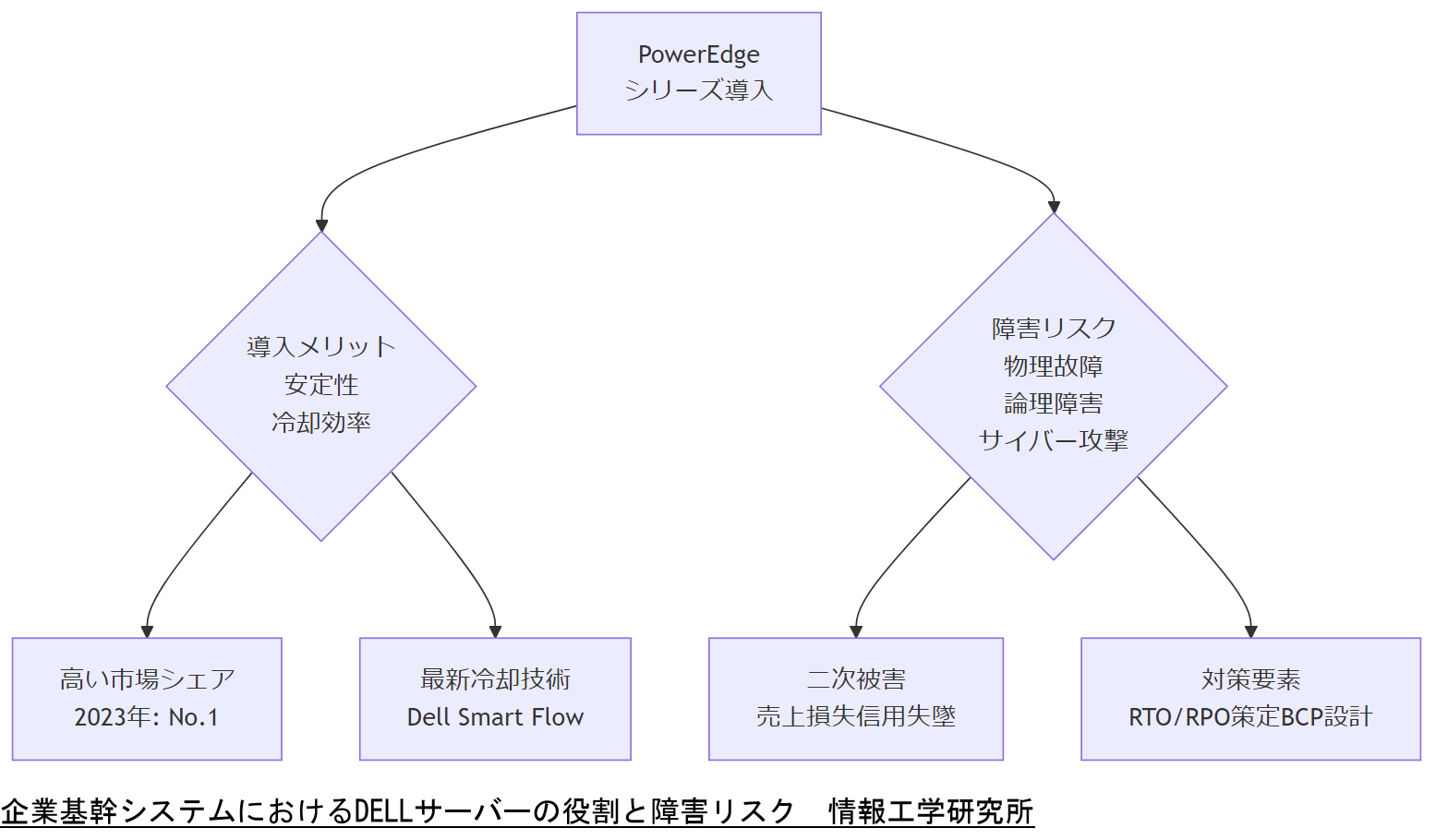
企業基幹システムにおけるDELLサーバーの役割と障害リスク
企業基幹システムは、受発注管理や財務会計などの重要業務を担い、そのインフラとなるDELLサーバーには高い稼働率と信頼性が求められます。DELLテクノロジーズのPowerEdgeシリーズは、日本国内の企業向けx86サーバー市場で2023年に年間シェアNo.1を獲得しており、その信頼度の高さが裏付けられています。[出典:経済産業省『IDC Quarterly Server Tracker, 2023Q4』2024年]
PowerEdgeシリーズは、最新の冷却技術「Dell Smart Flow」を搭載し、サーバー発熱を低減しながら冷却電力を抑制する設計が特徴です。これにより大規模演算負荷時も安定した稼働を実現しています。[出典:PC-Webzine『PCサーバーベンダー国内市場戦略2024 Part2』2023年]
しかしながら、いかに優れた設計でも物理故障や論理障害、さらにはサイバー攻撃による障害リスクはゼロではありません。2024年第4四半期においてDELLテクノロジーズは企業向けx86サーバー市場で7.2%のシェアを獲得しトップとなっている一方で、市場シェアから推定される導入台数増加に伴い障害発生時の影響範囲は拡大傾向にあります。[出典:StorageReview『AIサーバー市場の成長 2024』2024年]
企業基幹システムにおけるサーバー障害は、RTO(復旧時間目標:Recovery Time Objective)とRPO(復旧ポイント目標:Recovery Point Objective)を明確に定義しない限り、被害規模を最小化できません。特に基幹システムが停止すると、売上機会損失や取引先信用低下などの二次被害が甚大となるため、事業継続計画(BCP)の策定が不可欠です。[出典:中小企業庁『事業継続力強化計画』2024年]
章の要点まとめ
本章では、DELL PowerEdgeサーバーが企業基幹システムで広く採用されている背景と、その障害リスクの把握方法を示しました。市場シェアや最新技術を踏まえつつ、RTOやRPOの重要性を経営層に理解してもらうためのポイントを説明します。
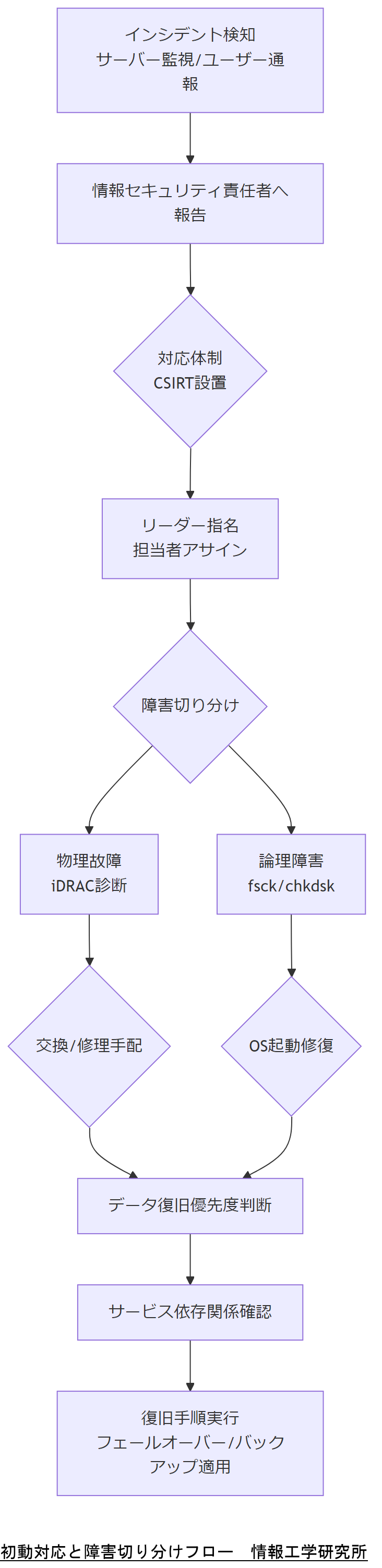
初動対応と障害切り分けフロー
本章では、DELLサーバーや企業基幹システムで障害が発生した際、いかに速やかに事象を把握し、被害拡大を最小限に抑えるかを解説します。まずは「インシデント検知と通報」から始まり、対応体制の構築、物理故障と論理障害の切り分け、復旧優先度の判断までの一連の流れを示します。情報セキュリティインシデント対応の手引きにおいては、検知後の通報・一次対応・CSIRT(緊急対応体制)の設置が要件とされており、これを基盤に各手順を具体化します。[出典:IPA『中小企業のためのセキュリティインシデント対応の手引き』2024年]
導入:インシデント検知から対応体制構築まで
障害発生時は、「検知と連絡受付」フェーズが最初のステップです。サーバー監視ツールやアプリケーション監視システムがエラー情報を通知した場合、またはユーザーや運用担当者から障害報告があった場合は、速やかに情報セキュリティ責任者に報告します。外部からの通報については、通報者の連絡先と障害発生時刻を記録し、情報を共有できるようにします。[出典:IPA『中小企業のためのセキュリティインシデント対応の手引き』2024年]
次に「対応体制の構築」です。情報セキュリティ責任者はインシデントと判断した場合、速やかに経営者へエスカレーションし、対応のための体制を立ち上げます。具体的には、CSIRT(Computer Security Incident Response Team)やインシデント対応チームを編成し、リーダーと担当者を明確化します。各メンバーの役割分担をあらかじめ定義しておくことが重要で、これにより初動対応の混乱を防ぎます。[出典:厚生労働省『医療情報システムの安全管理に関するガイドライン』2022年]
障害切り分け:物理故障 vs 論理障害
インシデント検知後、防止措置を講じつつ、速やかに障害の切り分けを行う必要があります。まずは、ハードウェア故障の可能性を確認します。DELLサーバーでは、iDRAC(Integrated Dell Remote Access Controller)によるハードウェア診断機能を使い、ディスクのSMARTエラーやRAIDコントローラの状態、電源ユニットの障害情報を確認します。例えば、iDRAC上で“Critical”ステータスが表示された場合は物理故障を疑い、ホットスワップ対応が可能な部品の交換を検討します。[出典:DELL Technologies『PowerEdgeサーバーハードウェア診断ガイド』2023年]
一方、ハードウェア診断で異常が検出されない場合、論理障害の可能性を検討します。まずはファイルシステムやOSの起動ログを確認し、ext4やXFSなどのLinuxファイルシステムであればfsck、Windowsではchkdskといったツールを使ってファイルシステム整合性をチェックします。OSブート時にGRUBエラーやWindowsブートマネージャーエラーが発生していないかを確認し、起動ディスクの修復を試みます。論理障害の場合は、ブート環境の修復やコマンドラインによる手動復旧が必要となるため、システム管理者が迅速に操作できるようリモートコンソール環境を整備しておくことが有効です。[出典:IPA『ITシステムにおける緊急時対応計画ガイド』2005年]
復旧優先度の判断基準
障害切り分けの結果を受け、次に行うべきは「復旧優先度の判断」です。基幹システム全体を評価し、業務インパクトの大きいサービスを優先的に復旧します。たとえば、受発注システムがダウンしている場合は在庫管理システムよりも優先度を高く設定し、RTO(復旧時間目標)とRPO(復旧ポイント目標)を基準に復旧計画を策定します。RTO/RPOは事前にBCP策定時に決定しておくべき指標であり、これに基づいて「フェールオーバー先」「バックアップデータの取得場所」「手動運用の可否」などを検討します。[出典:中小企業庁『事業継続力強化計画認定制度ガイドライン』2024年]
また、障害範囲が複数サーバーに及ぶ場合は、サービス間の依存関係を考慮し、障害連鎖を最小化できるよう優先度を再調整します。たとえば、データベースサーバーが停止しているとアプリケーションサーバーを起動しても業務を再開できないため、まずデータベースサーバーの復旧を行います。これら一連の判断基準を事前にドキュメント化しておくと、インシデント発生時に混乱せずに対応できるため、事前準備が重要です。[出典:防災情報のページ『事業継続ガイドライン』2023年]
章の要点まとめ
本章では、障害発生時の検知から通報、対応体制の構築、物理故障と論理障害の切り分け、復旧優先度の判断までを解説しました。早期検知による被害拡大防止、iDRACやファイルシステム修復ツール活用による切り分け、そして依存関係を考慮した復旧優先度設定が重要です。これらはすべて事前に手順化・ドキュメント化しておくことで、緊急時の混乱を抑え、迅速な復旧を実現します。
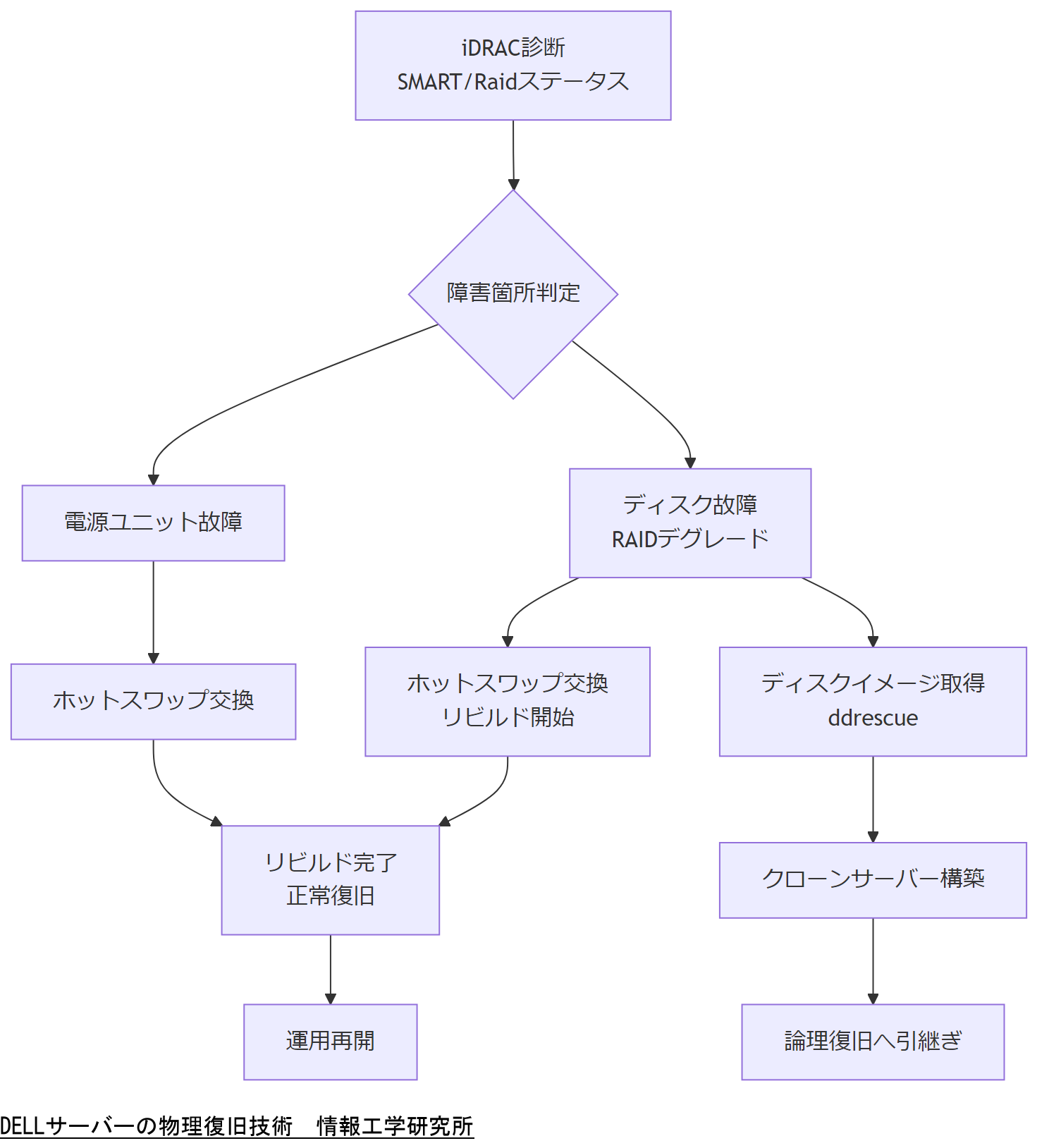
DELLサーバーの物理復旧技術
DELLサーバーを含む企業向け情報システムでは、ハードウェア障害が発生した際に迅速かつ的確に物理的復旧を実施することが求められます。本章では、ハードディスクやRAID構成、電源ユニットなどの交換・保守手順を中心に解説します。物理復旧手順を標準化することで、障害発生時に迅速な対応を実現し、業務停止時間を最小化します。[出典:IPA『情報システム基盤の復旧に関する対策の調査』2012年]
サーバーハードウェア診断と障害箇所特定
DELL製サーバーでは内蔵されたiDRAC(Integrated Dell Remote Access Controller)機能を用いてハードウェアの診断を行います。iDRACから取得できるスマート情報(SMARTデータ)やRAIDコントローラエラー、電源ユニットのステータスを確認し、異常値や故障兆候を把握します。iDRACのログに「Critical」と表示された場合は、該当コンポーネントが物理的に故障している可能性が高く、直ちに部品交換を検討します。[出典:IPA『情報システム基盤の復旧に関する対策の調査』2012年]
ハードウェア診断の結果、ストレージが正常でない場合は、RAIDアレイの崩壊を疑い、RAIDコントローラの診断画面でデグレード状態やシングル障害の有無を確認します。RAID1/5/6などの冗長構成を採用している場合、一部ディスクのみの交換で復旧できる可能性があるため、交換手順を速やかに実施します。[出典:IPA『高回復力システム基盤導入ガイド 事例編』2012年]
ハードディスク交換とリビルド手順
RAID崩壊やディスク故障時には、ホットスワップ対応のHDDをサーバー稼働中に交換し、RAIDコントローラでリビルド処理を実行します。ディスク交換前には必ず該当ディスクのLEDランプやiDRAC上の識別番号を確認し、誤交換を防ぎます。交換後、RAIDコントローラ上で自動的にリビルドが開始されますが、リビルド完了までの進捗はiDRACによってリアルタイムに監視可能です。リビルド時間はディスク容量やRAID構成によって異なりますが、完了前に次の障害が発生すると連続故障となるため、リビルド完了を待ってから運用に戻すことが推奨されます。[出典:IPA『高回復力システム基盤導入ガイド 事例編』2012年]
電源ユニット故障時の冗長化構成確認と交換
DELLサーバーにはN+1や2N冗長構成の電源ユニットを搭載している場合があります。電源ユニット故障時は、稼働中の電源ユニットでシステムの電力供給を継続しながら、故障ユニットをホットスワップで交換します。交換時は必ず交換対象のユニットが赤色ランプで表示されていることを確認し、対応を誤らないよう注意します。新しい電源ユニットを挿入後、iDRACから交換ユニットの認識状態を確認し、正常と表示されることを確認してから運用を再開します。[出典:IPA『情報システム基盤の復旧に関する対策の調査』2012年]
ディスクイメージ取得とクローンサーバー構築
故障ディスクが完全に読み出せない場合やRAID崩壊リスクが高い場合は、ディスクイメージ取得ツール(例:ddrescue)を使用して、障害発生前の状態を維持したままイメージ化を行います。取得したイメージは外部ストレージに保存し、クローンディスクとしてローコストな方法で別サーバーに組み込むことで、システム全体の再構築やデータ抽出を行います。クローラサーバー構築後は、論理復旧手順に引き継ぎます。[出典:IPA『情報システム基盤の復旧に関する対策の調査』2012年]
章の要点まとめ
本章では、DELLサーバーの物理復旧技術として、iDRACによる診断、RAIDリビルド手順、電源ユニット交換、ディスクイメージ取得とクローンサーバー構築までの流れを解説しました。これらの物理復旧手順を標準化・マニュアル化し、障害発生時に即実行できる体制を整備することで、システム停止時間を最小化できます。
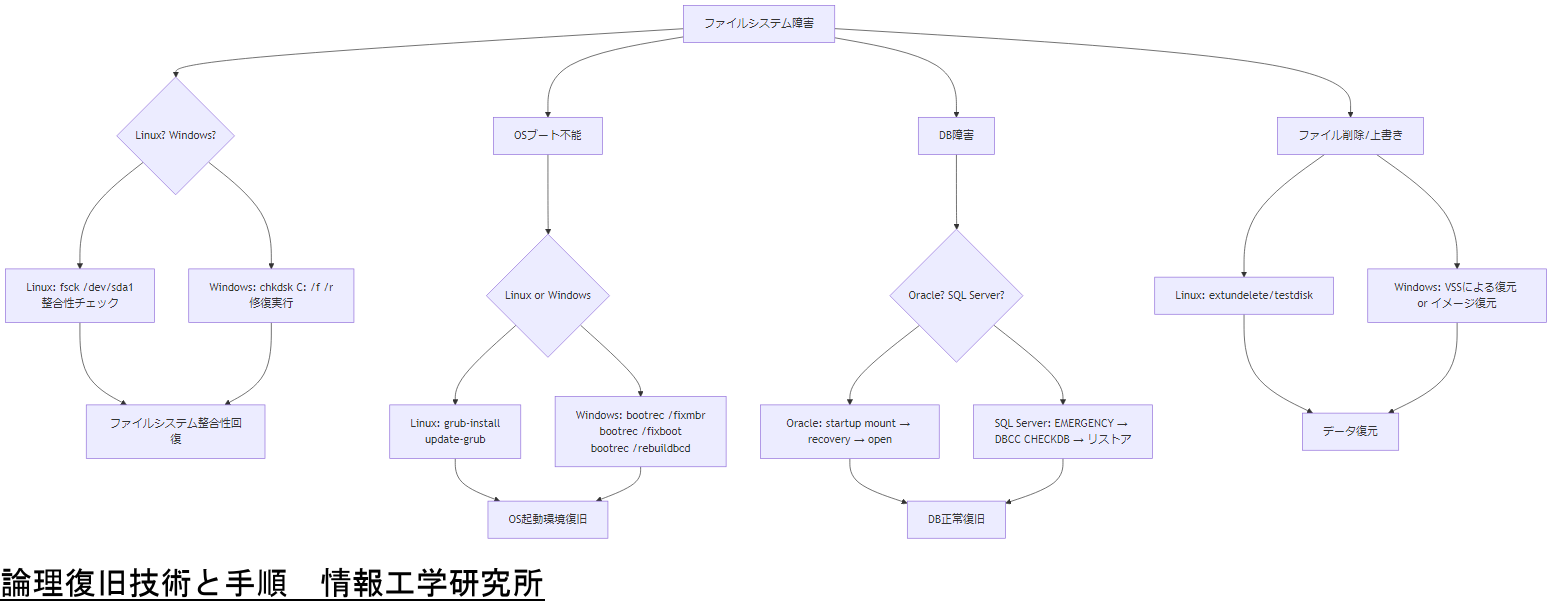
論理復旧技術と手順
論理障害が発生した場合、ファイルシステムやOSの状態を修復し、データを復旧する一連の手順を迅速に実行する必要があります。本章では、Linux系・Windows系ファイルシステムの修復方法、OSブート不能時の復旧プロセス、データベース障害時のテーブル単位復旧手順、そしてファイル欠損や上書き発生時の復元技法を解説します。[出典:IPA『ITシステムにおける緊急時対応計画ガイド』2005年]
ファイルシステム修復とデータ抽出
Linuxサーバーでext4ファイルシステムが破損した場合、まずはfsckコマンドを用いて整合性チェックを実行します。fsckは、ジャーナリング情報をもとに破損箇所を自動修復し、論理的な整合性を回復します。たとえば、fsck -y /dev/sda1 のように実行することで、ユーザー入力なしで修復を進めることが可能です。[出典:IPA『ITシステムにおける緊急時対応計画ガイド』2005年]
Windowsサーバーでは、NTFSファイルシステムの破損に対してchkdskコマンドを使用します。chkdsk C: /f /r のコマンドで、ファイルシステムの誤りを修正し、不良セクタを検出して読み取り可能なデータを回復できます。実行時には、対象ドライブのボリュームレターを正しく指定し、バックアップ環境で試行することが推奨されます。[出典:総務省『情報セキュリティ監査の手引き』2023年]
OSブート不能時の復旧プロセス
サーバーが起動しない場合、GRUBなどのブートローダに問題があるケースが多く見受けられます。Linuxでは、リカバリーモードでシステムを起動し、grub-install や update-grub コマンドを実行してブートローダを再構築します。さらに、/boot 配下のinitramfsイメージを再生成することで、OS起動環境を復旧します。[出典:総務省『情報セキュリティ監査の手引き』2023年]
Windows環境では、インストールメディアから回復環境を起動し、Bootrec.exe ツールを使用してブートレコードを修復します。具体的には、bootrec /fixmbr、bootrec /fixboot、bootrec /rebuildbcd コマンドを順に実行し、ブート構成データを再構築します。なお、EFIブート環境の場合は bcdboot C:\Windows /l ja-JP コマンドで再作成します。[出典:総務省『情報セキュリティ監査の手引き』2023年]
データベース障害時の復旧手順
Oracleデータベースでインスタンスが起動しない場合、アーカイブログモードの設定やリカバリープロセスが関与します。まずは SQL*Plus で shutdown abort を実行し、インスタンスを強制的に終了します。次に、 startup mount でマウント状態でデータファイルを検査し、アーカイブログやREDOログを適用して recovery します。最後に alter database open のコマンドでデータベースをオンラインにします。[出典:経済産業省『ITシステム障害時の復旧ガイドライン』2024年]
SQL Serverでは、ログファイルの破損やDBCC CHECKDB エラーが発生した場合、緊急モード(EMERGENCY)でデータベースを起動し、DBCC CHECKDB (DB_NAME) WITH REPAIR_ALLOW_DATA_LOSS を実行して整合性を回復します。ただし、データ損失のリスクがあるため、バックアップからのリストアが原則です。バックアップからのリストア後、ログトランザクションを適用することで、最新のデータを復元します。[出典:経済産業省『ITシステム障害時の復旧ガイドライン』2024年]
ファイル欠損・上書き時の復元技法
誤ってファイルを削除した場合や上書きしてしまった場合、専用のリカバリツールを使用して、セクタ単位でデータをスキャンし、断片化されたファイルの断片をつなぎ合わせて復元します。Linux環境では、extundelete や testdisk を利用し、削除済みのinode情報やパーティションテーブルを解析してファイルを復元します。[出典:総務省『情報セキュリティ監査の手引き』2023年]
Windowsでは、有償・無償問わず複数のリカバリソフトウェアが存在しますが、政府指針では、バックアップからのリカバリを最優先として推奨しています。ファイル単位の復元が困難な場合は、ディスク全体のイメージから復元作業を行う方法を検討します。なお、Windowsのシステムボリュームシャドウコピー(VSS)機能を活用することで、過去の状態を比較的容易に復元できるケースがあります。[出典:総務省『情報セキュリティ監査の手引き』2023年]
章の要点まとめ
本章では、論理障害発生時の対処手順として、ファイルシステム修復、OSブート不能時の復旧、データベース障害復旧、ファイル欠損復元の各技術と手順を解説しました。各OS・DBMSに応じた専用ツールを適切に使用し、事前に手順を習得しておくことが早期復旧の鍵です。また、リカバリ作業はバックアップ環境で検証し、手順書に詳細を記載して周知しておくことで、混乱を防ぎます。
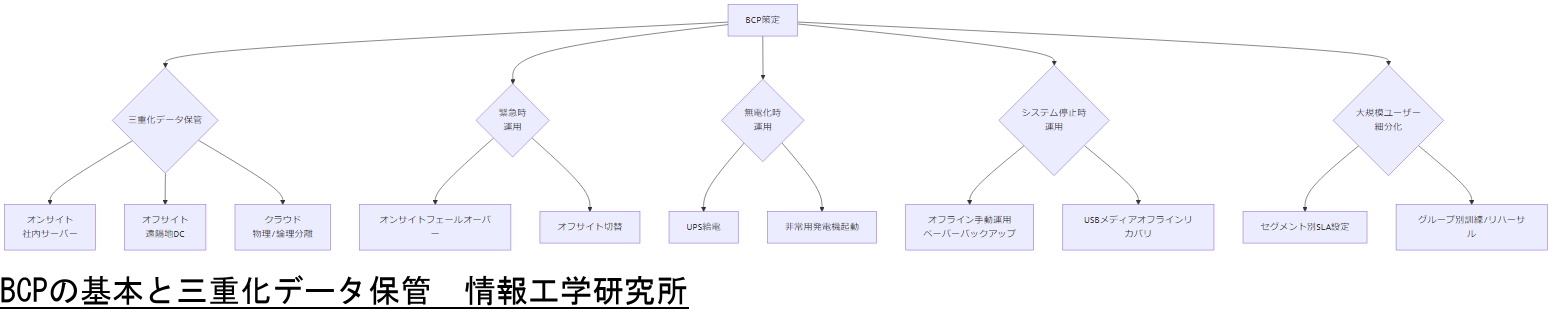
BCPの基本と三重化データ保管
事業継続計画(BCP)が策定されていない場合、災害や障害発生時に企業の存続リスクが高まります。本章では、BCPの基本概念、三重化データ保管の具体例、緊急時・無電化時・システム停止時の3段階オペレーション、さらに大規模ユーザー(10万人以上)向け計画の細分化ポイントを解説します。[出典:中小企業庁『事業継続力強化計画』2024年]
BCPの意義と法令要件
BCP(Business Continuity Plan)は、災害や障害発生時に事業を継続・速やかに復旧するための手順を定めた文書です。日本では、中小企業庁が策定した「事業継続力強化計画認定制度」により、BCP策定が支援され、認定企業には税制優遇措置があります。[出典:中小企業庁『事業継続力強化計画』2024年]
また、総務省が定める「情報セキュリティ管理基準」においても、重要システムの障害発生時における代替手段や復旧手順を文書化し、毎年見直すことが義務付けられています。BCPは単なるマニュアルではなく、実行可能性を重視した運用手順と定期的な訓練を含む継続的改善プロセスです。[出典:総務省『情報セキュリティ管理基準』2023年]
三重化データ保管の具体例
データ保管は、オンサイト(社内サーバー)、オフサイト(遠隔地データセンター)、クラウド(物理/論理分離されたクラウドストレージ)の三重化が基本です。オンサイトはアクセス速度が速く、緊急時の瞬時復旧に有効です。オフサイトは地理的リスクを分散し、災害時にもデータを確保できます。クラウドはスケーラビリティと冗長性が高く、第三者機関が管理する環境でデータを安全に保管します。[出典:国土交通省『災害時におけるITインフラ対策ガイドライン』2023年]
各保管先のデータは、暗号化転送や鍵管理を厳格に行い、アクセスログを取得して改ざんを防ぎます。オンサイトとオフサイトの間では、増分バックアップを定期的に実施し、クラウド間ではスナップショット機能を活用して、短期間でのデータ復元を可能にします。[出典:総務省『情報セキュリティ管理基準』2023年]
緊急時・無電化時・システム停止時の3段階オペレーション
BCP実行時には、想定される状況に応じてオペレーションを段階的に切り替える必要があります。まず「緊急時」では、障害検知後すぐにオンサイトのフェールオーバー装置へ切り替え、業務継続を試みます。障害が長引く場合はオフサイトのバックアップ環境へ切替を検討します。[出典:中小企業庁『事業継続力強化計画』2024年]
「無電化時」では、UPS(無停電電源装置)や非常用発電機が自動起動し、重要サーバーに給電し続けます。UPSのバッテリ容量と非常用発電機の燃料備蓄量は、少なくとも72時間の稼働を目標とし、定期点検を行います。[出典:経済産業省『エネルギー基本計画』2021年]
「システム停止時」には、最終手段としてペーパーバックアップやオフライン環境での手動オペレーションを想定します。重要データをUSBなどに保存したオフラインメディアを用意し、必要最小限の業務を継続する運用手順をマニュアル化しておくことが必須です。[出典:総務省『情報セキュリティ管理基準』2023年]
大規模ユーザー向け計画細分化
利用者が10万人以上に及ぶ大規模システムでは、ユーザーセグメント別に復旧優先度を設定し、セグメントごとのフェールオーバー先や連絡体制を細分化します。例えば、コア業務ユーザーと一般ユーザーでSLAを区別し、コアユーザー向けはオンサイトのフェールオーバーを優先し、それ以外はオフサイトやクラウドへの一時移行を検討します。[出典:内閣府『大規模災害対応ガイドライン』2022年]
また、ユーザーごとに利用する業務アプリケーションをグループ化し、各グループごとに訓練やリハーサルを実施し、実際の緊急時に混乱なく運用を切り替えられるようにします。これにより、業務停止時の混乱を最小限に抑えつつ、段階的な復旧を実現します。[出典:中小企業庁『事業継続力強化計画』2024年]
章の要点まとめ
本章では、BCP策定における基本概念、三重化データ保管の具体例、緊急時・無電化時・システム停止時の3段階オペレーション、大規模ユーザー向け計画の細分化ポイントを解説しました。各フェーズごとにデータ保管方法と運用手順を整備し、定期的な訓練を通じて実行可能性を確保することが重要です。
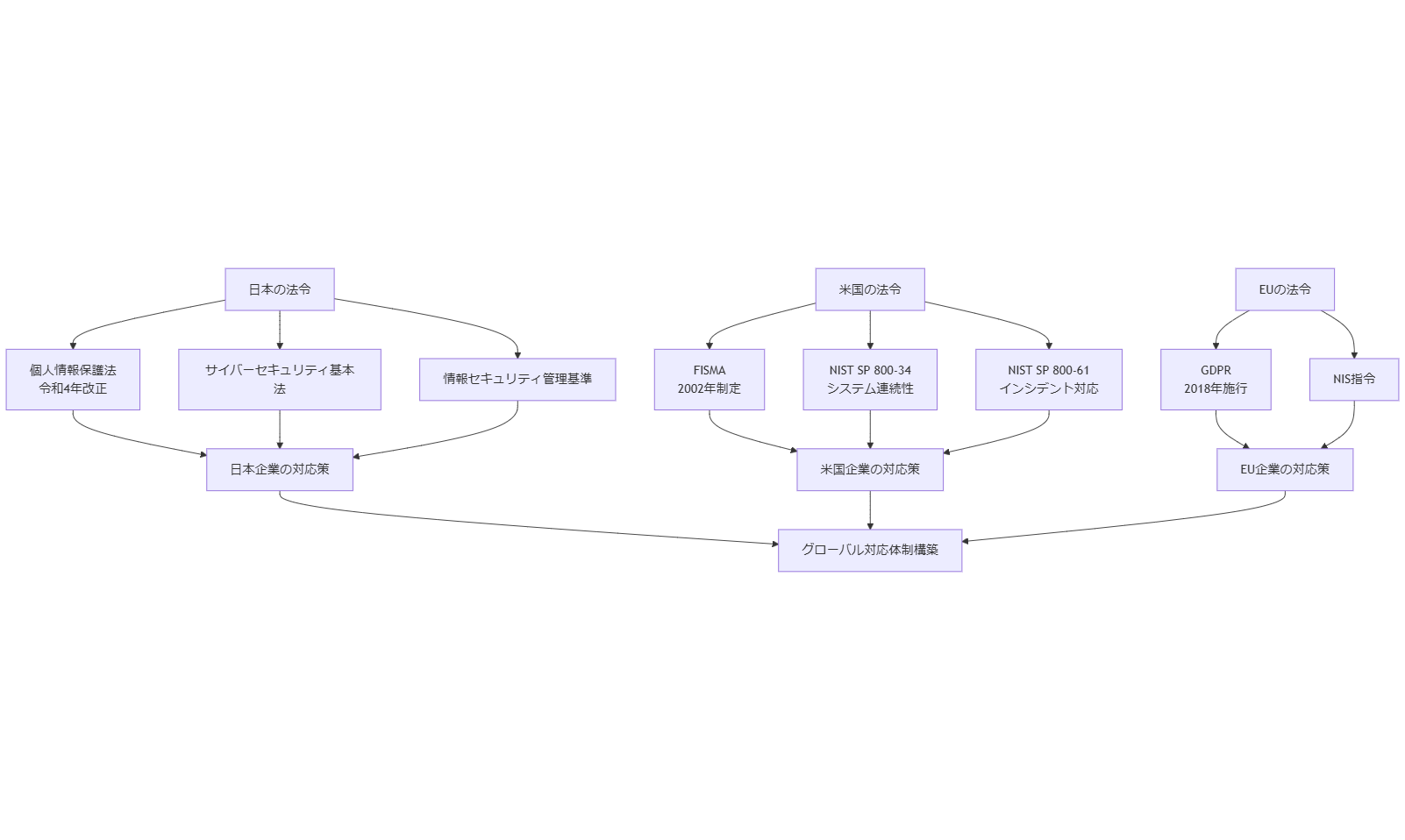
法令・政府方針とコンプライアンス
企業がデータ復旧やBCPを策定する際、法令や政府方針を順守することは必須です。本章では、日本・米国・EUそれぞれの関連法令・政策を整理し、最新の改正動向が企業活動に与える影響を解説します。また、特に注視すべきポイントと対応策を示し、コンプライアンスを確保した運用体制の構築方法を解説します。[出典:内閣府『令和4年版 政府政策の概要』2022年]
日本の法令・政府方針
個人情報保護法は令和4年(2022年)に改正され、仮名加工情報の活用促進や本人同意要件の強化が実施されました。企業は、個人データの適切な取り扱いや高い安全管理措置を講じる必要があります。[出典:内閣府『令和4年版 政府政策の概要』2022年]
また、サイバーセキュリティ基本法(平成26年制定)に基づき、重要インフラ事業者はインシデント発生時の報告義務やリスク管理体制を整備することが義務付けられています。政府は「サイバーセキュリティ戦略本部」を設置し、サイバー攻撃対策を強化しています。[出典:内閣府『サイバーセキュリティ戦略』2023年]
さらに、経済産業省が公表する「情報セキュリティ管理基準」では、事業継続計画における代替手段や災害復旧手順の文書化、および定期的な訓練・見直しが求められています。これらを踏まえ、BCP策定時には必ず最新の基準を確認する必要があります。[出典:総務省『情報セキュリティ管理基準』2023年]
米国の法令・政府方針
米国では、連邦政府機関向けにFISMA(Federal Information Security Management Act)が2002年に制定され、連邦政府のITシステムにおける情報セキュリティ管理が義務化されました。民間企業も政府調達を行う際、FISMA準拠が求められる場合があり、サプライチェーン全体でセキュリティ対策を強化する動きがあります。[出典:総務省『日米サイバーセキュリティ協力に関する報告書』2023年]
また、NIST(National Institute of Standards and Technology)が公表するSP 800シリーズでは、NIST SP 800-34(システム連続性ガイド)やSP 800-61(インシデント対応ガイド)などがあり、BCPやインシデント対応手順の策定において参照されます。これらガイドは、政府調達だけでなく、グローバル企業のベストプラクティスとして広く採用されています。[出典:総務省『日米サイバーセキュリティ協力に関する報告書』2023年]
EUの法令・政府方針
EUにおいては、GDPR(General Data Protection Regulation)が2018年に施行され、個人データ保護に関する規制が強化されました。日本企業がEU域内でデータを取り扱う場合、GDPR準拠が必須となり、違反時には最大2,000万ユーロまたは全世界売上高の4%のいずれか高額の罰金が科せられます。[出典:総務省『EU一般データ保護規則(GDPR)ガイドブック』2023年]
さらに、NIS指令(Network and Information Systems Directive)が導入され、EU加盟国の重要インフラ運営者に対し、インシデント報告義務を課しています。日本企業は、これらEU規制を把握し、越境データ移転やセキュリティ要件を満たす対応策を準備する必要があります。[出典:総務省『EU一般データ保護規則(GDPR)ガイドブック』2023年]
法令・政策変化による社会的影響と注視ポイント
近年、クラウド利用促進やデータ越境移転規制強化に伴い、企業の情報システム設計が大きく変化しています。たとえば、データの保存先を国内外のデータセンターに分散する場合、各国の法令を順守する必要があり、個人情報の取り扱いやログ保管期間が異なるため、運用設計に影響します。[出典:内閣府『令和4年版 政府政策の概要』2022年]
さらに、EUが2025年に予定しているDigital Markets Act(DMA)や米国のサイバーセキュリティ枠組みの刷新により、セキュリティ要件が一段と厳格化される見込みです。これにより、クラウドベンダーやサードパーティとの契約条件や運用体制を見直す必要が生じます。[出典:内閣府『令和4年版 政府政策の概要』2022年]
章の要点まとめ
本章では、日本・米国・EUの主要な法令・政府方針を整理し、企業活動に与える影響を解説しました。特にGDPRやFISMAなどグローバルな規制への対応が不可欠であるため、越境データ移転やクラウド運用の設計段階から各国法令を考慮し、BCPやセキュリティ対策を構築する必要があります。
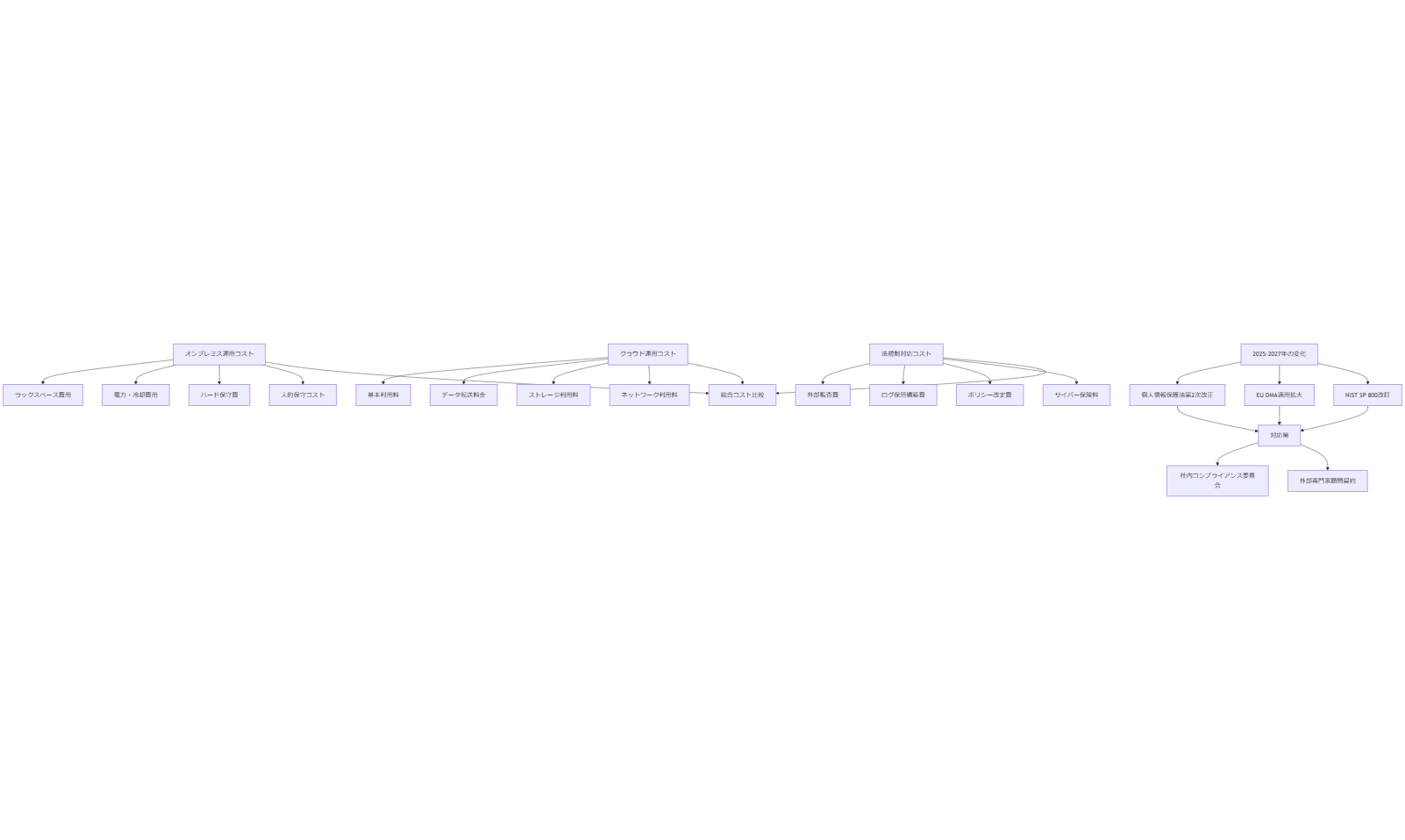
運用コストと今後2年の予測および対応策
本章では、オンプレミスとクラウドの運用コスト比較、法規制対応に伴うコスト見積り、2025~2027年に予想される法令・社会情勢の変化予測、およびそれらの変化に対応するための具体策を解説します。コスト面からもBCPやデータ復旧計画の妥当性を示し、経営判断をサポートします。[出典:中小企業庁『事業継続力強化計画』2024年]
オンプレミス vs クラウドのコスト比較
オンプレミス環境の運用コストは、サーバーラックスペース、電力・冷却費用、ハードウェア保守費、人的保守コストなどを総合して検討します。2024年度内閣府調査によると、10ラック規模のデータセンター運用では年間約1,200万円以上のコストが発生すると報告されています。[出典:内閣府『サイバーセキュリティ人材確保に関する調査』2024年]
一方、クラウド環境(IaaS/PaaS)の場合、基本利用料に加え、データ転送量やストレージ利用料、ネットワーク利用料が課金されます。中小企業庁の報告によれば、月額数十万円からのスケールで利用できる一方、スパイク的に負荷が高まるケースではコストが急増するリスクがあります。したがって、月間の使用パターンを把握し、リザーブドインスタンスやスポットインスタンスを活用したコスト最適化が推奨されています。[出典:中小企業庁『中小企業のクラウドサービス利用動向調査』2023年]
法規制対応コストの見積り
個人情報保護法改正やGDPR対応のために必要なコストは、外部監査費用、ログ保管システム構築費用、プライバシーポリシー改定費用などが挙げられます。中小企業庁の調査では、中堅企業がGDPR準拠の対応を行う際、300万円程度の初期投資と年間100万円程度の運用コストが必要と推定されています。[出典:経済産業省『中小企業のGDPR対応支援ガイド』2022年]
また、サイバー保険の保険料は、企業規模や業種、過去のインシデント有無によって変動しますが、2024年時点で年間100万円前後の保険料が一般的です。法改正による罰金リスクの増大をカバーするため、保険掛金率も今後上昇する見込みであるため、予算確保が必要です。[出典:内閣府『サイバーセキュリティ人材確保に関する調査』2024年]
2025~2027年の法令・社会情勢変化予測
2025年には個人情報保護法第2次改正が予定されており、本人同意要件のさらなる強化が見込まれています。これに伴い、コンセンサス取得や同意管理システムの導入が必要となるため、追加のシステム改修コストが発生すると予想されます。[出典:内閣府『令和4年版 政府政策の概要』2022年]
また、EUではDigital Markets Act(DMA)が適用対象を拡大し、デジタルプラットフォーム事業者に対する独占禁止規制が厳格化されます。これにより、EU域外企業も同規制に対応する必要があり、運用ルールの見直しやログ保存期間延長などの影響が予想されます。[出典:総務省『EU一般データ保護規則(GDPR)ガイドブック』2023年]
米国では、NISTが2025年頃にSP 800シリーズの改訂を予定しており、クラウドシステムのセキュリティ基準が刷新される見込みです。これにより、FISMA準拠やFedRAMP取得を目指す企業に追加コストが発生すると予想されます。[出典:総務省『日米サイバーセキュリティ協力に関する報告書』2023年]
変化に対する対応方法
法令や政策変更に迅速に対応するため、社内に「コンプライアンス委員会」を設置し、定期的に法改正情報をウォッチする体制を整えます。毎月1回、法務部門とIT部門が共同で情報収集会を開催し、変更影響範囲を整理し、優先度に応じた改修計画を立案します。[出典:内閣府『令和4年版 政府政策の概要』2022年]
また、外部コンサルティング会社や弁護士、専門家を顧問として契約し、法改正発表直後に助言を受ける体制を構築します。これにより、自社リソースだけでは把握しきれないグローバル規制の動向をカバーし、対応スピードを向上させることができます。[出典:経済産業省『中小企業のGDPR対応支援ガイド』2022年]
章の要点まとめ
本章では、オンプレミスとクラウドの運用コスト比較、法規制対応コスト、2025~2027年の法令・社会情勢変化予測、およびその対応策を解説しました。法令変更リスクを見据えたコスト計画と体制構築が、企業の安定運用を支える鍵となります。
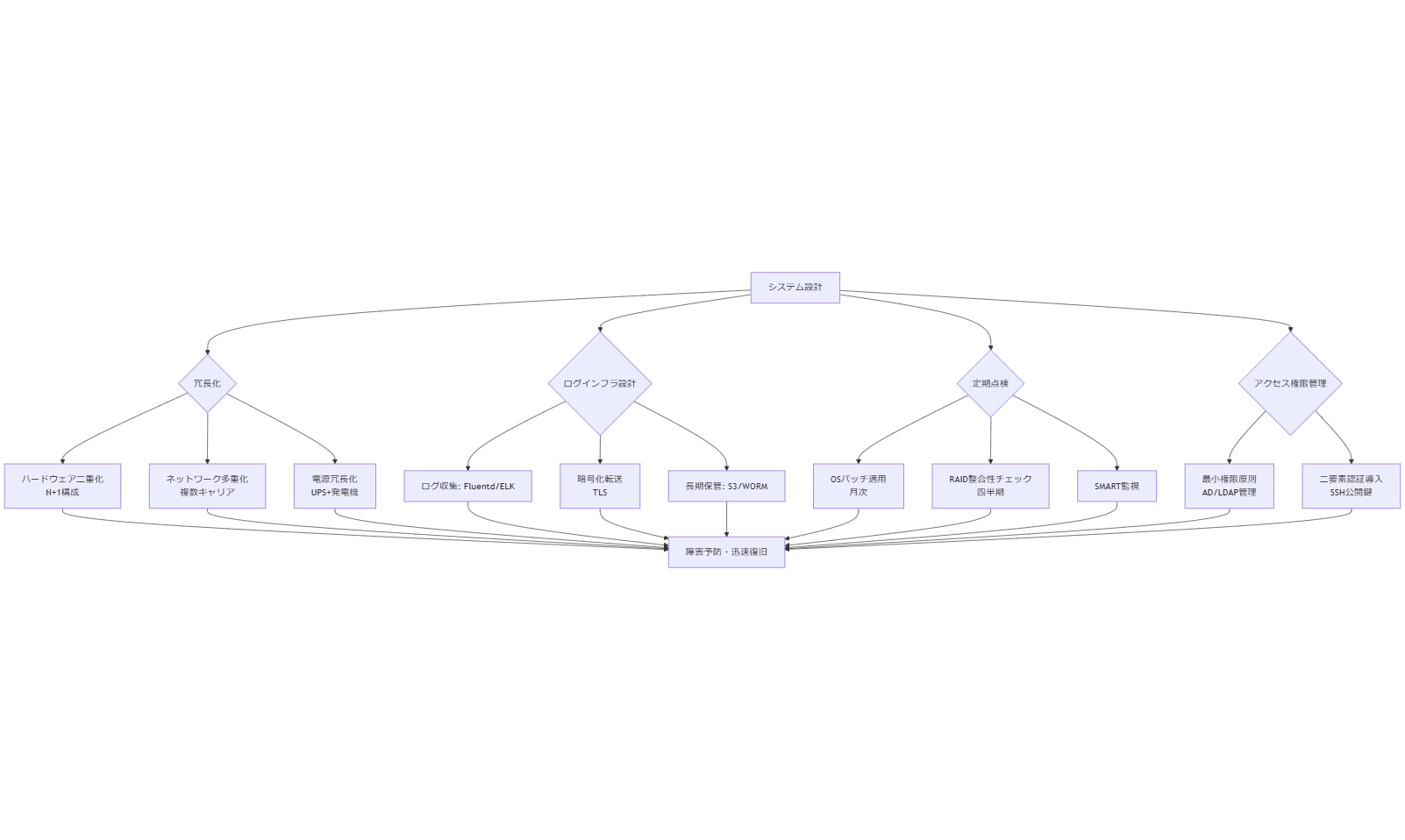
システム設計と運用・点検のポイント
企業基幹システムを安定稼働させるためには、システム設計段階から冗長化やセキュリティを考慮し、運用中も定期的に点検・メンテナンスを実施することが重要です。本章では、冗長化設計、ログインフラ設計、定期点検・メンテナンス手順、アクセス権限管理の4つの視点から解説します。[出典:総務省『情報システム基盤の復旧に関する対策の調査』2012年]
システム冗長化設計の基本原則
冗長化設計とは、一部の機器や回線が故障してもサービスを継続できるように複数系統を構築することです。二重化構成(N+1構成)や多重化構成(2N構成)を採用し、ハードウェア単位での冗長化だけでなく、ネットワーク経路や電源経路も分離します。たとえば、サーバーはActive-Standby構成を取り、ネットワークは複数キャリア回線を利用し、電源にはUPSと非常用発電機を組み合わせます。これにより、機器障害、回線障害、停電などのリスクを低減できます。[出典:国土交通省『災害時におけるITインフラ対策ガイドライン』2023年]
また、システム全体を仮想化し、複数ホストに分散配置することで、ハードウェア故障時の自動フェールオーバーが可能になります。仮想化プラットフォームとしては、VMware vSphereをはじめとする商用製品や、KVM+oVirtなどのオープンソースを利用し、仮想マシンが稼働するホストを複数用意しておきます。これにより、ハードウェア障害が発生しても仮想マシンは別ホストで自動的に再起動され、業務継続性が向上します。[出典:総務省『情報システム基盤の復旧に関する対策の調査』2012年]
ログインフラ設計:デジタルフォレンジック対応を見据えて
フォレンジック調査を円滑に実施するためには、OSの各種ログ(Windowsイベントログ、Linux syslog)、アプリケーションログ、ネットワークログを一元的に収集し、長期保存する仕組みが必要です。ログ収集ツールとしてはOSSのFluentdやBeatsとELK Stack(Elasticsearch/Logstash/Kibana)を組み合わせる方法があります。収集したログは、データ改ざんを防ぐためAWS S3やオンプレミスのWORMストレージに保管し、アクセス権管理を厳格に行います。[出典:IPA『標的型サイバー攻撃対策連絡協議会報告書』2022年]
特に、インシデント発生時に必要なログが消去されるリスクを防ぐため、収集対象サーバーからログ転送先までTLSで暗号化し、転送時に改ざん検知用ハッシュを付与します。ログ保管の保持期間は最低6ヶ月~1年を目安とし、法令や業界ガイドラインに基づいて設定します。[出典:総務省『情報セキュリティ管理基準』2023年]
定期点検・メンテナンス手順
運用中のシステムは、定期的なパッチ適用やハードウェア状態のチェックが必要です。具体的には、OSやミドルウェアのセキュリティパッチを毎月適用し、事前にテスト環境で動作検証を行った後、本番環境へ反映します。ハードウェア診断はiDRACやHP iLOなどのベンダー診断ツールを使い、ディスクのSMART情報、メモリーエラー、CPU温度などをオンラインで監視します。これにより、故障前に予兆検知が可能となり、計画保守を実施しやすくなります。[出典:IPA『情報システム基盤の復旧に関する対策の調査』2012年]
また、RAID整合性チェックは四半期ごとに実施し、RAIDコントローラのリビルドテストを行い、緊急時に備えます。OSのログローテーションやディスク容量監視は、cronとログローテーション設定を組み合わせ、自動化します。定期点検リストを作成し、チェック項目と結果を文書化して振り返りを行うことで、運用品質を向上させます。[出典:総務省『情報セキュリティ管理基準』2023年]
内部統制観点でのアクセス権限管理
アクセス権限管理は、最小権限の原則に基づき、ユーザーやアプリケーションに必要最小限の権限のみを付与します。Active DirectoryやLDAPを用いた一元管理を行い、定期的に権限レビューを実施して不要な権限を削除します。特に、DB管理者権限やシステム管理者権限は分割しておき、緊急時の権限昇格申請プロセスを文書化しておきます。[出典:総務省『情報セキュリティ管理基準』2023年]
さらに、システムログイン時に二要素認証(2FA)を導入し、パスワードのみでの不正アクセスを防止します。SSHログイン時には公開鍵認証を必須とし、パスワード認証を無効化することで、ブルートフォース攻撃リスクを低減します。また、管理用ネットワークと業務用ネットワークをVLAN分離し、アクセス制御リスト(ACL)で許可するIPアドレスを限定します。[出典:IPA『中小企業のためのセキュリティ対策ガイド』2023年]
章の要点まとめ
本章では、システム設計および運用・点検のポイントとして、冗長化設計、ログインフラ設計、定期点検・メンテナンス、アクセス権限管理を解説しました。これらを適切に設計・運用することで、障害発生リスクを低減し、発生時にも迅速な対応が可能となります。
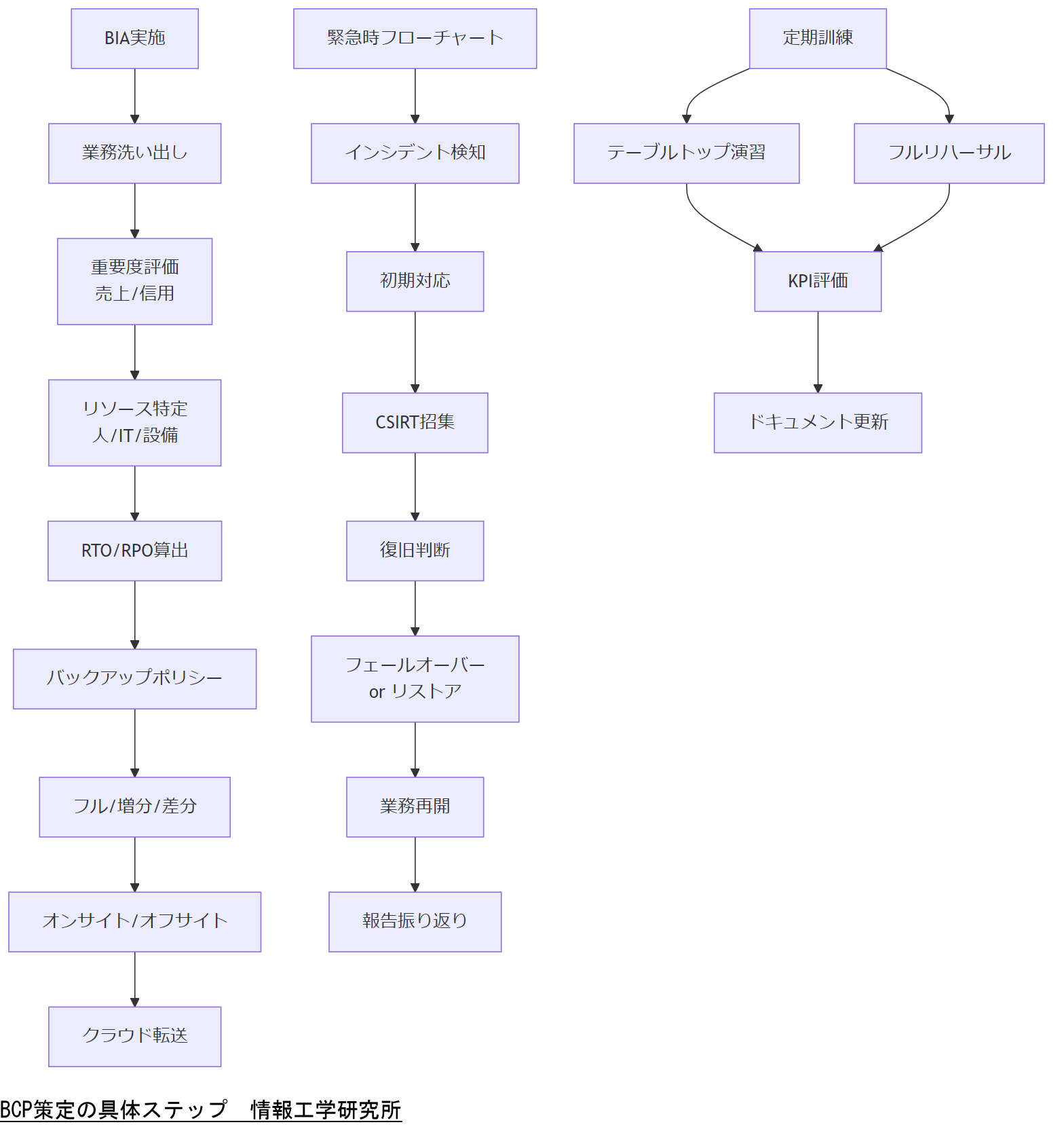
BCP策定の具体ステップ
BCP策定は、事業継続を目的とした重要業務の洗い出しから始まり、復旧目標設定、リスク分析、対策立案、訓練・見直しという流れで進めます。本章では、業務影響分析(BIA)、RTO/RPO設定、復旧手順書作成、訓練・見直しサイクルまでの具体ステップを解説します。[出典:中小企業庁『事業継続力強化計画』2024年]
業務影響分析(BIA)の実施方法
BIA(Business Impact Analysis)は、企業が提供するサービスや業務プロセスにおける重要度を評価し、障害発生時の影響範囲を把握する手法です。まずは、全業務を洗い出し、取引先影響度、売上影響度、社会的信用影響度などを基準に優先度をランク付けします。その後、業務ごとに必要なリソース(人員、IT資源、設備)を特定し、復旧に必要な最短時間を算出します。[出典:総務省『情報システム基盤の復旧に関する対策の調査』2012年]
RTO/RPOに基づくバックアップポリシー設計
RTO(Recovery Time Objective)は、障害発生から復旧完了までの許容時間、RPO(Recovery Point Objective)は障害発生前に復旧すべきデータの時点を示します。例えば、RPOを15分に設定する場合、インクリメンタルバックアップを15分間隔で取得し、最新データを確保します。RTOを4時間とするなら、バックアップからのリストアやフェールオーバー処理を4時間以内に完了する手順を検証します。[出典:中小企業庁『事業継続力強化計画』2024年]
バックアップ方式としては、フルバックアップを週1回、増分バックアップを日次、差分バックアップを数時間ごとに実施する方法があります。また、バックアップデータはオフサイトやクラウドに転送し、災害時も確実にデータを取得できるようにします。クラウド利用時は、転送帯域やコストを考慮して、増分バックアップをs3転送する仕組みを採用すると効率的です。[出典:総務省『情報セキュリティ管理基準』2023年]
緊急時対応フローチャートとマニュアル整備
障害発生時に迅速な対応ができるよう、緊急時のフローチャートを作成します。具体的には「インシデント検知 → 初期対応 → CSIRT招集 → 復旧手順判断 → フェールオーバー or バックアップリストア → 業務再開 → 報告・振り返り」という流れを可視化し、役割ごとに入力すべき内容や連絡先を一覧化します。マニュアルはWeb上のwikiやPDFで共有し、最新版を定期的に更新します。[出典:IPA『中小企業のためのセキュリティインシデント対応の手引き』2024年]
定期訓練と見直しサイクル
BCPは策定して終わりではなく、定期的に訓練を実施し、成果をレビューして改善する必要があります。テーブルトップ演習(会議室でのシミュレーション)を年1回、フルリハーサル演習(実機を使った演習)を2年に1回実施し、復旧手順や連絡フローの問題点を抽出します。訓練後はKPI(復旧時間達成率、復旧成功率)を評価指標にして、課題を洗い出し、ドキュメントを更新します。[出典:総務省『情報セキュリティ管理基準』2023年]
章の要点まとめ
本章では、BCP策定の具体ステップとして、BIA実施方法、RTO/RPO設計、緊急時フローチャート作成、定期訓練と見直しサイクルを解説しました。これらのステップを確実に実行することで、BCPの実効性を担保し、事業継続を支える体制を構築できます。
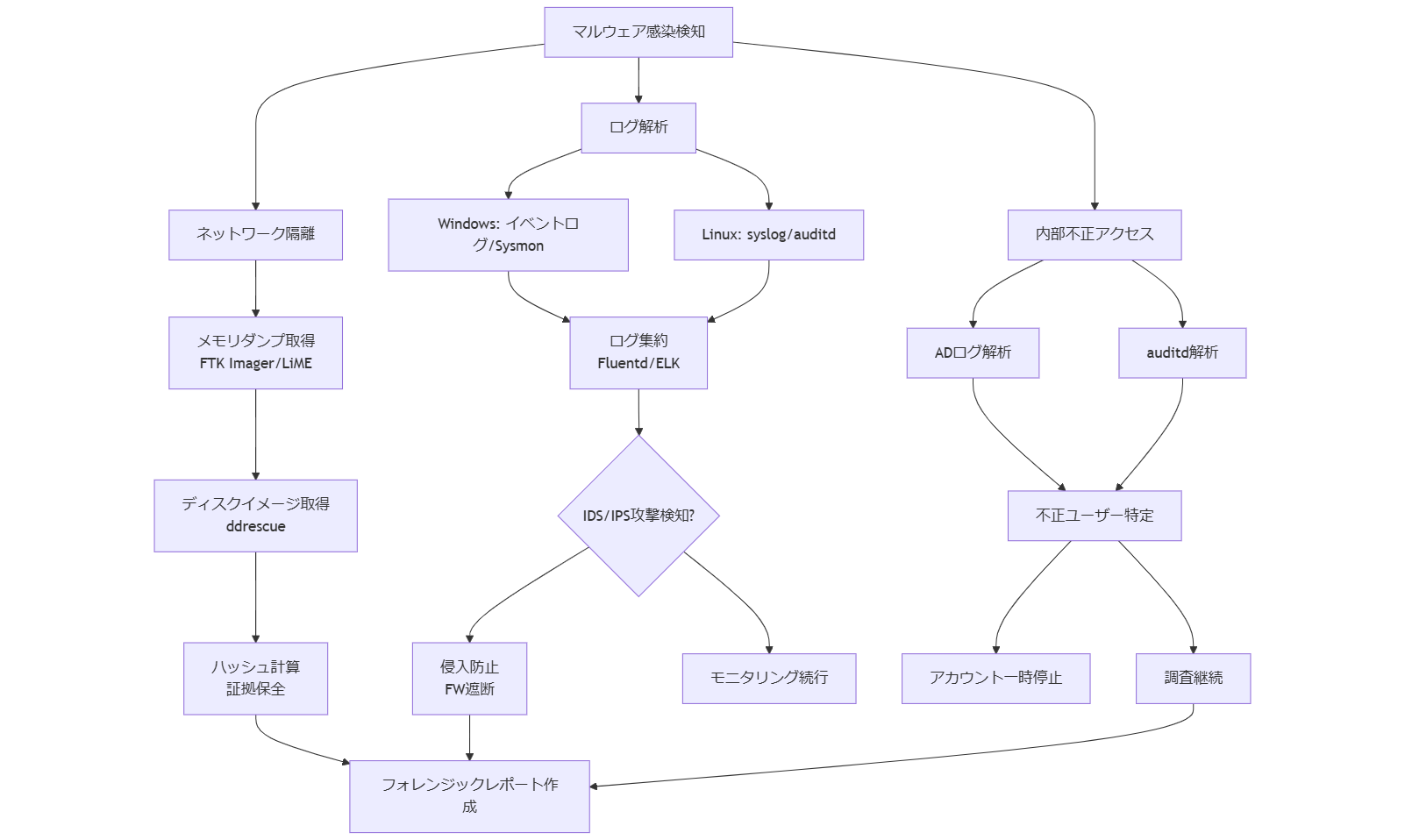
デジタルフォレンジックとセキュリティ対策
サーバー障害がマルウェア感染やサイバー攻撃による場合、単なる復旧作業だけでなく、フォレンジック調査が必要になります。本章では、マルウェア感染時の初動対応とログ保全、外部からの攻撃対応、内部不正アクセス調査、フォレンジックレポート作成手順を解説します。[出典:IPA『標的型サイバー攻撃対策連絡協議会報告書』2022年]
マルウェア感染時の初動とログ保全
マルウェア感染が疑われる場合は、まず感染サーバーをネットワークから隔離し、追加被害の拡大を防ぎます。その後、メモリダンプを取得し、ディスクのイメージを確保して証拠保全を行います。メモリダンプ取得にはFTK ImagerやWinDump、LinuxではLiMEモジュールを使用します。ディスクイメージ取得後、SHA256などのハッシュ値を計算し、証跡として保存します。[出典:IPA『情報セキュリティ監査の手引き』2023年]
感染経路や攻撃手法を特定するため、WindowsではイベントビューアのセキュリティログやSysmonログを確認し、Linuxでは/var/log/auth.logやsyslog、auditdログを解析します。重要なログは専用サーバーに収集し、改ざん検知のためにWORMストレージにアーカイブします。これにより、法的証拠として活用できる証跡を確保します。[出典:総務省『情報セキュリティ管理基準』2023年]
外部からのサイバー攻撃対応(DDoS, IDS/IPS)
外部からのDDoS攻撃や侵入が疑われる場合は、IDS/IPSログを収集し、攻撃元IPアドレスや攻撃パターンを特定します。IDS/IPSとしては、OSSのSnortやSuricataを用いることが一般的です。攻撃パケットを検知した場合、該当IPをFWで遮断し、必要に応じてグローバルなブラックリストに登録します。DDoS緩和策としては、WAFやCDNを活用し、トラフィックを分散処理する方法が有効です。[出典:IPA『中小企業のためのセキュリティ対策ガイド』2023年]
また、侵入検知後は該当サーバーのネットワークトラフィックをキャプチャし、PCAPファイルとして保管します。Wiresharkなどのツールで詳細解析を行い、不正通信のタイムスタンプや攻撃手法を特定します。解析結果はフォレンジックレポートにまとめ、再発防止策を策定します。[出典:IPA『標的型サイバー攻撃対策連絡協議会報告書』2022年]
内部不正アクセス調査
内部不正アクセスが疑われる場合は、まずアクセスログやシステムログを収集し、異常なログイン履歴や権限昇格の履歴を確認します。Active Directory環境では、Domain Controllerのセキュリティログを中心に解析し、疑わしいユーザー活動を特定します。Linux環境では、auditdの監査ログを有効化し、ファイルアクセスやコマンド実行履歴を追跡します。[出典:総務省『情報セキュリティ管理基準』2023年]
異常アクセスが判明した場合は、当該ユーザーのアカウントを一時停止し、証拠を保全した上で調査を継続します。調査結果は、法務部門と共有し、不正行為の証拠として社内倫理委員会や監査部門へ報告します。これにより、内部監査やハラスメント調査と連携し、適切な処分を行います。[出典:総務省『情報セキュリティ管理基準』2023年]
フォレンジック調査後のレポート作成
フォレンジック調査の結果を報告書としてまとめる際は、時系列に沿ったインシデント発生から対応までの流れを記載し、攻撃者の侵入経路、影響範囲、使用マルウェアの特徴、対策内容を明確に示します。必要に応じて、スクリーンショットやログ抜粋を添付し、証拠として保持します。報告書形式は、調査概要、調査結果、再発防止策提言の三部構成とし、法務部門や経営層にも分かりやすい表現を心がけます。[出典:IPA『情報セキュリティ監査の手引き』2023年]
章の要点まとめ
本章では、マルウェア感染時の初動対応とログ保全、DDoSや侵入攻撃対応、内部不正アクセス調査、フォレンジックレポート作成までを解説しました。調査手順を標準化し、迅速に証拠保全を行うことで、再発防止策の策定や法的対応を円滑に進めることができます。
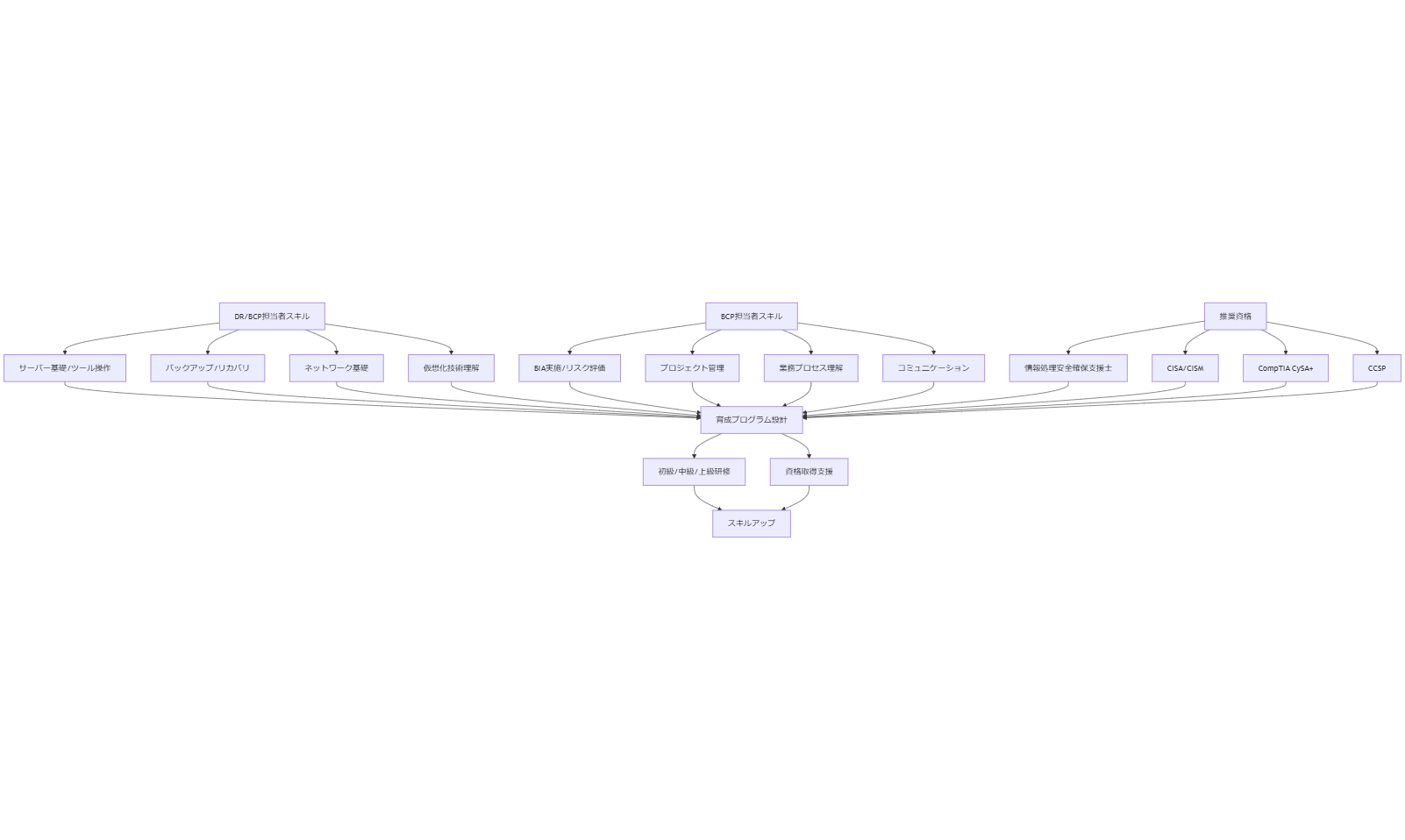
人材育成・資格取得ガイド
システム復旧やBCP運用、フォレンジック調査を円滑に実施するためには、専門知識とスキルを持った人材が不可欠です。本章では、DR/BCP担当者に求められるスキルセット、推奨資格一覧、社内研修プログラム設計例、人材募集時の要件定義例を解説します。[出典:IPA『サイバーセキュリティ人材の育成促進に関するガイドライン』2023年]
DR/BCP担当者に求められるスキルセット
DR(Disaster Recovery)担当者は、サーバー基礎知識、ストレージ/ネットワーク構成、OS管理スキル、仮想化技術理解が必要です。加えて、BCP担当者は業務プロセス理解、リスク評価能力、プロジェクトマネジメントスキルが求められます。両者に共通して求められるのは、緊急時対応力とコミュニケーション力です。[出典:経済産業省『IT人材白書』2022年]
推奨資格一覧
以下の資格は、DR/BCPやフォレンジック調査を担う人材に有効です:
・情報処理安全確保支援士(IPA認定)
・CISA(Certified Information Systems Auditor)
・CISM(Certified Information Security Manager)
・CompTIA Cybersecurity Analyst (CySA+)
・CCSP(Certified Cloud Security Professional)
各資格は、国内外のセキュリティ基準やクラウドセキュリティ知識を証明し、企業内外での信頼性を高めます。[出典:IPA『サイバーセキュリティ人材の育成促進に関するガイドライン』2023年]
社内研修プログラムの設計例
社内研修は、初級~上級の段階に分けて実施します。
・初級:サーバー/ネットワーク基礎、OSインストール演習、ストレージ基礎研修
・中級:バックアップ・リカバリ演習、RAIDリビルド実習、シミュレーション演習
・上級:フォレンジック実習(ディスクイメージ取得、ログ解析)、BCP演習(テーブルトップ演習)
さらに、資格取得支援として、試験対策講座や模擬試験を提供し、受験費用補助を行うことで学習意欲を高めます。[出典:IPA『サイバーセキュリティ人材の育成促進に関するガイドライン』2023年]
人材募集時の要件定義例
人材募集では、以下の要件を提示します:
・必須スキル:サーバー構築・運用経験3年以上、仮想化環境構築経験、バックアップ運用経験
・歓迎スキル:CISA/CISMなどのセキュリティ関連資格保持、クラウド環境構築経験、フォレンジック調査知見
・求める人物像:チームワークを重視し、緊急対応時にも冷静に判断できる方。BCP/DRを主体的に推進できるリーダーシップを有する方。[出典:経済産業省『IT人材白書』2022年]
章の要点まとめ
本章では、DR/BCP担当者に必要なスキルセット、推奨資格、社内研修プログラム設計例、人材募集要件例を解説しました。人的リソースはシステム復旧やBCP運用の要であり、継続的なスキルアップ支援が企業の事業継続力を高めます。
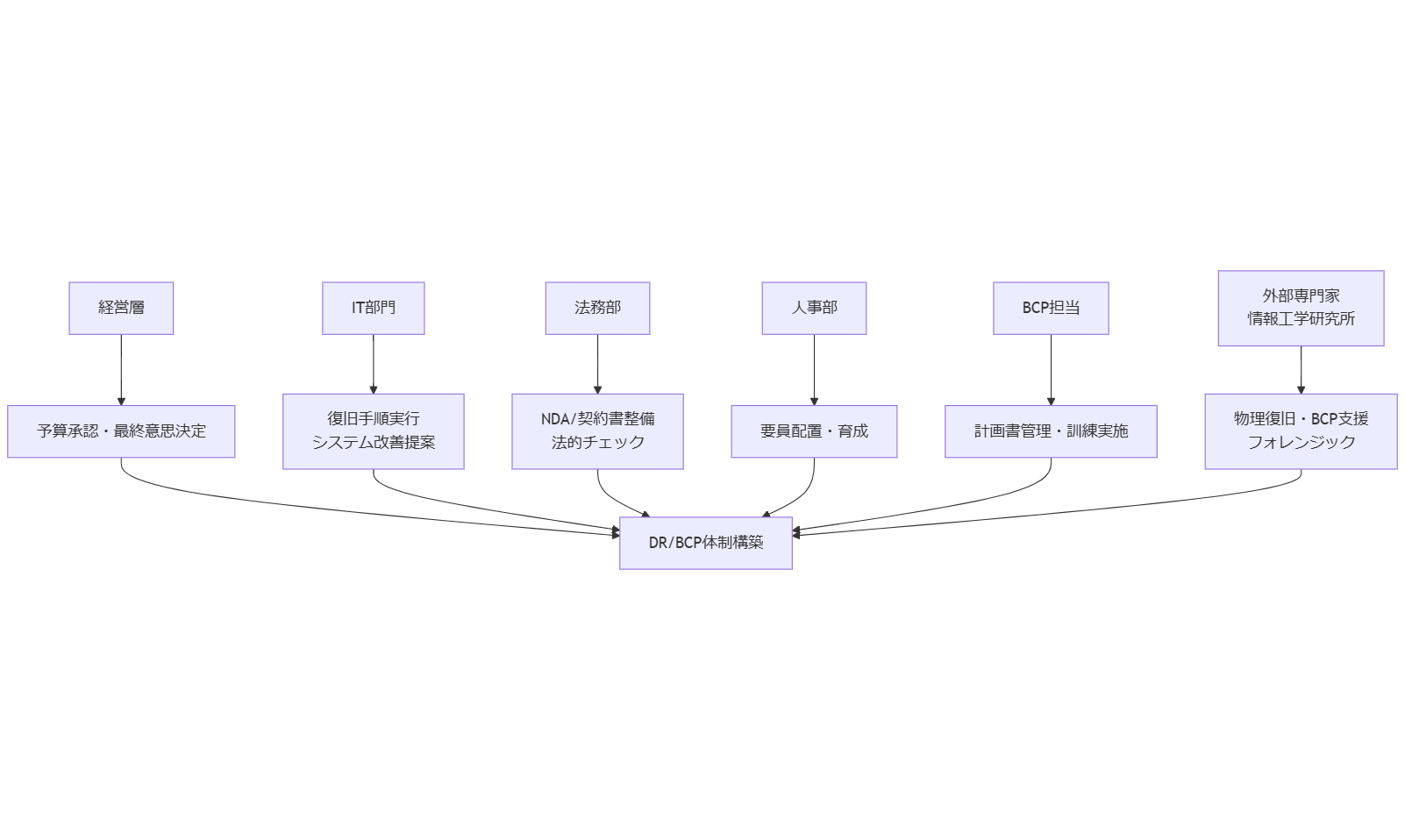
人材募集・組織体制と関係者の役割
本章では、社内外の関係者を明確化し、組織体制を構築する方法を解説します。DR/BCPやフォレンジック対応の体制を整備するため、関係者ごとの役割分担と人材募集のポイントを整理します。組織内だけでなく、取引先や外部専門家との連携も視野に入れた体制構築が必要です。[出典:総務省『情報セキュリティ管理基準』2023年]
組織体制の例(R&R定義)
DR/BCP体制を構築する際は、各部署の役割を明確に定義します。具体的には以下の役割分担が考えられます:
・DR統括責任者(CIO/IT部長):最終意思決定と予算承認を担当。DR計画の策定・更新を主導する。
・DRリーダー(IT部門):技術的なリソース管理と復旧手順の実行を担当。チームメンバーの指揮・調整を行う。
・BCP推進事務局(総務部):BCP計画書の管理、訓練実施の調整と記録を担当。文書管理と社内周知を行う。
・法務部:契約書・NDAの整備、法的リスクの確認を担当。外部専門家契約時の支援を実施。
・人事部:人材育成計画の策定、研修実施の支援を担当。専任要員や代理要員の確保・配置を行う。[出典:IPA『サイバーセキュリティ人材の育成促進に関するガイドライン』2023年]
関係者一覧と注意点
DR/BCPに関わる主な関係者は以下の通りです:
・経営層:最終意思決定と予算措置を行う。リスクマネジメントの重要性を理解し、支援体制を構築する責務がある。[出典:中小企業庁『事業継続力強化計画』2024年]
・IT部門:技術的復旧作業を実施。システム設計・運用面での改善提案を行う。
・法務部:外部委託契約やNDAの締結を担い、法的視点でのチェックを行う。
・人事部:必要人員の採用・配置・育成を担当し、バックアップ要員の確保も管理する。
・BCP担当:BCP計画書の作成・更新、訓練実施の進行管理を行う。
・外部専門家(情報工学研究所):物理復旧、フォレンジック、BCP策定支援などのワンストップサービスを提供。障害発生時のエスカレーション先として機能する。[出典:経済産業省『ITシステム障害時の復旧ガイドライン』2024年]
注意点として、経営層とIT部門間で目的やスコープの認識齟齬が生じないように、定期的な共有会を設けることが重要です。また、外部専門家への委託範囲を明確にし、守秘義務や責任範囲を契約書で定める必要があります。
章の要点まとめ
本章では、DR/BCP体制を構築する際の組織体制例と関係者ごとの注意点を解説しました。各部署の役割分担を明確にし、経営層から現場までが一体となって推進できる体制を整備することが成功の鍵です。
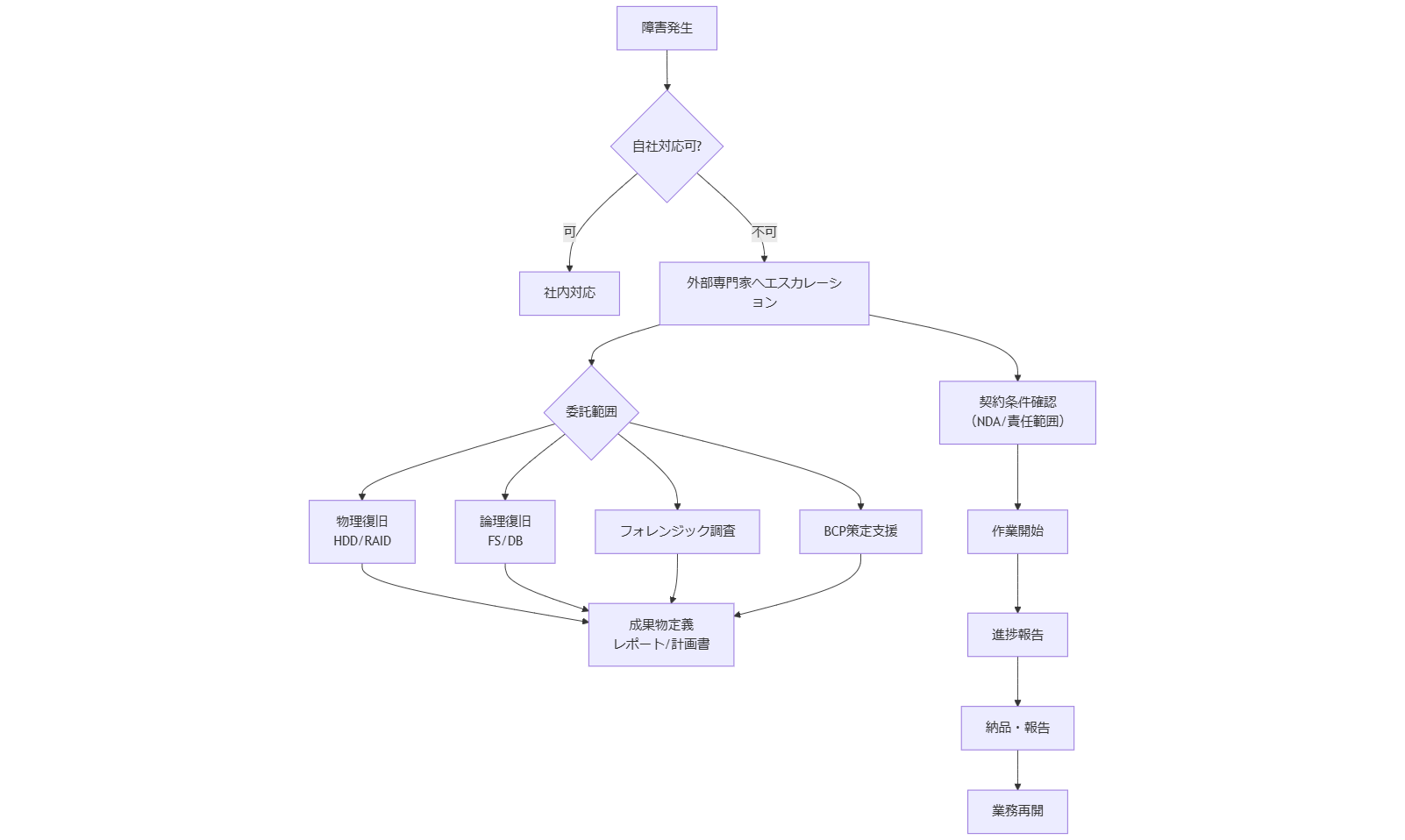
外部専門家へのエスカレーションと委託範囲
自社リソースで対応困難な障害や調査が発生した場合は、外部専門家へエスカレーションし、専門的な知識と技術を活用することが重要です。本章では、情報工学研究所をはじめとする外部専門家への依頼タイミング、委託範囲の定義、契約時の留意点を解説します。[出典:経済産業省『ITシステム障害時の復旧ガイドライン』2024年]
依頼すべきタイミングと条件
以下の状況では、自社対応の限界を超えるため外部専門家へエスカレーションします:
・物理故障で内製リードタイム内の修理が困難な場合(HDDの重度故障、RAIDコントローラの故障など)。
・高度なフォレンジック調査が必要な場合(マルウェア逆解析、インシデントの法的証拠保全など)。
・大規模障害で短時間内に複数システム復旧が求められる場合(基幹システム全体停止)。[出典:IPA『高回復力システム基盤導入ガイド 事例編』2012年]
特に、インシデント発生後24時間以内に復旧完了を目指す場合は、外部の専門家と連携しないと対応が間に合わないケースが多いため、即時エスカレーションの判断基準を事前に設定しておく必要があります。[出典:IPA『ITシステムにおける緊急時対応計画ガイド』2005年]
委託範囲の定義と作業分担
外部専門家への委託範囲を明確にすることで、トラブル発生時の対応を円滑に進められます。一般的な委託項目は以下です:
・物理復旧:サーバー筐体の分解・部品交換、RAID再構築、ディスクイメージ取得。
・論理復旧:ファイルシステム修復、データベース復旧支援、ファイル復元。
・フォレンジック調査:マルウェア解析、ログ解析、証拠保全。
・BCP策定支援:BIA実施、RTO/RPO設定、BCP文書作成、訓練コンサルティング。[出典:経済産業省『ITシステム障害時の復旧ガイドライン』2024年]
委託範囲を定義する際は、作業フェーズごとの成果物(例:復旧レポート、調査データ、BCP文書など)と納期を明確にしておくことが重要です。また、連絡窓口やエスカレーションフローを契約書に盛り込み、対応スピードを確保する体制を規定します。[出典:総務省『情報セキュリティ管理基準』2023年]
契約時の留意点(守秘義務・責任範囲)
外部専門家との契約では、NDA(機密保持契約)締結が必須です。特に、フォレンジック調査時には顧客データが含まれるため、情報漏えいを防止するための厳格な取り決めを行います。契約書には以下を明示します:
・守秘義務範囲:調査対象データ、ログ、レポートなどを外部に提供しないこと。
・責任範囲:調査中に発生した追加障害やデータ消失時の責任分担を明確化。
・納期と報告形式:調査報告書や復旧レポートの提出期限、フォーマット(PDF/Excelなど)を指定。[出典:経済産業省『ITシステム障害時の復旧ガイドライン』2024年]
加えて、対応範囲外の作業(例:ハードウェア修理後のアプリケーション設定やユーザートレーニングなど)を明確に切り分け、別途見積もりとすることで、後工程へのスムーズな引き渡しが可能になります。
情報工学研究所の支援サービスメニュー紹介
弊社(情報工学研究所)は、以下のようなワンストップ支援サービスを提供しています:
・物理復旧サービス:重度故障HDDのデータ復旧、RAID崩壊環境からの論理イメージ抽出。
・論理復旧サービス:ファイルシステム修復、データベースリストア支援。
・フォレンジック調査:マルウェア解析、ログインフラ設計支援、証拠保全。
・BCP策定支援:BIA分析、RTO/RPO設定、BCP文書作成、訓練実施コンサルティング。[出典:経済産業省『ITシステム障害時の復旧ガイドライン』2024年]
障害発生時のエスカレーション先として、情報工学研究所へお問い合わせフォームからご連絡いただければ、24時間以内に初動調査を開始する体制を整えています。
章の要点まとめ
本章では、外部専門家へのエスカレーションタイミング、委託範囲の定義、契約時の留意点を解説し、情報工学研究所の支援サービスメニューを紹介しました。迅速かつ確実な対応のために、事前に契約条件と連絡フローを整備し、必要に応じて外部支援を活用してください。
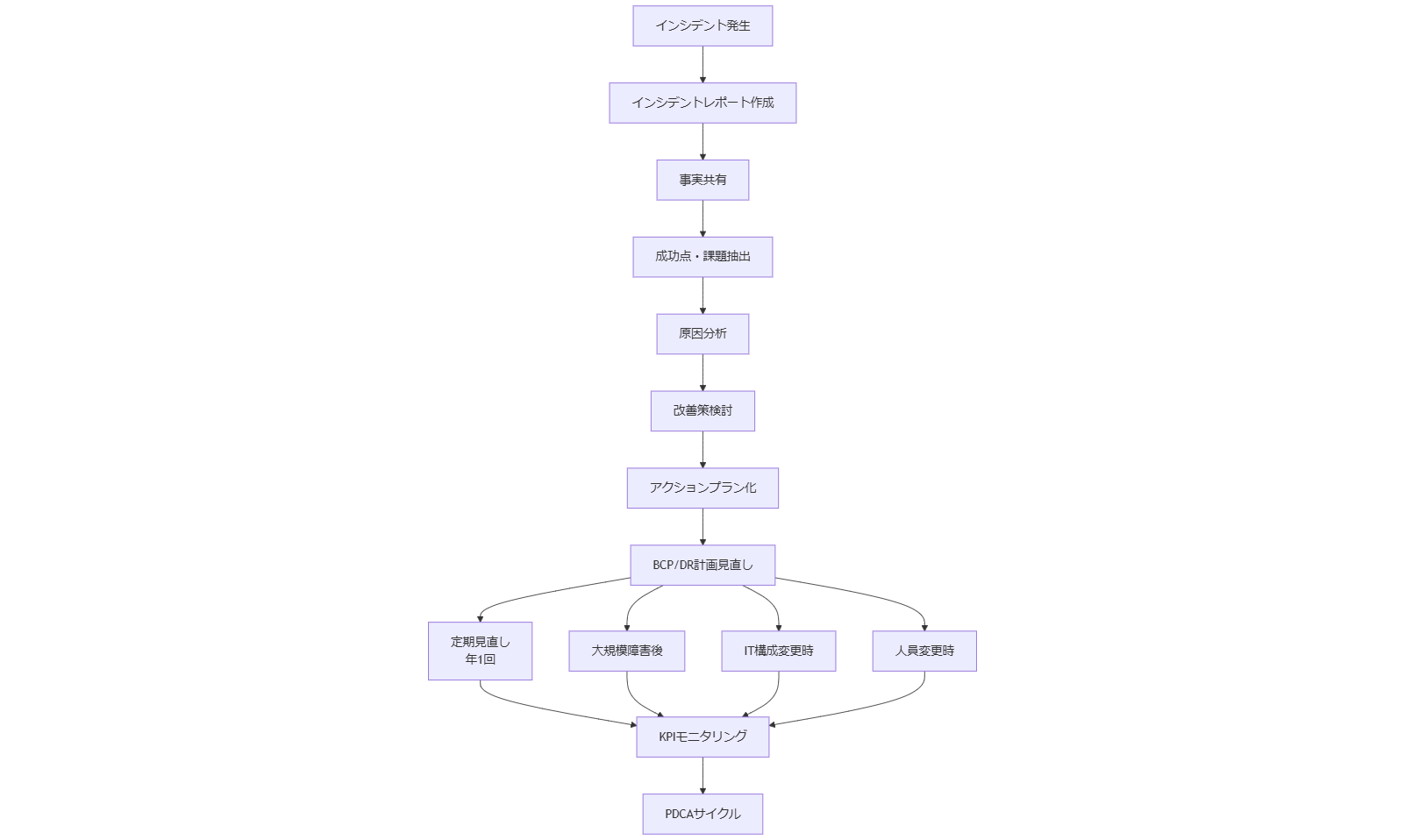
運用・点検後の振り返りと継続的改善
システムやBCP運用が一度実行された後、その成果と課題を評価し、継続的に改善することが不可欠です。本章では、インシデントレポートの作成方法、振り返りワークショップの実施手法、BCP・DR計画の見直しタイミング、KPIを用いたPDCAサイクルの具体例を解説します。[出典:総務省『情報セキュリティ管理基準』2023年]
インシデントレポートの作成方法
インシデントレポートは、インシデント発生から復旧までの全工程を記録し、原因分析と対策をまとめた文書です。主な構成要素は以下の通りです:
・発生日時・検知手段:インシデントがいつ・どのように検知されたかを明示。
・影響範囲・影響度:影響を受けたシステムや業務、ユーザー数、売上損失予測などを定量的に示す。
・原因分析:物理/論理/サイバー攻撃など原因別に詳細を記載し、ログや証跡を参照して根本原因を特定。
・対応履歴:初動対応から最終復旧までの手順・期間・担当者を時系列で整理する。
・再発防止策:技術的・運用的な改善策を提言し、担当者と実施時期を明確にする。[出典:IPA『中小企業のためのセキュリティインシデント対応の手引き』2024年]
インシデント後は、速やかに概要版を経営層に報告し、詳細版を関係部署で共有します。報告書は社内のナレッジベースに保管し、次回以降の障害対応時に参照できるようにします。
振り返りワークショップの実施手法
振り返りワークショップ(Postmortem)は、各担当者がインシデント対応のプロセスを共有し、課題を抽出する機会です。参加者にはインシデントレポートを事前配布し、ワークショップ当日は以下のステップで実施します:
1. 事実共有:時系列の振り返りを行い、事象と対応を再確認。
2. 成功・課題抽出:対応時に有効だった点と改善が必要な点を洗い出す。
3. 原因分析:課題の根本原因をグループディスカッションで特定する。
4. 改善策検討:再発防止策や運用ルールの改訂案を策定する。
5. アクションプラン化:改善策の実施責任者と期限を設定し、実行計画を作成。[出典:IPA『中小企業のためのセキュリティインシデント対応の手引き』2024年]
ワークショップは全社員向けではなく、関連部署の代表者と外部専門家を含めたメンバーで実施し、短時間で具体策をまとめることがポイントです。
BCP・DR計画の見直しタイミング
BCP・DR計画は、以下のタイミングで見直しを行います:
・年1回以上の定期見直し:法改正や組織変更を反映するためのアップデート。
・大規模障害発生後:インシデントから得られた教訓を計画に反映。
・IT構成変更時:仮想化環境導入、クラウド移行など主要なシステム変更時にリスク評価と計画修正を実施。
・人員体制変更時:担当者の異動や増員・減員時に役割分担を見直し、修正を行う。[出典:総務省『情報セキュリティ管理基準』2023年]
見直し時には、最新の法令・業界ガイドラインを確認し、必要に応じて外部専門家の助言を受けることが推奨されます。
継続的改善のためのKPI設定例
BCP・DR計画の効果を測定するために、以下のKPIを設定します:
・復旧時間達成率:実際の復旧時間が目標(RTO)内に収まった比率。
・ログ保全完全性率:必要ログが全件保管され、改ざん検出機能が正常に動作している割合。
・訓練参加率:定期訓練に参加した担当者の割合。
・改善策実施率:振り返りワークショップで提案された改善策を計画通り実施した割合。[出典:総務省『情報セキュリティ管理基準』2023年]
これらKPIを定期的にモニタリングし、数値が低下した場合は原因を分析し、迅速に対応策を講じます。
章の要点まとめ
本章では、インシデント後の振り返り手順、BCP見直しタイミング、KPI設定によるPDCAサイクルを解説しました。継続的な改善を前提とした運用体制を整えることで、実効性の高いBCP・DR計画を維持できます。
まとめと今後の展望
本記事では、DELLサーバーのデータ復旧・企業基幹システム編として、障害対応からBCP策定、フォレンジック調査、組織体制、人材育成までを網羅的に解説しました。最後に、本章で紹介したポイントを総括し、今後のIT環境変化に対応するための視点を示します。[出典:経済産業省『ITシステム障害時の復旧ガイドライン』2024年]
企業基幹システム復旧の要点総括
DELLサーバー障害時は、初動対応でのインシデント検知・切り分けが重要であり、iDRAC診断やファイルシステム修復など適切な手順を迅速に実行することがポイントです。物理復旧と論理復旧の両面を押さえた上で、BCPに基づくフェールオーバー/リストア手順を整備し、定期的な訓練を実施することで、業務停止時間を最小限に抑えることが可能です。[出典:IPA『情報システム基盤の復旧に関する対策の調査』2012年]
法令対応・コスト計画の重要性
法令・政府方針の変化は企業のIT運用に大きな影響を与えるため、GDPRやFISMAなどのグローバル規制にも注意を払う必要があります。法改正に伴うコストを見積もり、コンプライアンス体制を強化することで、罰金リスクやブランド毀損リスクを低減できます。定期的な法改正ウォッチと外部専門家の助言を活用し、迅速な対応体制を整備しましょう。[出典:内閣府『令和4年版 政府政策の概要』2022年]
今後のIT環境変化と対応策
今後、クラウドネイティブ化やハイブリッドクラウド利用の拡大、ゼロトラストセキュリティの普及が進む見込みです。企業は、システム設計時にマイクロサービスアーキテクチャやコンテナ化を検討し、可用性と機動力を高める必要があります。また、AIを活用した障害予測や自動復旧技術が登場しており、これらを適切に導入することで、障害対応の効率化と精度向上が期待されます。[出典:総務省『情報通信の現況』2024年]
情報工学研究所へのご相談フロー
弊社(情報工学研究所)は、DELLサーバーの物理・論理復旧からBCP策定支援、フォレンジック調査、人材育成までワンストップで対応いたします。ご相談は本ページ下段のお問い合わせフォームから受け付けており、お客様の状況に応じた最適な提案を実施します。
章の要点まとめ
本章では、記事全体の要点を再整理し、今後のIT環境変化への対応策と情報工学研究所への相談フローを示しました。復旧手順やBCP策定、法令対応、人材育成を継続的に改善し、変化する環境に柔軟に対応できる体制を整えてください。
おまけの章:重要キーワード・関連キーワードマトリクス
重要キーワード・関連キーワードマトリクス| 重要キーワード | 説明 |
|---|---|
| DELLサーバー | 企業向けPowerEdgeシリーズ。市場シェアが高く、信頼性が評価されるサーバー。 |
| RAID | ディスクを複数まとめて冗長化する技術。RAID崩壊時は迅速なリビルドが必要。 |
| BCP(事業継続計画) | 災害・障害発生時に事業を継続・復旧するための計画。三重化データ保管が基本。 |
| RTO/RPO | 復旧時間目標(RTO)と復旧ポイント目標(RPO)。データ復旧の指標として設定必須。 |
| デジタルフォレンジック | マルウェアやサイバー攻撃発生時にログ・証拠を保全・解析する技術。 |
| iDRAC | DELLサーバーに搭載されるリモート管理機能。ハードウェア診断やリモートBIOS操作が可能。 |
| fsck/chkdsk | Linux(fsck)/Windows(chkdsk)のファイルシステム修復コマンド。 |
| GDPR | EU一般データ保護規則。個人データ保護の規制。違反時は高額罰金リスクあり。 |
| FISMA | 米国連邦政府情報セキュリティ管理法。連邦調達企業も準拠が求められる場合あり。 |
| KPI | 重要業績評価指標。BCP運用では復旧時間達成率や訓練参加率などが該当。 |
| テーブルトップ演習 | 紙ベースや会議室でのシミュレーション訓練。BCPの実践準備に有効。 |
| フルリハーサル演習 | 実システムを使った本番環境に近い訓練。実行可能性を高めるために必須。 |
| WORMストレージ | 書き込み後に改ざん不可のストレージ。ログや証跡の保全に利用。 |
| 二要素認証 | パスワードに加え、ワンタイムトークンなどを用いる認証方式。不正アクセス防止に有効。 |
| ゼロトラストセキュリティ | 社内外ネットワークを区別せず、すべてのアクセスを検証するセキュリティモデル。 |